
Historical Knowledge Modelling and Analysis through Ontologies and
Timeline Extraction Operators: Application to Computing Heritage
Christophe Ponsard
1
, Aur
´
elien Masson
2
and Ward Desmet
3
1
CETIC Research Centre, Charleroi, Belgium
2
ESEO Engineering School, Angers, France
3
NAM-IP Computer Museum, Namur, Belgium
Keywords:
Domain Specific Modelling, Ontology, Historical Knowledge, Visualization, Timeline, Case Study.
Abstract:
Cultural heritage as human science has a long tradition of text-based reporting and analysis. This domain
has a very rich semantic structure, especially to relate many different types of entities anchored in some time
period with more or less strong temporal inter-dependencies. Various modelling approaches, largely based on
ontologies, have been proposed to capture and structure this kind of knowledge. In this paper, we are inter-
ested in easing the analysis capabilities on historical knowledge using the timeline as central concept that can
be extracted and manipulated in various ways through specific operators sharing some similarities with multi-
dimensional analysis in business intelligence. We propose zooming on a specific aggregates, pivoting from a
timeline to another one or drilling-across to compare different timelines. Our work is illustrated on a concrete
implementation targeting the Computing Heritage of the micro-computer period, including machines, operat-
ing systems, companies, people and applications. The information is extracted from a museum information
system combined with DBPedia. We also developed a specific visualisation tool under the form of a mobile
application which can also be used as museum guide.
1 INTRODUCTION
As defined by the SAGE dictionary (Thorpe and Holt,
2007): “Historical analysis is a method of the exam-
ination of evidence in coming to an understanding of
the past. It is particularly applied to evidence con-
tained in documents, although it can be applied to
all artefacts. The historian is, first, seeking to gain
some certainty as to the facts of the past. Establish-
ing the facts also gives the researcher a chronology.
The second task is to seek to establish cause and ef-
fect between those facts in order to understand why
things happened. It is important to remember that
while the past is the immensity of everything that has
happened, history is what we know of the past”. The
way the past is presented is usually based on a nar-
rative because “Human beings are story tellers who
exist ontologically in a universe of narrative making”
(Ankersmit, 2005).
The above references highlight fundamental as-
pects of historical analysis and reporting:
• history is what we know about the past,
• its analysis is based on the identification of the
chronology and casual relations across facts, and
• its reporting is done through some form of narra-
tive referring to an ontology.
The development of computer technologies and net-
works has led to the emergence of digital history
which goes far beyond the pure digital formatting of
content. It also enables new forms of historical anal-
ysis and visualisations (Burton, 2005), especially “vi-
sual historiography” which integrates non-textual ma-
terials into historical representations and hypertexts
with social, spatial, and chronological perspectives
(Roegiers and Truyen, 2006).
This paper focuses on a such visualisations
through a common form of visual representation for
time-based narrative: the timeline. Beyond the mere
chronological representation of events in chronologi-
cal order, the way it is build and displayed can exploit
a rich set of relationships such as mereology (is part
of), causality (is cause/consequence) and thematic as-
pects (tags). This requires conceptualisation and the
explicit modelling of event structure and relationships
through an adequate meta-model or ontology. Provid-
ing flexible and dynamic timeline visualisation means
is useful both for:
• understanding history by engaging with the model
302
Ponsard, C., Masson, A. and Desmet, W.
Historical Knowledge Modelling and Analysis through Ontologies and Timeline Extraction Operators: Application to Computing Heritage.
DOI: 10.5220/0010900400003119
In Proceedings of the 10th International Conference on Model-Driven Engineering and Software Development (MODELSWARD 2022), pages 302-309
ISBN: 978-989-758-550-0; ISSN: 2184-4348
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

to produce explanations for some events by trac-
ing its connections with other events and the his-
torical context (Walsh, 1951), and
• providing specific views and explanations to the
general public in the context of an exhibition to
stress the importance/influence of specific events
or of a more global context, e.g. through parallel
related timelines.
The use case which triggered this work is an exhi-
bition about the micro-computer revolution from the
1970’s to the 1990’s which is technologically an-
chored in the development of microprocessors and
graphical user interfaces, and socially in the hacker
counter-culture. This work involved many timeline
visualisation both in the preparation phase and as vi-
sualisation support for the exhibition. In order to
go beyond static paper posters, we also designed an
application providing a dynamic form of navigation
through timelines. This work has led us to refine and
formalise our approach with the aim to define a more
general framework and tooling. The result could be
applied in a wider context: in a computer museum
but also in other kinds of museums or organisations
involved in historical studies. We report here about
our current progress and the following contributions:
• the design of the underlying ontology, based on a
comparative survey,
• the extraction of interesting timelines from the re-
sulting knowledge base, and
• the illustration of specific visualisations though
our application.
This paper structure follows the above contributions.
Our micro-computer case study is used as running ex-
ample. Sections 2, 3 and 4 will respectively cover on-
tology design, timeline extraction and visualisation.
Section 5 will discuss our results. Finally, Section 6
will conclude and give some perspectives.
2 ONTOLOGIES FOR
HISTORICAL KNOWLEDGE
Many ontologies and meta-models have been pub-
lished and provide solid grounds to build a knowledge
base. This section reviews the main representatives
and compares them against key concepts for digital
history processing.
2.1 Simple Event Model (SEM)
Events have become central elements in the represen-
tation of data from domains such as history, cultural
heritage, multimedia and geography.
The Simple Event Model (SEM) is an ontology
created to model events in various domains such as
history, cultural heritage, multimedia and geography,
without making any assumptions about the domain-
specific vocabularies used (W3C, 2009)(van Hage
et al., 2011). It is designed with a minimum of se-
mantic commitment to guarantee maximal interoper-
ability. SEM is structured around four core concepts
depicted in Figure 1:
• Event is the central concept. It has a loose def-
inition (e.g. possibly fictional) and can originate
from different sources. To cope with this, events
may have bounded roles, related facts may have
time bounded validity and an authoritative source
may be associated to views.
• Actor: who or what participated in an Event.
• Place: where the an Event took place.
• Time: when the Event took place.
In this case study statement “The UK company Sin-
clair Radionics Ltd was founded by Clive Sinclair in
1961”: the Event is the foundation, the Actor is Clive
Sinclair, the Time is 1961 and Place is UK.
Figure 1: Simple Event Model.
Historical Knowledge Modelling and Analysis through Ontologies and Timeline Extraction Operators: Application to Computing Heritage
303
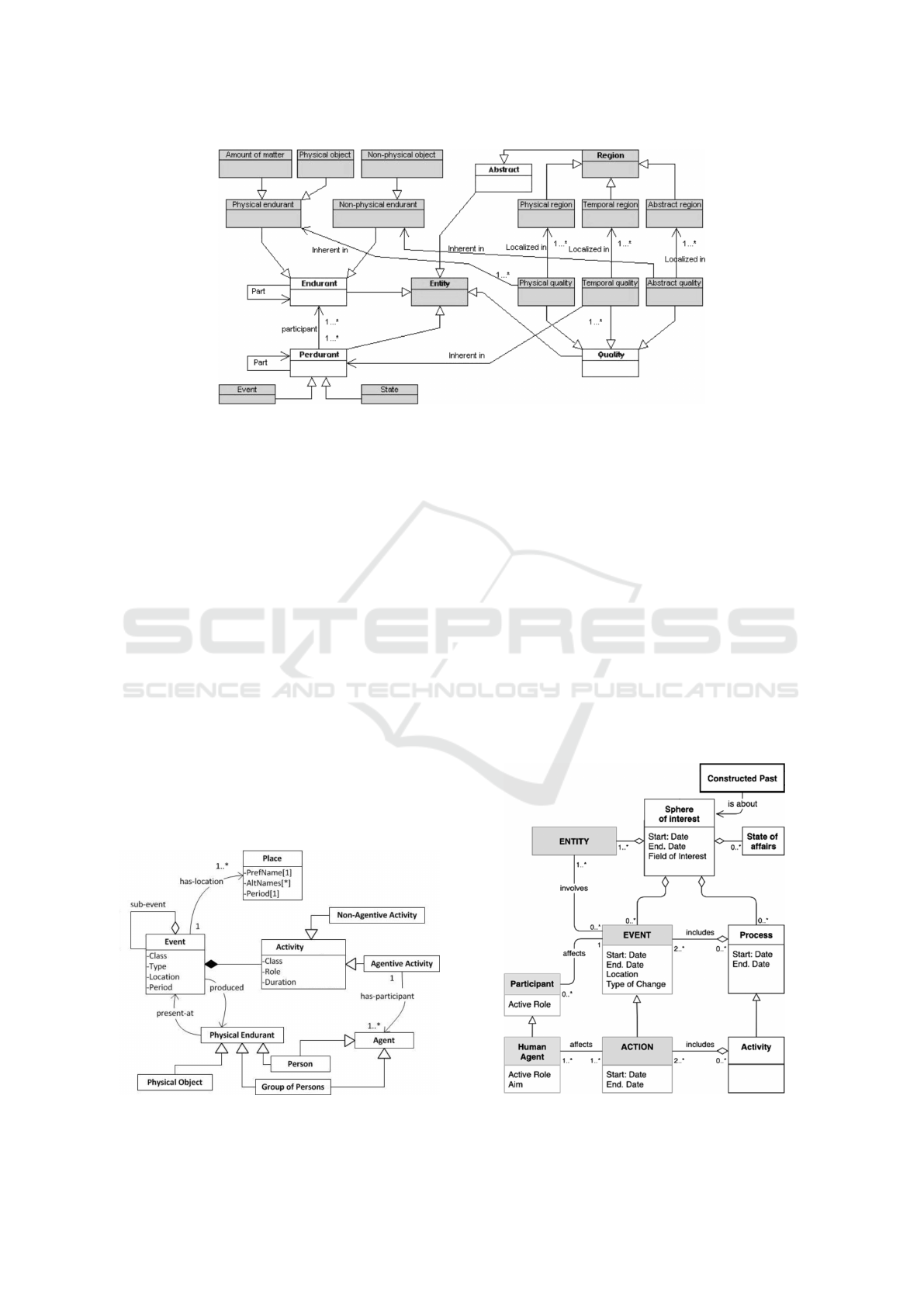
Figure 2: DOLCE Foundational Ontology.
2.2 DOLCE and Extensions
DOLCE (Descriptive Ontology for Linguistic and
Cognitive Engineering) is a foundational ontology
(FO) developed originally in the EU WonderWeb
project (Masolo et al., 2003). FOs are domain-
independent axiomatic theories that provide solid
grounds to capture and reason about knowledge. Fig-
ure 2 depicts the meta-model using an UML class di-
agram. It is structured using the dual concepts of En-
durant (including Objects or Substances) and Perdu-
rant (including Events, States, or Processes) which
are linked by the relation of participation:
• Endurants: localized in space, they get their tem-
poral location from Perdurants they participate in.
• Perdurants: localized in time, they get their spa-
tial location from Endurants participating in them.
• Additionally, specific qualities can characterise
either Endurants (as Physical or Abstract Quali-
ties) or Events (as Temporal Qualities). Each kind
of Quality is associated to a Quality Space repre-
senting its range of possible values.
Figure 3: Spatial History Ontology.
Examples of Endurants in our exhibition are
micro-computers (e.g. IBM-PC, ZX81) and people
like computer scientists or entrepreneurs (e.g. Bill
Gates, Steve Jobs). However, the later have can ini-
tiate events while the former are pure physical ob-
jects. This finer-grained level is supported by ex-
tended ontologies such as Spatial History Ontology
(SHO) (Grossner, 2010) shown in Figure 3.
2.3 Constructed Past Theory (CPT)
Constructed Past Theory is an epistemological theory
about how we come to know things that happened or
existed in the past (Thibodeau, 2019). It is more elab-
orated in making the distinction between constructed
and target past. Is it specified as UML class diagram
partly depicted in Figure 4.
Figure 4: Constructed Past Theory (UML meta-model).
MODELSWARD 2022 - 10th International Conference on Model-Driven Engineering and Software Development
304

Figure 5: Main Structure of DBpedia.
It covers the SEM concepts of Event and En-
tity, including active. However, space and time
are captured as attributes and not as first class con-
cepts as in SEM and DOLCE. More complex events
can be captured through processes which is also
present in DOLCE (aggregated Perdurant) and SEM
(subevents).
2.4 DBPedia Ontology
The previous meta-models are interesting but in order
to be practical, data must be available. A rich form of
data is provided by wikipedia. Structured information
(e.g. infoboxes) is collected by DBPedia (Bizer et al.,
2009)(Cvjetkovic et al., 2013)(Lehmann et al., 2015).
It is organised into a dedicated semantic web ontology
depicted in Figure 5. It shows the presence of the key
concepts discussed before: general Thing and a more
specialised form of Agent. The notion of Space is also
explicit.
However, the notion of Event is not a first class
concept: time aspects are only attached to specific
concepts as attributes, e.g. birth and death date of a
Person, release date or a Work. Consequently, build-
ing timelines requires to perform complex queries to
gather the relevant information possibly across differ-
ent concepts. DBPedia can be queried using SparQL
(SPARQL Protocol and RDF Query Language), a
standardised semantic query language for databases
able to retrieve and manipulate data stored in Re-
source Description Framework (RDF) format (OMG,
2008).
Listing 1: SparQL query over computer companies.
SELECT DISTINCT ? da t e ?name
WHERE {
? company f o a f : name ? name .
? company dbo : i n d u s t r y d b r : C o m p u t e r ha r d w a r e .
? company dbo : fou nde dBy ? f o u n d e r .
? company dbo : f o u n d i n g Y e a r ? da t e .
FILTER ( ? d a t e <= ” 1 9 9 0 0 1 0 1 ” ˆ ˆ xsd : d a t e )
}
ORDER BY ASC( ? d a t e )
LIMIT 100
Listing 1 shows how to retrieve companies active
in computer hardware founded before 1990. The for-
mulation of the query requires careful design as data
can be quite heterogeneous. This query yields the re-
sult partially depicted in Listing 2 which represents a
timeline. Note that extra attributes retrieved by the re-
lated query are not shown but can be used e.g. founder
and other company attributes. Note the interesting du-
plicate: HP Inc. and Hewlett-Packard. It can be ex-
plained by the split of this company in 2015. Such
evolution is not yet captured by our current frame-
work.
Listing 2: SparQL query over computer companies.
d a t e name
1911 I n t e r n a t i o n a l B u s i n e s s Mach i nes C o r p o r a t i o n
1939 HP In c .
1939 Hewlett − P a c k a r d Company
1958 Commodore I n t e r n a t i o n a l C o r p o r a t i o n
1959 K o n t r o n S\&T AG
1960 Augmentation Re s e a r c h
. . .
Historical Knowledge Modelling and Analysis through Ontologies and Timeline Extraction Operators: Application to Computing Heritage
305
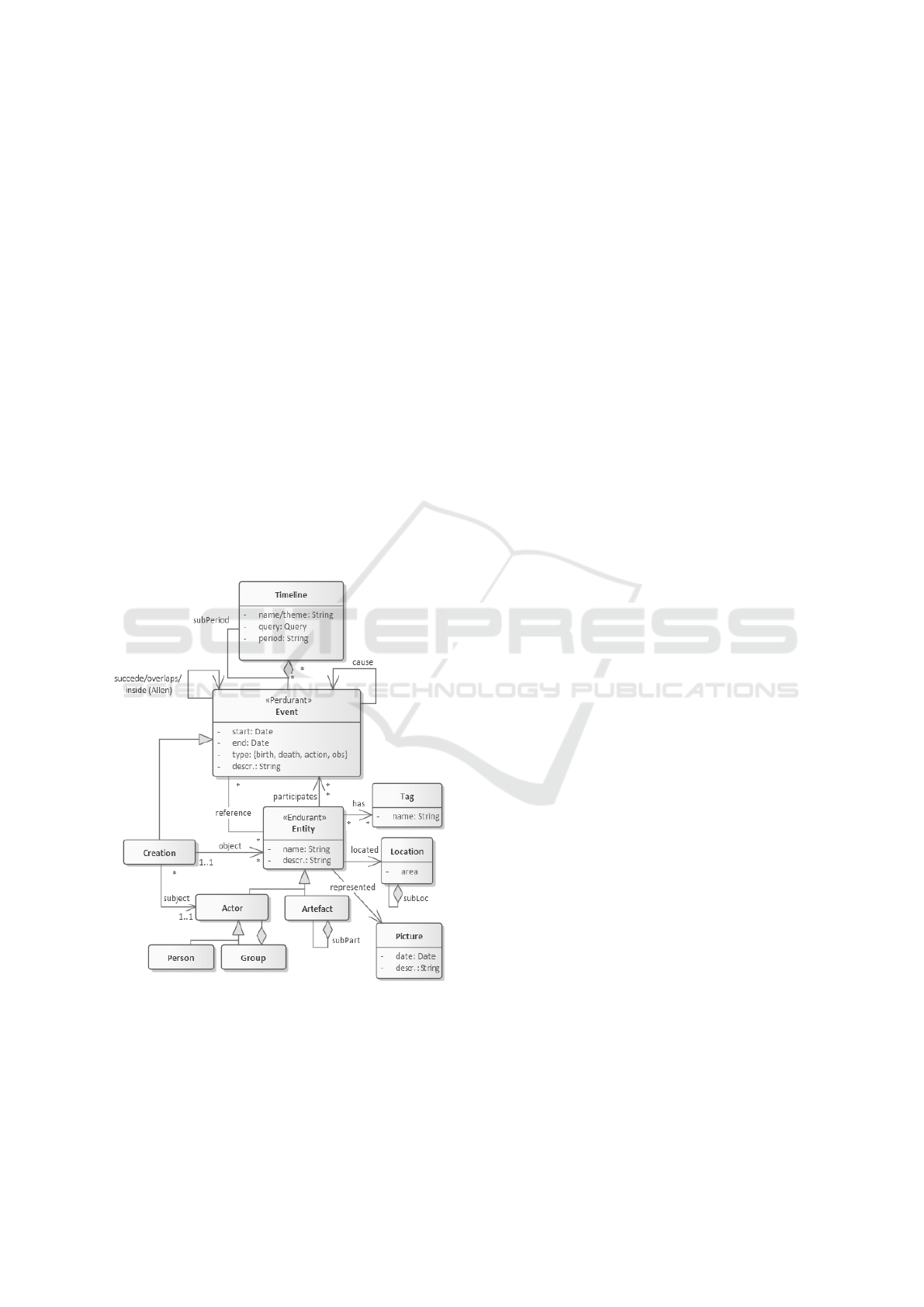
3 TIMELINE PROCESSING
This section details how our timelines are represented
and manipulated. First, we present our meta-model
design which is strongly inspired from the ontologies
reviewed in Section 2. Second, we identify the main
timeline extraction and navigation operations in order
to provide interesting ways to walk through a domain
using the time dimension as main representation but
also by exploiting various filters and interconnections
present in our meta-model.
3.1 Meta-model Design
The survey in the previous section illustrated that the
identified ontologies share key concepts of event, ac-
tive/passive objects and links with space and time in-
formation but with some differences on how to gener-
alise or specialise them. We did not select a specific
ontology literally but produced a customised meta-
model strongly aligned with them, only keeping com-
mon and relevant concepts fitting our need to reason
on timelines. Figure 6 depicts its current version.
Figure 6: Current Timeline-oriented Meta-model.
Our approach was to combine the strong theoret-
ical background based on DOLCE/SHO while keep-
ing it as simple as possible like SEM while enabling
to rely on information extracted from DBPedia. Our
goal is to build a high quality knowledge base by
combining first class data sources like museum in-
ventory and implementing a cleaning and validation
process by relying on open data. We explicitly mod-
elled the Timeline as first class concept because it is
central to our time-oriented approach while Space is
captured using a Location concept. We refer to Per-
durant (Events) and Endurant (either passive: Ob-
jects or active: Actors) using stereotypes. We sup-
port aggregation for all concepts with possible sub-
timelines (e.g. specific phases of micro-computer de-
velopment), sub-locations (e.g. a specific country,
town), groups for actors (to capture the notion of com-
pany, department, e.g. XEROX PARC) and objects
sub-parts (e.g. computer monitor, central unit, key-
board). An Object can be of physical but also logical
nature, e.g. software in our case.
3.2 Timeline Extraction and Navigation
Assuming we have achieved data collection and vali-
dation according to our meta-model, we can consider
the user experience going through the knowledge base
using timelines. It is interesting to explore what kind
of timeline can be extracted and how they can be con-
nected together. We could identify different meaning-
ful timelines that collect related events by focusing
on:
• actor(s) at different granularity levels: it can be
the life of a person, a group or a company, possi-
bly with a focus on common event characteristics,
• object(s), also at different granularity levels: it
could relate to the precise history of a specific ob-
ject (e.g. the design of the LISA computer) but
also of a family of objects according to specific
criteria, e.g. micro-computer of a specific period,
manufacturer, using a specific CPU,...
• temporal, spatial or thematic contexts, respec-
tively through specific Event (dates), Location or
Tag characteristics. Different granularity levels
can also be considered, e.g. to reflect the com-
puter history related to micro-computer in France
from 1970 to 1985. This can come as additional
filter for the previous types of timelines.
Moreover timelines can be enriched by following
specific dependencies such as causality links or ex-
pressed by explicit references to secondary enti-
ties. However, this can result in losing focus so we
favoured a more dynamic mechanism through the use
of different navigation operators allowing the user to
easily “switch”between timelines according to spe-
cific aspects he would like to investigate. This shares
some similarities with OLAP operators in multidi-
mensional analysis, although we only focus on time
here (Salley and Codd, 1998).
Figure 7 reflects this idea by showing 6 timelines
MODELSWARD 2022 - 10th International Conference on Model-Driven Engineering and Software Development
306

with different scopes (Person, Company, Operating
System,...) with intersecting points through specific
events which can be used as pivot to change perspec-
tive. Some possible operators are:
• event pivoting between related entities or features:
e.g. from Amiga 500 computer to Commodore
Company or the 68k CPU or GUI timeline.
• time zoom in/out based on a defined period, e.g.
the micro-computer history can be divided in
early, golden age and standardisation periods.
• actor zoom in/out, from person level to company.
• object zoom in/out, e.g. down to version/variant
level and up to product family level.
• relations inclusion, possibly iterative and with
closure, e.g. to follow casual relation to look for
causes/consequences related to some events.
• combining multiple timelines together either
merged or keeping them separated with an ad-
equate visualisation (temporal alignment, shared
events, specific relations...)
Figure 7: Navigation through Pivoting.
4 IMPLEMENTATION
Our current implementation is a monolithic proto-
type mobile application composed of two main com-
ponents: a database and a visualisation module.
The database implements our meta-model using a
lightweight SQLite relational database (Hipp, 2000)
fed by local computer inventory and DBPedia. The
visualisation relies on React Native (Facebook, 2015)
which provides a nice interface for a museum guide.
It can later evolve towards a client/server application
and is already available in Open Source (NAM-IP,
2021). Figure 8 shows a typical usage scenario with a
pivoting between two timelines, from left to right:
1. a timeline showing some computers of the second
phase (1977-1990),
2. a navigation to the Amiga 500 computer launched
in 1987 displaying features such as the manu-
facturer, location, Operating System (OS), all of
which are possible entry points to other timelines,
3. as the user decided to pivot to OS, the OS timeline
is shown with a focus on the Amiga OS.
The user is also able to configure its timeline by se-
lecting a specific period or the whole history, and by
enabling or disabling different thematic features such
as machines (MICRO), operating systems (OS), pro-
cessors (CPU), user interface (IHM) or applications
(APP). At this point, all events are merged and only
the start date is considered so possible overlaps are
not reflected. In order to have a better view, especially
on smaller displays, a compact mode not showing pic-
ture nor first lines of description is available.
Figure 8: Navigation Scenario through our Mobile Guide.
Historical Knowledge Modelling and Analysis through Ontologies and Timeline Extraction Operators: Application to Computing Heritage
307

5 DISCUSSION OVER RELATED
WORK
The use of timelines in visual historigraphy has been
discussed in the introduction. From a research per-
spective, the importance of tools providing visual
contextualization of events is well-known (Shneider-
man, 1996). We focus here on software development
sharing similarities with our approach.
ChronoZoom is an open source data visualiza-
tion tool that supports zooming through time to ex-
plore timelines across the whole history of the uni-
verse down to present history of humanity (Walter
et al., 2013). It is fully web-based and has an ef-
ficient Cloud-based hosting providing efficient “infi-
nite” zooming capabilities. It allows the user to cre-
ate or customize timelines and to plot various time
series data next to each other for comparison. Our
approach is less ambitious as we only focus on spe-
cific thematic typically the domain of a museum. Al-
though we focused on a specific exhibition, our ap-
proach is general and inspired by major ontological
frameworks but also practical semantic web technolo-
gies, which opens the way to grab information from
Wikipedia contributions. As ChronoZoom, we target
both education and research but our current front-end
is more focused on education. At the technological
level, our solution can grab data from a locally em-
bedded database but possibly also from a web API
although not optimised for large scale use.
Different mobile applications have been devel-
oped more specifically for supporting computer his-
tory in general or in the context of a museum collec-
tion. They rely on the notion of timeline more or less
explicitly. The Nexon Computer Museum, the first
Korean Computer Museum with approximately 7,000
artifacts has a complete application to browse through
the 400 artefacts on display and relying on a chrono-
logical ordering (Nexon, 2013). It gives details but
few navigation operations. A computer history time-
line developed by a company specialised in guides is
also available for Android (Every Time Apps Studio,
2018). It is close to a poster timeline with however
a practical slider for quick access. Different websites
also publish computer timeline, including the famous
Computer History Museum (CHM, 2021). It recaps
the main events with a zoom by decades and years. It
also proposes classification in different themes as we
do, and additionally a search engine.
Gathering and qualifying data is a difficult task
and can benefit from the semantic web. Our current
approach relies on DBPedia (Bizer et al., 2009) but
other knowledge graphs could be used such as the
one provided by Google (Google, 2012), although
it is itself largely based on Wikipedia. A difficulty
is to achieve a mapping towards on our meta-model
given the diversity of fields which are not uniformly
used. Moreover the content is largely pure text, which
means many interesting information cannot be auto-
matically extracted with semantic search engines. A
solution to this is the use of a semantic extension
enabling to make semantic content explicit and thus
make it visible to DBPedia (Vrandecic and Krotzsch,
2005). Another/complementary approach is to rely
on natural language processing to extract such knowl-
edge provided some form of reliability can be en-
forced. In our approach, we introduced a basic form
of semantic processing by detecting synonyms in our
text description, e.g. ”First Macintosh” or ”Macintosh
128K” or ”Apple Macintosh” which can be extracted
from DBPedia and manually enriched as required.
Specialised work on the formulation and recognition
of temporal patterns of events in English could also
be considered (Saygi et al., 2018).
6 CONCLUSION & NEXT STEPS
In this paper, we presented our current progress in
developing a framework for modelling and analysing
historical knowledge by relying on timeline extrac-
tion, navigation and visualisation techniques. Al-
though anchored in a specific case study of computer
heritage, we took care of setting solid foundations
based on a survey of relevant ontologies. We could
successfully implement a prototype application based
on a designed meta-model populated by a validated
dataset mixing in-house and DBPedia information.
The application, currently under validation in our mu-
seum, is quite appreciated.
Our framework is already available in Open
Source on Github (NAM-IP, 2021). In the future,
we plan to extend it in different directions: introduce
more pivot points in the user interface, support par-
allel visualisation of timelines, provide location fil-
tering and new categories for more cultural or politi-
cal context and references. We also plan to elaborate
a web-service API with a robust and scalable graph
database as backend. At longer term, a collaborative
web client with semantic editing capabilities will be
considered.
ACKNOWLEDGEMENTS
We thanks the volunteers and anonymous visitors of
the NAM-IP computer museum for their feedback on
our current prototype.
MODELSWARD 2022 - 10th International Conference on Model-Driven Engineering and Software Development
308

REFERENCES
Ankersmit, F. (2005). Sublime Historical Experience.
Cultural memory in the present. Stanford University
Press.
Bizer, C. et al. (2009). DBpedia - A crystallization point for
the Web of Data. Journal of Web Semantics, 7(3):154–
165. The Web of Data.
Burton, O. V. (2005). American Digital History. Social
Science Computer Review, 23(2):206–220.
CHM (2021). Timeline of computer history. https://www.
computerhistory.org/timeline.
Cvjetkovic, V., Djokic Petrovic, M., and Arsic, B. (2013).
Wikipedia Browsing With DBpedia. In The 2nd Elec-
tronic International Interdisciplinary Conference.
Every Time Apps Studio (2018). History of Computer.
Google Play Store.
Facebook (2015). React native. https://reactnative.dev.
Google (2012). Knowledge Graph. https://developers.
google.com/knowledge-graph.
Grossner, K. (2010). Representing Historical Knowledge in
Geographic Information Systems. PhD thesis.
Hipp, D. R. (2000). Sqlite. https://www.sqlite.org.
Lehmann, J. et al. (2015). Dbpedia - a large-scale, multi-
lingual knowledge base extracted from wikipedia. Se-
mantic Web, 6(2):167–195.
Masolo, C., Borgo, S., Gangemi, A., Guarino, N., and
Oltramari, A. (2003). Ontology Library D18. Won-
derWeb project.
NAM-IP (2021). Mobile museum guide. https://github.
com/NAMIP-Computer-Museum/guideApp.
Nexon (2013). Mobile application of the computer
museum. https://www.nexoncomputermuseum.org/
english.
OMG (2008). SPARQL Query Language for RDF. https:
//www.w3.org/TR/rdf-sparql-query.
Roegiers, S. and Truyen, F. (2006). History is 3D: present-
ing a framework for meaningful historical representa-
tions in new media. New heritage: beyond verisimili-
tude, pages 49–57.
Salley, C. and Codd, E. F. (1998). Providing OLAP to User-
Analysts: An IT Mandate.
Saygi, G., Blaise, J.-Y., and Dudek, I. (2018). Temporal
hints in the cultural heritage discourse: what can an
ontology of time as it is worded reveal? Revue des
Nouvelles Technologies de l’Information.
Shneiderman, B. (1996). The eyes have it: A task by data
type taxonomy for information visualizations. IEEE
Computer Society.
Thibodeau, K. (2019). The construction of the past: To-
wards a theory for knowing the past. Information, 10.
Thorpe, R. and Holt, R. (2007). The SAGE Dictionary of
Qualitative Management Research. SAGE Publica-
tions.
van Hage, W. R., Malais
´
e, V., Segers, R., Hollink, L., and
Schreiber, G. (2011). Design and use of the Sim-
ple Event Model (SEM). Journal of Web Semantics,
9(2):128–136.
Vrandecic, D. and Krotzsch, M. (2005). Semantic wiki.
https://www.semantic-mediawiki.org.
W3C (2009). ”simple event model”. https://semanticweb.
cs.vu.nl/2009/11/sem/.
Walsh, W. H. (1951). An Introduction to Philosophy of His-
tory.
Walter, R. L., Berezin, S., and Teredesai, A. (2013).
Chronozoom: Travel through time for education, ex-
ploration, and information technology research. As-
sociation for Computing Machinery.
Historical Knowledge Modelling and Analysis through Ontologies and Timeline Extraction Operators: Application to Computing Heritage
309
