
Uniform Density in Linguistic Information Derived from Dependency
Structures
Michael Richter
1 a
, Maria Bardaj
´
ı I Farr
´
e
2 b
, Max K
¨
olbl
1 c
, Yuki Kyogoku
1
,
J. Nathanael Philipp
1 d
, Tariq Yousef
1 e
, Gerhard Heyer
1
and Nikolaus P. Himmelmann
2 f
1
Institute of Computer Science, Natural Language Processing Group, Leipzig University, Germany
2
Institute of Linguistics, University of Cologne, Germany
Keywords:
Dependency Structures, Uniform Information Density, Universal Dependencies.
Abstract:
This pilot study addresses the question of whether the Uniform Information Density principle (UID) can be
proved for eight typologically diverse languages. The lexical information of words is derived from dependency
structures both in sentences preceding the sentences and within the sentence in which the target word occurs.
Dependency structures are a realisation of extra-sentential contexts for deriving information as formulated in
the surprisal model. Only subject, object and oblique, i.e., the level directly below the verbal root node, were
considered. UID says that in natural language, the variance of information and information jumps from word
to word should be small so as not to make the processing of a linguistic message an insurmountable hurdle. We
observed cross-linguistically different information distributions but an almost identical UID, which provides
evidence for the UID hypothesis and assumes that dependency structures can function as proxies for extra-
sentential contexts. However, for the dependency structures chosen as contexts, the information distributions
in some languages were not statistically significantly different from distributions from a random corpus. This
might be an effect of too low complexity of our model’s dependency structures, so lower hierarchical levels
(e.g. phrases) should be considered.
1 INTRODUCTION
The current work is a pilot study based on the hypoth-
esis that dependency structures may serve as prox-
ies for the contextual factors relevant in computing
Uniform Information Density (UID). The primary re-
search question is: can the UID-principle in linguistic
utterances be proved by information derived from de-
pendency structures in extra-sentential contexts of a
target word?
The UID principle claims of a universal condition
of successful linguistic communication. It says that
the flow of information in any natural language should
be uniform, that is to say, without extreme peaks and
troughs of information, in order not to overload the
a
https://orcid.org/0000-0001-7460-4139
b
https://orcid.org/0000-0003-3512-0435
c
https://orcid.org/0000-0002-5715-4508
d
https://orcid.org/0000-0003-0577-7831
e
https://orcid.org/0000-0001-6136-3970
f
https://orcid.org/0000-0002-4385-8395
communication channel’s capacity. In case of an in-
formation overload, the processing of the message -
and thus successful communication - is threatened,
for instance, the comprehension of a linguistic mes-
sage. (Jaeger, 2010, 25) formulates the following
cognitive principle:
“Within the bounds defined by grammar,
speakers prefer utterances that distribute infor-
mation uniformly across the signal (informa-
tion density). Where speakers have a choice
between several variants to encode their mes-
sage, they prefer the variant with more uni-
form information density (ceteris paribus).”
If the density of information in a linguistic utter-
ance is ”dangerously high” (Levy and Jaeger, 2007),
that is, if the information structure within that utter-
ance exhibits extreme peaks, this might cause mas-
sive problems in comprehension. Consider, for exam-
ple, the garden path sentence with dropped relative
pronoun the horse raced past the barn fell, which,
as (Crocker and Demberg, 2015) demonstrate, is ex-
496
Richter, M., Bardají I. Farré, M., Kölbl, M., Kyogoku, Y., Philipp, J., Yousef, T., Heyer, G. and Himmelmann, N.
Uniform Density in Linguistic Information Derived from Dependency Structures.
DOI: 10.5220/0010969600003116
In Proceedings of the 14th International Conference on Agents and Artificial Intelligence (ICAART 2022) - Volume 1, pages 496-503
ISBN: 978-989-758-547-0; ISSN: 2184-433X
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

tremely hard to process since the sentence-final fell
is highly surprising and has thus a high information
value, thereby forming an information peak. UID,
therefore, seems to be an essential principle of lan-
guage processing. This study aims to check whether
the UID principle holds when extra-sentential con-
texts for calculating the information content of words
are considered. Formal definitions of UID (given in 6
and 7 below) consider both the variance of informa-
tion in messages, for example, in sentences, and the
change of information from sign to sign in messages,
for instance, from word to word in sentences (Collins,
2014; Jain et al., 2018). Our prediction for the eight
languages in focus is that the variance and informa-
tion change per word will be small on average and
per sentence.
In contrast to the assumption of the cross-
linguistically valid UID principle, we assume that
information derived from dependency structures is
language-dependent. Therefore we exploit corpora
from typologically different languages: the empirical
testing ground for this study is a convenience sam-
ple of the non-European languages Indonesian and
Arabic and some European languages from different
language subfamilies, i.e. Russian (Slavic), Span-
ish, French (Romance), Swedish and German (Ger-
manic). Including more than one language from the
same (sub)family allows us to see whether the Ro-
manic or the Germanic languages, respectively, be-
have similarly.
Shannon defines information as the likelihood of a
sign s (Shannon, 1948). Shannon Information (SI), in
bits, is the log-transformation of the sign’s probability
whereby s represents a sign, given equation 1:
SI(s) = −log
2
(P(s)) (1)
Intuitively, the number of bits corresponds to the
number of ‘yes/no’-questions to determine a possible
state in a probability space, and it is important to clar-
ify that information in Shannon’s theory is different
from the concept of ’information’ in linguistics and
also in everyday language use. Initially, the mean-
ing of messages was not of any interest for Shan-
non, since “[...] semantic aspects of communication
are irrelevant to the engineering problem[. . . ]” (Shan-
non and Weaver, 1949), i.e. for the optimal coding
and transmission of messages. In particular since
the seminal work of (Dretske, 1981), the relation-
ship between Shannon information and natural lan-
guage understanding came into focus (see for instance
(Resnik, 1995; Melamed, 1997; Bennett and Good-
man, 2018)). This is also important for our study,
since the UID deals with principles of language un-
derstanding. In surprisal theory (Hale, 2001), infor-
mation is derived from conditional probabilities, i.e.,
given a context. (Levy, 2008) equals information con-
tent of a sign with its surprisal, which, in turn, is
proportional to the processing effort it causes (Hale,
2001; Levy, 2008): the more surprising a sign s is,
that is to say, the smaller its probability is in a con-
text. The more informative s is, the higher the effort
is to process it. This relationship is given in 2:
di f f iculty ∝ surprisal (2)
This corresponds to Zipf’s law (Zipf, 2013),
which describes the negative correlation between fre-
quency and length of linguistic signs and, in addition,
the principle of least effort (Zipf, 1949): frequently
occurring signs tend to be short, rarely occurring ones
tend to be longer and tend to have higher information
content. (Levy, 2008) points out that in the Surprisal
Model model of language comprehension that em-
ploys information theory, large, extra-sentential con-
texts need to be considered to estimate a word’s infor-
mation content (IC). This is represented in 3 by the
variable CONTEXT:
SI(w
i
) = −log
2
P(w
i
|w
1
...w
i−1
, CONTEXT) (3)
However, (Levy, 2008) gives no clear definition
of what a context is. This makes the notion of extra-
sentential context somewhat challenging to grasp and
might explain that, to our best knowledge, there are
no studies on the calculation of information utilis-
ing large contexts. In this paper, we will explicitly
take up the idea of extra-sentential contexts by us-
ing dependency structures on the highest hierarchy-
level (directly below the verbal root-node) in sen-
tences that precede the target word and in the actual
sentence a target word occurs. Thereby we take up
an idea from (Levshina, 2017), who estimated lexi-
cal information from dependency structures. How-
ever, in contrast to Levshina, we consider complete
syntactic dependency patterns in sentences. We as-
sume that the languages in focus differ in terms of
their dependency structures: differences in the posi-
tion of subjects and objects are to be expected because
our set of languages contains both strongly inflected
and weakly inflected languages, with the former tend-
ing to have greater freedom in word position in the
sentence. Consequently, when deriving lexical in-
formation from language-specific dependency struc-
tures, there should be differences in the distribution
of information between the languages.
The present study uses the existing – partly quite
small - corpora in the Universal Dependency Tree-
banks
1
; in this respect, our study is based on conve-
nience sampling. For some languages like Indone-
sian, larger Dependency treebanks as models need to
1
https://universaldependencies.org
Uniform Density in Linguistic Information Derived from Dependency Structures
497

be annotated to prepare testing corpora of sufficient
sizes (a task we are currently engaged in). Our inten-
tion is to subject the usability of a syntactic-semantic
context type for deriving the information content of
words to a first empirical test based on these data.
2 RELATED WORK
(Levy, 2008; Levy, 2018) found a positive correla-
tion between surprisal and processing effort of signs,
which underpins the relevance of UID. Processing ef-
fort was operationalized by measuring reading times:
surprising words in sentences need more time to be
read. In their study on the omission of the relative
pronoun in relative clauses (RC) in English, (Levy
and Jaeger, 2007) showed that that as a relative pro-
noun is omitted if RC is less informative. However,
in unexpected and (too) high informative RC, that is
not omitted: The relative pronoun signals to the hu-
man processor that a relative sentence follows, thus
reducing the amount of surprisal and information.
The study of (Horch and Reich, 2016) provided evi-
dence that for article omission in German, UID holds
on the level of non-terminal POS-tags and that POS-
tags provide even a better basis for explaining article-
omission than terminal symbols. Exploring Univer-
sal Dependency corpora from 30 languages, (Richter
et al., 2019) observed UID within two types of lexical
information of single words, i.e., lexical information
from pure unigram frequencies and lexical informa-
tion from conditional probabilities (n-grams): the two
lexical information values correlate negatively, but the
variance of information is not high, that is to say,
the information density is uniform (for the definition
of UID see equation 6 and equation 7) (Richter and
Yousef, 2019) came to the same result in their study
on verbal information content in six Slavic languages,
which is illustrated in figure 1 for Polish, Slovenian
and Latvian (The a-axis gives the UID-values, the y-
axis depicts the raw frequencies of the values).
3 CORPORA AND METHOD
As data resource, we utilised eight UD treebanks
(number of sentences in brackets) (version 2.8),
i.e., ar padt-ud-train.conllu.txt (7664), en ewt-
ud-train.conllu (16621), fr gsd-ud-train.conllu
(16341), de gsd-ud-train.conllu (15590), id gsd-ud-
train.conllu (5593), ru gsd-ud-train.conllu (5030),
es gsd-ud-train.conllu (16013), sv pud-ud-test.conllu
(1000). We consider subject, direct object, indirect
object and oblique as syntactic complements (in the
case of several oblique elements, we took only the
first ) in sentence frames on the top hierarchical level
below the verb root node. We calculated first the
individual information values of the word forms,
given in equation 4:
I(w) = −
1
N
N
∑
i=1
log
2
(P(w) ∗P(w|c
i
))
= −log
2
P(w) −
1
N
N
∑
i=1
log
2
P(w|c
i
) (4)
The information content of a word w is the aver-
age of its information I, which is made up of Shannon
Information and Surprisal of w. Equation 4 expresses
the concatenation of two types of information: infor-
mation of a given word in relation to all alternative
words and information in its contexts c
i
. . . c
n
, i.e., the
dependency structures in the environment of the target
word. A short fictitious example, starting from figure
2, may clarify the idea of deriving information from a
dependency frame as context. Note that the example
just covers P(w|c
i
) in equation 4 above:
Figure 2 depicts a sort of dependency structure
with which the verb esse
[1st person singular]
‘eat’ occurs.
The labels on the top level, directly below the node
TOP ROOT / S are SUBJ (=subject), OBJA (=di-
rect object) and ROOT (which indicates punctua-
tion). Without ROOT, the dependency structure is
SUBJ-OBJA. Let us say, that is dependency structure
#1. Let us further assume that in the entire corpus
esse occurs in 100 sentences, 50 times with depen-
dency structure #1, 30 times with dependency struc-
ture #2, which is, say, SUBJ-OBJA-OBJD(=indirect
object) and 20 times with dependency structure #3,
say, SUBJ-OBJA-OBL(=oblique). The dependency
structures #1, #2, and #3 occur each 1000 times in the
corpus. The average information of esse derived from
these dependency contexts is given in equation 5:
I(esse) = −
1
3
(log
2
0.05 + log
2
0.03 + log
2
0.02)
=5.01bits (5)
From the information values, we calculated the
Uniform Information Density (Collins, 2014; Jain
et al., 2018), that is in particular (i) the Global Uni-
form Information Density (UID
global
), i.e., the av-
erage variation of information within the sentences
of a language in a corpus (calculated with 6) and
finally (ii) the Local Uniform Information Density
(UID
local
), i.e., the average degree of information
changes from word to word within the sentences
(equation 7). Where IC is the information content of
a word form, N is the number of sentences in the cor-
pus, M is the number of tokens in a sentence, and is µ
NLPinAI 2022 - Special Session on Natural Language Processing in Artificial Intelligence
498

Figure 1: P Uniform Information Density in Polish, Slovenian and Latvian.
Figure 2: A type of dependency structure of the sentence ich esse einen Keks ’I eat a cookie’.
the average information content of a sentence.
UID
GLOBAL
= −
1
N
N
∑
i=1
M
∑
j=1
(IC
i j
−µ)
2
(6)
UID
LOCAL
= −
1
N
N
∑
i=1
M
∑
j=1
(IC
i j
−IC
i j−1
)
2
(7)
4 RESULTS
Figure 3 gives six figures for each language: from
left to right, these are (1) the density of the distribu-
tion (the area under the curve is 1) of the informa-
tion values derived from the dependency structures
of the previous sentence, (2) the density of the in-
formation distribution from the dependency structures
of the current sentence the target word occurs in, (3)
the density distribution of UID
global
of the previous
sentence, (4) UID
global
of the current sentence, (5)
UID
local
of the previous sentence, (6) UID
local
of the
current sentence. The x-axis in the plots of the first
two columns in figure 2 depicts the information val-
ues. The y-axis depicts the distribution of informa-
tion values. In columns three and four, the x-axis
depicts the variance of information in sentences, i.e,
UID
global
. Columns five and six depict the difference
in information from word to word in sentences. The
y-axis depicts the density in all plots, and the area un-
der the curve should be 1.
Figure 3 shows differences and similarities in the
distribution of information between languages (plots
in columns 1 and 2 from left). The genetically areally
related languages Germanic languages German and
Uniform Density in Linguistic Information Derived from Dependency Structures
499

Figure 3: Distribution of Information and UID
global
and UID
local
in eight languages. Columns 3 and 4 contain the plots
of UID
global
, and columns 5 and 6 contain the plots of U ID
local
, for both UIDs within previous and current sentences,
respectively. In columns 1 and 2, the x-axis gives the information values, in columns 3 - 5, the x-axis depicts the UID-values.
In all plots, the y-axis depicts the distribution of the respective values whereby the area under the curve is 1.
Swedish cluster together and show similar curves. In
contrast, Russian stands somewhat out from the other
languages. However, this does not appear to be neces-
sarily so since we observed similarities between Ara-
bic, English, Indonesian and the two Romance lan-
guages, French and Spanish. The UID curves (plots
3 – 6 in figure 3 above) show strong similarities be-
tween the languages. With UID
global
, English stands
out a little, but with UID
local
, almost identical den-
sity curves are shown for all languages. We also note
that the values for both UID
global
and U ID
local
are
close to 0. That is to say, the sentence-wise variance
of information in the eight languages and the aver-
age change of information from word to word is small
across the languages. In order to assess the relevance
of dependency structures at the top hierarchical level
as contexts for the information value calculation, we
compared the single language information values in
pairs with values from a random corpus using T-Tests
and Mann-Whitney-U-Tests.
We created the random corpus by extracting each
sentence frame and the set of words that belong to
the sentence frame. They are stored respectively in
a set of sentence frames and in a set of word sets,
in which the word order is maintained as in the sen-
tence. Then the set of sentence frames and the set of
word sets are randomly combined to change the orig-
inal arrangements between sentence frames and word
sets. The elements of a sentence frame must be fewer
than those of a word set. If a sentence frame is com-
bined with a word set whose elements are fewer than
those of the sentence frame, they are rearranged. For
example, the sentence frame ”[nsubj, obj, obl]” can-
not be combined with a word set ”[I, sleep]”, because
it is impossible for the word set with two elements to
possess three elements as a sentence frame.
The second and third columns of table 1 show the
p-values of the tests. A ”
√
” means the assumption of
NLPinAI 2022 - Special Session on Natural Language Processing in Artificial Intelligence
500
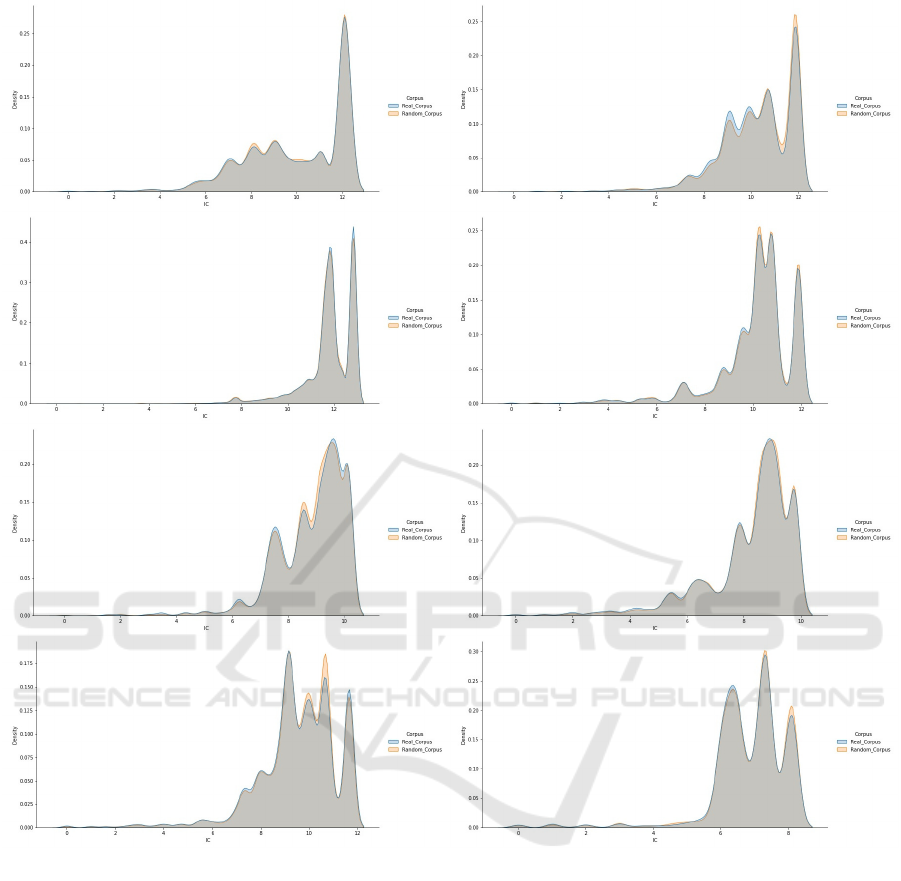
Figure 4: Density plots of the distribution of information derived from dependency structures in UD-corpora and in random
corpora in the eight languages. (Top row from left to right: Arabic, English; second row: French, German; third row
Indonesian, Russian; bottom row Spanish and Swedish). The x-axis gives the information values, the y-axis depicts their
distribution whereby the area under the curve is 1.
the null hypothesis, i.e., that both sets of information
values (language corpus-random corpus) are equally
distributed.
In English, French, Russian and Spanish, both the
null hypothesis of equality of the distribution function
and the equality of the means are rejected. In Ara-
bic and German, both the null hypothesis of equal-
ity of the distribution function and the equality of the
means are confirmed. In Indonesian and Swedish, the
equality of the distribution function is confirmed only
by the Mann-Whitney U-Test. These results suggest
that dependency structures at the highest hierarchical
level cannot derive different information courses in all
languages. This makes it necessary to include depen-
dency structures at lower hierarchical levels to derive
information values (see section 5). Figure 4 depicts
density plots of the distributions of information values
derived from dependency structures in (top row from
left to right) Arabic, English, French and (bottom row
from left to right) Indonesian, Russian, Spanish and
Swedish. The information values from the real cor-
pus are highlighted in blue, and the random corpus
values in orange. The grey colour indicates their over-
lapping range. Even in languages where the H0 hy-
pothesis was rejected, such as English, the curves are
very similar. This observation again underlines the
Uniform Density in Linguistic Information Derived from Dependency Structures
501

Table 1: Test for equality of the distribution functions of
the information values and equality of the means of natural
language corpora random corpus by the Mann-Whitney-U-
Test and the T-Test.
Language Mann-Whitney-U-test T-test
p-values
Arabic 0.85
√
0.37
√
English ∼ 0 ∼ 0
French ∼ 0 ∼ 0
German 0.34
√
0.09
√
Indonesian 0.51
√
0.03
Russian ∼ 0 ∼ 0
Spanish ∼ 0 ∼ 0
Swedish 0.06
√
0.02
necessity of including dependency structures of lower
hierarchies to calculate the information content.
5 CONCLUSION AND
DISCUSSION
Due to the sparseness of the data, the results of our
study are to be interpreted with all due caution. We
got evidence for the UID principle in linguistic utter-
ances with information of words that is derived from
dependency structures. We observed across the eight
languages in focus almost identical distributions of
the density values, which strengthen the hypothesis of
UID as a universal linguistic principle to enable and
facilitate language processing. However, the question
of whether dependency structures are suitable as con-
texts could not yet be answered conclusively: There
are differences in lexical information between the lan-
guages, but for some languages, we found the H0-
hypothesis to be valid, that is, there was no statistical
difference between information from the actual cor-
pus and a random corpus. We draw the preliminary
conclusion that deriving lexical information content
from complex sentence dependency structures seems
to be a promising approach - after all, the UID prin-
ciple could be substantiated. Nonetheless, future re-
search will have to address the inclusion of more com-
plex dependency structures from lower levels in the
sentence, such as phrase structures, to derive words’
information, and we will also expand the database.
Additionally, for an operationalising of the complete
surprisal-model, additional extra-sentential contexts
will have to be tested, for example, semantic contexts
in the discourse of a target word (K
¨
olbl. et al., 2020;
K
¨
olbl et al., 2021; Richter and Yousef, 2020), and so
future research will address the concatenation of the
different types of extra-sentential context types in the
surprisal model.
ACKNOWLEDGEMENTS
This work was funded by the Deutsche Forschungs-
gemeinschaft (DFG, German Research Foundation),
project number: 442315837.
REFERENCES
Bennett, E. D. and Goodman, N. D. (2018). Extremely
costly intensifiers are stronger than quite costly ones.
Cognition, 178:147–161.
Collins, M. X. (2014). Information density and dependency
length as complementary cognitive models. Journal
of psycholinguistic research, 43(5):651–681.
Crocker, M. and Demberg, V. (2015). Surprisal theory and
empirical evidence. https://www.coli.unisaarland.de/
∼
vera/InfoTheoryLecture3.pdf.
Dretske, F. (1981). Knowledge and the Flow of Information.
MIT Press.
Hale, J. (2001). A probabilistic earley parser as a psycholin-
guistic model. In Proceedings of the second meet-
ing of the North American Chapter of the Association
for Computational Linguistics on Language technolo-
gies, pages 1–8. Association for Computational Lin-
guistics.
Horch, E. and Reich, I. (2016). On “article omission” in
german and the “uniform information density hypoth-
esis”. Bochumer Linguistische Arbeitsberichte, page
125.
Jaeger, T. F. (2010). Redundancy and reduction: Speakers
manage syntactic information density. Cognitive psy-
chology, 61(1):23–62.
Jain, A., Singh, V., Ranjan, S., Rajkumar, R., and Agar-
wal, S. (2018). Uniform information density effects
on syntactic choice in hindi. In Proceedings of the
Workshop on Linguistic Complexity and Natural Lan-
guage Processing, pages 38–48.
K
¨
olbl., M., Kyogoku., Y., Philipp., J., Richter., M., Riet-
dorf., C., and Yousef., T. (2020). Keyword extrac-
tion in german: Information-theory vs. deep learn-
ing. In Proceedings of the 12th International Con-
ference on Agents and Artificial Intelligence - Volume
1: NLPinAI,, pages 459–464. INSTICC, SciTePress.
K
¨
olbl, M., Kyogoku, Y., Philipp, J. N., Richter, M., Riet-
dorf, C., and Yousef, T. (2021). The Semantic Level of
Shannon Information: Are Highly Informative Words
Good Keywords? A Study on German, volume 939
of Studies in Computational Intelligence (SCI), pages
139–161. Springer International Publishing.
Levshina, N. (2017). Communicative efficiency and syn-
tactic predictability: A cross-linguistic study based on
the universal dependencies corpora. In Proceedings of
the NoDaLiDa 2017 Workshop on Universal Depen-
dencies, 22 May, Gothenburg Sweden, number 135,
pages 72–78. Link
¨
oping University Electronic Press.
Levy, R. (2008). Expectation-based syntactic comprehen-
sion. Cognition, 106(3):1126–1177.
NLPinAI 2022 - Special Session on Natural Language Processing in Artificial Intelligence
502

Levy, R. and Jaeger, T. F. (2007). Speakers optimize infor-
mation density through syntactic reduction. Advances
in neural information processing systems, 19:849.
Levy, R. P. (2018). Communicative efficiency, uniform in-
formation density, and the rational speech act theory.
In Proceedings of the 40th Annual Meeting of the Cog-
nitive Science Society, page 684–689.
Melamed, I. D. (1997). Measuring semantic entropy. In
Tagging Text with Lexical Semantics: Why, What, and
How?
Resnik, P. (1995). Using information content to evaluate se-
mantic similarity in a taxonomy. arXiv preprint cmp-
lg/9511007.
Richter, M., Kyogoku, Y., and K
¨
olbl, M. (2019). Interaction
of information content and frequency as predictors of
verbs’ lengths. In International Conference on Busi-
ness Information Systems, pages 271–282. Springer.
Richter, M. and Yousef, T. (2019). Predicting default and
non-default aspectual coding: Impact and density of
information feature. In Proceedings of the 3rd Work-
shop on Natural Language for Artificial Intelligence
co-located with the 18th International Conference of
the Italian Association for Artificial Intelligencey.
Richter, M. and Yousef, T. (2020). Information from topic
contexts: the prediction of aspectual coding of verbs
in russian. In Proceedings of the Second Workshop on
Computational Research in Linguistic Typology.
Shannon, C. E. (1948). A mathematical theory of communi-
cation. The Bell system technical journal, 27(3):379–
423.
Shannon, C. E. and Weaver, W. (1949). The Mathemati-
cal Theory of Communication. University of Illinois
Press.
Zipf, G. K. (1949). Human behavior and the principle of
least effort: an introd. to human ecology.
Zipf, G. K. (2013). The psycho-biology of language: An
introduction to dynamic philology. Routledge.
Uniform Density in Linguistic Information Derived from Dependency Structures
503
