
DMISTA: Conceptual Data Model for Interactions in Support Ticket
Administration
Christian Mertens and Andreas Nürnberger
Otto-von-Guericke-University, Universitätsplatz 2, 39106, Magdeburg, Germany
Keywords: IT Service Management, Enterprise Information System, Conceptual Data Model, Data Mining, Data Flow
Architectures, Requirements Engineering, Support Ticket Administration.
Abstract: Changing business models and dynamic markets in the globally connected world results in more and more
complex system environments. The IT service infrastructure as enabler of innovative business models has to
support these innovations by providing agile methods to quickly adapt to new use-cases. This underlines the
need to manage the digitized environment systematically in order to foster efficiency. IT Service Management
(ITSM) as a discipline evolved and now provides the framework to orchestrate the complexity in Information
Technology. The activities, processes, and capabilities to maintain the portfolio are served by individuals,
who interact with each other. There is an emphasized need for identifying, acquiring, organizing, storing,
retrieving, and analyzing data related to human interaction processes to support finally the business processes.
This paper proposes a conceptual data model to capture information about human interactions during support
ticket administration (DMISTA). The presented model-structure and -requirements allow for efficient selec-
tion of appropriate data for various data science use-cases to understand and optimize business processes.
The DMISTA supports different types of relationships (based on causality, joint cases, and joint activities) to
enable efficient processing of specific analysis methods. The applicability of the model is shown based on a
typical use-case.
1 INTRODUCTION
IT operations is nowadays a vital function in the busi-
ness enterprises. Frequent changes in provided ser-
vices are often part of the corporate strategies since
constant re-invention and adaption is crucial to de-
velop a competitive position in the global markets.
The resulting shorter product lifecycles requires to
constantly transform the organizations capabilities.
Moreover, the actual global pandemic accelerated the
transformation in digitalization, which leads to a par-
adigm shift in the products we assemble, the services
we offer, and the way we collaborate. IT Service
Management (ITSM) as a discipline provides the un-
derlying framework to orchestrate (manage) the es-
sential implementations in Information Technology.
This is mainly done by handling the IT operations
through considering standardized procedures and
processes - mapped in digitized process landscapes.
Basically, this field has much priority for research in
optimization since IT operations accounts 70% - 90%
of total cost of IT ownership (Fleming, 2005).
Processes are operated by individuals (the human
actors in the network) who exchange and interact with
each other. These interactions form the glue between
the processes and can be considered as networks of
interactions. One individual interacts with another in-
dividual and thus ensures that requirements are routed
through the organization properly and implemented
accordingly. In ITSM, this communication is mainly
captured by using standardized and documented
statements (support tickets), which are processed
through supporting workflow management systems
(ticket system). The rising complexity of the underly-
ing service structure of most organizations results in
a mass amount of ticket data which is mostly in busi-
ness operations still underutilized. Applying intelli-
gent approaches on the ticket administration activities
has potential to discover valuable knowledge about
the involved individuals and to foster efficiency by
analyzing the interactions between them. Therefore,
as a first step, a conceptual data model has to be de-
veloped to unify the description of the ticket structure
and to enable further analytics use-cases, which aim
on analyzing behavior and characteristics patterns of
112
Mertens, C. and Nürnberger, A.
DMISTA: Conceptual Data Model for Interactions in Support Ticket Administration.
DOI: 10.5220/0010999100003179
In Proceedings of the 24th International Conference on Enterprise Information Systems (ICEIS 2022) - Volume 1, pages 112-119
ISBN: 978-989-758-569-2; ISSN: 2184-4992
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

individuals. Based on this aim, the following research
questions may be asked: What are the requirements
to model interaction-based data?, and subsequently:
How could a conceptional ticket data model for inter-
actions look like?
This paper proposes a conceptual data model to
capture information about human interactions during
support ticket administration (DMISTA). The defini-
tion of interaction relies on the relations between en-
tities in the data model. The DMISTA supports dif-
ferent types of relationships (based on causality, joint
cases, and joint activities) to enable efficient pro-
cessing of specific analysis methods.
In the following section, related work will be
briefly discussed to classify the work into the research
context. Subsequently, a use-case is introduced, mo-
tivating the necessity of the DMISTA. The require-
ments, structure and the model itself is introduced in
Section 4. The paper concludes with a discussion of
security and privacy demands and the outlook for fur-
ther research.
2 RELATED WORK
The related work of data modeling in the relevant area
can be structured in two main parts, respectively: (1)
“What data models have been proposed in the area of
ITSM and for which use-cases?”; and (2) “Aiming on
deriving human interactions, what data modeling con-
cepts have been proposed?”.
Considering the first question, it can be concluded
that much research in ITSM has been carried out to
provide data models for implementing text mining
methods (which aim finally on optimizations in ticket
administration), such as (Asres et al., 2021) (Ferland
et al., 2020) (Molino et al., 2018). A large number of
these approaches rely on features that arise from
ticket summary, description, and resolution text, sup-
plemented partially by additional meta information.
Accordingly, the underlying data models which were
described aim on the tickets itself, not on the interac-
tions between the individuals. Thus, to answer the
second question, we have to consider adjacent areas.
An example for a developed data model, based on
general ticket management is described in the work
from (Shao et al., 2008). The authors proposed an ap-
proach for a ticket routing recommendation engine
(EasyTicket) that mines the steps of ticket transfers
from one group to another. However, this approach
aims on probabilistic workflow mining (instead of hu-
man interactions), which opens corresponding re-
search questions. (Zisiadis et al., 2011) created the
network trouble ticket data model (NTTDM) to pro-
vide the basis for storing as much as possible ticket
data from multiple sources in a grid. The aim is to
simplify the exchange of information between differ-
ent operation centers to enable efficient cooperation.
Since each of the sources operates its own ticket sys-
tem, the definitions of entities and attributes in
NTTDM are generic and maps to the formal defini-
tions in ITSM to achieve a normalization. The out-
come helps to verify the used metrics for our data
model, although it aims on a different use-case.
Best results related to data models that aims on
human interactions around information systems can
be found in the area of process mining (e.g., based on
event logs) and digital communication (e.g., e-mail
exchange considered as communication logs). One of
the first approaches to discover networks of individu-
als in log data was proposed by (Van der Aalst et al.,
2005). The suggested metrics to define relationships
can be used as inspiration to be mapped on ITSM.
Further research in logfile- and communication min-
ing deliver structures for data modeling in (1) organ-
izational development, e.g., (Laclavik et al., 2011),
which describes implicitly the requirements of a data
model for organizational modeling (entities, attrib-
utes, and relationships) in e-mail communication; (2)
social networks, e.g., (Ferreira & Alves, 2012), which
proposes useful relationship metrics, such as “hando-
ver of work” and “working together” as identifier of
relationships between individuals; and (3) sociologi-
cal and psychological areas, e.g., an approach by
(Agarwal et al., 2012) and (Gilbert, 2012) to model
relationship metrics based on hierarchies.
3 MOTIVATION
A conceptual data model must be able to capture the
requirements of different use-cases and should not be
limited to a specific ticket system. Therefore, the con-
ceptual schema represents the core characteristics of
interest, thus can be easily extended to cover the use-
cases (e.g., by adding additional attributes). Further-
more, it should support different types of relation-
ships, which ultimately opens opportunities for re-
search in interdisciplinary sciences such as data min-
ing, business process management, or pedagogics. It
enables the application of analytical data science
methods on - in this case - the representation of inter-
actions. The possible questions extend over the fol-
lowing five areas:
(1) Most of the research in ITSM aims on improv-
ing efficiency in ticket administration procedures. Im-
DMISTA: Conceptual Data Model for Interactions in Support Ticket Administration
113

proved ways of interaction by the individuals in-
volved leads to increased efficiency in processing
tickets.
(2) The interaction between individuals provides
information of organizational development. Aspects
of asked questions in this area can relate to work as-
signments, work organization, skills and capabilities
of individuals, control of the quality and quantity of
the services provided, or the organizational structure.
(3) Communicating Systems are processing infor-
mation and enable exchange between individuals via
interactions. Possible research questions can relate to
the information flow (e.g., unidirectional or bidirec-
tional between individuals) and information pro-
cessing (e.g., acquisition, storage, processing and out-
put of information).
(4) Statistical Analysis of communication and in-
teractions can help to identify dependent effects and
characteristics.
(5) Human interactions are often linked to socio-
logical, psychological, and pedagogical questions,
which aim generally on interrelationships between
acting partners. Possible questions in the area of
ITSM could relate to hierarchies, roles, empathy,
identities, language behavior, or the cooperation be-
tween all parties involved.
The research community around ITSM focusses
mainly on questions which aim on (1) improving
ticket administration efficiency. The degree of ma-
turity of the processing has directly impact on the
quality and continuity, which will be served as value
to the customer. In the following, the activities of han-
dling and processing tickets are also referred as ticket
administration. (Kang et al., 2010) summarized fol-
lowing main issues, concerning ticket administration
in IT operations:
Manual processing steps, i.e., activities such as
gathering required additional information, analyzing
characteristics within the provided data or workload
that is associated with solving a ticket (ticket admin-
istration). These steps might consist of several inter-
actions with the ticket system and are done mainly
manually and individually. This is a labor-intensive
work, therefore error-prone and time-consuming, that
needs to be minimized to meet budget requirements.
Subsequently, tickets are not being processed consist-
ently. The different hierarchies in service manage-
ment are based on a different depth of knowledge. Re-
sult is that the quality of resolution is dependent on
the actors and may be not reproducible.
According to this description, a specific use-case
would be the ticket dispatching step. In an IT service
environment, the precise and timely dispatch of a
ticket to the responsible resolution group is one of the
crucial first step in the whole ticket administration
procedure. The complexity of support structures in
such environments results in challenging routing de-
cisions which have to be made by individuals in the
first level of the support structure. Incorrect dispatch-
ing decisions have impact on resolution times, there-
fore on financials and customer satisfaction.
With the DMISTA, we are able to develop opti-
mization models to identify important individuals to
route tickets directly to the expert. This leads to im-
provements in time-efficiency (optimized ticket rout-
ing) and gives a view on critical team members (iden-
tifying interesting influential members). Furthermore,
the development of recommendation-engines focused
on individuals and relations between them is conceiv-
able. For example, the processing partner in between
of the ticket issuer and resolver could play a crucial
role in the whole support process as an individual
with strong connectedness.
The described use-case highlights the benefits and
necessity of the DMISTA from different angles. Ac-
cordingly, the data model must fulfil functional and
non-functional requirements, which may differ while
applying different use-cases. The functional require-
ments for modeling a database are given by the use-
case, which provides the properties for the implemen-
tation. This is done by the definition and specifica-
tions of the core entities in an information system, re-
quired core attributes, and relationship types.
Non-functional requirements, on the other hand,
indicate how qualitatively efficient the system should
be. The international standard ISO/IEC 25010 (Sys-
tem and software quality models) defines (among oth-
ers) performance efficiency, reliability, and maintain-
ability of such non-functional requirements (Interna-
tional Organization for Standardization, 2011). A
suitable architecture for a target DBMS should be se-
lected that also considers the non-functional require-
ments.
Therefore, the DMISTA (1) must be based on
common standards (ITSM) to be used generically and
independent from a single ticket system; (2) must be
able to store the required core entities to enable ana-
lytics on relations between individuals in the network;
(3) must be able to store the relevant core attributes
as identifier of the entities; (4) must be able to store
and represent the relevant relationships on different
levels to model human interactions; (5) must effi-
ciently support the processing of complex queries be-
tween relationships of different entities.
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
114

4 THE DATA MODEL
4.1 Structure and Requirements
Derived from the use-case presented in Section 3, the
DMISTA should not be limited to a specific service
management system in an organization but contain
specifications as generic as possible without accept-
ing redundancy or losing characteristic. Thus, the
DMISTA contains central core description of entities,
attributes, and relations based on standards in ITSM.
A historical ticket data log is suitable to deliver the
data to fulfil the requirements. Entities are objects
which can be distinctly identified and refers to the
logical representation of data. For data modeling of
interactions of individuals in a network its crucial to
identify strong entities as anchor, for which their ex-
istence does not depend on any other entity. The char-
acteristics of these entities are given by the attributes
which are in context of the entity. The connection be-
tween two or more entities is called relationship. The
key to the successful subsequent analysis of the inter-
actions is the representation of the relationships be-
tween the individuals.
Requirements for data volumes and query times
raise the question of a selection of the appropriate ar-
chitecture for the logical and physical implementa-
tion. Considering the underlying data, different as-
pects need to be discussed to select the required data-
base-model. As mentioned before, the ability to effi-
ciently represent and process complex relationships is
crucial. Relational databases (RDBs) are designed to
managed tables and forms, which can be use-cases to
aggregate highly structured data. Basically, relation-
ships can be mapped in those, however, the amount
of relations required to store highly networked infor-
mation is very high and query processing leads often
to complex sequences of data base operations (e.g.,
for depth search purposes). Relationships in RDB
schemas do not directly reveal the semantics needed
for ITSM analysis. Thus, this implicit information
must be reconstructed in queries by using joins. To
solve this problem a database that was explicitly de-
signed to represent sequences of relationships, a
graph database, could be used (Paul et al., 2019). The
main advantage of employing graph databases is the
explicit support to store and navigate relationships in
a graph (G). Vertices (V) are utilized to store entities,
while edges (E) describe directed, semantically con-
nections between objects, with properties: G = (V,E).
Since the relations are not computed at query time but
stored directly in the database, crossing the joins or
relationships is efficient. Provided that the research in
interactions in support ticket data is an application
that involves a large number of relationships between
the data, the graph databases are suitable in terms of
performance. This has also been concluded in re-
search, such as (Khan et al., 2019) (Rodriguez Reyes,
2021) (Stanescu, 2021) (Vicknair et al., 2010), where
relational databases are compared against graph data-
bases. According to the authors, typical projects for
graph databases are storage and analysis of connec-
tions and relationships, mapping of complex relation-
ships in collaborative systems, optimization of rout-
ing in networks, etc. - in general: connection-, highly
networked-, or route problems. Investigations in in-
teractions in ticket workflow management systems
can be interpreted as an example of data in a collabo-
rative system, where users interact with each other to
achieve a solution for a specific request (described in
a ticket).
4.2 Entities and Attributes
The entities to identify are those who are relevant to
describe interactions in support tickets. The DMISTA
contains the core primary- and associated entities in
the structured and unstructured data of the ticket his-
tory logs. Primary entities describe the strong and as-
sociative entities, which consists of the main objects
to research in and can be identified with Primary Key
relations (see Table 1). Associated entities (weak en-
tities) in this context consists of the artifacts which
are generated while interacting in support tickets and
refer with Foreign Key relations to the primary enti-
ties (see Table 2).
Table 1: Core primary entities in the DMISTA.
Individual
Attribute Description
UserID Unique identification label for
individuals.
E-Mail E-Mail address of an individual.
Name Name of an individual.
Ticket
Attribute Descri
p
tion
ID Unique identification number for
tickets.
CreationTimestamp Date and time of creation of the
s
p
ecific dataset.
ClosureTimestamp Date and time of closure of the
s
p
ecific dataset.
DescriptionText Description of the ticket as free
text.
SolutionText Solution of the ticket as free text.
Major primary entity is the individual (the human
actor) in the ticket network. He is involved in the
ticket administration procedure, therefore of special
DMISTA: Conceptual Data Model for Interactions in Support Ticket Administration
115
interest for studies related to interactions. Usually,
ticket workflow management systems consist of users
(the individuals), who hold specific identifier and at-
tributes (user-ids, clear names, e-mail addresses, etc.)
to enable support ability. Furthermore, a ticket (sec-
ond primary entity) can be identified by a unique id
and consists of creation date, closure date, description
text (short and long description) and solution text.
Additional attributes can be added to both, if re-
quired by the analytical use-case (such as priority
(ticket), status (ticket), type (ticket), company (indi-
vidual), department (individual), or telephone num-
ber (individual)).
Table 2: Core associated entities in the DMISTA.
ActivityLogEntry
Attribute Description
Timestamp Date and time of activity.
IndividualUserID Identification label for individual
which act as author.
TicketID Unique identification number for
referenced ticket.
ActivityDescrip-
tionText
Description of the activity
p
erformed by the individual as free
text.
Topic
Attribute Description
TicketID Unique identification number for
referenced ticket.
TopicName Content of activities categorized to
describe the to
p
ic of the ticket.
Activit
y
Cate
g
or
y
Attribute Description
IndividualUserID Identification label for individual
which act as author.
ActivityCatego-
r
y
Name
Activity summarized in a
cate
g
or
y
.
Associated entities are derived from activities -
while the activity log entries reflect the actual de-
scriptions of the activities, it is possible to derive fur-
ther categorial entities from them, e.g., to describe re-
lationships. An activity log entry contains Foreign
Keys as set of attributes in a child table, since they
refer to tickets and individuals as the primary entities.
4.3 Relations
Key is to define the types of relations between indi-
viduals or group of individuals, which can be derived
from the ticket log data. (Van der Aalst et al., 2005)
proposed different metrics to describe relations in the
area of process mining in log data: (1) Relation metric
based on causality; (2) Relation metric based on joint
cases; (3) Relation metric based on joint activities;
and (4) Relation metric based special event type (de-
rived from the data that the researchers employed,
therefore not applicable in ITSM).
In the following, the first three proposed metrics
will be used as inspiration to develop own description
of metrics, that fit to the ticket administration proce-
dures in ITSM.
4.3.1 Relations based on Causality
Causality is the relation between cause and effect,
based on a sequence of events that are related to each
other. This principle can be found in the ticket lifecy-
cle by defining corresponding associations. A simple
relation, which can be used as a good starting point is
the contribution of different individuals in one spe-
cific ticket. The assumption is, that all actors, who are
involved in resolving that ticket (“handover of
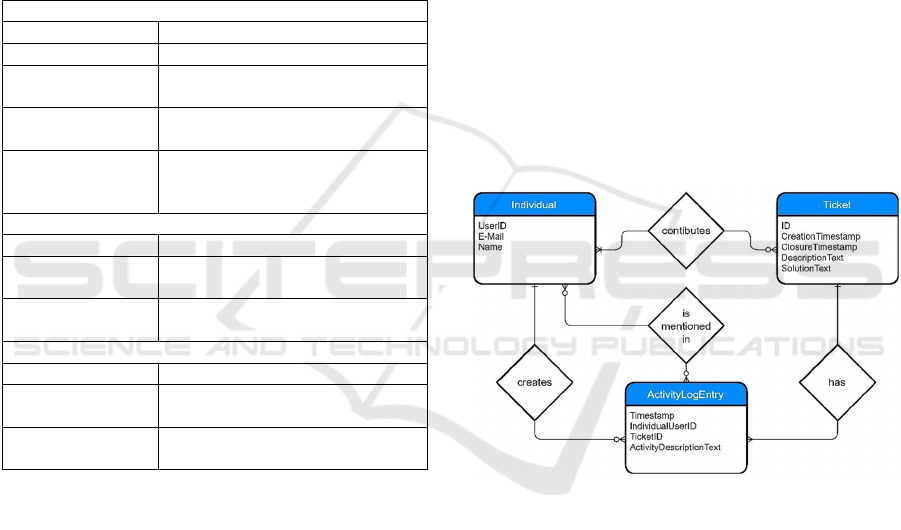
work”), are related to each other (see ERD in Figure
1). This principle can be extended to all involved in-
dividuals, even if they are just mentioned in the activ-
ity description (e.g., e-mail chains as “working to-
gether”-metric).
Figure 1: ERD: Relations based on causality.
The frequency of interaction within a timeframe
between those individuals define the intensity of rela-
tionship and can be used to assess the role of an actor
in the network. Furthermore, the timestamp of the
events in the ticket history can be used to create causal
relations by combining the information of different
tickets. Related questions can be answered, such as:
„How are individuals interconnected?“; „Who is per-
forming best (in resolving tickets)?“; and „Who is
centralizing the communication as focal point („men
in the middle“)?”.
4.3.2 Relations based on Joint Cases
To derive relations based on joint cases, it is neces-
sary to define a case. Related to ticket management, a
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
116
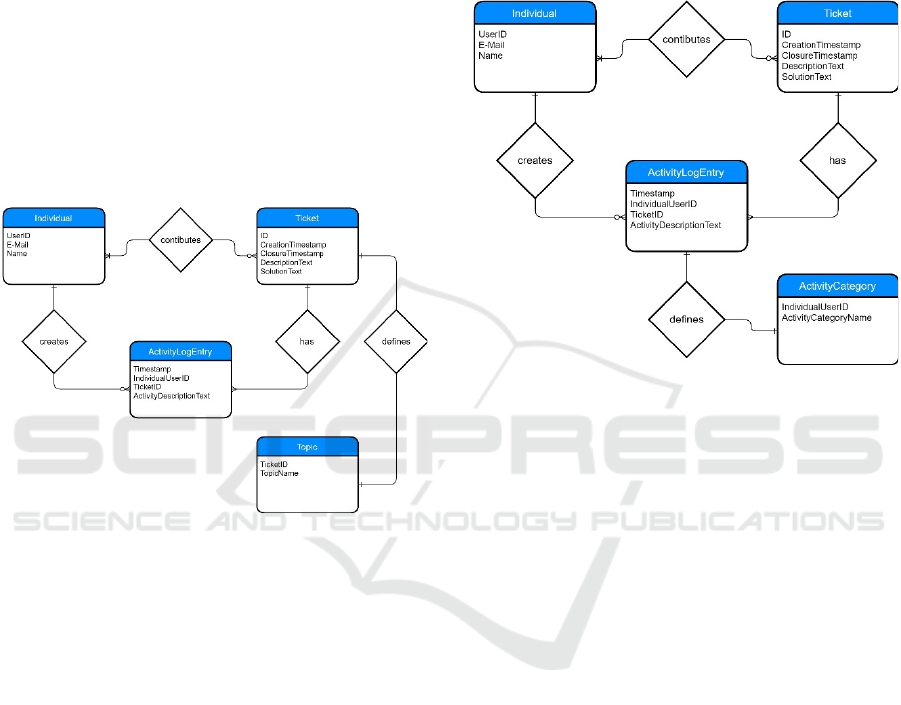
case is a topic that is defined by the ticket itself (what
the ticket is about). Therefore, an approach is to clas-
sify the unstructured data in the ticket description text
to determine its topic or topic category (see ERD in
Figure 2). Thus, it reveals how often an individual
works on one specific case. Once the resulting da-
tasets of different individuals are similar to each
other, it is likely that the individuals are related, since
they are working on joint cases. This can be achieved
even without considering any kind of causal depend-
ency. Text mining methods provide different ap-
proaches to achieve the topic classification or cluster-
ing. The more often two individuals work on the same
case, the stronger the relation. This could be devel-
oped further, e.g., by considering the kind of activities
performed for the specific case.
Figure 2: ERD: Relations based on joint cases.
Identifying the groups of individuals working on
same or similar problems could help, e.g., to address
optimizations in routing challenges by detecting the
right people for the requested domain. Furthermore,
the synergies within the different teams who are
working on same topics can be promoted, once the
collaboration of experts gets fostered (e.g., by provid-
ing a shared knowledge base, creating space to share
experiences, or implementing coordinated proce-
dures). Subsequently, organizational structures can
be improved in accordance with the findings of how
the teams are distributed.
4.3.3 Relations based on Joint Activities
The definition of joint activities relates to individuals,
who are performing similar or same activities (instead
of completely different activities). Once we find indi-
viduals executing activities from the same category
(activity profile), it is possible to create a relationship.
The basic assumption is: The more often two individ-
uals perform same or similar activities, the stronger
the relationship - ignoring the specific topics they are
working on. The correlation between the individuals
can be calculated, e.g., by measuring the distance of
the activity-profiles. Mapped on ticket management,
these profiles can be derived by processing the con-
tent of activity log entries through suitable classifica-
tion or clustering algorithms.
Figure 3: ERD: Relations based on joint activities.
Relations based on joint activities provide the an-
swer to the question of „Who is doing what and which
activity profiles can be created from this insights?“.
Dependent on the results, this enables to identify the
individuals, who are involved in important activities,
such as resolving the tickets. Applied on a specific
part of organization, it helps to foster efficiency (e.g.,
to improve routing decisions), but also to change pro-
cedures if bottlenecks are identified (e.g., increased
amount of unproductive activities). Activity profiles
provide information about the value a specific group
delivers. Combined with further metrics, variations
can be researched to extend the insights.
4.4 Implementation
We developed a prototype which implements the
DMISTA to validate the data models’ ability to store
the required ticket data. Two raw datasets are availa-
ble for research purposes: Ticket corpus 1 sourced
from entertainment-branch (112,452 ticket history
datasets within three years) and ticket corpus 2 from
industrial-branch (15,300 ticket history datasets
within one year). On average, one ticket history da-
taset consists of 6,5 entries. Both originate from dif-
ferent ticket tools and branches, which allows the val-
idation of the effectiveness of the achieved research
results. All datasets were derived from primary
DMISTA: Conceptual Data Model for Interactions in Support Ticket Administration
117

sources and were captured from large-scale corporate
background. The datasets were initially classified into
subsets to investigate in the organizational properties
of a predefined technical area (example group).
In the following, one example group derived from
corpus 2 will be described to illustrate the results.
Based on 4,935 history entries from approximately 3
months, we were able to successfully store 750 ticket
entities and 492 individual entities. Relationships
were derived accordingly. Based on the data model,
we implemented different analytical use-cases. One
of them was to identify central actors in the intercon-
nectedness set of relations which are structurally
strong integrated, using degree centrality (refers best
to a question of category (4): Statistical analysis - see
description in Section 3). Centrality measures are part
of network science and uses mathematical methods to
systematically analyze graph structures. For the group
selected, we were able to identify the group charac-
teristics, especially the set of major contributors (pos-
sible key players). Four individuals show significant
higher numbers of connections to its neighbors, com-
pared to the others. We conducted a separate verifica-
tion-step with domain experts, who validated the re-
sults. They confirmed the central role of those indi-
viduals in the ticket administration procedure. We
were able to identify the service responsible, two
technical engineers with special knowledge, and one
central individual who routes the tickets.
The first results showed that the DMISTA works
according to its requirements and is able to store the
required ticket data. The modeling capabilities were
cross validated based on datasets from two different
areas. The next planned step is to provide a bench-
mark dataset in order to be able to deepen the research
in ticket interactions and to provide traceability.
5 SECURITY AND PRIVACY
CONSIDERATIONS
The paper defines the DMISTA to enable research in
the defined area. The model itself does not raise any
type of security and privacy concerns. However, it is
crucial to consider appropriate data and security care-
fulness while handling the primary sources. These
questions arise from different perspectives, e.g., the
storage of data (access management, encryption,
etc.), the publication of results (public, internal, etc.),
or the usage in applications. Individuals can increas-
ingly collect datasets about communication behavior,
identifier and company-related aspects using com-
mon tools and technologies. The data collected within
the ticket corpus can be both, personal (e.g., the ac-
tivity profiles of individuals) and business sensitive
(e.g., information about system vulnerabilities). This
form of data invokes challenges and value judgments
while applying information sciences, considering the
type of user participation, rights and agency of data
collectors, and what type of information will be pro-
cessed.
To take these aspects into account, the appropriate
measures have to be initiated. Considering publica-
tion purposes for research, the “Guide on Good Data
Protection Practice in Research” (European Univer-
sity Institute, 2019) proposes a series of activities: As
a precondition, a data preprocessing step needs to be
implemented to ensure anonymization. Features that
are suitable to identify directly or indirectly personal
or corporate data will be replaced by parameters using
randomization, generalization and pseudonymization
techniques. This approach is commonly applied in
network analysis research. Depending on the applica-
tion to be developed, it is necessary to consider fur-
ther measures to effectively protect personal privacy
and business sensitive information.
6 CONCLUSIONS
The maintenance of complex system environments in
ITSM includes a huge amount of quantitative and
qualitative aspects, which have to be detected, logi-
cally organized, retrieved, and stored to be finally an-
alyzed in research. The DMISTA contributes to re-
searchers and organizations that collect, manage, an-
alyze, and interpret ticket information in a proper and
consistent way. Studying the interactions in the ticket
data is an open question in research, which have to be
based on relevant and accurate statistical data that
rely on properly designed, frequently updated, and
maintained databases.
The DMISTA (1) aims to enable research in hu-
man interactions use-cases by modeling relationships
on different levels; (2) provides a common format
that allows researcher to store, exchange, manage,
and analyze support tickets; (3) identifies relevant
core entities and attributes; (4) is effective, as it cap-
tures the core characteristics of individual’s activities
during ticket administration procedures. It is also dy-
namic to future demand, as it allows to be enriched by
additional components; (5) can address key questions
from research area in ITSM, including efficiency-, or-
ganizational-, communication-, statistical-, and soci-
ological, psychological, pedagogical-related ques-
tions.
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
118

It is planned to provide a benchmark dataset to be
able to discuss further research results in the commu-
nity. Moreover, our DMISTA opens interesting ques-
tions in ITSM to be analyzed in our future work.
REFERENCES
Agarwal, A., Omuya, A., Harnly, A., & Rambow, O.
(2012). A Comprehensive Gold Standard for the Enron
Organizational Hierarchy. In Proc. of the 50th Annual
Meeting of the Assoc. for Computational Linguistics:
Short Papers Vol. 2 (pp. 161–165). ACL.
Asres, M. W., Mengistu, M. A., Castrogiovanni, P., Bot-
taccioli, L., Macii, E., Patti, E., & Acquaviva, A.
(2021). Supporting Telecommunication Alarm Man-
agement System With Trouble Ticket Prediction. IEEE
Trans. Ind. Inf., 17(2), 1459–1469.
European University Institute (2019, April 1). Guide on
Good Data Protection Practice in Research.
https://www.eui.eu/documents/servicesadmin/deanof-
studies/researchethics/guide-data-protection-re-
search.pdf
Ferland, N., Sun, W., Fan, X., Yu, L., & Yang, J. (2020).
Automatically Resolve Trouble Tickets with Hybrid
NLP. In Symposium Series on Computational Intelli-
gence (SSCI) (pp. 1334–1340). IEEE.
Ferreira, D. R., & Alves, C. (2012). Discovering User
Communities in Large Event Logs. In LNBIP. Business
Process Management Workshops (Vol. 99, pp. 123–
134). Springer.
Fleming, W. (2005, September 18). Using cost of service to
align IT: Presentation at itSMF, Chicago, Illinois,
USA.
Gilbert, E. (2012). Phrases that signal workplace hierarchy.
In Proc. of the Conf. on Computer Supported Coopera-
tive Work (CSCW) (p. 1037). ACM.
International Organization for Standardization. (2011).
ISO/IEC 25010:2011: System and software quality
models. https://www.iso.org/obp/ui/#iso:std:iso-
iec:25010:ed-1:v1:en
Kang, Y.‑B., Zaslavsky, A., Krishnaswamy, S., & Barto-
lini, C. (2010). A knowledge-rich similarity measure
for improving IT incident resolution process. In Proc.
of the Symposium on Applied Computing (SAC)
(p. 1781). ACM.
Khan, W., Ahmad, W., Luo, B., & Ahmed, E. (2019). SQL
Database with physical database tuning technique and
NoSQL graph database comparisons. In 3rd Infor-
mation Technology, Networking, Electronic and Auto-
mation Control Conf. (ITNEC).
Laclavik, M., Dlugolinsky, S., Kvassay, M., & Hluchy, L.
(2011). Email Social Network Extraction and Search.
In Intl. Conf. on Web Intelligence and Intelligent Agent
Technology (pp. 373–376). IEEE/WIC/ACM.
Molino, P., Zheng, H., & Wang, Y.‑C. (2018). COTA. In
Proceedings of the 24th ACM SIGKDD International
Conference on Knowledge Discovery & Data Mining
(pp. 586–595). ACM.
Paul, S., Mitra, A., & Koner, C. (2019). A Review on
Graph Database and its representation. In Intl. Conf. Re-
cent Advances in Energy-efficient Computing and Com-
munication (ICRAECC) (pp. 1–5). IEEE.
Rodriguez Reyes, R. (2021). Comparison between Graph
and Relational Databases based on performance. Serie
Científica De La Universidad De Las Ciencias Infor-
máticas(Vol. 13), 174–195.
Shao, Q., Chen, Y [Yi], Tao, S., Yan, X., & Anerousis, N.
(2008). EasyTicket. Proc. Of the VLDB Endowment,
1(2), 1436–1439.
Stanescu, L. (2021). A Comparison between a Relational
and a Graph Database in the Context of a Recommen-
dation System. In Position and Communication Papers
of the 16th Conf. on Computer Science and Intelligence
Systems (pp. 133–139). PTI.
Van der Aalst, W. M. P., Reijers, H. A., & Song, M.
(2005). Discovering Social Networks from Event Logs.
Computer Supported Cooperative Work (CSCW),
14(6), 549–593.
Vicknair, C., Macias, M., Zhao, Z., Nan, X., Chen, Y
[Yixin], & Wilkins, D. (2010). A comparison of a graph
database and a relational database. In Proc. of the 48th
Annual Southeast Regional Conference. ACM.
Zisiadis, D., Kopsidas, S., Tsavli, M., & Cessieux, G.
(2011). The Network Trouble Ticket Data Model
(NTTDM). RFC (No. 6137).
DMISTA: Conceptual Data Model for Interactions in Support Ticket Administration
119
