
Semantic Code Clone Detection Method for Distributed Enterprise
Systems
Jan Svacina
a
, Vincent Bushong
b
, Dipta Das
c
and Tomas Cerny
d
Computer Science, Baylor University, One Bear Pl, Waco, TX, U.S.A.
Keywords:
Source Code Analysis, Code Clone Detection, Semantic Clone, Enterprise Applications, Code Smells.
Abstract:
Conventional approaches to code clone detection consider systems from elementary construct perspectives,
making it difficult to detect semantic clones. This paper argues that semantic clone detection could be im-
proved for enterprise systems since they typically use well-established architectures and standards. Semantic
clone detection is crucial for enterprises where software’s codebase grows and evolves and maintenance costs
rise significantly. While researchers have proposed many code clone detection techniques, there is a lack of
solutions targeted explicitly toward enterprise systems and even fewer solutions dedicated to semantic clones.
Semantic clones exhibit the same behavior between clone pairs but differ in the syntactic structure. This pa-
per proposes a novel approach to detect semantic clones for enterprise frameworks. The driving idea is to
transform a particular enterprise application into a control-flow graph representation. Next, various propri-
etary similarity functions are applied to compare targeted enterprise metadata for each pair of the control-flow
graph fragment. As a result, we achieve to detect semantic clones with high accuracy and reasonable time
complexity.
1 INTRODUCTION
Enterprise applications support many vital systems in
our modern society (Fowler, 2002). As the addressed
tasks grow in complexity, so too must the applica-
tions themselves. An array of enterprise frameworks
provide a degree of standardization and stability to
the development of these large applications (Oracle,
2020; He and Xu, 2014; Jin, 2014), but due to evolv-
ing requirements, changing technologies, and a con-
stant backlog of legacy code, increases in complex-
ity are inevitable. Complexity in software applica-
tions is ultimately felt in increased maintenance costs
(Banker et al., 1993). Maintenance costs demand be-
tween 20% and 25% of corporations’ total costs and
fees, so the need for reducing complexity is clearly
seen as companies fight to keep costs down (Krigs-
man, 2015; Doig, 2015).
Code clones are one source of complexity in soft-
ware, which comprise between 10% to 23% of large
codebases (Kapser and Godfrey, 2003; Roy et al.,
a
https://orcid.org/0000-0002-6958-6455
b
https://orcid.org/0000-0003-0475-4232
c
https://orcid.org/0000-0001-8366-2453
d
https://orcid.org/0000-0002-5882-5502
2009). Code clones are duplicated or redundant snip-
pets of code and they add complexity to the sys-
tem. Code clones make updates to the codebase more
time-consuming since the changes have to be made
in multiple places. The effect is multiplied if there
are bugs in the cloned code. The possibility of in-
complete bug fixes increases, and developers need to
scour potentially thousands or hundreds of thousands
of code lines for the duplicate usages (Saini et al.,
2018). When code clones are embedded in legacy
systems, the problem further compounds; training de-
velopers on large legacy codebases is expensive and
time-consuming, and it drains resources away from
new development. Furthermore, attempting to fix
code clone-filled legacy systems by assigning more
developers comes with its own problems. Suppose
the clones are not systematically identified and cata-
loged. In that case, new developers may waste hours
discovering and rediscovering the same bugs and poor
coding practices, resulting in no extra progress be-
ing made. Reducing code duplication in a codebase
would save extra maintenance costs and prevent un-
needed refactorings.
Developers can keep codebases more manageable
with better practices enforced with the help of code
clone detection (Saini et al., 2018). Of the varieties of
Svacina, J., Bushong, V., Das, D. and Cerny, T.
Semantic Code Clone Detection Method for Distributed Enterprise Systems.
DOI: 10.5220/0011032200003200
In Proceedings of the 12th International Conference on Cloud Computing and Services Science (CLOSER 2022), pages 27-37
ISBN: 978-989-758-570-8; ISSN: 2184-5042
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
27

code clones, semantic code clones are of the most in-
terest in large enterprise systems, since enterprise de-
velopers often employ superficially similar code snip-
pets that are quite different in their effects and end
results; for example, the process of fetching, pro-
cessing, and storing data in different places appears
structurally similar each time it is used, but seman-
tically, it is different in different contexts. On the
flip side, it is possible that different developers (or
the same developer at different times) created seman-
tically similar code in different places with different
structural elements. These two facts lead us to con-
clude that semantic code clones are far more interest-
ing and impactful to enterprise applications. There-
fore, since code clones cause complexity and raise
costs for enterprise applications, we pose that seman-
tic code clone detection can provide meaningful re-
sults to the fields of development, quality assurance,
and maintenance with respect to the software engi-
neering of large enterprise applications.
In previous work (Svacina et al., 2020), we pro-
posed a method to represent enterprise systems as
a set of Control-Flow Graphs (CFG) where nodes
are represented by method statements and edges by
calls between methods. In this work, we increase the
number of properties to CFGs to further improve the
detection of potential code clones. With introduce
weights of individual components in CFG, to reflect
their semantic meaning in the system. For instance:
what responsibilities the method has (database per-
sistence, communication with the user, etc.), data at-
tributed to the method (the input and output of the
method), and the enterprise-specific implications of
the method (security, entry-point, etc.). These en-
hanced CFGs are compared one with another by a
global similarity function. Our similarity function
runs in O(n) and comparing each CFG pair results in
O(n
2
) combinations. This method keeps both the time
complexity and the number of CFGs n low. Accord-
ing to the results from our similarity function, we can
categorize the code clones. This paper brings detailed
results from a case study on an extensive third-party
and heavily distributed enterprise application bench-
mark. We present results from the testing in Section
4.2, where we further elaborate on the false-positive
ratio and other statistical values. Further, we con-
ducted stress tests to establish the time efficiency of
our approach, and we share results in Section 4.2.
This paper advances knowledge in the field of
semantic code clone detection in enterprise applica-
tions. Such advancement is needed to better cope with
enterprise software architectural degradation (Baabad
et al., 2020) and enable providers to reduce mainte-
nance costs or address several desired metrics. In Sec-
tion 2, this paper outlines the state of the art. The
other approaches to code clone detection focus on
general code clone detection methodologies and then
narrowing to the focus of semantic code clones. Sec-
tion 3 outlines our proposed detection method, fol-
lowed by Section 4 – a case study on an enterprise
application. Lastly, we summarize our experiment re-
sults and highlight important notes and concepts ob-
tained through our research.
2 RELATED WORK
In this section, we discuss previous work in categoriz-
ing and detecting code clones. In particular, we con-
sider the code clone background and detection; next,
we consider program representation.
2.1 Code Clone Background and
Detection
Similar or identical code blocks are called code clones
and are usually copied from some source (Saini et al.,
2018)(Walker et al., 2020). As a result, they are code
fragments that bear similarities in structure or func-
tion. Specifically, there are 4 code clone types or
classes(Saini et al., 2018; Roy and Cordy, 2007; Bel-
lon et al., 2007; Koschke et al., 2012):
• Type 1 - exact clones
• Type 2 - parameterized clones
• Type 3 - near-miss clones
• Type 4 - semantic code clones
Type 1 is self-descriptive: a block of code is a type
1 clone if an exact copy of the source code can be
found elsewhere. Type 2 clones are similar to type
1, with the caveat that variables or function calls may
have different names. Type 3 clones are copied frag-
ments that have had some statements injected or re-
moved while retaining a similar structure. The fo-
cus for this paper, type 4 clones, or semantic clones,
are those which have the same behavior but different
structure or method of approach (Saini et al., 2018).
Type 4 clones are unique because while types 1-3 de-
pend solely on the code structure, type 4 clones de-
pend on the actual results. This is an important dis-
tinction, particularly between type 3 and 4 clones; de-
pending on which statements were modified, type 3
clones can appear quite similar but achieve different
results, while type 4 clones can superficially look dif-
ferent while serving the same purpose (Fowler, 2002).
Much research has been contributed to code clone
detection, from type 1 to type 4 alike. The research
CLOSER 2022 - 12th International Conference on Cloud Computing and Services Science
28

of tools focused on enterprise systems is underrep-
resented, and their need is well justified. One tool
named DSCCD (Dynamic and Static Code Clone De-
tector) (Nasirloo and Azimzadeh, 2018) can detect
semantic code clones - the most challenging of the
four types to detect - at a rate of accuracy of 66%.
The tool was developed to weigh the benefits of run
time versus the reduction of false positives. How-
ever, a thorough analysis of a codebase for seman-
tic code clone detection is naturally a computation-
time consuming task. The case study done over
DSCCD had 12 semantic code clones written into it,
and in order to get their 66% overall accuracy rat-
ing, it took over 426 seconds in one study (Nasir-
loo and Azimzadeh, 2018). They utilized both dy-
namic and static analysis via Program Dependency
Graphs (PDGs) and Abstract Memory States (AMS).
The PDGs provide a higher level flow analysis for
the semantic clone detection, and the AMS provides a
quick, lower-level analysis (Nasirloo and Azimzadeh,
2018). While using AMS helped lessen the run time
and lowered false-positive rates, AMS methods can-
not handle scopes beyond single methods. This flaw
renders them much less useful for enterprise applica-
tions, where the flow of method calls is more impor-
tant for determining duplicate behavior due to sepa-
ration of concerns making some methods extremely
short.
For example, consider the following; let there be
some method A that performs an action a. Create
some new method B such that B calls A and returns
the action a. It is trivial to see that B does the same
exact thing as A. However, if the flows of these two
methods are not analyzed and compared, they will not
be tagged as semantic clones though it is clearly ev-
ident that they are. Semantic clone detection should
be agnostic of lines of code.
One approach that was able to resolve many of
these concerns was made with deep learning imple-
mentation. Research by White et al. (White et al.,
2016) led to the development of a deep learning al-
gorithm capable of analyzing massive codebases with
extremely low false-positive rates. White et al. man-
aged to get 93% true positives, taking only around 3
seconds using a model trained off of Abstract Syn-
tax Trees (ASTs) and 35 seconds using a proprietary
greedy algorithm. White et al. discovered dozens of
types 1 through 3 clones in multiple systems and a
small number (5) of type 4 clones. Their approach
could analyze systems with exceptionally large code-
bases (such as Hibernate or Java JDK); the caveat is
that running on a new system requires training the
model on that system. The training takes an equally
exceptional amount of time. Their example of using
Java JDK, with over 500,000 lines of code (not unrea-
sonable for large enterprise applications), took 2,977
seconds to train via the less accurate AST method
and 14,965 seconds via their greedy learning method.
Considering that enterprise applications are explicitly
based on business logic that may change and the con-
stant evolution of such systems, any given enterprise
application will have to be constantly re-fed into the
model for re-training to provide an accurate model for
what code clones may look like, requiring a high time
investment.
White et al. are not the first to attempt code clone
detection via machine learning approaches. Yu et al.
proposed a similar method by running two simultane-
ous neural networks over each pair of code snippets
and categorized them into one of the types of clones
(Yu et al., 2019). The approach provided by Yu et
al. is powerful, with accuracy above 96%. However,
a similar pitfall of complexity and training time ren-
ders the approach unsuitable for enterprise solutions.
Their algorithm required several hours for training, so
their utility as an enterprise application code clone-
detection tool is severely limited.
Other attempts at machine learning-based analy-
sis, such as that by Sheneamer et al. (Sheneamer and
Kalita, 2016), which uses 15 machine learning algo-
rithms, and Buch et al. (Buch and Andrzejak, 2019)
are competitive in accuracy and performance at run
time. However, they are system-specific in that they
similarly need to be trained for each code base and do
not consider the meta-information provided by enter-
prise structures and patterns.
The tool CCFinder by Kamiya et al. is an exam-
ple of code clone detection that has been implemented
and can discover types 1 through 3 code clones effi-
ciently and effectively (Kamiya et al., 2001). Kamiya
et al. focus heavily on maintainability and can help
users determine if a code clone is safe to remove or re-
duce with impact to the system (Kamiya et al., 2001).
However, they acknowledge inter-method flows are
challenging to capture, and they focus exclusively on
source code analysis. Thus this tool is not beneficial
for large and complex enterprise systems that are de-
pendent on inter-flow communication. So, even tools
that are fantastic for types 1 through 3 code clones
may not provide useful analysis for enterprise appli-
cations.
There are dozens of proposed code clone detec-
tion methods (Walker et al., 2020), many even spe-
cializing in semantic types. However, for the moment,
these methods are strictly theoretical and academic,
with no way to easily reproduce shared results, as the
implementations and benchmarks have not been made
available. Other tools such as Agec, by Kamiya et al.
Semantic Code Clone Detection Method for Distributed Enterprise Systems
29

(Kamiya, 2013) and the algorithm by Tekchandani et
al. (Tekchandani et al., 2018) provide code clone de-
tection solutions for type 4 specifically, but also fall
short in these same ways.
2.2 Program Representation
When gathering semantic code clones of an enter-
prise system, a method of representing the program
is needed. One option is to use Control-Flow Graphs
(CFGs), a type of call graph where the nodes rep-
resent the system’s methods and the edges are calls
to other methods. We prefer this method of pro-
gram representation over other methods (token-based
(Basit and Jarzabek, 2007), Abstract Syntax Tree
(AST)(Baxter et al., 1998), Abstract State Memory
(ASM)(Agapitos et al., 2011), Program Dependency
Graph (PDG)(Higo and Kusumoto, 2009), etc.) since
it can capture more meta-information regarding the
context of the code clones or methods with regards to
enterprise architecture (i.e., component types of as-
sessed code).
Awareness of system meta-information in the
analysis process could open new perspectives to code
clone detection in the enterprise systems. This could
utilize GRASP patterns (Larman, 2003) and base on
the application layer they are at (Fowler, 2002). This
information that is only accessible in a higher-level
abstraction such as a CFG could allow our program
to eventually be filtered to only analyze service mod-
ules or controller modules, helping developers decide
whether their service/controller/etc. Classes could
be further split or merged to improve cohesion and
reduce unnecessary coupling. Performance would
greatly improve if users could filter code clone de-
tection by concern. Besides, the code clone detection
would be more meaningful knowing where in the ap-
plication they are found and in which context. This
could be accomplished through augmented CFGs
with the additional meta-information used when de-
veloping enterprise applications (i.e., component type
annotation, indicating a service, controller or en-
tity). For instance, annotations in Java code, provided
by the common and widely used Spring Framework
(VMware, 2020), or similar means in other enterprise
frameworks.
Our related work found AST and token-based ap-
proaches are popular program representation methods
for finding code clones, both semantic and syntactic,
so our choice to use CFGs is explicit and oriented par-
ticularly toward enterprise applications. We pose that
the benefit to a CFG (a type of control-flow graph)
over an AST is that AST provides too low-level of a
depiction of the program and can consume too much
memory to analyze. This is especially true since we
are not interested in clone detection that requires such
low-level, syntactic knowledge.
Code clone detection is a widely studied field, but
it lacks in its depth concerning enterprise applica-
tions. It is not the case that business domain-related
code clones have never been researched. However,
many glances into this field left many questions unan-
swered and only emphasized the need for such a tool
than provided one (Koschke et al., 2012).
3 PROPOSED METHOD
The proposed method to detect semantic code clones
focuses primarily on the semantic meaning of a CFG
rather than on the structure itself. The CFGs are used
to represent the enterprise system. Semantic proper-
ties (hereby referred to only as properties) are derived
from the metadata associated with each method in the
form of configuration files or annotations. We exam-
ine each graph’s properties by applying a global sim-
ilarity function, as shown in the Definition 1. Proper-
ties of the CFG bring higher value to identifying code
clones because programs in enterprise systems tend
to be repetitive in their structure but differ in mean-
ing of the data in the input and output of the program
(Fowler, 2002). In other words, not every structural
repetition of code is a code clone, but a semantic rep-
etition is very likely to be a code clone. Our approach
consists of four stages, graph transformation, graph
quantification, similarity comparison, and classifica-
tion, as shown in Figure 1.
Definition 1 - Global similarity.
G(A,B) =
k
∑
i=1
w
i
× sim
i
(a
i
,b
i
)/
k
∑
i=1
w
i
Where k is the number of attributes, w
i
is the weight
of importance of an attribute i, AND sim
i
(a
i
,b
i
) is a
local similarity function taking attributes i of cases A
and B.
In the first transformation phase, we transform
Java source code into a CFG. We used Java Reflection
and Javassist (JBoss, 2020) libraries to scan the code
for all declared methods; then, we get each method
call within its body for each declared method. We
used the depth-first search to construct a graph for
each method that does not have a parent method call.
Such a method is an entry-point to the enterprise ap-
plication. Starting with these entry points, we expand
the CFGs to include all the methods that get called,
eventually covering all components of the system. For
CLOSER 2022 - 12th International Conference on Cloud Computing and Services Science
30

Classified
Clones
Graph
Transformation
Source
Code
Graph
Quantification
CFGs
Similarity
function
Property
CFGs
Classification
CFG pairs with
similarity
Figure 1: Schema of the algorithm.
illustration consider an example of a system, where
an endpoint method create in the PosController that
calls savePos method in the service PosService. Next,
PosService makes two procedure calls, first to some
third-party API, and the second to PosRepository.
The schema of this code is depicted in the Listing 1,
and the resulting CFG is in Figure 2.
1 @C o n tro l ler
2 public class P osC o n tr o l ler {
3 @A u t ow i r ed
4 private P osS e rvi c e ser v ic e ;
5
6 @Re q u est M a ppi n g ( v al ue = " / pos " ,
7 me tho d = Req u e st M e tho d . P OS T )
8 public Po s cr ea te ( @Re q ues t B od y Pos p ) {
9 return s er v ic e . save ( p );
10 }
11 }
12
13 @S e rv i ce
14 public class P os S erv i ce {
15 @A u t ow i r ed
16 private P o sRe p o sit o ry rep o sit o ry ;
17
18 public Po s sa ve P os ( Pos pos ){
19 Pr op s p = re stT e mpl a t e
20 . p o s tO b j ec t ("/ p ro ps " );
21 pos . s e tP r op s (p );
22 return r epo s ito r y . sa ve ( pos );
23 }
24 }
25
26 @R e p osi t ory
27 public interface P osR e p os i t ory {
28 Pos sa ve ( Po s pos );
29 }
Listing 1: Source code example. Note Pos is a domain ob-
ject representing a point-of-sale system.
In the next phase, we need to associate each CFG
with a set of properties as shown in Figure 2. First,
we identify the method types of each method in-
volved in the CFG. We present the method type cat-
egories in Table 1. We can base our identification
on analyzing standard enterprise annotations. Meth-
ods are associated with annotations that depict the
type. For instance, annotations @Controller and
@RestController defines controller method type in
Spring Boot projects. Annotation @Repository sig-
nifies repository type. Next, we can associate a set
of properties P with each method. The properties
set is different for each method type with some over-
lapping properties. For instance, we associate each
method type with a method name, return type, and
arguments. The metadata depicts a method’s role in
the system (database connector, entrypoint, etc.). For
service
controller
service.save()
exit
restTemplate.call()
repository.save()
repository
save()
Op: create
Http: POST
Argument: Pos
Return: Pos
Figure 2: Example of control-flow graph.
instance, controller methods have properties HTTP
method that signifies HTTP messages that the method
handles. Thus, our utilization of CFGs provides ad-
ditional meaning that determines individual compo-
nent’s roles in the system.
Table 1: Classification of properties.
Method Similarity Weight Properties
Type Name
Controller ctr 0.4 arguments,
return type,
HTTP
method,
method name
Message
calls
rfc 0.4 HTTP type,
arguments
return entity,
method name
Repository rp 0.2 arguments,
return type,
database
operation,
method name
Next, we assign a similarity score between 0 and 1
to each pair of CFGs, using the global similarity func-
tion G as given in Definition 1. The function depends
on each method time, multiplying each result by the
weight coefficient found in Table 1; this weight rep-
resents that method type’s relative importance. Con-
Semantic Code Clone Detection Method for Distributed Enterprise Systems
31

troller and Message call methods are weighted highly
at 0.4, since they respectively define the API of the
program’s entry points and the locations where exter-
nal interactions are made, both of which highly im-
pact a system’s behavior. Repository-type methods
persist data to stable storage, and while not insignifi-
cant, their properties are often subsumed into the cor-
responding Controller methods, so they are weighted
lower at 0.2.
The usage of the similarity functions for each
method type is shown in Definition 2. All three func-
tions consider common elements such as the method
name, arguments, and return type, but each is differ-
entiated by specific considerations for each method
type.
Definition 2.
sim(a
i
,b
i
) = ctr(a
i
,b
i
) + rfc(a
i
,b
i
) + rp(a
i
,b
i
)
The ctr function targets Controller methods,
which represent endpoints that accept input to the ser-
vice. REST-based endpoints are often differentiated
in purpose by the HTTP method type (GET, POST,
PUT, DELETE), so HTTP type is considered here. Ad-
ditionally, any Role-Based Access Control measures
are most often applied at the endpoint level. There-
fore, we examine any required roles to gain access to
the endpoint (such as user or admin) when consider-
ing similarity of controllers.
Remote function calls are governed by the rfc
function. To compare these function calls, rfc specif-
ically considers any IP addresses and ports involved,
as well as the HTTP type and type and number of ar-
guments of the call and the expected return type from
the call.
When comparing two function calls, similarity
function rfc takes into account IP address, port, HTTP
type, argument types, and return type. Lastly, the
similarity function rp compares methods working
with databases by evaluating database operations, as
shown in Table 1.
Once the similarity scores are calculated, the last
step is to classify the CFG pairs. Different ranges of
the similarity value correspond to three different cat-
egorizations: identical clones or clones that differ in
one property, clones that differ in multiple properties,
and non-clones. The exact ranges are given in Table 2.
Table 2: Classification of code clones and non-clones.
Classification Global Characteristics
Type Similarity
A 1.0 - 0.91 Same or differs in
one property
B 0.9 - 0.81 Differs in multiple
properties in one
method type
Non-clone 0.8 - 0.0 Not considered a
clone
4 CASE STUDY
We conducted the following analysis to prove that
the global and local similarity model with control-
flow graphs’ properties works sufficiently in finding
semantic code clones in real microservice systems.
4.1 The Benchmark
To avoid any bias, for our case study, we used a
public, third-party, medium-size microservice bench-
mark system developed by Zhou et al. (Zhou et al.,
2018b). The benchmark uses microservice architec-
ture and Spring Boot (VMware, 2020) with a set of
API methods using standard procedures of multilay-
ered applications such as controllers, services, repos-
itories. The benchmark depicted in Figure 3 is com-
posed of 37 microservices, and it provides compre-
hensive functionality for ticket train purchase (Zhou
et al., 2018b). The authors created the application to
analyze log outputs from the running application to
detect faults (Zhou et al., 2019; Zhou et al., 2018;
Zhou et al., 2018a). We analyzed the application in a
study to detect semantic code clones across the appli-
cation. In the next part, we will discuss an example of
a semantic code clone and our study’s overall results.
4.2 The Study
We present an example of derived properties from
two CFGs. Both the CFG
A
and CFG
B
are derived
from the benchmark as shown in Figure 4. Both of
the CFGs have the same input (String orderId), but
differs in output (objects FoodOrder and Order), use
the same HTTP method GET and fetch the object type
with the same database operation READ and same pa-
rameter order Id.
Properties of both graphs CFG
A
and CFG
B
from
the Table 4 were evaluated by local similarity func-
tions detailed in Table 3. Similarity function r f c give
a full match result, whereas the similarity function ctr
CLOSER 2022 - 12th International Conference on Cloud Computing and Services Science
32

Advanced travel
(route info & tickets)
Traffic management
Gateway
Service
discovery
(Kubernetes)
Service
registry
Load
balancing
Monitoring & metri cs
Travel admi n
(order, route, station)
Ticket
rebook
High-speed
ticket reserve
Ticket
reserve
News
Ticket
office
Route plan
(price, change, time)
Ticket
execute
Pay
High-speed
travel explore
Travel
expl ore
Security
Cancel
order
Inside
pay
Consign
Route Seat Voucher
High-speed
order
Ticket info
Order
Consign
price
Assurance
User
Basic
info
Notify
Food
service
Food
map
Config Station Train Contact Price
Verify
code
Authorization
Figure 3: Benchmark microservice overview (Zhou et al., 2018b).
Table 3: Similarity function results of benchmark system.
Method Type Abbr. Similarity Weight Weighed SIM
Controller ctr 0.66 0.4 0.264
Message calls rfc 1 0.4 0.4
Repository rp 0.5 0.2 0.1
total 2.16 0.764
Controller
Argument: String orderId
HTTP method: GET
Return Type: Order
Repository
Database operation: READ
Argument: String OrderId
Return Type: Order
Controller
Argument: String orderId
HTTP method: GET
Return Type: FoodOrder
Repository
Database operation: READ
Argument: String OrderId
Return Type: FoodOrder
CFG A
CFG B
Figure 4: Example of properties of 2 CFGs (Note: in this
particular case there are no REST methods).
and rp shows a lower match value due to the different
return type.
Table 3 shows total similarity 2.16 and weighted
similarity 0.764, or 76.4%. On our scale defined in
the previous section and highlighted in Table 2 this
value does not fall under the Type A or Type B cate-
gory. Thus, this is not an example of a code clone. We
weighed all of the similarities in order to reflect their
importance in the system. For example, controllers
are critical since they define what data is accepted and
produced. Methods working databases and services
that make REST calls also have high significance as
these operations are specific to the enterprise system’s
business rules.
We derived all 238 CFGs from the TrainTicket ap-
plication, which comes out to 27221 combinations in
total. After applying similarity functions on each pair,
there are 56 CFGs making 28 pairs that we classi-
fied as code clones. They fell into respective cate-
gories as shown in Table 5, which shows that 2 pairs
of CFGs were strongly similar and 26 were fairly sim-
ilar. Strongly similar accounts for 0.84% of all CFGs.
We verified our approach by manual review of the
TrainTicket application by multiple reviewers. We
divided reviewers into two groups. The first group
verified results produced by our method, and the sec-
ond group gathered manually results from TrainTicket
without knowing results from our approach. The
Semantic Code Clone Detection Method for Distributed Enterprise Systems
33
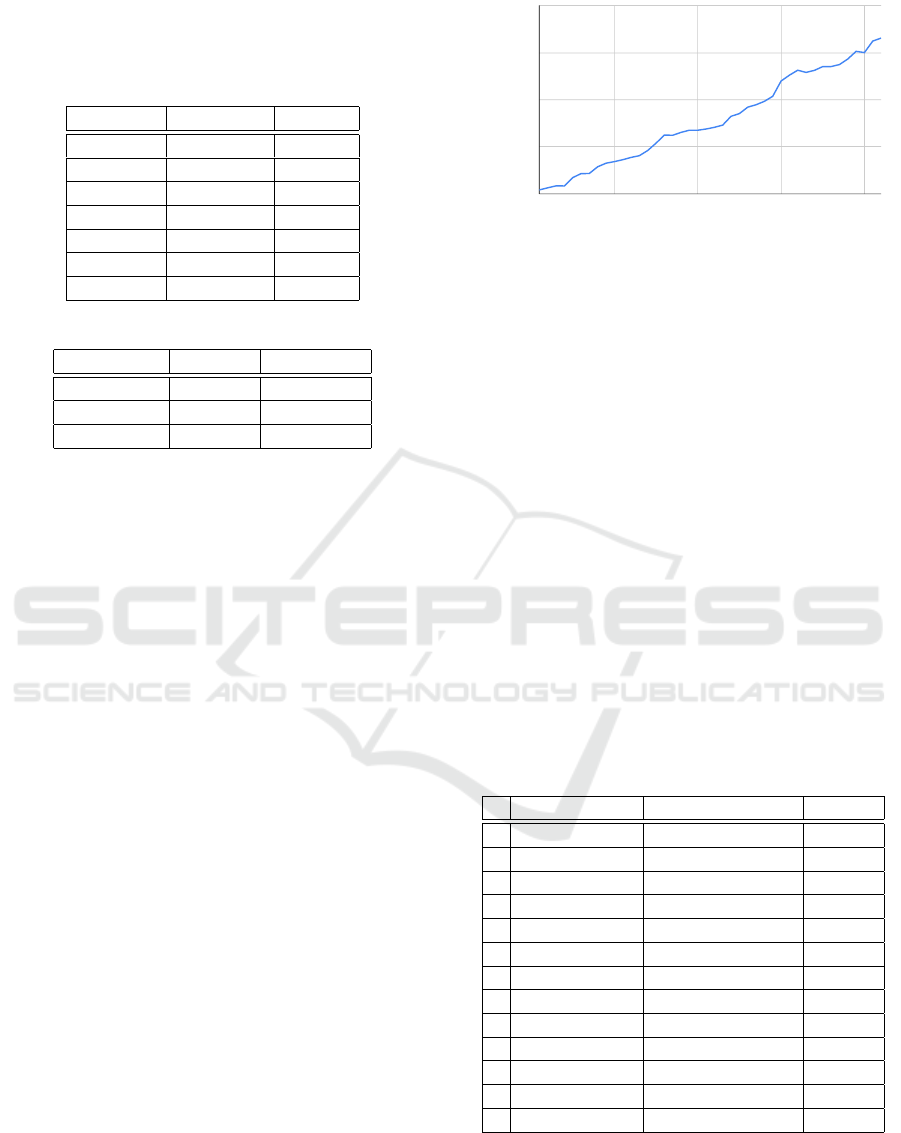
Table 4: First column depicts statistical values of true-
positive (TP), false-positive (FP), true-negative (TN) and
false-negative (FN). Second column shows values for au-
tomatic approach, manual approach is depicted in the third
column.
Automatic Manual
TP 28 24
FP 10 0
TN 27183 27193
FN 0 4
Accuracy 0.999 0.999
Precision 0.736 1
Recall 1 0.85
Table 5: CFG clones percentage.
Clone Type Total Nr Percentage
Type A 2 0.84 %
Type B 26 10.92 %
No Clone 202 88.24 %
first group distinguished our method’s true and false
positives, while the second group established missed
code clones by our method. Results from Table 4
shows that our method found all code clones present
in TrainTicket, while wrongly categorizing 10 code
samples as clones. Manual review missed 4 code
clones in the codebase. This shows that our method
has a tendency to include false positives where more
than one in three is not a code clone, but it ultimately
includes all code clones in the application.
We also calculated statistical values of accuracy,
precision, and recall. Accuracy is a measure of cor-
rectly classified cases among all cases. Both manual
and automatic approaches have almost perfect accu-
racy due to a high number of combinations. More
telling is precision and recall values. Precision shows
the ratio between relevant and retrieved instances,
and our method has a competitive precision value of
0.736. On the other hand, recall models the ability
to identify only relevant code clones, and here our
method proved to be more competitive than the man-
ual approach.
This is in part caused by having a high sensitiv-
ity or weight based on input and output types. Types
of arguments and return values are important because
the same constructs intended for other data types will
tend to have the exact same behavior; for example, a
repository method to save a question to the questions
table will semantically behave the same as a reposi-
tory method to save a test to the tests table, and both
are necessary and cannot be removed from the appli-
cation due to semantic similarity alone. This sensi-
tivity with the weights avoids including structurally
identical but semantically different CFGs as semantic
Number of microservices
Time in milliseconds
0
2500
5000
7500
10000
10 20 30 40
Figure 5: Time analysis of the approach with respect to
number of microservices.
clones in our results.
We also look at the distribution of code clones in
microservices. We associated the Type-A and Type-B
clones with a particular microservice. Next, we cal-
culated the proportions shared with other microser-
vices. Table 6 shows microservices with type A and
B clones. There are 13 microservice pairs that share
some CFGs as column Nr. depicts. This column is
only for reference purposes. The second and third
columns show a pair of microservices that are simi-
lar to each other. The first row of the Table 6 shows
that ts-contacts-service shares 37.5% of CFGs with
admin-basic-info-service. Microservice pairs on row
6, 7, and 8 share substantial functionality. Pairs in
rows 8 - 13 shows microservices that share CFGs one
with the other, creating a cluster of the same function-
ality. Pairs in rows 2 - 5 show how one microservice
can be similar to multiple other microservices.
Table 6: CFG Type A and B clones per module distribution
in the benchmark from Figure 3.
Nr MS A MS B Sim
1 ts-contacts admin-basic-info 37.5 %
2 ts-config ts-train 16.6 %
3 ts-config admin-basic-info 16.6 %
4 ts-config ts-travel2 33.3 %
5 ts-config ts-travel 33.3 %
6 ts-order-other ts-order 87.5 %
7 ts-preserve preserve-other 50.0 %
8 ts-security ts-train 50.0 %
9 ts-security ts-seat 16.6 %
10 ts-train ts-seat 16.6 %
11 ts-train ts-travel2 16.6 %
12 ts-train ts-travel 16.6 %
13 ts-travel2 ts-travel 66.6 %
We also tested our approach for the time efficiency
of our solution in terms of code analysis. We ran
our solution on an increasingly higher number of mi-
croservices, starting from one and up to forty-two. It
CLOSER 2022 - 12th International Conference on Cloud Computing and Services Science
34

enabled us to observe the time efficiency of our sys-
tem on small, medium, and large-sized systems and
potentially establish a trend for even larger projects.
We used microservices from the TrainTicket project
for our experiment. We run our analysis on each num-
ber of microservices 10 times to avoid any software or
hardware deviations. We used a system running oper-
ating system Ubuntu 20.10 LTS with Intel processor
11th Gen Intel
®
Core
™
i7-1165G7 @ 2.80GHz × 8,
32 GB RAM and 500 GB SSD. The results from the
experiment are plotted in Figure 5. One microservice
needed 208 milliseconds to analyze, while forty-two
8200 ms, which is approximately 200 ms per one ad-
ditional microservice.
The case study with results can be found on GitHub at
https://github.com/iresbaylor/semantic-code-clones.
4.3 Result Discussion
Our main goal was to verify that control-flow graphs
with properties are a good match for semantic code
clone identification, which we identified manually.
We compared manual and automatic approaches and
showed that our method tends to include false pos-
itives but can detect all code clones from the code-
base, where a manual approach fell short. We were
able to ensure the time complexity of O(n
2
), where n
is the number of CFGs. This is due to deriving only
CFGs from the whole code base and then comparing
them with each other. We derived only 238 instances
from the code base of thousands of lines of code. This
reduction enabled the algorithm to process each mi-
croservice in roughly 200 ms. We were also able to
cluster code clones related to microservices and show
overlaps of functionality in percentage ratio.
4.4 Threats to Validity
The main validity threat is the way how we set the
thresholds in our method and how extensible our
method is for other frameworks. We also elaborate on
our custom thresholds used in the proposed method.
4.4.1 Internal Threats
Our proposed method uses several constants for the
detection. We set weights for local similarity func-
tions that correspond to real importance in enterprise
systems. However, we did not execute the experi-
ment under various settings in an attempt to produce
an optimal solution. Semantic-type clones require a
low threshold in order to detect. Therefore we set the
classification classes to be within the first third of our
scale. We observed that found clones had a very dis-
tinctive nature; Type A clones were exact clones only,
Type B clones delegated the task on another service.
These distinctive characteristics ensure that we detect
these occurrences only. We utilized our knowledge of
enterprise systems and code clones to set these con-
stants.
Our proposed method solely focuses on seman-
tic code clones for three different types of methods
that are associated with enterprise application layers.
However, there can be other utility or helper meth-
ods within the application. Detecting code clones for
those methods are more straightforward and exten-
sively studied in previous research works.
Our solution relies on standard practices for en-
terprise application development. Thus non-standard
practices can influence the accuracy of our method.
For example, it is possible to perform a delete oper-
ation on the database through a GET API call, where
standard practice is to use a DELETE API call. If two
methods with different HTTP types perform the same
operation, their similarity will be low and require a
high threshold value to detect as a code clone. Simi-
larly, two different methods with the same name, pa-
rameters, and HTTP type can perform entirely differ-
ent operations. Their similarity value will be high and
will cause false-positive detection. However, this in-
dicates a poor coding practice and will require a low
threshold value to be ignored from detection.
4.4.2 External Threats
We conducted the tests on a real-world application.
We picked the application from this publication (Zhou
et al., 2018c). Our proposed method utilizes enter-
prise standards, and thus it can be facilitated on any
project that uses the same standards. We focused
on Java and utilized Java Parser for static analysis,
and our case study demonstrates that we can success-
fully analyze such a Java-based system following en-
terprise standards. Microservices can also be written
in other languages, and if the language has a parser,
the properties can be derived and later integrated with
our interfaces. Since the benchmark system does fol-
low enterprise standards, structurally similar systems
in other languages can indeed be analyzed with our
method if such parsers are available.
5 CONCLUSION
Our semantic code clone detection method targets en-
terprise applications, a massive industry, yet an area
that has been sparsely studied. Our method CFG-
based method captures broader information about
the system regarding its architecture, which provides
Semantic Code Clone Detection Method for Distributed Enterprise Systems
35

wider means to analyze more criteria and calculate
more metrics at a more efficient rate than if we were
to use a storage-intensive method such as ASTs or to-
kens.
The goal of finding code clones in any codebase
is not a trivial one; finding semantic code clones
via some form of graph traversal is an NP-Complete
problem. Therefore, our ability to produce reasonable
results efficiently with the complexity of O(n
2
) is im-
pressive when considering that our method of CFG
generation produces only tens of operations n. Our
method of building CFGs is also efficient, needing to
scan the codebase only once using a depth-first search
to check all methods and build out their children list.
Another benefit to our approach is the extensibil-
ity. When it comes to enterprise applications, exten-
sibility is a marketable property. The success of mi-
croservice architectures stands behind the principle of
extensibility. Thus, it would not be too much of an
investment at both a micro and macro level to trans-
form this tool into a microservice that other microser-
vices could utilize (Walker and Cerny, 2020). The
macro-extensibility can become a module in some
other suite and is not the only type of extensibility
present. More micro-extensibility exists since, to ex-
pand on this tool, developers need only to add new
local similarity functions to capture new metrics or
other kinds of enterprise framework properties. So,
the inner workings of our tool itself are similarly ex-
tensible. A tool like ours could be an essential boon to
quality assurance teams for software-providing com-
panies worldwide.
For future work, new metrics or other program-
ming language support could be added. For example,
there could be a measurement for the system’s pro-
cedural entropy by running checks on each git com-
mit and calculating the degradation and code clone
accumulation over time. In the future, we could im-
plement the means to measuring greater distances be-
tween CFGs using the meta-information and enter-
prise design patterns to analyze whether a controller
class is behaving too much like a service class or etc.,
the possibilities for introducing new metrics are end-
less thanks to our method of developing an enterprise
application code clone detection tool using enterprise
architecture methodologies.
ACKNOWLEDGEMENTS
This material is based upon work supported by
the National Science Foundation under Grant No.
1854049 and a grant from Red Hat Research.
REFERENCES
Agapitos, A., O’Neill, M., and Brabazon, A. (2011). State-
ful program representations for evolving technical
trading rules. pages 199–200.
Baabad, A., Zulzalil, H. B., Hassan, S., and Baharom, S. B.
(2020). Software architecture degradation in open
source software: A systematic literature review. IEEE
Access, 8:173681–173709.
Banker, R., Datar, S., Kemerer, C., and Zweig, D. (1993).
Software complexity and maintenance costs.
Basit, H. A. and Jarzabek, S. (2007). Efficient Token Based
Clone Detection with Flexible Tokenization. In Pro-
ceedings of the the 6th Joint Meeting of the European
Software Engineering Conference and the ACM SIG-
SOFT Symposium on The Foundations of Software En-
gineering, ESEC-FSE ’07, pages 513–516, New York,
NY, USA. ACM. event-place: Dubrovnik, Croatia.
Baxter, I. D., Yahin, A., Moura, L., Sant’Anna, M., and
Bier, L. (1998). Clone detection using abstract syntax
trees. In Proceedings. International Conference on
Software Maintenance (Cat. No. 98CB36272), pages
368–377.
Bellon, S., Koschke, R., Antoniol, G., Krinke, J., and
Merlo, E. (2007). Comparison and Evaluation of
Clone Detection Tools. IEEE Transactions on Soft-
ware Engineering, 33(9):577–591.
Buch, L. and Andrzejak, A. (2019). Learning-Based Re-
cursive Aggregation of Abstract Syntax Trees for
Code Clone Detection. In 2019 IEEE 26th Inter-
national Conference on Software Analysis, Evolution
and Reengineering (SANER), pages 95–104.
Doig, C. (2015). Calculating the total cost of ownership for
enterprise software.
Fowler, M. (2002). Patterns of Enterprise Application Ar-
chitecture. Addison-Wesley Longman Publishing Co.,
Inc., USA.
He, W. and Xu, L. D. (2014). Integration of Distributed En-
terprise Applications: A Survey. IEEE Transactions
on Industrial Informatics, 10(1):35–42.
Higo, Y. and Kusumoto, S. (2009). Enhancing Quality
of Code Clone Detection with Program Dependency
Graph. In 2009 16th Working Conference on Reverse
Engineering, pages 315–316.
JBoss (2020). Javassist : Java bytecode engineering toolkit.
https://www.javassist.org. Accessed 14 August 2020.
Jin, A. (2014). DCOM Technical Overview.
Kamiya, T. (2013). Agec: An execution-semantic clone
detection tool. In 2013 21st International Conference
on Program Comprehension (ICPC), pages 227–229.
Kamiya, T., Kusumoto, S., and Inoue, K. (2001). A Token
based Code Clone Detection Technique and Its Eval-
uation.
Kapser, C. and Godfrey, M. (2003). Toward a Taxonomy of
Clones in Source Code: A Case Study.
Koschke, R., Baxter, I., Conradt, M., and Cordy, J. (2012).
Software Clone Management Towards Industrial Ap-
plication (Dagstuhl Seminar 12071). Dagstuhl Re-
ports, 2(2):21–57.
CLOSER 2022 - 12th International Conference on Cloud Computing and Services Science
36

Krigsman, M. (2015). Danger zone: Enterprise mainte-
nance and support.
Larman, C. (2003). Agile and Iterative Development: A
Manager’s Guide. Pearson Education.
Nasirloo, H. and Azimzadeh, F. (2018). Semantic code
clone detection using abstract memory states and pro-
gram dependency graphs. In 2018 4th International
Conference on Web Research (ICWR), pages 19–27.
Oracle (2020). Java Platform, Enterprise Edition (Java EE)
| Oracle Technology Network | Oracle.
Roy, C., Cordy, J., and Koschke, R. (2009). Comparison
and evaluation of code clone detection techniques and
tools: A qualitative approach. Science of Computer
Programming, 74(7):470–495.
Roy, C. K. and Cordy, J. R. (2007). A Survey on Software
Clone Detection Research. School of Computing TR
2007-541, Queen’s University, 115.
Saini, N., Singh, S., and Suman (2018). Code Clones:
Detection and Management. Procedia Computer Sci-
ence, 132:718–727.
Sheneamer, A. and Kalita, J. (2016). Semantic Clone De-
tection Using Machine Learning. In 2016 15th IEEE
International Conference on Machine Learning and
Applications (ICMLA), pages 1024–1028.
Svacina, J., Simmons, J., and Cern
´
y, T. (2020). Seman-
tic code clone detection for enterprise applications. In
Hung, C., Cern
´
y, T., Shin, D., and Bechini, A., editors,
SAC ’20: The 35th ACM/SIGAPP Symposium on Ap-
plied Computing, online event, [Brno, Czech Repub-
lic], March 30 - April 3, 2020, pages 129–131. ACM.
Tekchandani, R., Bhatia, R., and Singh, M. (2018). Seman-
tic code clone detection for Internet of Things applica-
tions using reaching definition and liveness analysis.
The Journal of Supercomputing, 74(9):4199–4226.
VMware, I. (2020). Spring Projects.
Walker, A. and Cerny, T. (2020). On cloud computing
infrastructure for existing code-clone detection algo-
rithmss. ACM SIGAPP Applied Computing Review,
20(1):in print.
Walker, A., Cerny, T., and Song, E. (2020). Open-source
tools and benchmarks for code-clone detection: past,
present, and future trends. ACM SIGAPP Applied
Computing Review, 19(4):28–39.
White, M., Tufano, M., Vendome, C., and Poshyvanyk, D.
(2016). Deep learning code fragments for code clone
detection. In Proceedings of the 31st IEEE/ACM In-
ternational Conference on Automated Software Engi-
neering - ASE 2016, pages 87–98, Singapore, Singa-
pore. ACM Press.
Yu, H., Lam, W., Chen, L., Li, G., Xie, T., and Wang, Q.
(2019). Neural Detection of Semantic Code Clones
Via Tree-Based Convolution. In 2019 IEEE/ACM 27th
International Conference on Program Comprehension
(ICPC), pages 70–80.
Zhou, X., Peng, X., Xie, T., Sun, J., Ji, C., Li, W., and Ding,
D. (2018). Fault analysis and debugging of microser-
vice systems: Industrial survey, benchmark system,
and empirical study. IEEE Transactions on Software
Engineering, pages 1–1.
Zhou, X., Peng, X., Xie, T., Sun, J., Ji, C., Liu, D., Xi-
ang, Q., and He, C. (2019). Latent error prediction
and fault localization for microservice applications by
learning from system trace logs. In Dumas, M., Pfahl,
D., Apel, S., and Russo, A., editors, Proceedings of
the ACM Joint Meeting on European Software Engi-
neering Conference and Symposium on the Founda-
tions of Software Engineering, ESEC/SIGSOFT FSE
2019, Tallinn, Estonia, August 26-30, 2019, pages
683–694. ACM.
Zhou, X., Peng, X., Xie, T., Sun, J., Li, W., Ji, C., and Ding,
D. (2018a). Delta debugging microservice systems. In
Huchard, M., K
¨
astner, C., and Fraser, G., editors, Pro-
ceedings of the 33rd ACM/IEEE International Confer-
ence on Automated Software Engineering, ASE 2018,
Montpellier, France, September 3-7, 2018, pages 802–
807. ACM.
Zhou, X., Peng, X., Xie, T., Sun, J., Xu, C., Ji, C., and
Zhao, W. (2018b). Benchmarking microservice sys-
tems for software engineering research. In Chaudron,
M., Crnkovic, I., Chechik, M., and Harman, M., edi-
tors, Proceedings of the 40th International Conference
on Software Engineering: Companion Proceeedings,
ICSE 2018, Gothenburg, Sweden, May 27 - June 03,
2018, pages 323–324. ACM.
Zhou, X., Peng, X., Xie, T., Sun, J., Xu, C., Ji, C., and
Zhao, W. (2018c). Benchmarking microservice sys-
tems for software engineering research. In Proceed-
ings of the 40th International Conference on Software
Engineering: Companion Proceeedings, ICSE ’18,
page 323–324, New York, NY, USA. Association for
Computing Machinery.
Semantic Code Clone Detection Method for Distributed Enterprise Systems
37
