
Using Node Embeddings to Generate Recommendations for Semantic
Model Creation
Alexander Paulus, Andreas Burgdorf, Alina Stephan, Andr
´
e Pomp and Tobias Meisen
Chair of Technologies and Management of Digital Transformation,
University of Wuppertal, Wuppertal, Germany
Keywords:
Enterprise Data Management, Knowledge Graphs, Semantic Modeling, Recommender Systems.
Abstract:
With the ongoing digitalization and the resulting growth in digital heterogeneous data, it is becoming increas-
ingly important for enterprises to manage and control this data. An approach that has established itself over the
past years for managing heterogeneous data is the creation and use of knowledge graphs. However, creating
a knowledge graph requires the generation of a semantic mapping in the form of a semantic model between
datasets and a corresponding ontology. Even though the creation of semantic models can be partially auto-
mated nowadays, manual adjustments to the created models are often required, as otherwise no reliable results
can be achieved in many real-world use cases. In order to support the user in the refinement of those automat-
ically created models, we propose a content-based recommender system that, based on the present semantic
model, automatically suggests concepts that reasonably complement or complete the present semantic model.
The system utilizes node embeddings to extract semantic concepts from a set of existing semantic models and
utilize these in the recommendation. We evaluate accuracy and usability of our approach by performing syn-
thetic modeling steps upon selected datasets. Our results show that our recommendations are able to identify
additional concepts to improve auto-generated semantic models.
1 INTRODUCTION
For many years, digital transformation has been
changing a wide variety of business segments in en-
terprises, such as the fabrication of goods, the admin-
istration of organizational processes or even the com-
munication with customers. One outstanding tech-
nology that is considered to have great potential for
process optimization and the development of new
business models is artificial intelligence, respectively
data-driven machine learning. Today’s AI-based sys-
tems rely on large amounts of data in order to pro-
vide meaningful and concise support. An approach
for managing these heterogeneous data in a meaning-
ful and efficient way is the use of knowledge graphs.
Integrating data into a knowledge graph requires a
mapping between the attributes of a dataset and an
ontology that defines the entities of the knowledge
graph. While the generation of mappings in the form
of semantic labeling already enables a basic specifi-
cation of the data, the construction of a more detailed
mapping, known as semantic model, enables a sup-
plementary description of the data, thus easing the
process of finding, understanding and utilizing data
(Vu et al., 2019; Futia et al., 2020; Knoblock et al.,
2012; Paulus et al., 2021). Thereby, a semantic model
extends the basic mapping by defining relations be-
tween mapped attributes, increasing the level of infor-
mation associated with the dataset. However, creating
a semantic model is often challenging as automated
approaches can only cover parts of the process and
mostly yield basic models. Hence, human interaction
is often needed in a process called Semantic Refine-
ment which corrects and expands the model according
to the modelers needs.
In this paper, we focus on the task of providing
part of a support system that proposes suitable rec-
ommendations for missing concepts or relations dur-
ing the semantic refinement. For this purpose, we de-
sign a recommendation engine that serves as the core
of this support system and considers implicit informa-
tion expressed in historically (human-)created seman-
tic models. On the basis of these, a prediction is made
which additional concepts should be added to the cur-
rent state of the semantic model. Providing suitable
choices via a recommendation engine supports non-
expert users by suggesting potentially unknown con-
cepts to extend the model and expert users by pro-
Paulus, A., Burgdorf, A., Stephan, A., Pomp, A. and Meisen, T.
Using Node Embeddings to Generate Recommendations for Semantic Model Creation.
DOI: 10.5220/0011034900003179
In Proceedings of the 24th International Conference on Enter prise Information Systems (ICEIS 2022) - Volume 1, pages 699-708
ISBN: 978-989-758-569-2; ISSN: 2184-4992
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
699

id
hum
temp1
temp2
67edaccf42
56
32.4
75.0
64ab4eedf3
55
32.2
75.2
20ab37f54d
56
31.3
75.3
89a04feff3
57
33.8
78.9
:weather_station
:temperature
:fahrenheit:celsius
:relative_humidity
:hasUnit
:hasUnit
:measures
:measures
:sensor
:has
:identifier
:identifiedBy
:temperature
:sensor
:sensor
:has
:has
:measures
Added to the model by automated approach
Missing in automated approach
Figure 1: Resulting semantic model for a given dataset.
Element omitted by automated approaches are denoted as
dashed.
viding suitable contexts faster. In order to generate
recommendations, we use node embeddings to build
a recommendation engine to recommend nodes that
have a high proximity to the current semantic model
to the modeler. We show that this approach reduces
the effort and time required to manually create se-
mantic models. To evaluate our approach, we per-
form synthetic modeling steps on different semantic
models and estimate how many usable predictions the
recommendation engine produces in this process (re-
call). Based on the results, we evaluate the number
of recommended concepts that were added as context
information.
In the further course of the paper, we formulate
the problem in Section 2 and discuss previous related
work in Section 3. Afterwards, we explain our recom-
mendation system for supporting users during model-
ing in Section 4. The evaluation of the performance
of the approach is given in Section 5. We conclude
and give an outlook in Section 6.
2 PROBLEM STATEMENT
Figure 1 shows an example of a semantic model,
which was created on the basis of the exemplified
ontology illustrated in Figure 2. Mapping the con-
cepts :identifier, :relative humidity and :temperature
to the data attributes id, hum, temp1, and temp2, re-
spectively, creates an initial linkage between the on-
tology and the dataset. Afterwards, additional con-
cepts and relations from the ontology should be used
to describe the dataset, represented by its columns or
labels, in more detail. Such provided meta informa-
tion allows a semantic model to provide context in-
:weather_station
:temperature
:celsius:fahrenheit:relative_humidity
:hasUnit
:hasUnit:measures
:measures
:sensor
:has
:identifier
:identifiedBy
:location
:locatedAt
Figure 2: Example ontology to describe a set of sensors in
a weather station.
formation of further specification on the relations be-
tween single labels. Following the given example, the
specification of the unit of measurement :fahrenheit
in the semantic model for the concept :temperature
provides an essential added value that facilitates an
unambiguous and correct description of the data. Ad-
ditionally specifying data contained in a single col-
umn, like :date and :time, or :latitude and :longitude
further improves the model’s quality. Without those
information, understanding and processing the data
can be challenging as implicit meta information, like
units of measurement or reference systems, are left
unspecified. This will lead to inconsistencies when
automatically merging datasets or integrating them
into a knowledge graph. Context information in the
semantic model can also be used to provide supple-
mental information, i.e., data that is not present in the
original dataset. In our example ontology this could
be the manufacturer of the sensors, the operator of
the weather station or its location (assuming a fixed
installation). While not explicitly needed, such infor-
mation is valuable to people working with the data,
like analysts or developers. We denote nodes in a se-
mantic model that provide this additional information
as context nodes.
In recent years, the focus of research has been
on reducing the effort required to generate seman-
tic models (cf. Section 3). However, there are no
approaches that are able to create accurate semantic
models, especially when the structure of the dataset
or the target semantic model is complex (Futia et al.,
2020). In addition, existing automated approaches are
mostly limited to generate minimal semantic models
by computing a minimal spanning tree for mapped at-
tributes. (cf. Figure 1, solid relations). Context nodes
such as :fahrenheit, that are present in the ontology
shown in Figure 2, would not be added by such exist-
ing automated semantic modeling approaches.
It is therefore often required that a human user
supervises the creation of semantic models and ap-
plies modification afterwards (Futia et al., 2020). This
step, known as Semantic Refinement, describes user-
validated modifications such as corrections as well
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
700

as extensions of the semantic model (Paulus. et al.,
2021). While ontologies (like our example ontology
or (Rijgersberg et al., 2013)) only provide choices for
units of measurements, a modeler that is familiar with
the corresponding dataset can with certainty decide
which unit is fitting.
While semantic refinement does mitigate the
shortcomings of automatic modeling approaches, new
challenges arise once manual action is involved. First,
the modeler may not know which information is
meaningful and needs to be added to the semantic
model. Second, the user may not know what pos-
sibilities exist in the underlying ontology to model
the desired facts. Especially the second problem con-
sumes much time when browsing potentially large on-
tologies for matching concepts and relations. There
is also the possibility that certain facts may be mod-
eled in different ways by different users. While au-
tomatic algorithms operate consistently, each human
modeler tends to act and model differently. All of
the above contribute to less consistent models that are
more complex to process and understand.
3 RELATED WORK
Mapping heterogeneous datasets to conceptualiza-
tions is a research direction that has, so far, played
an important role especially in the areas of Ontology-
based Data Management (OBDM) and knowledge
graph construction.Semantic typing cf. (Pham et al.,
2016), (Abdelmageed and Schindler, 2020)) usually
describes the process of mapping labels (e.g., ta-
ble headers or leafs in a semi-structured hierarchi-
cal dataset) to an ontology. Here, different auto-
mated approaches exist that follow either a schema-
driven (e.g., (Papapanagiotou et al., 2006), (Pinkel
et al., 2017)) or a data-driven strategy (e.g., (Pham
et al., 2016), (R
¨
ummele et al., 2018), or (Pomp et al.,
2020)).
Besides that, the creation of semantic models (also
called semantic relation inference (Futia et al., 2020))
is also an important sub-field of semantic mapping.
Apart from a direct mapping of the data attributes to
concepts of the ontology, semantic models also in-
clude a specification of additional concepts as well
as the relations that hold between the identified con-
cepts. Approaches presented by (Taheriyan et al.,
2016) and (U
˜
na et al., 2018) have shown significant
improvements in the area of semantic modeling dur-
ing the last years. However, even the most recent ap-
proaches like (Vu et al., 2019) and (Futia et al., 2020)
still lack full coverage, especially for complex model-
ing problems. In addition, the named approaches still
only aim to connect the concepts created by semantic
labeling using a minimal spanning tree (cf. Section 2.
In order to overcome the shortcomings of auto-
mated approaches, it is important to rely on the in-
tegration of humans in a subsequent refinement pro-
cess (cf. (Taheriyan et al., 2016), (Futia et al., 2020)).
However, there are only few approaches that feature
tools to inspect and modify a semantic model after the
automated generation. Notable examples are Karma
(Knoblock et al., 2012) and PLASMA (Paulus. et al.,
2021). However, although following the human in the
loop approach to finalize and refine models, all sys-
tems do not actively support the user during the mod-
ification phase.
Supporting the human user in the refinement pro-
cess requires to derive additional implicitly modelled
information from existing semantic models, which is
often regarded as a problem of entity prediction or
link prediction, i.e., derivation of facts that are not yet
part of a model but could potentially increase its use-
fulness. (Baumgartner et al., 2021) proposed an en-
tity prediction method based on textual descriptions.
In (Futia et al., 2020), historic data is used to im-
prove models but the problem of target node selection
is solved in a brute force manner unsuited for most
scenarios, especially interactive environments due to
time constraints. Also, the resulting model is still
minimal as it is computed via a Steiner Tree, disre-
garding context nodes.
While there has been an extensive usage of seman-
tic information to build recommender systems for dif-
ferent domains (cf. (Codina and Ceccaroni, 2010),
(Almonte et al., 2021)), using recommender systems
to iteratively build semantic models is, to the best of
our knowledge, a new approach. Existing approaches
in this direction are suggestion generators for seman-
tic labeling which let the user make a one-time deci-
sion which candidate to chose from a set of potential
matches (cf. (Papapanagiotou et al., 2006), (Paulus
et al., 2018)) or full ontologies and knowledge graphs
(Saeedi et al., 2020).
4 MODEL EXTENSION
RECOMMENDATION
While there are several approaches that improve the
generation of initial (and minimal) models, the in-
troduction of human modelers generates a need for
different types of systems, namely those that im-
prove the human modeling process. Recommenda-
tions help users to find suitable items of interest, as of-
ten observed in search engines or online warehouses.
For example, recommender systems for online ware-
Using Node Embeddings to Generate Recommendations for Semantic Model Creation
701

DateTime
RecordId
RoadSurface
Temperature
Air
Temperature
StationName
geo_type*
StationLocation
11/09/2020 07:30:00 PM
1055363
41.56
43.72
AlbroPlaceAirportWay
POINT
(-122.314114 47.547426)
11/09/2020 07:28:00 PM
3045392
45.83
45.83
35thAveSW_SWMyrtleSt
POINT
(-122.37658 47.53918)
11/09/2020 07:26:00 PM
4190802
41.19
41.19
RooseveltWay_NE80thSt
POINT
(-122.31765 47.692098)
11/09/2020 07:31:00 PM
1055364
41.56
43.72
AlbroPlaceAirportWay
POINT
(-122.314114 47.547426)
:sensor_station
:fahrenheit
:fahrenheit
:measuredIn
:measuredIn
:measures
:identifiedBy
:measurement
:locatedAt
:measuredAt
:location
:temperature_sensor
:has
:has
Added to the model by automated approach Missing in automated approach
:name
:air_
temperature
:datetime :identifer
:surface_
temperature
:latitude
:longitude
:has :has
:measuredAt
:consistsOf
:time
:date
:consistsOf
:consistsOf
:geoposition
:consistsOf
:wgs84
:definedBy
:definedBy
:definedBy
:geo_type
:has
:measures
* generated / splitted column
Figure 3: Semantic model for a dataset from the VC-SLAM corpus. Element omitted by automated approaches are denoted
as dashed. ’geo type’ is a generated column which has been split from ’StationLocation’.
houses use information observed in previous shop-
ping histories to generate advertising emails.
Recommendations for semantic concepts use a
similar approach to generate suitable suggestions for
the modeling user by exploiting previously observed
models of different users. The engine’s objective is
to recommend concepts that are not added by fully-
automated approaches but provide significant addi-
tional information to the model or selected parts of
it. Figure 3 gives an example of a larger semantic
model built for one of 100 datasets from the evalua-
tion corpus (cf. Section 5.1). The models in this cor-
pus was built using human modelers and does provide
semantic models that are not limited to the minimal
spanning tree but contain additional nodes to provide
context. In the figure, solid lines indicate the mini-
mal model, which has been generated automatically
by a Steiner tree algorithm. The remaining items of
interest are those denoted with dashed lines. We refer
to the dashed nodes as target concepts as those are the
model extensions our recommender should predict, as
they are not covered by existing approaches.
Following the recommender system approach for
products and items, our engine generates specific rec-
ommendations based on observed concept combina-
tions. For example, imagine we have a set of con-
cepts that comprise a semantic model to which the
user adds the concept :temperature. If the concept
:temperature has been observed in combination (not
necessarily directly related) with the concept :fahren-
heit in a majority and with :celsius in a minority of
historic models, we expect the system to recommend
adding :fahrenheit to the model and provide :celsius
as an alternative.
We suggest a multi-step algorithm to identify and
select target concepts. Figure 4 gives an overview of
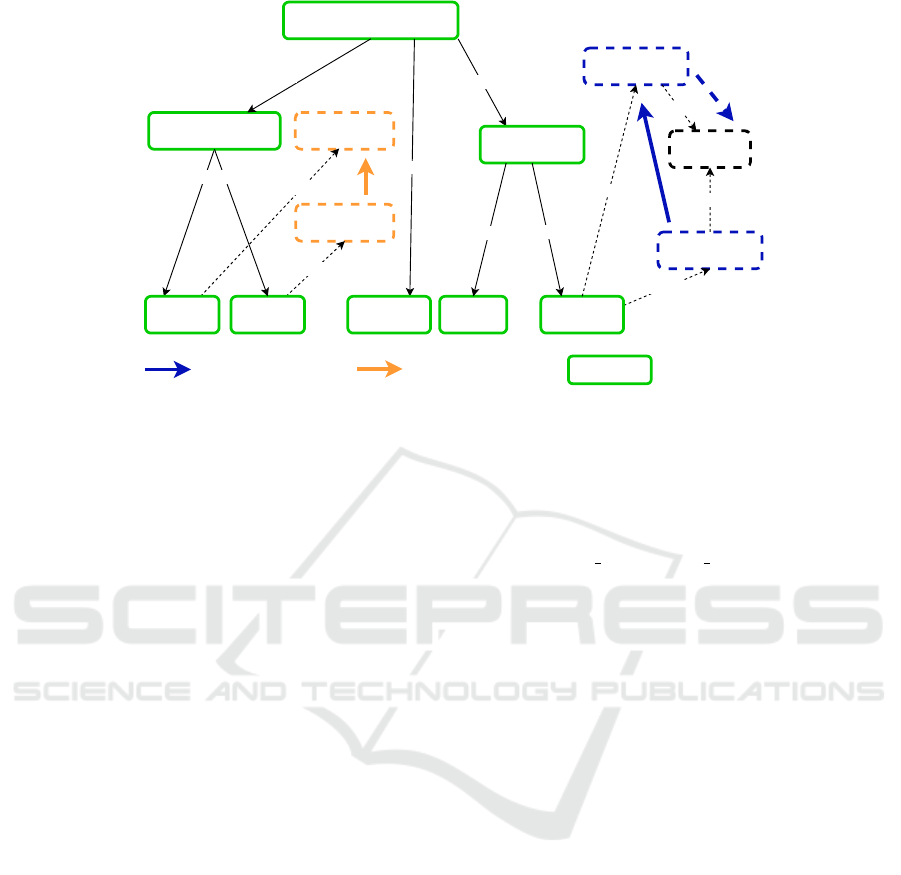
the recommendation process. Step 0 comprises the
preparation and training and includes the extraction
of relevant information from the historic data. Step 1-
4 are the actual recommendation generation where a
subset of nodes is selected to be used as a basis to
generate the recommendations. In step 1, it is de-
cided which concepts to use for recommendation gen-
eration, step 2 converts those to be fed into the node
embedding. The results are then curated in step 3 be-
fore being filtered (for unwanted recommendations)
in step 4. Afterwards, the resulting recommendation
list is presented in an UI to be made available to the
user (step 5). Last, elements are added to the model
(step 6). As we focus on the recommendation gener-
ation during steps 0-4, we do not cover steps 5 and 6
in this paper.
In particular, we focus on two key aspects of sup-
port during manual semantic model creation: (1) re-
duction of modeling time and (2) provision of use-
ful context information. We achieve a reduction of
modeling time by eliminating the need for manual
searches in ontologies. By offering a pre-selection
of likely concepts, the user saves browsing time, thus
speeding up the modeling process. Ideally, this also
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
702

0
Node Embeddings
Training
1
Current Model
2
Feed to NE
Extract label sets
3
Compute similar concepts
4
Filter
5
Display in UI
6
Add to model
Historic Models
Extended Model
Figure 4: Overview of the model extension process. The proposed engine covers steps 1-4. Steps 5+6 are not realized yet.
saves the user the time to identify the next fact to add,
e.g., This geoposition consists of latitude and longi-
tude, but also, and more significantly, the time to iden-
tify proper concept(s) and/or relation(s), e.g., :geopo-
sition :consists
of :latitude.
4.1 Embedding Generation
In order to generate model extensions, the engine
needs to select a small number of concepts from all
available concepts to recommend. Those target con-
cepts are identified by means of node similarity com-
puted using node embeddings. As training data, we
use RDF triples contained in previously created se-
mantic models. Those triples express facts in a (sub-
ject, predicate, object) form and are used to built
ontologies, semantic models and knowledge graphs.
We generate a directed weighted graph by incorpo-
rating those triples (s, p, o) and combine them to one
graph where duplicate triples are merged to one edge
with a higher weight. The weights are calculated
as ω
s,o
=
|(s,?,o)|
|(s,?,?)|
where |(s, ?, o)| denotes the number
of times a matching triple (s, ?, o) was found in the
training data (|(s, ?, ?)| respectively). The final em-
beddings are generated using Node2Vec (Grover and
Leskovec, 2016) with the weighted graph as input.
As Node2Vec only works on homogeneous graphs,
do not differentiate between relations p
1
and p
2
when
building the weighted graph, i.e. we drop the edge
label (URI) and treat all relations uniformly. In con-
trast to ontology based embeddings, this weighted
graph approach exploits previously observed models
to compute the most probable matching node com-
binations. Matching nodes are nodes similar to the
given input node and are identified by computing the
cosine distance (dot product) using the Node2Vec’s
underlying Word2Vec embeddings. Thus, in our ap-
proach, recommendations can only be generated for
concepts observed in the training data. With addi-
tional available training data, the number of domains
covered could be increased.
4.2 Model Extension Generation
In order to provide useful model extensions, the en-
gine has to predict a concept and / or relations a user
likely needs to add to increase usefulness and con-
sistency of the model. We differentiate between two
modes. In each mode, the selection of concepts to use
as an input as well as the generation inside the engine
differs.
The first mode is the extension of an existing
model with the aim of adding useful supplementary
information. This is similar to the customer visiting
a warehouse site and being shown recommendations
for general products the customer may want to pur-
chase. Those recommendations can be based on the
personal shopping history in general or items that are
being bought by multiple customers frequently in the
past. In the semantic modeling scenario, the goal is to
make the user aware of missing meta information that
could be added to the model. While it is challenging
to find improvements that apply for the whole model,
the direction of this mode is to first identify certain
areas that could be extended with context informa-
tion, and second to find suitable concepts to do so.
As a basis for those extension recommendations the
model-wide general context is used. The engine gen-
erates model extensions using all nodes of the whole
semantic model as input. In Figure 5, the general con-
text is indicated by a green border.
Using Node Embeddings to Generate Recommendations for Semantic Model Creation
703
:sensor_station
:fahrenheit
:fahrenheit
:measuredIn
:measuredIn
:measures
:locatedAt
:location
:temperature_sensor
:has
:has
:name
:air_
temperature
:surface_
temperature
:latitude
:longitude
:consistsOf
:geoposition
:consistsOf
:wgs84
:definedBy
:definedBy
:definedBy
:geo_type
:has
:measures
modeling chain / history
(focus context)
general context
modeling chain / history
(focus context)
Figure 5: Different foci during semantic model creation on a reduced semantic model from Figure 3. Arrows indicate the
order in which concepts could be added by the user and form different focus contexts. Elements in green indicate the general
context.
Once the user begins to model, i.e., manually adds
concepts to the graph, the mode changes. Now, the
engine is able to recommend concepts based on a
specific concept that has recently been added to the
model, similar to recommendation engines that sug-
gest accessories when a single item is bought online.
In this second mode, the local focus context is used
which consists of the recent modeling history, e,g,,
the last three concepts added to the model, as an input
to the engine, resulting in extensions that are more
focused on the current part of the graph. The rec-
ommendations from the focus context can be used to
quickly advance the model creation by recommending
matching concepts in the current domain or subgraph,
effectively working as an adaptive filter. The main
aim in this mode is to reduce modeling time. Differ-
ent focus contexts are shown in Figure 5 indicated by
arrows. For the orange focus context, the user added
:fahrenheit two times, resulting in a history of just
[:fahrenheit]. For the blue context, the modeling or-
der leads to a focus context of [:latitude, :longitude],
with :wgs84 being a probable output of the engine.
Once the user would add :wgs84 to the model, the
history contains [:latitude, :longitude, :wgs84].
For the actual recommendation, the trained em-
beddings in the Node2Vec model are used as back-
ground data. For each set of input concepts,
Node2Vec outputs a set of matching concepts and a
score, indicating how certain the model is for each
recommendation. In general context mode, the en-
gine is set to generate five recommendations for each
node of the input. For those nodes, the engine ad-
ditionally considers the undirected neighborhood of
the node (if it exists) to obtain more context informa-
tion. Using Figure 5 as an example, for node :loca-
tion, the input given to the embedding would be :lo-
cation, :sensor station, :geo type, :geoposition. For
each of the resulting sets of matching nodes, the aver-
age score is computed and the best three sets are se-
lected. We build the union of those sets, while adding
up the scores if the node occurred in two or more sets
and use the resulting set as the recommendation out-
put. In focus context mode, no additional information
is added before generating the model’s suggestions,
as the history already defines a context. The resulting
set of recommendations is directly used as output.
Once a set of recommendations for either of the
two modes has been computed, the engine returns the
whole set. The embedding system then has the choice
of selecting a proper sample from those elements, e.g.
top n elements based on the certainty score.
5 EVALUATION
In order to evaluate our approach, we tested the model
extension generation engine on predicting new con-
cepts for a given combination of concepts.
5.1 Data Selection
The main challenge of recommendation training is to
find a suitable data corpus that contains models with
meta concepts like units of measurement or reference
systems. As most evaluation data corpora for seman-
tic model creation aim for minimal models (Paulus
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
704

Table 1: Parameters used for the node embedding genera-
tion.
p 1
q 1
walk length 30
walks per node 500
window size 10
dimensions 100
negative sampling size 5
negative samling exponent 1.0
et al., 2021) which do not include the desired meta
concepts, those are not usable in this context.
Thus, for the test setup, we chose the VC-SLAM
corpus (Burgdorf et al., 2022) with more than 100
rich semantic models, i.e., models that contain more
than the minimal set of concepts and relations. It rep-
resents a heterogeneous collection of datasets from
the smart city domain obtained from open data plat-
forms. The data corpus itself is handcrafted and thus
also contains modeling variations for the same fact.
The underlying ontology consists of 483 different
concepts and 117 relations. Each model consists on
average of 28.1(±11.34) relations and 23.74(±8.4)
concepts with 14.81 ± 6.58 types, i.e., concepts con-
nected to data, and 8.93 ± 3.78 context nodes. Al-
though, heterogeneity is one of the advantages of the
data corpus, it poses a problem to the training ap-
proach that relies on single facts appearing multiple
times. The only shared domain in a majority of se-
mantic models is geoinformation (cf. Figure 6). We
therefore expect the engine to perform particularly
well in this domain.
The node embedding training parameters are
given in Table 1. All 101 models in the VC-SLAM
data corpus are used during training and the eval-
uation is done using a subset of 10 randomly se-
lected models. We do not treat training and evaluation
datasets separately as we expect to deal with triples
that have already been seen before.
5.2 Focus Context Evaluation
In order to evaluate the focus context extension gener-
ation, we measure the ability of the model to generate
coherent chains of concepts. In an optimal case, sub-
sequently recommended concepts are able to build a
whole subgraph, e.g., representing a specific part of
a domain, of the semantic model. The starting point
is an empty model. As target, we define the model
as it is defined in VC-SLAM. In order to generate
the chains, we use an algorithm that takes into ac-
count the output of the recommendation engine and
selects the next concept to add to the semantic model
Figure 6: Distribution of nodes over all 101 semantic mod-
els in VC-SLAM. Red bars indicate a concept from the
geoinformation domain. Only the top 30 are shown. Mul-
tiple occurrences of a concept in one model are counted as
one.
Figure 7: Chain lengths for all 101 models of the VC-
SLAM dataset obtained by Algorithm 1.
based on a set of rules. Algorithm 1 illustrated in
the Appendix shows the algorithm that, from a ran-
dom starting node, tracks the current modeling state
(model nodes, history, current chain) and computes
an intersection of the concepts in the target model
and those from the recommendation for the specific
history. A chain denotes the sequence of subsequent
recommendations that could be found using the rec-
ommendation engine. The collection of all chains is
called the trail. For each resulting node, the algorithm
then recursively computes what would happen if this
recommendation was accepted, expanding the chain
until no suitable concept can be found in the recom-
mendations. After all recursive calls have finished,
the state that generated the longest chain is selected
and added to the trail. Afterwards, a concept is ran-
domly chosen from all concepts in the target nodes
that are not yet present in the model. The process
is then repeated until all target concepts have been
added to the model and the trail is returned.
Figure 7 shows the length of all chains obtained
when running Algorithm 1 once for each model in
the data corpus. Chains of length one indicate that
Using Node Embeddings to Generate Recommendations for Semantic Model Creation
705

Figure 8: Recommendations of single concepts during the
chain evaluation. Highlighted bars indicate a concept from
the geoinformation domain.
Figure 9: Recall of the general focus recommender over all
concepts and limited to the geoinformation domain. Aver-
age is denoted by dashed line. The median of geoinforma-
tion domain is 1.0.
no matching follow up concepts could be identified
by the recommendation engine, thus the chain con-
tains only the randomly selected concept. 358 chains
of length greater than one could be found, with the
longest chains containing 9 concepts. The high num-
ber of chains of length one indicate that the recom-
mendation does not provide sufficiently certain con-
cepts for large parts of the models. Figure 8 shows
that the majority of recommended concepts are in-
deed from the geoinformation domain, showing that,
as expected in those subgraphs, focus context recom-
mendation does work. While this was expected (cf.
Section 5.1), it shows that there is future potential in
the approach once enough data becomes available to
sufficiently generate recommendations for other parts
of the ontology.
5.3 General Context Evaluation
We evaluated the performance of the general con-
text by extracting the target nodes from all models of
the VC-SLAM data corpus. Target nodes were com-
puted by first generating an approximate Steiner Tree
(i.e. minimal spanning tree that contains at least all
mapped nodes)(Hwang and Richards, 1992) of each
model and second, declare all concepts of a model
which are not part of this Steiner Tree as a target node
(cf. Figure 3, dashed elements). We then used the
Steiner Tree model as an input to the general context
recommender (cf. Figure 3, solid elements) and com-
pared the resulting recommendations with the set of
target nodes. If one or more matches are found, those
are added to the model and the next iteration started.
If no matching concepts were recommended, we se-
lect one of the remaining target concepts and add it
to the model before starting the next iteration. We ob-
tained an average recall of 0.42 over all recommended
concepts on 80 models, which is similar to the results
obtained in the focus context evaluation. For the re-
maining 21 models, we did not identify any target
concepts in addition to the the minimal model iden-
tified by the Steiner Tree, eliminating those models
from the general context evaluation. Limited to the
geoinformation domain, recall increased to 0.72 (Fig-
ure 9). This shows that, given more available training
data, the engine provides improved results.
5.4 Discussion
The achieved results in both focus context recommen-
dation as well as the general context show the poten-
tial benefit of the approach. In both modes, recom-
mendations were generated that improve the model-
ing process once implemented into a semantic refine-
ment platform such as Karma or PLASMA (cf. Sec-
tion 3). However, as a content-based recommender
system, the approach can only be used for domains
where existing semantic models are available. The
effective modeling performance of a recommenda-
tion system is still dependent on an external model-
ing system to measure the acceptance rate using a
comparative user study. Based on our observations,
the achieved results indicate that recommendations
will in most cases result in a modeling time reduction
compared to manual search of concepts. However,
while the approach yielded promising results in the
domain of geoinformation, the general performance
of the approach could not be estimated due to the lack
of training data. Nevertheless, we can assume that
if additional training data for other domains becomes
available, the approach will show similar results for
those domains.
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
706

6 CONCLUSION AND OUTLOOK
In this paper, we presented an recommendation en-
gine to generate model extension recommendations
for semantic models. The focus of this engine is to en-
rich auto-generated semantic models with additional
information to increase the informativeness and us-
ability of the model. Recommendations are gener-
ated using a node embedding trained on existing se-
mantic models using Node2Vec. We have shown that
the engine finds suitable recommendations for both
operation modes (focus and general context) when
used on the VC-SLAM data corpus. However, the
most promising results were limited to the domain of
geoinformation due to the characteristics of the sin-
gle suitable data corpus that was used as background
data. Once more data sets like VC-SLAM become
available, we will evaluate our approach on those.
For our future work, we would like to improve the
engine to be able to recommend whole triples, i.e.,
including the relation, instead of single concepts in
order to add more context information that has been
observed in the training data in one step. The cur-
rent state of the engine does not take into account
which relation type could potentially be used to link
an existing concept to a recommended one and there-
fore does not exploit all available information. Triple
recommendation would further reduce the modeling
time. Furthermore, we would also like to recommend
replacements to existing elements, targeting elements
that were potentially falsely added by fully automated
approaches even before the refinement began. Once
capable of recommending triples, we plan to inte-
grate the approach into a modeling framework and
test the usefulness of the generated recommendations
in a comprehensive user study.
REFERENCES
Abdelmageed, N. and Schindler, S. (2020). JenTab: Match-
ing Tabular Data to Knowledge Graphs. The 19th In-
ternational Semantic Web Conference.
Almonte, L., Guerra, E., Cantador, I., and Lara, J. (2021).
Recommender systems in model-driven engineering:
A systematic mapping review. Software and Systems
Modeling.
Baumgartner, M., Dell’Aglio, D., and Bernstein, A. (2021).
Entity Prediction in Knowledge Graphs with Joint
Embeddings. In Proceedings of the Fifteenth Work-
shop on Graph-Based Methods for Natural Language
Processing (TextGraphs-15), pages 22–31, Mexico
City, Mexico. Association for Computational Linguis-
tics.
Burgdorf, A., Paulus, A., Pomp, A., and Meisen, T. (2022).
VC-SLAM - A Handcrafted Data Corpus for the Con-
struction of Semantic Models. Data, 7(2).
Codina, V. and Ceccaroni, L. (2010). Taking advantage of
semantics in recommendation systems. volume 220,
pages 163–172.
Futia, G., Vetr
`
o, A., and de Martin, J. C. (2020). SeMi:
A SEmantic Modeling machIne to build Knowledge
Graphs with graph neural networks. SoftwareX,
12:100516.
Grover, A. and Leskovec, J. (2016). Node2vec: Scal-
able feature learning for networks. In Proceedings
of the 22nd ACM SIGKDD International Conference
on Knowledge Discovery and Data Mining, KDD ’16,
page 855–864, New York, NY, USA. Association for
Computing Machinery.
Hwang, F. K. and Richards, D. S. (1992). Steiner tree prob-
lems. Networks, 22(1):55–89.
Knoblock, C. A., Szekely, P., et al. (2012). Semi-
Automatically Mapping Structured Sources Into the
Semantic Web. In Extended Semantic Web Confer-
ence, pages 375–390.
Papapanagiotou, P., Katsiouli, P., et al. (2006). RONTO:
Relational to Ontology Schema Matching. AIS
Sigsemis Bulletin, 3(3-4):32–36.
Paulus, A., Burgdorf, A., Pomp, A., and Meisen, T. (2021).
Recent advances and future challenges of semantic
modeling. In 2021 IEEE 15th International Confer-
ence on Semantic Computing (ICSC), pages 70–75.
Paulus., A., Burgdorf., A., Puleikis., L., Langer., T., Pomp.,
A., and Meisen., T. (2021). PLASMA: Platform for
Auxiliary Semantic Modeling Approaches. In Pro-
ceedings of the 23rd International Conference on En-
terprise Information Systems - Volume 2: ICEIS,,
pages 403–412. INSTICC, SciTePress.
Paulus, A., Pomp, A., et al. (2018). Gathering and Com-
bining Semantic Concepts from Multiple Knowledge
Bases. In ICEIS 2018, pages 69–80, Set
´
ubal, Portugal.
Pham, M., Alse, S., et al. (2016). Semantic Labeling: A
Domain-Independent Approach. In The Semantic Web
– ISWC 2016, pages 446–462, Cham. Springer Inter-
national Publishing.
Pinkel, C., Binnig, C., et al. (2017). IncMap: a Journey
Towards Ontology-based Data Integration. Daten-
banksysteme f
¨
ur Business, Technologie und Web (BTW
2017).
Pomp, A., Kraus, V., et al. (2020). Semantic Concept Rec-
ommendation for Continuously Evolving Knowledge
Graphs. In Enterprise Information Systems, Lecture
Notes in Business Information Processing. Springer.
Rijgersberg, H., Assem, M., and Top, J. (2013). Ontology
of units of measure and related concepts. Semantic
Web, 4:3–13.
R
¨
ummele, N., Tyshetskiy, Y., and Collins, A. (2018). Eval-
uating Approaches for Supervised Semantic Labeling.
CoRR, abs/1801.09788.
Saeedi, A., Peukert, E., and Rahm, E. (2020). Incremen-
tal multi-source entity resolution for knowledge graph
completion. In The Semantic Web, pages 393–408,
Cham. Springer International Publishing.
Using Node Embeddings to Generate Recommendations for Semantic Model Creation
707

Taheriyan, M., Knoblock, C. A., et al. (2016). Learning the
Semantics of Structured Data Sources. Journal of Web
Semantics, 37-38:152–169.
U
˜
na, D. D., R
¨
ummele, N., et al. (2018). Machine Learn-
ing and Constraint Programming for Relational-To-
Ontology Schema Mapping. In Proceedings of the
Twenty-Seventh International Joint Conference on Ar-
tificial Intelligence.
Vu, B., Knoblock, C., and Pujara, J. (2019). Learning Se-
mantic Models of Data Sources Using Probabilistic
Graphical Models. In The World Wide Web Confer-
ence, WWW ’19, pages 1944–1953, New York, NY,
USA. ACM.
APPENDIX
Algorithm 1: Algorithm to simulate a modeling process in order to evaluate the generation of subsequent recommendations
in the focus context. For each proper recommendation, the current modeling chain is recursively expanded until no further
matching recommendations can be found. All computed chains then form the trail which is returned for evaluation.
function BUILD CHAIN(chain, model nodes, current node, history)
history ← history + current node # remove first element in list if list longer than n
history ← TRUNCATE(history, n)
chain ← chain + current node
model nodes ← model nodes + current node
# generate recommendations for the current history
f ocus recommended ← ENGINE.RECOMMEND(history)
# remove nodes that are already present
f ocus recommended ← REMOVE EXISTING NODES( f ocus recommended, model nodes)
matches ← GET MATCHES IN TARGET MODEL( f ocus recommended, target nodes)
if len(matches) == 0 then
return chain, model nodes, current node, history # end the chain
end if
results ← [ ] # recursively evaluate recommendations for each possible added concept
for all match in matches do
new chain ← BUILD CHAIN(chain,model nodes, match, history)
results ← results + (new chain, model nodes, match, history)
end for
results ← SORT BY CHAIN LENGTH(results) # find the longest chain
return results[0] # return the longest chain and modeling context
end function
function BUILD TRAIL(target nodes)
model nodes ← [ ] # start with an empty model
random node ← GET UNMAPPED RANDOM NODE(model nodes, target nodes)
current ← random node
trail ← [ ], chain ← [ ], history ← [ ]
while |model nodes| < |target nodes| do
chain, model nodes, current, history ← BUILD CHAIN(chain,model nodes, current, history)
trail ← trail + chain
history ← [ ], chain ← [ ]
current = GET UNMAPPED RANDOM NODE(model nodes, target model)
end while
return trail
end function
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
708
