
FAIR Principles and Big Data:
A Software Reference Architecture for Open Science
Jo
˜
ao P. C. Castro
1,2 a
, Lucas M. F. Romero
1 b
, Anderson C. Carniel
3 c
and Cristina D. Aguiar
1 d
1
Department of Computer Science, University of S
˜
ao Paulo, Brazil
2
Information Technology Board, Federal University of Minas Gerais, Brazil
3
Departament of Computer Science, Federal University of S
˜
ao Carlos, Brazil
Keywords:
Open Science, FAIR Principles, Big Data Analytics, Software Reference Architecture.
Abstract:
Open Science pursues the assurance of free availability and usability of every digital outcome originated from
scientific research, such as scientific publications, data, and methodologies. It motivated the emergence of
the FAIR Principles, which introduce a set of requirements that contemporary data sharing repositories must
adopt to provide findability, accessibility, interoperability, and reusability. However, implementing a FAIR-
compliant repository has become a core problem due to two main factors. First, there is a significant complex-
ity related to fulfilling the requirements since they demand the management of research data and metadata.
Second, the repository must be designed to support the inherent big data complexity of volume, variety, and
velocity. In this paper, we propose a novel FAIR-compliant software reference architecture to store, process,
and query massive volumes of scientific data and metadata. We also introduce a generic metadata warehouse
model to handle the repository metadata and support analytical query processing, providing different perspec-
tives of data insights. We show the applicability of the architecture through a case study in the context of a
real-world dataset of COVID-19 Brazilian patients, detailing different types of queries and highlighting their
importance to big data analytics.
1 INTRODUCTION
In the era of big data analytics, data is constantly be-
ing collected on an unprecedented scale. This occurs
mostly due to advances in cloud computing and paral-
lel and distributed data processing, which are respon-
sible for reducing challenges regarding storing and
querying massive datasets. These advances also moti-
vate the sharing of datasets and their derived analyses.
In this context, a significant opportunity has
emerged for the scientific community: boosting sci-
entific data sharing to increase the collaboration be-
tween researchers across the globe. The concept of
Open Science is an answer to this opportunity. Its
objective is to ensure that every digital output of re-
search objects is made available and usable free of
charge (Medeiros et al., 2020). These outputs can in-
clude, but are not limited to: (i) research publications;
a
https://orcid.org/0000-0003-3566-0415
b
https://orcid.org/0000-0002-2155-8076
c
https://orcid.org/0000-0002-8297-9894
d
https://orcid.org/0000-0002-7618-1405
(ii) research data; and (iii) research methodologies,
encompassing any algorithm employed in the process
of generating research data.
Such magnitude of scientific data sharing de-
mands a dedicated infrastructure, which must be im-
plemented in a standardized manner to avoid any type
of incompatibilities. Therefore, a set of standards
referred to as the FAIR Principles have been pro-
posed (Wilkinson et al., 2016). FAIR stands for Find-
ability, Accessibility, Interoperability, and Reusabil-
ity of digital datasets. These principles describe
several requirements that contemporary data sharing
repositories must adopt to support manual and au-
tomated deposition, exploration, sharing, and reuse.
Satisfying these requirements involves handling sci-
entific data and their associated metadata, which can
result in a significant complexity depending on their
volume, variety, and velocity (Chen et al., 2014).
However, the FAIR Principles alone may not be
enough to guide a data engineer towards the imple-
mentation of a repository capable of addressing chal-
lenges inherent to the context of Open Science. Their
proximity to the user level and the complexity intrin-
Castro, J., Romero, L., Carniel, A. and Aguiar, C.
FAIR Principles and Big Data: A Software Reference Architecture for Open Science.
DOI: 10.5220/0011045500003179
In Proceedings of the 24th International Conference on Enterprise Information Systems (ICEIS 2022) - Volume 1, pages 27-38
ISBN: 978-989-758-569-2; ISSN: 2184-4992
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
27

sic to big data environments requires the adoption of a
Software Reference Architecture (SRA) to assist data
engineers in overcoming this gap.
According to Nakagawa et al. (2017), an SRA
is “an architecture that encompasses the knowledge
about how to design concrete architectures of sys-
tems of a given application or technological domain”.
That is, SRAs are employed as a basis to derive archi-
tectures adapted to the requirements of specific con-
texts (Angelov et al., 2012). Regarding Open Science,
SRAs can work as a bridge between the FAIR Princi-
ples and the repository being implemented.
Due to the close relationship between Open Sci-
ence and big data analytics, an SRA designed to sup-
port the FAIR Principles must include components
to store considerable volumes of data and metadata,
which can be later efficiently retrieved by analytical
queries. The use of a data warehouse and a data lake
in this context enhances the features provided by the
SRA. A data warehouse is an integrated, subject ori-
ented, historical, and non-volatile database that is usu-
ally built by a multidimensional model (Kimball and
Ross, 2011; Vaisman and Zim
´
anyi, 2014). A data
lake is a considerably large raw data storage that deals
with any data format, i.e., structured, semi-structured,
and unstructured data (Couto et al., 2019; Sawadogo
and Darmont, 2021). Besides their importance in en-
abling the repository compliance with the FAIR Prin-
ciples, these components also contribute to the gener-
ation of data insights, an essential characteristic in the
decision-making process of big data analytics.
Despite the considerable importance behind
adopting an SRA to support Open Science, solutions
available in the literature introduce limitations, as de-
tailed in Section 2 and summarized as follows.
There are studies that propose SRAs for generic
big data systems but are unaware of the intrinsic char-
acteristics of the FAIR Principles. There are also
implementations of the FAIR principles in reposito-
ries that are driven to specific contexts. However,
these implementations do not propose an architecture
generic enough to fit the concept of an SRA, nega-
tively impacting on reusability. These limitations mo-
tivate the development of our work.
We introduce the following contributions:
• Proposal of an SRA to implement a data sharing
repository that is compliant with the FAIR Princi-
ples and is able to store, process, and query mas-
sive volumes of scientific data and metadata.
• Specification of a generic multidimensional
model to implement a metadata warehouse to han-
dle the repository metadata.
• Demonstration of the applicability of our architec-
ture through a case study that manipulates a real-
world dataset.
The remainder of this paper is organized as fol-
lows. Section 2 reviews related work. Section 3
presents the proposed architecture and highlights its
compliance with the FAIR Principles. Section 4 de-
tails the design of the metadata warehouse. Section 5
describes the case study that instantiates the architec-
ture and shows the execution of analytical queries,
discussing their usefulness in the decision-making
process. Finally, Section 6 concludes the paper.
2 RELATED WORK
In this section, we analyze studies available in the
literature by dividing them in two groups. Group 1,
named big data architectures, consists of general pur-
pose big data SRAs, i.e., big data architectures that
were not developed with the objective of complying
with the FAIR Principles. The state-of-the art ar-
chitectures are (Davoudian and Liu, 2020): (i) tra-
ditional business intelligence (Vaisman and Zim
´
anyi,
2014); (ii) kappa (Kreps, 2014); (iii) lambda (Warren
and Marz, 2015); (iv) liquid (Fernandez et al., 2015);
(v) solid (Mart
´
ınez-Prieto et al., 2015); and (vi) bol-
ster (Nadal et al., 2017).
The main objective behind these architectures is
the generation of knowledge from big data to assist
users in the decision-making process. However, due
to their concern in providing real time analytics, most
of these SRAs are not designed for collecting and
managing data provenance and other types of meta-
data. Since this is an essential characteristic for a
repository to be compliant with the FAIR Principles,
these architectures can be deemed inadequate for the
context of Open Science.
The exceptions are the traditional business intel-
ligence and bolster architectures. Besides being able
to provide real time analytics, these architectures em-
ploy a centralized metadata repository for the collec-
tion and maintenance of different types of metadata.
However, they do not comply with several require-
ments imposed by the FAIR Principles. For instance,
these SRAs do not support the retrieval of source data
objects based on their metadata. They are also not
capable of guaranteeing that metadata will be kept
alive even when their corresponding data objects no
longer exist. Furthermore, these architectures are not
concerned with ad-hoc data anonymization or the em-
ployment of knowledge mapping data structures to
comply with domain-relevant community standards.
Group 2, named FAIR implementations, consists
of implementations of the FAIR Principles in data
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
28
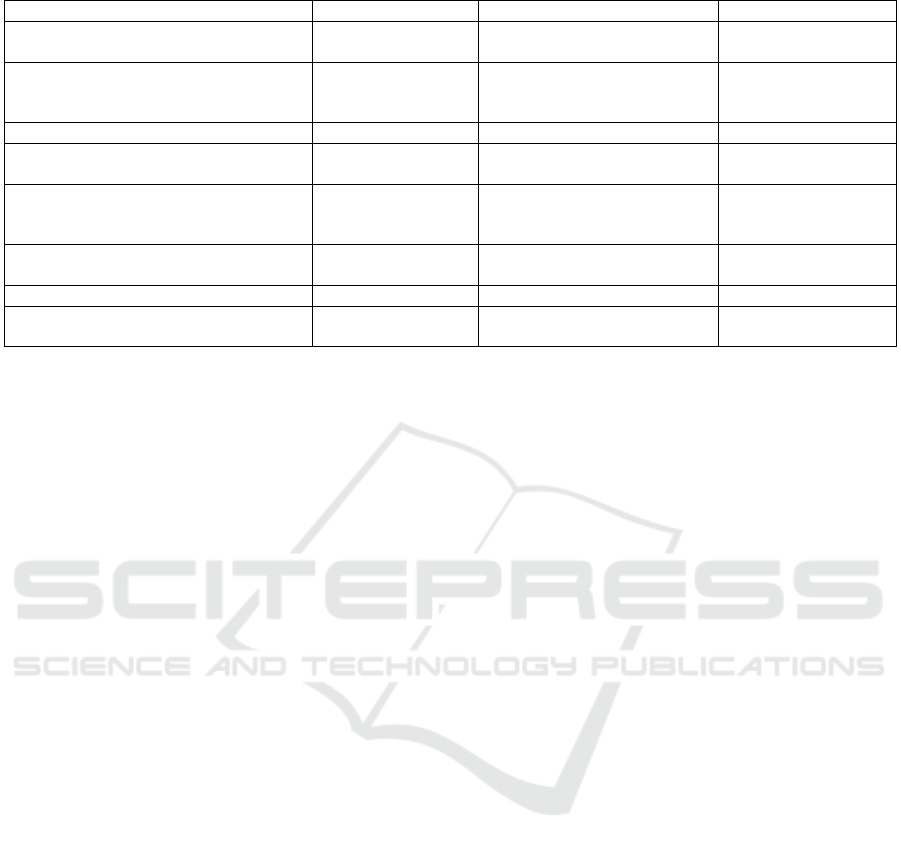
Table 1: Comparing the key characteristics of the proposed SRA with related work.
Key Characteristics Big Data SRAs FAIR Implementations Our Architecture
Complies with the FAIR Principles 7
Not clear if all requirements
are fulfilled
3
Describes the association between the
architecture’s layers and the FAIR
Principles
7 7 3
Can fit the concept of a SRA 3 7 3
Retrieves source data objects though its
metadata
7 3 3
Guarantees the existence of the
metadata even when the related data
object does not exist
7 3 3
Enables the generation of big data
insights
3 7 3
Provides ad-hoc data anonymization 7 7 3
Employs knowledge mapping data
structures
7 3 3
sharing repositories that are driven to specific con-
texts. The work of Pommier et al. (2019) describes a
workflow for the plant phenotypic data management,
detailing the data models and technologies used to
comply with the FAIR Principles. Devarakonda et al.
(2019) introduce a workflow to enable the adoption
of the FAIR Principles in the Atmospheric Radiation
Measurement Data Center, specifying the dataflow
and the employed components. In Lannom et al.
(2020), the context of biodiversity science and geo-
science is addressed through the proposal of a Digital
Object Architecture in an attempt to satisfy the FAIR
Principles. Sinaci et al. (2020) propose a workflow
to implement the FAIR Principles in the context of
health data, along with an architecture for this specific
domain. Finally, in Delgado and Llorente (2021), a
modular architecture that handles genomic informa-
tion and supports the FAIR Principles is proposed,
and the technologies employed in each service are
specified.
Although studies in Group 2 are concerned with
the intrinsic characteristics of the FAIR Principles,
they face several limitations. First, they do not pro-
pose an architecture that is generic enough to fit the
concept of an SRA. This is mostly due to the fact
that the proposed solutions are domain-specific, over-
burdening data engineers in the process of adapting
their solutions to different contexts. Second, some of
the studies are described at the implementation level,
such as Pommier et al. (2019) and Devarakonda et al.
(2019). This negatively impacts the reuse of the pro-
posed solutions, a FAIR principle of significant im-
portance.
Third, none of the studies clarify which require-
ments imposed by the FAIR Principles are satisfied
by their solutions. This fact raises two significant con-
cerns: (i) which parts of the solution are responsible
for implementing a specific requirement; and (ii) if all
requirements are being completely fulfilled. Fourth,
the studies are not optimized to provide big data in-
sights to data consumers. Although this is not a re-
quirement imposed by the FAIR Principles, it is im-
portant to support the decision-making process. Fifth,
ad-hoc data anonymization is not addressed by the
studies, raising an imbroglio regarding data security
and the compliance of the repository with domain-
relevant community standards.
In this paper, we overcome the limitations of the
studies analyzed in this section, as summarized in Ta-
ble 1. We propose an SRA to implement a data and
metadata sharing repository according to the FAIR
Principles. We highlight the relationship between
these principles and each of the architecture layers.
Our solution can retrieve source data objects by us-
ing their metadata and also generate multiple insights
to assist users in the decision-making process of big
data analytics. Furthermore, due to the employment
of a metadata warehouse, our architecture guaran-
tees the persistence of metadata even when the re-
lated data objects no longer exist. Finally, we employ
ad-hoc data anonymization and knowledge mapping
data structures to comply with domain-relevant com-
munity standards.
3 ARCHITECTURE
In this section, we describe a novel SRA for imple-
menting a data sharing repository compliant with the
FAIR Principles. Section 3.1 introduces the layers of
this architecture. Section 3.2 describes how these lay-
ers comply with the FAIR Principles.
FAIR Principles and Big Data: A Software Reference Architecture for Open Science
29

Personal
Repository
Personal
Repository
Personal
Repository
Metadata Lake
Extraction/Load
(EL) via Streaming
Transformation (T)
Metadata
Warehouse
Metadata Governance
Repository
Big Data
Querying
Authentication
Software
Data Providers
and Consumers
Personal Storage Layer
Metadata Storage Layer
Data Retrieval Layer
Data Publishing Layer
User Layer
Ontologies
Knowledge
Graphs
Knowledge Mapping Layer
Big Data
Processing
Search Engine
Registering
User Permissions
Database
Data Insights Layer
Analytics
Dashboards
Machine Learning
Algorithms
Report Tools
Data
Anonymization
Local Infrastructure Repository Infrastructure
Figure 1: The proposed architecture for implementing a data sharing repository compliant with the FAIR Principles.
3.1 Layers
Figure 1 depicts our proposed architecture, which
consists of the following layers: (i) User; (ii) Per-
sonal Storage; (iii) Metadata Storage; (iv) Data Re-
trieval; (v) Knowledge Mapping; (vi) Data Insights;
and (vii) Data Publishing. In these layers, compo-
nents are represented by boxes with a solid border,
whereas processes are represented by boxes with a
dashed border. Furthermore, directional arrows rep-
resent the flow of data through the different layers,
components, and processes. Whenever the depiction
of these arrows include a padlock, the flow of data
must be end-to-end encrypted. This is due to the fact
that our architecture employs ad-hoc data anonymiza-
tion based on user permissions; thus, it is important to
guarantee that non anonymized data travels the net-
work with enhanced security (Puthal et al., 2017).
User Layer. Encompasses the users that interact with
the data repository and their respective environment.
Users can assume one or both of the following roles:
(i) data providers, which are responsible for loading
their own personal repository with their research data
and respective metadata, if available; and (ii) data
consumers, which can consume different types of data
from the repository. Data providers interact only
with the Personal Storage Layer, where their personal
repositories are located. On the other hand, data con-
sumers interact only with the Data Publishing Layer,
providing data requests and their credentials for au-
thentication, depending on the nature of the request.
Personal Storage Layer. Comprises a set of repos-
itories built to store research data objects along with
their respective metadata. Each personal repository
is owned by a different data provider and can be im-
plemented by using any available technology (e.g. a
data lake). Thus, the repositories can be autonomous,
geographically distributed, and heterogeneous. Our
architecture requires every personal repository to be
connected to a data streaming application program-
ming interface (API) responsible to send every novel
metadata entry to the metadata storage layer in real
time (e.g., Apache Kafka (Le Noac’h et al., 2017)).
This is an important characteristic of the architecture
since it enables analyses involving researches that are
constantly generating data in short intervals. It is also
imperative for the personal repositories to have an in-
terface that allows the Data Retrieval Layer to capture
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
30

research data objects when requested by data con-
sumers.
Metadata Storage Layer. Stores the metadata con-
stantly extracted from the Personal Storage Layer. To
this end, we employ two types of repositories: Meta-
data Warehouse and Metadata Lake. Due to its his-
torical and non-volatile characteristics, the Metadata
Warehouse keeps the metadata alive even when their
related data objects no longer exist. It is also designed
to support batch metadata querying to provide differ-
ent types of big data insights, as detailed in Section 4.
The Metadata Lake is responsible for instantly stor-
ing the raw metadata obtained via streaming from the
Personal Storage Layer until it is completely trans-
formed and loaded into the Metadata Warehouse. The
Metadata Lake supports real time metadata querying
and also serves as a data staging area, storing the in-
termediate results of the metadata transformations to
enhance performance. All metadata provenance, such
as data about the personal repositories that provide
the metadata and details about the extraction (E), load
(L), and transformation (T) processes, are maintained
in the Metadata Governance Repository. This repos-
itory also contains metadata about the metadata ex-
tracted from the Personal Storage Layer, i.e., a set of
data that describes and gives information about the
metadata.
Data Retrieval Layer. Provides resources to process-
ing and querying tasks, and is considered the core of
the architecture. It uses the repository big data infras-
tructure along with a parallel and distributed frame-
work (e.g., Apache Spark (Zaharia et al., 2010)) to
perform several tasks, such as: (i) retrieving source
research data objects from the Personal Storage Layer
based on the content of the metadata stored in the
Metadata Storage Layer; (ii) performing ad-hoc data
anonymization (Bazai et al., 2021) in the original re-
search data objects and in their associated metadata
according to the specifications sent by the Data Pub-
lishing Layer; (iii) using the ontologies and knowl-
edge graphs from the Knowledge Mapping Layer to
translate user data requests to the data model adopted
by the Metadata Storage Layer; and (iv) accessing the
content of every other layer to generate different types
of intelligence for the Data Insights Layer.
Knowledge Mapping Layer. We employ knowledge
mapping data structures, such as ontologies (Staab
et al., 2001) and knowledge graphs (Ehrlinger and
W
¨
oß, 2016) for different purposes. For instance, these
structures can serve as a mapping between a generic
data model known by data consumers and the data
model implemented by the Metadata Storage Layer.
This is a very important requirement to data con-
sumers since it enables data retrieval by using well-
known standards. Further, the models stored in the
Knowledge Mapping Layer can also be applied to de-
lineate different data relationships, enabling the gen-
eration of several types of big data insights.
Data Insights Layer. Enables the generation of de-
scriptive, predictive, and prescriptive analyses (Lep-
enioti et al., 2020) by using the content stored in the
Metadata Storage, Personal Storage, and Knowledge
Mapping layers. The insights created by this layer to
support big data analytics can include, but are not lim-
ited to: (i) public dashboards that enhance the public-
ity of the scientific data stored in the repository, mak-
ing it more findable; (ii) private dashboards used by
managers and directors to monitor the repository; (iii)
machine learning models, which can be employed to
perform predictive and prescriptive analyses; and (iv)
report tools that generate predefined reports from the
stored data. The created insights are accessed only
through the Data Publishing Layer to guarantee secu-
rity and anonymization.
Data Publishing Layer. Serves as a single access
point for data consumers to obtain any type of data
from the repository. It is responsible for authenticat-
ing data consumers, receiving their data requests, and,
based on their permissions, sending the requests to the
Data Retrieval Layer along with data anonymization
specifications. It also returns the metadata requested
to data consumers as soon as they are processed by the
Data Retrieval Layer or the Data Insights Layer. Fur-
ther, the Data Publishing Layer supports mechanisms
for indexing the metadata stored in the repository in a
search engine to provide increased findability.
Because of the multiple possible contexts behind
the implementation of a repository compliant with the
FAIR Principles, it is not mandatory to instantiate ev-
ery component in the architecture. Data engineers
should choose the appropriate layers and components
according to the characteristics of the environment in
which the architecture is being employed.
3.2 Compliance with the FAIR
Principles
Table 2 describes the requirements related to the FAIR
Principles of Findability, Acessibility, Interoperabil-
ity, and Reusability. It also highlights which layers of
the proposed SRA (Figure 1) fulfill each requirement.
The Findability requirements are mostly satisfied
by the Metadata Storage Layer. This layer contains
the Metadata Warehouse, which is responsible for
storing the metadata (F2) and its identifier (F1), as
well as maintaining the identifier of the data instance
FAIR Principles and Big Data: A Software Reference Architecture for Open Science
31

Table 2: Relationship between the architecture layers and the FAIR Principles. Requirements reproduced from Wilkinson et
al. (2016).
Principles Requirements Architecture Layers
Findability
F1. Data and metadata are assigned a globally unique and
persistent identifier.
Personal Storage
Metadata Storage
F2. Data is described with rich metadata. Metadata Storage
F3. Metadata clearly and explicitly include the identifier of the
data it describes.
Metadata Storage
F4. Data and metadata are registered or indexed in a searchable
resource.
Data Publishing
Accessibility
A1. Data and metadata are retrievable by their identifier using a
standardized communications protocol.
Data Publishing
Data Retrieval
Metadata Storage
Personal Storage
A1.1. The protocol is open, free, and universally implementable. Data Publishing
A1.2. The protocol allows for an authentication and authorization
procedure, where necessary.
Data Publishing
A2. Metadata is accessible, even when the data is no longer
available.
Metadata Storage
Interoperability
I1. Data and metadata use a formal, accessible, shared, and
broadly applicable language for knowledge representation.
Knowledge Mapping
I2. Data and metadata use vocabularies that follow FAIR
Principles.
Knowledge Mapping
I3. Data and metadata include qualified references to other data
and metadata.
Knowledge Mapping
Reusability
R1. Data and metadata are richly described with a plurality of
accurate and relevant attributes.
Metadata Storage
R1.1. Data and metadata are released with a clear and accessible
data usage license.
Metadata Storage
R1.2. Data and metadata are associated with detailed provenance. Metadata Storage
R1.3. Data and metadata meet domain-relevant community
standards.
Metadata Storage
Knowledge Mapping
to which the metadata refers (F3). These identifiers
can be implemented as unique fields, such as primary
keys in relational databases. Two other layers also
enable findability. The Personal Storage Layer as-
signs an identifier for every data instance (F1) and the
Data Publishing Layer is responsible for registering
the repository in search engines (F4).
Regarding the Accessibility requirements, they
fall mostly under the responsibility of the Data Pub-
lishing Layer since it handles user connection (A1,
A1.1) and authentication (A1.2). The Metadata Stor-
age Layer also plays a significant role since the Meta-
data Warehouse keeps the metadata alive even when
the source data is no longer available (A2). Fi-
nally, the Data Retrieval, Metadata Storage, and Per-
sonal Storage layers enable data retrieval based on its
unique identifier (A1).
The Knowledge Mapping Layer must be em-
ployed to enable the Interoperability requirements.
This layer handles the translation between schemas in
the Metadata Storage and Personal Storage layers to
a well-known language (I1) and vocabulary (I2). It is
also responsible for storing the relationships between
different instances of metadata and data objects (I3).
Finally, the Reusability requirements are tackled
as follows. In the Metadata Storage Layer, the Meta-
data Warehouse enables a rich description of the data
objects and their metadata (R1), encompassing a di-
mension to deal with licensing information (R1.1)
and a Metadata Governance Repository to store data
provenance (R1.2). Further, the compliance with
domain-relevant community standards (R1.3) is ob-
tained by the Metadata Warehouse or through a map-
ping stored in the Knowledge Mapping Layer.
Our architecture goes one step forward in regards
to the FAIR Principles since it also enables big data
analytics. The Metadata Warehouse and the Metadata
Lake store huge volumes of metadata that can be re-
trieved efficiently by the Data Insights Layer. The
Metadata Warehouse supports the traditional batch
analytical query processing, while the Metadata Lake
is responsible for the streaming query processing to
monitor and extract knowledge in (almost) real time.
Therefore, the architecture contributes to the genera-
tion of a broad set of data insights to support data con-
sumers in the decision-making process. We show this
applicability by using real-world datasets of COVID-
19 Brazilian patients, as discussed in Section 5.
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
32

FACT_STORAGE
sk_dataprovider
sk_datarepository
sk_datacell
sk_status
sk_permissions
sk_license
sk_date
sk_time
size
DIM_DATE
sk_date
day
month
semester
year
DIM_TIME
sk_time
second
minute
hour
DIM_DATAREPOSITORY
sk_datarepository
name
description
storage_type
connection_string
connection_username
connection_password
DIM_DATACELL
sk_datacell
data_object_title
data_object_description
data_object_type
data_attribute_title
data_attribute_description
data_attribute_type
data_attribute_possible_content
data_instance_unique_source_id
DIM_STATUS
sk_status
source_status
DIM_PERMISSIONS
sk_permissions
required_access_role
anonymization_required
DIM_LICENSE
sk_license
type
description
DIM_DATAPROVIDER
sk_dataprovider
name
description
type
city
state
country
Figure 2: The proposed metadata warehouse generic model.
4 METADATA WAREHOUSE
GENERIC MODEL
To effectively implement a data warehouse, we must
first model its numeric measures and dimensions. Nu-
meric measures are the subjects of interest. Dimen-
sions are described by a set of attributes and deter-
mine the context for these measures. In relational
implementations, the data warehouse is designed
through a star schema composed of fact and dimen-
sion tables, corresponding to the numeric measures
and dimensions, respectively (Kimball and Ross,
2011).
We propose a generic model for the Metadata
Warehouse that encompasses the needed metadata for
a repository to be compliant with the FAIR Principles.
This model is composed of eight dimension tables and
one fact table, as shown in Figure 2. More dimensions
or attributes can be included depending on the scope
of the repository being modeled.
The fact table FACT STORAGE represents the
event of extracting the metadata of a data cell at a
given date and time, considering the data repository,
the data provider, and the associated status, permis-
sions, and license. A data cell can be defined as the in-
tersection of an attribute and a tuple, such as the value
of a column in a row for a relational table, or the value
of a field in a document for a document collection.
The fact table contains the surrogate keys of every di-
mension, enabling different perspectives of analysis.
The set of these surrogate keys also composes the pri-
mary key. The fact represents the size of the data cell,
which can be expressed in characters, bytes, or simi-
lar measurement units. It is an additive numeric mea-
sure, indicating that the size can be summed across all
dimensions. Thus, it can be useful to support analy-
ses regarding the growth of the repository over time.
Other numeric measures can also be included in the
fact table, depending on the context of the repository
being implemented.
The following dimension tables are associated
with the fact table: (i) DIM DATAPROVIDER,
storing information on the provider of the data
cell, such as its name, type, and location;
(ii) DIM DATAREPOSITORY, containing the data
necessary to connect to the repository, its descrip-
tion, and storage type (e.g., PostgreSQL storage);
(iii) DIM DATACELL, keeping the metadata related
FAIR Principles and Big Data: A Software Reference Architecture for Open Science
33

BPSP HDFS
Repository
HDFS Metadata
Lake
Extraction/Load (EL)
via Apache Kafka
Transformation (T)
with Apache Spark
HDFS Metadata
Warehouse
Data Consumer
Personal Storage Layer
Metadata Storage Layer
Data Retrieval Layer User Layer
Big Data Processing
with Apache Spark
(c) Local Infrastructure(b) Repository Infrastructure
BPSP Provider
User Layer
USP Provider
FG Provider
AE Provider
SL Provider
USP HDFS
Repository
FG HDFS
Repository
AE HDFS
Repository
SL HDFS
Repository
(a) Local Infrastructure
Big Data Querying
with SparkSQL
Figure 3: Architecture instantiation for the context of the COVID-19 DataSharing/BR dataset.
to the source data objects (e.g., a relational table),
its attributes (e.g., a column in a relational table),
and its instances (e.g., a row in a relational ta-
ble); (iv) DIM STATUS, storing the status of the
data cell in the data source, specifying if it still ex-
ists; (v) DIM PERMISSIONS, maintaining the re-
quired role to access a data cell and a boolean at-
tribute to inform if data anonymization is required for
the access; (vi) DIM LICENSE, containing the data
cell licensing information; and (vii) DIM DATE and
DIM TIME, representing respectively the date and
time in which the data cell metadata has been ex-
tracted from the Personal Storage Layer.
The use of the metadata warehouse generic model
depicted in Figure 2 is very important to achieve the
FAIR Principles in a data sharing repository. For in-
stance, it enables data objects to be associated with
rich metadata, keeping it persisted even when these
objects no longer exist. Furthermore, due to the in-
trinsic characteristics of a data warehouse (i.e. sub-
ject oriented and integrated), analytical queries on the
stored metadata are considerably optimized, an essen-
tial characteristic for a big data analytics environment.
Analyses involving multiple perspectives are also en-
abled, not only due to the plurality of the dimensions
incorporated in the model but also due to the fact that
the data size is stored in the lowest possible granular-
ity level. Finally, since the model does not contain any
components that are specific to a particular repository,
it is generic enough to be reused in distinct contexts.
5 CASE STUDY
In this section, we present a case study to show how
our architecture and the metadata warehouse generic
model can be deployed to enable scientific data shar-
ing according to the FAIR Principles in a real-world
context. Our goal is to not conduct performance eval-
uations since it goes beyond the scope of this paper.
Section 5.1 discusses how to instantiate the architec-
ture to the given context. Section 5.2 describes differ-
ent analytical queries that data consumers can execute
on top of this instantiation.
5.1 Architecture Instantiation
We employ a real-world dataset of COVID-19 Brazil-
ian patients. The dataset is available in the COVID-19
DataSharing/BR repository (FAPESP, 2020), which
is a FAIR-compliant Open Science repository devel-
oped by the State of S
˜
ao Paulo Research Foundation
(FAPESP). Every data object available in this repos-
itory is accompanied by its metadata, such as a data
dictionary that describes the data type and the mean-
ing of every one of its attributes.
There are five distinct data providers, all refer-
ences in the field of medical diagnosis in Brazil:
(i) Benefic
ˆ
encia Portuguesa de S
˜
ao Paulo (BPSP);
(ii) the University of S
˜
ao Paulo clinics hospital (USP);
(iii) the Fleury Group clinics (FG); (iv) the Albert
Einstein hospital (AE); and (v) the Syrian-Lebanese
hospital (SL). Each data provider contributed with
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
34

three different data objects: (i) patients data, includ-
ing their unique identification (ID), sex, birth date,
country, state, city, and zip code; (ii) medical ex-
ams, including the patient’s unique ID, consultation
ID, collection date, collection venue, analyte descrip-
tion, exam description, result, measurement unit, and
reference value; and (iii) outcome, whose fields are
the patient’s unique ID, consultation ID, consultation
date, consultation type, clinic ID, clinic description,
outcome date, and outcome description. The con-
tent of these data objects were translated from Por-
tuguese to English to provide readability. Considering
all data providers, there is a total of 862,571 patients,
54,763,675 exams, and 307,928 outcomes.
Figure 3 depicts the layers and respective com-
ponents that are required to instantiate the architec-
ture shown in Figure 1 according to the characteris-
tics of the case study. The aforementioned five data
providers are represented in the User Layer drawn
on the left (Figure 3a). The COVID-19 DataShar-
ing/BR dataset is composed of comma-separated val-
ues (CSV) and Microsoft Excel sheet (XLSX) files.
Therefore, in the Personal Storage Layer (Figure 3a),
we choose to store each data provider using a different
Hadoop Distributed File System (HDFS) (Shvachko
et al., 2010) environment so that repositories owned
by different data providers are properly represented.
The Metadata Lake and Warehouse of the Meta-
data Storage Layer (Figure 3b) are also implemented
by using the HDFS. We employ Apache Kafka
((Le Noac’h et al., 2017)) to extract every new in-
stance of metadata inserted into the Personal Stor-
age Layer (Figure 3a) and to load it into the Meta-
data Lake. Furthermore, we employ Apache Spark to
transform the content of the Metadata Lake and load
it into the Metadata Warehouse for further analyses.
The design of the Metadata Warehouse follows the
model proposed in Section 4. Thus, every fact and
dimension depicted in Figure 2 is implemented.
Data consumers, represented in the User Layer
drawn on the right (Figure 3c), can issue differ-
ent types of requests. Three examples of analytical
queries involving the stored metadata and the source
data objects to which they refer are described in Sec-
tion 5.2. Data consumers issue queries using the
Structured Query Language (SQL). The queries are
then executed by the Data Retrieval Layer (Figure 3b)
in a parallel and distributed manner through the use
of SparkSQL (Armbrust et al., 2015). Because of the
characteristics of this interaction, the case study does
not require the instantiation of any data structure from
the Knowledge Mapping Layer.
Finally, since the COVID-19 DataSharing/BR
dataset has its personal and sensitive data already
anonymized, the Data Retrieval Layer (Figure 3b)
does not need to be concerned with ad-hoc data
anonymization. We also consider that data consumers
have all the needed permissions to query the reposi-
tory data, which renders the instantiation of the Data
Publishing Layer unnecessary.
5.2 Analytical Queries
We describe three analytical queries that data con-
sumers can execute on top of the instantiated archi-
tecture outlined in Section 5.1. The motivation be-
hind these queries is to validate the communication
between multiple layers of the proposed architecture.
The validation encompasses the task of integrating
the source data objects stored in the Personal Stor-
age Layer) with their respective metadata stored in the
Metadata Storage layer. We propose different types of
queries, i.e., queries that analyze different aspects in
the decision-making process:
• Query 1. Involves only metadata stored in the
Metadata Warehouse.
• Query 2. Encompasses only source data objects.
• Query 3. Includes both the stored metadata and
the source data objects.
These types of queries are generic and can be ap-
plied to different contexts. We present specific exam-
ples of these queries in our scenario as follows.
Query 1. Analyzing Data Size Grouped by Year,
Month, and Data Provider Type. This type of query
allows data consumers to verify which type of data
provider bestows the majority of the data to the repos-
itory over time. Hence, it can be useful to analyze the
growth of the repository. Since this analysis involves
only the stored metadata, the Data Retrieval Layer
can perform it by executing the following SparkSQL
query against the Metadata Warehouse:
SELECT DIM_DATE.year,
DIM_DATE.month,
DIM_DATAPROVIDER.type,
SUM(FACT.size) AS size
FROM FACT_STORAGE
INNER JOIN DIM_DATE
ON (FACT.sk_date =
DIM_DATE.sk_date)
INNER JOIN DIM_DATAPROVIDER
ON (FACT.sk_dataprovider =
DIM_DATAPROVIDER.sk_dataprovider)
GROUP BY DIM_DATE.year, DIM_DATE.month,
DIM_DATAPROVIDER.type
The results of Query 1 are depicted in Figure 4.
Through the interpretation of the results, data con-
sumers can verify that most of the data in the reposi-
tory has been provided by laboratories in 2020. It is
FAIR Principles and Big Data: A Software Reference Architecture for Open Science
35

also possible to identify that no laboratory has pro-
vided new data in February and April 2021. With this
information, data consumers can work on prospecting
new laboratory data providers, as well as on request-
ing more data from the current ones.
06/2020 04/202102/2021
10
7
10
8
10
9
Month/year
Data size in characters
Hospital
Laboratory
Figure 4: Results of Query 1, which represent data size
grouped by month, year, and data provider type. A loga-
rithmic scale is employed to improve data visualization.
Query 2. Analyzing the Amount of Patients That
Were Tested for Calcium Grouped by Sex using
the Dataset Bestowed by the USP Provider. This
type of query inspects if there is any relationship be-
tween the patient sex and the types of exams per-
formed. Even though this investigation encompasses
only source data objects, the Data Retrieval Layer
must first access the Metadata Warehouse to obtain
the connection information to the Personal Storage
Layer. Once this information is retrieved and used
as a parameter to load the source data objects, data
consumers can run the following SparkSQL query:
SELECT USP_PATIENTS.ic_sex,
COUNT(DISTINCT
USP_PATIENTS.id_patient) AS amount
FROM USP_PATIENTS
INNER JOIN USP_EXAMS
ON (USP_PATIENTS.id_patient =
USP_EXAMS.id_patient)
WHERE USP_EXAMS.de_exam
LIKE ’%CALCIUM%’
GROUP BY USP_PATIENTS.ic_sex
By analyzing the results of Query 2 depicted in
Figure 5, it becomes clear that the majority of pa-
tients tested for calcium in the USP dataset are male.
With this insight, data consumers can perform further
analyses to confirm if there really is a correlation be-
tween the patient sex and the exams performed. For
instance, it is needed to verify the proportion of men
and women in the dataset, as well as if this behavior
remains unchanged in other data providers’ datasets.
Male
61.7%
Female
38.3%
Figure 5: Results of Query 2, which represent the amount of
patients that were tested for calcium grouped by sex using
the dataset bestowed by the USP provider.
Query 3. Analyzing the Five Most Voluminous
Data Sizes of Outcomes Registered in Emergency
Rooms, Grouped by Data Provider and Clinic
Name. Data consumers can use this type of in-
vestigation to generate insights to reveal which data
providers occupy the most repository space with out-
comes registered in emergency rooms. It is also pos-
sible to verify in which of the data providers clin-
ics the data size is bigger. Since this query involves
stored metadata and source data objects, the Data Re-
trieval Layer must access the Metadata Warehouse
twice: first for retrieving the connection information
to the Personal Storage Layer, and then for joining
the source data objects with their respective metadata.
Once the data objects are loaded, the following Spark-
SQL query is executed:
SELECT DIM_DATAPROVIDER.name,
OUTCOMES.clinic,
SUM(FACT.size) AS size
FROM FACT_STORAGE
INNER JOIN DIM_DATAPROVIDER
ON (FACT.sk_dataprovider =
DIM_DATAPROVIDER.sk_dataprovider)
INNER JOIN DIM_DATACELL
ON (FACT.sk_datacell =
DIM_DATACELL.sk_datacell)
INNER JOIN OUTCOMES
ON (OUTCOMES.id_patient =
DIM_DATACELL
.data_instance_unique_source_id_01
AND OUTCOMES.id_consultation =
DIM_DATACELL
.data_instance_unique_source_id_02
AND OUTCOMES.data_object_title =
DIM_DATACELL.data_object_title)
WHERE OUTCOMES.exam_description
LIKE ’%Emergency%’
GROUP BY DIM_DATAPROVIDER.name,
OUTCOMES.clinic
ORDER BY SUM(FACT.size) DESC
LIMIT 5
The results of Query 3 are depicted in Figure 6.
By interpreting these results, data consumers can ob-
tain different insights. For instance, they can observe
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
36

that only clinics belonging to the BPSP and the SL
data providers are displayed in the query results. This
can indicate that, in regards to outcomes registered
in emergency rooms, there is a considerable gap be-
tween the data size of these clinics and those belong-
ing to other data providers. Additionally, data con-
sumers can realize that the significant majority of the
data referring to these outcomes have been registered
by two BPSP clinics: “U.Pa.” and “U.B.M.”. With
this information, it is possible to investigate the rea-
sons behind these outliers. For example, data con-
sumers can verify if these specific clinics store more
details regarding outcomes in emergency rooms when
compared to clinics with smaller data sizes. This in-
formation can be useful to encourage other clinics to
increase the level of detail in their data, enriching fu-
ture analyses that encompass this context.
U.Pa. U.B.M.
C.M.S.V. C.M.
U.Pe.
10
6
10
7
Clinic name
Data size in characters
BPSP
SL
Figure 6: Results of Query 3, which represent the data size
of outcomes registered in emergency rooms, grouped by
data provider and clinic name. A logarithmic scale is em-
ployed to improve data visualization.
6 CONCLUSIONS AND FUTURE
WORK
In this paper, we propose a software reference archi-
tecture to implement data sharing repositories com-
pliant with the FAIR Principles. This architecture
is composed of seven layers: (i) User Layer, repre-
senting data providers and consumers; (ii) Personal
Storage Layer, encompassing the source data objects;
(iii) Metadata Storage Layer, responsible for storing
and maintaining the metadata extracted from the per-
sonal storage layer; (iv) Data Retrieval Layer, re-
sponsible for querying and processing data and meta-
data; (v) Knowledge Mapping Layer, containing as-
sociations between the repository data models and
domain-relevant community standards; (vi) Data In-
sights Layer, aimed to generate different types of
analyses from data and metadata; and (vii) Data Pub-
lishing Layer, representing a single access point for
data consumers to retrieve any type of data, metadata,
or insights from the repository. We detail which layer
fulfills each FAIR Principles requirement.
We also propose a metadata warehouse model that
can be employed by data engineers to guarantee meta-
data persistence, i.e., to guarantee that metadata re-
mains alive even when their corresponding source
data objects no longer exist. This model is generic
and can be adapted in the design of distinct reposito-
ries, according to the data consumers’ requirements.
Finally, we describe a case study that instantiates
the proposed architecture to the context of a real-
world dataset of COVID-19 Brazilian patients, avail-
able in the COVID-19 DataSharing/BR repository.
We detail three different types of queries and high-
light their importance to big data analytics.
We are currently developing guidelines to assist
data engineers in the process of implementing the
proposed architecture. Another future work includes
validating the efficiency of the architecture through
performance tests that investigate several aspects,
such as query response time, scalability, and memory
throughput. New case studies instantiating the pro-
posed architecture to different real-world contexts are
also planned as future work.
ACKNOWLEDGMENTS
This study was financed in part by the Coordenac¸
˜
ao
de Aperfeic¸oamento de Pessoal de N
´
ıvel Superior -
Brasil (CAPES) - Finance Code 001.
REFERENCES
Angelov, S., Grefen, P., and Greefhorst, D. (2012). A frame-
work for analysis and design of software reference ar-
chitectures. Inf Softw Technol, 54(4):417–431.
Armbrust, M., Xin, R. S., Lian, C., Huai, Y., Liu, D.,
Bradley, J. K., Meng, X., Kaftan, T., Franklin, M. J.,
Ghodsi, A., and Zaharia, M. (2015). Spark SQL: Re-
lational data processing in Spark. In Proc. ACM SIG-
MOD, pages 1383–1394.
Bazai, S. U., Jang-Jaccard, J., and Alavizadeh, H. (2021).
Scalable, high-performance, and generalized subtree
data anonymization approach for Apache Spark. Elec-
tronics, 10(5).
Chen, M., Mao, S., and Liu, Y. (2014). Big data: A survey.
Mob Netw Appl, 19(2):171–209.
Couto, J., Borges, O., Ruiz, D., Marczak, S., and Priklad-
nicki, R. (2019). A mapping study about data lakes:
An improved definition and possible architectures. In
Proc. SEKE, pages 453–458.
FAIR Principles and Big Data: A Software Reference Architecture for Open Science
37

Davoudian, A. and Liu, M. (2020). Big data systems: A
software engineering perspective. ACM Comput Surv,
53(5):1–39.
Delgado, J. and Llorente, S. (2021). FAIR aspects of a
genomic information protection and management sys-
tem. In Proc. EFMI STC, pages 50–54.
Devarakonda, R., Prakash, G., Guntupally, K., and Kumar,
J. (2019). Big federal data centers implementing FAIR
data principles: ARM data center example. In Proc.
IEEE Big Data, pages 6033–6036.
Ehrlinger, L. and W
¨
oß, W. (2016). Towards a definition of
knowledge graphs. In Martin, M., Cuquet, M., and
Folmer, E., editors, Proc. Posters and Demos Track of
SEMANTiCS, volume 1695 of CEUR Workshop Pro-
ceedings.
FAPESP (2020). COVID-19 Data Sharing/BR. Available at
https://repositoriodatasharingfapesp.uspdigital.usp.br.
Fernandez, R. C., Pietzuch, P. R., Kreps, J., Narkhede, N.,
Rao, J., Koshy, J., Lin, D., Riccomini, C., and Wang,
G. (2015). Liquid: Unifying nearline and offline big
data integration. In Proc. CIDR.
Kimball, R. and Ross, M. (2011). The data warehouse
toolkit: the complete guide to dimensional modeling.
John Wiley & Sons.
Kreps, J. (2014). Questioning the Lambda architec-
ture. Available at https://www.oreilly.com/radar/
questioning-the-lambda-architecture/.
Lannom, L., Koureas, D., and Hardisty, A. R. (2020). FAIR
data and services in biodiversity science and geo-
science. Data Intell, 2(1-2):122–130.
Le Noac’h, P., Costan, A., and Boug
´
e, L. (2017). A perfor-
mance evaluation of Apache Kafka in support of big
data streaming applications. In Proc. IEEE Big Data,
pages 4803–4806.
Lepenioti, K., Bousdekis, A., Apostolou, D., and Mentzas,
G. (2020). Prescriptive analytics: Literature review
and research challenges. Int J Inf Manage, 50:57–70.
Mart
´
ınez-Prieto, M. A., Cuesta, C. E., Arias, M., and
Fern
´
andez, J. D. (2015). The solid architecture for
real-time management of big semantic data. Future
Gener Comput Syst, 47:62–79.
Medeiros, C. B., Darboux, B. R., S
´
anchez, J. A., Tenka-
nen, H., Meneghetti, M. L., Shinwari, Z. K., Montoya,
J. C., Smith, I., McCray, A. T., and Vermeir, K. (2020).
IAP input into the UNESCO Open Science Recom-
mendation. Available at https://www.interacademies.
org/sites/default/files/2020-07/Open Science 0.pdf.
Nadal, S., Herrero, V., Romero, O., Abell
´
o, A., Franch, X.,
Vansummeren, S., and Valerio, D. (2017). A soft-
ware reference architecture for semantic-aware big
data systems. Inf Softw Technol, 90:75–92.
Nakagawa, E. Y., Antonino, P. O., and Becker, M. (2011).
Reference architecture and product line architecture:
A subtle but critical difference. In Proc. ECSA, pages
207–211.
Pommier, C., Michotey, C., Cornut, G., Roumet, P.,
Duch
ˆ
ene, E., Flores, R., Lebreton, A., Alaux, M., Du-
rand, S., Kimmel, E., et al. (2019). Applying FAIR
principles to plant phenotypic data management in
GnpIS. Plant Phenomics.
Puthal, D., Nepal, S., Ranjan, R., and Chen, J. (2017). A
synchronized shared key generation method for main-
taining end-to-end security of big data streams. In
Proc. HICSS, pages 6011–6020.
Sawadogo, P. and Darmont, J. (2021). On data lake archi-
tectures and metadata management. J Intell Inf Syst,
56(1):97–120.
Shvachko, K., Kuang, H., Radia, S., and Chansler, R.
(2010). The Hadoop distributed file system. In Proc.
IEEE MSST, pages 1–10.
Sinaci, A. A., N
´
u
˜
nez-Benjumea, F. J., Gencturk, M.,
Jauer, M.-L., Deserno, T., Chronaki, C., Cangioli,
G., Cavero-Barca, C., Rodr
´
ıguez-P
´
erez, J. M., P
´
erez-
P
´
erez, M. M., et al. (2020). From raw data to FAIR
data: the fairification workflow for health research.
Methods Inf Med, 59(S1):21–32.
Staab, S., Studer, R., Schnurr, H.-P., and Sure, Y. (2001).
Knowledge processes and ontologies. IEEE Intell
Syst, 16(1):26–34.
Vaisman, A. and Zim
´
anyi, E. (2014). Data warehouse sys-
tems. Springer.
Warren, J. and Marz, N. (2015). Big data: Principles and
best practices of scalable realtime data systems. Si-
mon and Schuster.
Wilkinson, M. D., Dumontier, M., Aalbersberg, I. J., Apple-
ton, G., Axton, M., Baak, A., Blomberg, N., Boiten,
J.-W., Santos, L. B. S., Bourne, P. E., et al. (2016).
The FAIR Guiding Principles for scientific data man-
agement and stewardship. Sci Data, 3(1):1–9.
Zaharia, M., Chowdhury, M., Franklin, M. J., Shenker, S.,
and Stoica, I. (2010). Spark: Cluster computing with
working sets. In Proc. USENIX HotCloud.
ICEIS 2022 - 24th International Conference on Enterprise Information Systems
38
