
Improved Assessment of Offshore Helideck Marking Standards’
Compliance using Optimized Machine Learning Principles in
the U.S. Gulf of Mexico
Mitchell Bosman, Kazim Sekeroglu and Ghassan Alkadi
Department of Computer Science, Southeastern Louisiana University, 500 W University Ave, Hammond, U.S.A.
Keywords: Machine Learning, Helidecks, CAP 437, HSAC RP 161, U.S. Gulf of Mexico, Convolutional Neural Network,
Deep Learning.
Abstract: There is an unknown number of offshore helidecks in the U.S. Gulf of Mexico that comply with a specific
marking standard. This is a direct result from the lack of national regulations enforced. The purpose of this
research is to improve the assessment of offshore helideck marking standards’ compliance using optimized
machine learning principles. Using two different phases and employing the transfer learning approach, an
optimized machine learning algorithm is generated to classify offshore helidecks from photographs into CAP
437, HSAC RP 161 or None. Results show that this model can identify marking standards being used with an
accuracy of 95.7 percent. Therefore, demonstrating that the machine learning principles used can improve the
assessment of offshore helideck marking standards’ compliance.
1 INTRODUCTION
Across the world, energy industry workers must be
transported to offshore facilities. Originally, this
transportation was performed by ship, yet this
presented issues such as individuals getting seasick,
hazardous transition from the ship to the facility, and
wearisome travel times. Now, with the use of
helicopters, these legacy issues have been mitigated.
Helicopter travel decreases passenger illness, eases
transition from the helicopter to the facility, and
significantly reduces travel time compared to travel
by ship. Due to these benefits, helicopters have been
used since 1947 to perform tasks like offshore
transportation of personnel, cargo, and parts. To
execute offshore helicopter operations, a safe landing
area should be guaranteed on these offshore facilities,
referred to as helidecks (HSAC ~ Helicopter Safety
Advisory Conference - Home, 2016).
A helideck is defined as “a heliport located on a
fixed or floating offshore facility such as an
exploration and/or production unit used for the
exploitation of oil and gas” (International Civil
Aviation Organization, 2018).
Many offshore facilities, and their helidecks, were
built prior to the introduction of any applicable design
standard. Therefore, the underlying design
parameters and associated safety aspects for these
facilities remain unknown. In the past two decades,
design standards and guidance material have been
developed and became more readily available;
however, compliance with these standards or
guidelines for newly built helidecks, as well as the
gaps in compliance with those previously built
(legacy) helidecks remain an industry concern. This
results in a plethora of issues that offshore helicopter
pilots must face when attempting to safely land a
helicopter on a helideck. For example, the lack of,
incorrect, or ambiguous markings force the pilots to
adapt and draw their own conclusions as to whether it
is safe to land or not during the final stages of landing.
To clarify the various interpretations of these
markings, standardization of helideck markings is
crucial to improve landing safety.
It takes time for a helideck to be inspected and
verify compliance with applicable standards or
industry guidelines. A trained and competent helideck
inspector will need to be transported to the facility by
helicopter, leading to significant additional costs.
These costs also include travel labor costs of the
inspector, offshore room, and board for the inspector,
as well as the potential disruption of the daily
activities at the facility due to the inspection of the
helideck. With the vast number of active helidecks in
234
Bosman, M., Sekeroglu, K. and Alkadi, G.
Improved Assessment of Offshore Helideck Marking Standards’ Compliance using Optimized Machine Learning Principles in the U.S. Gulf of Mexico.
DOI: 10.5220/0011108800003209
In Proceedings of the 2nd International Conference on Image Processing and Vision Engineering (IMPROVE 2022), pages 234-241
ISBN: 978-989-758-563-0; ISSN: 2795-4943
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

the U.S. Gulf of Mexico, this presents an immense
challenge. It will take considerable sum of money and
resources to inspect and subsequently improve
marking standards’ compliance for all helidecks in
the U.S. Gulf of Mexico.
1.1 Helidecks in the U.S. Gulf of
Mexico
Oversight of platform structures is being handled by
the Bureau of Safety and Environmental Enforcement
(BSEE) and the U.S. Coast Guard (USCG), where
floating facilities and vessels are under the USCG, the
fixed-leg facilities on the U.S. Continental Shelf in
the Gulf of Mexico are overseen by BSEE. BSEE has
a database that maintains the number and details of
active and non-active offshore facilities in the U.S
Gulf of Mexico, excluding vessels. The number of
offshore facilities that are currently active can be
derived from this BSEE database. Using the available
dataset as of 1/23/2021, a pivot table can be created
to identify those facilities that may potentially be non-
compliant and in need of inspection to assess if they
need to be re-marked to become compliant with
current available guidelines. The resulting pivot table
shows that there are 1311 facilities that need to be
assessed and might be candidates for re-marking.
1.2 Helideck Design
Offshore helideck safety starts with a safe design. In
this section, the available standards and guidance
material regarding design will be introduced. Design
criteria include the application of markings as visual
cues to help the helicopter pilot interpret safety
related information.
Currently, there are three prevailing guidance
documents available for use in offshore helideck
design. These three documents are the International
Civil Aviation Organization (ICAO) Doc 9261 Part 1
- Heliport Manual (International Civil Aviation
Organization, 2018), United Kingdom Civil Aviation
Authority (UK CAA) Publication 437 Standards for
offshore helicopter landing areas (CAP 437), and The
Code for the Construction and Equipment of Mobile
Offshore Drilling Units, 2009 (2009 MODU Code
(International Maritime Organization, 2010)).
ICAO Doc 9261 Part 1 is approved by and
published under the authority of the Secretary
General of the United Nations. Within ICAO, the 191
Member States and several global aviation
organizations work together to develop international
Standards and Recommended Practices (SARPs).
These SARPs are the references countries utilize to
develop their national civil aviation regulations,
which then become enforceable. This is an important
aspect: ICAO SARPs are not legally binding by
themselves. Instead, they form the basis of national
regulations which have legal status. As such, ICAO
Document 9261 provides global guidance regarding
the design of offshore helicopter landing areas,
including helidecks, and should be used by civil
aviation authorities to develop their own regulations.
CAP 437 is a similar standard created by the UK
CAA and is a mandatory standard for all the helidecks
under their regulatory oversight. CAP 437 has been
applied in the North Sea since 1981 and has since
undergone several amendments. “CAP 437 presents
the criteria required by the CAA in assessing the
standards of offshore helicopter landing areas for
world-wide use by helicopters registered in the UK”
(International Civil Aviation Organization, 2018) . As
international vessels and drill ships with helidecks
move around the globe, several of those vessels have
been in the operating region of the U.S. Gulf of
Mexico. As a result, this document has started to
influence helideck design guidelines for other
platforms and installations in the U.S. Gulf of
Mexico. In addition, the CAP 437 design guidelines
are considered an equivalent design standard to the
design requirements mentioned in the U.S. Code of
Federal Regulations for Helideck design by the
USCG (Hawkins, 2015).
The 2009 MODU Code is a document that
addresses requirements for drilling ships and vessels;
it does provide a section regarding helideck design
guidelines. It facilitates their international movement
and operation, plus it ensures a level of safety for such
units and for personnel on board. However, as the
MODU code only focuses on ships and vessels, and
not all platform facilities, it is outside of the scope of
this thesis, so this concludes the introduction and use
of the 2009 MODU Code.
Due to the limited number of design criteria
specifications in the United States Code of Federal
Regulations, the energy industry in the U.S. Gulf of
Mexico started developing their own guidance
material in the form of Recommended Practices
(RPs). In 1978, the Helicopter Safety Advisory
Conference (HSAC) was created as a conference
composed of over 115 members. This conference
creates RPs for the industry in the U.S. Gulf of
Mexico. In 2008, they started their process of
developing RPs for helideck markings. The RPs were
influenced by CAP 437, but not fully identical in
every aspect of the document, such as the system of
measurement (imperial units versus metric). HSAC
decided to combine relevant elements of onshore
Improved Assessment of Offshore Helideck Marking Standards’ Compliance using Optimized Machine Learning Principles in the U.S. Gulf
of Mexico
235

helideck markings from the Federal Aviation
Authority (FAA) Advisory Circulars and from CAP
437. They merged these elements, along with their
own innovative ideas, into RP 2008-1 Offshore
Helideck Markings in the U.S. Gulf of Mexico. Since
2008, an additional document, RP 2013-1 regarding
Helideck Parking Area Markings was developed, and
ultimately all helideck marking guidance was
absorbed into the HSAC RP 160-series of helideck
design guidance between 2016 and 2019.
For a pilot to safely land on the intended helideck,
the pilot needs to be able to correctly identify the
helideck, know the size and weight capacity of the
helideck he is going to land on, and any obstacles he
needs to avoid (Bosman, 2021).
To ensure that the pilot safely lands on the
helideck of the intended platform, the identification
marking on the helideck must be recognizable.
Guidance material depicts this identification marking
as white lettering in a specific location of the
helideck. In HSAC RP 161 (Helicopter Safety
Advisory Conference, 2021) and CAP 437
(International Civil Aviation Organization, 2018), the
identification marking locations are identical. Both
identification markings are white, and while minor
differences in size of font may occur, overall, these
documents provide similar guidance for pilot
recognition.
Secondly, the pilot needs to be able to verify the
weight limitations and size of the helideck. A
helideck is designed for a specific model helicopter,
which is the largest helicopter type the helideck is
intended to serve. This design helicopter determines
the maximum weight and size of the helideck. Once
designed for this largest envisioned helicopter to be
operating to the helideck, the helideck can safely
accept that helicopter type and all smaller and lighter
helicopter types. The weight capacity is therefore
capped to the maximum allowable take-of mass
(MTOM) of the design helicopter, which is available
in the rotorcraft flight manual of the design
helicopter. The helideck size is determined by the D-
value of the design helicopter. The d-value is defined
as “The largest overall dimension of the helicopter
when rotor(s) are turning, measured from the most
forward position of the main rotor-tip-path plane to
the most rearward position of the tail rotor-tip-path
plane or rearward extension of the helicopter
structure” (Helicopter Safety Advisory Conference,
2021). The markings for weight and size between
HSAC RP 161 and CAP 437 differ due to separate
units of measurements used. CAP 437 documentation
and marking standards are fully based on the metric
system, whereas HSAC RP 161 is based on the
imperial system while also providing some metric
system options. CAP 437 (International Civil
Aviation Organization, 2018) displays weight
markings in metric tons in one specific location on the
helideck. Size limitations are displayed on the
helideck perimeter line using the applicable D-values.
HSAC RP 161 (Helicopter Safety Advisory
Conference, 2021) displays the D-value in a location
marked inside of the bottom three-tiered box outlined
in red preceded by the letter “D”.
Finally, the pilot needs to be aware of any
obstacles that might surround a helideck. Obstacle
related markings are divided into three individual
sectors: a 210 degree Obstacle Free Sector (OFS), a
150 degree Limited Obstacle Sector (LOS) and a “No
Nose” sector. The OFS is “An area free of all
obstacles above helideck level outwards to a distance
that will allow for an unobstructed arrival and
departure path to/from the helideck for the
helicopter(s) it is intended to serve” (Helicopter
Safety Advisory Conference, 2021).The opposite side
of the chevron marking is the LOS. As opposed to the
OFS where n obstacles are allowed, the LOS allows
some obstacles to be present, as long as they remain
smaller in size than the preset profile. Obstacles in the
colored areas shall remain below the associated
height profile for the helideck to be considered
compliant, providing a safe operating area for
helicopters. If an object protrudes from the labeled
sections, the helideck is not considered safe to land.
The “No Nose” sector is a sector where the location
of the helicopter’s nose is not allowed to go over to
avoid the tail rotor to strike any obstacle or prevent
the tail rotor to be maneuvered over a helideck access
point.
According to Table 1 (Composed from the BSEE
database) there are 1194 facilities that were built
before 2008. Resulting in 91.1 percent of the
facilities in the U.S. Gulf of Mexico with the
potential of being non-compliant to HSAC RP
helideck marking guidelines. Additionally, the U.S.
Coast Guard did not approve CAP 437 for use within
the U.S. Gulf of Mexico until 2015 (Hawkins,
2015). Cross referencing the BSEE database to filter
out the number of facilities before 2015
demonstrates that 98.8 percent of helidecks in the
U.S. Gulf of Mexico might not follow the CAP 437
guidance materials.
Seeing as a staggering 98.8 percent of helidecks
have not yet been verified as compliant with marking
standards and therefore cannot be positively
confirmed to be safe for landing, it is imperative that
arrangements are made to further ensure offshore
helideck operations safety. With the use of an image
IMPROVE 2022 - 2nd International Conference on Image Processing and Vision Engineering
236

Table 1: Percentage of helidecks in the Gulf of Mexico.
Number of
Helidecks
Percentage of all
Helidecks in
U.S. Gulf of
Mexico
1311 100.0%
Helidecks
before 2015
1295 98.8%
Helidecks
before 2008
1194 91.1%
classification program, this issue of quickly verifying
if helideck markings are applied using an available
and acceptable standard can be easily resolved with
much less hassle and cost.
2 METHODS
2.1 Marking Standard Comparison
To properly identify helidecks and categorize them
accordingly, a comparison needs be made between
HSAC RP 161 and CAP 437. Both helidecks are
painted green, have a yellow circle (Touch
Down/Positioning Marking), an identification name,
the letter ‘H’, and a chevron in a relative location of
the ‘H’. HSAC RP 161 helidecks have a distinguished
three-tiered red box to display the size, dimensions,
and weight specifications of the helideck, where CAP
437 helideck size markings are located within the
perimeter line and the weight marking is identified in
the top left corner. These are the key elements that the
machine learning algorithm needs to be able to
identify to distinguish between HSAC RP 161 and
CAP 437 helidecks. Moreover, a third option will be
added for the algorithm to use if the helideck is not
able to be classified as either HSAC RP or CAP 437,
it will be categorized as None. The third option is the
most important option in this regard, as it will show
which helidecks are non-compliant to either marking
standard or will therefore have to be re-marked using
one of the acceptable standards.
2.2 Assessment of Helidecks Utilizing
Deep Convolutional Neural
Networks
The main goal for the proposed convolutional neural
network model is to identify if the helideck is
compliant or not based on an image. Since there are
limited options in obtaining photographs of offshore
helidecks, the use of the guidance material can aid in
creating self-developed (artificial) compliant
imagery. This will demonstrate to the convolutional
neural network how each helideck is supposed to look
when following the HSAC RP 161 guidance material,
the CAP 437 material, or None at all. Secondly, a
convolutional neural network model with initial
parameters is needed to provide a base and from there
build an optimized model. While the parameters will
change within the convolutional neural network
through training, certain parameters such as kernel
size, pooling size, and the size of the fully connected
layer must be set manually. Based on the results of
the initial configuration of the model, the accuracy
might not be acceptable, therefore layers might need
to be added, removed, or modified to adjust the model
and increase the desired accuracy.
Convolutional neural networks are like traditional
neural networks in that they are both able to optimize
their weights by learning. They also end the same way
by receiving the outputs of earlier nodes and use loss
functions to classify the object (O’Shea & Nash,
2015). Where traditional neural networks and
convolutional neural networks differ is that in
traditional neural networks, the data is composed of
text or numbers, such as a database, whereas
convolutional neural networks perform their
operations based on imagery and find information
within images to recognize patterns.
The proposed framework can be explained using
the diagram in Figure 1 below. For each block in the
process, a brief explanation is available to explain
each specific process and the associated activities that
were performed. The process will run in two different
phases: phase one being composed of images that
were self-developed (artificial) using the guidance
materials, and phase two being composed of
photographs from offshore facilities in the U.S. Gulf
of Mexico. One key difference is the Image Pre-
Processing stage, as it is not performed in phase one,
while in phase two, each photograph will need to be
pre-processed before entering the convolutional
neural network.
Figure 1: Flowchart of methodology.
Improved Assessment of Offshore Helideck Marking Standards’ Compliance using Optimized Machine Learning Principles in the U.S. Gulf
of Mexico
237

2.3 Phase One – Developing the Model
using Artificial Images
Using the guidance material, eight individual
helideck marking images were made for each
document, 8 using HSAC RP 161 and 8 using CAP
437, resulting in 16 distinct images for the machine
learning process. These images include helidecks that
are round, rectangular, and octagonal. Based on these
16 images, the category None was created manually
by copying the images and using a photo editor to
change colors and remove key elements. This process
resulted in a folder with 23 individual images and
were categorized as HSAC, CAP 437 or None.
Before being able to create a dataset, the model
will need to distinguish individual images from each
other. To achieve this, each image has been verified
and classified manually and the filename reflects the
classification of the image. The filenames will either
start with a prefix CAP 437, HSAC, or None.
In Convolutional Neural Networks, more
available data provides better overall results. The
number of 23 images currently available is not
enough to properly train a convolutional neural
network. Data augmentation was used to
automatically generate more images for the network
to use during learning. The data augmentation
consisted of taking a single image and altering
saturation, brightness, or rotation to generate
additional images that have different properties.
Tensorflow has an ImageDataGenerator function that
can adjust the mentioned property values and save the
newly generated image to a different location (Abadi,
et al., 2015). Additionally, this function can perform
functions such as flipping the image orientation,
shifting horizontally and vertically, adjusting zoom
levels to make it appear closer or further away, and
shearing the image to make the helideck appear
angled (Abadi, et al., 2015). The augmented image
was sheared, mirrored horizontally, zoomed out, and
has an increased brightness. Repeating this step for
each image 100 times will result in over 4,343 images
as a dataset for the neural network learning.
Just as important as the algorithm itself, the
environment used to train the algorithm needs to be
taken into consideration. While the model can be
exported and be reused in other hardware, the training
process requires a more robust setting. For this
training process a desktop computer with a ZOTAC
GeForce® GTX 1070 Ti Mini graphics card was used
to train the model.
The graphics card aids in accelerating the neural
network training process by using the Tensorflow
library. This library will use the CUDA cores to allow
parallel processing (Abadi, et al., 2015). The software
used in this process was Microsoft Visual Studio
Code with the Python extension provided by
Microsoft. Libraries within Python 3.8.7 mainly
consist of Tensorflow 2.4.1 and keras 2.4.3, while
sklearn was used for metrics (Pedregosa, et al., 2011).
A base convolutional neural network model is
first created to start the process of finding an
optimized model. The base model is manually
constructed to increase productivity and a gradient
descent optimizer is selected. Based on the resulting
graphs of accuracy and loss, manual modifications
are made to add and adjust layers and create a model
that demonstrates the desired learning curve, as well
as a desired loss function curve.
This initial model will also define the compiler
used for future fine-tuning, and will be chosen
between SGD, AdaDelta, RMSprop, and Adam. The
chosen optimizer will be based on the graphs
generated after each training session and by the
performance of the model.
During the training, the model will be modified
until it has a validation accuracy above 90 percent
This number was chosen as this program is meant to
be an aid to the pilot, so in case it does misidentify,
the pilot will still be able to personally verify the
helideck. In this process, the computer uses a loop to
modify the number of convolutions per layer and the
number of nodes per dense layers to find a model that
has an accuracy above 90 percent.
The accuracy of the predictions is dependent on
the training and testing data. There are no universal
rules regarding the identification of proper ratios
between training and testing data to obtain a certain
percentage in accuracy. Also, as the size of the
training data increases, the accuracy of the model will
likewise increase (Medar, Rajpurohit, & Rashmi,
2017). Focusing on the model, rather than the number
of images it is training and testing on, will give the
program the chance to obtain accuracies of 90 percent
or higher. The training and testing ratio will be set at
75 percent training and 25 percent testing. Using this
ratio, the model will have enough images to learn and
adapt to the ratio to get accuracies above 90 percent.
In case the optimization process is not able to obtain
90 percent, the training and testing ratio will be
modified and then the process will have to be
restarted to find the proper model.
2.4 Phase Two - Developing the Model
using Real Images
Phase two of the process is similar to phase one,
except that instead of self-developed images actual
IMPROVE 2022 - 2nd International Conference on Image Processing and Vision Engineering
238

photographs are used. The photographs need to be
pre-processed before entering the neural network.
Additionally, the previously optimized model in
phase one is now being used as the initial model to
start phase 2. In other words, the model used in phase
2 benefits from the transfer learning approach. Most
of the photographs obtained had a broad range of
resolutions. Some images were as large as 4252 by
2838 pixels compared to other images which were as
small as 640 by 480 pixels in resolution. In addition,
some images included the entire facility and not just
the helideck. Therefore, some images needed to be
resized and cropped to focus on the helideck in order
to be usable in the convolutional neural network. The
image preparation was performed through a process
of segmentation, in which certain features are filtered
out of the image depending on the users’
specifications.
The similarities in HSAC RP 161 and CAP 437
work in the favor of segmentation in such a way that
the computer can focus on the helideck being green
to find it in the image. For this process to work, each
image is converted into a three-dimensional array,
this is done because each image is composed of
values for red, green, and blue, and range from zero
to 255. Unfortunately, there is a drawback, as each
pixel in an image has a green value to create its color.
This results in it being more difficult for the computer
to find the green helideck. To remedy this, hue,
saturation, and value (also known as intensity) are
used to give more control over which green to look
for. Applying a range of green values, contrast values,
and intensity values, the computer can filter the image
based on the range provided. This is also known as
thresholding.
Within python, using the OpenCV (commonly
called cv2) library, the use of masks can help segment
the helideck from the rest of the image (Bradski,
2000). To develop this mask, a custom tool was
created to find the ranges of hue, saturation, and
intensity of the green helideck. The tool provides a
graphical interface where color (HSV) values can be
adjusted at will, filtering the color of the resulting
image. Once the values are identified, they can then
be used in the findContours function built into the cv2
library. This function will locate a rectangle around
the helideck and create the image that will later be
used in the neural network (Bradski, 2000).
Moreover, a total of 56 photographs of helidecks
or offshore platforms with helidecks were collected,
and these underwent the same data augmentation
process as mentioned under phase one to generate
additional photographs for the dataset. The same
parameters for data augmentation were used as in
phase one. This resulted in 4,873 photographs that the
neural network can use.
3 RESULTS
3.1 Results of Phase One
The initial model starts off with a single 200-by-200
pixel image. This image was then convoluted with 32
filters in the convolutional layer. Following this, the
ReLU activation layer was used to remove the
negative values that may appear and adjust them to
zero. After activation, a dropout rate of 50 percent
was applied; meaning that out of the 32 nodes, 16
were randomly selected to be passed onto the next
layer. The next layer is the fully connected layer, in
which the 16 nodes are then condensed into one single
vector. At the end of the network, the dense layer will
further narrow the results down to three choices. The
softmax activation layer will then use these three
choices to return a probability vector.
Using this model, different optimization
algorithms were used to find the optimum. Adam and
RMSProp show the most potential. Adam, however,
showed a more stable curve, and was therefore chosen
to be used for the rest of the development. Using the
Adam compiler and step five of the methodology, a
more complex network was created. This model was
able to reach an accuracy of 98.1 percent. Both the
confusion matrix and classification report are shown
below in Table 2 and Table 3. These show the model
tends to classify some helidecks that were None as
HSAC RP 161 helidecks. As seen in Figure 2, the
model was able to learn the data at a steady rate, and
both accuracy and loss remained close together
throughout the entire training process.
Table 2: Confusion matrix of final theoretical model.
Precision Recall
F1-
score
Support
CAP 437 0.98 0.97 0.98 427
HSAC 0.99 0.95 0.97 603
None 0.91 0.98 0.95 189
Table 3: Classification report of the final theoretical model.
Actual
CAP 437 HSAC None
Predicted
CAP 437 200 0 2
HSAC 0 183 14
None 0 4 683
Improved Assessment of Offshore Helideck Marking Standards’ Compliance using Optimized Machine Learning Principles in the U.S. Gulf
of Mexico
239
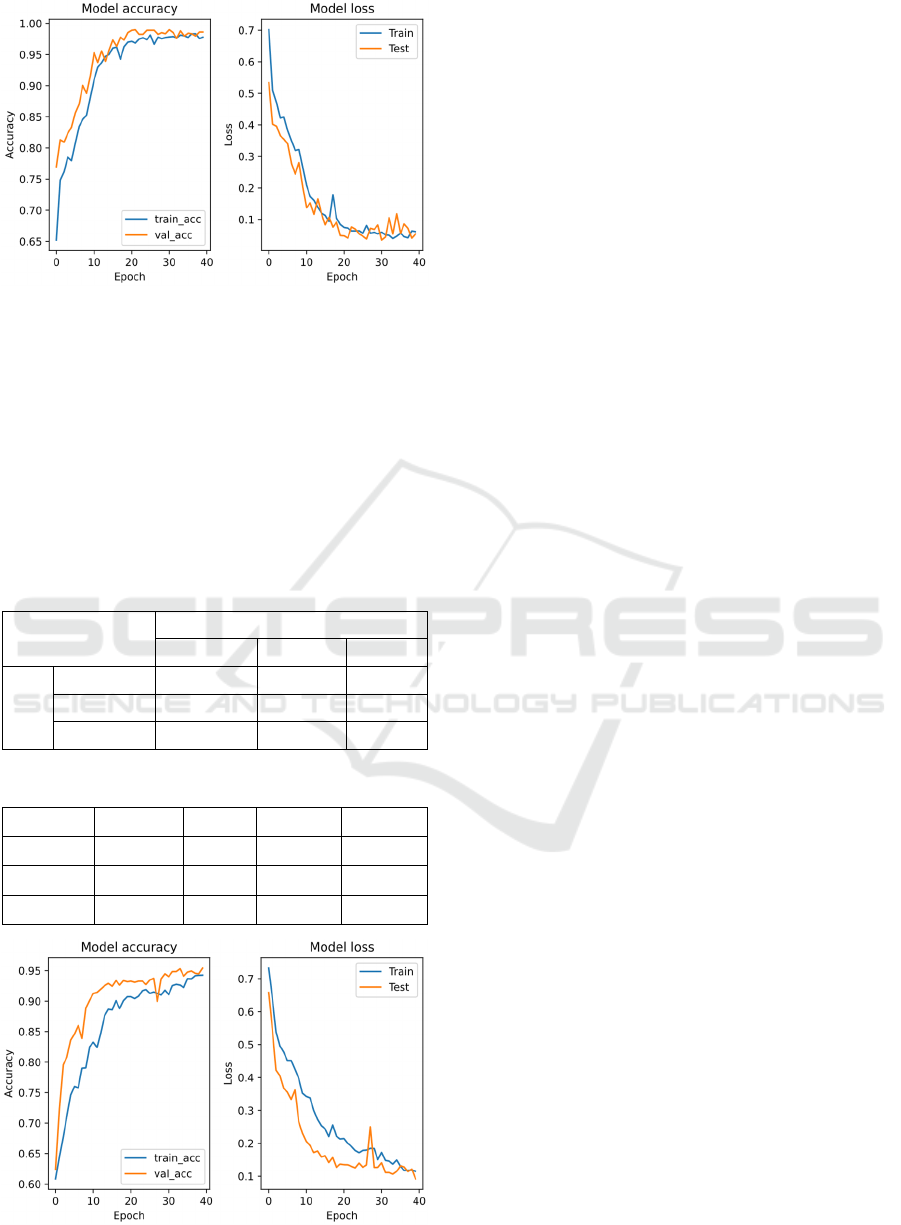
Figure 2: Accuracy and loss of the phase one model.
3.2 Results of Phase Two
In phase two, images are cropped and resized to the
resolution of 200 by 200 pixels in the pre-processing
stage. The same model and compiler from the
previous phase were used for this phase as well, with
the model being re-trained using the pre-processed
photographs rather than the manually created images
used in phase one. The model was able to train up to
Table 4: Confusion matrix from phase two model.
Actual
CAP437 HSAC None
Predicted
CAP437 407 7 13
HSAC 16 551 36
None 4 1 184
Table 5: Classification report from phase two model.
Precision Recall F1-score Support
CAP 437 1.00 1.00 1.00 202
HSAC 0.98 0.94 0.96 197
None 0.98 1.00 0.99 687
Figure 3: Accuracy and Loss curves of phase two model.
an accuracy of 95.7 percent. This is lower than phase
one, but it is to be expected due to the noise presented
in the photographs. The same confusion matrix,
classification report and performance graphs were
generated to evaluate the model and are shown in
Table 4 and Table 5 as well as Figure 3.
4 DISCUSSION
4.1 Conclusions
According to the literature review, the standardization
of offshore helideck marking is an important aspect
for the safety of offshore helicopter occupants. With
standardized markings in place, the pilot will be able
to identify the correct helideck, know its weight and
size limitations, and be able to find obstacle sector
markings crucial for landing safely such as the OFS,
LOS, and “No Nose” sectors. To ensure that
acceptable marking standards are complied with,
assessments of each individual offshore helideck
must be completed. Unfortunately, to do this requires
many resources due to the number of applicable
helidecks, manpower needed to perform the
inspections, and costs associated with offshore travel
for the inspectors and their hourly rate as subject
matter experts. In-person assessment of individual
helidecks will also require many years to complete.
Using machine learning, this task can be accelerated
and simplified with the use of convolutional neural
networks, where images are used to classify a
helideck into three different categories of helideck
marking standards: HSAC RP 161, CAP 437, or
None. These standards depict safety related markings
in specific locations on a helideck where the pilots
can obtain information quickly. Images were
generated based on the marking requirements in
HSAC RP 161, CAP 437, and None, and photographs
were pre-processed to focus on the helideck rather
than the entire platform.
Using the literature review results, and the
flowchart depicting the methodology, two models
were created in separate phases. Phase one to classify
manually constructed images, and phase two to
classify actual helideck photographs using the
transfer learning approach. The objective of each
phase was to create a theoretical model that had an
accuracy above 90 percent. The first phase resulted in
a model classification success rate of 98.1 percent,
while phase two had a success rate only slightly
decreased at 95.7 percent. These results show that
optimized machine learning principles can be used to
improve the assessment of compliance of offshore
IMPROVE 2022 - 2nd International Conference on Image Processing and Vision Engineering
240

helideck marking standards in the U.S. Gulf of
Mexico.
4.2 Future Work
There is potential in this model to possibly be
integrated into a helicopter, where a camera and
artificial intelligence can assist the pilot in identifying
hazards, obstacles, and destination information in
real-time. This model can also be adjusted to possibly
include other marking standards or recommended
practices, thereby furthering its reach to outside of the
U.S. Gulf of Mexico.
This model could provide a base understanding to
add additional features such as obstacle detection
around the helidecks to improve safety even more or
initiate another research to use infrared and/or radar
imagery in real time to augment pilot vision and
situational awareness.
Moreover, this model is not limited by the
offshore applications. It can also be used for onshore
applications such as hospital and rooftop heliports.
REFERENCES
Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z.,
Citro, C., . . . Zheng, X. (2015). TensorFlow: Large-
Scale Machine Learning on Heterogeneous Systems}.
Retrieved from https://www.tensorflow.org/
Bosman, P. (2021, February 10). Helicopter Safety. (M.
Bosman, Interviewer)
Bradski, G. (2000). The OpenCV Library. Dr. Dobb's
Journal of Software Tools.
Hawkins, B. J. (2015, September 3). Acceptance of CAP
437, Standards for offshore helicopter landing areas.
CG-ENG Policy Letter No. 03-15. Washington, District
of Columbia, United States of America: U.S. Coast
Guard, U.S. Department of Homeland Security.
Retrieved from https://www.dco.uscg.mil/Portals/9/
DCO%20Documents/5p/5ps/Design%20and%20Engi
neering%20Standards/docs/CG-ENG%20PolicyLetter
%2003-15.pdf
Helicopter Safety Advisory Conference. (2021). HSAC RP
161 (Second Edition ed.). Helicopter Safety Advisory
Conference.
HSAC ~ Helicopter Safety Advisory Conference - Home.
(2016). Retrieved from HSAC ~ Helicopter Safety
Advisory Conference: http://www.hsac.org/
International Civil Aviation Organization. (2018). Heliport
Manual. Montréal: International Civil Aviation
Organization.
International Maritime Organization. (2010). 2009 MODU
code: code for the construction and equipment of
mobile offshore drilling units. London: International
Maritime Organization.
Medar, R., Rajpurohit, V. S., & Rashmi, B. (2017). Impact
of Training and Testing Data Splits on Accuracy of
Time Series Forecasting in Machine Learning. 2017
International Conference on Computing, Communica-
tion, Control and Automation (ICCUBEA), 1-6.
O’Shea, K., & Nash, R. (2015). An Introduction to
Convolutional Neural Networks. eprint
arXiv:1511.08458, 10.
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V.,
Thirion, B., Grisel, O., Duchesnay, É. (2011). Scikit-
learn: Machine Learning in Python. Journal of Machine
Learning Research, 12, 2825-2830.
Improved Assessment of Offshore Helideck Marking Standards’ Compliance using Optimized Machine Learning Principles in the U.S. Gulf
of Mexico
241
