
Statistical and Requirement Analysis for an IDM Tool for Emergency
Department Simulation
Juan David Mogollon
1
, Virginie Goepp
2
, Oscar Avila
1
and Roland de Guio
2
1
Department of Systems and Computing Engineering, School of Engineering, Universidad de los Andes, Bogota, Colombia
2
I-Cube, INSA Strasbourg, France
Keywords: Input Data Management, IDM, Discrete Event Simulation, Emergency Department, Health Information
System.
Abstract: Emergency Departments (ED) are spaces prone to congestion due to the high number of patients. This problem,
known as overcrowding, has negative effect on patient waiting time. In order to find a solution, analysis of
the flow of patients through Discrete Event Simulation (DES) is a relevant approach that models the operation
of a system through a sequence of events. This technique relies on high-quality input data which needs to be
previously managed in a complete process known as Input Data Management (IDM). The objective of this
research is to present our progress in the development of a software application to efficiently automate the
IDM process required for DES of ED. Preliminary findings and results presented in this paper include the
problem definition, the evaluation of required statistical methods, and the gathering of specific requirements
from a case study with real data. Based on these results, this paper describes the initial architecture of a
software application that satisfies the identified requirements.
1 INTRODUCTION
One of the main problems in Emergency Departments
(ED) is over-crowding, which is according to Duguay
and Chetouane (2007), “the situation in which ED
function is impeded primarily because of the
excessive number of patients waiting to be seen,
undergoing assessment and treatment, or waiting for
departure comparing to the physical or staffing
capacity of the ED”. Overcrowding is thus recognized
as a global problem, which has reached crisis
proportions in some countries. It has direct
implications in the well-being of patients and staff,
mainly due to waiting times derived from process
deficiencies, the inappropriate placement of physical
and human resources, and budget restrictions. In
addition, it can affect institution’s financial
performance and reputation (Komashie & Mousavi,
2005).
One of the strategies to mitigate the adverse
effects of overcrowding is using Discrete Event
Simulation (DES) to provide analytical methods to
assess and redesign processes, and support data-
driven decision-making. DES modeling has become
an efficient strategy for solving real-world problems,
it provides a conceptual framework that describes
evolving stochastic dynamic systems used to test
hypotheses and forecast expected behavior. There is
a broad range of applications of DES in Healthcare,
Manufacturing, System Operations, Logistics, and
more (Rodriguez, 2015a). DES models, in ED
context, aim to reproduce the flow of patients and
their relationship with the different areas, personal,
and resources available to solve specific problems.
The success of DES applications depends on the
prior preparation of high-quality input data. Some of
the event data required in DES are represented in
probability distributions. The parameters describing
the underlying distributions are a key input for the
simulation. The process that involves transforming
raw data into a quality-assured representation of all
parameters appropriate for simulation is known as
Input Data Management (IDM) (Skoogh et al., 2008).
Input data preparation is one of the most crucial
and time-consuming tasks in a DES project
(Robertson & Perera, 2002). According to (Skoogh et
al., 2012) the input data management process
consumes about 10-40% of the total time of a DES
project. In most cases, practitioners transform
manually raw data from different sources into
appropriate simulation input (Robertson & Perera,
2002) and separately from the software used for the
Mogollon, J., Goepp, V., Avila, O. and de Guio, R.
Statistical and Requirement Analysis for an IDM Tool for Emergency Department Simulation.
DOI: 10.5220/0011286300003266
In Proceedings of the 17th International Conference on Software Technologies (ICSOFT 2022), pages 197-204
ISBN: 978-989-758-588-3; ISSN: 2184-2833
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
197

simulation. The automation of the data preparation
phase has the potential to increase efficiency in DES
projects, by integrating data resources (Skoogh et al.,
2012).
While reviewing the literature, we did not find any
commercial tool for IDM automation and identified
only three open-source tools allowing such
procedure, namely, GMD-Tool (Skoogh et al., 2010),
DESI (Rodriguez, 2015b), and KE Tool (Barlas &
Heavey, 2016). Some of the main lacks we found
when reviewing them include the fact that these tools
do not offer features for sharing data and results,
limiting the opportunities for collaboration by
allowing other researchers to replicate the process to
obtain similar outputs. Moreover, the reviewed tools
do not have features for managing projects and
generating data quality reports. Although these have
features for fitting some statistical distributions, they
do not fit all the possibilities that can be used for ED
operation simulation, such as, Markov chains
modeling and do not have features for evaluating
distribution properties. In addition, in the research
works presenting them there are no information
related to their utility for handling large datasets or
running in tensive workloads and only examples with
small volumes of data on personal computers are
presented.
To identify potential current challenges in the data
preprocessing tasks in the case of a DES project
studying ED crowding, a case study analyzing a
sample of the patient flow data of the ED at the
Hautepierre Hospital located in the city of Strasbourg,
France, was carried out. The case study has two main
objectives: first, to identify the statistical methods to
generate the required inputs in a simulation of the
patient pathway within an ED. Second, to determine
the preparation and validation requirements to
guarantee data quality. As a result, the case study
reveals limitations regarding the automation of the
required processing.
In this context, the research problem addressed by
our research is: how to automate the IDM process for
DES models to address the overcrowding problem in
ED? To deal with this question, this article presents
our progress towards an open-source cloud-based
web application for IDM.
The article is organized as follows: section 2
presents related work in the domain. Section 3
presents the IDM requirements and evaluation of
required statistical methods from the analysis of the
case study. Section 4 introduces the IDM solution’s
architecture. Finally, section 5 presents conclusions
and recommendations for future work.
2 RELATED WORK
2.1 Simulation of ED Operation
Patient flow in an ED can be analyzed through both
analytical and simulation methods. Analytical
methods are often insufficient at dealing with
complex systems such as emergency rooms, while
simulation models are more appropriate to capture
and optimize the performance of these (Ghanes et al.,
2014).
The most common methods for simulating ED
operations include dynamic systems (Robertson &
Perera, 2002), experimental design (Kuo et al., 2012),
survival analysis (Levin & Garifullin, 2015),
stochastic process (Ghafouri et al., 2019), linear
programming (Furian et al., 2018; Ghanes et al.,
2014). Such approaches cover a wide range of
applications that can fit in the following categories:
resource allocation, process-related optimization, and
environment-related analysis. The usual procedures
for conducting a simulation study may vary according
to the nature of the study. However, there are typical
stages: problem formulation, setting study objectives,
developing a conceptual model, data collection,
model building, model validation, and verifications
(Al-Aomar et., 2015). Our approach can be
considered as the automation of processing tasks after
data collection and before building the simulation
model.
Regarding the construction of the conceptual
model to analyze overcrowding problems, it is
necessary to know in advance the configuration of
each ED, which depends on the needs, staff,
capacities, and areas of the health institution. The
possible areas described in studies such as (Ghanes et
al., 2014; Komashie & Mousavi, 2005; Kuo et al.,
2012; Levin & Garifullin, 2015, Mohammad et al.,
2019; Armel et al., 2003) include waiting room for
walk-in patient arrival, the registration and sorting
zone, shock room or resuscitation room, assessment
areas (physician, paediatricians), examination rooms
(X-rays, CT SCAN, echocardiography, blood- test),
among others. The staff usually refers to physicians,
nurses, doctors, specialists, residents, practitioners,
medical students, consultants, registrars, engineers,
and administrative staff.
The data source plays an essential role in
obtaining data on the main studied operation
variables, i.e., arrival patterns, time spent on different
activities by care providers, inter-arrival times and
length of stay (LOS) distributions (Ghanes et al.,
2014; Vanbrabant et al., 2019). Data obtained about
inter-arrival times and service times, volume and mix
ICSOFT 2022 - 17th International Conference on Software Technologies
198

of patients staffing levels, types and duration of
treatment are used to determine model inputs and
outputs. Once the data is collected, it is exploited to
calculate processing times, statistical distributions,
routing probabilities, among others.
The validity and credibility of the data models are
evaluated using different approaches, the first of
which is the evaluation by experts and senior
management, secondly the sensitivity analysis,
thirdly the emulation of the models, and finally, by
considering the source of external variability. In most
cases, historic consistent data of the process such as
triage category, arrival date and time, and time-stamp
records of the triage start time, consultation start time,
and departure time of each patient are used to test
hypotheses and to evaluate scenarios about staffing
levels and schedules (Ghanes et al., 2014).
2.2 IDM
Skoogh and Johanson (2008), defined Input Data
Management (IDM) as "the entire process of
preparing quality assured, and simulation adapted,
representations of all relevant input data parameters
for simulation models. This includes identifying
relevant input parameters, collecting all information
required to represent the parameters as appropriate
simulation input, converting raw data to a quality
assured representation, and documenting data for
future reference and re-use”. Data collection has
multiple inherent difficulties (Bokrantz et al., 2018).
Organizations can have multiple data sources and
systems to collect the data from. Second, accuracy,
reliability, and validity are the analyst’s responsibility
when extracting and preparing the data for the
simulation; those procedures, in most cases, are made
manually, which makes it prone to errors. In a survey
presented in (Robertson & Perera, 2001), it was
inquired about the most frequent issues in simulation
projects, considering data collection issues: 60% of
respondents indicated they manually input the data to
the model; 40% reported they use connectors to an
external system like spreadsheets, text files or
databases. In summary, as described in (Furian et al.,
2018), the main challenges in this process are, in the
first place, manual data collection and data entry,
which increases the likelihood of data entry errors
arising from human manipulation of data. The
inherent difficulties of the manual process
compromise the quality and integrity of the data. In
addition, multiple manual files handling to maintain
and process data makes it difficult to track errors and
reproduce procedures.
3 STATISTICAL TOOLS AND
REQUERIMENTS
This section focuses on analyzing the IDM tasks
enabling to prepare statistical representations of the
patient flow data of the ED of the Hautepierre
Hospital in Strasbourg (France). In addition, we
evaluate IDM tools that could be used for the
analysis.
3.1 Emergency Department
Description
We figure out the main steps of the patient flow by
several, complementary means (see Figure 1). First,
we observe the ED functioning during half a day.
Second, we organize several workshops with three
doctors of the ED (one senior doctor in charge of the
ED and two junior doctors) in order to model the flow
in the form of a BPMN private process model. During
these two-hour workshops, we iteratively model and
validate the patient flow with them. In this diagram,
the patient flow is represented linearly as patients
perform each of the activities consecutively.
However, it is worth mentioning that there are
iterations between the stages, as patients may require
a procedure to be repeated or an exam to be performed
multiple times. In addition, patients may undergo
many different paths and do not necessarily goes
through all the steps of the process. The number and
types of diagnosis tests (Blood analysis, RX or CT
scan) depend on the consultation and are not known
as the outset, that is why we model the pathway using
routing probabilities.
The data used in the case study were provided in
comma-separated values (CSV) files extracted from
the ED databases. The files contained anonymized
records of patients and the events during their stay in
the ED. The collected data contains records from June
22nd, 2020, to June 28th, 2020, of the ED flow of 795
patients. The records include information on the
following events of the patient flow: arrival, triage,
blood analysis (BA) (Coagulation, Hematology,
Biochemistry), Computer tomography (CT) Scan,
and X-rays (RX). The average throughput time is 5,52
patients/h. The ED uses a severity index for the
assignment of degrees of emergency to decide the
priority and the order of procedures. According to
each severity level, the patients are assigned to one of
three zones in the ED.
Statistical and Requirement Analysis for an IDM Tool for Emergency Department Simulation
199
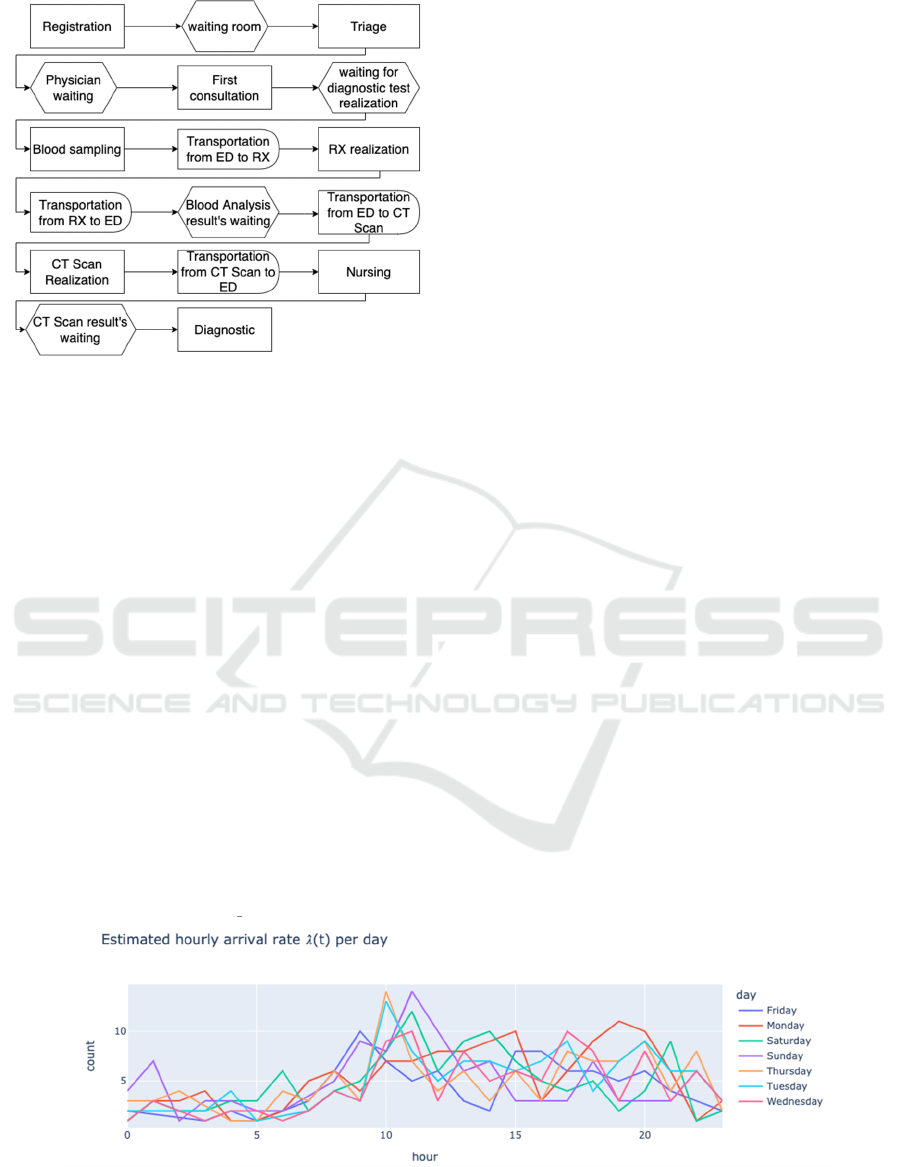
Figure 1: ED general process flow.
The data processing tasks were carried out by
following the next activities: consolidating data
sources, normalizing tables in which patients are in
the rows as many times as events in the ED, verifying
column names, verifying variable types, validating
activity date formats, creating new variables from
existing ones such as the duration of each stage of the
process, generating flags for patients.
3.2 Statistical Analysis
3.2.1 Analysis Description
Different types of metrics are required to simulate an
ED, which can be grouped into three categories:
Arrival Patterns, Routing Probabilities, and
Processing Times (Ghanes et al., 2014). In the
following sections we carry out the necessary
transformations with the data collected and identify
the statistical methods to calculate them.
Arrival Patterns. The arrival patterns refer to the
measurements made to the patients at the time of
entering the emergency room. The metric used in this
case is the arrival rate per hour/day.
For the modeling we consider 𝑁𝑡 the number of
patients arriving at the emergency room at a particular
time 𝑡. It is assumed that patients arrive randomly and
independently. In that case, it is possible to model the
patient count as a Poisson process of parameter 𝜆.
However, when considering the temporal dependence
of the counts, it can be considered as a Non-
Homogeneous Poisson process with rate 𝜆𝑡. For the
estimation it is assumed that the rate is piecewise
constant on a set of time independent intervals. Given
that 𝑁𝑡 is a Poisson process with rate 𝜆𝑡 the
distribution of the interarrival time follows an
exponential distribution of parameter 𝜆𝑡.
Routing Probabilities. For the estimation of routing
probabilities, we consider the sequence of events
observed in the data as a Markov Process in which
each state represents one event in the process, such as
triage, or blood test, among others. The transition
probabilities associated with the Markov Chain are in
consequence, the routing probabilities. For the
verification of this model, the following hypothesis
tests on the properties of the chain are considered:
Markov property, order, and stationarity of the
transition probabilities, and sample size (Anderson &
Goodman, 1957).
Processing Times. In the case, three elements can be
distinguished in the processing times. The waiting
times from the prescription of the exams to the
moment they are performed, the time it takes to
complete the exam and the additional waiting time to
get the results.
Once the data were adequately arranged, we
iterate over a set of continuous distributions to
identify the one with the best fit for each variable. To
test the goodness of fit, we used the Kolmogorov-
Smirnoff test in which the null hypothesis evaluates
that the data follow some specific distribution.
Figure 2: Estimate hourly arrival rate.
ICSOFT 2022 - 17th International Conference on Software Technologies
200
3.2.2 Analysis Results
Arrival Patterns. Firstly, the non-homogeneous
Poisson process was estimated and the parameter 𝜆
was determined for all the one-hour intervals. Figure
2 shows the behavior of the parameter for all the days
of the week, which can be evidenced by the bands of
greater congestion and the peaks of patient arrivals
during the day. The x-axis indicates the hours of the
day, and the y-axis is the number of patients.
The curves represent the behavior of the intensity
parameter for each day of the week. From these
arrival patterns it is possible to construct the
distribution of arrivals and inter-arrivals per hour,
following the deduction mentioned above.
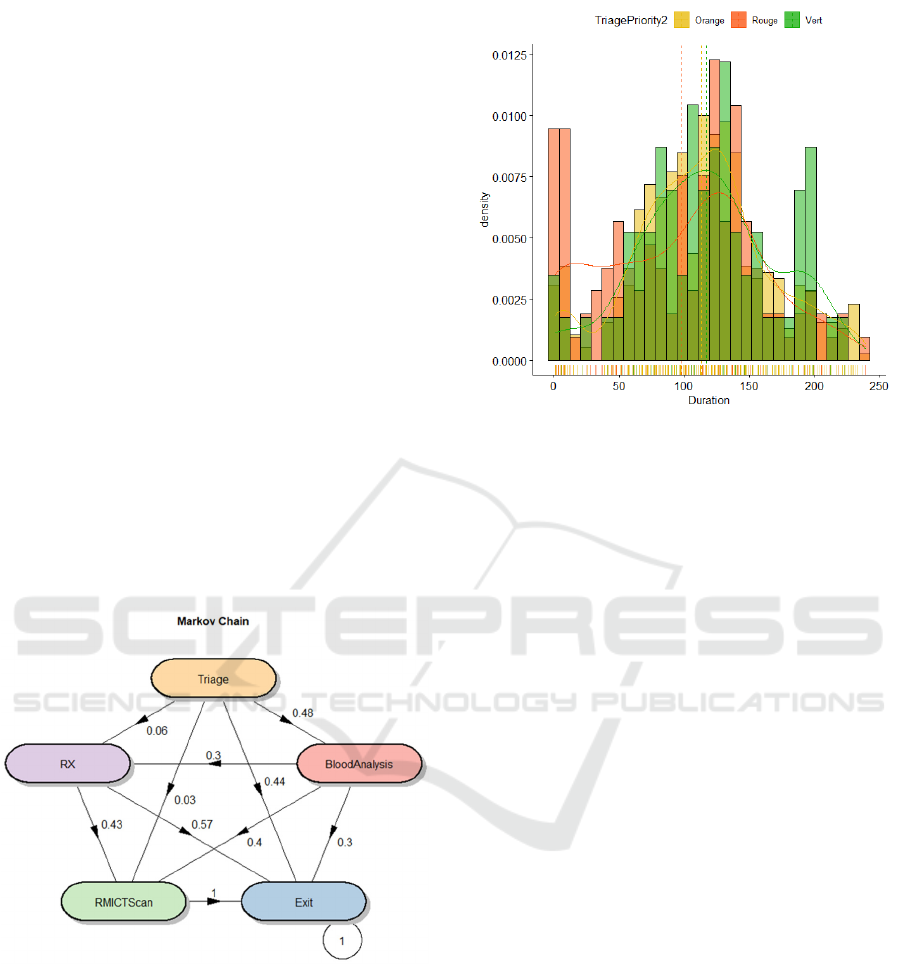
Routing Probabilities. The chain states are
represented as the nodes of the Figure 3, which
describes the transition matrix that indicates the
probability of moving from one state to another. We
can see that after triage, for example, the probability
that a patient undergoes a blood test is 0.48, while not
going through any stage is 0.44. Patients do not
usually go directly from Triage to RX or MRI CT
Scan; generally, to obtain these tests, a blood test is
performed beforehand, where 70% are referred to one
of these two tests.
Figure 3: General routing probabilities.
Processing Time. After triage, the subsequent most
frequent examination is a blood test. The collected
samples are used for three evaluations, Biochemistry,
Hematology, and Coagulation. For the Biochemistry
blood analysis, we consider the distinction by severity
index, and plot the histogram and the fitted
distributions as seen in Figure 4.
Figure 4: Biochemistry BT duration.
3.3 Requirements
From the manual process and interviews with the medical
staff beforementioned as well as from interviews with two
researchers in DES, we gathered the following
requirements in terms of user stories:
• User Accounts: As a user, I want to register, login,
change and recover my password into the app.
• Manage Projects: As an admin user, I want to
create, edit, search, and delete projects into the
app so I can manage resources
• Invite User: As an admin user, I want to invite
users into the app so I can see grant access to
projects
• Manage Input Data: As a user, I want to manage
my datasets so I can analyse it on the platform.
Acceptance criteria: Upload resource, encrypt
and version files.
• Check Data Quality: As a user, I want to check
the quality of my dataset so I can make sure my
dataset is appropriate for simulation. Acceptance
criteria: Perform data quality checks, generate
Data quality reports.
• Process Data: As a practitioner user, I want to
process my input data and obtain statistical
representations of my variables in a compatible
format for simulation software. Acceptance
criteria: Display variables, fit distribution, display
results, export results.
• Software Architecture: As a user, I want to
process my data from a website to access my data
and results anytime from the internet. Acceptance
criteria: software and cloud architecture.
Statistical and Requirement Analysis for an IDM Tool for Emergency Department Simulation
201

• Reproducibility: As a user, I want to replicate the
analysis and results of my projects so I can make
research is reproducible. Acceptance criteria:
Public repository, cloud available, share data,
share results. Download dataset: As a practitioner
user, I want to download my data for using it
outside the app
•
Display dashboard: As a practitioner user, I want
a dashboard so I can quickly gain insights into the
most important aspects of my data.
3.4 Existing IDM Tools
The analysis of existing IDM tools is made through
criteria extracted from the requirements identified
before. We identified only three tools: GMD-TOOL
DESI (Skoogh et al., 2010), KE tool (Barlas et al.
2016) and DESI (Rodriguez, 2015b). The specific gap
between the tools’ characteristics and the
requirements are presented as follows:
Manage Input Data: All the tools have data loading
features, GMD-Tool (Skoogh et al., 2010), and DESI
(Rodriguez, 2015b), have features for data collection
and use a database for storage. None of the tools has
encryption, and versioning features.
Check Data Quality: The comparison of the tools in
this criterion showed that only KE Tool (Barlas &
Heavey, 2016) has methods for evaluating the input
data. None of the tools has features to generate reports
on the quality of the input data.
Process Data: it was found that all the tools have
features for exporting data, displaying results, and
adjusting statistical distributions. GMD-Tool
(Skoogh et al., 2010), and DESI (Rodriguez, 2015b)
have an user interface. KE Tool (Barlas & Heavey,
2016) and DESI (Rodriguez, 2015b) show graphs of
the obtained distributions. Although the KE Tool
(Barlas & Heavey, 2016) does not have a user
interface, it is possible to generate graphs from the
code in the development environment. None of the
tools adjust specific distributions such as Markov
Chain or evaluate the hypothesis of the properties of
the chains.
Software Architecture: KE Tool (Barlas & Heavey,
2016) is the only one that presents diagrams referring
to the architecture and implements unit testing to the
code. None of the tools introduces a complete
solution architecture or uses cloud-based
architectures, mainly because they are desktop
applications.
Reproducibility: KE Tool (Barlas & Heavey, 2016),
is available in a public repository. However, none of
the tools is available in the cloud, and they do not
have features for sharing data and results obtained.
User Accounts, Manage Projects and Invite User:
None of the tools has functional features for
managing users and projects or invite users.
4 PRELIMINARY
ARCHITECTURE
We present our preliminary solution architecture (see
Figure 5) to provide a top-level view of a software’s
structure representing the principal design and
understanding of the problem. The mapping between
requirements elicited and described before and the
architecture’s areas and components is presented in
Table 1.
Figure 5: Software architecture.
The main sections of the architecture are described
as follows.
Input Data Management: it relates to the input data
management requirement described before and
includes the following components. Data
management: The system should provide a mean to
ingest high volumes of data, persist it and store it
securely. Data quality: The system must outline data
quality issues and provide visualizations and reports
to the user. Data processing: The system must process
all the data according to the user configuration and
apply convenient transformation for analytical
purposes.
ICSOFT 2022 - 17th International Conference on Software Technologies
202

Table 1: Mapping of requirements and architecture’s areas
and components.
Area Component Requirements
Input Data
Management
Data
Management
Manage Input Data
Data Processing Process Data
Data Quality Check Data Quality
Analytics Dashboard Display Dashboard
Statistical
Analysis
Process Data
Data
Visualization
Process Data
Reports Export Download Dataset,
Check Data Quality
and Process Data
Generate Data Download Dataset
Project Project
Management
Manage projects
Version Control Manage Input Data
Authorization User accounts
Share & Search Invite User and
Search Project
Analytics: Dashboard: Dashboards allow the user to
quickly gain insights into the critical metrics and
i n f o r m a t i o n r e l e v a n t t o h i m . I t a l s o p r o v i d e s m e a n s
for identifying potential issues that require imminent
action.
Statistical analysis: It provides summary statistics of
variables, fits statistical distributions, estimates
parameters, and test goodness of fit hypothesis. Data
visualization: Visualization techniques provide to the
user a clear representation of information to get quick
data insights.
Reports: Export report: It enables the user to have a
portable version of the results of the data quality
inspection, data processing, and the statistical
analysis in html format. Generate data: The platform
has to provide the user a mechanism to generate
synthetic data that mimic the system’s original data
according to the statistical distributions of the
processes.
Project
: Project management: Projects allow the
user to organize and centralize the resources, and
arrange data, analysis, and reports. Version
control: it keeps track of versions of the projects
and
their resources in an organized manner.
Authorization: it allows the
administrator to manage
roles and permissions over the project’s context. It
provides a good way to secure files. Share and
search:
Provide mechanisms for indexing and
cataloging data sources and
analysis objects in order
to facilitate the searching and sharing of files.
Information:
Users: A database dedicated to
centralizing user’s data, roles, and authorizations.
Projects data: A dedicated database for project data
management. Processing: All the data are allocated
in memory during the processing. File storage:
The
excepted contents of the system are the original data
sources,
transformed data, metadata, parameters,
results, reports, and syn thetic data.
5 CONCLUSIONS
This paper deals with IDM for DES projects in the
context of ED overcrowding. To deal with this issue
we exploit the real case of the ED of HautePierre
Hospital in Strasbourg, France as an experimentation
field. From this case, we carried out a statistical
analysis of the patient flow and then a requirement
analysis to develop a IDM automation tool. The
exercise allowed us to analyse this specific IDM
process to evidence the needs raised when managing
the input data manually without using specialized
tools for evaluating data quality, data pre-processing,
making statistical analysis and the generation outputs
for simulation.
As a result of the experimentation, it was possible
to identify some limitations, among which it is worth
mentioning the importance of providing rules to
validate the data and assess the quality before
processing. The validations that need to be done on
the data include the revision of variable's names,
expected data types, ranges of the variables, presence
of null and atypical values, among others. An
alternative identified from this process is to perform
unit tests on the data, to identify possible errors, and
avoid unnecessary processing and erroneous
estimations. Moreover, the patient flow events were
exported from different data sources and were
provided in separate files, which required an
additional effort to consolidate them. Hence the first
requirement defined is to standardize input file to
minimize the time needed for consolidation.
Regarding the statistical analysis, there is a couple
of considerations. First, it is important to mention the
need to sample enough patient records for several
days in order to get a good representation of the
process. Second, the number of records considered
will impact the statistical methods used for the
goodness-of-fit hypothesis tests and the estimation of
the transition matrix since these estimates are
adequate for certain sample sizes. In the case of
Statistical and Requirement Analysis for an IDM Tool for Emergency Department Simulation
203

estimating the transition probabilities, it is expected
that the file contains enough records of the flow of
patients so that the transition probabilities can be
estimated from the frequencies observed on the event
sequences.
From this experimentation we defined the basic
requirements for an automated IDM solution for DES
model of EDs. Such requirements include managing
the input data, verifying the quality of the data,
processing and presenting process statistics in
dashboards. The preliminary solution consists of an
architecture that includes a set of functional
automation areas that satisfies these requirements.
As future work, we need to detail the architecture
and carry out further developments. To do so, early
indications are that the best solution would be to take
a microservices approach and to adopt a cloud
infrastructure instead of on-premises infrastructure
by considering three characteristics of the former
model: manageability, scalability, and cost.
REFERENCES
Al-Aomar, R., Williams, E. J., & Ulgen, O. M. (2015).
Process simulation using witness. John Wiley & Sons.
Anderson, T. W., & Goodman, L. A. (1957). Statistical
inference about Markov chains. The annals of
mathematical statistics, 89-110.
Armel, W. S., Samaha, S., & Starks, D. W. (2003). The use
of simulation to reduce the length of stay in an
emergency department. In Proceedings of the 2003
Winter Simulation Conference. New Orleans,
Louisiana, USA.
Barlas, P., & Heavey, C. (2016). KE tool: an open source
software for automated input data in discrete event
simulation projects. In 2016 Winter Simulation
Conference (WSC) (pp. 472-483). IEEE.
Bokrantz, J., Skoogh, A., Lämkull, D., Hanna, A., & Perera,
T. (2018). Data quality problems in discrete event
simulation of manufacturing operations. Simulation,
94(11), 1009-1025.
Duguay, C., & Chetouane, F. (2007). Modeling and
improving emergency department systems using
discrete event simulation. Simulation, 83(4), 311-320.
Furian, N., Neubacher, D., O’Sullivan, M., Walker, C., &
Pizzera, C. (2018). GEDMod–Towards a generic
toolkit for emergency department modeling. Simulation
Modelling Practice and Theory, 87, 239-273.
Ghafouri, S. M. M. S., & Haji, B. (2019). Utilizing a
simulation approach for analysis of patient flow in the
emergency department: A case study. In 2019 15th Iran
International Industrial Engineering Conference
(IIIEC) (pp. 151-157). IEEE.
Ghanes, K., Jouini, O., Jemai, Z., Wargon, M., Hellmann,
R., Thomas, V., & Koole, G. (2014). A comprehensive
simulation modeling of an emergency department: A
case study for simulation optimization of staffing
levels. In Proceedings of the Winter Simulation
Conference 2014 (pp. 1421-1432). IEEE.
Komashie, A., & Mousavi, A. (2005). Modeling emergency
departments using discrete event simulation techniques.
In Proceedings of the Winter Simulation Conference,
2005. (pp. 5-pp). IEEE.
Kuo, Y. H., Leung, J. M., & Graham, C. A. (2012).
Simulation with data scarcity: developing a simulation
model of a hospital emergency department. In
Proceedings of the 2012 winter simulation conference
(WSC) (pp. 1-12). IEEE.
Levin, S., & Garifullin, M. (2015). Simulating wait time in
healthcare: accounting for transition process variability
using survival analyses. In 2015 Winter Simulation
Conference (WSC) (pp. 1252-1260). IEEE.
Robertson, N. H., & Perera, T. (2001). Feasibility for
automatic data collection. In Proceeding of the 2001
Winter Simulation Conference (Cat. No. 01CH37304)
(Vol. 2, pp. 984-990). IEEE.
Robertson, N., & Perera, T. (2002). Automated data
collection for simulation?. Simulation Practice and
Theory, 9(6-8), 349-364.
Rodriguez, C. (2015a). An Integrated Framework for
Automated Data Collection and Processing for Discrete
Event Simulation Models. Electronic Theses and
Dissertations. 719.
Rodriguez, C. (2015b). Evaluation of the DESI interface
for discrete event simulation input data management
automation. International Journal of Modelling and
Simulation, 35(1), 14-19.
Skoogh, A., & Johansson, B. (2008). A methodology for
input data management in discrete event simulation
projects. In 2008 Winter Simulation Conference (pp.
1727-1735). IEEE.
Skoogh, A., Michaloski, J., & Bengtsson, N. (2010).
Towards continuously updated simulation models:
combining automated raw data collection and
automated data processing. In Proceedings of the 2010
Winter Simulation Conference (pp. 1678-1689). IEEE.
Skoogh, A., Johansson, B., & Stahre, J. (2012). Automated
input data management: evaluation of a concept for
reduced time consumption in discrete event simulation.
Simulation, 88(11), 1279-1293.
Vanbrabant, L., Braekers, K., Ramaekers, K., & Van
Nieuwenhuyse, I. (2019). Simulation of emergency
department operations: A comprehensive review of
KPIs and operational improvements. Computers &
Industrial Engineering, 131, 356-381.
ICSOFT 2022 - 17th International Conference on Software Technologies
204
