
World State-dependent Action Graph: A Representation of Action
Possibility and Its Variations in Real Space based on World State
Yosuke Kawasaki
1 a
and Masaki Takahashi
2 b
1
Graduate School of Science and Technology, Keio University, 3-14-1 Hiyoshi, Kohoku-ku, Yokohama 223-8522, Japan
2
Department of System Design Engineering, Keio University, 3-14-1 Hiyoshi, Kohoku-ku, Yokohama 223-8522, Japan
Keywords:
Service Robot, Environmental Representation, Action Possibility.
Abstract:
For intelligent systems, it is important to understand the action possibility for agent in real space. As the
action possibility varies with the subsystem configuration of the agent and its states, the possibilities should be
understood based on the world state comprising the agent’s state as well as the environmental state. However,
most conventional methods consider only the environmental state. Therefore, this study proposes a world state-
dependent action graph based on knowledge representation using scene graphs which allows the capturing of
the action possibility of agents, which implies the feasible actions and their positions in real space, and their
recursive variations depending on the world state. Moreover, the effectiveness of the proposed method was
verified with simulations, assuming a coffee shop environment.
1 INTRODUCTION
The feasible actions for intelligent systems such as
robots and other agents such as humans or robots in
real space are required to be understood. In particular,
understanding the feasible actions facilitates various
kinds of reasoning, such as planning, understanding
instructions from humans, and behavior prediction.
The feasible actions for the agent depend on the
environment state such as the objects and scenes in
the environment. Also, the feasible actions for the
agent depend on the subsystem configuration of the
agent and their states. For instance, if an agent’s grip-
per is grasping an object, the gripper cannot feasibly
grasp onto other objects. In summary, the feasible ac-
tions for the agent depend on the world state, i.e., the
states of both agent and environment. On the contrary,
the world state varies with the actions executed by the
agent. Thus, the action of the agent alters the world
state, which consequently modify the agent’s feasible
actions. To understand the feasible action including
its variations, the mutual interaction between the fea-
sible action according to the world state and the action
executions involving the varying world state.
Conventionally, several methods of affordance
estimation have been proposed for associating ac-
a
https://orcid.org/0000-0002-3076-3258
b
https://orcid.org/0000-0001-8138-041X
tions to objects and scenes in an environment, such
as the image segmentation method based on affor-
dance(Do et al., 2018; Chu et al., 2019). Then, the
mutual interaction between the feasible actions and
the action executions are represented by using con-
ventional symbolic representations such as STRIPS
and PDDL(Fikes and Nilsson, 1971; Fox and Long,
2003). However, existing studies do not focus on un-
derstanding the feasible actions in real space, and it
can be actually difficult for the agent to execute asso-
ciated actions.
As an approach for understanding the action
possibility, which implies the feasible actions and
their positions in real space, certain methods have
been proposed to map the feasible actions into real
space. One such method constitutes the action
graph(Kawasaki et al., 2021), which is an environ-
mental representation method pivoted on the feasible
actions in real space. In this graph, the edges indicate
actions and the nodes denote the executable locations
of the actions to represent the connections between
actions. Specifically, the multilayered graph structure
of the action graph enables the representation of vari-
ations in action possibility. However, the action graph
handles not the agent’s state but the configuration of
the subsystem. In addition, only once change of the
action possibility is taken into account, making it dif-
ficult to represent the mutual interaction between the
action possibility and the action.
Kawasaki, Y. and Takahashi, M.
World State-dependent Action Graph: A Representation of Action Possibility and Its Variations in Real Space based on World State.
DOI: 10.5220/0011298000003271
In Proceedings of the 19th International Conference on Informatics in Control, Automation and Robotics (ICINCO 2022), pages 459-466
ISBN: 978-989-758-585-2; ISSN: 2184-2809
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
459

By extending the action graph, this study aims to
understand the action possibility and its variations in
real space based on the world state. The requirements
for constructing an action graph considering the world
state are stated as follows: 1) Construction of a frame-
work for symbolic reasoning to understand the feasi-
ble actions and its effects on the world state. 2) Rep-
resentation of mutual interaction between the action
possibility and action execution involving the varia-
tions in the world state.
Therefore, to fulfill the objective, we propose a
world state-depended action graph (WDAG) based on
knowledge representation with scene graphs. In par-
ticular, the scene graph is an environmental represen-
tation that is compatible with the world state and con-
tains both geometric and semantic information. For
this reason, we adopted the scene graph to repre-
sent knowledge about action, specifically the precon-
ditions for actions and the changes in the world state
caused by the action. Additionally, the WDAG repre-
sents the mutual interaction between the action possi-
bility and the action in a recursive multilayered graph
structure.
2 RELATED WORK
Our work is related to the study of understanding fea-
sible actions.
As an approach to understanding feasible actions,
segmentation of images based on object affordance
has been proposed (Do et al., 2018; Chu et al., 2019).
The AffordanceNet is a deep learning approach that
assigns affordance to each pixel of the object in real-
time (Do et al., 2018). In addition, T. L
¨
uddecke et
al. proposed a method to rate the action plausibili-
ties in accordance to the object set present in the im-
age (L
¨
uddecke and W
¨
org
¨
otterr, 2020). In the research
field of predicting human activity, the consideration of
the agent’s state can improve the performance of the
prediction (Koppula and Saxena, 2016; Liang et al.,
2019). Thus, ATCRF is proposed to obtain a distri-
bution for predicting human activities based on their
posture and the surrounding environment (Koppula
and Saxena, 2016). Nonetheless, these studies do not
consider the possibility of action in real space.
Thus, methods have been proposed to map the ac-
tion possibility onto real space for understanding the
action possibility in real space(Ziaeetabar et al., 2017;
Rhinehart and Kitani, 2016). In particular, the mul-
tilayer environmental affordance map is proposed to
represent the traversability into the grid map follow-
ing the arrangement and affordance of the object set in
the environment (Ziaeetabar et al., 2017). Moreover,
an action map is proposed, wherein the actions other
than the movement are mapped in real space (Rhine-
hart and Kitani, 2016). However, these methods do
not consider the variations in action possibility occur-
ring as a consequence of performing the action. The
most relevant study pertains to the action graph, repre-
senting the action possibility and its variations in real
space (Kawasaki et al., 2021). We propose an action
graph based on the agent’s state, which is not typically
considered, to capture the feasible actions depending
on the world state in the real world.
3 WORLD STATE-DEPENDENT
ACTION GRAPH
3.1 Overview
WDAG G
a
is an environmental representation that de-
picts an agent’s action possibility in a world state W
along with its variations.
The world state W =
{
o|o ∈ R oro ∈ O
}
can be
described as a set of N
o
objects comprising the robot
state R and environment state O. The object o details
the following information:
• l
o
: Label of the object
• p
o
: Position of the object in a two-dimensional
absolute coordinate system
• θ
o
: Direction of the object in a two-dimensional
absolute coordinate system
• s
o
: Shape data of the object comprising geometric
primitives such as square or circle and size.
The objects in the robot state R =
o|p
o
= p
R
are
whose position p
o
is p
R
, e.g., a manipulator, speaker,
or an object grasped by the manipulator, where p
R
denotes a parameter reflecting the robot’s position for
convenience. Conversely, the elements of the envi-
ronmental state E =
o|p
o
6= p
R
include the objects
o with their position p
o
indicated as not p
R
but as a
three-dimensional coordinate in real space.
More importantly, the WDAG G
a
defines a pair of
sets G
a
= (N
a
, E
a
), where N
a
and E
a
denote the set
of nodes and edges. The nodes, n
a
, represent the po-
sitions in which the robot can perform actions in real
space. Furthermore, the actions a are assigned to the
edges e, and a transition between the nodes implies
the performance of the set action a.
The WDAG G
a
comprises multiple action possi-
bility graphs G
a
1∼N
W
. In particular, the action possi-
bility graph G
a
i
describes feasible actions for the agent
as well as the positions corresponding to the perfor-
mance of the actions based on the world state W
i
. In
ICINCO 2022 - 19th International Conference on Informatics in Control, Automation and Robotics
460
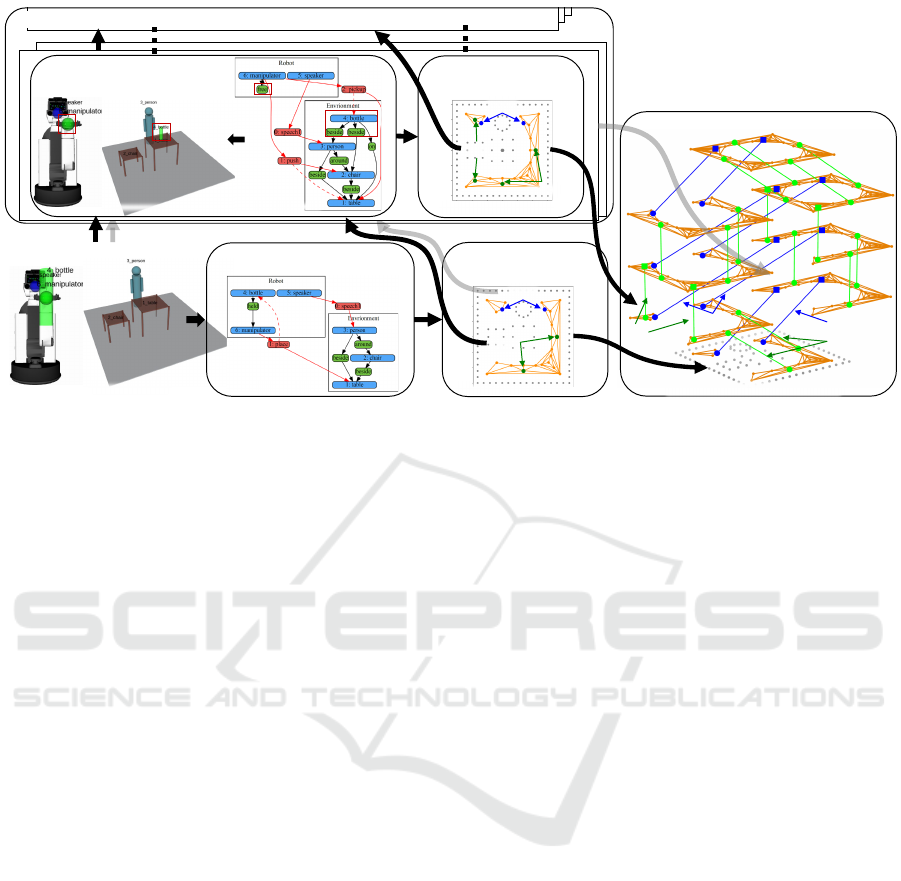
3. Action possibility graph
construction
speech
place
4(a). Update world state
1. Scene graph construction
2. Action association
4(c) World state-dependent action graph
construction
Action possibility graph
construction
Action
World state, Scene graph
speech
pickup
push
4(b). Recursive construction of action possibility graph
Initial world state
place
speech
push
speech
0
W
0
a
G
Action possibility graph
1
a
G
Action possibility graph
0
s
G
Scene graph
Worl d state
1
W
Scene graph
1
s
G
1~
W
a
N
G
World state-dependent action graph
a
G
Figure 1: Pipeline diagram of WDAG construction.
the action possibility graph, the edges represent ac-
tions excluding the transition of the world state, such
as the movement action in real space. On the other
hand, the feasible action involving the state transi-
tion of the world is denoted by the edges connecting a
prior action possibility graph G
a
i
with a posterior one
G
a
j
to the state transition.
Thus, a symbolic inference associating the actions
to the world state is required for constructing the ac-
tion graph. Therefore, we construct a scene graph that
includes both the symbolic and geometric informa-
tion from the world state and incorporates them into
the inference. The scene graph G
s
defines a pair of
sets G
s
= (N
s
, E
s
), where N
s
and E
s
denote the set
of nodes and edges, respectively. The objects o in
the world state W correspond to the nodes in the G
s
.
Furthermore, the edges reflect the spatial relation be-
tween the objects.
The pipeline diagram of the automatic construc-
tion of the WDAG is illustrated in Fig. 1.
1. Construction of the scene graph G
s
based on the
world state W to derive the geometric and sym-
bolic information of the W (Section 3.3)
2. Association of actions with the scene graph G
s
based on the prior action knowledge (Sections 3.2
and 3.4)
3. Construction of action possibility graph G
a
0
based
on the scene graph G
s
and associated actions (Sec-
tion 3.5)
4. Recursive construction of action possibility
graphs (Section 3.6)
(a) Updating scene graph and world state accord-
ing to the effect of feasible action
(b) Recursive construction of action possibility
graphs based on the updated world state
(c) Construction of WDGE G
a
by connecting the
action possibility graphs
Steps 1, 2, 4(a), and 4(b) were modified or added
from the conventional method of constructing action
graphs.
3.2 Action Knowledge Representation
The prior knowledge of the actions is represented
using the scene graphs that are compatible with the
world state and symbolic reasoning.
Each property of the action is described below.
• l
a
: Label of the action
• S
a
p
: Scene graph as affordance that affords this ac-
tion
• d
a
: Appropriate distance from the target object to
execute the action
• S
a
e
: Scene graph after execution of action
The examples of action labels l
a
include “move-
ment,” “pick up” (to pick up the bottle), “place” (to
place the bottle on the table), “push”(to push the chair
underneath the table), “speech”(to ask a person to al-
low passing movement), and “do not disturb” (to dis-
miss all actions). In particular, the “do not disturb”
action is associated with situations involving a seated
customer for courteous service. The prior knowledge
about action are detailed in Table 1. In this study, we
assume that robots can acquire the prior knowledge
about action with the affordance classification and the
action understanding (Chu et al., 2019; Dreher et al.,
2019).
World State-dependent Action Graph: A Representation of Action Possibility and Its Variations in Real Space based on World State
461
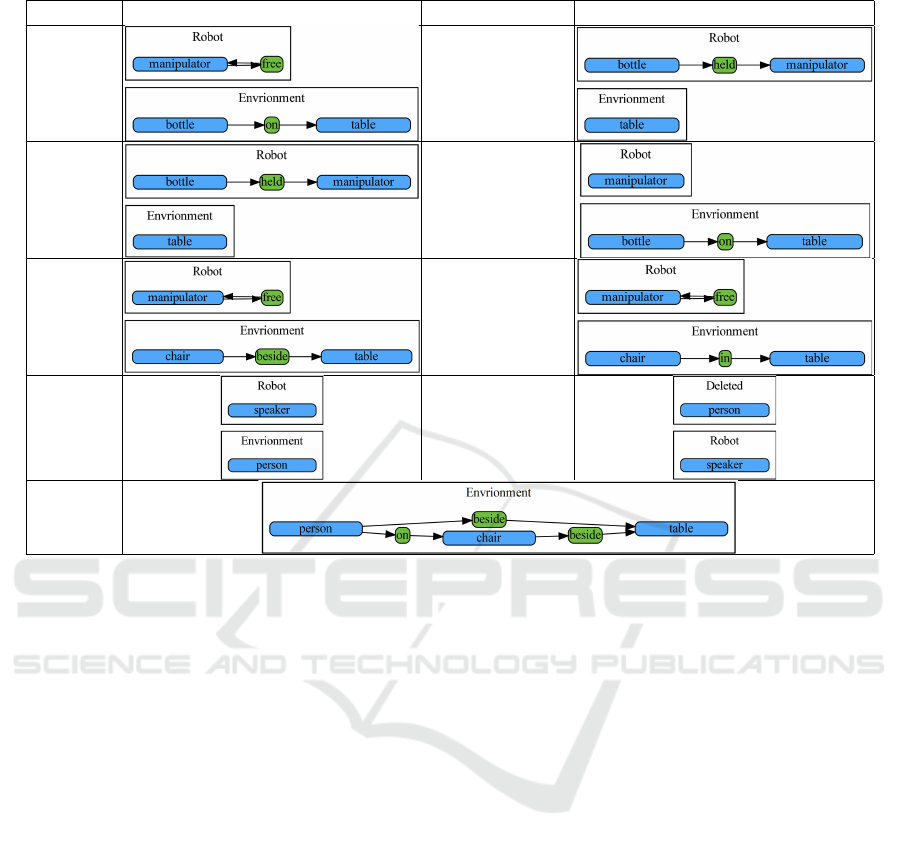
Table 1: Prior knowledge of action.
label precondition
appropriate distance
effect
pick up 0.5m
place 0.5m
push 0.7m
speech 0.4m
don’t disturb
3.3 Scene Graph Construction
A scene graph is constructed based on the world state
obtained beforehand by semantic slam, etc. The scene
graph G
s
is a directed graph in which the nodes indi-
cate objects and edges denote relations based on the
world state W . The adjacency matrix of G
s
is derived
by classifying the relational position into the relation
label r for every combination of two objects in the
world state. Generally, a positional relation r labels a
relative position from a larger object to a smaller one.
The considered labels of positional relations are
“around” (distance A from B is 1.0– 2.0 m), “beside”
(distance A from B is 0–1 m), “in,” “on,” “held,” and
“free” based on previous research (Kim et al., 2019;
Armeni et al., 2019). In particular, “held” and “free”
are positional relations related to the manipulator. In
the case the positions of a manipulator and the other
object are the same, the relative position is labeled
“held.” A self-looping relation labeled as “free” is as-
sociated with the manipulator, if the manipulator does
not relate to any object.
3.4 Association of Actions with Scene
Graph
The feasible actions for the agent depend on the world
state W comprising the agent state R and environmen-
tal state E. Therefore, the feasible actions are associ-
ated with the world state based on the precondition
of each action in the prior knowledge. Accordingly,
the subgraph isomorphism problem is applied to the
action association. The subgraphs of the world-state
scene graph G
s
are isomorphic to the precondition
scene graph of an action, which were associated with
the action and determined using the VF2 algorithm
(Cordella et al., 2004). Thus, multiple actions can be
associated with the same object.
3.5 Construction of Action Possibility
Graph
3.5.1 Sparse Representation of Reachable
Positions
The positions sparsely representing the accessible lo-
cations of the agent are determined as nodes focused
on the movement.
First, the object footprints including the wall are
expressed using a set of points in a two-dimensional
ICINCO 2022 - 19th International Conference on Informatics in Control, Automation and Robotics
462

: Table
: Chair
: Person
(a) Environment (b) Reachable positions
speech
place
a
d
a
d
(c) Action positions
: infeasible movement
(d) Connecting nodes
Figure 2: Construction of action possibility graph.
space. Thereafter, the generalized Voronoi diagram
is generated by setting the base points of the diagram
equal to the object points. As the generalized Voronoi
diagram contains untraversable edges and nodes in-
accessible by the robot, the invalid nodes and edges
were deleted with reference to the robot’s footprint.
Furthermore, neighboring nodes are merged together
to more efficiently represent the space, as portrayed
in Fig. 2b.
3.5.2 Adding Appreciate Action Positions for
Associated Actions
The nodes are added to positions considered appropri-
ate for executing the actions associated with the world
state, as depicted in Fig. 2c. In particular, certain re-
quirements that ensure the suitability of a given posi-
tion to perform the action include an appropriate dis-
tance to the target object o
a
t
and accessibility to the
target object position o
a
t
based on the agent’s foot-
print and surrounding obstacles. The position candi-
dates suitable for executing the actions are determined
based on the appropriate distance d
a
t
to the target ob-
ject o
a
t
in the prior knowledge of the action, includ-
ing the position and posture of the target object o
a
t
. In
this study, the candidates are simply determined as the
four points on the circle whose center denotes the po-
sition of the target object and radius is d
a
, as depicted
in the figure. Thereafter, among the candidates, the
nodes are selected if it did not overlap with any object
in the environment, and if there is no object situated
between itself and the target object o
a
t
.
3.5.3 Connecting Nodes
The edges connecting the nodes are determined based
on inspecting the movement feasibility through geo-
metric reasoning.
Subsequently, the edge candidates are obtained
by applying Delaunay triangulation to the determined
nodes. In addition, the edges are adopted by review-
ing the intersection based on the object placement in
the environment and the agent’s footprint. Ultimately,
an action possibility graph is obtained, as illustrated
in Fig. 2d.
3.6 Recursive Construction of Action
Possibility Graph
The actions involving the state transitions of the en-
vironment are represented with directed edges that
connect the action possibility graphs before and after
the state transition. Thus, the exhaustive understand-
ing of the connections between the action possibility
graphs is essential to represent the mutual interaction
between the action possibility and actions in WDAG.
Accordingly, the construction of the action possibility
graph in the world state and updating the world state
by executable actions are recursively repeated to de-
rive the exhaustive action possibility graphs. There-
after, the WDAG is obtained by connecting each ac-
tion possibility graph with edges indicating the action,
which is the cause of variation in the action possibil-
ity.
The specific process of constructing the WDAG is
described below.
3.6.1 Update Scene Graph and World State
According to Effect of Action
Herein, the action possibility graph derived in Sec-
tion 3.5 is used as a starting point. First, the prior
scene graph is updated based on each action associ-
ated with the obtained action possibility graph, and
the posterior scene graph to the action is obtained, as
depicted in Fig. 3. The subgraph associated with the
action in the prior scene graph is adjusted according
to the influence of the action in the prior knowledge.
Subsequently, the new scene graphs are obtained for
the number of associated actions.
Thereafter, the nodes of the scene graph, i.e., the
world states, are updated based on the freshly ob-
tained scene graph, as portrayed in Fig. 3. In particu-
lar, the object positions are updated following the re-
lationship altered by the action. Overall, the updated
positions of the object are determined following sim-
ilar rules as those applied for constructing the scene
World State-dependent Action Graph: A Representation of Action Possibility and Its Variations in Real Space based on World State
463

Posterior Scene graph
Knowledge of speech action
Precondition
Effect
Posterior world statePrior world state
Update scene graph
Interpret scene graph
s
j
G
j
W
i
W
speech
Prior Scene graph
s
i
G
place
Figure 3: Updating scene graph and world state based on action knowledge.
Connecting action possibility graphs
Prior action possibility graph
speech
place
Posterior action possibility graph
Construction of
action possibility graph
After speech
speech
place
Add the position
of executed action
Figure 4: Connecting action possibility graphs.
graph based on the relative position classification al-
gorithm.
3.6.2 Construction of Action Possibility Graph
The subsequent step involves the construction of the
new action possibility graphs based on the updated
scene graph and world state. Predominantly, the ac-
tion possibility graph is constructed based on the pro-
cess described in Sections 3.4 and 3.5. The method
was modified with the addition of a node to be consid-
ered. Moreover, the executive positions of the actions
altering the prior action possibility graph are added
as nodes in the new action possibility graph, which
enabled the connection of edges before and after the
adjustment of the graphs, as shown in Fig. 4.
3.6.3 Iterative Processing
The above process is repeated for each new action
possibility graph and its associated actions. In this it-
eration, as the same scene graph may occur in various
backgrounds, they are considered as a single scene
graph. This integration limits the number of world
states to be considered. In particular, the iteration is
terminated when the actions associated with all the
graphs were processed. Eventually, all possible ver-
sions of the action possibility graphs are obtained.
3.6.4 Connecting the Action Possibility Graphs
The multilayered graph is constructed by connecting
the action possibility graphs with edges. Specifically,
the action possibility graphs before and after the ad-
justments are connected using the edges assigned to
the actions causing the modification, as exemplified
in Fig. 4. The edges are directed from the prior graph
to the posterior graph. Ultimately, the obtained mul-
tilayered graph is WDAG.
4 EXPERIMENT
To verify the effectiveness of the proposed method,
we qualitatively evaluated the following terms: 1)
The proposed method can capture the action possibil-
ities depending on the agent’s state. 2) The proposed
method can capture the variations in the action possi-
bilities caused by the agent’s actions.
4.1 Setting
In this experiment, we assumed that an agent is HSR
(Human support robot), a mobile manipulator, and the
environment was similar to that of a caf
´
e. As dis-
played in Fig. 6, the target world state included two
world states with distinct agent states. In world state
ICINCO 2022 - 19th International Conference on Informatics in Control, Automation and Robotics
464

(a) World state 1 (G
a
0
)
(b) World state 2
(c) G
a
2
(d) G
a
6
Figure 5: Mutual interaction between action possibility
and action.
Figure 6: Difference of action possibility graph depending on agent’s state.
0
a
G
2
a
G
6
a
G
Figure 7: World state-dependent action graph based on world state 1.
1, the agent grasped the bottle, and in world state 2,
the agent grasped nothing.
4.2 Result
First, the action possibility graphs constructed based
on the world states with the two distinct agent’s states
are displayed in Fig. 6. The action possibility graphs
represent feasible actions for the agent and their po-
sitions in real space. According to Fig. 5a, the fea-
sible actions involved placing the bottle on the table
and speech toward the person in the world state 1.
In comparison, pushing the chair and speech to the
person are feasible in the world state 2 according to
Fig. 5b. Thus, the proposed method can capture the
action possibilities of the agent based on the state of
its manipulator.
The WDAG constructed based on the world state
1 is illustrated in Fig. 7. As the WDAG comprised
64 action possibility graphs, the robot could real-
ize 64 world states. In WDAG, the variations in
the action possibility graph in case the agent exe-
cutes the “place” and “push” from the initial state
G
a
0
⇒ G
a
2
⇒ G
a
6
are displayed in Fig. 6 The com-
parison of G
a
0
and G
a
2
displayed in Fig. 5c revealed
that “placing” the bottle on the table enabled the agent
to “push” the chair in a new manner. Moreover, the
comparison of G
a
0
and G
a
2
unveiled that the agent
could render the location of the chair traversable by
pushing the chair, as displayed in Figs. 5c and 5d.
Furthermore, the connection of the action possibil-
ity graphs displayed that the variations of the world
state and the action possibility caused by actions such
as that a blocked passage by a chair can be rendered
traversable. In summary, the proposed method could
capture the mutual interaction between the action and
its possibility in the recursive multilayered structure.
Individual action possibility graphs in WDAG
represent feasible actions and their positions in real
space based on geometric reasoning. Also, the con-
nection of the action possibility graph in WDAG rep-
resents the possible world states by executing ac-
tions, as well as the conventional symbolic repre-
sentations. Thus, it is expected that task planning
based on WDAG will derive more suitable sequences
of actions according to the evaluation index because
WDAG combines both symbolic and geometric infer-
ence and can comprehensively capture feasible action
sequences in real space.
5 CONCLUSION
The understanding of feasible actions for agents re-
quires further detail to realize intelligent systems in
real space. Essentially, the feasible actions for the
agent vary with the subsystem configuration of the
agent and their states. Therefore, the feasible ac-
tions depending on the world state that comprises the
agent’s state and environmental state should be com-
prehended with clarity. Conventionally, the mutual
interaction between the feasible actions and the action
World State-dependent Action Graph: A Representation of Action Possibility and Its Variations in Real Space based on World State
465

executions are represented by using symbolic repre-
sentations. However, the approaches did not consider
the feasibility of actions.
This study aimed to understand the action possi-
bility, which implies the feasible actions and their po-
sitions in real space, and its variations in real space
based on the world state. To archive the objective,
we proposed a WDAG based on knowledge represen-
tation using scene graphs. In particular, we adopted
the scene graph to represent the knowledge of action,
because it is an environmental representation that is
compatible with the world state and contains both ge-
ometric and semantic information. In addition, the
WDAG represented the mutual interaction between
the action and its possibility in a recursive multi-
layered graph structure. Accordingly, a construction
method of an action graph was established based on
the scene graph-based representation of action effects
and a recursive multilayered graph structure. This al-
lowed the capturing of the action possibility of agents
and the recursive variations of the action possibility
depending on the world state. The effectiveness of
the proposed method was verified by simulation, as-
suming a coffee shop environment. Moreover, the fol-
lowing two points were verified. 1) WDAG represents
the action possibility in real space based on the world
state. 2) WDAG represents the variations in the action
possibility caused by the agent’s action on the recur-
sive multilayered structure.
In future, we will validate the effectiveness of
WDAG in practice by implementing a planning
method of action sequences based on WDAG and ap-
plying to task plannings in real space. Task planning
based on WDAG is expected to yield more efficient
plans, such as plans with shorter movement distances,
by considering geometric information such as object
placement.
ACKNOWLEDGMENTS
This study was supported by the Core Research for
Evolutional Science and Technology (CREST) of the
Japan Science and Technology Agency (JST) under
Grant Number JPMJCR19A1.
REFERENCES
Armeni, I., He, Z.-Y., Zamir, A., Gwak, J., Malik, J., Fis-
cher, M., and Savarese, S. (2019). 3d scene graph:
A structure for unified semantics, 3d space, and cam-
era. In 2019 IEEE/CVF International Conference on
Computer Vision (ICCV), pages 5663–5672.
Chu, F.-J., Xu, R., Seguin, L., and Vela, P. A. (2019).
Toward affordance detection and ranking on novel
objects for real-world robotic manipulation. IEEE
Robotics and Automation Letters, 4(4):4070–4077.
Cordella, L., Foggia, P., Sansone, C., and Vento, M. (2004).
A (sub)graph isomorphism algorithm for matching
large graphs. IEEE Transactions on Pattern Analysis
and Machine Intelligence, 26(10):1367–1372.
Do, T.-T., Nguyen, A., and Reid, I. (2018). Affordancenet:
An end-to-end deep learning approach for object af-
fordance detection. In 2018 IEEE International Con-
ference on Robotics and Automation (ICRA), pages
5882–5889.
Dreher, C. R., Waechter, M., and Asfour, T. (2019).
Learning Object-Action Relations from Bimanual Hu-
man Demonstration Using Graph Networks. IEEE
Robotics and Automation Letters.
Fikes, R. E. and Nilsson, N. J. (1971). Strips: A new ap-
proach to the application of theorem proving to prob-
lem solving. Artificial Intelligence, 2(3):189–208.
Fox, M. and Long, D. (2003). PDDL 2.1: An extension to
pddl for expressing temporal planning domains. Jour-
nal of artificial intelligence research, 20:61–124.
Kawasaki, Y., Mochizuki, S., and Takahashi, M. (2021).
Astron: Action-based spatio-temporal robot naviga-
tion. IEEE Access, 9:141709–141724.
Kim, U.-H., Park, J.-M., Song, T.-J., and Kim, J.-H. (2019).
3-D Scene Graph: A Sparse and Semantic Representa-
tion of Physical Environments for Intelligent Agents.
IEEE Transactions on Cybernetics, pages 1–13.
Koppula, H. S. and Saxena, A. (2016). Anticipating human
activities using object affordances for reactive robotic
response. IEEE Transactions on Pattern Analysis and
Machine Intelligence, 38(1):14–29.
Liang, J., Jiang, L., Niebles, J. C., Hauptmann, A. G., and
Fei-Fei, L. (2019). Peeking into the future: Predict-
ing future person activities and locations in videos. In
Proceedings of the IEEE Conference on Computer Vi-
sion and Pattern Recognition, pages 5725–5734.
L
¨
uddecke, T. and W
¨
org
¨
otterr, F. (2020). Fine-grained action
plausibility rating. Robotics and Autonomous Systems,
129:103511.
Rhinehart, N. and Kitani, K. M. (2016). Learning action
maps of large environments via first-person vision. In
Proceedings of the 2016 IEEE Conference on Com-
puter Vision and Pattern Recognition (CVPR), pages
580–588.
Ziaeetabar, F., Aksoy, E. E., W
¨
org
¨
otter, F., and Tamosiu-
naite, M. (2017). Semantic analysis of manipula-
tion actions using spatial relations. In 2017 IEEE In-
ternational Conference on Robotics and Automation
(ICRA), pages 4612–4619.
ICINCO 2022 - 19th International Conference on Informatics in Control, Automation and Robotics
466
