
Applying Personal and Group-based Trust Models in Document
Recommendation
Chin-Hui Lai
1
, Duen-Ren Liu
2
and Cai-Sin Lin
2
1
Department of Information Management, Chung Yuan Christian University, Chung-Li, TaoYuan County, Taiwan
2
Institute of Information Management, National Chiao Tung University, Hsinchu, Tawian
Keywords: Collaborative Filtering, Document Recommendation, Group Trust, Role Relationship, Personal Trust, Trust-
based Recommender System.
Abstract: Collaborative filtering (CF) recommender systems have been used in various application domains to solve
the information-overload problem. Recently, trust-based recommender systems have incorporated the
trustworthiness of users into CF techniques to improve the quality of recommendation. Some researchers
have proposed rating-based trust models to derive the trust values based on users’ past ratings of items, or
based on explicitly specified relations (e.g. friends) or trust relationships. The rating-based trust model may
not be effective in CF recommendations, due to unreliable trust values derived from very few past rating
records. In this work, we propose a hybrid personal trust model which adaptively combines the rating-based
trust model and explicit trust metric to resolve the drawback caused by insufficient past rating records.
Moreover, users with similar preferences usually form a group to share items (knowledge) with each other,
and thus users’ preferences may be affected by group members. Accordingly, group trust can enhance
personal trust to support recommendation from the group perspective. Eventually, we propose a
recommendation method based on a hybrid model of personal and group trust to improve recommendation
performance. The experiment result shows that the proposed models can improve the prediction accuracy of
other trust-based recommender systems.
1 INTRODUCTION
Recommender systems have been, and are currently
applied in various applications to support item (e.g.
movies or music) recommendation (Resnick et al.,
1994); (Schafer et al., 2007), solving the
information-overload problem by suggesting items
of interest to users. In the various recommendation
methods, collaborative filtering (CF) (Konstan et al.,
1997) is the most widely and successfully used
method in diverse applications. It predicts user
preferences for items by considering the opinions (in
the form of preference ratings) of other similar (e.g.
“like-minded”) users. Thus, personalized
recommendations are made according to the
preferences of similar users.
Recently, trust-based recommender systems
(Lathia et al., 2008); (O'Donovan and Smyth, 2005);
(Liu et al., 2011) have incorporated the
trustworthiness of users into CF techniques to
improve the quality of recommendation. There are
two categories of calculating trust scores
(trustworthiness) between users. One category of
trust-based system computes the trust scores based
on users’ past ratings on items (O'Donovan and
Smyth, 2005), while the other uses an explicitly
specified trust metric to derive the trust values based
on explicitly specified relations (e.g. friends) or trust
relationships. Users need to specify explicitly whom
they trust and how much they trust each other.
Although conventional trust-based CF systems
have proposed rating-based trust models (Hwang
and Chen, 2007, O'Donovan and Smyth, 2005) or
explicitly specified trust metrics (Massa and
Avesani, 2004); (Massa and Avesani, 2007a);
(Massa and Avesani, 2007b); (Massa and
Bhattacharjee, 2004) to derive the trustworthiness of
users, they do not investigate how to combine the
rating-based trust model with an explicit trust
metric. In this work, we propose a personal trust
model that adaptively combines the rating-based
trust model and explicit trust metric to resolve the
drawback caused by insufficient past rating records.
We derive the trust values between two users based
29
Lai C., Liu D. and Lin C..
Applying Personal and Group-based Trust Models in Document Recommendation.
DOI: 10.5220/0004039300290038
In Proceedings of the International Conference on Data Technologies and Applications (DATA-2012), pages 29-38
ISBN: 978-989-8565-18-1
Copyright
c
2012 SCITEPRESS (Science and Technology Publications, Lda.)

on their explicitly specified role relations. Such
explicit relationship trust can complement the
traditional rating-based trust model for improving
the reliability of trust values.
Moreover, users with similar preferences usually
form a group to share items (knowledge) with each
other, and thus users’ preferences may be affected
by group members. Accordingly, group trust can
enhance personal trust to support recommendations
from group perspective. Nevertheless, conventional
trust-based CF systems do not address trust
computation by considering both personal and group
trust. Therefore, we propose a hybrid trust model,
which integrates personal and group trust to improve
the performance of collaborative filtering. From the
group-based trust metric we can find trustworthy
recommenders from the group’s point of view. Such
a group perspective may be important because it can
complement the trustworthiness of personal
perspective, in particular, when an individual is not
sure who to trust. In the group-based trust, we define
a role-weight for each user to represent the
importance degree in the group. By adopting the
role-weight value, the group-based trust can be
aggregated from group members’ trust values. On
the other hand, the group-based trust focuses on the
majority of the group’s opinions, which might
ignore the personal perspective. Accordingly, our
proposed hybrid trust model combines personal trust
and group-based trust models to integrate the merits
of both perspectives. The trust values derived from
our trust models are regarded as weightings in the
collaborative filtering (CF) method to identify the
trustworthy recommenders for predicting document
ratings. Our experiment results show that the
proposed trust model can improve the prediction
accuracy of the CF method in comparison with other
trust-based recommender systems.
This paper is organized as follows: We present
the related work in Section 2. An overview of our
trust computation models from the personal and
group perspectives and recommendations based on
these trust models are presented in Section 3. The
experiment results and evaluations are presented in
Section 4. Conclusions are presented in Section 5.
2 RELATED WORK
This section introduces the related works of trust-
based CF recommender systems.
2.1 Reputation Trust based
Recommender System
Reputation trust is a more quantitative assessment,
which allocates a score to a specific object or person
within a particular context. An individual’s
reputation trust is collected from the members in the
community. Thus, reputation trust is referred to as
"expert" or "professional degree". Cho et al. (Cho et
al., 2007) and Kim et al. (Kim et al., 2008) judge
whether someone is qualified as an expert by
adopting Riggs’s model (Riggs and Wilensky,
2001), which assigns scores to reviewers based on
how close their ratings are to the average ratings.
For example, Kim et al. (Kim et al., 2008) use
Epinion.com data to derive the degree of trust based
on users’ expertise in categories, which is derived
based on the quality of reviews and reputations of
review raters/writers.
Several researchers propose reputation trust as an
auxiliary factor in the recommendation phase.
O'Donovan and Smyth (O'Donovan and Smyth,
2005) claim that accurate recommendation in the
past is important and reliable, and they propose
profile-level trust and item-level trust derived from
user rating data. Both profile-level trust and item-
level trust can be used in the recommendation phase.
2.2 Relationship Trust based
Recommender System
Relationship trust relies on qualitative measurements
dependent on social network connections. A user
decides his/her trust of another based on some
private knowledge which was gained through past
interactions, or explicitly specified relationships.
Thus, relationship trust metrics consider the truster’s
subjective opinions when predicting the trust value
which s/he places on the trustee. Epinions.com
allows users to express their trust opinions by adding
a reviewer into their Web of Trust list or Block list,
according to whether the reviewer’s reviews are
valuable. Massa and Avesani (Massa and Avesani,
2007b) call this kind of trust opinion as local trust
(relationship trust), and take advantage of the Web of
Trust in Epinions.com to balance the collaborative
recommender system’s defects (Massa and Avesani,
2004); (Massa and Avesani, 2007a); (Massa and
Bhattacharjee, 2004).
Even though relationship trust presents an
improvement on traditional CF recommender
systems, the direct relationship trust data is not usual
in most recommender systems, and it is difficult to
collect. Besides this, the quality of a reviewer’s
DATA2012-InternationalConferenceonDataTechnologiesandApplications
30
review
c
relation
s
reviewe
r
and Ch
e
truster’s
p
ersonal
value
w
research
,
p
ersonal
b
etter th
work,
w
p
ropose
d
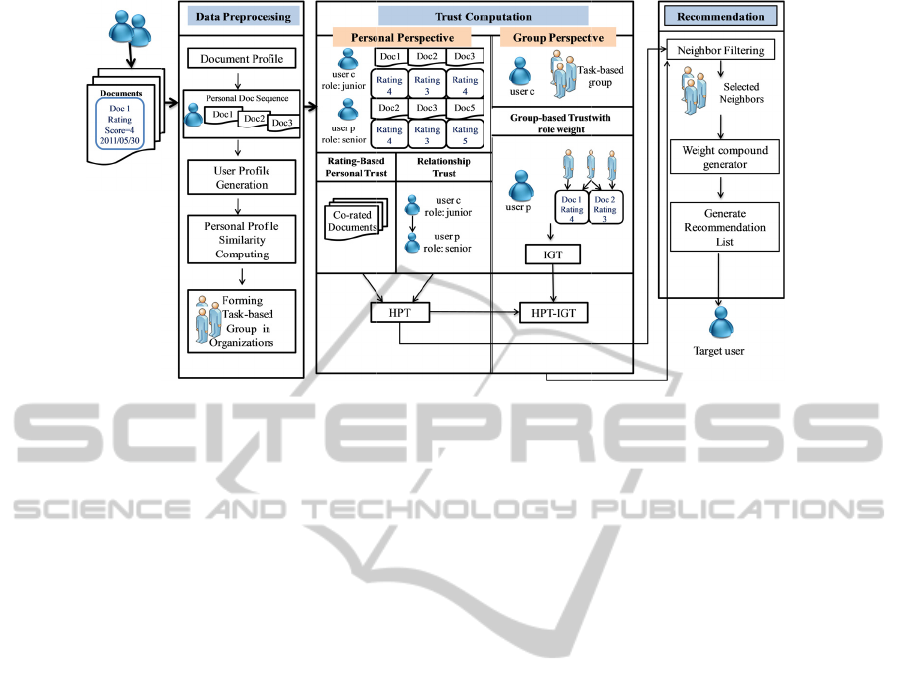
3 H
Y
D
O
R
E
3.1
T
M
In this
w
combini
n
improve
models
a
select tr
u
1 shows
model a
n
on the p
r
framew
o
Data P
r
by tf-id
f
generate
contents
Figur
e
c
annot alway
s
s
hip trust
m
r
’s quality a
n
e
n (Hwang
a
subjective
ization effec
w
hich s/he p
l
, the experi
m
(local) trus
t
an the global
w
e also apply
d
method for
m
Y
BRID T
R
O
CUME
N
E
COMM
E
T
he Frame
w
M
odels for
R
w
ork, we pr
o
n
g personal
the recom
m
a
re used in o
u
u
stworthy ne
i
the framewo
r
n
d the CF re
c
r
oposed mod
e
o
rk:
r
eprocessin
g
:
f
approach (
S
document
of documen
t
e
1: The frame
w
s
maintain co
n
m
ay vary a
c
n
d the user’s
a
nd Chen, 2
0
opinions
t
ts when pr
e
l
aces on the
m
ent evaluati
o
t
-
b
ased CF
m
trus
t
-
b
ased
C
such relatio
n
m
aking reco
m
R
UST M
O
N
T
E
NDATIO
w
ork of H
y
R
ecomme
n
o
pose hybrid
and group
m
endation q
u
u
r recommen
d
i
ghbors for ta
r
r
k of our pro
p
c
ommendatio
n
e
l. There are t
h
:
Documents
S
alton and
B
profiles des
t
s. Accordin
g
w
ork of hybrid
p
n
sistency, an
d
c
cording to
interest. H
w
0
07) consider
o obtain
m
dicting the
t
trustee. In
t
o
n shows tha
t
m
ethod perf
o
C
F method. In
n
ship trust in
m
mendations.
O
DELS A
N
NS
y
brid Trus
t
n
dation
trust model
s
trusts. Then
u
ality, these
t
d
ation metho
d
r
get users. Fi
g
p
osed hybrid
t
n
methods, b
a
h
ree phases i
n
are pre
p
roce
B
uckley, 198
8
cribing the
g
to users’ a
c
p
ersonal and g
r
d
the
the
w
ang
r
the
m
ore
trust
t
heir
t
the
o
rms
n
this
our
N
D
t
s
by
n
, to
trust
d
s to
gure
trust
ased
n
our
e
ssed
8
) to
key
c
cess
b
e
h
ge
n
Us
e
tas
k
Tr
u
b
ot
h
p
er
an
d
co
m
der
i
wh
i
ex
p
Th
e
a h
y
of
c
nu
m
p
er
is
p
er
der
i
use
use
hy
b
b
ot
h
tru
s
Th
e
use
the
Ho
w
the
gro
foc
u
use
ign
o
r
oup trust mod
e
h
avior and d
o
n
erated to r
e
e
rs with simi
l
k
-
b
ased grou
p
u
st Computa
t
h
the person
a
s
onal perspe
c
d
relationship
m
putation. T
h
i
ved from us
e
i
le the relatio
n
p
erts accordin
g
e
se two kinds
y
brid person
a
c
o-rated item
s
m
ber of co-
r
s
onal trus
t
is
m
assigned to
s
pective, the
i
ved by agg
r
r’s group m
rs’ role weig
h
b
rid trust mo
d
h
personal a
n
s
t value from
t
e
se trust mod
e
A user’s rati
n
r’s perceptio
n
document c
o
w
ever, the pr
o
opinions o
f
u
p
p
erspecti
v
u
ses on the
rs rather than
o
re personal
l for recomme
n
o
cument pro
fi
present user
s
ar user profil
p
.
t
ion: We pro
p
a
l and group
tive, the rati
n
trust are c
o
h
e rating-
b
a
s
e
rs’ ratings o
n
n
ship trust is
g
to the role
r
of trust are
a
a
l trust (HPT
)
s
between tw
o
r
ated docum
e
m
ore reliable
,
it. Moreo
v
ite
m
-level
g
r
egating the
o
e
mbers with
h
ts. In additi
o
d
el, i.e., HPT
-
n
d group tru
s
t
he personal
a
e
ls will be dis
c
n
g of a docu
m
n
of the rele
v
o
ntent to his/
h
o
posed
p
erso
n
other grou
p
v
e, group tr
u
m
ajority of
t
an individua
l
information
n
dation.
f
iles, user pr
o
s
’ informati
o
l
es are cluste
r
p
ose trust mo
d
perspec
t
ive.
n
g-
b
ased pers
o
nsidered in
s
ed personal
n co-rated d
o
explicitly as
s
r
elation betw
e
a
daptively co
m
)
based on th
e
o
users. With
e
nts, the rat
i
,
and thus mo
v
er, from t
h
group trust
o
pinions of
t
the consid
e
o
n, we also
p
T
-
IGT, which
st models to
a
nd group per
s
c
ussed in Sec
t
m
ent usually r
e
v
ance or use
f
h
er informati
o
n
al trust mod
e
p
members.
F
u
s
t
, i.e., IG
T
t
he opinions
l
user. Howe
v
in comput
i
o
files are
o
n needs.
r
ed into a
d
els from
F
rom the
o
nal trust
the trust
trust is
o
cuments,
s
igned by
e
en users.
m
bined as
e
number
a greater
i
ng-based
re weight
h
e group
(IGT) is
t
he target
ration of
p
ropose a
c
ombines
derive a
s
pectives.
t
ion 3.3.
e
flects the
f
ulness of
o
n needs.
e
l ignores
F
rom the
T
, mainly
of group
er, it may
i
ng trust.
ApplyingPersonalandGroup-basedTrustModelsinDocumentRecommendation
31

Conventional trust-based recommendation systems
have not addressed how to take both personal and
group aspects into account to derive a reliable trust
prediction. Accordingly, the hybrid model of
personal and group trusts is proposed for trust
computation.
Recommendation: According to the trust models in
the previous phase, the obtained trust values are
incorporated into our recommendation methods to
discover the trustworthy recommenders, in order to
enhance the performance of recommendations, and
facilitate knowledge sharing. Users with high trust
values are identified as trustworthy recommenders,
and then they are selected as neighbors for our target
users. The proposed CF methods derive the
predictions of document ratings for the target user
based on the trust values and the document ratings of
neighbors. Documents with high predicted ratings
are used to compile a recommendation list.
3.2 Document Profiling and User
Clustering
In order to group similar users as a task-based group,
we analyze users’ information needed to generate
document profiles and user profiles first. Then,
similar users can be clustered into a group by
measuring the similarities of user profiles. Two
profiles, a document profile and a user profile, are
used to represent a document and a user’s preference,
respectively.
A document profile can be represented as an n-
dimensional vector composed of terms and their
respective weights derived by the normalized tf-idf
approach(Salton and Buckley, 1988). Based on the
term weights, terms with higher values are selected
as discriminative terms to describe the
characteristics of a document. The document profile
of d
j
is comprised of these discriminative terms. Let
the document profile be
>=<
njnjjjjjj
dtwdtdtwdtdtwdtDP :,,:,:
2211
L
, where dt
ij
is
the term i in d
j
, and dtw
ij
is the degree of importance
of a term i to the document d
j
, which is derived by
the normalized tf-idf approach. The document
profiles are used to generate a user’s profile.
Similarly, a user profile is generated by
aggregating the profiles of documents that the user
has accessed. Let UP
x
=<ut
1x
:utw
1x
, ut
2x
:utw
2x
, …,
ut
nx
:utw
nx
> be the profile of a user x, where ut
ix
is a
term in the user profile, and utw
ix
is the weight of the
term. These terms are chosen from all document
profiles of the user, according to their term weights.
Additionally, we adopt the K-means clustering
algorithm (Jain et al., 1999) to group users with
similar profiles into clusters by using the cosine
measurement. Note that a cluster is a task-based
group where users have similar task-related
knowledge and preferences.
3.3 The Hybrid Trust Models
We will elaborate on the proposed hybrid of trust
models, which take both the personal and group
perspectives into account, in this section. In this
work, “target user” indicates the user who is
recommended, while “recommender” denotes the
user who recommends items to the target user.
3.3.1 The Rating-based Personal Trust
The rating-based personal trust is derived from two
users’ past ratings on co-rated documents by
adopting Hwang and Chen’s (Hwang and Chen,
2007) trust computation method. Note that the
document rating, which is given by a user on a scale
of 1 to 5, indicates whether a document is perceived
as useful and relevant to the user’s task. In the
conventional trust model (Hwang and Chen, 2007);
(O'Donovan and Smyth, 2005), it calculates the ratio
of accurate predictions made according to past
ratings when counting how much the target user may
trust the recommender. Generally, a recommender is
more trustworthy if s/he has contributed more
precise predictions than other users. Similar to the
conventional trust computation model, we also use a
simple version of Resnick’s prediction formula
(Resnick et al., 1994) to calculate a target user c’s
predicted rating of a document d
k
,
,
ˆ
p
cd
p
, which is
derived from a recommender p’s rating of d
k
, as
defined in Eq. (1):
,,
,
ˆ
kk
cd p
p
cp
d
prrr
⎛⎞
⎜⎟
⎝⎠
=+ −
(1)
where
c
r
and
p
r
refer to the mean ratings of target
user c and recommender p; and
,
k
p
d
r
is p’s rating of
document d
k
. If
,
ˆ
k
p
cd
P
is close to the real rating score
of user c on d
k
, i.e.,
,
k
cd
r
, we conclude that both the
target user c and the recommender p have a similar
perspective on document d
k
. The more similar the
perspective, the more trust they have, as illustrated
in Eq.(2):
,
,
,
,
ˆ
1
k
k
d
cp
cd
p
k
cd
P r
T
M
−
=−
(2)
where
,
k
d
cp
T
is the pure trust value between target user
c and recommender p pertaining to document d
k
that
DATA2012-InternationalConferenceonDataTechnologiesandApplications
32

is derived from the rating data, and M is the range of
the rating score, which equals the difference of the
maximum and minimum rating scores.
We adopt Hwang and Chen’s (Hwang and Chen,
2007) trust model to calculate the rating-based
personal trust by considering all items that are co-
rated by recommender p and target user c, as defined
in Eq.(3):
()
,,
,
1
ˆ
,
1
dd
cp
kk
p
II
cd cd
k
cp
d
c
a
d
r
p
d
Pr
M
PT
II
∩∈
−
−
⎛⎞
⎜⎟
⎜⎟
⎝⎠
∩
=
∑
(3)
where
,
ra
cp
P
T
is a trust degree of the rating-based
personal trust that represents how much a target user
c trusts the recommender p;
d
c
I
/
d
p
I
is a document set
of target user c / recommender p; M is the range of
the rating score, which equals the difference of the
maximum and minimum rating scores;
,
ˆ
p
cd
p
is a
predicted rating on a document d
k
of target user c,
which is derived from a recommender p’s rating of
d
k
; and
,
k
cd
r
is the actual rating score of user c on d
k
.
By counting
,
k
d
cp
PT
from the co-rated document set,
we derive the average trust value. With more co-
rated documents, the trust degree of the rating-based
personal trust is more reliable.
However, if two users have no co-rated
documents, the result is no direct relationships
between them; the rating-based personal trust is
unreliable to represent the trust relation between
these two users. Thus, to enhance the prediction
ability for the personal trust model, we consider the
relationship trust based on two user’s roles in
computing personal trust. The detail is illustrated in
Section 3.3.2.
3.3.2 The Hybrid Personal Trust (HPT)
To resolve the limitation in the rating-based personal
trust, we propose the hybrid personal trust (HPT)
model, which adaptively combines rating-based
personal trust and relationship trust based on the
number of co-rated documents between two users.
The rating-based personal trust is derived from users’
ratings on the co-rated documents by adopting
Hwang and Chen’s (Hwang and Chen, 2007) trust
computation method, illustrated in Section 3.3.1.
The relationship trust is measured according to the
role relationship between two users. A user is usually
assigned a specific role when he/ she participates in
an organization or group. Because there are various
roles, the relationships and trust reliability among
these roles may differ. For example, a junior user
generally trusts a senior user more than they would
another junior, since senior users have more
knowledge and experiences of tasks. Thus, the value
of the relationship trust between these two roles, i.e.,
junior-to-senior, should be higher than that of senior-
to-junior.
Because of the relationship trust, HPT can
adaptively provide a precise prediction of trust based
not only on co-rated documents, but also on users’
role relationships. It also can resolve the problem
that insufficient co-rated documents could cause an
unreliable prediction of rating-based personal trust.
The model which adaptively integrates the rating-
based personal trust and the relationship trust is
proposed and defined in Eq.(4):
(
)
,, ,
,1=
ra rel
cp cp cp
PTPT
P
TH
α
α
×
+− ×
(4)
where HPT
c,p
is a hybrid personal trust for the target
user c with respect to recommender p;
,
ra
cp
P
T
is the
rating-based personal trust for the user c, derived
from the co-rated documents between user c and p;
,
el
cp
r
PT
is the relationship trust for the target user c
based on the role relation between user c and p; and
α, which ranges from 0 and 1, is used to adaptively
adjust the relative importance of the rating-based
personal trust (i.e.,
,
ra
cp
PT
), with respect to the
relationship trust (i.e.,
,
el
cp
r
PT
).
The value of α is adaptively computed based on
the number of co-rated documents between two
users. It is defined as
α
=m/N
if m < N, and
α
= 1 if
m ≥ N, where m is the number of co-rated documents
between target user c and recommender p; and N is a
pre-specified value, and is an appropriate number of
co-rated documents which is used to determine the
reliability of rating-based personal trust. The more
documents the target user c and recommender p
have accessed and given ratings, the more reliable
the rating-based personal trust is. That is, with more
co-rated documents, the rating-based personal trust
is more capable of inferring the personal trust for the
target user c.
3.3.3 Item-level Group Trust (IGT)
From the group perspective, the item-level group
trust (IGT) method is proposed to predict a trust
value of a user, i.e., a recommender, on a specific
item. In task-based environments, users with similar
preferences or information needs for task-related
knowledge may form a group. In the same group, a
target user usually has preferences similar to his
group members’, such that a recommender trusted
ApplyingPersonalandGroup-basedTrustModelsinDocumentRecommendation
33

by his group members may also be trusted by the
user. Accordingly, a user trusted by the majority of
the target user’s group members is more likely to be
a trustworthy recommender for providing reliable
recommendations to the target user. Moreover, the
preferences of users in different groups may be
different; that is, the opinions of the target user’s
group may differ from those of other groups; thus
the trust values derived from the opinions of the
majority of all users without considering group
perspective may not be appropriate for finding
trustworthy recommenders for the target user.
Traditional item-level trust does not take the group
perspective into account.
Therefore, we propose the IGT model to infer the
trust value of the target user’s group on a
recommender for a specific document by
aggregating the opinions of the target user’s group
members. Additionally, since users have different
task-related knowledge and experience, each user is
assigned an appropriate role in performing a task.
Similar to the relationship trust described in Section
3.3.2 , the role weight is also assigned by experts
according to the role influence in the group. The
trust value can be used to indicate how much a user
is trusted by a target user’s group members, from the
group perspective.
IGT defined in Eq. (5) is used to predict a group
trust value for a recommender on a specific
document. We take not only the pure trust between
two users on a specific document, but also users’
role weights into account. The group trust of group
U
g
with respect to recommender p is derived by
taking the weighted average of the pure trust values
of predictions made for document d
k
, and the role
weights of users. Let
,
k
g
d
Up
I
GT
be a group U
g
’s group
trust on recommender p for document d
k
:
,,
,
,
,
ˆ
r
1
,
kk
g
g
k
g
g
g
p
ud ud
uU
uU
d
Up
u
R
ole
U
Role
uU
P
W
M
IGT
W
∈
∈
⎛⎞
−
⎜⎟
−×
⎜⎟
⎝⎠
=
∑
∑
(5)
where U
g
is a task-based group to which target user c
belongs, and
,
g
uU
R
ole
W
is the role weight of user u to the
group U
g
. The IGT model can be used to identify
trustworthy recommenders, who have higher role
weights in a group and similar opinions to a specific
document, for a target user from the group
perspective. Such a group perspective may be
important, because it can complement the
trustworthiness of the personal perspective, in
particular, when an individual is not sure who to
trust.
3.3.4 The Hybrid of HPT and IGT
(HPT-IGT)
In this section, we propose a hybrid trust model of
HPT and IGT (HPT-IGT), which linearly combines
hybrid personal trust (HPT) and item-level group
trust (IGT). It takes not only the pure trusts between
users, but also the role weights into account.
However, HPT ignores other users’ opinions because
it mainly exploits the opinions of two users, i.e., the
ratings on the co-rated documents, to obtain the
personal trust value. Besides, IGT computes a user’s
group trust value for a particular document from
group users’ opinions. That is, this kind of trust
value is derived from the group perspective, which
can complement the trustworthiness of personal
perspective, especially when an individual has very
few rating data and is not sure who to trust. However,
it neglects the personal trust between users.
Therefore, in order to obtain a reliable trust value,
both HPT and IGT are integrated as a HPT-IGT
model for trust computation.
Let
,
,
k
H
d
cp
HT
be a trust value of target user c on
recommender p for the document d
k
, which is
derived by linearly integrating the HPT and IGT
models, as defined in Eq. (6). This value represents a
trust degree that a target user c trusts the
recommender p on document d
k
:
(
)
,
,, ,
,1
kk
g
Hd d
cp cp U p
HT HPT IGT
ββ
=× +− ×
(6)
where HPT
c,p
is a hybrid personal trust derived from
the HPT model to predict target user c’s trust value
on recommender p;
,
k
g
d
Up
IGT
is the trust value of
target user c’s group U
g
on recommender p for
document d
k
, derived from the opinions of group U
g
by using the IGT model; and β is the weighting to
adjust the relative importance of the trust values of
the HPT and IGT models. The value of β is on a
scale of 0 to 1. From both personal and group
perspectives, the trust value on a recommender is
derived by not only the opinion of a target user, but
also by those of the target user’s group members.
Therefore, we will apply the HPT-IGT model to our
recommendation methods in determining the
trustworthy recommenders for improving the quality
of recommendations. The details will be discussed in
the next section.
3.4 Recommendations with Personal
and Group Trust Weighting
To provide accurate recommendations for a target
user, the trust values between the target user and
DATA2012-InternationalConferenceonDataTechnologiesandApplications
34

recommenders, as illustrated in Section 3.3, are used
to select the trustworthy recommenders (or
neighbors), and then applied in the prediction
formula as weightings to derive the predicted ratings
for documents. Let NS be a neighbor set; TM be the
proposed trust models to predict a trust degree of
recommender p from the personal and group
perspective; TM may be HPT
c,p
,
,
k
g
d
Up
I
GT
, and
,
,
k
H
d
cp
HT
,
which represents one of our proposed trust models.
Based on these proposed trust models, different
trustworthy users are selected as recommenders for a
target user.
In this section, we propose a document
recommendation method based on our proposed
trust models. The recommendation methods utilize
the personal/group/hybrid trust values as weightings.
Users whose trust values are more than or equal to a
specified threshold are selected as credible
recommenders for a target user, and their document
ratings are used to make recommendations. The
predicted rating of a document d for a target user c,
,
ˆ
k
cd
P
is calculated by Eq. (7):
(
)
,
,
,
ˆ
k
k
pd p
pNS
cd
c
pNS
TM r
r
T
r
P
M
∈
∈
×−
=+
∑
∑
(7)
where NS is a neighbor set for the target user c that
each users’ trust value is greater than or equal to a
specified threshold; user p who belongs to NS is a
neighbor of user c;
c
r /
p
r
is the average rating of
documents given by the target user c/ recommender
p;
,
k
p
d
r
is the rating of document d
k
given by user p;
and TM is the trust value between user c and p,
which derived from one of our proposed trust
models, including the HPT, IGT and HPT-IGT
respectively. According to Eq. (7), documents with
high predicted ratings are recommended to the target
user.
4 EXPERIMENTS AND
EVALUATIONS
In this chapter, we conduct experiments on our
proposed trust models and recommendation methods,
and compare them with other trust-based
recommendation methods in order to evaluate their
recommendation quality. We describe the
experiment set-up in Section 4.1, and demonstrate
the experiment results in Section 4.2
, 4.3 and 4.4.
4.1 Experiment Set-up
In our experiment, we collect a data set from a
research institute laboratory. We build a knowledge
management system (KMS) to collect documents
related to knowledge workers’ tasks. The data set
contains users’ access and rating behaviors
concerning documents over time in conducting
research tasks. Workers’ tasks are research-based
tasks, and their research domains are recommender
systems, data mining, information retrieval,
workflow systems, knowledge management, etc.
There are over 800 research-related documents, and
about 80 users in the data set.
From the group perspective, a user’s role also has
different degree of importance to the group.
Therefore, we give each role a weighting value to
represent its importance and influence for a group.
Similarity, we also define explicit relationship trusts
between users based on role relations. In general, a
user usually may trust other users who have great
influence in a group. Therefore, we set a value to the
relationship trust for users based on the influence
between their different roles. For example, the trust
value of “senior-junior” is higher than that of
“junior-senior” in our dataset. Note that such
relationship trust is a direct trust. For two users, two
different relationship trusts will be assigned.
Moreover, according to users’ information needs, we
cluster these users into 10 groups as task-based
groups by utilizing the K-means clustering method.
Each group may consist of 5-16 users with similar
information needs.
In our experiment, the data set is divided into a
training set and a testing set. The training set is used
to generate recommendation lists, while the test set
is used to verify the quality of the recommendations.
30% of the users in the data set were selected as the
target workers. The data of non-target workers is
included in the training set.
To measure the recommendation quality of our
proposed methods, we use the Mean Absolute Error
(MAE), which evaluates the average absolute
deviation of a predicted rating, and the user’s true
rating, as an evaluation metrics. The lower the MAE
is, the more accurate the method will be. The MAE
is defined in Eq. (8).
1
ˆ
,
kk
N
dd
k
Pr
MAE
N
=
−
=
∑
(8)
Here N is the number of testing data,
ˆ
k
d
P
is the
predicted rating of document d
k
and
k
d
r
is the real
ApplyingPersonalandGroup-basedTrustModelsinDocumentRecommendation
35
rating of document d
k
.
4.1.1 Methods Compared in the Experiment
In the trust-based recommender systems, the trust
values are obtained by using different trust
computation models for selecting neighbors for a
target user. Thus, we use different trust computation
models to make recommendations, and then analyze
their recommendation quality. These
recommendation methods are defined as follows:
CF: the standard Resnick model in GroupLens
(Resnick et al., 1994). The Pearson correlation
coefficient is used in filtering and making
predictions.
Profile Trust-CF (ProfileT-US-CF): The profile-
level trust is used in filtering, and the weight which
combines both the profile-level trust and user
similarity by harmonic mean is used to make
predictions (O'Donovan and Smyth, 2005).
Item Trust-CF (ItemT-US-CF): The item-level
trust is used in filtering, and the weight which
combines both the item-level trust with user
similarity by harmonic mean is used to make
predictions (O'Donovan and Smyth, 2005).
Rating-based Personal Trust CF (PersonalT-CF):
Personal trust between two users is calculated by
averaging the prediction error of their co-rated items
(Hwang and Chen, 2007).
Relationship Trust CF (RelationT-CF):
recommendations with relationship trust between
two users, based on their role relationships, as
described in Section 3.3.2.
Hybrid Personal Trust CF (HPT-CF):
recommendations with hybrid personal trust, which
combines rating-based personal trust and
relationship trust derived by Eq.(4), as described in
Section 3.3.2.
Item-Level Group Trust CF (IGT-CF):
recommendations with IGT trust model, which
infers a user’s trust value on a specific document by
aggregating the opinions of the members of a target
user’s group (Eq. (5)), as described in Section 3.3.3.
Hybrid of HPT and IGT CF (HPT-IGT-CF):
recommendations with hybrid of HPT and IGT
models, using Eqs.(4), (5), and (6), as described in
Section 3.3.4.
4.2 The Effect of the Hybrid Personal
Trust Model
In this section, we evaluate the effect of the hybrid
personal trust model by comparing its
recommendation quality to those of the PersonalT-
CF, RelationT-CF, and HPT-CF methods. For the
trust-based recommendation methods,
recommenders with trust values greater than a
threshold are selected as the neighbors of target user
for making CF recommendations. The setting of the
threshold for the trust value may affect the
recommendation quality. A suitable threshold should
be decided to select “trustworthy” recommenders in
the trust models. According to our experiments, the
most suitable threshold of trust value for the trust-
based recommendation methods is 0.7.
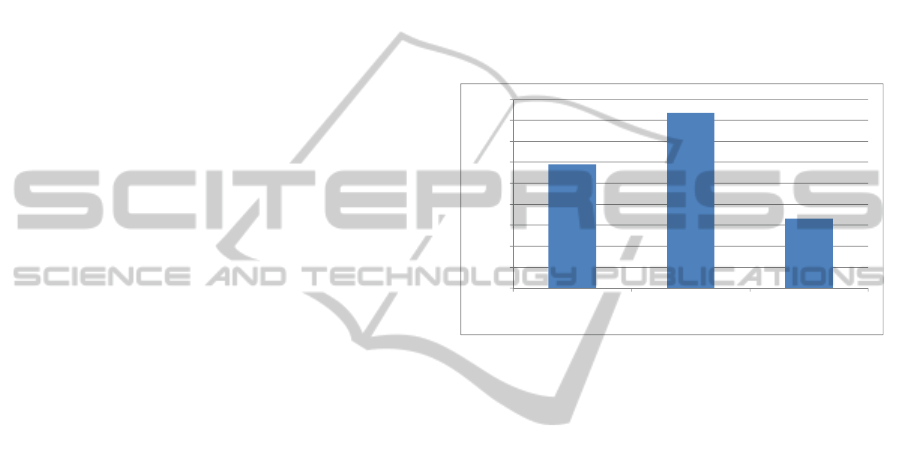
Figure 2: The performance of hybrid personal trust.
The PersonalT-CF derives personal trust from the
ratings of co-rated items between two users. The
HPT-CF adaptively integrates a user’s rating-based
personal trust and relationship trust to obtain a
hybrid personal trust by adopting a parameter α (Eq.
(4)). From the experimental result, N
is set as 20 for
α to combine the two kinds of trust, because this
achieved the lowest MAE.
Figure 2 shows that HPT-CF performs better than
PersonalT-CF and RelationT-CF. This implies that
considering both the rating-based personal trust and
the relationship trust in deriving the trust values can
more effectively improve the recommendation
quality than can the methods which consider only
rating-based personal trust or relationship trust.
HPT-CF resolves the drawback of insufficient past
rating records, and improves the reliability of trust
values.
4.3 The Effect of the Hybrid Personal
and Group Trust Model
In this section, we evaluate the effect of the hybrid
personal and group trust model by comparing the
HPT-CF, IGT-CF and HPT-IGT-CF methods. To
combine two trust values of HPT and IGT in HPT-
IGT-CF, a parameter β is utilized to adjust the
0.64
0.65
0.66
0.67
0.68
0.69
0.70
0.71
0.72
0.73
PersonalT-CF RelationT-CF HPT-CF
MAE
Methods
DATA2012-InternationalConferenceonDataTechnologiesandApplications
36
relative importance between the hybrid personal
trust value (HPT) and item-level group trust (IGT).
In order to determine the optimal value for β, we
conduct several experiments for systematically
adjusting the values of β in an increment of 0.1, as
shown in Figure 3. According to the experiment
results, HPT-IGT-CF has the lowest MAE when β is
0.9. This means that the relative importance for HPT
and IGT is 0.9 and 0.1, respectively. The HPT-IGT-
CF performs better when HPT is given a higher
weight than IGT in computing the trust degree of
HPT-IGT.
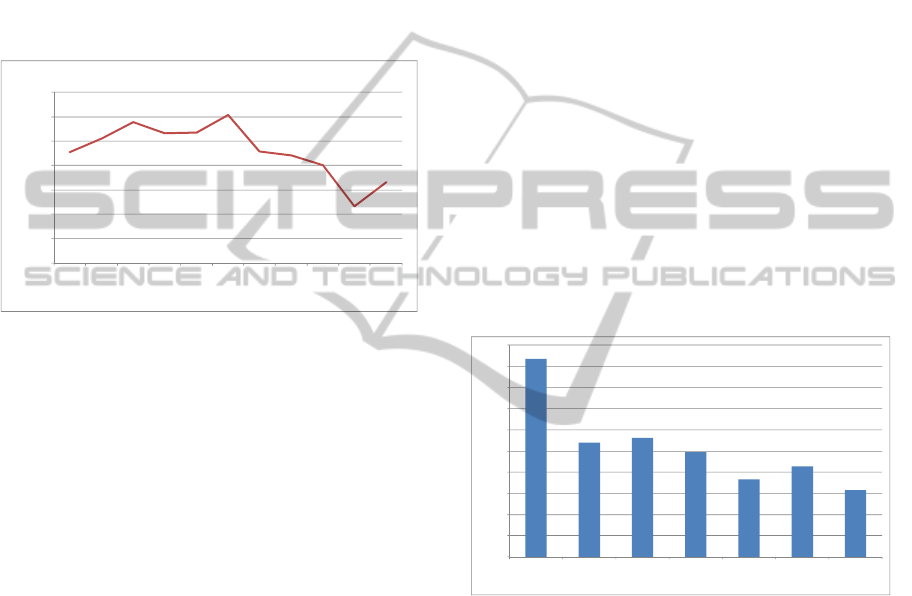
Figure 3: The MAEs of HPT-IGT-CF method under
different
β.
Figure 3 also shows the performance of HPT-CF
under
β
=1, where the predicted rating of a document
is derived totally by the HPT. When
β
= 0, the HPT-
IGT-CF becomes the IGT-CF, which derives the
predicted rating according to the IGT. The
experiment results show that the HPT-IGT-CF
performs better than HPT-CF and IGT-CF, while
HPT-CF performs better than IGT-CF. Thus, giving a
large weight to the HPT method in computing the
hybrid trust value of HPT-IGT, i.e. Eq. (6), is
reasonable. This implies that considering both the
personal and group perspectives in deriving the trust
values can better improve recommendation quality
than can the methods considering only personal trust
or group trust.
4.4 Comparison of all Methods
We compare our proposed methods, i.e., HPT-CF,
IGT-CF, and HPT-IGT-CF, with the CF method, and
other traditional trust-based recommendation
methods, i.e., ProfileT-US-CF and ItemT-US-CF, as
shown in Figure 4. The ItemT-US-CF/ProfileT-US-
CF method predicts users’ trust by computing the
ratio of accurate predictions that s/he has made to all
other users over a particular item/all items rated in
the past. The trust metrics of these two methods
ignore the group perspective. The suitable threshold
values for selecting trustworthy neighbors by ItemT-
US-CF and ProfileT-US-CF are set to 0.7 and 0.5,
respectively. Note that the two methods use the
harmonic mean of item-level/profile trust value and
user similarity as the weight to make predictions.
The group perspective can be considered in trust
computation to derive a reliable trust value, and
enhance the recommendation quality. The IGT-CF
method aggregates the opinions of the target user’s
group members on a specific item to derive the trust
value of a target user’s group on a recommender.
Both ItemT-US-CF and ProfileT-US-CF derive trust
values without considering group perspective. The
experiment result shows that IGT-CF has better
recommendation quality than both the ItemT-US-CF
and ProfileT-US-CF methods. In addition, the
conventional trust-based CF methods do not address
users’ role relationships in the computation of trust
values. For the trust models based on personal
perspective, the HPT-CF performs better than the
traditional trust-based recommendation methods,
including Personal-TCF, Item-US-CF, and Profile-
US-CF.
Figure 4: Comparison of all methods.
Moreover, our proposed trust methods, i.e., HPT-
CF, IGT-CF, and HPT-IGT-CF, perform better than
the conventional trust-based CF methods. The
traditional recommendation method, i.e., CF, has the
worst recommendation quality because it does not
consider the issue of trust between users. Therefore,
the trust models indeed contribute to improve the
recommendation quality. The result also shows that
the HPT-IGT-CF method performs better than HPT-
CF and IGT-CF methods. Recommending
documents from both personal and group
perspectives results in better performance than one
based on only one or the other. The hybrid trust
model can indeed enhance the trust models in order
to improve the recommendation quality.
0.64
0.65
0.66
0.67
0.68
0.69
0.7
0.71
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
MAE
β
H P T- I G T- C F
0.60
0.62
0.64
0.66
0.68
0.70
0.72
0.74
0.76
0.78
0.80
CF ItemT-US-CF ProfileT-US-CF PersonalT-CF HPT-CF IGT-CF HPT-IGT-CF
MAE
Methods
ApplyingPersonalandGroup-basedTrustModelsinDocumentRecommendation
37

5 CONCLUSIONS
In this work, we proposed document
recommendation methods based on hybrids of
personal and group trust models. Such hybrid
models are used to compute users’ trust values from
the personal and group perspectives in order to
discover reliable and trustworthy users in the
recommendation process. In considering these two
perspectives, three trust models are proposed,
namely the hybrid personal trust (HPT), item-level
group trust (IGT), and a hybrid of HPT and IGT
(HPT-IGT). From the personal perspective, HPT
adaptively not only takes users’ ratings on co-rated
documents, but also the role relationship trust into
account in trust computation. From the group
perspective, IGT derives the trust value of a target
user’s group on a recommender by using users’ role
weights to aggregate the opinions of the target user’s
group members on a specific item.
Moreover, to take advantage of the merits of both
HPT and IGT models, we also propose a hybrid of
HPT and IGT (HPT-IGT) models in order to obtain
trust values by considering both the personal and
group aspects. A target user usually has preferences
similar to his group members’, such that a
recommender trusted by his group members may
also be trusted by the user. The experiment result
shows that the trust value of IGT can indeed
complement the trustworthiness of personal
perspective. Additionally, the prediction accuracy of
recommendation is indeed improved using the HPT,
IGT, and HPT-IGT models. Our proposed methods
not only intensify the prediction accuracy of trust,
but also offer better improvement of
recommendation quality than other trust-based CF
methods.
ACKNOWLEDGEMENTS
This research was partially supported by the
National Science Council of the Taiwan under the
grant NSC 100-2410-H-033-037.
REFERENCES
Cho, J., Kwon, K. & Park, Y. 2007. Collaborative filtering
using dual information sources.
IEEE Intelligent
Systems,
22, 30-38.
Hwang, C.-S. & Chen, Y.-P. 2007. Using trust in
collaborative filtering recommendation. In: OKUNO,
H. & Ali, M. (eds.)
New Trends in Applied Artificial
Intelligence.
Springer Berlin / Heidelberg.
Jain, A. K., Murty, M. N. & Flynn, P. J., 1999. Data
clustering: a review. ACM Computing Surveys (CSUR),
31, 264-323.
Kim, D. J., Ferrin, D. L. & Rao, H. R., 2008. A trust-based
consumer decision-making model in electronic
commerce: The role of trust, perceived risk, and their
antecedents.
Decision Support Systems, 44, 544-564.
Konstan, J. A., Miller, B. N., Maltz, D., Herlocker, J. L.,
Gordon, L. R. & Riedl, J., 1997. GroupLens: Applying
collaborative filtering to Usenet news.
Communications of the ACM, 40, 77-87.
Lathia, N., Hailes, S. & Capra, L., 2008. Trust-based
collaborative filtering. In: Karabulut, Y., Mitchell, J.,
Herrmann, P. & Jensen, C. (eds.)
Trust Management II.
Springer Boston.
Liu, D.-R., Lai, C.-H. & Chiu, H., 2011. Sequence-based
trust in collaborative filtering for document
recommendation. International Journal of Human-
Computer Studies,
69, 587-601.
Massa, P. & Avesani, P., 2004. Trust-aware collaborative
filtering for recommender systems. On the Move to
Meaningful Internet Systems: CoopIS, DOA, and
ODBASE.
Springer Berlin / Heidelberg.
Massa, P. & Avesani, P., 2007a. Trust-aware
recommender systems. Proceedings of the ACM
Conference on Recommender Systems.
Minneapolis,
MN, USA: ACM.
Massa, P. & Avesani, P., 2007b. Trust metrics on
controversial users: Balancing between tyranny of the
majority. International Journal on Semantic Web &
Information Systems,
3, 39-64.
Massa, P. & Bhattacharjee, B., 2004. Using trust in
recommender systems: An experimental analysis. In:
JENSEN, C., POSLAD, S. & DIMITRAKOS, T. (eds.)
Trust Management. Springer Berlin / Heidelberg.
O'donovan, J. & Smyth, B., 2005. Trust in recommender
systems.
Proceedings of the 10th International
Conference on Intelligent User Interfaces.
San Diego,
California, USA: ACM.
Resnick, P., Iacovou, N., Suchak, M., Bergstrom, P. &
Riedl, J., 1994. GroupLens: an open architecture for
collaborative filtering of netnews.
Proceedings of the
ACM Conference on Computer Supported Cooperative
Work.
Chapel Hill, North Carolina, United States:
ACM.
Riggs, T. & Wilensky, R., 2001. An algorithm for
automated rating of reviewers.
Proceedings of the 1st
ACM/IEEE-CS Joint Conference on Digital Libraries.
Roanoke, Virginia, United States: ACM.
Salton, G. & Buckley, C., 1988. Term weighting
approaches in automatic text retrieval.
Information
Processing and Management,
24, 513-523.
Schafer, J., Frankowski, D., Herlocker, J. & Sen, S. 2007.
Collaborative filtering recommender systems. In:
Brusilovsky, P., Kobsa, A. & Nejdl, W. (eds.)
The
Adaptive Web.
Springer Berlin / Heidelberg.
DATA2012-InternationalConferenceonDataTechnologiesandApplications
38
