
Self-organizing Contents
Agostino Forestiero
Institute for High Performance Computing and Networking, ICAR-CNR,
Via Pietro Bucci, 41C 87036 Rende (CS), Italy
Keywords:
Content Delivery Networks, Self-organizing Agents.
Abstract:
To delivery static contents, Content Delivery Networks (CDNs) are an effective solution, but that shows its
limits in dynamic and large systems with centralized approach. Decentralized algorithms and protocols can
be usefully employed to tackle this weakness. A biologically inspired algorithm to organize the contents in a
Content Delivery Networks, is proposed in this paper. Mobile and bio-inspired agents move and logically re-
organize the metadata that describe the contents to improve discovery operation. Experimental results confirm
the efficacy of the self-organizing and decentralized algorithm.
1 INTRODUCTION
Content Delivery Networks are an efficient alterna-
tive to deliver static contents, as video on-demand,
TV broadcasts, media streaming services, pay-per-
use software or pay-per-download music, etc, to the
centralized approach. A group of users, can select,
simultaneously watch all and share the control of a
multimedia session, thanks to the collaborative play-
back services provided by such networks. The per-
formance, in terms of response time, accessibility and
bandwidth, of Internet-based content delivery by co-
ordinated content replication, can be improved ex-
ploiting CDNs. A group of clusters of surrogate
servers, located at the network edge, are maintained
and geographically distributed. Nowadays, many as-
pects of Content Networks get better in the available
content, the number of hosts and servers, the kind and
the number of the users and the number of services
where real time and bandwidth that can be exploited.
The best surrogate servers - that store copies of the
content - can satisfy the user requests. Hence, a sys-
tem and a mechanisms to provide contents and ser-
vices in a scalable manner, should be offered. With
the explosion of social networks and P2P technolo-
gies, the content is incredibly increased, such as the
exploitation of the Cloud Computing paradigm, in
which numerous server hosts located in the ”Clouds”
manage the contents and the services. However, to
perform retrieval or access operations, current appli-
cations that create, modify and manage the content,
and actively place it at appropriate locations, are of-
ten insufficient. Decentralized algorithms and proto-
cols, such as peer-to-peer (P2P) and multi agent sys-
tems, can be useful to deal with new technologies and
complex paradigms (Fortino and Mastroianni, 2009).
Small- or medium-sized networks can be acceptably
tackled with a centralized approach owing to its poor
scalability. But, the CDN paradigm shows its limits in
large and dynamic systems as the big-sized networks.
In this paper an algorithm that exploits nature-
inspired agents to organize the contents in Content
Delivery Networks, is presented. The metadata that
describe the content are moved and logically orga-
nized by the agents to improve information retrieval
operations. The relocation of the metadata is driven
by behavior of agents. The metadata are indexed by
binary strings obtained as result of the application of
a locality preserving hash function. The locality pre-
serving hash function is tailored to map similar re-
sources into similar metadata. It can have several dif-
ferent meanings, for example, each bit can represent
the absence or presence of a given topic. To guarantee
that similar resources are associated to similar binary
strings, an hash function locality preserving must be
used. Agents move across the network through the
peer to peer interconnections moving the metadata.
The similar metadata, representing similar resources,
are located into the same or in a neighbor host/server.
The host and the metadata in not hardly associated,
but easily adapts to the different conditions of the net-
work.
The logical reorganization performed thanks to
the self organizing and adaptive behavior of the pro-
534
Forestiero A..
Self-organizing Contents.
DOI: 10.5220/0004972405340538
In Proceedings of the 16th International Conference on Enterprise Information Systems (ICEIS-2014), pages 534-538
ISBN: 978-989-758-027-7
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)

posed algorithm allows to exploit the benefits of struc-
tured and unstructured approach of the peer to peer
systems. The approach here analyzed is basically un-
structured and then it is easy to maintain in a dy-
namic environment where the departures and arrivals
of hosts can be frequent events. The logical reorga-
nization of the metadata can improve the rapidity and
effectiveness of discovery operations, and moreover,
it is possible perform range queries, which is typical
feature of structured peer to peer systems. In fact,
thanks to the features of hash function, the metadata
with few different bits will be located in neighboring
regions. To measure the similarity between two meta-
data the Hamming distance or the cosine of the angle
between the related vectors can be used. In section 3
a brief description of the nature-inspired algorithm is
given, but further details can be found on (Forestiero
and Mastroianni, 2009), in which a similar algorithm
was exploitedfor building a Grid InformationSystem.
2 RELATED WORKS
Hybrid approach between CDN and P2P was ana-
lyzed by several studies, but while (Kang and Yin,
2010) (Huang et al., 2008) proposed further steps into
the use of P2P to deliver multimedia content, (Mu-
lerikkal and Khalil, 2007) (Guomin et al., 2006) ex-
ploit the P2P overlay for surrogate cooperation while
leaving the clients are regular non-cooperative enti-
ties. (Xu et al., 2006) a collaboration between clients
is proposed, but clients cannot receive data from dif-
ferent sources, such as from the peering community
and CDN entities at the same time. The dynamic
nature of the today’s networks and the large variety
of the resources make the management and discovery
operations more troublesome. Administrative bottle-
necks and low scalability of centralized systems are
becoming unbearable. Innovative approaches need to
have properties as self-organization, decentralization
and adaptivity. Erdil et al. in (Erdil et al., 2006)
outline the requirements and properties of self orga-
nizing grids. Reorganization of resources to facili-
tate discovery operations and adaptive dissemination
of information, were introduced and applied in the
approach here presented. A class of agent systems
which aims to solve very complex problems by imi-
tating the behavior of some in species of ants as in-
troduced in (Bonabeau et al., 1999). In (Forestiero
et al., 2008b) and (Forestiero et al., 2008a), the perfor-
mance of discovery operations are improved through
the creation of Grid regions specialized in a particular
class of resources. Whereas (Van Dyke Parunak et al.,
2005) proposes a decentralized scheme to tune the ac-
tivity of a single agent. These systems are positioned
along a research avenue whose objective is to devise
possible applications of ant algorithms (Bonabeau
et al., 1999) (Dorigo et al., 2000). A tree-based
ant colony algorithm to support large-scale Internet-
based live video streaming broadcast in CDNs, was
proposed in (Liu et al., 2012). In this paper, differ-
ently from the traditional solution to find paths, an
algorithm to optimize the multicast tree directly and
integrate them into a multicast tree, was introduced.
3 SELF-ORGANIZING
ALGORITHM
The work of the nature inspired agents is profitably
exploited to logically reorganizethe metadata. Agents
move among hosts performing simple operations.
When an agent arrives to an host and it does’not carry
any metadata, it decides whether or not to pick one
or more metadata from the current host. While when
arrives to an host and the agent is loaded, it decides
whether or not to leave one or more metadata in the
local host. A couple of probability functions drive
agent’s decision. The probability functions are based
on a similarity function (Lumer and Faieta, 1994),
that is:
sim( ¯m, Reg) =
1
Num
m
∑
mεReg
1−
Hamming(m, ¯m)
α
(1)
The similarity of a metadata m with all the meta-
data located in the region Reg, is measured through
the function sim. The region Reg for each host h, is
represented by h and of all host reachable from h with
a given number of hops. Here it is set to 1. Num
m
is
the overall number of metadata located in Reg, while
Hamming(m, ¯m) is the Hamming distance between m
and ¯m. The similarity scale α is set to 2. The value of
sim ranges between -1 and 1, but negative values are
septated to 0. The probability function of picking a
metadata from an host will be inversely proportional
to the similarity function sim. Vice versa, the prob-
ability function of dropping a metadata will be di-
rectly proportional to the similarity function sim. The
probability functions of picking a metadata P
1
and the
probability function of leaving a metadata P
2
, are:
P
1
= (
k1
k1+ sim( ¯m, Reg)
)
2
; (2)
P
2
= (
sim( ¯m, Reg)
k2+ sim( ¯m, Reg)
)
2
(3)
Self-organizingContents
535
The degree of similarity among metadata can be
refined through the parameter k1 and k2, that have
values comprised between 0 and 1 (Bonabeau et al.,
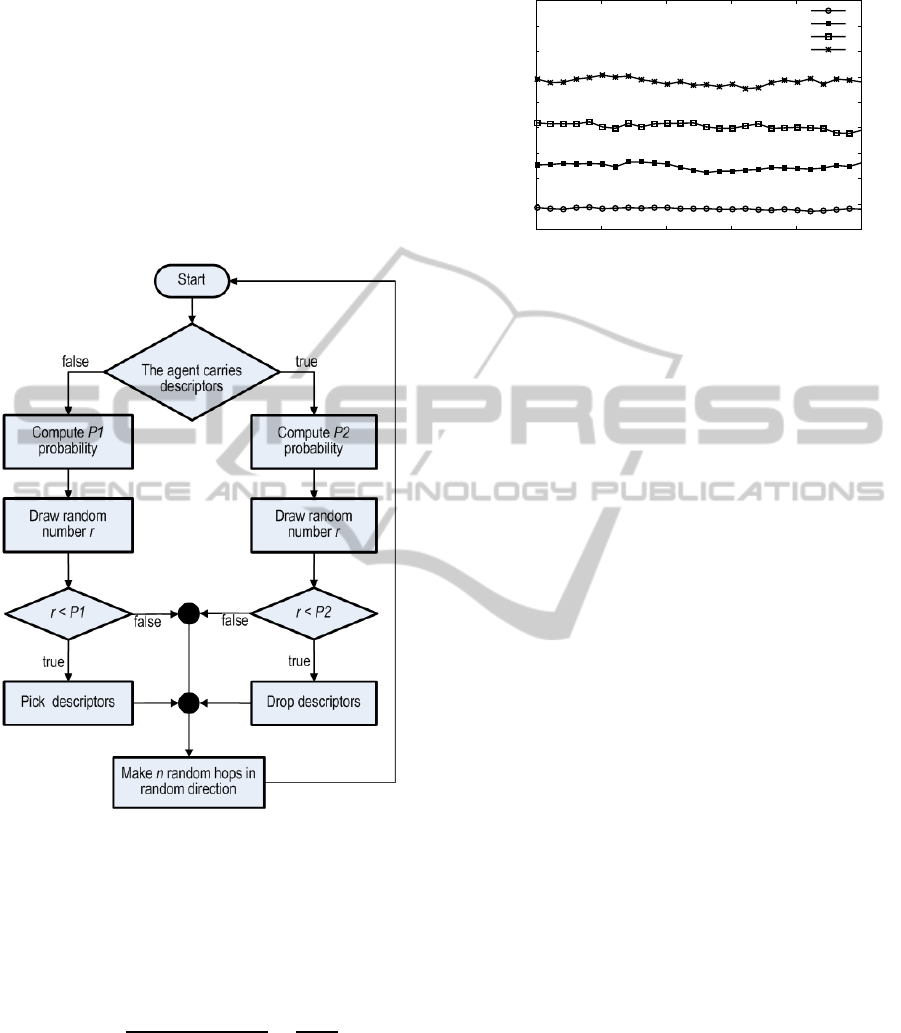
1999). The flowchart showed in Figure 1 gives an
high-level description of the algorithm performed by
mobile agents. Cyclically, the agents perform a given
number of hops among servers, and when they get to
a server, they decide which probability function com-
pute based on their load. If the agent does not carries
metadata it computes P
1
, otherwise if the agent carries
metadata the P
2
probability is computed.
Figure 1: The algorithm performed by the agents.
The processing load Load, that is the average
number of agents per second that are processed by
a server, does not depend neither on the network size
nor on the churn rate, but only depends on the num-
ber of agents and the frequency of their movements
across the network. Load can be obtained as:
Load =
n.ofagent
n.ofserver· T
move
=
F
gen
T
move
(4)
where T
move
is the average time between two suc-
cessive movement of an agent and F
gen
is the mean
number of agents generated by a single server. In a
typical scenario, T
move
is set to 60 sec and F
gen
is set to
0.5, so that each server receives and processes about
one agent every 120 seconds, which can be consid-
ered an acceptable load. Note that the processing load
does not depend on other system parameters such as
0
0.005
0.01
0.015
0.02
0.025
0.03
0.035
0.04
0.045
0 20000 40000 60000 80000 100000
Traffic load (agents/s)
Time(s)
hop = 1
hop = 3
hop = 5
hop = 7
Figure 2: The traffic generated by the algorithm when the
number of hops performed within a single agent movement
ranges from 1 to 7.
the average number of resources handled by a server
or the number of server, which is a further confirma-
tion of the scalability properties of the algorithm.
The traffic load, that is the number of agents that
go through a server per unit time, was calculated and
shown in Figure 2. As showed, the value of traf-
fic load changes according to the maximum number
of hops performed within a single agent movement.
During the simulations, it was noted that the reorgani-
zation of metadata is accelerated if agent movements
are longer,because they can explore the network more
quickly. To choice of the number of hops is necessary
a compromise between the level of the traffic load tol-
erable and the rapidity and efficiency of the reorgani-
zation process.
The effectiveness of the algorithm has been evalu-
ated exploiting the spatial homogeneity function. By
averaging over the whole network the Hamming dis-
tance between every couple of metadata, we obtained
the average homogeneity Homogeneity of the meta-
data in the region Reg related to the host h, this is:
AVG = Average
m, ¯mεReg
(Hamming(m, ¯m)
Homogeneity
h
= n.ofbits− AVG (5)
When the similar metadata are collected in the
same region, the value of homogeneity function in-
creases. A graphical description of the logical reorga-
nization achieved by agents, in Figure 3 is reported.
Here, each metadata is associated to a color. The
network is photographed at Time = 0 sec, when the
process is starting and the metadata are randomly dis-
tributed in a random fashion and at Time = 50.000 sec
when the process is in a steady situation.
Notice that similar metadata are located in the
same region and between near region the color change
ICEIS2014-16thInternationalConferenceonEnterpriseInformationSystems
536
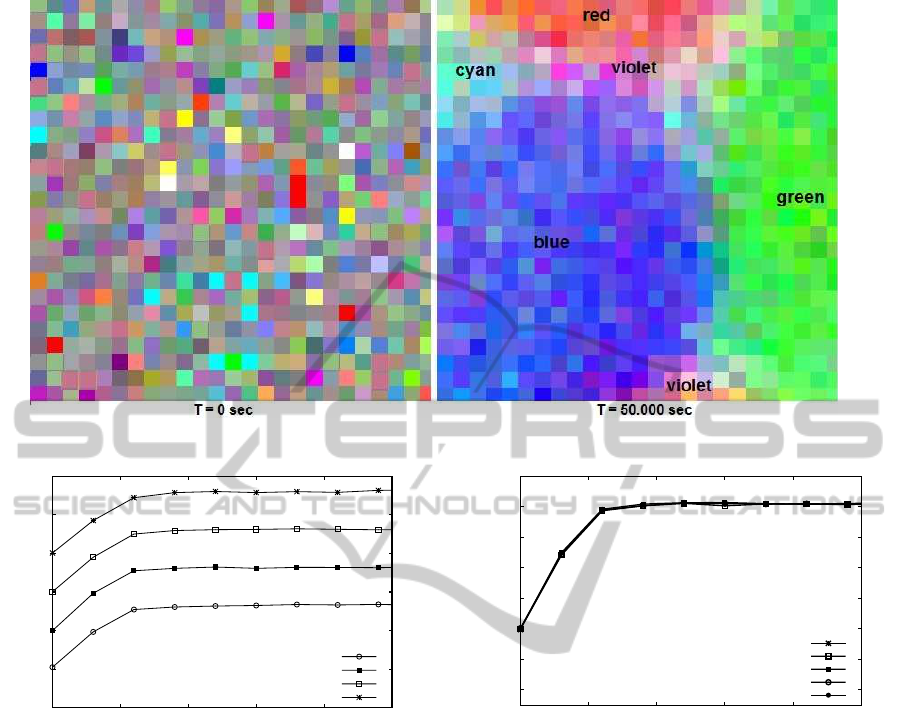
Figure 3: Snapshots of the system when the process is starting, and when the process is in a steady situation.
1
1.5
2
2.5
3
3.5
4
10000080000600004000020000 0
Homogeneity
Time(s)
n. of bits = 3
n. of bits = 4
n. of bits = 5
n. of bits = 6
Figure 4: Homogeneity of the whole network when the
number of bit of the binary string representing the content
ranges from 3 to 6.
gradually, which proves the spatial sorting on the net-
work. In Figure 4 the overall homogeneity when the
number of bit of the metadata describing the con-
tent, is varied. We can see as the logical reorga-
nization is obtained independently of the number of
bits. To confirm the scalability nature of the algo-
rithm, which derives from its decentralized and self-
organizing characteristics, its behavior when number
of involved servers changes from 1000 to 7000, was
analyzed and reported in Figure 5. Notice that the
size of the network, that is the number of servers in-
volved in the logical organization of contents, has no
detectable effect on the performance, as overall ho-
mogeneity index.
1.6
1.8
2
2.2
2.4
2.6
2.8
3
0 20000 40000 60000 80000 100000
Homogeneity
Time(s)
n. of servers = 500
n. of servers = 1000
n. of servers = 2000
n. of servers = 4000
n. of servers = 8000
Figure 5: Homogeneity, vs. time, for different values of the
number of servers.
4 CONCLUSIONS
In this paper a nature inspired approach to build a P2P
information system for CDNs, was proposed. Thanks
to its swarm intelligence characteristics, the proposed
algorithm features fully decentralization, adaptivity
and self-organization. Ant-inspired agents move and
logically reorganize the metadata representing the
contents. Agent’s operations are driven by simple
probability functions that are evaluated when the
agent gets to a new server. In this way, similar
metadata representing similar contents are placed in
the same region, that is in neighbor server. Moreover,
the reorganization of metadata spontaneously adapts
to the ever changing environment as the joins and de-
parts of servers and the changing of the characteristics
Self-organizingContents
537

of the contents. The experimental results proved the
effectiveness of the algorithm.
REFERENCES
Bonabeau, E., Dorigo, M., and Theraulaz, G. (1999).
Swarm intelligence: from natural to artificial systems,
volume 4. Oxford university press New York.
Dorigo, M., Bonabeau, E., and Theraulaz, G. (2000). Ant
algorithms and stigmergy. Future Generation Com-
puter Systems, 16(8):851–871.
Erdil, D. C., Lewis, M. J., and Abu-Ghazaleh, N. B. (2006).
Adaptive approach to information dissemination in
self-organizing grids. In Autonomic and Autonomous
Systems, 2006. ICAS’06. 2006 International Confer-
ence on, pages 55–55. IEEE.
Forestiero, A. and Mastroianni, C. (2009). A swarm al-
gorithm for a self-structured p2p information sys-
tem. Evolutionary Computation, IEEE Transactions
on, 13(4):681–694.
Forestiero, A., Mastroianni, C., and Spezzano, G. (2008a).
Reorganization and discovery of grid information with
epidemic tuning. Future Generation Computer Sys-
tems, 24(8):788–797.
Forestiero, A., Mastroianni, C., and Spezzano, G. (2008b).
So-grid: A self-organizing grid featuring bio-inspired
algorithms. ACM Transactions on Autonomous and
Adaptive Systems (TAAS), 3(2):5.
Fortino, G. and Mastroianni, C. (2009). Next generation
content networks. Journal on Network and Computing
Applications, 32(5):941–942.
Guomin, Z., Changyou, X., and Ming, C. (2006). A
distributed multimedia cdn model with p2p architec-
ture. In Communications and Information Technolo-
gies, 2006. ISCIT’06. International Symposium on,
pages 152–156. IEEE.
Huang, C., Wang, A., Li, J., and Ross, K. W. (2008). Under-
standing hybrid cdn-p2p: why limelight needs its own
red swoosh. In Proceedings of the 18th International
Workshop on Network and Operating Systems Support
for Digital Audio and Video, pages 75–80. ACM.
Kang, S. and Yin, H. (2010). A hybrid cdn-p2p sys-
tem for video-on-demand. In Future Networks, 2010.
ICFN’10. Second International Conference on, pages
309–313. IEEE.
Liu, G., Wang, H., and Zhang, H. (2012). An ant colony
optimization algorithm for overlay backbone multi-
cast routing in content delivery networks. In Trust,
Security and Privacy in Computing and Communica-
tions (TrustCom), 2012 IEEE 11th International Con-
ference on, pages 1878–1882. IEEE.
Lumer, E. D. and Faieta, B. (1994). Diversity and adapta-
tion in populations of clustering ants. In Proceedings
of the Third International Conference on Simulation
of Adaptive Behavior : From Animals to Animats 3:
From Animals to Animats 3, SAB94, pages 501–508.
MIT Press.
Mulerikkal, J. P. and Khalil, I. (2007). An architecture for
distributed content delivery network. In Networks,
2007. ICON 2007. 15th IEEE International Confer-
ence on, pages 359–364. IEEE.
Van Dyke Parunak, H., Brueckner, S. A., Matthews, R.,
and Sauter, J. (2005). Pheromone learning for self-
organizing agents. Systems, Man and Cybernetics,
Part A: Systems and Humans, IEEE Transactions on,
35(3):316–326.
Xu, D., Kulkarni, S. S., Rosenberg, C., and Chai, H.-K.
(2006). Analysis of a cdn–p2p hybrid architecture for
cost-effective streaming media distribution. Multime-
dia Systems, 11(4):383–399.
ICEIS2014-16thInternationalConferenceonEnterpriseInformationSystems
538
