
Highly Scalable Microservice-based Enterprise Architecture for
Smart Ecosystems in Hybrid Cloud Environments
Daniel M
¨
ussig
1
, Robert Stricker
2
, J
¨
org L
¨
assig
1,2
and Jens Heider
1
1
University of Applied Sciences Zittau/ G
¨
orlitz, Br
¨
uckenstrasse 1, G
¨
orlitz, Germany
2
Institutsteil Angewandte Systemtechnik AST, Fraunhofer-Institut f
¨
ur Optronik, Systemtechnik und Bildauswertung IOSB,
Am Vogelherd 50, Ilmenau, Germany
Keywords:
Cloud, IT-Infrastructure, Scaling, Microservices, Application Container, Security, Authorization Pattern.
Abstract:
Conventional scaling strategies based on general metrics such as technical RAM or CPU measures are not
aligned with the business and hence often lack precision flexibility. First, the paper argues that custom metrics
for scaling, load balancing and load prediction result in better business-alignment of the scaling behavior
as well as cost reduction. Furthermore, due to scaling requirements of structural –non-business– services,
existing authorization patterns such as API-gateways result in inefficient scaling behavior. By introducing
a new pattern for authorization processes, the scalability can be optimized. In sum, the changes result in
improvements of not only scalability but also availability, robustness and improved security characteristics of
the infrastructure. Beyond this, resource optimization and hence cost reduction can be achieved.
1 INTRODUCTION
The number of enterprises using the cloud to host
their applications increases every year (Experton,
2016). Adopting the cloud has in essence two rea-
sons: first, more flexibility and in general better per-
formance. Second, the pay-per-use model is more
cost effective than hosting own servers. However,
these advantages are only achieved, if the cloud is
used efficiently. Thus, the fast provisioning and re-
lease of resources should be optimised for each ap-
plication. Therefore, an application has to be able to
scale with the demand.
To specify scalability, the AKF scale cube defines
three different dimensions of scaling (Abbott and
Fisher, 2015): The horizontal duplication produces
several clones, which have to be load balanced. The
Split by function approach is equivalent to splitting a
monolith application in several microservices (New-
man, 2015), scaling them individually. The last di-
mension is called split by customer or region and ap-
plied for optimizing worldwide usage and service-
level specific performance. While all three dimen-
sions are compatible, only the first two of them are
relevant for our considerations here. Current scaling
solutions are using general metrics, namely CPU and
RAM, for the horizontal duplication and load balanc-
ing. A general drawback of these approaches is that
they are not able to describe the utilization of a service
precisely. E. g. services with a queue have mostly a
stable CPU utilization, no matter how many requests
are in the queue. There are already metrics using the
queue length, but therefore each entity would need to
have the same run time.
Another issue with efficient scaling of cloud in-
frastructures is connected to the high priority of secu-
rity aspects and the rigorous implementation of secu-
rity and authorization patterns. Looking at conven-
tional authorization patterns, which are quickly re-
viewed in the paper, their scaling behaviour turns out
to be limited due to the need of replication of services
which are only used for the authorization process. It
further turns out that there is a lack of several security
objectives such as availability or robustness.
We introduce and describe an infrastructure,
which is able to dynamically scale itself according to
the used resources and predicted resource consump-
tion. It is not only able to start and stop replicas of
services, but also compute nodes. This is achieved by
using custom metrics instead of general metrics.
To address the inherent scaling problems of con-
ventional authorization pattern, we propose a new de-
sign approach for authorization in microservice archi-
tectures, which is able to utilize the benefits produced
454
Müssig, D., Stricker, R., Lässig, J. and Heider, J.
Highly Scalable Microservice-based Enterprise Architecture for Smart Ecosystems in Hybrid Cloud Environments.
DOI: 10.5220/0006373304540459
In Proceedings of the 19th International Conference on Enterprise Information Systems (ICEIS 2017) - Volume 3, pages 454-459
ISBN: 978-989-758-249-3
Copyright © 2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
by the scaling infrastructure by avoiding scaling of –
non-business– services. Our distribution concept even
results in better partition tolerance and has the ability
to achieve lower response times. In sum, the approach
should lead to a more efficient scaling of the cloud in-
frastructure, which is applicable in almost any cloud
environment.
The paper is structured as follows. In Section 2
we refer to current related approaches. Section 3 de-
scribes the key concept and essential services for a
flexible infrastructure design. Afterwards we describe
custom metrics that are used for optimized scaling of
the application in Section 3.3 and in Section 3.4 we
illustrate how highly scalable infrastructures can be
optimized by using machine learning algorithms. In
Section 4 we show weaknesses of common authoriza-
tion patterns and introduce details of a new approach.
The paper concludes with Section 5.
2 RELATED WORK
To the best of our knowledge, this is the first at-
tempt of a highly scalable enterprise architecture for
the cloud which is optimized with security by de-
sign instead of inhibition through security restrictions.
Toffetti et al. describe an architecture for microser-
vices, which is self-managed (Toffetti et al., 2015).
This architecture focuses on health management as
well as auto scaling services. However, this work
is based on etcd
1
and does not describe a generic
scalable microservices architecture. Furthermore, this
paper disregards the scaling of compute nodes and
security aspects. The API key distribution concept
seems to be similar to the whitelist configuration ap-
parently used by Google for the Inter-Service Access
Management
2
. A major difference is the ability to
update permissions during run time by using an ob-
server pattern in our approach. Additional security
aspects like network traffic monitoring and intrusion
detection can also be done in a microservice archi-
tecture (Sun et al., 2015). They use the perspective
on a microservice environment as a type of a network
as we do. Using docker container for our approach
we refer to (Manu et al., 2016) for docker specific se-
curity aspects. The potential scope of application is
quite extensive. E. g. (Heider and L
¨
assig, 2017) de-
scribe a development towards convergent infrastruc-
tures for municipalities as connecting platform for
different applications. The authors outline the need
1
https://github.com/coreos/etcd
2
https://cloud.google.com/security/security-
design/#inter-service access management
for high scalability and security as there are require-
ments for high computational power and extensive
data exchange in many use cases, if different plat-
forms are tied closely together and considered as con-
nected infrastructure landscape.
3 EFFECTIVE
INFRASTRUCTURE-
MANAGEMENT
Running an infrastructure is connected with high
costs and administrative effort. As mentioned before,
the number of enterprises migrating to the cloud is
increasing, since the cloud promises advantages in
cost and administration efficiency. In this section we
present our approach of an intelligent infrastructure,
which is capable of up- and down-scaling the number
of used compute nodes as well as service instances.
The model is very general and can be deployed anal-
ogously in many use cases.
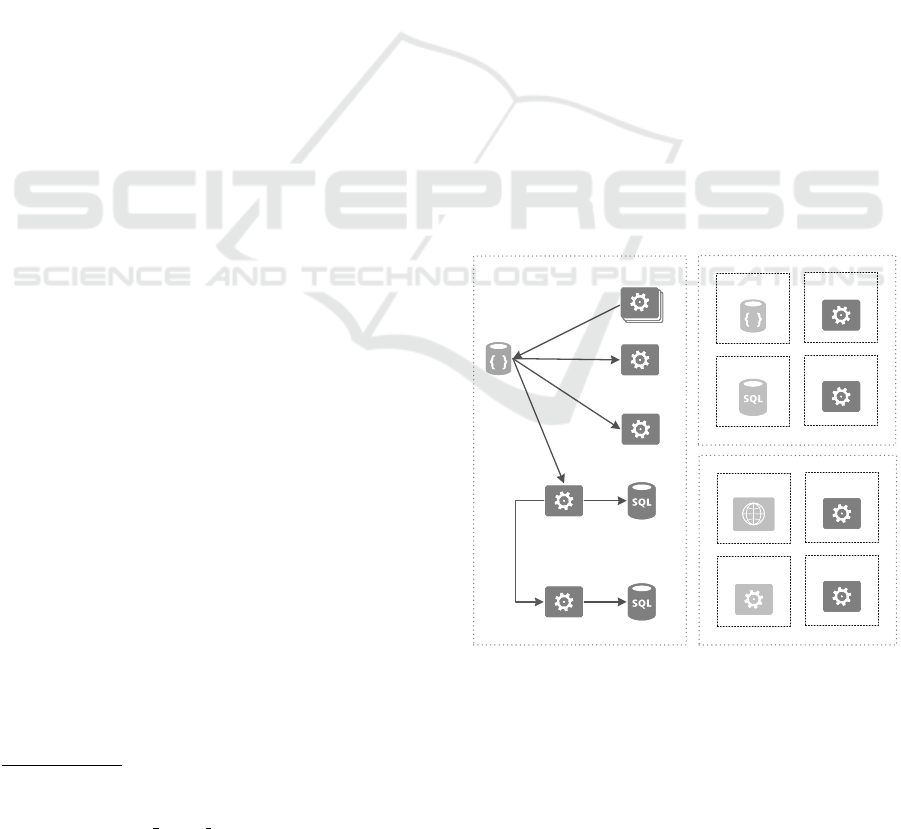
3.1 Services
The proposed architecture consists of several ser-
vices, which are operational. These are shown in
Figure 1. The services run similar to the bussiness
Container
Container
Container
Container
Container
Container
Container
VM
VM
Container/ServicesContainer/Services
MachinesMachines
System Load
Balancer
System Load
Balancer
User Load
Balancer
User Load
Balancer
Load-ReceiverLoad-Receiver
Container
Commandline-
Executer
Commandline-
Executer
VM-Load-
Transmitter
VM-Load-
Transmitter
Redis DBRedis DB
Container-
Manager
Container-
Manager
VM-ManagerVM-Manager
anywhere
Figure 1: The architecture is managed by six operational
services. Each service sends its utilization to the load-
receiver, which stores the information in an in-memory db.
The loadbalancer uses the information to balance the re-
quests and the container manager is scaling the services. To
scale the number of compute nodes, the information of the
VM load transmitter is used. The commandline executor
receives instructions from the machine manager to create or
delete compute nodes.
Highly Scalable Microservice-based Enterprise Architecture for Smart Ecosystems in Hybrid Cloud Environments
455

services in their own container and are divided in
the groups: node-specific services, self-contained ser-
vices and system services. While the services of
the first group, such as the load balancer and the
databases, run on specific compute nodes, services
of the second group are independent from the node
they run on. The load-receiver, container-manager
and machine-manager belong to this group and can
run on every compute node. The third group contains
services which are running in addition to the applica-
tion services on each compute node. These services
are the VM-load-transmitter and the commandline-
executor. We assume, that there is an interface, which
could be used to create and delete compute nodes.
Most cloud providers and private cloud frameworks
such as OpenStack already offer similar services.
The commandline-executor is used to create and
delete containers. This service receives commands
e. g. via a POST-REST call and executes them on
the compute node. Only this service can access the
container engine of the compute node. To ensure that
there is no unauthorized usage of the service, it is only
accessible by the container-manager.
The other service which has to run on every com-
pute node is the VM-load-transmitter. This service
monitors the utilization of the compute node. The
measurements of cpu, ram, bandwidth and used disk
space are sent to the machine-manager. These infor-
mation are used to determine if machines have to be
started or stopped.
The machine-manager stores information about
the environment. In most cases there are many dif-
ferent types of compute nodes which can be ordered
or created. They differ in the amount of processors,
their performance, ram, disk space and disk type. The
available types have to be defined and configured. The
service stores the commands to start or stop/delete
such a compute node. Besides this the service stores
also the maximum number of compute nodes of the
same type that are allowed to run. This mechanism
is intended to restrict the costs. It is also possible
to store cost limits, e. g. the maximum amount to be
spent per month.
Once the machine-manager starts a compute node,
the service stores information about it. These consist
of its IP address, but also the type of compute node
and whether the compute node is allowed to be shut-
down or not. This design feature is important since
the infrastructure requires some static parts, e. g. ma-
chines to run databases or to store certain informa-
tion in general. Besides indicating the application of
a machine, its type is also used to determine the com-
pute node, on which an instance of a service should
be executed. E. g. databases usually require fast disks
to run with good performance, while a machine that
is running compute services needs a cpu with more
performance. The machine-manager stores statistics
about the compute node e. g. cpu utilization, used
ram, bandwidth and used disk space. All information
should be stored with time stamps, as we explain in
detail later.
The container-manager controls the services. As
initial step, every new service has to be registered.
This can be part of the deployment process. For
a registered service at least the following informa-
tion should be stored: name, minimum number of
instances, maximum number of instances, the start
and stop commands, bool value if load balancing is
required and requirements for the node (e. g. the
name of a particular compute note, if specified). For
an efficient management of the instances, also in-
formation about the resource consumption should be
stored. If an instance of a service is executed, the
IP of the machine and the port where the service can
be reached, should be stored in a service registry.
The IP address also corresponds the commandline-
executor. If the average load of all instances of a ser-
vice is above or below a certain percentage in a given
time frame, the container-manger can take action and
scales the service up or down. The container-manager
sends a request to the machine-manager to decide on
which compute node the instance should be started
or stopped. In general the container-manager stores
information about the utilization of containers using
custom metrics and the number of instances of a ser-
vice, which is discussed in detail in Section 3.3.
3.2 Load Balancing
The load balancer and the load-receiver are using
the same database, preferably an in-memory database
such as redis
3
. The latter receives the utilization of the
custom metric from the instance and stores it in the
database. Redis supports sorted sets. This makes it
possible to store the information in the right order for
the load balancer, so that reading from the database
has the least effort. We are using a set for each ser-
vice, resulting in multiple scoreboards.
For load balancing a NAT proxy with feedback
method can be used. With this method the load bal-
ancer can handle requests with different durations
much better than other approaches such as round
robin. But also due to the frequently starting and
stopping of machines and containers other methods
apart from this and the round robin approach wouldn’t
work. The load balancer and the in-memory database
which stores the utilization should run on the same
3
https://redis.io
ICEIS 2017 - 19th International Conference on Enterprise Information Systems
456

compute node to lower the latency. With increasing
number of requests the load balancer has to be scaled.
There are already approaches such as (Shabtey, 2010).
However we consider to use a different approach. We
want to use, if needed, a load balancer for user re-
quests and a load balancer for inter service commu-
nication. If it has to be scaled further we recommend
to use a load balancer for each heavy used service to
avoid having more than one load balancer per service.
Since the requests are referred in our architecture to
different instances of services a special security pat-
tern is needed, which authenticates each request. A
further discussion on this topic is given in Section 4.
3.3 Custom Metrics
Recently, there are many articles which describe that
only a small number of services or applications could
be efficiently scaled using a CPU and/or RAM metric.
To encounter this, our approach uses custom metrics,
which are defined for each service separately. This
is done by the developers of the service, since they
have most knowledge about it. So they can define it
e. g. as the internal queue length or progress of an al-
gorithm. The service sends than a percentage between
0 and 100 to the load-receiver in a self defined inter-
val. Utilization of services should be between 60 and
80 percent. When there is only one replica it is scaled
up at 60 percent. The percentage where a scaling is
done increases with the number of replicas. The steps
could be also defined in the container-manager. Since
it takes some time to rebalance when an instance is
started or stopped, the developers also define a warm
up and cool down time for the service. The former de-
scribes the time which is needed for starting a new in-
stance and distribute new incoming requests equally.
To the contrary, the latter describes the time which is
needed on average to stop an instance after all pend-
ing requests on this instance were finished.
3.4 Enhanced Infrastructure
Management
Infrastructure management could be enhanced fur-
ther using machine learning techniques (Ullrich and
L
¨
assig, 2013). Since the services collect information
about the number of instances and machines as well
as their utilization with time and weekday, maching
learning algorithms can learn pattern and operate in
advance. This could be particularly useful for on-
line shops, but could be carried over to the most other
web-based services.
Besides this, machine learning algorithms could
also be used in other directions. Very important when
scaling services is the information about the duration
till the new instance is started and completely inte-
grated in the balancing. This is different from ser-
vice to service and depends even on the compute node
and where it is started. Furthermore, the machine-
manager learns the usual utilization of CPU and RAM
to enhance the decision on which a new instance
should be started to use the resources optimal.
4 SECURITY CHALLENGES
A flexible infrastructure architecture as presented in
this paper realizes a dynamic environment, which
practically ends up in a complex system of service in-
stances that can be removed or newly created imme-
diately and which are sending or receiving requests
permanently. One of the security objectives (in addi-
tion to the CIA triad) that have to be considered is au-
thorization, which is necessary for protection against
misuse. Accounting for the distributed character of
the services, the CAP-Theorem has to be considered
as well. We investigate some common authorization
principles concerning the compatibility with our pre-
sented infrastructure and point out their weaknesses
concerning other security objectives and system abil-
ities. Afterwards we propose our idea which is op-
timized to maximize the robustness, availability and
the scalability of each microservice.
4.1 Common Authorization Principles
The task of authorization is to answer the question
if a request to a microservice has to be fulfilled or re-
jected. There are several possibilities to design the au-
thentication and authorization process such as shown
in Figure 2.
request
API
gateway
request
auth-
service
A
B
C
A
B C
1
2
1
2
3
Figure 2: Common design patterns for authorization in a
microservice architecture with weaknesses in availability,
scalability and robustness.
In the first part of Figure 2 the API gateway pat-
tern
4
is shown. In security contexts the gateway
is called Application-Level-Gateway (ALG). All re-
quests were sent to the API gateway which routes
4
http://microservices.io/patterns/apigateway.html
Highly Scalable Microservice-based Enterprise Architecture for Smart Ecosystems in Hybrid Cloud Environments
457

them, creates access tokens, encrypts messages, etc.
There are significant advantages of this approach. The
real interface addresses (URLs) of the microservices
can be hidden, injection inspection or input valida-
tion (content-types, HTTP methods) can be realized
equivalently for each service. But for the authoriza-
tion process this service requires also a database con-
taining data for all services, which creates vulnerabil-
ities.
Also the second design approach is often used
for microservices. The request is sent directly to the
service which is able to fulfill it. The service itself
sends a new request to an authorization service (auth-
service), which checks whether the user (or other ser-
vice) has the permission to use the microservice (A).
If the requester is privileged, the microservice cal-
culates the response. One advantage of this process
chain is the separation of sensitive user data from the
open interfaces, another advantage is the less exten-
sive functionality of the auth-service compared to an
API gateway, which improves the authorization pro-
cess concerning response time. Tasks from the gate-
way such as validation has to be addressed by the
microservices additionally. A negative aspect is the
generation of traffic from the service (A) to the auth-
service for each incoming request. If an opponent
sends many requests during a (D)Dos attack, the pat-
tern supports him by multiplying each request. More-
over, an attack on service A even attacks the auth
service and can make it unavailable for the other ser-
vices. These and similar designs contain one single
point of failure and are vulnerable to DoS-Attacks on
one single service. The whole application is affected
if the management service is not available. Account-
ing for the dependency of the microservices from the
management services, they have to be scaled together.
The worst aspect of these designs is the dependency
between the microservices and the management ser-
vices from the count of requests, not of running ser-
vice instances.
4.2 API-Key-Distribution
Following our requirements, each microservice
should be able to fulfill a request without connect-
ing to another service. This makes the application not
only more secure but also faster. Hence, each service
requires a database to store information about valid
requesters. In more detail, each instance of a service
requires this data which consists of an API key and
maybe some additional information, such as the role
connected with a key. The key represents a service or
user, which is authorized to use it. We divide the life-
time of a service instance into two parts, the initial-
Figure 3: The two phases of API key distribution to realize
independence of each microservice from additional man-
agement services while fulfilling a request.
ization and the production phase. The initialization
phase starts immediately after the creation of a new
instance and the API Key distribution has to be done.
This is shown in the left part of Figure 3.
The newly created service instance registers on the
permission database and receives the API keys, there
is merely read-only access required. Note that several
instances of the same service get the same data.
In the production phase as shown in Figure 3, the
microservice is available for requests, which contain
the authentication data (API key) of the user or ser-
vice where the request comes from. Now our pre-
pared service instance is able to authorize this request
without connecting to other management services and
the response can be calculated immediately.
The services can easily be scaled by creating new
instances and going through the initialization process.
Maybe there is also a management service required
if direct communication with the database has to be
avoided, but this service is only essential during the
initialization phase. Afterwards there are no conse-
quences for the running instances if the service is not
available. Another difference is that the application
services only has to be scaled if the number of re-
quests is rising. The access to the permission database
depends only on the number of instances, not the
number of incoming requests. During the production
phase, changes in permission settings (adding a new
user for example) will be sent from the permission
database to the service instances based on the regis-
tering process during the initialization phase, which
is an observer pattern. At the end of the production
phase (removing the instance), the service instance
must be unregistered from the permission database.
Advantages of this approach besides improved scala-
bility and availability are reduced network traffic for
incoming requests and improved robustness.
The costs for these benefits are situated in terms
of consistency, because changes in permissions are
becoming active with a delay. With focus on re-
quests from each service to another, the availability
has higher priority than consistency, because permis-
sions did not change permanently.
ICEIS 2017 - 19th International Conference on Enterprise Information Systems
458

4.3 Secure Data Transmission
The network traffic (user to service and service
to service communication) can possibly be sniffed,
changed and interrupted by a man in the middle. The
assumption of an existing active adversary leads to se-
rious problems in secure communication, because we
can not exchange encryption keys between newly cre-
ated instances. The Diffie-Hellman key exchange is
vulnerable to this kind of attack as well (Johnston and
Gemmell, 2002), due to the lack of authentication.
Required is an information advantage, which
must be pre-distributed over a trusted channel (Gold-
wasser and Bellare, 2008). In the three party model
there is an authentication server which shares private
keys with each party and generates session keys for
each communication session. This has the disadvan-
tages of a centralized service. If we assume that ev-
ery service instance receives its own API key over an
trusted channel (e. g. in the Docker image) and the
permission database contains only non-compromised
data, the API keys can be used as information advan-
tage.
It is not necessary to authenticate each instance,
because the following authorization process is based
on the service level as described in Section 4.2. The
API key could also be used as secret for signing with
a HMAC, which can be used to authenticate a ser-
vice and verify the integrity of a request. Using this
approach we are able to use key exchange methods,
which results in the ability to ensure the confidentially
of a request.
5 CONCLUSION
In this position paper we describe the concept of a
high scalable microservice infrastructure using cus-
tom metrics in addition to common CPU and RAM
measurements. It uses resources more efficiently
for reducing costs in the public cloud and fewer
workload in the private cloud. The different opera-
tional services necessary for our approach can be ex-
panded with smart machine learning algorithms for
self-optimization and self healing.
The paper also proposes an authorization pattern
for the proposed microservice architecture, which
supports not only the scalability of our flexible infras-
tructure but also security objectives such as availabil-
ity and robustness.
We plan to implement our suggestions in a frame-
work which can be used easily to implement and opti-
mize a microservice architecture. Afterwards we plan
to apply the framework for an evaluation based on
different use cases and prototype implementations in
the Internet of Things context, such as Industry 4.0 or
Smart Home applications. The performance and flex-
ibility of the approach must be evaluated and com-
pared to other approaches based on different bench-
marks.
REFERENCES
Abbott, M. L. and Fisher, M. T. (2015). The Art of Scalabil-
ity: Scalable Web Architecture, Processes, and Orga-
nizations for the Modern Enterprise. Addison-Wesley
Professional, 2nd edition.
Experton (2016). Marktvolumen von Cloud Computing
(B2B) in Deutschland nach Segment von 2011 bis
2015 und Prognose f
¨
ur 2016 (in Millionen Euro).
Goldwasser, S. and Bellare, M. (2008). Lecture notes
on cryptography. Summer course Cryptography and
computer security at MIT, 1999:1999.
Heider, J. and L
¨
assig, J. (2017). Convergent infrastructures
for municipalities as connecting platform for climate
applications. In Advances and New Trends in Environ-
mental Informatics, pages 311–320. Springer.
Johnston, A. M. and Gemmell, P. S. (2002). Authenticated
key exchange provably secure against the man-in-the-
middle attack. Journal of cryptology, 15(2):139–148.
Manu, A., Patel, J. K., Akhtar, S., Agrawal, V., and
Murthy, K. B. S. (2016). Docker container security via
heuristics-based multilateral security-conceptual and
pragmatic study. In Circuit, Power and Computing
Technologies (ICCPCT), 2016 International Confer-
ence on, pages 1–14. IEEE.
Newman, S. (2015). Microservices: Konzeption und De-
sign. mitp.
Shabtey, L. (2010). US Patent No. 7,739,398 B1: Dynamic
Load Balancer.
Sun, Y., Nanda, S., and Jaeger, T. (2015). Security-as-
a-service for microservices-based cloud applications.
In Cloud Computing Technology and Science (Cloud-
Com), 2015 IEEE 7th International Conference on,
pages 50–57. IEEE.
Toffetti, G., Brunner, S., Bl
¨
ochlinger, M., Dudouet, F.,
and Edmonds, A. (2015). An architecture for self-
managing microservices. In Proceedings of the 1st
International Workshop on Automated Incident Man-
agement in Cloud, pages 19–24. ACM.
Ullrich, M. and L
¨
assig, J. (2013). Current challenges
and approaches for resource demand estimation in
the cloud. In IEEE International Conference on
Cloud Computing and Big Data (IEEE CloudCom-
Asia 2013), Fuzhou, China.
Highly Scalable Microservice-based Enterprise Architecture for Smart Ecosystems in Hybrid Cloud Environments
459
