
Automatic Summary System for Patients Hematological
Examination Result in Textual Representation Form
Opim Salim Sitompul
1
, Erna Budhiarti Nababan
1
, Dedy Arisandi
1
and Indra Aulia
1
1
Department of Information Technology, Universitas Sumatera Utara, Jl. Universitas No. 9A, Medan, Indonesia fopim,
Keywords: Natural Language Generation, Narrative Science, Textual Representation, Hematological Examination,
Summary Text.
Abstract: Results of hematological examination from a laboratory are presented in the form of medical abbreviations
and numbers alongside their units, which are represented in tabular form. The result of laboratory examination
is not provided with explanation text on whether the blood components of the hematologic examination results
are normal, abnormal or critical. In order to analyze the blood components of a hematological examination, a
physician should manually compare each blood component value with the known normal range of values
available. In this research Natural Language Generation (NLG) with a template-based method is employed to
interpret the results of the patient’s hematology laboratory examination. The result of interpretation is written
into a summary text in Bahasa Indonesia. Evaluation of the naturalness of the summary text obtained from
the system performed by general practitioners and young doctors reported higher percentage interval of 93.1%
to 97.5%.
1 INTRODUCTION
Results of hematological examinations obtained from
a laboratory are given in medical terms and
abbreviations. Those results are in the form of
numbers alongside their units (e.g. MCV: 70.4 fL;
MCH: 24.3 pg) represented in tabular form with no
explanation on whether the blood components of the
hematological examination results are within normal,
abnormal or critical values. To find out a normal,
abnormal or critical blood component, a physician
should manually compare each blood component of
the hematological examination with a normal range
of values available, one after another individually.
This manual procedure will consume much time not
to mention it is an error-prone task.
Research works that focus on developing a
system to interpret data (such as numeric data) into
informa-tion in the form of textual representations
(such as re-ports or summary text) had been
performed by many researchers. Reiter and Dale
(2000) developed a system of textual representation
to make data (numbers) easy to read and
understandable by non-expert users or users who
have no time in reading the whole data.
Eugenio et al. (2014) used Natural Language
Generation (NLG) or narrative science approach
whereby they examined the making of a system that
can generate a summary text from a brief record of
data written by a physician and a nurse’s structural
documentation (patient care plan) for a patient with a
heart condition who has undergone hospitalization.
Generating this summary text is useful for helping
patients to take care of themselves after their
hospitalization and as an approach to educate patients
about what treatments are being performed to
patients during the in-patient process. The
preparation of the summary text begins with a
process of building a graph to see the relationship
between two input data (short note data written by the
doctor and nurse structural documentation data).
Then selected information extracted from the graph
obtained was written into the summary text. The last
process undertaken was the application of
SimpleNLG system.
In addition, research work by Archarya et al.
(2016) generated a summary text of hospital patient
by linking two heterogeneous sources of doctors and
nurses documentation, while considering the
complexities of medical terms. The summary text
generated was still based on inpatient medical data
1924
Sitompul, O., Nababan, E., Arisandi, D. and Aulia, I.
Automatic Summary System for Patients Hematological Examination Result in Textual Representation Form.
DOI: 10.5220/0010093719241928
In Proceedings of the International Conference of Science, Technology, Engineering, Environmental and Ramification Researches (ICOSTEERR 2018) - Research in Industry 4.0, pages
1924-1928
ISBN: 978-989-758-449-7
Copyright
c
2020 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
and did not cover laboratory examination data (e.g.
hematol-ogy).
The aim of this research is to develop a system
that could help interpreting data resulted from
laboratory examination on hematology patient and
putting the interpretation into a summary text that
would provide information whether the blood
components are in normal condition or the values
obtained indicate ab-normal or critical condition. In
this research, we used Natural Language Generation
approach to report the results of patients
hematological examination in the form of summary
text using template-based methods.
2 NLG FOR TEXTUAL
REPRESENTATION OF
HEMATOLOGY
EXAMINATION RESULT
Natural language generation is the natural language
processing task of generating natural language from a
machine representation system such as a knowledge
base or a logical form. It is like a translator that
converts data into a natural language representation.
NLG is one of the areas of research that deals with the
automation of producing human-readable text suit-
able for certain applications (Biran, 2016). Exam-ple
of NLG applications that commonly applied is in
medical field to improve service and patients safety
for hospital pre-treatment (Schneider et al., 2013).
2.1 Haematology Laboratory
Examination
The results of laboratory tests can be expressed in
three forms of numbers: quantitative numbers (e.g.
normal haemoglobin values of women are 12 - 16 g
/ dl), qualitative (results expressed as positive or neg-
ative values without mentioning positive or negative)
and semiquantitative (qualitative results which men-
tion the positive or negative degree without
specifying the exact number of examples: 1+, 2+,
etc.).
Hematologic examination (hemogram) con-sists
of examination of leukocytes, erythrocytes,
haemoglobin, hematocrit, erythrocytes and platelets.
Complete blood count checks consist of hemogram
along with differential leukocyte checks consisting of
neutrophils, basophils, eosinophils, lymphocytes and
monocytes (Herawati & Andrajati, 2011).
Interpretation guidelines of the clinical data pub-
lished by the Ministry of Health, Indonesia (Herawati
& Andrajati, 2011) showing the normal
hematological range of values based on sex is shown
in Table 1, which describe: Hematocrit (Hct) shows
the percentage of red blood cells to total blood
volume.
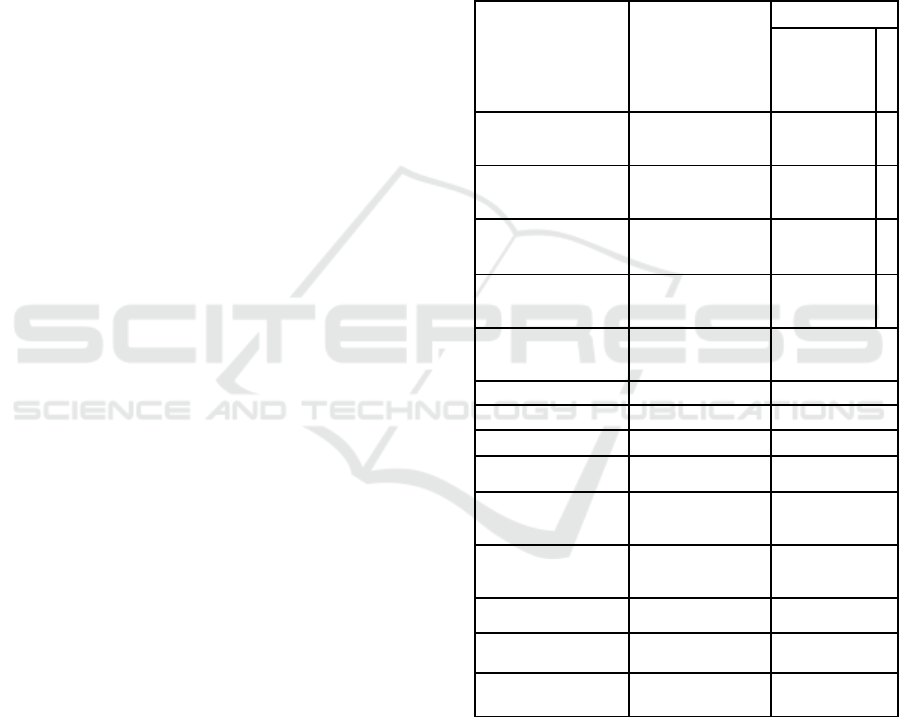
Table 1: The Full Range of Normal Hematological
Values.
(Source: Herawati and Andrajati (2011)
Examination
Unit
Sex
Male
e
m
al
e
Hematrokit
(
Hct
)
%
40-50
5-
45
Haemoglobin
(
Hb
)
g
/dL
13-18
2-
16
Eritrosit
(
RBC
)
10
12
/L
4.4-5.6
.8-
5
Blood Sediment
Rate
(
LED
)
mm/1 hour
<15 20
MCV fL 80-
0
0
MCH
P
g
28-34
MCHC
g
/dL
32-36
Leukosi
t
10
9
/L
3.2-10
Neotro
fil
(
Se
g
ment
)
%
36-73
Eosinofil
%
-
6
Basofil
%
-
2
Limfosit
%
15-45
Monosit
%
0-10
Trombosit
10
9
/L
170-380
Haemoglobin (Hb) is a component of blood that
serves as a means of transport of oxygen (O
2
) and
carbon dioxide (CO
2
).
Red blood cells or Erythrocytes have a primary
function that is to transport oxygen from lungs to the
body tissues and transport CO
2
from body tis-sues to
the lungs by Hb.
Automatic Summary System for Patients Hematological Examination Result in Textual Representation Form
1925

Blood Sediment Rate (LED) is a measure of
erythrocyte sedimentary velocity describing plasma
composition as well as erythrocyte and plasma
comparisons. LEDs are affected by the weight of
blood cells and cell surface area and the earth’s
gravity.
Platelets are the smallest element in the blood
vessels. Platelets are activated after contact with the
surface of the endothelial wall.
3 PREVIOUS RESEARCH
Eugenio et al. (2014) performed a research on the
creation of a system that could produce summary text
from physician doctors’ briefed notes and nurse
structural documentation (containing patient care
plans) for patients with inpatient heart disease. This
summary text is useful for helping patients to take
care of themselves after their hospitalization and as
an ap-proach to educate patients about what
treatments are being performed to patients during the
inpatient process.
Archarya et al. (2016) create a system for gener
ating summary text of patient hospital data by com-
bining information from two heterogeneous sources of
doctors and nurses documentation. Their study fo-
cuses on producing summary text taking into consid-
eration the complexities of medical terms. The first
step is to extract written content of the medical docu-
ment from the mix of both sources, and then the con-
tent is identified to determine if there are any terms
that belong to simple (unexplainable) terms or com-
plex (terms that need explanation) using metrics cre-
ated.
Another research by Mahamood and Reiter
(2011) focused on the effective approach of creating
a system that generates a text of medical information
reports for parents of premature babies. They analyze
the signal and interpret EMR data to identify the
important events and the relationship between the
events occur-ring in the EMR data. Then use the
NLG method to convert the EMR data into a
narrative text. Their research focused on the text
produced by the system that could be understood by
people who are not professionals in the medical field
and the resulting report text only gives positive
information about infant development.
The difference of this research with the previous
research works is that in this study we implement
Natural Language Generation to interpret the results
of hematological examination of patients into the
form of summary text using Template Generation
System (TGen-System). TGen System generates the
template candidates (i.e sentences with related slots)
automatically which has been classified by
considering the content sentences.
4 METHODOLOGY
In this research we implement NLG template-based
to interpret the data of Complete Blood Count (CBC)
into the Indonesian textual representation. The sys-
tem, called Complete Blood Count Interpreter System
(CBCI-System), employs Natural Language Genera-
tion (NLG) concept in generating Indonesian textual
representation. The textual representation is deployed
by filling related data into the appropriate template
slots. Furthermore to handle the limitation of
traditional template-based approach in term of text
diversity and maintainability, we propose Template
Generation System (TGen System). TGen System
generates template candidates that has been classified
based on content of the sentences. This system helps
CBCI System to produce the textual report of CBC
result which is not only varied but also easier to
understand. The proposed architecture of TGen
System is presented in Figure 1.
As shown in Figure 1, TGen System generates the
list of sentence templates based on the related corpus
(i.e. corpus existing text interpretation of CBC)
through Text Segmentation, Slot Generation, Simi lar
Template Removing, and Template Classification.
During the process of TGen system, it requires
linguistics knowledge, which is obtained from the
hematology experts.
Since the related corpus is the textual report
examples of CBC result, the first process of TGen
System is Text Segmentation. Conceptually, Text
Segmentation works on the sentence level, then it is
used to split every sentence contained in corpus based
on the newline and end of character. After sentences
are segmented by Text Segmentation, the system will
decide words or phrases, which are the related slot
candidates. The output of Slot Generation can be
called as the template candidates. Since Slot
Generation may generate the same templates, Similar
template Removing is responsible to collect one
template called as unique sentence template.
Furthermore unique sentence template is classified
into three content sentences (such as the opening
sentence, general description sentence, and detail
description sentence) by using linguistics knowledge.
Finally, Output of Template Classification will be
template in the interpretation of generated CBC result.
ICOSTEERR 2018 - International Conference of Science, Technology, Engineering, Environmental and Ramification Researches
1926
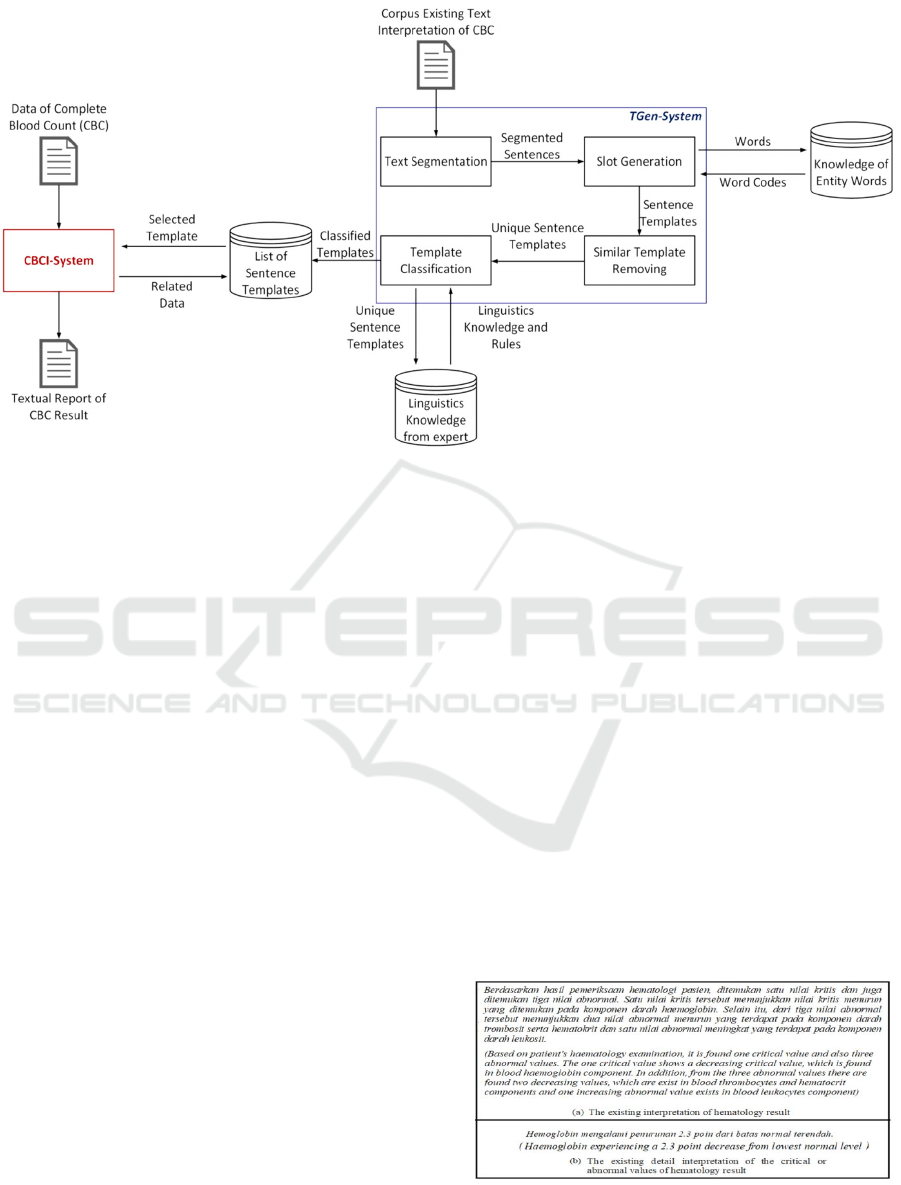
Figure 1: Architecture of the proposed method.
5 RESULT AND DISCUSSION
Data used as an input to T-Gen system is the corpus
of existing interpretation of hematology results (see
for example Figure 2a) and corpus examination of the
details critical or abnormal values of hematologic ex-
amination results as seen in Figure 2b. In the cor-pus
of the results of hematology examination there are 20
examples of text description consisting of 10
examples of description text which have 3 sentences
in each paragraph and 10 examples of description text
which have 2 sentences in each paragraph totaling in
50 sentences. In addition, within the corpus there are
20 detail example sentences about the critical or ab-
normal values of the hematologic examination result
to be analyzed.
After the corpus of the result of hematology and
corpus of the details of the critical or abnormal value
of the hematology examination results are analyzed
by a series TGen system process, a set of sentence
template is obtained. The number of sentence
templates obtained from the T-Gen system analysis
consists of 10 double-opening sentence templates, 10
sin-gle opening sentence templates, 4 multiple
description sentence templates, 7 single expression
sentence templates, and 5 detail sentence templates.
The Example of sentence template result from TGen
system analysis can be seen in Figure 3.
TGen-System can support the CBCI System per
formance in generating the interpretation of CBC
Result in the medical report. One example of the
CBC result from a medical report is shown in Figure
4. Meanwhile, text diversity and maintainability of
template can be achieved by TGen-System.
Finally, an evaluation of the system was
performed using questionnaires through the appraisal
conducted by young doctors as the primary user of
the summary text produced by the system and then
assessment were performed by general practitioners
as a measure of the accuracy of the summary text
generated. Three aspects are considered in this
evaluation: readability (understandable), clarity and
general apropriateness (Belz & Reiter, 2006), (Aulia,
2015).
The result shown that the system has 96.5%
readability, 97.0% in clarity and 98.9% in general
appropri-ateness.
Figure 2: Example of corpus.
Automatic Summary System for Patients Hematological Examination Result in Textual Representation Form
1927
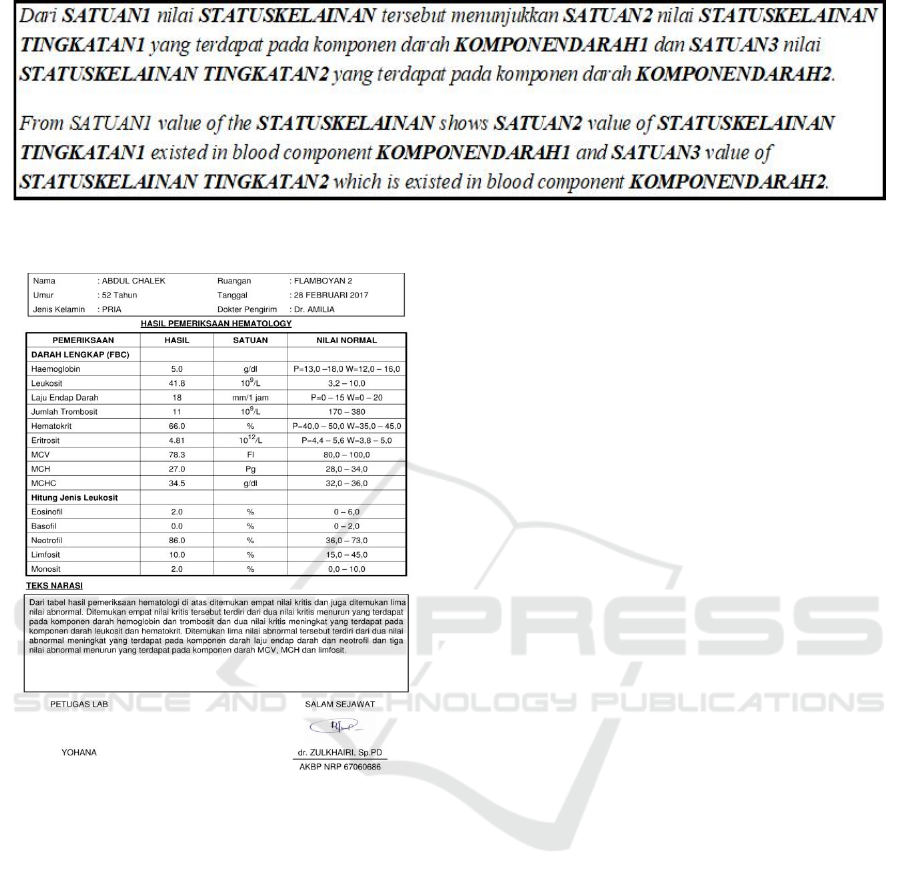
Figure 3: Example of sentence template generated by T-Gen system.
Figure 4: Summary of the patient’s hematology laboratory
examination in Bahasa Indonesia.
6 CONCLUSIONS
Based on our experiment, this paper concluded that
the proposed system (TGen-System) is able to
generate the template candidates automatically by
utilizing the linguistic knowledge of related expert.
This condition proved that the limitation of traditional
template-based approach can be minimized, so that
the hematologic report is not only varied but also
easier to understand. This paper plans to further
improve the reliability of TGen-System in term of
determining slots in the complex sentence.
ACKNOWLEDGEMENTS
We gratefully acknowledge that this research is
funded by Kemenristekdikti Republik Indonesia
through Lembaga Penelitian Universitas Sumatera
Utara. The support is under the research grant DRPM
Kemenristekdikti of Year 2018 Contract Number:
253/UN5.2.3.1/PPM/KP-DRPM/2018.
REFERENCES
Archarya, S., Eugenio, B., Boyd, A., Lopez, K.,
Cameron, R., & Keenan, G. (2016). Generat-ing
summaries of hospitalizations: A new met-ric to assess
the complexity of medical terms and their definitions.
In The 9th international natural language generation
conference (p. 26 - 30).
Aulia, I. (2015). Automatic chart interpreter sys-tem for
generating health surveillance sum-maries based on
indonesian language. Ban-dung: Telkom University.
Belz, A., & Reiter, E. (2006). Comparing automatic and
human evaluation of nlg systems. In Eacl.
Biran, O. (2016). Data-driven solutions to bottle-necks in
natural language generation. Univer-sity of Columbia,
New York: Dissertation.
Eugenio, B., Boyd, A., Lugaresi, C., Balasubrama-nian, A.,
Keenan, G., Burton, M., . . . Lussier,
Y. (2014). Patientnarr: Towards generating patient-centric
summaries of hospital stays. In The 8th international
natural language genera-tion conference (p. 6 - 10).
Herawati, F., & Andrajati, R. (2011). Pedoman inter-pretasi
data klinik (in bahasa). Jakarta: Min-istry of Health
Republic of Indonesia.
Mahamood, S., & Reiter, E. (2011). Generating af-fective
natural language for parents of neonatal infants. In The
13th european workshop on nat-ural language
generation (enlg) (p. 12 - 21).
Reiter, E., & Dale, R. (2000). Building natural lan-guage
generation system. Cambridge: Cam-bridge University
Press.
Schneider, A., Vaudry, P., Mort, A., Mellish, C., Re-iter, E.,
& Wilson, P. (2013). Mime - nlg in pre-hospital care.
In The 14th european natural language generation
workshop (enlg) (p. 152 - 156).
ICOSTEERR 2018 - International Conference of Science, Technology, Engineering, Environmental and Ramification Researches
1928
