
Building Robust Industrial Applicable Object Detection Models using
Transfer Learning and Single Pass Deep Learning Architectures
Steven Puttemans, Timothy Callemein and Toon Goedem
´
e
KU Leuven, EAVISE Research Group, Jan Pieter De Nayerlaan 5, Sint-Katelijne-Waver, Belgium
Keywords:
Deep Learning, Object Detection, Industrial Specific Solutions.
Abstract:
The uprising trend of deep learning in computer vision and artificial intelligence can simply not be ignored.
On the most diverse tasks, from recognition and detection to segmentation, deep learning is able to obtain
state-of-the-art results, reaching top notch performance. In this paper we explore how deep convolutional
neural networks dedicated to the task of object detection can improve our industrial-oriented object detection
pipelines, using state-of-the-art open source deep learning frameworks, like Darknet. By using a deep learning
architecture that integrates region proposals, classification and probability estimation in a single run, we aim
at obtaining real-time performance. We focus on reducing the needed amount of training data drastically by
exploring transfer learning, while still maintaining a high average precision. Furthermore we apply these al-
gorithms to two industrially relevant applications, one being the detection of promotion boards in eye tracking
data and the other detecting and recognizing packages of warehouse products for augmented advertisements.
1 INTRODUCTION
Several drawbacks have kept deep learning in the
background for quite the while. Until recently deep
learning had a very high computational cost, due to
the thousands of convolutions that had to process the
input data from a pixel level to a more content-based
level. On high-end systems, reporting processing
speeds of several seconds on VGA resolution has long
been the state-of-the-art. This limited the use of these
powerful deep learning architectures in industrial situ-
ations such as real-time applications and on platforms
with limited resources. Furthermore deep learning
needed a dedicated and expensive general purpose
graphical processing unit (GPGPU) and an enormous
set of manually annotated training data, both things
that are almost never available in industrially rele-
vant applications. The available frameworks for deep
learning lacked proper documentation and guidelines,
while pre-built deep learning models were not easily
adaptable to new and unseen classes.
These issues no longer exist, and deep learning
made a major shift towards usability and real-time
performance. With the rise of affordable hardware,
large public datasets (e.g. ImageNet (Deng et al.,
2009)), pre-built models (e.g. Caffe model zoo (Jia
et al., 2014)) and techniques like transfer learning,
deep learning took a step closer towards actual indus-
trial applications. Together with the explosion of sta-
ble and well documented open-source deep learning
frameworks (e.g. Caffe (Jia et al., 2014), Tensorflow
(Abadi et al., 2016), Darknet (Redmon, 2016)), deep
learning opened up a world of possibilities.
Many industrially relevant applications do not fo-
cus on existing classes from academically provided
datasets. Gathering tremendous amounts of train-
ing data and providing manual labelling, is a time-
consuming and thus expensive process. Luckily trans-
fer learning (Bengio, 2012) provides possibilities in
this case. Given a limited set of manually annotated
training samples, it retrains existing off-the-shelf deep
learning models and adapts the existing weights so
that the model can detect a complete new object class.
Figure 1: Examples of both applications: (left) promotion
boards and (right) product packs detectors.
Puttemans, S., Callemein, T. and Goedemé, T.
Building Robust Industrial Applicable Object Detection Models using Transfer Learning and Single Pass Deep Learning Architectures.
DOI: 10.5220/0006562002090217
In Proceedings of the 13th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2018), pages 209-217
ISBN: 978-989-758-306-3
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
209

We apply transfer learning in two applications,
while focussing on using a small set of training data
for the new classes (to prove we do not need huge
datasets for this task) and simultaneously ensuring
real-time performance. The first industrial relevant
application handles the detection of promotion boards
in eye-tracking data, allowing companies to analyse
shopping behaviour, as seen in Figure 1(left). The
second application handles the detection and recogni-
tion of warehouse products for augmented advertise-
ment purposes (as seen in Figure 1(right)). Specifi-
cally we look at a generic product box detector, fol-
lowed by a multi-class 14-brand-specific detector.
The remainder of this paper is organized as fol-
lows. In section 2 we discuss related work and high-
light the state-of-the-art in deep object detection. Sec-
tion 3 discusses the collected dataset for training and
validating the object detection models. This is fol-
lowed by section 4 discussing the selected deep learn-
ing framework and model architecture, used for trans-
fer learning. Section 5 handles each application case
in detail. In section 6 we discuss the obtained average
precisions and execution speeds. Finally we conclude
this paper in section 7 and provide some future work
in section 7.4.
2 RELATED WORK
Since convolutional neural networks process image
patches, doing a multi-scale and sliding-window
based analysis takes a lot of time, especially if im-
age dimensions increase. Combined with the fact that
deeper networks achieve a better detection accuracy,
deep networks like DenseNet201 and InceptionV3 can
easily take a couple of seconds for VGA resolution.
To increase execution speed, academia introduced the
concept of region proposal techniques. These are fast
lightweight filters that pre-process images, looking
for regions that might contain objects we are looking
for. Instead of supplying the classification pipeline
with millions of candidate windows, the region pro-
posal algorithms reduce this to several thousands of
windows, clearly reducing processing time.
Region proposing convolutional neural networks
(R-CNN) (Ren et al., 2015) use a separate shallow re-
gion proposal network on the GPU that uses mutual
information (some convolutional layers are shared)
of the actual detection pipeline to avoid unnecessary
overhead. This enabled to run deep deep models like
VGG19 at 10FPS for VGA resolution, giving a 30x
speed improvement towards the original implementa-
tion. The ‘Single Shot Multibox’-detector (SSD) (Liu
et al., 2016) introduces an algorithm for detecting ob-
jects in image using only a single deep neural net-
work, immediately grouping the convolutional output
activations and returning object boxes. The ‘You Only
Look Once’-detector (YOLO) (Redmon et al., 2016)
implements a similar approach, using anchor points
that allow learned aspect ratios around pixel areas that
have a high response. Both detectors remove the need
of extra region proposal networks and perform bound-
ing box prediction and class probability generation in
a single run through the network.
If your industrial application concerns a class that
is previously trained on any given public dataset (e.g.
pedestrians, cars, bicyclists), these algorithms pro-
vide off-the-shelf pre-trained detection models. How-
ever, when your object class does not occur in any
of the pre-trained networks, one needs a huge dataset
and a lot of processing time to come up with a new
deep learned model. That is why (Yosinski et al.,
2014) investigated the transferability of deep learn-
ing features and discovered that the first convolutional
layers of any deep learning architecture actually stick
to very general feature representations, and that the
actual power resides in the linking of those features
by finding the correct convolutional weights for each
operator. This allowed applying the concept of trans-
fer learning (Dauphin et al., 2012) onto deep learn-
ing. By initializing the weights of the convolutional
layers that provide a general feature description, us-
ing the weights of any pre-trained model, and by us-
ing a small number of annotated application-specific
training samples to update the weights of all layers
for the new object class, one can learn a complete new
model. Combined with data augmentation (Gan et al.,
2015), a small set of these training samples can in-
troduce enough knowledge for fine-tuning an existing
deep model onto this new class.
3 DATASET AND FRAMEWORK
For this paper we created two datasets used for train-
ing and evaluating our deep learned object detection
models. In both cases we provided manual annota-
tions, allowing for a precision-recall based evaluation.
The first dataset exists of several videos of an eye-
tracker experiment in a Belgian warehouse. Data is
collected by costumers, approached at the entrance
and asked to go shopping wearing an eye-tracker,
without explaining them the goal of the experiment.
Two classes of promotion boards (small sign and
large sign) are manually annotated in each frame of
the eye-tracker videos. As training data we use re-
spectively 75 and 65 frames containing the promo-
tion boards. As validation data, we use 420 and 960
VISAPP 2018 - International Conference on Computer Vision Theory and Applications
210

Table 1: Number of product box samples per brand.
Label Training Validation
brandA v1 63 163
brandA v2 14 149
brandA v3 29 157
brandA v4 14 167
brandB v1 75 157
brandB v2 15 222
brandC v1 15 185
brandC v2 15 188
brandC v3 15 229
brandD v1 46 183
brandD v2 30 146
brandD v3 15 179
brandE v1 15 178
brandE v2 15 179
TOTAL: 376 4279
frames respectively, containing both frames with and
without the actual promotion boards.
The second industrial relevant dataset contains
376 images of product packages. In each image the
location of the package is manually annotated using a
rectangular bounding box. In total 14 brands are in-
cluded, allowing us to both provide labels of a prod-
uct box and the associated brand, useful for training
multi-class object detection models. A separate val-
idation set is collected, existing of twentysix fifteen-
second videos (@30FPS), containing different views
of similar product boxes. Table 1 contains a detailed
overview of the specific amounts of training and vali-
dation samples per brand.
As framework we decide to use Darknet (Redmon,
2016), a lightweight deep learning library, based on
C and CUDA, which reports state-of-the-art perfor-
mance for object detection using the YOLOv2 archi-
tecture. Moreover, it reaches inference speeds up to
120 FPS and integrates well with our existing C++
based software platform (using OpenCV3.2 (Bradski
et al., 2000)). The framework does not require ex-
plicit negative training samples but rather uses areas
in the image that are not labelled as object. We build
our customized version of the framework, which is
publicly available
1
and allows integrated evaluation
of trained models using the precision-recall metric.
4 SUGGESTED APPROACH
In order to converge to an optimal configuration, deep
learned models need large amounts of annotated train-
1
https://gitlab.com/EAVISE/darknet
ing data and a lot of processing time. For the sug-
gested YOLOv2 architecture, this is also the case.
The default network configuration uses 800.000 float-
ing point operations per given image. To optimize
the weights assigned to each operation, one literally
needs multiple thousands of training samples. For in-
dustrial applications this is not manageable, certainly
if for each new object detection model, you need new
and annotated training data. Transfer learning bridges
the gap here. For our detection models we start from
a YOLOv2 architecture previously trained on the Pas-
cal VOC 2007 dataset with pre-trained weights. To be
able to apply transfer learning onto a new object class
several adaptations have to be made to the network.
1. We physically change the architecture of the net-
work at the level of the class predictions and class
probabilities. To ensure the convolutional layers
output the correct format for the detection layer,
we change the total number of filters in the fi-
nal convolutional layer to (N
classes
+5)×N
anchors
.
This allows the detection layer to convert the final
layer activations into useful detections.
2. We adapt the amount of anchor ratios to our class
specific problem. This ensures that in the detec-
tion layer, prediction boxes are generated fitted in
a ratio that agrees to our actual fine-tuning data
from our new object class.
3. We initialize the weights of all convolutional lay-
ers except the last one and leave the weights of the
final convolutional layer and the detection layer
uninitialized. This allows us to learn class specific
weights for these deciding layers.
Keeping these changes in mind, we transfer learn
a new object model for our new object class. We al-
low all weights to update (including the pre-assigned
weights) and thus to converge towards the optimal so-
lution given our new training data. We also use data
augmentation to ensure we enrich the small applica-
tion specific annotated training set.
In our experience the detection model generally
fine-tunes over multiple thousands of iterations, pro-
viding a batch of 64 samples at each iteration to the
model for updating the weights and reducing the loss
rate on those given samples. If our model trains for
10.000 iterations, the model needs more than 640.000
training samples. Given we only have around 400 an-
notated training samples available this would mean
that each sample is shown over a thousand times to
the network, risking to overfit the model to the train-
ing data. Data augmentation applies specific transfor-
mations to the image to generate a large set of data
from a small set of training samples, effectively re-
ducing the number of times a single sample is shown
Building Robust Industrial Applicable Object Detection Models using Transfer Learning and Single Pass Deep Learning Architectures
211

to the network and thus avoiding overfitting.
During our training we allow the following aug-
mentations on our limited set of manually annotated
training data:
• Randomly rescaling (max.±30%) of the input size
of the first convolutional layer, making the detec-
tor more robust for multi-scale detections.
• For each training sample, the algorithm randomly
decides to flip around the vertical axis.
• Input images are converted to HSV and a maxi-
mally ±10% deviation on the hue value is applied.
• The average saturation and exposure of the input
image can deviate 50% from the input value.
• We allow the annotations of the training samples
to jitter for 20% in relation to the original size,
but the cropped or moved annotation still has to
contain 80% of the original annotation area.
In general we notice that any object model we
train is able to converge towards a stable model
overnight, maximally taking a full 24 hours, on a Ti-
tan X (Pascal) and with a default architecture input
resolution of 416 × 416 pixels. We halt the training
when the loss rate on the provided training samples
seems to drop under 0.5, what for our applications al-
ways produces a robust detection model. Continuing
the training from that point, lets say for example up to
50.000 iterations, only introduces training data over-
fitting and thus a model that loses its generalization
properties on an unseen validation set.
5 PRACTICAL CASES
Before we move on to qualitative and quantitative
evaluation of our object models in section 6, we first
elaborate on how we built object detection models for
our specific industrially relevant applications.
5.1 Promotion Boards
For our promotion boards, we look into deep learning
with two specific reasons:
1. We want to analyse complete eye-tracker experi-
ments by linking object detections to eye-tracker
data, removing the need for manual analysis.
2. We want to reduce the amount of annotations as
much as possible without losing too much average
precision on the obtained object detectors.
We build two separate object detection models for
this application. First we build a single-class de-
tection model, able to detect the small red promo-
tion board as seen in Figure 2(left). However, since
Figure 2: Two promotion board classes (left) small sign
(right) large sign.
the same shop also contains a second board of in-
terest, seen as the large red promotion board in Fig-
ure 2(right), we explore the possibilities of building
a two-class detector, able to detect and classify both
signs at the same time and in a single run.
5.2 Warehouse Product Packages
Our second application is the robust detection and
classification of warehouse product packages for aug-
mented advertisements. In this application it is first
of all our task to robustly locate the packages in any
given input image. Furthermore we want to classify
each product box in the same, single run of our deep
learning classifier, and return its brand.
The packages all have general product box prop-
erties, while the print on the box distinguishes the
brand. Therefore we start building a robust product
package detector, able of localizing packages with
a very high average precision in newly provided in-
put images. This can easily be followed by a small
classification network deciding which brand we have.
However, doing this in a single run per image is our
ultimate goal Once we succeed in building a robust
product pack detector, we try pushing our luck , so
we generate a 14-class brand detector, which is able
to both localize and classify the product packs in a
single run, completely removing the need of a sepa-
rate classification pipeline.
6 EXPERIMENTS AND RESULTS
This section discusses in more detail the achieved re-
sults with each trained object detector. Furthermore it
highlights some of the issues we have when training
these object detection models and discusses some of
the limits of using the YOLOv2 architecture. Since
VISAPP 2018 - International Conference on Computer Vision Theory and Applications
212
0.5 1 1.5 2 2.5 3
# Iterations
10
4
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
Training loss
Loss rate
Averaged loss rate
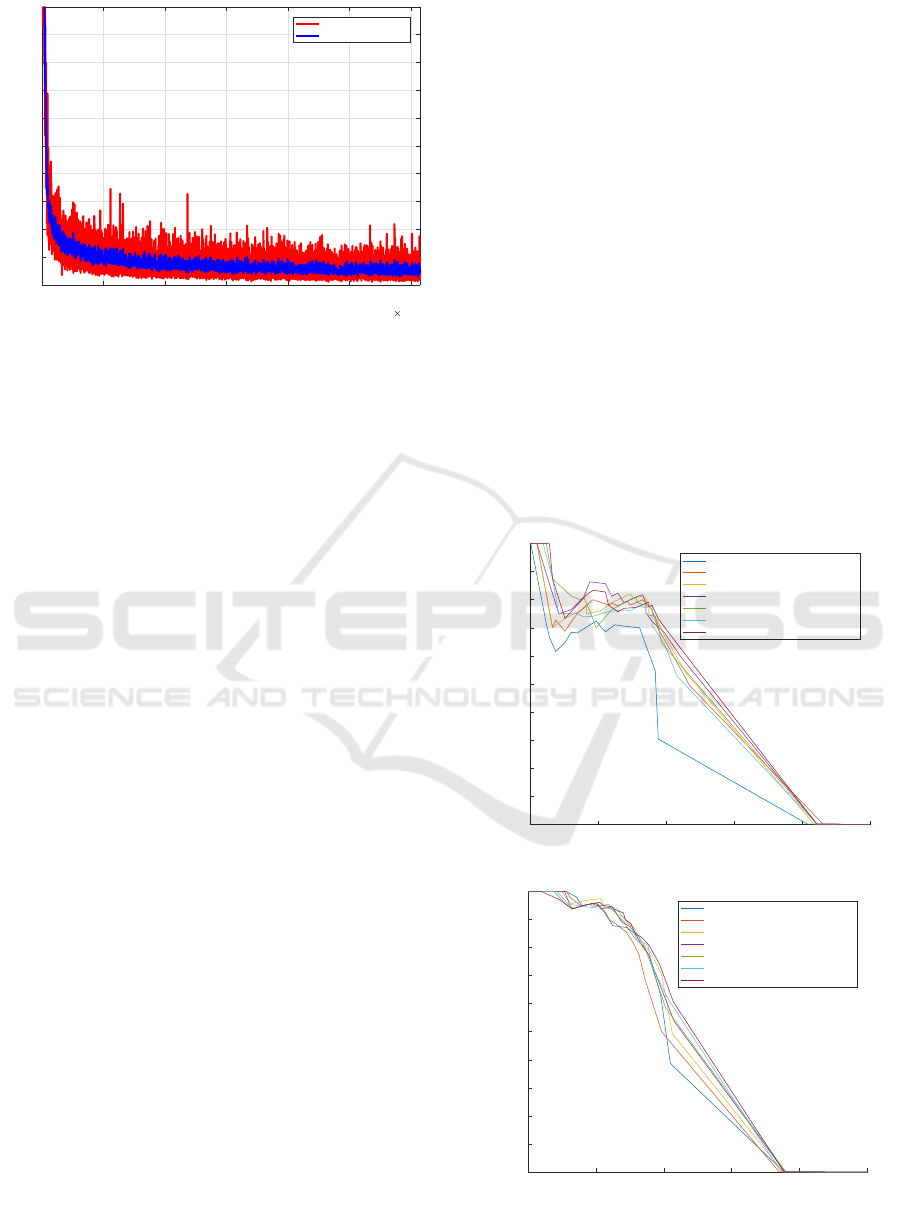
Figure 3: An example loss rate and average loss rate curve
for single class advertisement board detector, in function of
the iterations (with 64 sample batch per iteration).
all our models are fine-tuned from the same YOLOv2
architecture, we have an equal storage size of 270MB,
while the GPU memory footprint of the same model
equals 450MB.
6.1 Stop the Model Transfer-learning
We need a way of defining when our training algo-
rithm reaches an optimal solution. At the same time
we need to avoid overfitting the model to the train-
ing data, keeping a model that generalizes well to
never seen before data. In order to check the training
progress we continuously monitor the loss-rate on the
given training data. This is monitored for every new
batch of samples provided to the training algorithm,
together with the average loss-rate over all batches.
Once the average loss-rate no longer drops, we halt
the training process.
An example of the loss rate tracking for one of our
transfer-learned models can be seen in Figure 3. In
general we notice that a loss rate just below 0.5 seems
optimal for any model, which is transfer-learned from
the given YOLOv2 pre-trained architecture.
6.2 Evaluate the Promotion Detectors
Figure 4(top) and 4(bottom) shows the precision-
recall curves for the trained promotion board models.
For both models we run the training overnight halting
the training at 30.000 iterations. We evaluate the pre-
cision, recall and average precision performance of
each detection model at 1.000, 5.000, 10.000, 15.000,
20.000, 25.000 and 30.000 training iterations.
Initially we see an increase in average precision
when raising the number of iterations for each model.
However, once the average precision (calculated on
the validation set) starts dropping, we select the pre-
vious model as best fit, in order to keep the model
that generalizes best on the given validation set. For
the single-class detector this means a model of 15.000
iterations at an average precision of 59.98% while for
the two-class detector the 30.000 iterations model at
an average precision of 59% performs best. Look-
ing at these curves it seems that the two-class model
might still be converging to an optimal solution and
thus continuing training with more iterations might
be a feasible option.
We reckon our models seem to be under-
performing, seeing their optimal configuration strands
at about 65% precision for a 50% recall. This can be
due to motion blur in the eye-tracker data in the vali-
dation set. The scales of the annotated validation data
also differ from the training data, leading to unlearned
object dimensions. Finally YOLOv2 has problems
with detecting objects that are relatively small in com-
parison to the image dimensions, while this is not an
issue for a human annotator.
However these precision and recall values are ac-
tually more than enough, given the context of the
0 20 40 60 80 100
Recall
0
10
20
30
40
50
60
70
80
90
100
Precision
SClass(1000) / AP = 40.3279%
SClass(5000) / AP = 55.8061%
SClass(10000) / AP = 56.0418%
SClass(15000) / AP = 59.9822%
SClass(20000) / AP = 57.2641%
SClass(25000) / AP = 55.549%
SClass(30000) / AP = 59.5089%
0 20 40 60 80 100
Recall
0
10
20
30
40
50
60
70
80
90
100
Precision
2Class(1000) / AP = 51.0406%
2Class(5000) / AP = 53.0601%
2Class(10000) / AP = 55.1197%
2Class(15000) / AP = 56.4617%
2Class(20000) / AP = 57.9215%
2Class(25000) / AP = 58.5357%
2Class(30000) / AP = 59.0091%
Figure 4: Precision-recall curves for the single class (top)
and the two-class (bottom) object detection model.
Building Robust Industrial Applicable Object Detection Models using Transfer Learning and Single Pass Deep Learning Architectures
213

application. We only need to signal when a cos-
tumer has noticed a promotion board, related to the
gaze-cursor location. If we are not able to find a
promotion board on a smaller scale, once the cos-
tumer walks towards the sign, we are able to ro-
bustly detect it with a high probability. Looking at
the execution speeds of the trained models, we no-
tice that both the single- and two-class models per-
form around 55 FPS for a 1280 × 720 pixel resolu-
tion on a NVIDIA Titan X GPU. A video of the sin-
gle class promotion board detector can be found at
https://youtu.be/dQIdRSDm6Jc.
6.3 Evaluating the Product Package and
Brand Detectors
For our general single-class product box detector, we
perform transfer-learning for 5.000 iterations, while
our fourteen-class brand detector is trained for 15.000
iterations. Both trainings lead to a convergence in
loss-rate, just below the 0.5 threshold, previously in-
dicated as a good stopping point.
Figure 6 gives us an overview of the generated
precision-recall curves for all the transfer-learned
models. At the bottom left part of the figure we
observe the performance on the complete validation
dataset (so all fourteen brands together). Our general
single-class product box detector is able to robustly
detect every single object instance in the large vali-
dation set, obtaining an average precision of 100%.
The 14-class object detection model is as promising,
obtaining an overall average precision of 99.87%, di-
rectly providing the correct brand label in combina-
tion with an accurate localisation.
The small difference in average precision between
both models is caused by brandC
v1, which is unable
to reach a class-specific average precision of 100%.
We discovered four samples of the brandC v1 with a
wrong label, which under data augmentation seems to
have a significant influence. Before adjusting these la-
bels, we obtained a 93.97% average precision for this
class, while afterwards we obtain a 95.66% average
precision.
We compared the performance three different
brandC classes (v1, v2 and v3), as seen in Figure 5,
evaluated on brandC v1 validation data with the goal
of uncovering where it goes wrong. There is still a
large amount of validation data that gets classified as
brandC v2 or brandC v3, and this with a high class
probability, instead of providing the brandC v1 la-
bel. After visually inspecting the brandC class this be-
haviour is kind of expected, and actually the detectors
are performing better than expected, since there are
only very subtle visual changes between these three
Figure 5: Box-plot of the brandC sub-brands probability
scores indicating a significant number of v1 packages trig-
gering v2 and v3 detections with a high probability.
sub-brands. Keeping in mind that our network resizes
the input data to a fixed 416 × 416 resolution this can
lead to the loss of these very small details, resulting
in a deep learning architecture that is even more chal-
lenged in finding an optimal separation between the
sub-brand classes.
Looking at the execution speeds of the trained
models, we notice that both the single-class and the
fourteen-class product package detector are running
at 70 FPS for a 720 × 1280 pixel resolution on an
NVIDIA Titan X GPU.
7 DISCUSSION AND
CONCLUSIONS
In this section we want to discuss some restrictions
of the current YOLOv2 framework, shed a light on
some issues that still arise when using our models and
finally draw some conclusions on our suggested ap-
proach. Finally we suggest ways for further improv-
ing the current pipeline.
7.1 Drawbacks using YOLOv2
Due to chosen internal construction of convolutional
layers and the final detection layer (in which YOLO
smartly combines it probability maps), it is unable to
robustly detect objects that are small compared to the
image dimensions. This happens quite frequently in
our promotion board detection case, resulting in lower
average precisions. Once the object instances cover
more than 20-30% of the image (e.g. the product box
case), this is no longer an issue.
The grid based region proposal system in
YOLOv2 forces neighbouring detections together in
VISAPP 2018 - International Conference on Computer Vision Theory and Applications
214

Figure 6: Precision-recall curves for our product brand case, showing a per (sub-)brand evaluation, a combined evaluation
and a small extra investigation for the brandC v1 sub-brand.
a single detection box, dropping the average preci-
sion. The architecture has a non-maxima suppression
parameter that can be tweaked for this, but initial ex-
periments show this does not resolve all issues.
Finally deep learning separates training data based
on a combination of convolution filters, trying to find
an optimal solutions. However we do not tell it how it
should do its task or which features to ignore, which
sometimes has undesired effects. E.g. in the case
of our generic product box detector, when presented
with a similar rectangular shape (e.g. a box of cere-
als or sugar) the model also triggers a detection. This
behaviour is expected since a product package is first
of all a rectangular box.
7.2 Avoiding Detections on General
Rectangular Shapes
To remove the effect of other rectangular packages
triggering the product package detector, we investi-
gate the detection probability range. Given a set of
product packs and some random packs with other as-
pect ratios, we noticed that there is a large probability
gap between known and unknown packages. Simply
placing a probability threshold of 65% already results
in the removal of all detections of non-known product
packages and brands.
However we are interested in other possible solu-
tions to this problem, that do not include setting a hard
threshold on the probability output, since unseen data
could screw up this approach and trigger detection
probabilities for desired objects that are lower than
the given threshold.
7.2.1 Adding a Non-standard Box Class to the
Multi-class Detector
By adding a class that contains all non-standard boxes
we basically want to force the deep learning network
to learn all product brands, and on top of that an extra
generic box detector. We add extra t. raining data,
collected from 12 household rectangular boxes and
started training again. Figure 7 shows that the initial
iterations show a promising drop in loss rate, how-
ever, at a certain moment we literally experience a
training loss rate explosion, and the model is not able
to recover from this. To be able to recover from this,
a possibility might be to lower the learning rate from
the moment the loss-rate increases again, since the gi-
ant loss-rates clearly show the architecture is on the
wrong track looking for the optimal solution, given
the multi-dimensional error surface.
7.2.2 Adding Hard Negative Training Images
A second attempt is made by adding hard negative
training images, images containing generic unanno-
tated box shapes, without changing the number of
Building Robust Industrial Applicable Object Detection Models using Transfer Learning and Single Pass Deep Learning Architectures
215

1000 2000 3000 4000 5000 6000 7000 8000
# Iterations
0
10
20
30
40
50
60
70
80
90
100
Training loss
Loss rate
Averaged loss rate
Figure 7: Training a brand-specific box detector with a
generic box as extra class, leading to a loss rate explosion.
Figure 8: Example of classes that are unseen and untrained,
yielding clearly lower probabilities allowing for easier sep-
aration based on class probability.
classes to learn. The architecture will force the learn-
ing process to try and make the response of those hard
negative images zero and thus hopefully improve the
ignoring power of the model for generic packages.
This approach works and yields a transfer-learned
model with a low loss-rate. The hard negative data
is not removing the generic box detection properties
from the model, which it still needs for detecting
the actual brands, but when looking at the probabil-
ities for the generic box detections, we clearly notice
a larger gap in probability between object class in-
stances and generic box detections.
Caution should be used here. This only works
when using a limited set of hard negatives samples in
relation to the amount of training samples per class.
Adding too much hard negative samples increases the
risk of generating training sample batches that con-
tain almost no actual object annotations, which forces
to learn the model to detect nothing at all.
Examples of generic packages or packages of un-
trained brands, yielding low probabilities compared to
actual trained brands can be seen in Figure 8. Know-
ing that actual trained classes trigger detections al-
most always above a probability of 85% ensures us
that there is still a margin for defining the most opti-
mal threshold.
7.3 Conclusion
We proved that using deep learning for industrial ob-
ject detection applications is no longer infeasible due
to computational demands and unavailable hardware.
By using an off-the-shelf deep learning framework
and by using transfer learning we succeed in building
several robust object detection models on an afford-
able general purpose GPU.
Our application of promotion board detection
proves that the deep learned object detection pipeline
is valid for industrially relevant cases, using only a
very limited training set and thus minimal manual ef-
fort in labelling, yielding models that achieve moder-
ate average precisions. At the same time we conclude
that not all applications need a model with a 100% av-
erage precision, in order to do its job, like in the case
of automated eye-tracker data analysis.
Finally the application of product package detec-
tion and classification tries to push the limits of deep
learning and model fine-tuning on industrial cases.
By using again very limited datasets (keep in mind
some classes have only 15 labelled image samples)
we achieve a perfect solution for our application,
achieving a 100% average precision when it comes to
generic box detection. Furthermore if we directly in-
corporate the classification in the detection pipeline,
we achieve a remarkable 99.87% average precision.
This perfectly proves that deep object detection could
be a valid solution to several industrial challenges that
are still around nowadays.
7.4 Future Work
First of all we would like to do a deeper study of our
promotion board detection case and how we can im-
prove the moderate average precision rates obtained.
VISAPP 2018 - International Conference on Computer Vision Theory and Applications
216

We can only guess towards the actual reasons, but
we are convinced that one of the issues could well be
the sampling of the actual eye tracker video material,
which contains huge amounts of motion blur, espe-
cially when people tend to move their head fast, for a
quick look down the isle. Better eye-tracker hardware
could be a possible solution here, or replacing the
validation data with only clear eye-tracker data, re-
moving the actual motion blurred evaluation frames.
We also reckon our model will never be able to detect
motion blurred advertisement boards, since we never
used them as actual training data. Adding them to the
actual training data might also improve the general-
ization capabilities of the deep learned model.
A challenge for the package detection and classifi-
cation case exists in expanding the multi-class model.
For now our model still needs an overnight training
step. For most applications this is feasible, but there
are still applications where this is not feasible at all.
We should thus investigate how we can optimally ex-
pand existing models with an extra class, at a minimal
processing cost. This research field is called incre-
mental learning and already has several applicational
fields, like object detection in video sequences, as de-
scribed in (Kuznetsova et al., 2015).
Finally every augmented training sample is ran-
domly flipped around the vertical axis in the Dark-
net data augmentation pipeline. While in most cases
this helps to build robustness inside the detector, there
are cases where this can worsens the actual model.
We therefore suggest training models without these
random flips, and comparing them to our already ob-
tained results, to investigate their actual influence.
ACKNOWLEDGEMENTS
This work is supported by the KU Leuven, Cam-
pus De Nayer and the Flanders Innovation & En-
trepreneurship (AIO).
REFERENCES
Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z.,
Citro, C., Corrado, G. S., Davis, A., Dean, J., Devin,
M., et al. (2016). Tensorflow: Large-scale machine
learning on heterogeneous distributed systems. arXiv
preprint arXiv:1603.04467.
Bengio, Y. (2012). Deep learning of representations for
unsupervised and transfer learning. In Proceedings
of ICML Workshop on Unsupervised and Transfer
Learning, pages 17–36.
Bradski, G. et al. (2000). The opencv library. Doctor Dobbs
Journal, 25(11):120–126.
Dauphin, G. M. Y., Glorot, X., Rifai, S., Bengio, Y., Good-
fellow, I., Lavoie, E., Muller, X., Desjardins, G.,
Warde-Farley, D., Vincent, P., et al. (2012). Unsuper-
vised and transfer learning challenge: a deep learning
approach. In Proceedings of ICML Workshop on Un-
supervised and Transfer Learning, pages 97–110.
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-Fei,
L. (2009). Imagenet: A large-scale hierarchical image
database. In Computer Vision and Pattern Recogni-
tion, 2009. CVPR 2009. IEEE Conference on, pages
248–255. IEEE.
Gan, Z., Henao, R., Carlson, D., and Carin, L. (2015).
Learning deep sigmoid belief networks with data aug-
mentation. In Artificial Intelligence and Statistics,
pages 268–276.
Jia, Y., Shelhamer, E., Donahue, J., Karayev, S., Long, J.,
Girshick, R., Guadarrama, S., and Darrell, T. (2014).
Caffe: Convolutional architecture for fast feature em-
bedding. In Proceedings of the 22nd ACM inter-
national conference on Multimedia, pages 675–678.
ACM.
Kuznetsova, A., Ju Hwang, S., Rosenhahn, B., and Sigal,
L. (2015). Expanding object detector’s horizon: in-
cremental learning framework for object detection in
videos. In Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition, pages 28–
36.
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S.,
Fu, C.-Y., and Berg, A. C. (2016). Ssd: Single shot
multibox detector. In European conference on com-
puter vision, pages 21–37. Springer.
Redmon, J. (2013–2016). Darknet: Open source neural net-
works in c. http://pjreddie.com/darknet/.
Redmon, J., Divvala, S., Girshick, R., and Farhadi, A.
(2016). You only look once: Unified, real-time object
detection. In Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition, pages 779–
788.
Ren, S., He, K., Girshick, R., and Sun, J. (2015). Faster
r-cnn: Towards real-time object detection with region
proposal networks. In Advances in neural information
processing systems, pages 91–99.
Yosinski, J., Clune, J., Bengio, Y., and Lipson, H. (2014).
How transferable are features in deep neural net-
works? In Advances in neural information processing
systems, pages 3320–3328.
Building Robust Industrial Applicable Object Detection Models using Transfer Learning and Single Pass Deep Learning Architectures
217
