
Open Set Logo Detection and Retrieval
Andras T
¨
uzk
¨
o
1
, Christian Herrmann
1,2
, Daniel Manger
1
and J
¨
urgen Beyerer
1,2
1
Fraunhofer IOSB, Karlsruhe, Germany
2
Karlsruhe Institute of Technology KIT, Vision and Fusion Lab, Karlsruhe, Germany
Keywords:
Logo Detection, Logo Retrieval, Logo Dataset, Trademark Retrieval, Open Set Retrieval, Deep Learning.
Abstract:
Current logo retrieval research focuses on closed set scenarios. We argue that the logo domain is too large
for this strategy and requires an open set approach. To foster research in this direction, a large-scale logo
dataset, called Logos in the Wild, is collected and released to the public. A typical open set logo retrieval
application is, for example, assessing the effectiveness of advertisement in sports event broadcasts. Given
a query sample in shape of a logo image, the task is to find all further occurrences of this logo in a set of
images or videos. Currently, common logo retrieval approaches are unsuitable for this task because of their
closed world assumption. Thus, an open set logo retrieval method is proposed in this work which allows
searching for previously unseen logos by a single query sample. A two stage concept with separate logo
detection and comparison is proposed where both modules are based on task specific Convolutional Neural
Networks (CNNs). If trained with the Logos in the Wild data, significant performance improvements are
observed, especially compared with state-of-the-art closed set approaches.
1 INTRODUCTION
Automated search for logos is a desirable task in vi-
sual image analysis. A key application is the effecti-
veness measurement of advertisements. Being able
to find all logos in images that match a query, for
example, a logo of a specific company, allows to as-
sess the visual frequency and prominence of logos in
TV broadcasts. Typically, these broadcasts are sports
events where sponsorship and advertisement is very
common. This requires a flexible system where the
query can be easily defined and switched according
to the current task. Especially, also previously unseen
logos should be found even if only one query sample
is available. This requirement excludes basically all
current logo retrieval approaches because they make
a closed world assumption in which all searched logos
are known beforehand. Instead, this paper focuses on
open set logo retrieval where only one sample image
of a logo is available.
Consequently, a novel processing strategy for logo
retrieval based on a logo detector and a feature extrac-
tor is proposed as illustrated in figure 1. Similar stra-
tegies are known from other open set retrieval tasks,
such as face or person retrieval (B
¨
auml et al., 2010;
Herrmann and Beyerer, 2015). Both, the detector and
the extractor are task specific CNNs. For detection,
Figure 1: Proposed logo retrieval strategy.
the Faster R-CNN framework (Ren et al., 2015) is
employed and the extractor is derived from classifica-
tion networks for the ImageNet challenge (Deng et al.,
2009).
The necessity for open set logo retrieval becomes
obvious when considering the diversity and amount of
existing logos and brands
1
. The METU trademark da-
taset (Tursun et al., 2017) contains, for example, over
half a million different brands. Given this number,
a closed set approach where all different brands are
pre-trained within the retrieval system is clearly inap-
propriate. This is why our proposed feature extractor
generates a discriminative logo descriptor, which ge-
neralizes to unseen logos, instead of a mere classifi-
cation between previously known brands. The well-
known high discriminative capabilities of CNNs al-
low to construct such a feature extractor.
1
The term brand is used in this work as synonym for a
single logo class. Thus, a brand might also refer to a product
or company name if an according logo exists.
284
Tüzkö, A., Herrmann, C., Manger, D. and Beyerer, J.
Open Set Logo Detection and Retrieval.
DOI: 10.5220/0006614602840292
In Proceedings of the 13th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2018) - Volume 5: VISAPP, pages
284-292
ISBN: 978-989-758-290-5
Copyright © 2018 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

One challenge for training a general purpose logo
detector lies in appropriate training data. Many logo
or trademark datasets (Eakins et al., 1998; Hoi et al.,
2015; Tursun et al., 2017) only contain the original
logo graphic but no in-the-wild occurrences of these
logos which are required for the target application.
The need for annotated logo bounding boxes in the
images limits the number of suitable available data-
sets. Existing logo datasets (Joly and Buisson, 2009;
Kalantidis et al., 2011; Romberg et al., 2011; Letes-
sier et al., 2012; Bianco et al., 2015; Su et al., 2016;
Bianco et al., 2017) with available bounding boxes
are often restricted to a very small number of brands
and mostly high quality images. Especially, occlusi-
ons, blur and variations within a logo type are only
partially covered. To address these shortcomings, we
collect the novel Logos in the Wild dataset and make
it publicly available
2
.
The contributions of this work are threefold:
• A novel open set logo detector which can detect
previously unseen logos.
• An open set logo retrieval system which needs
only a single logo image as query.
• The introduction of a novel large-scale in-the-wild
logo dataset.
2 RELATED WORK
Current logo retrieval strategies are generally solving
a closed set detection and classification problem. Eg-
gert et.al. (Eggert et al., 2015) utilized CNNs to ex-
tract features from logos and determined their brand
by classification with a set of Support Vector Machi-
nes (SVMs). Fast R-CNN (Girshick, 2015) was used
for the first time to retrieve logos from images by Ian-
dola et al. (Iandola et al., 2015) and achieved superior
results on the FlickrLogos-32 dataset (Romberg et al.,
2011). Furthermore, R-CNN, Fast R-CNN and Faster
R-CNN were used in (Bao et al., 2016; Oliveira et al.,
2016; Qi et al., 2017). As closed set methods, all of
them use the same brands both for training and for
validation.
2.1 Open Set Retrieval
Retrieval scenarios in other domains are basically
always considered open set, i.e., samples from the
currently searched class have never been seen be-
fore. This is the case for general purpose image
retrieval (Sivic and Zisserman, 2003), tattoo retrie-
val (Manger, 2012) or for person retrieval in image or
2
http://s.fhg.de/logos-in-the-wild
video data where face or appearance-based methods
are common (B
¨
auml et al., 2010; Weber et al., 2011;
Herrmann and Beyerer, 2015). The reason is that
these in-the-wild scenarios offer usually a too large
and impossible to capture variety of object classes. In
case of persons, a class would be a person identity
resulting in a cardinality of billions. Consequently,
methods are designed and trained on a limited set of
classes and have to generalize to previously unseen
classes. We argue that this approach is also requi-
red for logo retrieval because of the vast amount of
existing brands and according logos which cannot be
captured in advance. Typically, approaches targeting
open set scenarios consist of an object detector and a
feature extractor (Zheng et al., 2016). The detector
localizes the objects of interest and the feature extrac-
tor creates a discriminative descriptor regarding the
target classes which can than be compared to query
samples.
2.2 Object Detector Frameworks
Early detectors applied hand-crafted features, such as
Haar-like features, combined with a classifier to de-
tect objects in images (Viola and Jones, 2004). No-
wadays, deep learning methods surpass the traditional
methods by a significant margin. In addition, they al-
low a certain level of object classification within the
detector which is mostly used to simultaneously de-
tect different object categories, such as persons and
cars (Sermanet et al., 2013). The YOLO detector
(Redmon et al., 2015) introduces an end-to-end net-
work for object detection and classification based on
bounding box regressors for object localization. This
concept is similarly applied by the Single Shot Multi-
Box Detector (SSD) (Liu et al., 2016). The work on
Faster Region-Based Convolutional Neural Network
(R-CNN) (Ren et al., 2015) introduces a Region Pro-
posal Network (RPN) to detect object candidates in
the feature maps and classifies the candidate regions
by a fully connected network. Improvements of the
Faster R-CNN are the Region-based Fully Convoluti-
onal Network (R-FCN) (Dai et al., 2016), which redu-
ces inference time by an end-to-end fully convolutio-
nal network, and the Mask R-CNN (He et al., 2017),
adding a classification mask for instance segmenta-
tion.
2.3 CNN-based Classification
AlexNet (Krizhevsky et al., 2012) was the first neu-
ral network after the conquest of SVMs, achieving
impressive performance on image content classifi-
cation and winning the ImageNet challenge (Deng
Open Set Logo Detection and Retrieval
285

closed set open set
Detection +
Classification
(e.g. Yolo, SSD,
Faster R-CNN)
Comparison
(e.g. VGG, ResNet,
DenseNet)
Detection
(e.g. Yolo, SSD,
Faster R-CNN)
input
input
query
training data
(bounding boxes)
training data
(bounding boxes + label)
training data
(cropped logos + label)
logo
logo
logo
bmw
match
Figure 2: Comparison of closed and open set logo retrieval strategy.
et al., 2009). It consists of five convolutional layers,
each followed by a max-pooling, which counted as a
very deep network at the time. VGG (Simonyan and
Zisserman, 2015) follows the general architecture of
AlexNet with an increased number of convolutional
layers achieving better performance. The inception
architecture (Szegedy et al., 2015) proposed a multi-
path network module for better multi-scale addres-
sing, but was shortly after superseded by the Residual
Networks (ResNet) (He et al., 2015; He et al., 2016).
They increase network depth heavily up to 1000 lay-
ers in the most extreme configurations by additional
skip connections which bypass two convolutional lay-
ers. The recent DenseNet (Huang et al., 2016a) builds
on a ResNet-like architecture and introduces “dense
units”. The output of these units is connected with
every subsequent dense unit’s input by concatenation.
This results in a much denser network than a conven-
tional feed-forward network.
3 LOGO DETECTION
The current state-of-the-art approaches for scene re-
trieval create a global feature of the input image.
This is achieved by either inferring from the complete
image or by searching for key regions and then ex-
tracting features from the located regions, which are
finally fused into a global feature (Torii et al., 2015;
Arandjelovic et al., 2016; Kalantidis et al., 2016). For
logo retrieval, extraction of a global feature is coun-
terproductive because it lacks discriminative power to
retrieve small objects. Additionally, global features
usually include no information about the size and lo-
cation of the objects which is also an important factor
for logo retrieval applications.
Therefore, we choose a two-stage approach con-
sisting of logo detection and logo classification as fi-
gure 2 illustrates for the open set case. First, the logos
have to be detected in the input image. Since cur-
rently almost only Faster R-CNNs (Ren et al., 2015)
are used in the context of logo retrieval, we follow this
choice for better comparability and because it offers a
straightforward baseline method. Other state-of-the-
art detector options, such as SSD (Liu et al., 2016) or
YOLO (Redmon and Farhadi, 2016), potentially offer
a faster detection at the cost of detection performance
(Huang et al., 2016b).
Detection networks trained for the currently com-
mon closed set assumption are unsuitable to detect lo-
gos in an open set manner. By considering the out-
put brand probability distribution, no derivation about
occurrences of other brands are possible. Therefore,
the task raises the need for a generic logo detector,
which is able to detect all logo brands in general.
Baseline
Faster R-CNN consists of two stages, the first being
an RPN to detect object candidates in the feature maps
and the second being classifiers for the candidate re-
gions. While the second stage sharply classifies the
trained brands, the RPN will generate candidates that
vaguely resemble any of the brands which is the case
VISAPP 2018 - International Conference on Computer Vision Theory and Applications
286

Table 1: Publicly available in-the-wild logo datasets in comparison with the novel Logos in the Wild dataset.
dataset brands logo images RoIs
public
BelgaLogos (Joly and Buisson, 2009; Letessier et al., 2012) 37 1,321 2,697
FlickrBelgaLogos (Letessier et al., 2012) 37 2,697 2,697
Flickr Logos 27 (Kalantidis et al., 2011) 27 810 1,261
FlickrLogos-32 (Romberg et al., 2011) 32 2,240 3,404
Logos-32plus (Bianco et al., 2015; Bianco et al., 2017) 32 7,830 12,300
TopLogo10 (Su et al., 2016) 10 700 863
combined 80 (union) 15,598 23,222
new
Logos in the Wild 871 11,054 32,850
for many other logos. Thus, it provides an indicator
whether a region of the image is a logo or not. The
trained RPN and the underlying feature extractor net-
work are isolated and employed as a baseline open set
logo detector.
Brand Agnostic
The RPN strategy is by no means optimal because it
obviously has a bias towards the pre-trained brands
and also generates a certain amount of false positives.
Therefore, another option to detect logos is suggested
which we call the brand agnostic Faster R-CNN. It is
trained with only two classes: background and logo.
We argue that this solution which merges all brands
into a single class yields better performance than the
RPN detector because of two reasons. First, in the se-
cond stage, fully connected layers preceding the out-
put layer serve as strong classifiers which are able to
eliminate false positives. Second, these layers also
serve as stronger bounding box regressors improving
the localization precision of the logos.
4 LOGO COMPARISON
After logos are detected, the correspondences to the
query sample have to be searched. For logo retrie-
val, features are extracted from the detected logos for
comparison with the query sample. Then, the logo
feature vector for the query image and the ones for
the database are collected and normalized. Pair-wise
comparison is then performed by cosine similarity.
In order to retrieve as many logos from the images
as possible, the detector has to operate at a high recall.
However, for difficult tasks, such as open set logo de-
tection, high recall values induce a certain amount of
false positive detections. The feature extraction step
thus has to be robust and tolerant to these false positi-
ves.
Donahue et al. suggested that CNNs can produce
excellent descriptors of an input image even in the
absence of fine-tuning to the specific domain of the
image (Donahue et al., 2015). This motivates to apply
a network pre-trained on a very large dataset as fea-
ture extractor. Namely, several state-of-the-art CNNs
trained on the ImageNet dataset (Deng et al., 2009)
are explored for this task. To adjust the network to
the logo domain and the false positive removal, the
networks are fine-tuned on logo detections. The final
network layer is extracted as logo feature in all cases.
Altogether, the proposed logo retrieval system
consists of a class agnostic logo detector and a feature
extractor network. This setup is advantageous for the
quality of the extracted logo features because the ex-
tractor network has only to focus on a specific region.
This is an improvement compared to including both
logo detection and comparison in the regular Faster R-
CNN framework which lacks generalization to unseen
classes. We argue that the specialization in the regu-
lar Faster R-CNN to the limited number of specific
brands in the training set does not cover the complex-
ity and breadth of the logo domain. This is why a
separate and more elaborate feature extractor is pro-
posed.
5 LOGO DATASET
To train the proposed logo detector and feature ex-
tractor, a novel logo dataset is collected to supplement
publicly available logo datasets. A comparison to ot-
her public in-the-wild datasets with annotated boun-
ding boxes is given in table 1. The goal is an in-the-
wild logo dataset with images including logos instead
of the raw original logo graphics. In addition, ima-
ges where the logo represents only a minor part of
the image are preferred. See figure 3 for a few ex-
amples of the collected data. Following the general
suggestions from (Bansal et al., 2017), we target for
a dataset containing significantly more brands instead
of collecting additional image samples for the already
Open Set Logo Detection and Retrieval
287

Figure 3: Examples from the collected Logos in the Wild dataset.
tchibo
starbucks-
symbol
starbucks-
symbol
starbucks-text
six
Figure 4: Annotations differentiate between textual and
graphical logos.
covered brands. This is the exact opposite strategy
than performed by the Logos-32plus dataset. Starting
with a list of well-known brands and companies, an
image web search is performed. Because most ot-
her web collected logo datasets mainly rely on Flickr,
we opt for Google image search to broaden the dom-
ain. Brand or company names are searched directly or
in combination with a predefined set of search terms,
e.g., ‘advertisement’, ‘building’, ‘poster’ or ‘store’.
For each search result, the first N images are do-
wnloaded, where N is determined by a quick ma-
nual inspection to avoid collecting too many irrele-
vant images. After removing duplicates, this results
in 4 to 608 images per searched brand. These ima-
ges are then one-by-one manually annotated with logo
bounding boxes or sorted out if unsuitable. Images
are considered unsuitable if they contain no logos or
fail the in-the-wild requirement, which is the case for
the original raw logo graphics. Taken pictures of such
logos and advertisement posters on the other hand are
desired to be in the dataset. Annotations distinguish
between textual and graphical logos as well as diffe-
rent logos from one company as exemplary indicated
in figure 4. Altogether, the current version of the data-
set, contains 871 brands with 32,850 annotated boun-
ding boxes. 238 brands occur at least 10 times. An
image may contain several logos with the maximum
being 118 logos in one image. The full distributions
are shown in figures 5 and 6.
The collected Logos in the Wild dataset exceeds
the size of all related logo datasets as shown in ta-
ble 1. Even the union of all related logo datasets con-
tains significantly less brands and RoIs which makes
Logos in the Wild a valuable large-scale dataset. As
the annotation is still an ongoing process, different da-
taset revisions will be tagged by version numbers for
future reference. Note that the numbers in table 1 are
the current state (v2.0) whereas detector and feature
extractor training used a slightly earlier version with
numbers given in table 2 (v1.0) because of the requi-
red time for training and evaluation.
6 EXPERIMENTS
The proposed method is evaluated on the test set ben-
chmark of the public FlickrLogos-32 dataset inclu-
ding the distractors. Additional application specific
experiments are performed on an internal dataset of
VISAPP 2018 - International Conference on Computer Vision Theory and Applications
288
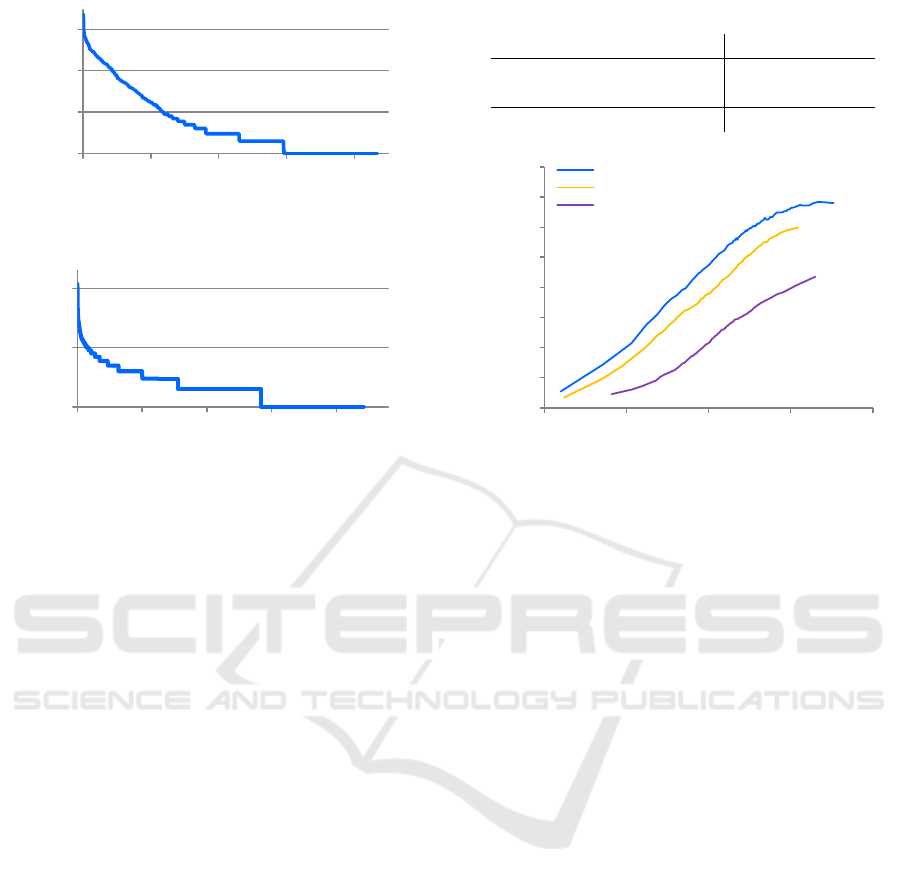
1
10
100
1000
0 200 400 600 800
RoIs per brand
brand
Figure 5: Distribution of number of RoIs per brand.
1
10
100
0 2500 5000 7500 10000
RoIs per image
image
Figure 6: Distribution of number of RoIs per image.
sports event TV broadcasts. The training set con-
sists of two parts. The union of all public logo da-
tasets as listed in table 1 and the novel Logos in the
Wild (LitW) dataset. For a proper separation of train
and test data, all brands present in the FlickrLogos-32
test set are removed from the public and LitW data.
Ten percent of the remaining images are set aside for
network validation in each case. This results in the
final training and test set sizes listed in table 2.
In the first step, the detector stage alone is asses-
sed. Then, the combination of detection and com-
parison for logo retrieval is evaluated. Detection
and matching performance is measured by the Free-
Response Receiver Operating Characteristic (FROC)
curve (Miller, 1969) which denotes the detection or
detection and identification rate versus the number of
false detections. In all cases, the CNNs are trained
until convergence. Due to the diversity of applied net-
works and differing dataset sizes, training settings are
numerous and optimized in each case with the vali-
dation data. Convergence occurs after 200 to 8,000
training iterations with a varying batch-size of 1 for
the Faster R-CNN detector, 7 for the DenseNet161,
18 for the ResNet101 and 32 for the VGG16 training
due to GPU memory limitation.
6.1 Detection
As indicated in section 3, the baseline is the state-of-
the-art closed set logo retrieval method from (Su et al.,
2016) which is trained on the public data and naively
adapted to open set detection by using the RPN scores
Table 2: Train and test set statistics.
phase data brands RoIs
train
public 47 3,113
public+LitW v1.0 632 18,960
test FlickrLogos-32 test 32 1,602
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.01 0.1 1 10 100
detection rate
average false detections per image
brand agnostic, public+LitW
brand agnostic, public
baseline, public
Figure 7: Detection FROC curves for the FlickrLogos-32
test set.
as detections The proposed brand agnostic logo detec-
tor is first trained on the same public data for compa-
rison. All Faster R-CNN detectors are based on the
VGG16 network. The results in figure 7 indicate that
the proposed brand agnostic strategy is superior by a
significant margin.
Further improvement is achieved by combining
the public training data with the novel logo data. Ad-
ding LitW as additional training data improves the de-
tection results with its large variety of additional trai-
ning brands. This confirms findings from other dom-
ains, such as face analysis, where wider training da-
tasets are preferred over deeper ones (Bansal et al.,
2017). This means it is better to train on additional
different brands than on additional samples per brand.
As direction for future dataset collection, this sugge-
sts to focus on additional brands.
6.2 Retrieval
For the retrieval experiments, the Faster R-CNN ba-
sed state-of-the-art closed set logo retrieval method
from the previous section serves again as baseline.
Now the full network is applied and the logo class
probabilities of the second stage are interpreted as
feature vector which is then used to match previ-
ously unseen logos. For the proposed open set stra-
tegy, the best logo detection network from the previ-
ous section is used in all cases. Detected logos are
described by the feature extraction network outputs
where three different state-of-the-art classification ar-
Open Set Logo Detection and Retrieval
289
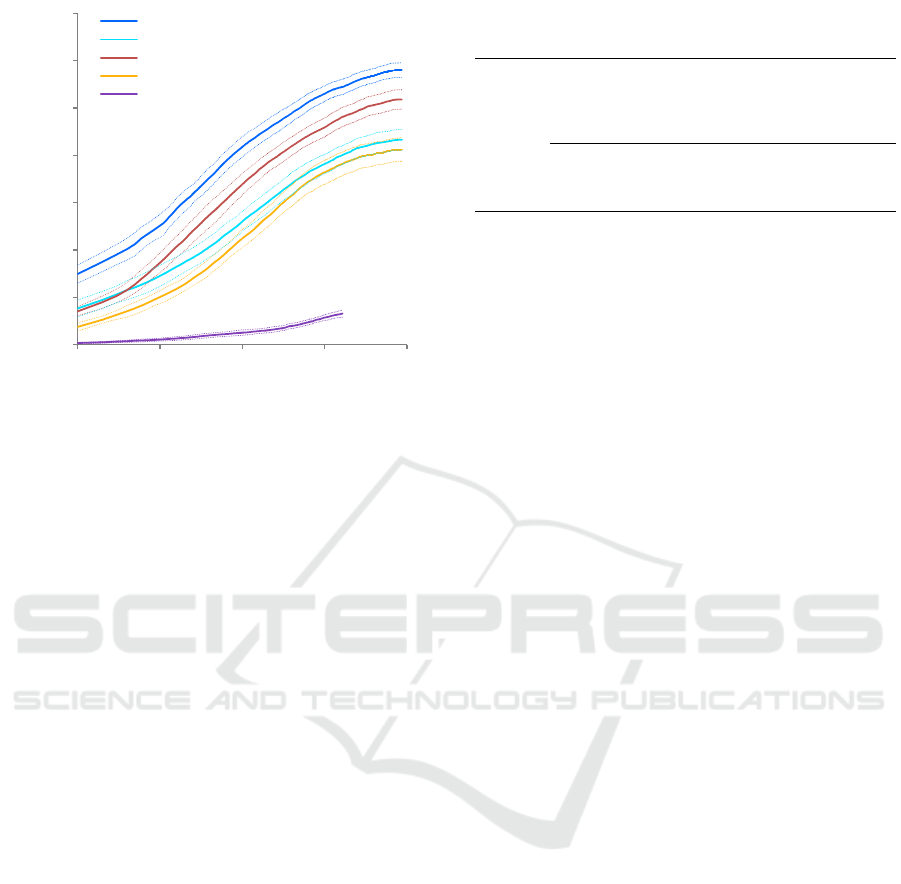
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.001 0.01 0.1 1 10
detection identification rate
average false alarms per image
ResNet101, public+LitW
ResNet101, public
VGG16, public+LitW
VGG16, public
baseline, public
Figure 8: Detection+Classification FROC curves for the
FlickrLogos-32 test set. Including dashed indicators for one
standard deviation. DenseNet results are omitted for clarity,
refer to table 3 for full results.
chitectures, namely VGG16 (Simonyan and Zisser-
man, 2015), ResNet101 (He et al., 2015) and Dense-
Net161 (Huang et al., 2016a), serve as base networks.
All networks are pretrained on ImageNet and after-
wards fine-tuned either on the public logo train set or
the combination of the public and the LitW train data.
FlickrLogos-32
In ten iterations, each of the ten FlickrLogos-32 train
samples for each brand serves as query sample. This
allows to assess the statistical significance of results
similar to a 10-fold-cross-validation strategy. Figure 8
shows the FROC results for the trained networks in-
cluding indicators for the standard deviation of the
measurements. The detection identification rate de-
notes the amount of ground truth logos which are
correctly detected and are assigned the correct brand.
While the baseline method is only able to find a minor
amount of the logos, our best performing approach is
able to correctly retrieve 25 percent of the logos if to-
lerating only one false alarm every 100 images. As
expected, the more recent network architectures pro-
vide better results. Also, including the LitW data in
the training yields a significant boost in performance.
Specifically, the larger training dataset has a larger
impact on the performance than a better network ar-
chitecture.
Table 3 compares our open set results with clo-
sed set results from the literature in terms of the mean
average precision (map).
We achieve more than half of the closed set per-
Table 3: FlickrLogos-32 test set retrieval results.
setting method map
open set
baseline, public (Su et al., 2016) 0.036
VGG16, public 0.286
ResNet101, public 0.327
DenseNet161, public 0.368
VGG16, public+LitW 0.382
ResNet101, public+LitW 0.464
DenseNet161, public+LitW 0.448
closed set
BD-FRCN-M (Oliveira et al., 2016) 0.735
DeepLogo (Iandola et al., 2015) 0.744
Faster-RCNN (Su et al., 2016) 0.811
Fast-M (Bao et al., 2016) 0.842
formance in terms of map with only one sample for
a brand at test time instead of dozens or hundreds of
brand samples at training time. Having only a sin-
gle sample is a significant harder retrieval task on
FlickrLogos-32 than closed set retrieval because logo
variations within a brand are uncovered by this single
sample. The test set includes such logo variations to a
certain extent which requires excellent generalization
capabilities if only one query sample is available.
In addition, our approach is not limited to the 32
FlickrLogos brands but generalizes with a similar per-
formance to further brands. In contrast, the closed set
approaches hardly generalize as is shown by the ba-
seline open set method which is based on the second
best closed set approach. The only difference is the
training on out-of-test brands for the open set task.
SportsLogos
In addition to public data, target domain specific ex-
periments are performed on TV broadcasts of sports
events. In total, this non-public test set includes
298 annotated frames with 2,348 logos of 40 brands.
In comparison to public logo datasets, the logos are
usually significantly smaller and cover only a tiny
fraction of the image area as illustrated in figure 9.
Besides perimeter advertising, logos on clothing or
equipment of the athletes and TV station or program
overlays are the most occurring logo types. Over-
all, the results in this application scenario are slightly
worse than in the FlickrLogos-32 benchmark with a
drop in map from 0.464 to 0.354 for the best perfor-
ming method, as indicated in figure 10. The baseline
approach takes the largest performance hit showing
that closed set approaches not only generalize badly
to unseen logos but also to novel domains. In contrast,
the proposed open set strategy shows a relatively sta-
ble cross-domain performance. Training with LitW
data again improves the results significantly.
VISAPP 2018 - International Conference on Computer Vision Theory and Applications
290
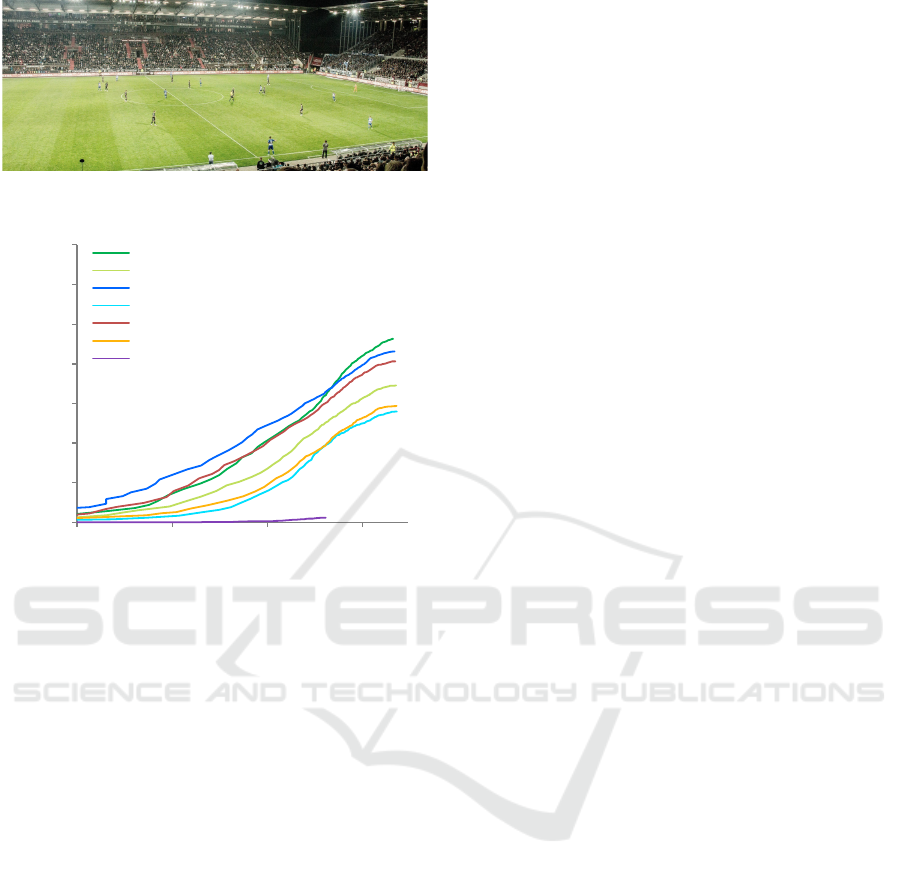
Figure 9: Example football scene with small logos in the
perimeter advertising.
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.01 0.1 1 10
detection identification rate
average false alarms per image
DenseNet161, public+LitW (0.326)
DenseNet161, public (0.256)
ResNet101, public+LitW (0.354)
ResNet101, public (0.195)
VGG16, public+LitW (0.238)
VGG16, public (0.184)
baseline, public (0.001)
Figure 10: Detection+Classification FROC curves for the
SportsLogos test set, map is given in brackets.
7 CONCLUSIONS
The limits of closed set logo retrieval approaches mo-
tivate the proposed open set approach. By this, gene-
ralization to unseen logos and novel domains is im-
proved significantly in comparison to a naive exten-
sion of closed set approaches to open set configurati-
ons. Due to the large logo variety, open set logo retrie-
val is still a challenging task where trained methods
benefit significantly from larger datasets. The lack
of sufficient data is addressed by introduction of the
large-scale Logos in the Wild dataset. Despite being
bigger than all other in-the-wild logo datasets com-
bined, dataset sizes should probably be scaled even
further in the future. Adding the Logos in the Wild
data in the training improves the mean average preci-
sion from 0.368 to 0.464 for open set logo retrieval on
FlickrLogos-32.
REFERENCES
Arandjelovic, R., Gronat, P., Torii, A., Pajdla, T., and Si-
vic, J. (2016). NetVLAD: CNN architecture for we-
akly supervised place recognition. In Proceedings of
the IEEE Conference on Computer Vision and Pattern
Recognition, pages 5297–5307.
Bansal, A., Castillo, C., Ranjan, R., and Chellappa, R.
(2017). The Do’s and Don’ts for CNN-based Face
Verification. arXiv preprint arXiv:1705.07426.
Bao, Y., Li, H., Fan, X., Liu, R., and Jia, Q. (2016). Region-
based CNN for Logo Detection. In International Con-
ference on Internet Multimedia Computing and Ser-
vice, ICIMCS’16, pages 319–322, New York, NY,
USA. ACM.
B
¨
auml, M., Bernardin, K., Fischer, M., Ekenel, H., and
Stiefelhagen, R. (2010). Multi-pose face recognition
for person retrieval in camera networks. In Internatio-
nal Conference on Advanced Video and Signal-Based
Surveillance. IEEE.
Bianco, S., Buzzelli, M., Mazzini, D., and Schettini, R.
(2015). Logo recognition using cnn features. In In-
ternational Conference on Image Analysis and Pro-
cessing, pages 438–448. Springer.
Bianco, S., Buzzelli, M., Mazzini, D., and Schettini, R.
(2017). Deep learning for logo recognition. Neuro-
computing, 245:23–30.
Dai, J., Li, Y., He, K., and Sun, J. (2016). R-FCN: Ob-
ject Detection via Region-based Fully Convolutional
Networks. arXiv preprint arXiv:1605.06409.
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-
Fei, L. (2009). Imagenet: A large-scale hierarchical
image database. In Conference on Computer Vision
and Pattern Recognition, pages 248–255. IEEE.
Donahue, J., Anne Hendricks, L., Guadarrama, S., Rohr-
bach, M., Venugopalan, S., Saenko, K., and Darrell, T.
(2015). Long-term recurrent convolutional networks
for visual recognition and description. In Conference
on Computer Vision and Pattern Recognition, pages
2625–2634. IEEE.
Eakins, J. P., Boardman, J. M., and Graham, M. E. (1998).
Similarity retrieval of trademark images. IEEE multi-
media, 5(2):53–63.
Eggert, C., Winschel, A., and Lienhart, R. (2015). On
the Benefit of Synthetic Data for Company Logo De-
tection. In ACM Multimedia Conference, MM ’15,
pages 1283–1286, New York, NY, USA. ACM.
Girshick, R. (2015). Fast R-CNN. In International Confe-
rence on Computer Vision.
He, K., Gkioxari, G., Doll
´
ar, P., and Girshick, R. (2017).
Mask R-CNN. arXiv preprint arXiv:1703.06870.
He, K., Zhang, X., Ren, S., and Sun, J. (2015). Deep Resi-
dual Learning for Image Recognition. arXiv preprint
arXiv:1512.03385.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Identity
mappings in deep residual networks. arXiv preprint
arXiv:1603.05027.
Herrmann, C. and Beyerer, J. (2015). Face Retrieval on
Large-Scale Video Data. In Canadian Conference on
Computer and Robot Vision, pages 192–199. IEEE.
Hoi, S. C. H., Wu, X., Liu, H., Wu, Y., Wang, H., Xue,
H., and Wu, Q. (2015). LOGO-Net: Large-scale
Deep Logo Detection and Brand Recognition with
Deep Region-based Convolutional Networks. CoRR,
abs/1511.02462.
Open Set Logo Detection and Retrieval
291

Huang, G., Liu, Z., and Weinberger, K. Q. (2016a). Den-
sely Connected Convolutional Networks. CoRR,
abs/1608.06993.
Huang, J., Rathod, V., Sun, C., Zhu, M., Korattikara, A.,
Fathi, A., Fischer, I., Wojna, Z., Song, Y., Guadar-
rama, S., et al. (2016b). Speed/accuracy trade-offs for
modern convolutional object detectors. arXiv preprint
arXiv:1611.10012.
Iandola, F. N., Shen, A., Gao, P., and Keutzer, K. (2015).
DeepLogo: Hitting Logo Recognition with the Deep
Neural Network Hammer. CoRR, abs/1510.02131.
Joly, A. and Buisson, O. (2009). Logo retrieval with a con-
trario visual query expansion. In ACM Multimedia
Conference, pages 581–584.
Kalantidis, Y., Mellina, C., and Osindero, S. (2016). Cross-
dimensional weighting for aggregated deep convoluti-
onal features. In European Conference on Computer
Vision, pages 685–701. Springer.
Kalantidis, Y., Pueyo, L., Trevisiol, M., van Zwol, R.,
and Avrithis, Y. (2011). Scalable Triangulation-based
Logo Recognition. In ACM International Conference
on Multimedia Retrieval, Trento, Italy.
Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2012).
ImageNet Classification with Deep Convolutional
Neural Networks. In Pereira, F., Burges, C. J. C., Bot-
tou, L., and Weinberger, K. Q., editors, Advances in
Neural Information Processing Systems, pages 1097–
1105. Curran Associates, Inc.
Letessier, P., Buisson, O., and Joly, A. (2012). Scalable
mining of small visual objects. In ACM Multimedia
Conference, pages 599–608. ACM.
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu,
C.-Y., and Berg, A. C. (2016). SSD: Single shot mul-
tibox detector. In European Conference on Computer
Vision, pages 21–37. Springer.
Manger, D. (2012). Large-scale tattoo image retrieval. In
Canadian Conference on Computer and Robot Vision,
pages 454–459. IEEE.
Miller, H. (1969). The FROC Curve: a Representation of
the Observer’s Performance for the Method of Free
Response. The Journal of the Acoustical Society of
America, 46(6(2)):1473–1476.
Oliveira, G., Fraz
˜
ao, X., Pimentel, A., and Ribeiro, B.
(2016). Automatic Graphic Logo Detection via
Fast Region-based Convolutional Networks. CoRR,
abs/1604.06083.
Qi, C., Shi, C., Wang, C., and Xiao, B. (2017). Logo Re-
trieval Using Logo Proposals and Adaptive Weighted
Pooling. IEEE Signal Processing Letters, 24(4):442–
445.
Redmon, J., Divvala, S. K., Girshick, R. B., and Farhadi,
A. (2015). You Only Look Once: Unified, Real-Time
Object Detection. CoRR, abs/1506.02640.
Redmon, J. and Farhadi, A. (2016). YOLO9000: better,
faster, stronger. arXiv preprint arXiv:1612.08242.
Ren, S., He, K., Girshick, R., and Sun, J. (2015). Faster R-
CNN: Towards real-time object detection with region
proposal networks. In Advances in Neural Informa-
tion Processing Systems, pages 91–99.
Romberg, S., Pueyo, L. G., Lienhart, R., and van Zwol,
R. (2011). Scalable Logo Recognition in Real-world
Images. In ACM International Conference on Mul-
timedia Retrieval, ICMR ’11, pages 25:1–25:8, New
York, NY, USA. ACM.
Sermanet, P., Eigen, D., Zhang, X., Mathieu, M., Fergus,
R., and LeCun, Y. (2013). OverFeat: Integrated Re-
cognition, Localization and Detection using Convolu-
tional Networks. CoRR, abs/1312.6229.
Simonyan, K. and Zisserman, A. (2015). Very deep con-
volutional networks for large-scale image recognition.
In International Conference on Learning Representa-
tions.
Sivic, J. and Zisserman, A. (2003). Video Google: A text
retrieval approach to object matching in videos. In
International Conference on Computer Vision, pages
1470–1477. IEEE.
Su, H., Zhu, X., and Gong, S. (2016). Deep Learning Logo
Detection with Data Expansion by Synthesising Con-
text. CoRR, abs/1612.09322.
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Angue-
lov, D., Erhan, D., Vanhoucke, V., and Rabinovich, A.
(2015). Going deeper with convolutions. In Confe-
rence on Computer Vision and Pattern Recognition,
pages 1–9. IEEE.
Torii, A., Arandjelovic, R., Sivic, J., Okutomi, M., and Pa-
jdla, T. (2015). 24/7 place recognition by view synthe-
sis. In Proceedings of the IEEE Conference on Com-
puter Vision and Pattern Recognition, pages 1808–
1817.
Tursun, O., Aker, C., and Kalkan, S. (2017). A Large-scale
Dataset and Benchmark for Similar Trademark Retrie-
val. arXiv preprint arXiv:1701.05766.
Viola, P. and Jones, M. J. (2004). Robust real-time face
detection. International Journal of Computer Vision,
57(2):137–154.
Weber, M., B
¨
auml, M., and Stiefelhagen, R. (2011).
Part-based clothing segmentation for person retrie-
val. In Advanced Video and Signal-Based Surveil-
lance (AVSS), 2011 8th IEEE International Confe-
rence on, pages 361–366. IEEE.
Zheng, L., Zhang, H., Sun, S., Chandraker, M., and Tian, Q.
(2016). Person Re-identification in the Wild. CoRR,
abs/1604.02531.
VISAPP 2018 - International Conference on Computer Vision Theory and Applications
292
