
An Efficient Group of Pictures Decomposition based Watermarking for
Anaglyph 3D Video
Dorra Dhaou
1
, Saoussen Ben Jabra
1,2
and Ezzedine Zagrouba
1
1
Higher Institute of Computer Science, University Tunis El Manar, LR16ES06 Research Laboratory of Computer Science,
Modeling and Information and Knowledge Processing (LIMTIC), 2 Street Abou Raihane Bayrouni, 2080 Ariana, Tunisia
2
National Engineering School of Sousse (ENISo), University of Sousse, BP 264 Sousse Erriadh 4023, Tunisia
Keywords:
3D Video Watermarking, Anaglyph, Group of Pictures, Invisibility, Robustness.
Abstract:
Due to the rapid grow of 3D technology, 3D video consumption over the internet is proliferated. 3D Content
protection has then become an important challenging problem for many researchers. Watermarking allows
resolving this problem by embedding a signature into 3D video content. However, only a few works are pro-
posed for 3D anaglyph content protection. In this paper, a new approach of 3D video anaglyph watermarking
is proposed. In fact, the anaglyph 3D technique is considered as the best used technique for creating 3D per-
ception for both images and videos. The proposed approach is based on GOP decomposition where original
video is considered as a set of Group of pictures (GOP). Each GOP will be divided in three types of images:
only one reference image and several B and R images. Then, every type of images will be marked using a
different algorithm based on blue, red or depth channel. This allows to benefit from advantage of every chan-
nel. Experimental results show a high level of invisibility of the proposed approach and a robustness against
several attacks such as compression, noise, filtering, frame suppression, and geometric transformations.
1 INTRODUCTION
Thanks to the availability of 3D TVs, the high-speed
Internet access and the progression of 3D technology,
the popularity of 3D videos increases daily. Indeed,
3D video is getting an enormous public attention re-
cently because of vivid stereo visual experience over
2D video. There are several ways and techniques to
perceive videos in 3D such as the polarized light sy-
stem and the active shutter system. Despite the ad-
vantages of these two techniques, they present a main
drawback which is the hardware requirement. In fact,
the active shutter system requires a special display
with an alternate liquid crystal shutter glasses which
is too expensive because of the needed electronic de-
vice while in the case of the polarized system, a po-
larized display is needed such the pairs of polarized
filter glasses which are also very expensive. Anot-
her display mode for 3D videos that has taken the at-
tention of researchers is the anaglyph mode. In fact,
an anaglyph 3D image consists of two superimposed
images (called homologues) of complementary colors
representing the same scene but seen from slightly
offset points : usually the left view in red and the right
view in cyan. It is a printed image to be seen in relief,
using two filters of different colors (3D glasses) pla-
ced in front of each eye of the observer. Anaglyph 3D
images contain two filtered colored images (red and
cyan), one for each eye. The anaglyphic processing is
the cheapest and the most simple way to make the 3D
visual experience accomplishable on ordinary moni-
tors without any special hardware needed, just only
colored glasses.
Due to the quick development of the 3D multi-
media technology, the transmission of 3D video con-
tent over the internet became very easy. However,
this content cannot be distributed illegally without
any protection. For produced views generated from a
depth image-based rendering technique, the left and
right views can be distributed as a 3D content and
also, the center, the left and right views, can be dis-
tributed separately as a 2D content. Protecting these
views from unauthorized distribution becomes a very
significant and important issue. Watermarking techni-
que presents an effective solution for this problem be-
cause it provides security and copyright protection to
digital data. Indeed, it consists to insert a robust and
invisible signature into an original 3D video then to
try to detect the presence of the embedded signature
after any attack applied on marked content.
Several 2D video watermarking works have been
proposed in the literature but regarding 3D videos, the
Dhaou, D., Jabra, S. and Zagrouba, E.
An Efficient Group of Pictures Decomposition based Watermarking for Anaglyph 3D Video.
DOI: 10.5220/0006619305010510
In Proceedings of the 13th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2018) - Volume 4: VISAPP, pages
501-510
ISBN: 978-989-758-290-5
Copyright © 2018 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
501

field is still not mature given the diversity of display
models and the complexity of 3D data. Most of the
techniques that have been proposed for 3D video wa-
termarking consider 3D video as a set of video views
plus a rendered depth image (Multi view Video plus
Depth MVD). Hence, they insert the signature into
this Depth Image Based Rendering (DIBR) using a
still image embedding scheme (Asikuzzaman et al.,
2016) (Rana and Sur, 2015).
Concerning 3D anaglyph video, only few works
are proposed and they didn’t maximize the compro-
mise invisibility / robustness. In order to resolve this
problem, we propose in this paper a new robust ap-
proach of 3D anaglyph video based on GOP decom-
position in which, the original video is considered as
a set of GOP. Each GOP will be divided into three
image types : one reference image I, R, and B images.
The reference image will be marked using a depth ba-
sed embedding, R image will be marked using a red
channel based embedding and B image using a blue
channel based scheme. This allows benefiting from
the robustness of every emebedding scheme. In order
to maximize the invisibility of the proposed approach,
the GOP will contain B images more than R images
because the eye is less sensitive to the blue channel.
The remaining of this paper is organized as fol-
lows: the next section presents a state of the art of
anaglyph 3D images and 3D videos watermarking
schemes. Section 3 deals with the different steps of
the proposed approach of anaglyph 3D video water-
marking based on GOP. Section 4 evaluates the per-
formance of the proposed method by giving the expe-
rimental results. Finally, a conclusion and some per-
spectives are drawn.
2 STATE OF THE ART
An anaglyph 3D video can be considered as a se-
quence of anaglyph 3D images. Hence, an anaglyph
3D video watermarking scheme can apply an anag-
lyph 3D image technique into images which com-
pose the 3D video. For this reason, we begun by stu-
dying the existing watermarking techniques proposed
for 3D anaglyph images.
2.1 Overview of Anaglyph 3D Image
Watermarking
The existing approaches proposed for anaglyph 3D
images can be classified according to two criteria: the
chosen channel for the embedding and the used trans-
formation.
Based on the first criteria, signature can be embed-
ded into one of the two pairs of stereo images using
a 2D embedding scheme. The watermarked image
will then be combined with the other views in order
to obtain the marked anaglyph 3D image. We have
noted that in the most of the proposed works, authors
insert the signature in the blue image because the hu-
man eye is less sensitive to the blue color. This allows
obtainning a high level of invisibility but it decreases
the robustness (Prathap and Anitha, 2014).
(Patel and Bhatt, 2015) propose a watermarking
scheme based on Wavelets where the signature is in-
serted into the blue image (right view). The obtained
marked blue image is then combined with the origi-
nal red image (left view) to obtain a marked anaglyph
3D image. For signature extraction, an inverse de-
anaglyph process is used to separate the two stereo-
scopic images and the signature is extracted from blue
image. This method has proven a high level of invi-
sibility but it is not robust to the majority of attacks.
Another watermarking technique is proposed in (Za-
dokar and Rathod, 2015) and (Zadokar et al., 2013)
where the mark is embedded into the three images
composing the anaglyph 3D image : red (left view),
blue (right view), and depth image. This technique
offers a better robustness against different attacks and
high invisibility.
Concerning the used transformation, we have no-
ted that the most of the proposed works are mainly
based on the Wavelet Transformation to embed sig-
nature in the anaglyph 3D images by modifying the
high frequencies in order to maximize the invisibility
and robustness compromise (Patel and Bhatt, 2015),
(Zadokar et al., 2013).
In (Prathap and Anitha, 2014) a simple scheme for
the protection of 3D red-cyan anaglyph images based
on 3D-DWT and the Jacket matrix is proposed. In
this approach, the original image is transformed using
multi-level 3D-DWT and the middle level sub-bands
are divided into blocks. Next, the Jacket matrix is
applied to the middle level sub-band blocks and the
signature is embedded by modifying the diagonal ele-
ments of each block. This method is robust against
several attacks thanks to the use of the decomposition
level of 3D-DWT, the block size, the minimum value
of middle level sub-bands and the watermark strength
factor. In addition, it is a blind watermarking scheme
that does not require the original image during the ex-
traction process. Therefore, this method has a good
invisibility with a PSNR value greater than 51 dB.
(Devi et al., 2016) proposed a robust and optimi-
zed blind encrypted three dimensional red-cyan anag-
lyph image watermarking system. In fact, the propo-
sed approach comprises two phases: trainning phase
VISAPP 2018 - International Conference on Computer Vision Theory and Applications
502

and testing phase. In the training phase, the origi-
nal red-cyan anaglyph cover image is decomposed ap-
plying Discrete Wavelet Transform (DWT) to get the
low and high pass filter values. The DWT transfor-
med bits (LH and HL) are optimized using genetic al-
gorithm (GA) and are trained using Back Propagation
neural Network (BPN). During the testing phase, a bi-
nary image with a size of 32 × 32 is embedded after
applying the Advanced Encryption Standard (AES)
encryption method into the three dimensional anag-
lyph image by adding it to the optimized transformed
bits. Finally, the extraction of the embedded image
is done by finding the Eigen feature vectors that give
the characteristic values for the extraction of the wa-
termarked image.
(Munoz-Ramirez et al., 2015) propose to embed
the signature into the frequency domain using the Dis-
crete Cosine Transform (DCT) and quantization of
index modulation (QIM) with its variant Dither Mo-
dulation (DM). (Rakesh and Dr.K.Sri Rama, 2016)
proposed a watermarking algorithm for anaglyph 3D
images based on the Fourier Fractional Transform
(FrFT). In this approach, the watermark is embedded
into the right image (blue channel) of the anaglyph
3D image after applying the 2-D FrFT transformation.
Then, the watermarked right image and left image are
combined to obtain the marked anaglyph 3D image.
At extraction step, the signature is detected by cal-
culating the threshold and comparing it with the de-
tection value.
(Wang et al., 2015) proposed two 3D watermar-
king scheme for 3D anaglyph image. The first one
uses Spread Spectrum (SS) technology to embed sig-
nature while the second is based on adaptive Dither
Modulation (DM) with Watsons improved perception
model. The two schemes present a robustness against
several attacks and a high level of invisibility.
An other blind three-dimensional anaglyph image
watermarking scheme for copyright protection is pro-
posed in (Devi and Singh, 2017) where the N-level
nonsubsampled contourlet transform and the Princi-
pal Component Analysis (PCA) are used to embedd
signature. In fact, The binary watermark is encrypted
using Arnold transform. Then, it is embedded into the
selected sub-band of the nonsubsampled contourlet-
transformed anaglyph 3D image using the principal
component analysis.
2.2 Overview of 3D Anaglyph Video
Watermarking
Based on our knowledge, there are only two existing
works proposed for anaglyph 3D videos watermar-
king until now. Indeed, the first work (Waleed et al.,
2013) is based on RGB color analysis where the sig-
nature is inserted in all the blue channels of all frames
composing the original anaglyph 3D video using the
Discret Wavelet Transform (DWT). The blue channel
is chosen because the blue color variation is hardly
perceived by the human visual system. For this appro-
ach, a 4-level Discrete Wavelet Transform is perfor-
med to the blue channel and the signature is embed-
ded in the high frequency bands (HH) of that chan-
nel. The detection step is blind and didn’t require the
original signature or the original video during the ex-
traction process.
The second scheme is a blind and invisible water-
marking technique based on scenes change detection.
Since human eye is less sensitive to blue color, the
signature bits are inserted into the high frequency
bands (HH) of the blue channel of the anaglyph fra-
mes where a scene change is detected (Salih et al.,
2015).
Despite the advantages of these two proposed ap-
proaches, they are not robust against the most impor-
tant video attacks. In fact, the insertion of mark only
in the blue images forming the video causes a lack of
robustness if the attack targets the blue images of the
video then the signature will be easily lost. Hence,
an insertion in the different views of the anaglyph
image is necessary to obtain a high level of robust-
ness. Moreover, if the signature is inserted only in
scenes change frames, a fragile watermarking can be
obtained in the case of videos presenting a single or a
small number of scenes.
Table 1: Comparison of the existing approaches.
Proposed
works
Method Invisivility Robustness
(Prathap and
Anitha, 2014)
image + (51 dB) JPEG compression, Filtering,
Noise, Geometric attacks, Contrast
adjustment, Color quantization.
(Devi et al.,
2016)
image + (53 dB) Filtering, Noise, Geometric at-
tacks, Blurring, Histogram Equali-
zation, Color quatization, Gamma
correction.
(Munoz-
Ramirez
et al., 2015)
image + (40 dB) JPEG compression, Noise.
(Rakesh and
Dr.K.Sri Rama,
2016)
image - (27 dB) Not mentioned
(Wang et al.,
2015)
image + (41 dB) Noise, Shrinking, Filtering, cut-
ting, JPEG compression, Lumi-
nance change, Volumetric scaling.
(Devi and
Singh, 2017)
image ++ (69 dB) Filtering, Noise, Geometric at-
tacks, Blurring, Histogram Equali-
zation, Color quantization, Gamma
correction, Contrast adjustment.
(Waleed et al.,
2013)
video ++ (65 dB) Noise, Cropping, Filtering,
Gamma correlation, Intensity
Adjustment,
(Salih et al.,
2015)
video ++ (69 dB) Histogram equalization, JPEG
compression.
An Efficient Group of Pictures Decomposition based Watermarking for Anaglyph 3D Video
503

In table 1, the existing approaches are compared
based on the most important criteria: invisibility and
robustness. We can observe that the majority of the
existing approaches guarantee a high level of invisi-
bility however they don’t resist against the most im-
portant attacks such as MPEG compression and fra-
mes suppression. Moreover, All the existing approa-
ches didn’t evaluate the combination of manipulations
which is an important attack to assess any video wa-
termarking approach.
3 PROPOSED ANAGLYPH 3D
VIDEO WATERMARKING
APPROACH
In order to avoid all the disadvantages of the existing
techniques, a new approach of 3D anaglyph video wa-
termarking based on GOP decomposition is proposed
in this paper. There are two main steps in this scheme:
GOP decomposition and signature embedding.
Giving an original 3D anaglyph video, it will be
decomposed in different Groups of Pictures (GOP).
Then, each GOP will be divided in three types of ima-
ges : reference image that we called I, Blue and Red
images that we called respectively B and R. Every
type of images will be marked using a different em-
bedding algorithm in order to maximize the robust-
ness of the proposed approach. Indeed, B images will
be marked using a scheme which modify only blue
channel, R images will be marked by modifying only
red channel and finally I image will be marked by
modifying all of red, blue channels in addition of the
depth image. Hence, if any attack removes one type
of images, the detection algorithm will be able to ex-
tract signature from the other types of images. Mo-
reover, in order to increase the invisibility of the pro-
posed scheme, the GOP must contain a larger number
of B images because the human eye is less sensitive
to the blue channel. Embedding process will be based
on Discrete Wavelet Transform (DWT), which allows
obtainning robustness against usual attacks.
The general watermarking scheme consists then of
the following steps :
1. Divide the original anaglyph 3D video into a set
of GOP.
2. Divide each GOP into three types of images : I, B
and R images.
3. Repeat the embedding stages for every GOP:
(a) Embed the signature into the blue and red chan-
nels in addition of the depth image generated
from I image.
(b) Embed the signature into the blue channel of B
images.
(c) Embed the signature into the red channel of R
images.
4. Combine the marked channels of each type of
images with their complementary original chan-
nels to obtain the marked anaglyph 3D images.
5. Combine all marked GOP in order to generate the
marked anaglyph 3D video.
Basic building block of the proposed approach is
shown in the Figure 1.
Figure 1: The general layout of the proposed approach.
VISAPP 2018 - International Conference on Computer Vision Theory and Applications
504

3.1 GOP Decomposition
In order to guarantee a high level of robustness against
attacks and especially against MPEG compression
and frames suppression attacks, the first step of the
proposed approach consists in decomposing the ori-
ginal anaglyph 3D video into a set of Group of Pic-
tures (GOP). Indeed, several existing video water-
marking techniques are based on GOP decomposi-
tion which is used in MPEG compression process. In
(Liu and Zhao, 2010), a watermarking algorithm ba-
sed on GOP decomposition was proposed. In fact,
the original 2D video sequence is divided into GOP.
Then, the signature is embedding in the coefficients
obatained after applying the 1D DFT transformation
on each GOP in order to improve the robustness of
the algorithm. In (Liu et al., 2008) a real-time video
watermarking scheme is presented by embedding the
watermark bits both in I and P frames based on GOP
decomposition. An uncompressed video watermar-
king system based on Hidden Markov Model (HMM)
and Artificial Neural Network (ANN) is proposed in
(ELBAS¸I, 2010). In fact, the proposed scheme splits
the video sequences into GOP with HMM. Then, Por-
tions of the binary watermark are embedded into each
GOP with a wavelet domain watermarking algorithm.
The embedding process is the standard additive al-
gorithm in low pass (LL) and high pass (HH) bands
in the wavelet domain. This proposed system increa-
ses the robustness against geometric and temporal at-
tacks, and increases the quality of the marked video.
In order to choice the GOP size for the proposed
approach, we consider that it is difficult to have large
changes in a video sequence after one second. Hence,
we choose one GOP per one second. Then, each GOP
is divided into three types of images : I, B and R ima-
ges. As the I image will be marked with a depth based
scheme, one only reference image is selected per one
GOP in order to guarantee a high invisibility. In ad-
dition, the number of B images should be superior to
R images because B images will be marked by mo-
difying blue channel which is the less sensitive for a
human eye. Each GOP is then composed of a single
reference image I, two R images and the rest will be
considered as B images.
Figure 2: GOP decomposition.
For the selected test videos, we have about 25 fra-
mes per second. Hence, each GOP will begin by one I
image followed by two identical parts each containing
one R image and 11 successive B images as shown in
Figure 2.
3.2 Signature Embedding
In order to increase the robustness and the invisibi-
lity of the proposed approach, a DWT based scheme
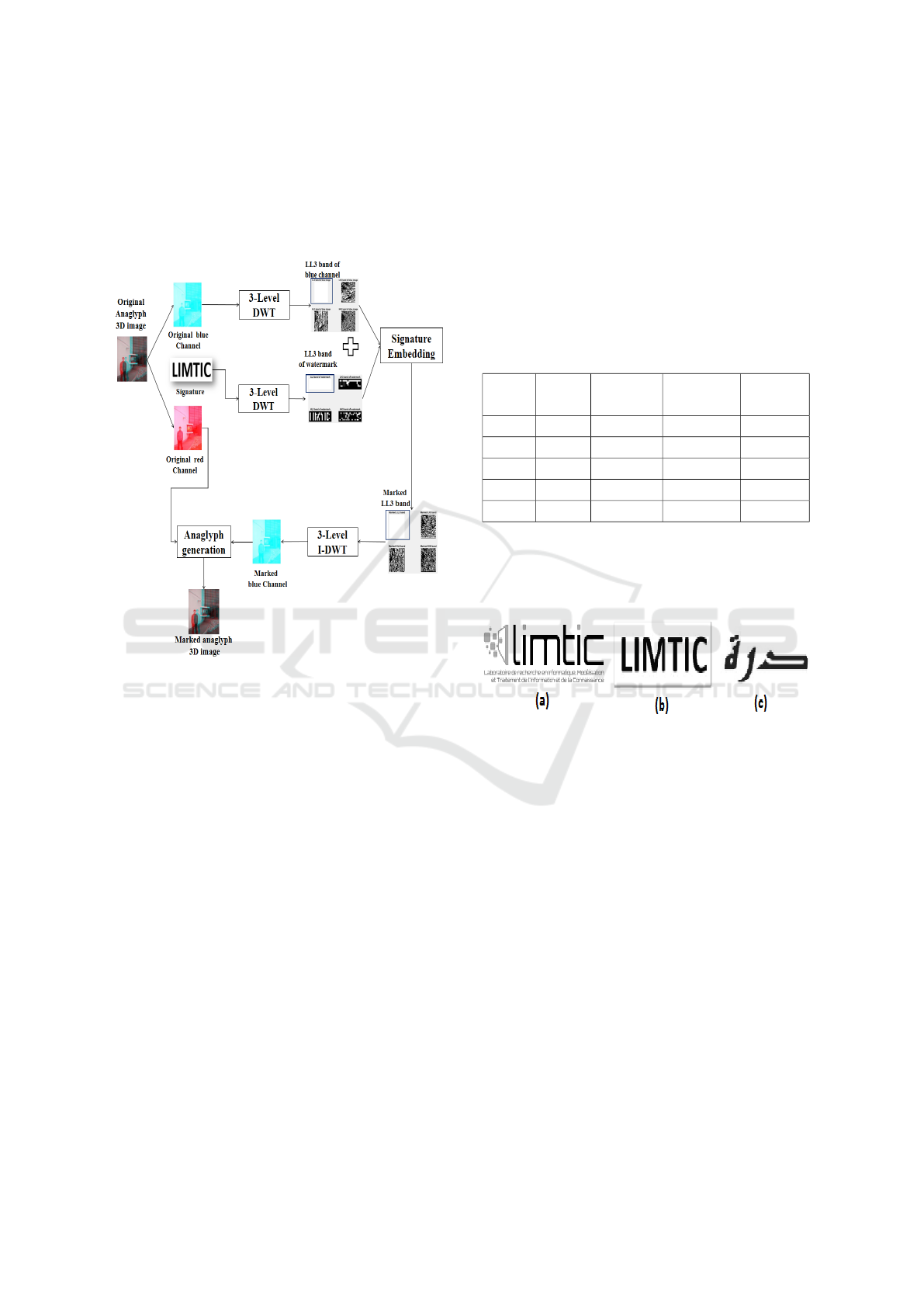
is chosen. Figure 3 shows the general architecture of
the signature embedding process which is decompo-
sed in several steps. Indeed, to embed the signature,
a three levels of wavelet decomposition are applied
on the different images of each GOP using the Haar
filter wavelet which is known for its simplicity and
speed of computation (Zhang, 2009) (Zheng et al.,
2007). DWT transformation will be applied on re-
spectively blue and red channels for B and R images
while for the reference image, DWT will be applied
on its depth image and both blue and red channels.
For each image, the watermark information is em-
bedded by adding the signature to the low frequency
sub-band (LL3) of each image in order to increase the
robustness of the signature, since it is the most sig-
nificant band, which contains more information and
includes the most energy of the image rather than the
others bands which include edge components of hori-
zontal, vertical and diagonal directions. The marked
images will be obtained by applying the inverse DWT
to the marked sub-bands. Finally, the marked B and
R images are obtained by combining respectively the
corresponding original red and blue channels with the
marked blue and red channels. The marked reference
image will be obtained by combining marked red and
blue channels with the depth image.
Given an original anaglyph 3D video, the signa-
ture embedding procedure consists then of the follo-
wing steps :
1. Apply a three levels of wavelet decomposition to
the original channel.
2. Apply a three levels of wavelet decomposition to
the signature.
3. Add the coefficients of the low frequency band of
the signature (CW
i
) to those of the original chan-
nel (C
i
) using an invisibility factor (α) to obtain
the marked coefficients (C
i
)0 according to the fol-
lowing equation :
C
i
0 = C
i
+ α ∗ CW
i
(1)
4. Apply the inverse decomposition wavelet trans-
form (I-DWT) to generate the marked channel.
An Efficient Group of Pictures Decomposition based Watermarking for Anaglyph 3D Video
505
5. Combine the marked channel to the other chan-
nels in order to obtain anaglyph 3D marked
image.
6. Combine all marked anaglyph 3D images to ge-
nerate the marked anaglyph 3D video.
Figure 3: Layout of the embedding process.
3.3 Extraction Process
The general detection scheme is decomposed in se-
veral steps where the two first ones are identical to
those of the embedding scheme.
In fact, given a marked anaglyph 3D video, it will
be decomposed in several GOP with the same frame
number chosen at embedding phase. Then, R, B and
reference images will be detected for every GOP. For
each type of image, the inverse embedding process
will be applied on the corresponding channel in which
the signature was embedded.
Given an input anaglyph 3D video, the extraction
algorithm consists of the following steps:
1. Divide the given video into several GOP.
2. Apply the 3-levels DWT to the different channels
as done in embedding process.
3. Extract the coefficients of the signature from the
low frequency band (LL3) channels.
4. Apply the inverse decomposition wavelet trans-
form (I-DWT) to recover the watermark.
4 EXPERIMENTAL RESULTS
In order to evaluate the proposed approach, a set of
robustness and invisibility tests are applied on a data-
base containing five original anaglyph 3D videos ha-
ving different characteristics of background texture,
movement, resolution and frame number.
Table 2 shows the characteristics of the chosen videos.
Moreover, for a same video, we have tested different
sizes in order to evaluate the GOP size choice.
Table 2: Video test characteristics.
Videos
Frame
number
Resolution
Background
Texture
Movement
Video 1 250 480 × 360 Uniform Slow
Video 2 750 480 × 360 Uniform Slow
Video 3 1500 640 × 180 Textured Medium
Video 4 2250 1280 × 720 Textured Rapid
Video 5 3000 480 × 360 Uniform Slow
Three different binary images (Lab Logo, Lab
name and Author name) with different sizes (245 ×
140, 160 × 50 and 80 × 25) are used as signatures
(Figure 4).
Figure 4: Original watermarks: (a) Lab logo, (b) Lab name,
(c) Author name.
4.1 Invisibility Evaluation
Figure 5 presents embedding results. No differences
can be observed between the original and marked vi-
deos.
In order to prove this high level of invisibility, the
average of the PSNR (Peak Signal to Noise Ratio) be-
tween original and marked frames is calculated. Ge-
nerally, a good invisibility is marked with a PSNR su-
perior to 40 dB.
Table 3 presents the obtained PSNR values for test
videos using the different signatures. These values
show that the proposed watermarking has a high invi-
sibility. In fact, the minimum PSNR is about 69 dB
and its maximum is about 72 dB.
Moreover, we evaluated the impact of video size
variation on the PSNR value in order to test the invisi-
bility of the proposed approach. Obtained results are
shown in Figure 6 which prove that even by increa-
VISAPP 2018 - International Conference on Computer Vision Theory and Applications
506
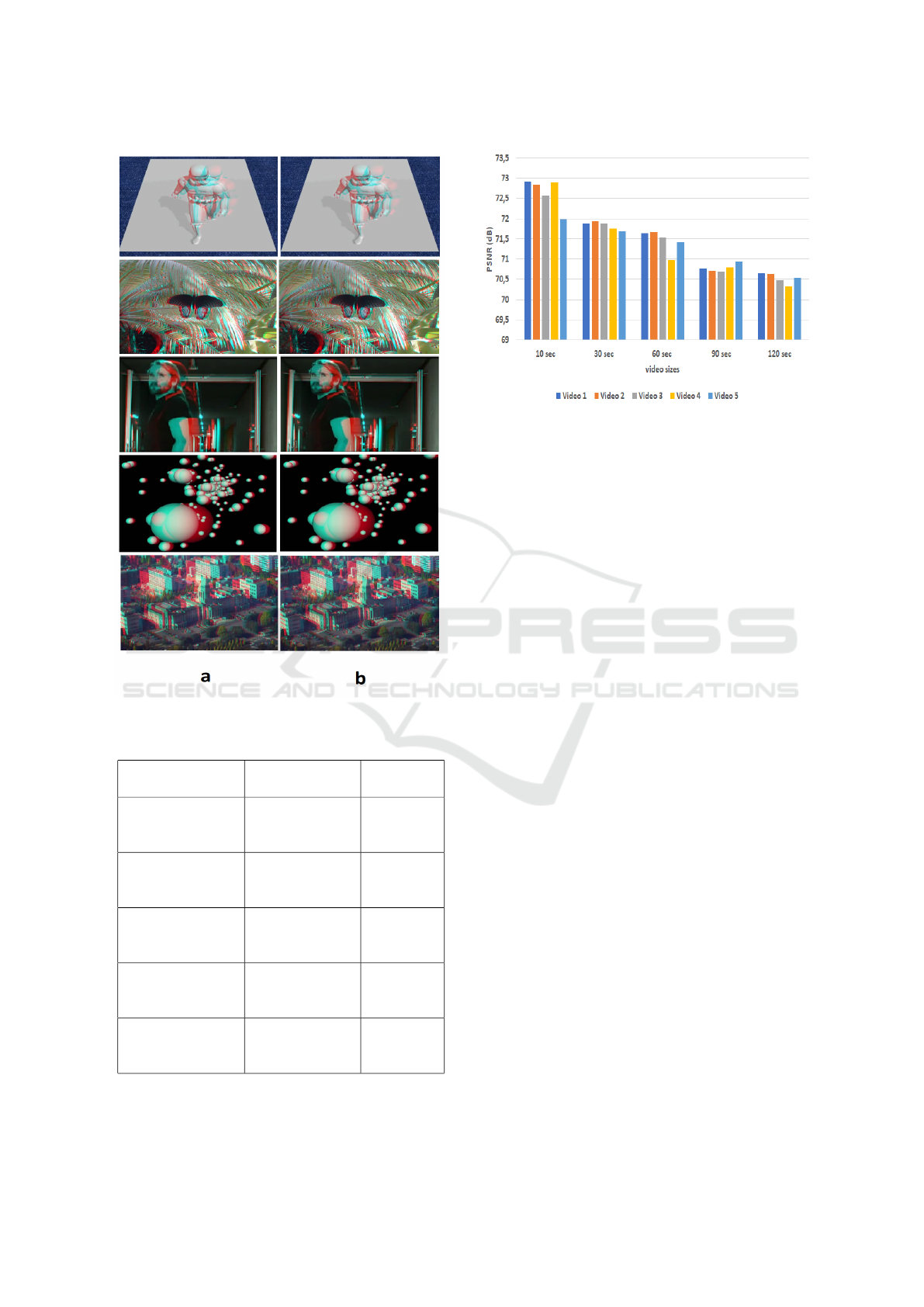
Figure 5: a- Original anaglyph frame. b- Watermarked
anaglyph frame.
Table 3: PSNR values of test videos.
Watermarked
video sequences
Watermark PSNR
Video 1
(a)
(b)
(c)
70.99
71.90
72.91
Video 2
(a)
(b)
(c)
70.93
71.82
71.89
Video 3
(a)
(b)
(c)
70.89
71.32
71.64
Video 4
(a)
(b)
(c)
70.77
70.68
70.56
Video 5
(a)
(b)
(c)
70.65
70.52
69.95
sing the size of the test video, the visual quality of the
marked video does not degrade.
Figure 6: Influence of invisibility based on video size.
4.2 Robustness Evaluation
To evaluate the robustness of the proposed approach,
different unintentional and malicious attacks are tes-
ted. These attacks were applied directly to the mar-
ked video. The Normalized Correlation value (NC)
and the Bit Error Rate (BER) are measured between
the original and the extracted marks in order to decide
the result of robustness against an attack.
In order to evaluate robustness against unintenti-
onal manipulations, geometric attacks are firstly tes-
ted as; cropping, rotation with various angles, scaling,
and resizing. Also some noises and filters were ap-
plied to the marked video and then we try to detect
the signature and calculate the BER and the Correla-
tion between extracted and original mark. Obtained
results of the Correlations values of the different test
anaglyph 3D videos without attacks and after attacks
are shown in Table 4.
The proposed approach is robust to cropping,
thanks to the repetition of the mark in all the frames.
The robustness against rotation, scaling and cropping
is obtained thanks to the use of DWT transformation,
which is invariant to these attacks.
The proposed technique is also robust against dif-
ferent noises such as salt and pepper, Gaussian, Pois-
son and Speckle, filters (Average and Gaussian filter)
and blurring where the BER was almost about 0.001
with a correlation about 0.9 almost times. This ro-
bustness was enhanced thanks to the invariance of the
used DWT transformation.
In second part, temporal attacks are tested by ap-
plying given transformation to the marked video as
deleting some frames and changing the frames orders
from the marked video.
In addition, we have tested frames transposition
and dropping until 70% into the same scene. We have
noted that the detection succeeds after all these at-
An Efficient Group of Pictures Decomposition based Watermarking for Anaglyph 3D Video
507

Table 4: Correlation values of different test videos after at-
tacks.
Attacks Video 1 Video 2 Video 3 Video 4 Video 5
Salt & Pepper
noise 0.1
0.9997 0.9995 0.9998 0.9996 0.9994
Gaussian
noise
0.9999 0.9998 0.9999 0.9997 0.9996
Poisson
noise
0.9997 0.9997 0.9996 0.9998 0.9995
Speckle
noise
0.9997 0.9998 0.9997 0.9995 0.9997
Average
Filter
0.9992 0.9994 0.9993 0.9994 0.9991
Gaussian
Filter 9x9
0.9987 0.9979 0.9969 0.9990 0.9989
Blurring 0.9998 0.9999 0.9996 0.9997 0.9995
Rotation
(50%)
09996 0.9995 0.9997 0.9998 0.9993
Rotation
(180%)
0.9958 0.9945 0.9961 0.9939 0.9986
Cropping
(50%)
0.9999 0.9996 0.9994 0.9996 0.9999
Scaling
0.9998 0.9996 0.9999 0.9997 0.9999
Frame
suppression
0.9993 0.9994 0.9995 0.9994 0.9992
Frame
swapping
0.9998 0.9997 0.9998 0.9994 0.9996
Resizing 0.9995 0.9993 0.9997 0.9996 0.9994
Histogram
equalization
0.9998 0.9995 0.9996 0.9997 0.9995
MPEG
compression
0.9999 0.9998 0.9999 0.9999 0.9997
Intensity
adjustment
1 0.9978 0.9987 0.9991 0.9999
No attacks 1 1 1 1 1
tacks. This is obtained thanks to the repetition of the
signature embedding in different GOP. This fact in-
creases the percentage of detection success even if a
part of the sequence is missed or destroyed.
Moreover, Our scheme can withstand various ot-
her attacks such as histogram equalization and Inten-
sity adjustment.
Then, the proposed scheme is evaluated against
the common video compression standards with bit
rate changing. To simulate real cases the mediaco-
der (http://www.mediacoderhq.com) software appli-
cation was adapted to transcode the marked video.
In fact, this transcoder uses different video codecs to
transcode the media to various formats. We have tes-
ted the MPEG-4 codec with a variable bit rate. Obtai-
ned results show the robustness against compression
where the BER was close to 0.0002 and the corre-
sponding correlation close to 0.99. The mark de-
tection is achieved by using the GOP decomposition
on which is based the MPEG compression. We have
also tested some combination of attacks such as rota-
tion with noise, filtering with geometric attacks and
frame suppression combined with geometric attacks.
We observe that the signature can be detected after
these manipulations which are considered as an im-
portant attacks for any video watermarking.
Finally, we noted that the proposed approach is ro-
bust against any manipulation which can attack either
only blue or red channel. This is obtained thanks to
embedding the signature in different channels of the
frames.
Figure 7 illustrates the mean BER value of the dif-
ferent anaglyph 3D video samples without attacks and
after attacks.
Figure 7: The mean BER value of different test videos.
4.3 Comparative Study
In order to assess the proposed approach, obtained re-
sults are compared with those of existing methods.
Since there exist only two anaglyph 3D video wa-
termarking schemes (Salih et al., 2015) and (Waleed
et al., 2013), we use these two techniques for the com-
parison. This last one is based on the two main fac-
tors: invisibility and robustness.
4.3.1 Invisibility Comparison
Figure 8 illustrates the obtained PSNR values by the
proposed approach and the two existing techniques in
(Salih et al., 2015) and (Waleed et al., 2013) and it
shows the high quality of our proposal.
VISAPP 2018 - International Conference on Computer Vision Theory and Applications
508

Figure 8: Invisibility comparison based on PSNR criteria.
In spite of the high visual quality of the existing
approaches, the proposed scheme allows the best in-
visibility rate where the PSNR is around 73 dB.
4.3.2 Robustness Comparison
To compare the robustness of the proposed technique
with existing approaches, we have distinguished two
categories of attacks: usual attacks as geometrics, noi-
ses, filtering, scaling and developed attacks as com-
pression, frame suppression, and combined attacks.
The proposed technique shows a good robustness
against these two types of attacks. However, a com-
parison of obtained results with previous techniques
is important to assess the proposed approach.
Table 5 resumes the robustness of each technique.
The proposed technique shows robustness to almost
of attacks whereas other techniques have some limits.
Considering usual attacks, the proposed technique has
the best robustness to filter attacks. In fact, it is robust
to Gaussian, average filter whereas (Salih et al., 2015)
and (Waleed et al., 2013) resist only to Gaussian filter.
Proposed approach has the best robustness against
noises such as Salt and Pepper , Gaussian, Poisson
and Speckle noise where the NC and the BER were
almost equal to 1 and 0 respectively. For (Salih et al.,
2015) and (Waleed et al., 2013), the NC is close to
0.9.
For geometric attacks, the proposed scheme and
the two existing schemes are robust to rotation, crop-
ping and resizing attacks with NC value equal to 0.9.
The proposed technique is robust to frame ba-
sed attacks as frame suppression and frame swapping
thanks to the embedding in all the video frames. The
proposed technique shows the best robustness against
MPEG compression whereas (Salih et al., 2015) and
(Waleed et al., 2013) are robust only to JPEG com-
pression.
Table 5: Robustness comparison between the proposed ap-
proach and the two existing techniques.
Attacks
Proposed
approach
(Salih et al., 2015) (Waleed et al., 2013)
Salt & Pepper
noise 0.1
Robust Robust Robust
Gaussian noise Robust Robust Robust
Poisson noise Robust Not Robust Not Robust
Speckle noise Robust Not Robust Not Robust
Average Filter Robust Robust Robust
Gaussian Filter
9x9
Robust Robust Robust
Blurring Robust Robust Robust
Rotation
(50%)
Robust Robust Robust
Rotation
(180%)
Robust Robust Robust
Cropping
(50%)
Robust Robust Robust
Scaling
Robust Robust Robust
Frame
suppression
Robust Not Robust Not Robust
Frame
swapping
Robust Not Robust Not Robust
Resizing Robust Robust Robust
Histogram
equalization
Robust Robust Robust
JPEG
compression
Robust Robust Robust
MPEG
compression
Robust Not Robust Not Robust
Intensity
adjustment
Robust Robust Robust
Combined
attacks
Robust Not tested Not tested
No attacks Robust Robust Robust
5 CONCLUSION
With the development of digital image and video pro-
cessing, anaglyph 3D images and videos consumption
over the internet is proliferated. To protect this type
of 3D video, a robust and invisible anaglyph 3D video
watermarking approach based on GOP decomposition
and a Discrete Wavelet Transformation is proposed in
this paper. In this approach, the original video is de-
An Efficient Group of Pictures Decomposition based Watermarking for Anaglyph 3D Video
509

composed to several GOP which are then divided in
reference, B and R images. Every type of images was
marked using a different embedding scheme. In fact,
reference image was marked by modifying its corre-
sponding depth image and both red and blue channels;
R images were marked by modifying its red channel
and finally, signature was embedded in B images by
modifying its blue channel. This allows maximizing
the robustness of our approach and obtaining a high
level of invisibility. In order to maximize the per-
formance of our approach, we choose 25 frames by
GOP (1 second = 1 GOP) and for each GOP we se-
lected the first image as a reference image, 2 R ima-
ges and the rest will be considered as B images be-
cause the human eye is less sensitive to the blue co-
lor. Experimentations show that the proposed appro-
ach is robust against several attacks such as geometric
attacks, frame suppression, compression, noises and
filtering with a high visual quality level. In addition,
The comparison of the proposed approach with ex-
isting techniques shows the good performance of the
proposed scheme to resist almost attacks types with a
good invisibility.
As future work, we will try to enhance the propo-
sed approach in order to be robust against other in-
tentional attacks and especially against collusion and
camcording.
REFERENCES
Asikuzzaman, M., Alam, M. J., Lambert, A. J., and Picke-
ring, M. R. (2016). Robust dt cwt-based dibr 3d video
watermarking using chrominance embedding. IEEE
Transactions on Multimedia, 18(9):1733–1748.
Devi, H. S., Imphal, T., and Singh, K. M. (2016). A ro-
bust and optimized 3d red-cyan anaglyph blind image
watermarking in the dwt domain.
Devi, H. S. and Singh, K. M. (2017). A novel, efficient, ro-
bust, and blind imperceptible 3d anaglyph image wa-
termarking. Arabian Journal for Science and Engi-
neering, pages 1–13.
ELBAS¸I, E. (2010). Robust multimedia watermarking: hid-
den markov model approach for video sequences. Tur-
kish Journal of Electrical Engineering & Computer
Sciences, 18(2):159–170.
Liu, S., Chen, T., Yao, H., and Gao, W. (2008). A real-time
video watermarking using adjacent luminance blocks
correlation based on compressed domain. In Intelli-
gent Information Hiding and Multimedia Signal Pro-
cessing, 2008. IIHMSP’08 International Conference
on, pages 833–836. IEEE.
Liu, Y. and Zhao, J. (2010). A new video watermarking
algorithm based on 1d dft and radon transform. Signal
Processing, 90(2):626–639.
Munoz-Ramirez, D. O., Reyes-Reyes, R., Ponomaryov, V.,
and Cruz-Ramos, C. (2015). Invisible digital color
watermarking technique in anaglyph 3d images. In
Electrical Engineering, Computing Science and Auto-
matic Control (CCE), 2015 12th International Confe-
rence on, pages 1–6. IEEE.
Patel, R. and Bhatt, P. (2015). Robust watermarking for
anaglyph 3d images using dwt techniques. Internati-
onal Journal of Engineering and Technical Research
(IJETR), 3(6).
Prathap, I. and Anitha, R. (2014). Robust and blind water-
marking scheme for three dimensional anaglyph ima-
ges. Computers & Electrical Engineering, 40(1):51–
58.
Rakesh, Y. and Dr.K.Sri Rama, K. (2016). Digital water-
marked anaglyph 3d images using frft. International
Journal of Computer Trends and Technology (IJCTT),
41(2):77–80.
Rana, S. and Sur, A. (2015). 3d video watermarking
using dt-dwt to resist synthesis view attack. In Signal
Processing Conference (EUSIPCO), 2015 23rd Euro-
pean, pages 46–50. IEEE.
Salih, J. W., Abid, S. H., and Hasan, T. M. (2015). Imper-
ceptible 3d video watermarking technique based on
scene change detection. International Journal of Ad-
vanced Science and Technology, 82:11–22.
Waleed, J., Jun, H. D., Hameed, S., Hatem, H., and Majeed,
R. (2013). Integral algorithm to embed impercepti-
ble watermark into anaglyph 3d video. International
Journal of Advancements in Computing Technology,
5(13):163.
Wang, C., Han, F., and Zhuang, X. (2015). Robust digital
watermarking scheme of anaglyphic 3d for rgb color
images. Int. J. Image Process.(IJIP), 9(3):156.
Zadokar, S. R., Raskar, V. B., and Shinde, S. V. (2013).
A digital watermarking for anaglyph 3d images. In
Advances in Computing, Communications and Infor-
matics (ICACCI), 2013 International Conference on,
pages 483–488. IEEE.
Zadokar, S. R. and Rathod, R. B. (2015). A robust dwt
watermarking for 3d images. IJETT, 2(1).
Zhang, Y. (2009). Blind watermark algorithm based on hvs
and rbf neural network in dwt domain. WSEAS Tran-
sactions on Computers, 8(1):174–183.
Zheng, D., Liu, Y., Zhao, J., and Saddik, A. E. (2007).
A survey of rst invariant image watermarking algo-
rithms. ACM Computing Surveys (CSUR), 39(2):5.
VISAPP 2018 - International Conference on Computer Vision Theory and Applications
510
