
Recovering 3D Human Poses and Camera Motions from Deep Sequence
Takashi Shimizu, Fumihiko Sakaue and Jun Sato
Department of Computer Science and Engineering, Nagoya Institute of Technology,
Gokiso, Showa, Nagoya 466-8555, Japan
Keywords:
Human Poses, Camera Motions, CNN , RNN, LSTM, Deep Learning.
Abstract:
In this paper, we propose a novel method for recovering 3D human poses and camera motions from sequential
images by using CNN and LSTM. The human pose estimation from deep learning has been studied extensively
in recent years. However, the existing methods aim to classify 2D human motions i n images. Although some
methods have been proposed for r ecovering 3D human poses recently, they only considered single fr ame poses,
and sequential properties of human actions were not used efficiently. Furthermore, the existing methods
recover only 3D poses relative to the viewpoints. In this paper, we propose a method for recovering 3D
human poses and 3D camera motions simultaneously from sequential input images. In our network, CNN is
combined with LSTM, so that the proposed network can learn sequential properties of 3D human poses and
camera motions efficiently. The efficiency of the proposed method is evaluated by using real images as well
as synthetic i mages.
1 INTRODUCTION
In recent years, huma n poses and actions are measu-
red and used in various applications, such as movies
and games. The motion capture systems are often
used for mea suring human poses and actions (Lab,
2003; Shotton et al., 2011). While the early mo-
tion capture system s (Lab, 2003) require special mar-
kers on the human body, recent systems such as Ki-
nect sensors (Shotton et al., 2011) do not need to
use markers. Although these motion capture sys-
tems are very useful for short range measurements
in well-maintained environments, they cannot be used
for long range m easurements or uncontrolled environ-
ments, such as outdoor scenes. In such situations, pas-
sive methods such as camera based pose recognition
methods are very useful.
For measuring human poses and actions f rom ca-
mera images, silhouette images were often u sed fo r
neglecting the texture of clothes etc. (Agarwal and
Triggs, 2004; Sminchisescu and Telea, 2002). The
shading information was also used fo r estimating 3D
poses from a single view (Guan et al., 2009). More
recently, the deep learning has been used for pose
estimation (Toshev and Szegedy, 2014). As shown
in many recent papers, the deep learning provides us
with the state of the art accuracy in var ious fields (Le-
Cun et al., 1989; LeCun et al., 1998; L e et al., 2011;
Le, 2013; Taylor et al., 2010), and the use of deep le-
arning in the human action recognition is promising.
Although many n eural nets have been proposed for
recogn izing 2D human poses a nd actions (Toshev and
Szegedy, 2014) , the research on neu ral nets for 3D hu-
man pose recovery has just started (Chen and Rama-
nan, 201 7; Tome et al., 2017; Lin et al., 2017; Mehta
et al., 2017), and it requires more work to obtain bet-
ter accuracy and to use in various situations. In par-
ticular, most of the current works on 3D human pose
recovery are based on a single image (Chen and Ra-
manan, 2017; Tome et al., 2 017; Mehta et al., 2017).
However, human poses are highly dependent in time,
and the sequential properties may be very useful to
recover 3D poses and actions.
Thus, in th is paper, we propose a novel me thod
for recovering 3D human poses from images by using
the sequential properties in 3D poses. For this ob-
jective, we combine the stan dard convolutional neu-
ral network (CNN) with Lo ng Short- Term Memory
(LSTM) (Ho c hreiter and Schmidh uber, 1997). The
LSTM can represent the sequential properties in 3D
human poses, and h ence our network can recover 3D
human pose at each time instant considering the se-
quence of human motions. As as result, our method
can recover 3D human poses, even if some body por-
tions are oc c luded by o ther b ody portions.
Furthermore, o ur network consid e rs not only 3D
human poses, but also 3D motio ns of a camera which
observes the human. For separating 3D human moti-
Shimizu, T., Sakaue, F. and Sato, J.
Recovering 3D Human Poses and Camera Motions from Deep Sequence.
DOI: 10.5220/0006718603930398
In Proceedings of the 13th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2018) - Volume 5: VISAPP, pages
393-398
ISBN: 978-989-758-290-5
Copyright © 2018 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
393

σ
+
×
×
tanh
σ
×
tanh
h
௧
σ
X
௧
σ
+
×
×
tanh
σ
×
tanh
h
௧
ି
ଵ
σ
X
௧
ି
ଵ
σ
+
×
×
tanh
σ
×
tanh
h
௧
ା
ଵ
σ
X
௧
ା
ଵ
Figure 1: The structure and the state transition of LSTM.
X
t
and h
t
denote input and output at time t. σ denotes a
sigmoid function, which acts as a gate of data fl ow. By
controlling these gates, the LSTM can preserve sequential
information and learn time varying properties.
Deep CNN
Pose,
Motion
Input Image
Silhouette Image
Figure 2: The outline of human pose and camera motion
estimation.
ons and 3D camera motions, we fix the basis 3D coor-
dinates at the waist of a human body, and 3D human
motions and 3D camera motions a re d e scribed based
on this basis coordinates. By using our method, we
can estimate 3D huma n poses and 3D camera moti-
ons simultaneously.
In section 2, we briefly review the convolutional
neural network ( CNN) and the Long Short-Term Me-
mory (LSTM). In section 3, we propose a method for
estimating 3D human poses and camera motions by
combining CNN with LSTM. The results from the
proposed method are shown in section 4, and the con-
clusions are described in the final section.
2 CNN AND LSTM
While the fully connected neural network learn th e
weight of connection between individual nodes in
adjacent layers, the convolutional neural network
(CNN) consists of convolution layers which connect
adjacent layers by convolution, and learn s the net-
work by optimizing the kernels of convolution. As
a result, CNN can optimize feature extraction from
images, which had been conducted by man made fe-
ature detectors such as SIFT and HOG traditionally.
Nowadays, CNN is the world standard in image re-
cognition and used in various applications.
Although CNN is very useful and efficient in
image recognition, the output of CNN is determined
just from the current input images. As a result, it can-
not p rocess sequential data such as movies properly,
since the output of sequential data depends not only
on the current input, but also on the past input data.
Figure 3: 3D human body model and the DOF of each joint.
For learning sequential data, Recurrent Neural
Network (RNN) has been proposed (Mikolov et al.,
2010).The recurrent neural network p reserves sequen-
tial past data as the internal state, and can process
sequential data properly. For learning long ter m de-
pendency in seq uential data, Long Short-Term Me-
mory (LSTM) has also been proposed (Hoc hreiter and
Schmidhuber, 1997). While the o riginal RNN can
only process short term data, LSTM can learn long
term properties of data.
Fig. 1 show th e network structure and the state
transition o f LSTM. The LSTM controls lea rning pro -
cess by using gates, σ. The input gate contro ls in-
put from the previous time, and the output gate con-
trols the effect of the current layer to the next layer.
The forget gate c ontrols the destruction of data which
are no longer need ed. By c ontrolling the se gates, the
LSTM can preserve sequential inf ormation and learn
time varying properties in the data e fficiently.
3 HUMAN POSE AND CAMERA
MOTION ESTIMATION FROM
CNN AND LSTM
In this research, we combine CNN and LSTM for es-
timating 3D human poses and ca mera motions simul-
taneously. For avoiding the effect of th e variation of
backgr ound scenes, we first transform camera images
into silhouette images of human bod y and use the sil-
houette images as the input of our network as shown
in Fig. 2.
3.1 Representation of 3D Human Poses
In this research 3D human poses are represented by a
set of rotation angles at body joints. Suppose we have
N joints in a human bod y. Then, since each joint has
3 rotation axes, the human pose can be represente d by
3N rotation parameters.
VISAPP 2018 - International Conference on Computer Vision Theory and Applications
394
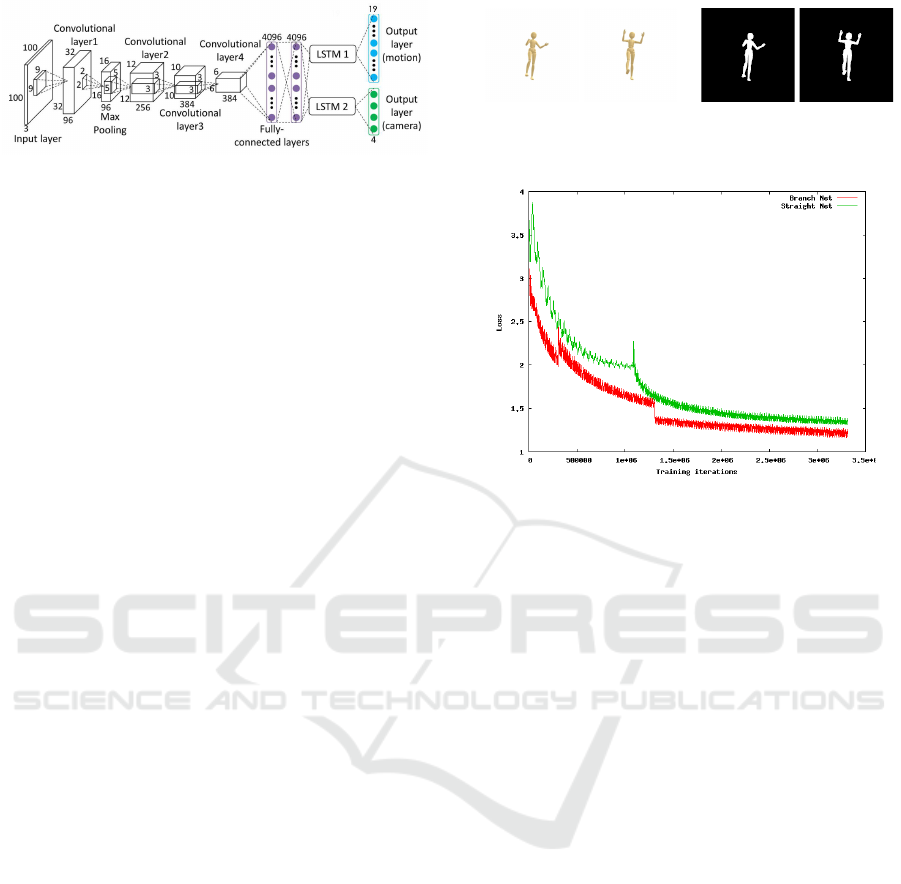
Figure 4: Proposed network structure for 3D human pose
and camera motion estimation.
However, the rota tions of arms and legs around
their axes are irreleva nt to human poses. Therefore,
we consider e a ch of the upper a rms, lower ar ms, up-
per legs and lower legs has only 2 DOF, and only the
waist has 3 DOF. Thus, in this research, we represent
the 3D hum an pose by using 19 parameters as shown
in Fig. 3.
The world coordinates are fixed at the waist of the
human body, an d 3D positions and orientations of all
the objects in the scene are represented by using the
waist based world coordinates.
3.2 Representation of Camera Motions
In this research, we assume that not only the human
body but also the camera whic h observes the human
body moves in the sequential observations. Thus, we
estimate camera positions as well as human poses at
each time instant. We assume that the viewing di-
rection of th e camera is fixed to the center of the hu-
man body, i.e. waist, and the camera p ositions are
represented by using the orientation, θ, φ, and the dis-
tance d from the waist based world coordinates. The
camera c an also rotate around the viewing axis with
ω. Thus, the camera position and o rientation have 4
parameters.
In this research we estimate these 4 parameters of
camera motions as well as 19 parameters of human
poses. Hence, we estimate totally 23 parameters.
3.3 Network Structure
We next describe the network structure of the propo-
sed method. In this research, we combine CNN and
LSTM for estimating 3D human poses and camera
motions simultaneously by using the sequential pro-
perties of h uman motions and camera motions effi-
ciently.
Suppose we have an input image x
t
from the ca-
mera at time t. Then our network estimates came ra
motion parameter s C
t
and human pose parameters P
t
at time t from the input image x
t
. Considering the
sequential prop erties of human poses and cam e ra mo-
tions, our network can be considered as a function F
which estimate the current state of th e network S
t
as
(a) input images (b) silhouette images
Figure 5: Examples of input images and silhouette images.
Figure 6: Changes in test loss in network training. The red
line shows the loss of the proposed branch net which uses
2 separate L STMs for human pose and camera motion, and
the green line shows the loss of a straight net which uses a
single LSTM for both human pose and camera motion.
well as the camera p arameters C
t
and human po se pa-
rameters P
t
from the current input image x
t
and the
previous state S
t−1
of the network as follows:
{C
t
, P
t
, S
t
} = F(x
t
, S
t−1
) (1)
Thus, learning of the network is considered as the es-
timation of function F by regression analysis.
For realizing the estimation, ou r network consists
of 4 convolution layers, a pooling layer and 2 fully
connected layers followed by 2 sets of LSTMs and
fully connected layers as shown in Fig. 4. Our net-
work first extract image features by using 4 convo-
lution layers and a pooling layer. Then 2 fully con-
nected layers transform the result into a low dimensi-
onal feature vector. Then, the result is separa te d and
analyzed by two different LSTM s, one for the esti-
mation of human pose parameters and the other for
the estimation of camera motion param eters. These
LSTMs derive feature parameters of human pose and
camera motions updating their internal state. Then,
the final layers transform these feature parameters
into 19 human pose parameters and 4 ca mera motion
parameters.
In this network, we consider the transition of hu-
man pose and the transition of camera position are in-
dependent to each other, and estimate the human po-
ses and came ra motions by using 2 different LSTM s.
By using the LSTM, w e ca n estimate 3D human po-
Recovering 3D Human Poses and Camera Motions from Deep Sequence
395
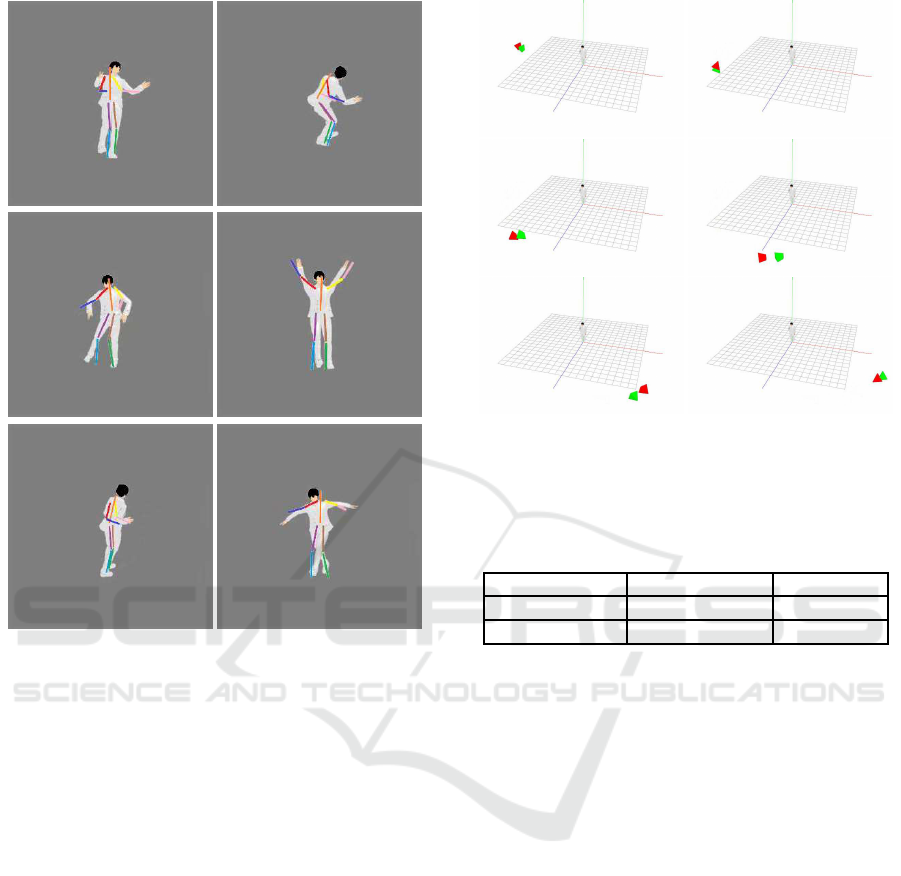
Figure 7: The result of 3D human pose estimation. The es-
timated 3D human poses were reprojected into the original
images by using the esti mated camera motion.
ses efficiently, even if some body po rtions are occlu-
ded by other body portions, which happe ns often in
silhouette images. By learning the network from the
back propagation, we realize the simultaneous esti-
mation of human poses and camera motions.
3.4 Learning Network by using CG
Models
We next consider the training of our network . For
training the network avoiding overlearning, we ne ed
huge amount of training data in general. However,
it is not easy to obtain huge amo unt of image data of
human poses under various camera m otions in the real
scene. Therefore, we in this re search use sy nthetic
images generated by using CG models.
We generated human models with various body
shapes, and ad ded various pose parameters to them.
We also gene rated a virtual camera with various mo -
tions, and obser ved the human poses to generate se-
quential CG images. For generating the pose of hu-
man, we used Mocap database (Lab, 200 3) provided
by Carnegie Mellon University. The Mocap databa se
Figure 8: The result of camera motion estimation. The red
quadrangular pyramid shows the estimated camera positi-
ons and orientations, and the green quadrangular pyramid
shows the ground truth.
Table 1: The error of 3D human pose estimation and camera
motion estimation with and without LSTM.
human pose (
◦
) camera (m)
with LSTM 11.8 2.6
without LSTM 18.2 5.7
consists of 2605 different motions, such as walking,
dancing , playing spo rts etc. We used 2000 of them
for training and used 605 of them for testing in the
synthetic image experiments. The vir tual camera was
moved around the human body fixating the viewing
direction to th e center of the world coordinates, i.e.
center of the waist of the human body.
The use of synthetic images enables us to learn
large variations of human pose parameters and ca-
mera mo tion parameters easily and efficiently. We
can also simulate various types of human body, and
control these parameters accord ing to the objective o f
application system s. By using the synthetic training
data, we train our network efficiently, a nd use it for
estimating human poses and camera motions simulta-
neously.
4 EXPERIMENTS
We next show the results of simultaneous estimation
of human poses and camera motions by using the pro-
posed network. The experime nts are conducted by
using synthetic images as well as real images.
In our experiments, a 3D human body mode l
VISAPP 2018 - International Conference on Computer Vision Theory and Applications
396
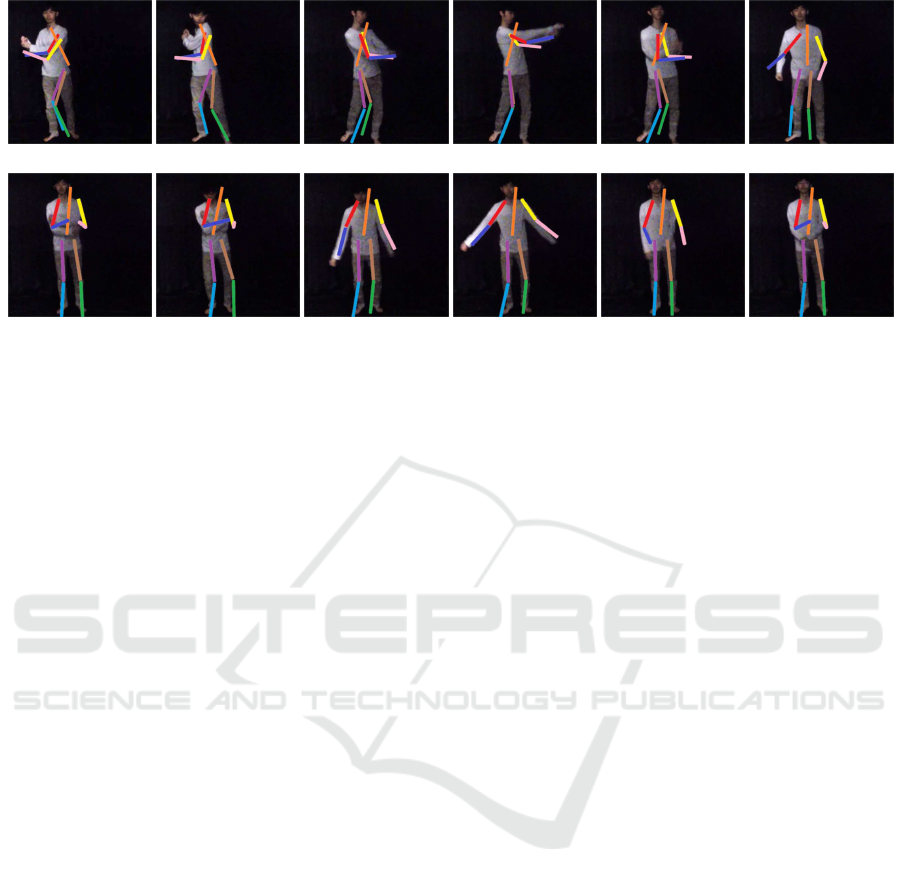
(a) batting
(b) exercise
Figure 9: The result of 3D human pose estimation. The estimated 3D human poses were reprojected into the original images
by using the estimated camera motions.
shown in Fig. 3 was used for synthesizing training
images. As we exp la ined in section 3.4, we used Mo-
cap d atabase (La b, 2003) for generating 3D human
poses. The synthetic images were generated by chan-
ging human poses and camera motions. The image
size was 100 × 100. Fig. 5 shows som e examples of
synthetic images and their silhouette images. We ge-
nerated 9000 sets of 10 sequential imag e s from 2000
motions in Mocap database random ly, and used them
for training our network. We also generated 1200 sets
of 10 sequential images from the remaining 6 05 mo-
tions in Mocap database ran domly, and used them for
testing in the synthetic image experiment. The net-
work train ing was executed by using Caffe frame-
work.
We first evaluated the efficiency of our network
structure, which uses 2 different LSTMs for huma n
pose estimation and camera motion estimation. For
compariso n, w e also evaluated a network which es-
timates human poses and camera motions by using a
single LSTM at the middle of our network shown in
Fig. 4. Fig. 6 shows the changes in test loss in these
2 networks. The red line shows the loss of the pro-
posed branch net which uses 2 separate LSTMs for
pose estimation and camera motio n estimation, and
the gr e en line shows the lo ss of a straight net which
uses a single LSTM for both pose estimation and ca-
mera motion estimation. As shown in this figur e , the
test loss of the proposed network decreases much fas-
ter than that of the straight net. This is because the
proposed network can learn the pose and motion pa-
rameters more efficiently without learning irrelevant
parameters by separating pose net a nd motion net.
We next show th e results of 3D human pose esti-
mation from synthetic images in Fig. 7. The estima-
ted 3D poses were reprojected into the original inp ut
images by using the estimated camera motions in this
figure. As shown in these ima ges, various p oses were
estimated well by using the proposed network. Fig. 8
shows the came ra motions e stima te d by the proposed
network. The red quadrangular pyramid shows the
estimated camera positions and orientations, and the
green quadrangular pyramid shows the groun d truth.
As shown in this figure, the 3D camera motions were
also estimated properly. The ac curacy of estimated
3D human poses and 3D camer a positions is as shown
in tab le 1. For comparison, we also evaluated the
accuracy of a network without LSTM. As shown in
this table, the proposed network with LSTM provides
us with much better a c curacy, and we find th at the use
of sequential properties of pose and motion is very
important.
Finally, we show the results of 3D human pose
estimation from real image sequences. Fig. 9 shows
sequential images of batting motion and exercise mo-
tion, and the estimated 3D human poses projected
into images. The silhouette images were extracted by
using the bac kground subtra ction m ethod in these ex-
periments. Although there are som e estimation errors
in the output of our network, the estimated resu lts are
reasonable.
These results show that the proposed method ena-
bles us to estimate sequ ential 3D human poses and
camera motions proper ly.
5 CONCLUSION
In this paper, we proposed a novel method for re-
covering 3D human poses and camera motions from
sequential images by using CNN and LSTM. While
the existing methods recover just 3D poses relative to
the viewpoints, our method estimates 3D human po-
Recovering 3D Human Poses and Camera Motions from Deep Sequence
397

ses and 3D camera motions simultaneously. For using
the sequential pr operties of human poses and camera
motions, we combined CNN with LSTM, and sho-
wed that they can represent sequential properties in
input data properly. We also showed that the network
structure which uses 2 separate LSTMs for 3D pose
estimation and camera motion estimatio n is efficient.
REFERENCES
Agarwal, A. and Triggs, B. (2004). 3d human pose from
silhouettes by relevance vector regression. In Proc.
CVPR.
Chen, C.-H. and Ramanan, D. (2017). 3d human pose es-
timation = 2d pose esti mation + matching. In Proc.
CVPR, pages 7035–7043.
Guan, P., Balan, A. W. A., and Black, M. (2009). Estimating
human shape and pose from a single image. In Proc.
ICCV.
Hochreiter, S. and Schmidhuber, J. (1997). Long short-term
memory. Neural Computation, 9(8):1735–1780.
Lab, C. G. (2003). Mocap: Motion capture database. In
http://mocap.cs.cmu.edu/.
Le, Q. V. (2013). Building high-level features using large
scale unsupervised learning. In Proc. International
Conference on Acoustics, Speech and Signal Proces-
sing, pages 8595–8598.
Le, Q. V., Karpenko, A., Ngiam, J., and Ng, A. Y. (2011).
Ica with reconstruction cost for efficient overcomplete
feature learning. In Advances in Neural Information
Processing Systems, pages 1017–1025.
LeCun, Y. , Boser, B., Denker, J. S., Henderson, D., Ho-
ward, R. E., Hubbard, W., and Jackel, L. D. (1989).
Backpropagation applied to handwritten zip code re-
cognition. Neural Computation, 1(4):541–551.
LeCun, Y., Bottou, L., Bengio, Y., and Haffner, P. (1998).
Gradient-based learning applied to document recogni-
tion. Proceedings of the IEEE, 86(11):2278–2324.
Lin, M., Lin, L., Liang, X., Wang, K., and Cheng, H.
(2017). Recurrent 3d pose sequence machines. In
Proc. CVPR.
Mehta, D., Sridhar, S., Sotnychenko, O., Rhodin, H.,
Shafiei, M., Seidel, H.-P., Xu, W., Casas, D., and The-
obalt, C. (2017). Vnect: Real-time 3d human pose
estimation with a single rgb camera. In Proc. SIG-
GRAPH.
Mikolov, T., Karafia, M., Burget, L., Cernocky, J., and Khu-
danpur, S. (2010). Recurrent neural network based
language model. In Proc. INTERSPEECH.
Shotton, J., Fitzgibbon, A., Cook, M., Sharp, T., Finocchio,
M., Moore, R., Kipman, A., and Blake, A. (2011).
Real-time human pose recognition in parts from single
depth images. In Proc. CVPR.
Sminchisescu, C. and Telea, A. (2002). Human pose esti-
mation from silhouettes : a consistent approach using
distance level sets. In Proc. International Conference
in Central Europe on Computer Graphics, Visualiza-
tion and Computer Vision.
Taylor, G., Fergus, R., LeCun, Y., and Bregler, C. (2010).
Convolutional learning of spatio-temporal features.
Proc. ECCV, pages 140–153.
Tome, D., Russell, C ., and Agapito, L. (2017). Lifting from
the deep: Convolutional 3d pose estimation from a
single image. In Proc. CVPR.
Toshev, A. and Szegedy, C. (2014). Deeppose: Human pose
estimation via deep neural networks. In Proc. CVPR,
pages 1653–1660.
VISAPP 2018 - International Conference on Computer Vision Theory and Applications
398
