
A Case-Based System Architecture based on Situation-Awareness for
Speech Therapy
Maria Helena Franciscatto
1
, Jo
˜
ao Carlos Damasceno Lima
1
, Augusto Moro
1
, Vin
´
ıcius Maran
1
,
Iara Augustin
1
, M
´
arcia Keske Soares
1
and Cristiano Cortez da Rocha
2
1
Universidade Federal de Santa Maria, Santa Maria, Brazil
2
Centro de Inform
´
atica e Automac¸
˜
ao do Estado de Santa Catarina (CIASC), Florian
´
opolis, Brazil
marcia-keske.soares@ufsm.br, ccrocha@ciasc.sc.gov.br
Keywords:
Case-Based Reasoning, Situation Awareness, Speech Therapy, Speech Recognition.
Abstract:
Situation Awareness (SA) involves the correct interpretation of situations, allowing a system to respond to the
observed environment and providing support for decision making in many systems domains. Speech therapy
is an example of domain where situation awareness can provide benefits, since practitioners should monitor
the patient in order to perform therapeutic actions. However, there are few proposals in the area that address
reasoning about a situation to improve these tasks. Likewise, the case-based reasoning methodology is little
approached, since existing proposals rarely use previous knowledge for problem solving. For this reason, this
paper proposes a case-based architecture to assist Speech-Language Pathologists (SLPs) in tasks involving
screening and diagnosis of speech sound disorders. We present the modules that compose the system’s archi-
tecture and results obtained from the evaluation using the Google Cloud Speech API. As main contributions,
we present the architecture of a system that aims to be situation-aware, encompassing perception, comprehen-
sion and projection of actions in the environment. Also, we present and discuss the results, towards a speech
therapy system for decision making support.
1 INTRODUCTION
Situation Awareness (SA) has been recognized as an
important and yet unsolved issue in many different
domains, including physical cyber-security systems,
epidemic monitoring and control, intelligent trans-
portation systems, among others (Kokar and Endsley,
2012). The term has been developed simultaneously
with the growth of problems interconnected to human
factors, since they require skills of perception and de-
cision making. According to Endsley (1995), “prac-
titioners must deal with human performance in tasks
that are primarily physical or perceptual, as well as
consider human behavior involving highly complex
cognitive tasks”, thus, it is necessary to conduct ac-
tions according to different context information.
In the speech therapy domain, there are few pro-
posals that use knowledge modeling to improve tasks
such as diagnosis, therapy planning and therapeutic
intervention (Chuchuca-M
´
endez et al., 2016). Also,
clinicians should be supported in achieving a good
level of situation awareness about their patient's con-
dition, when decisions need to be taken (Frost and
Gabrielli, 2013). In this sense, situation-aware sys-
tems represent powerful tools that should aid in the
process of diagnosis and clinical support.
Case-based reasoning can also be a favorable
choice in speech and health contexts, since this
methodology has good learning capabilities, and its
ability to solve problems improves as new cases are
stored in the history or in a database (Husain and
Pheng, 2010). In other words, knowing the solution to
a past clinical case (a disease or speech disorder, for
example) may be the easiest way to effectively solve
a similar case in future.
Given the need for a situation-aware approach fo-
cused on speech therapy, we present the architec-
ture of a case-based system that uses prior speech-
language knowledge to assist Speech-Language
Pathologists (SLPs) in tasks involving screening of
speech disorders and decision making. This paper
focuses on assessments performed through Google
Cloud Speech API and how these evaluations affect
the situation perception and classification of speech
disorders. We present the analyzes and discuss the
results, in order to verify the system usefulness.
Franciscatto, M., Lima, J., Moro, A., Maran, V., Augustin, I., Keske Soares, M. and Cortez da Rocha, C.
A Case-Based System Architecture based on Situation-Awareness for Speech Therapy.
DOI: 10.5220/0006781504610468
In Proceedings of the 20th International Conference on Enterprise Information Systems (ICEIS 2018), pages 461-468
ISBN: 978-989-758-298-1
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
461

The present paper is structured as follows. In the
next section we present concepts that cover Situation
Awareness and Case-Based Reasoning, as well as re-
searches that make use of these concepts. In Section 3
we present our approach of case-based system and as-
sessments performed with Google Cloud Speech API.
We discuss the results in Section 4 and conclude with
our remarks in Section 5.
2 BACKGROUND
2.1 Case-Based Reasoning
Case-Based Reasoning (CBR) describes a methodol-
ogy coming from the area of Artificial Intelligence
that draws on human reasoning for problem solv-
ing. The classic definition is given by Riesbeck and
Schank (1989), who point out that “a case-based rea-
soning solves problems using or adapting solutions to
old problems”; that is, a new problem is solved by
finding a similar past case, and reusing the informa-
tion and knowledge of this case in the new problem-
atic situation (Aamodt and Plaza, 1994).
The CBR methodology is commonly described by
a cycle of four activities: retrieving cases that resem-
ble the description of the problem, reusing an existing
solution for a similar case, reviewing this solution in
order to meet the new problem, and retaining this so-
lution once it has been confirmed (Watson, 1999).
Case-based reasoning is often used in the explo-
ration of medical or health contexts, where symptoms
represent the problem, and diagnosis and treatment
are the solution to the problem (Begum et al., 2011).
We can mention, for example, the proposal of Husain
and Pheng (2010), that addressed the development of
a recommendation system for therapy and well-being
using hybrid CBR. In the same way, Lee and Kim
(2015) proposed a recommendation system that ap-
plies CBR for immediate medical services in a cloud
computing environment.
2.2 Situation-Awareness
Situation Awareness is a term that expresses “the per-
ception of the elements of the environment within a
volume of time and space, the understanding of its
meaning and projection of its effects in the near fu-
ture” (Endsley, 1995). This definition suggests that
through situation awareness, applications and systems
are able to understand surrounding events and design
actions that can offer benefits to human life, from the
simple task of providing a personalized service to ef-
fective action in risk scenarios.
Situation perception is a critical component for
successful actions in complex and dynamic systems,
where a poorly planned action may lead to seri-
ous results (Oosthuizen and Pretorius, 2015). Thus,
situation-aware systems, in addition to dealing with
data complexity, must understand contexts and rela-
tionships in order to exercise control over situations.
Endsley (1995) proposed a model of situation aware-
ness based on three stages: perception, comprehen-
sion and projection. In other words, a system is aware
of a situation when it gets perception about the en-
vironment around it, comprehension of existing rela-
tionships and when it provides projection of actions
in accordance with the current situation.
2.3 Related Work
Salfinger, Reschitzegger and Schwinger (2013) pre-
sented a series of criteria based on components of
situation-aware systems that refer to the ability of sys-
tems to establish or obtain situation awareness as well
as maintain SA over time. According to the authors,
in order to obtain SA we must consider input data,
domain model, situation assessment and action sup-
port provided by the system. Likewise, in order to
maintain SA, the following items must be considered:
capturing and tracking evolution of situations, pro-
jection, incorporation of contextual information, in-
completeness and inconsistency of data, SA adapta-
tion, system tuning, knowledge base, incorporation of
human intelligence, personalization, explanation and
exploration. These criteria were used by Salfinger,
Reschitzegger and Schwinger (2013) to analyze ap-
proaches in different application domains, including
road traffic, maritime surveillance, driver-assistance
and airspace monitoring. In the speech therapy do-
main, we can also use the obtaining and maintaining
criteria to analyze and compare approaches, since SA
must be explored to face the challenges found in tra-
ditional therapy and provide support to SLPs. Thus,
a great variety of systems and automatic approaches
have been proposed.
Robles-Bykbaev et al. (2016) presented a spe-
cialist system for automatic generation of therapeu-
tic guidelines. The specialist system is able to se-
lect and suggest the best activities or intervention
strategies for a specific patient profile, based on their
abilities, limitations and needs. Abad et al. (2013)
proposed an automatic speech recognition technol-
ogy based on a hybrid recognizer, intended for pa-
tients with aphasia. Parnandi et al. (2015) presented
a system for speech therapy remote administration
for children with apraxia of speech, where the SLP
can assign the exercises remotely. EchoWear (Dubey
ICEIS 2018 - 20th International Conference on Enterprise Information Systems
462
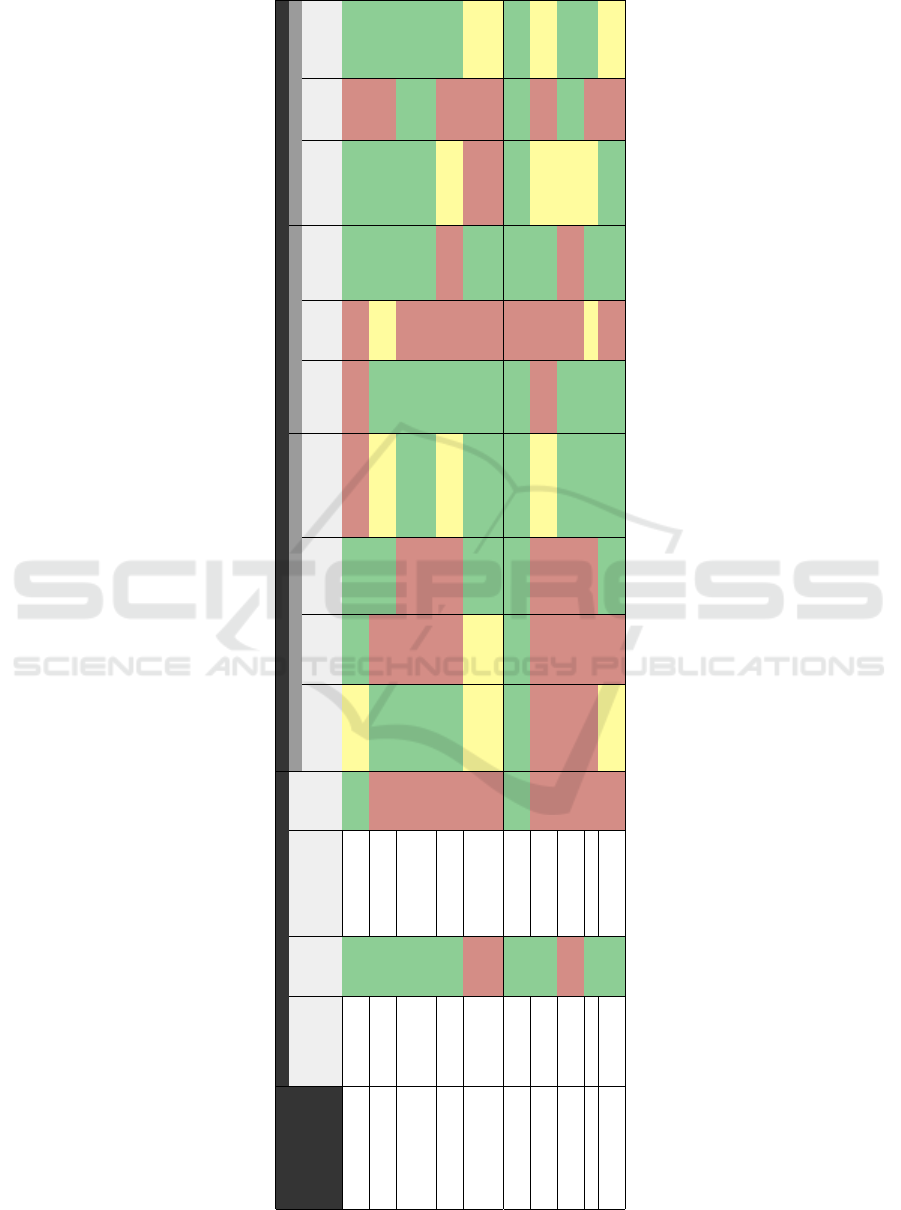
Table 1: Evaluation of related work according to SA criteria proposed by Salfinger, Retschitzegger and Schwinger (2013).
Gaining SA Maintaining SA
Environment Evolution System Evolution Usage Evolution
Approach
Input Data
Domain
Model
Situation
Assessment
Action
Support
Capturing and
Tracking
Evolution
Projection
Contextual
Information
Incompleteness
and Inconsistency
SA
Adaptation
System
Tuning
Knowledge
Base
Incorporating
Human
Intelligence
Persona-
lization
Explanation
and
Exploration
Robles-Bykbaev
et al., 2016
Heterogeneous yes
Ontology +
rules
yes partially yes yes no no no yes yes no yes
Abad et al., 2013 Heterogeneous yes
Hybrid recognizer
(HMM + MLP)
no yes no yes partially yes partially yes yes no yes
Parnandi et al., 2015 Homogeneous yes
HMM decoder.
SVM, MLP and
MaxEnt classifiers
no yes no no yes yes no yes yes yes yes
Dubey et al., 2015 Homogeneous yes
CLIP and SQM
computation
no yes no no partially yes no no partially no yes
Gabani et al., 2011 Heterogeneous no
Language models,
Machine Learning
and NLP
no partially partially yes yes yes no yes no no partially
Schipor, Pentiuc
and Schipor, 2010
Heterogeneous yes Fuzzy Logic yes yes yes yes yes yes no yes yes yes yes
Grzybowska and
Klaczynski, 2014
Homogeneous yes
DTW and kNN
algorithms
no no no no partially no no yes partially no partially
Grossinho et al., 2016 Heterogeneous no
Naive Bayes,
SVM and KDE
no no no no yes yes no no partially yes yes
Iliya and Neri, 2016 Homogeneous yes ANNs and SVM no no no no yes yes partially yes partially no yes
Ward et al., 2016 Homogeneous yes
HNN and
HMM decoder
no partially no yes yes yes no yes yes no partially
A Case-Based System Architecture based on Situation-Awareness for Speech Therapy
463
et al., 2015) represents another speech therapy sys-
tem, a smartwatch-based proposal for remotely mon-
itoring speech exercises as prescribed by an SLP. Ga-
bani et al. (2011) explored the use of an automated
method to analyze children's narratives in order to
identify the presence or absence of language impair-
ment. Schipor, Pentiuc and Schipor (2010) proposed
a CBST system (Computer Based Speech Training)
based on a therapeutic guide, in order to facilitate the
SLP's evaluation and support the therapeutic interven-
tion. Gzrybowska and Klaczynski (2014) presented a
software program that uses Automatic Speech Recog-
nition (ASR) technology to identify the speaker's
identity. The proposal aims to verify if the articulated
sound is the same as the previously recorded models.
Grossinho et al. (2016) proposed a phoneme recog-
nition solution for an interactive speech therapy envi-
ronment. Iliya and Neri (2016) pointed out the need
to detect and isolate some parts of speech, so they pre-
sented a technique based on neural system to segment
speech utterances, where two segmentation models
were developed and compared for detecting and iden-
tifying sections of disordered speech signals. Finally,
Ward et al. (2016) developed a proof-of-concept sys-
tem based on specialized SLP knowledge to identify
and evaluate phonological error patterns in children's
speech. An overview of the criteria supported by re-
lated work is presented in Table 1.
3 A CASE-BASED SYSTEM FOR
SPEECH THERAPY BASED ON
SA
3.1 System Architecture
As seen previously, traditional speech therapy
presents some obstacles which include, mainly, the
lack of specialists in the area and the difficulty of per-
forming adequate patient monitoring. We believe that
a situation-aware approach can mitigate these issues,
thus the proposed system aims to integrate aspects of
the SA Model (Endsley, 1995): Perception, Compre-
hension and Projection levels.
The first level, Perception, is achieved through
the collection of speech signals during image naming
tasks. In this way, the system is aware of elements
in the environment and their current states, evaluat-
ing their relevance to decision-making. The Com-
prehension capability should be achieved through as-
sessment tasks performed with Google Cloud Speech
API and CMUSphinx (tools for speech recognition).
A team composed by speech therapists should pro-
vide guidance in this step, collaborating for the un-
derstanding of data that may indicate the presence of
speech disorders. Also, along the CBR cycle, we aim
to increase the system's Comprehension level, basing
its actions according to previously diagnosed cases.
Lastly, the Projection level, should be achieved from
the identification and understanding of the patient's
situation. Thus, therapists can be supported in the
decision-making process, since the case-based system
should identify the best solution to deal with a situa-
tion and recommend it to the professional.
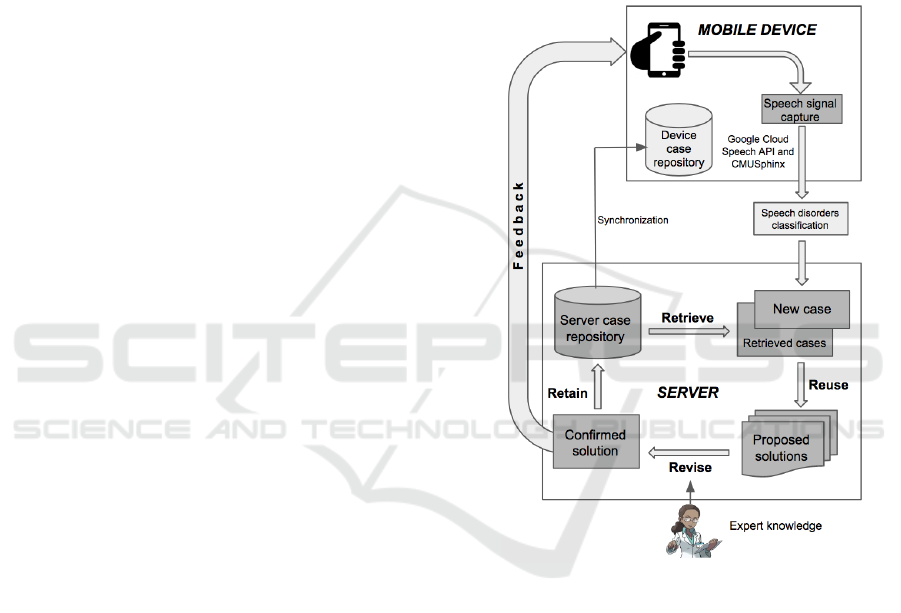
Figure 1: System’s architecture.
In order to provide Perception, Comprehension
and Projection capabilities, the proposed system ar-
chitecture consists of two main modules (see Figure
1):
• Mobile device: responsible for collecting speech
data from the target audience (children aged 3 to 8
years and 11 months) and processing it using two
specific tools: Google Cloud Speech and CMUS-
phinx. The Google Cloud Speech API is used
as initial assessment technique, making sure that
the collected data is suitable for training acous-
tic models. The CMUSphinx, in turn, is a public
domain software package for implementing auto-
matic speech recognition (ASR) systems (Oliveira
et al., 2012). In our proposal, this tool should per-
form acoustic training, thus, from the input data
ICEIS 2018 - 20th International Conference on Enterprise Information Systems
464

of a patient, it is possible to classify him/her as a
healthy individual or individual with speech dis-
order.
• Server: the server is responsible for taking each
patient evaluation analyzed in the previous mod-
ule as input for Case-Based Reasoning. In other
words, the previously classified pronunciation be-
comes a new case in the server domain, which ap-
plies the CBR methodology. Cases that are similar
to the new case are retrieved from the repository
in order to reuse an existing solution. The solu-
tion is reviewed in order to verify if it fits in the
new case and, if this solution is confirmed (with
speech therapist assistance in the review stage), it
is maintained. Thus, the case given as input in the
CBR cycle may result in a normal case or a speech
disorder case. Considering the last possibility, the
system should provide action support to the ther-
apist, indicating what measures can be taken ac-
cording to the patient's situation. At the end of the
whole process, the analyzed case is stored. Syn-
chronization occurs between the server repository
and the device repository, so that the knowledge
base always remains current with new case data.
3.2 Process of Speech Disorder
Assessment
The Google Cloud Speech API performs speech
recognition by converting audio to text through ma-
chine learning technology. More specifically, the tool
applies advanced neural network models and it is ca-
pable of performing voice transcriptions in a wide va-
riety of languages. Since the API is a simple way
for developers to integrate speech recognition capa-
bilities in their applications (Ballinger et al., 2010),
recent researches have used this technology in their
methodologies. We can mention, for example, the
proposal of Mohamed, Hassanin and Othman (2014),
which addressed an educational environment for blind
and handicapped people.
In the present paper, we specifically focus our ef-
forts on assessing whether the Google Cloud Speech
API (integrated in the first module of the architecture)
is adequate for conducting initial speech-language as-
sessments, since the evaluations aim to classify pa-
tients as individuals with speech disorders or healthy
individuals. The process of speech disorder classifi-
cation used in the first module of the architecture is
demonstrated in Figure 2.
A set of 20 target words in Brazilian Portuguese
was selected by a team of speech therapists from the
Universidade Federal de Santa Maria (Brazil) in order
to assess children’s pronunciation skills. This team of
Figure 2: Process of speech disorder classification, used in
the architecture.
SLPs performed a series of speech evaluations, which
consisted of naming tasks. In these naming tasks, the
child was presented to an image (referring to a target
word) and should pronounce the word corresponding
to this visual stimulus. At the end of each speech eval-
uation, feedback was given to the SLP through the
mobile device, stating whether the child's pronuncia-
tion was correct or incorrect, along with the transcript
of what was understood by the API (see Figure 3). In
total, 31.752 evaluations were performed with 1.362
children aged 3 to 8 years and 11 months.
Figure 3: Screenshots of the mobile application perform-
ing speech assessments with Google Cloud Speech API (in-
correct and correct pronunciation feedback from the word
corresponding to the English word ”house”).
A Case-Based System Architecture based on Situation-Awareness for Speech Therapy
465
The speech signals collected from each naming
task via mobile device were processed by Google
Cloud Speech tool. A file was generated containing
the speech data of each child and associated metadata
(personal and contextual information of the individ-
ual, as well as the transcripts of each audio) for spe-
cialist's use. The results obtained from our analyzes
are discussed in the next section.
4 DISCUSSION OF RESULTS
From a total of 31.752 evaluations performed, the ar-
chitecture, using Google Cloud Speech, returned a
transcript result to 11.641 of them. For the rest of the
evaluations (20.111), the tool was not able to under-
stand the spoken sentence. Table 2 shows the results
obtained from the 11.641 cases in which there was a
response from the API used. We consider, for each
target word:
• GCS1SLP1: Number of evaluations in which
Google Cloud Speech considered the pronuncia-
tion correct (1) and the SLP considered it correct
(1).
• GCS1SLP0: Number of evaluations in which
Google Cloud Speech considered the pronuncia-
tion correct (1) and the SLP considered it incor-
rect (0).
• GCS0SLP1: Number of evaluations in which
Google Cloud Speech considered the pronuncia-
tion incorrect (0) and the SLP considered it cor-
rect (1).
• GCS0SLP0: Number of evaluations in which
Google Cloud Speech considered the pronuncia-
tion incorrect (0) and the SLP considered it incor-
rect (0).
We considered a Concordance Rate (CR) com-
posed of cases in which the Google Cloud Speech API
and the SLP considered the child’s pronunciation as
correct added to the cases in which both considered
the pronunciation as incorrect. Thus, we have CR =
GCS1SLP1 + GCS0SLP0. Likewise, we established
a Discordance Rate (DR) composed of cases in which
the API and the SLP considered different results for
the analyzed pronunciation, so that DR = GCS1SLP0
+ GCS0SLP1.
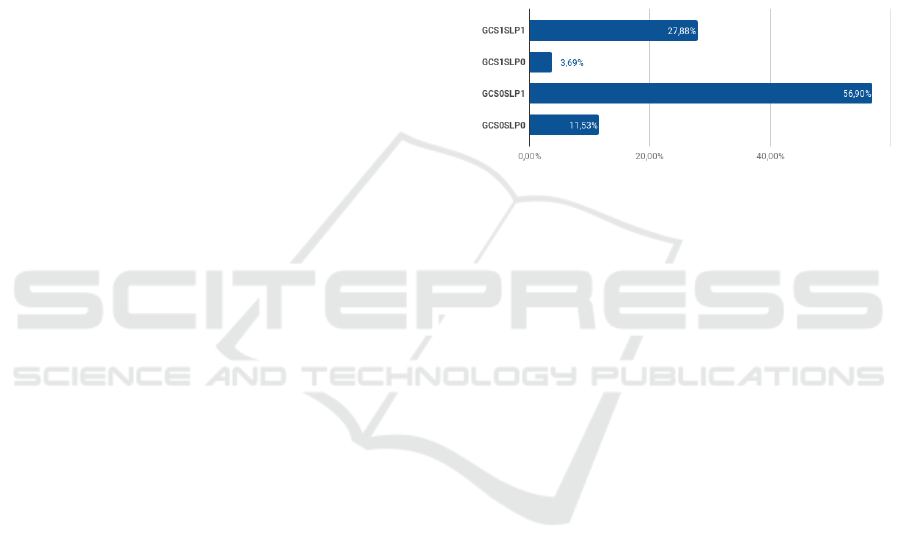
As shown in Figure 4, from the 11.641 evalua-
tions in which the Speech API returned a transcrip-
tion result, CR reached 39,41% of the cases, show-
ing concordance between the therapist and the API,
while there was a DR in 60,59% of the cases. We can
observe that the cases in which the child's pronuncia-
tion was considered incorrect by the API and correct
by the therapist (GCS0SLP1) reached the highest per-
centage among the comparative: 56,90%. We believe
that this high score is due to the low sound quality,
since there was no adjustment or modification on the
speech signal before the processing stage. Also, it
can be observed that the Discordance Rate reached
a very high value (greater than 50%), demonstrating
that the majority of responses from the API do not co-
incide with the answers given by the SLP responsible
for the pronunciation assessments. These results in-
dicate, therefore, that the Google Cloud Speech is not
the most indicated tool for speech-language screening
tasks, since it did not reached the expected CR rate.
Figure 4: Percentage of concordance and discordance be-
tween GCS API and SLP assessments.
However, it is important to note that the SLPs who
participated in the evaluation process considered, in
addition to the speech data, contextual information as
child's age and region to classify the pronunciation.
The justification is that words pronounced with an ac-
cent can be considered correct in certain regions and
incorrect in others. On the other hand, evaluations
with Google Cloud Speech API were performed with-
out contextual information integrated to speech data,
indicating that context influences the potential of the
API and the values of the calculated rates.
Besides that, we did not apply any preprocess-
ing, filtering or adjustment technique in the collected
speech signals, in the same way that we did not use
any method to optimize the processing performed by
the tool. Thus, even with the low value reached by
the CR rate (39.41%), we consider this result very
promising. In other words, we believe that CR can
reach high values if strategies are included to deal
specifically with incomplete, noisy or inconsistent
data.
5 CONCLUSIONS
In this work, a case-based system was proposed to as-
sist Speech-Language Pathologists in tasks involving
screening and diagnosis of speech disorders. Through
the literature review, we identified the lack of pro-
posals that cover Case-Based Reasoning for prob-
ICEIS 2018 - 20th International Conference on Enterprise Information Systems
466
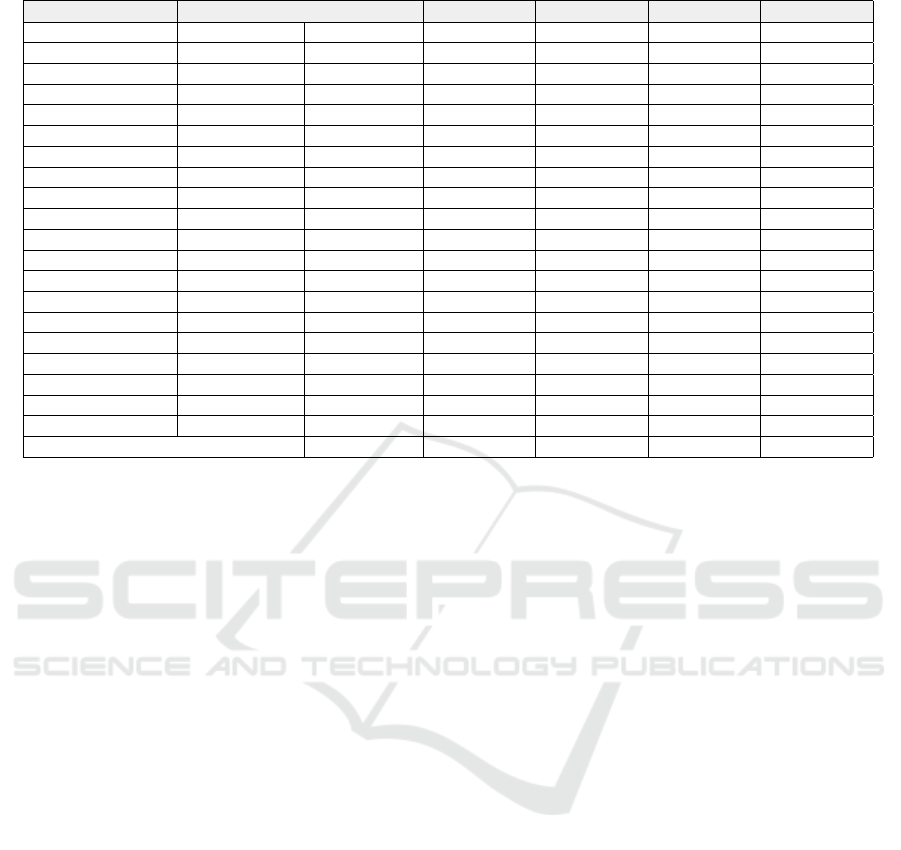
Table 2: Target words assessments.
Portuguese word English word Assessments GCS1SLP1 GCS1SLP0 GCS0SLP1 GCS0SLP0
Caminh
˜
ao Truck 631 310 10 293 18
Cachorro Dog 586 249 21 265 51
Beb
ˆ
e Baby 716 271 5 432 8
Casa House 473 148 2 292 31
Jacar
´
e Alligator 616 182 42 294 98
Cama Bed 462 135 3 309 15
Cavalo Horse 501 146 6 310 39
Coelho Rabbit 499 136 6 306 51
Jornal Newspaper 667 174 42 311 140
Cabelo Hair 797 203 10 547 37
Sof
´
a Couch 394 97 2 261 34
Bicicleta Bicycle 543 132 38 221 152
Rel
´
ogio Clock 462 110 12 246 94
Gato Cat 454 107 3 313 31
Batom Lipstick 530 122 2 394 14
Galinha Hen 622 142 14 442 24
Cobra Snake 578 130 30 277 141
Microfone Microphone 831 180 146 224 281
Folha Leaf 554 119 17 382 36
Barriga Belly 725 152 18 507 48
TOTAL 11641 3245 429 6624 1343
lem solving in the speech therapy domain. Also, we
pointed out in Section 2 that SA integration is scarce,
so we proposed a system that aims to provide per-
ception, understanding and projection in the environ-
ment to ensure dynamism and adaptation in a variety
of contexts.
We presented the architecture of the proposed sys-
tem, describing the modules that constitute it. This
paper specifically focused on evaluating the perfor-
mance of Google Cloud Speech API when executing
speech recognition, in order to verify if this tool can
be used in speech-language assessments in general.
From speech signals collected from a group of
1.362 children aged 3 to 8 years and 11 months per-
forming image naming tasks, Google Cloud Speech
API performed assessments and returned feedback to
the specialist stating whether the pronunciation was
correct or incorrect. These evaluations were com-
pared with the ones made by the SLP, reaching a Con-
cordance Rate (CR) in 39.41% of the evaluations per-
formed. Although it is a low value, this rate represents
a promising result, since no preprocessing techniques
were applied to the collected audio, and no contextual
information was integrated in the evaluation process
performed by the API. We believe that these factors
directly interfere with the performance of the tool,
which can achieve satisfactory rates with the inclu-
sion of optimization techniques.
From these considerations, our future work in-
cludes adding an effective data preprocessing phase,
in order to perform data filtering and optimization
of sound quality. We are currently investigating the
use of Cepstral Mean Normalization (CMN) and Mel-
Frequency Cepstral Coefficients (MFCCs) methods
for feature extraction operations and noisy data pro-
cessing. Also, our future work includes testing the
performance of other voice recognizers, estimating
the SLP’s classification through the Google Cloud
Speech API, as well as applying the CMUSphinx
tool for training and classification of speech disor-
ders. The classified data will be input to the CBR
cycle presented in the proposed architecture, which
should indicate the appropriate solution based on pre-
vious knowledge.
Finally, we conclude that our assessments with
Google Cloud Speech presented encouraging results.
Through preprocessing strategies, the API can possi-
bly achieve a higher Concordance Rate, so that it can
be effectively used as an initial evaluation method be-
fore the classification stage foreseen in the architec-
ture. In general, this architecture was designed to in-
tegrate capabilities of situation awareness: it should
support decision making in speech therapy contexts,
recommending the best action to be taken by the ther-
apist according to the identified situation.
ACKNOWLEDGEMENTS
The authors would like to thank CAPES for partial
funding of this research and UFSM/FATEC through
project number 041250 - 9.07.0025 (100548).
A Case-Based System Architecture based on Situation-Awareness for Speech Therapy
467

REFERENCES
Aamodt, A. and Plaza, E. (1994). Case-based reasoning:
Foundational issues, methodological variations, and
system approaches. AI communications, 7(1):39–59.
Abad, A., Pompili, A., Costa, A., Trancoso, I., Fonseca, J.,
Leal, G., Farrajota, L., and Martins, I. P. (2013). Au-
tomatic word naming recognition for an on-line apha-
sia treatment system. Computer Speech & Language,
27(6):1235–1248.
Ballinger, B., Allauzen, C., Gruenstein, A., and Schalkwyk,
J. (2010). On-demand language model interpolation
for mobile speech input. In Eleventh Annual Confer-
ence of the International Speech Communication As-
sociation.
Begum, S., Ahmed, M. U., Funk, P., Xiong, N., and Folke,
M. (2011). Case-based reasoning systems in the health
sciences: a survey of recent trends and developments.
IEEE Transactions on Systems, Man, and Cybernet-
ics, Part C (Applications and Reviews), 41(4):421–
434.
Chuchuca-M
´
endez, F., Robles-Bykbaev, V., Vanegas-
Peralta, P., Lucero-Salda
˜
na, J., L
´
opez-Nores, M., and
Pazos-Arias, J. (2016). An educative environment
based on ontologies and e-learning for training on
design of speech-language therapy plans for chil-
dren with disabilities and communication disorders.
In Ciencias de la Inform
´
atica y Desarrollos de In-
vestigaci
´
on (CACIDI), IEEE Congreso Argentino de,
pages 1–6.
Dubey, H., Goldberg, J. C., Abtahi, M., Mahler, L., and
Mankodiya, K. (2015). Echowear: smartwatch tech-
nology for voice and speech treatments of patients
with parkinson’s disease. In Proceedings of the con-
ference on Wireless Health.
Endsley, M. R. (1995). Toward a theory of situation aware-
ness in dynamic systems. Human factors, 37(1):32–
64.
Frost, M. and Gabrielli, S. (2013). Supporting situational
awareness through a patient overview screen for bipo-
lar disorder treatment. In Pervasive Computing Tech-
nologies for Healthcare (PervasiveHealth), 2013 7th
International Conference on, pages 298–301.
Gabani, K., Solorio, T., Liu, Y., Hassanali, K.-n., and Dol-
laghan, C. A. (2011). Exploring a corpus-based ap-
proach for detecting language impairment in monolin-
gual english-speaking children. Artificial Intelligence
in Medicine, 53(3):161–170.
Grossinho, A., Guimaraes, I., Magalhaes, J., and Cavaco,
S. (2016). Robust phoneme recognition for a speech
therapy environment. In Serious Games and Appli-
cations for Health (SeGAH), 2016 IEEE International
Conference on, pages 1–7.
Grzybowska, J. and Klaczynski, M. (2014). Computer-
assisted hfcc-based learning system for people with
speech sound disorders. In Pacific Voice Conference
(PVC), 2014 XXII Annual, pages 1–5.
Husain, W. and Pheng, L. T. (2010). The development of
personalized wellness therapy recommender system
using hybrid case-based reasoning. In Computer Tech-
nology and Development (ICCTD), 2010 2nd Interna-
tional Conference on, pages 85–89. IEEE.
Iliya, S. and Neri, F. (2016). Towards artificial speech ther-
apy: A neural system for impaired speech segmenta-
tion. International journal of neural systems, 26(6):1–
16.
Kokar, M. M. and Endsley, M. R. (2012). Situation aware-
ness and cognitive modeling. IEEE Intelligent Sys-
tems, 27(3):91–96.
Lee, H. J. and Kim, H. S. (2015). ehealth recommendation
service system using ontology and case-based reason-
ing. In Smart City/SocialCom/SustainCom (SmartC-
ity), 2015 IEEE International Conference on, pages
1108–1113. IEEE.
Mohamed, S. A. E., Hassanin, A. S., and Othman, M. T. B.
(2014). Educational system for the holy quran and its
sciences for blind and handicapped people based on
google speech api. Journal of Software Engineering
and Applications, 7(03):150.
Oliveira, R., Batista, P., Neto, N., and Klautau, A. (2012).
Baseline acoustic models for brazilian portuguese us-
ing cmu sphinx tools. Computational Processing of
the Portuguese Language, pages 375–380.
Oosthuizen, R. and Pretorius, L. (2015). System dynamics
modelling of situation awareness. In Military Commu-
nications and Information Systems Conference (Mil-
CIS), 2015, pages 1–6.
Parnandi, A., Karappa, V., Lan, T., Shahin, M., McKech-
nie, J., Ballard, K., Ahmed, B., and Gutierrez-Osuna,
R. (2015). Development of a remote therapy tool for
childhood apraxia of speech. ACM Transactions on
Accessible Computing (TACCESS), 7(3):10.
Riesbeck, C. K. and Schank, R. C. (1989). Inside case-
based reasoning. Erlbaum, Northvale, NJ.
Robles-Bykbaev, V. E., Guam
´
an-Murillo, W., Quisi-Peralta,
D., L
´
opez-Nores, M., Pazos-Arias, J. J., and Garc
´
ıa-
Duque, J. (2016). An ontology-based expert system
to generate therapy plans for children with disabilities
and communication disorders. In Ecuador Technical
Chapters Meeting (ETCM), IEEE, volume 1, page 6.
Salfinger, A., Retschitzegger, W., and Schwinger, W.
(2013). Maintaining situation awareness over time.
pages 1–8.
Schipor, O. A., Pentiuc, S. G., and Schipor, M. D. (2012).
Improving computer based speech therapy using a
fuzzy expert system. Computing and Informatics,
29(2):303–318.
Ward, L., Stefani, A., Smith, D., Duenser, A., Freyne,
J., Dodd, B., and Morgan, A. (2016). Automated
screening of speech development issues in children
by identifying phonological error patterns. In INTER-
SPEECH, pages 2661–2665.
Watson, I. (1999). Case-based reasoning is a method-
ology not a technology. Knowledge-based systems,
12(5):303–308.
ICEIS 2018 - 20th International Conference on Enterprise Information Systems
468
