
Ranking Quality of Answers Drawn from Independent Evident Passages
in Neural Machine Comprehension
Avi Bleiweiss
BShalem Research, Sunnyvale, U.S.A.
Keywords:
Machine Comprehension, Gated Recurrent Neural Networks, Coattention Mechanism, Passage Ranking.
Abstract:
Machine comprehension has gained increased interest with the recent release of real-world and large-scale
datasets. In this work, we developed a neural model built of multiple coattention encoders to address datasets
that draw answers to a query from orthogonal context passages. The novelty of our model is in producing
passage ranking based entirely on the answer quality obtained from coattention processing. We show that
using instead the search-engine presentation order of indexed web pages, from which evidence articles have
been extracted, may affect performance adversely. To evaluate our model, we chose the MSMARCO dataset
that allows queries to have anywhere from no answer to multiple answers assembled of words both in and out of
context. We report extensive quantitative results to show performance impact of various dataset components.
1 INTRODUCTION
Machine comprehension (MC), an extractive form
of question answering over a provided context para-
graph, is an active research area in natural language
processing (NLP). MC models that answer questions
over unstructured text are expected to have profound
impact on people who inquire about medical, legal,
or technical documents. In practice, trained MC sys-
tems can be applied to a variety of real-world problem
domains, including personal assistance, recommenda-
tions, customer support, and dialog management.
The rise of large-scale human-curated datasets
with over 100,000 realistic question-answer pairs,
such as SQuAD (Rajpurkar et al., 2016), NewsQA
(Trischler et al., 2016), MSMARCO (Nguyen et al.,
2016), and TriviaQA (Joshi et al., 2017), inspired a
large number of successful deep learning models for
MC (Lee et al., 2016; Wang and Jiang, 2016; Seo
et al., 2017; Xiong et al., 2017; Dhingra et al., 2017;
Raiman and Miller, 2017; Chen et al., 2017). In Ta-
ble 1, we show a comparison of key dataset proper-
ties that sets MSMARCO as the more realistic and
thus posing many unique challenges to an MC engine,
on several levels. Questions in MSMARCO are real
user queries tagged with categorical information, as
free-formed answers are generated by humans, each
potentially derived from several authentic web docu-
ments (see Appendix for a dataset example composi-
tion). Moreover, a subset of the queries has multiple
answers and possibly no answer. Unlike a single an-
swer of contiguous text snippet that is confined to ei-
ther one document as in SQuAD and NewsQA, or to a
single article member of a set of articles, in TriviaQA.
To date, MSMARCO remains fairly understudied
and most of the work published (Shen et al., 2016;
Wang and Jiang, 2016; Weissenborn et al., 2017;
Wang et al., 2017; Tan et al., 2017) was primarily de-
signed to run natively on SQuAD and NewsQA, and
followed by coercing MSMARCO to behave like the
former datasets. For instance, all text passages asso-
ciated with a query were concatenated to a single con-
text paragraph (Weissenborn et al., 2017; Wang et al.,
2017) and similarly, only the first of multiple answers
was evaluated (Tan et al., 2017). In this paper, we pro-
pose a neural MC design that is tightly linked to the
MSMARCO interface abstraction. We draw answers
to a query from each of the text passages separately,
and to sustain performance our passage scoring is de-
rived independently of the search-engine page rank-
ing. A ranking we assigned an instructive role rather
than binding as in the work by Tan et al. (2017).
Recently, recurrent neural networks (RNN) be-
came a widespread foundation for language model-
ing tasks (Sutskever et al., 2011; Sutskever et al.,
2014; Hoang et al., 2016; Tran et al., 2016). This
had spurred a growing interest in developing machine
learning models that use an attention-based RNN to
extend other NLP tools (Luong et al., 2015; Xu et al.,
2015) to MC, and achieve compelling results (Wang
Bleiweiss, A.
Ranking Quality of Answers Drawn from Independent Evident Passages in Neural Machine Comprehension.
DOI: 10.5220/0006923300610071
In Proceedings of the 10th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2018) - Volume 1: KDIR, pages 61-71
ISBN: 978-989-758-330-8
Copyright © 2018 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
61
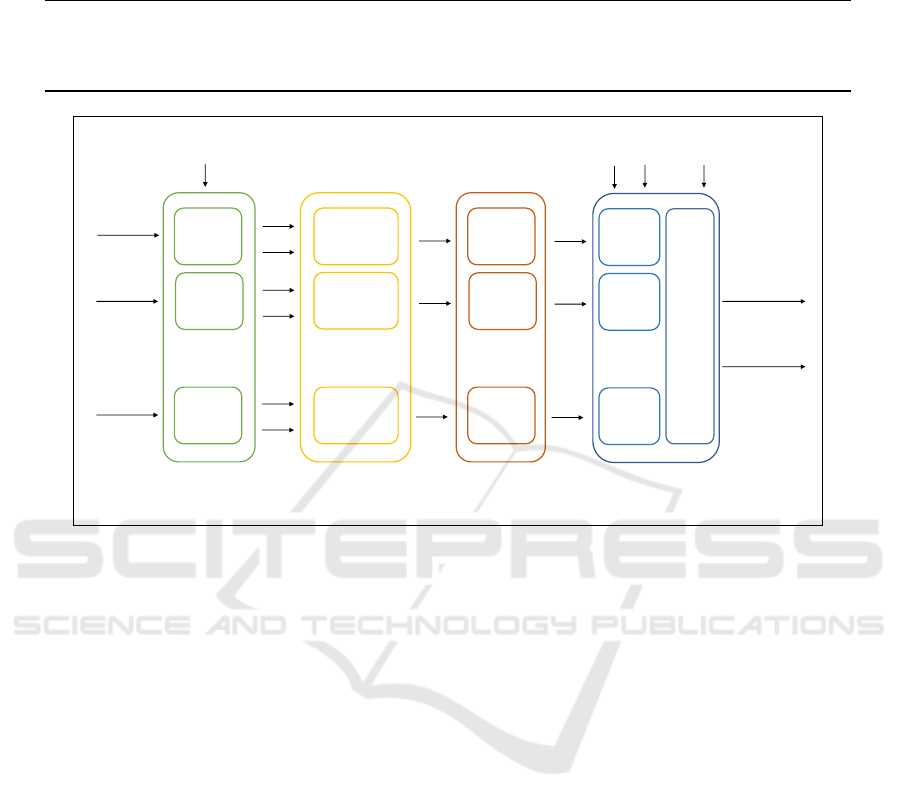
Table 1: Comparing key properties of existed large-scale datasets with over 100,000 realistic question-answer pairs. MS-
MARCO is the only dataset to draw answers by crossing evidence page boundaries.
Dataset Segment Query Source Answer Queries Documents
SQuAD N Crowdsourced Span of Words 107,785 536
NewsQA N Crowdsourced Span of Words 119,633 12,744
MSMARCO Y User Logs Human Generated 102,023 837,729
TriviaQA Y Crowdsourced Span of Words 110,495 662,659
Query
Passage 1
Passage 2
⋮
Passage 𝑛
GRU 1
GRU 2
GRU 𝑛
⋮
CoAtt 1
CoAtt 2
CoAtt 𝑛
⋮
𝑄
𝑃
𝑄
𝑃
𝑄
𝑃
𝑈
𝑈
𝑈
⋮ ⋮
LP 1
LP 2
LP 𝑛
⋮
Evaluation
Coattention
Contextual
𝑆
𝑆
𝑆
⋮
Eval 1
Eval 2
Eval 𝑛
⋮
Prediction
Gold Answers
Passage Rank
Metric Scores
⋯
1
2
𝑚
Multi-
Span
Figure 1: Architecture overview of our deep learning model. Word embeddings of a query, n context passages, and m answers
form a machine comprehension primitive to enter our computational pipeline. Pairs of the query and each of the passages are
first fed into independent gated recurrent neural networks (GRU). Contextualized query Q and passage P from each GRU are
then passed onto coattention encoders, each emitting the coattention context U. Simple linear decoders take U and predict
the endpoints of an answer span S in a context passage. Lastly, the evaluation layer combines multiple spans to address
non-contiguous answers, and produces both passage ranking and answer quality scoring in ROUGE and BLEU metrics.
and Jiang, 2016) (Cui et al., 2016) (Xiong et al., 2017)
(Seo et al., 2017). Perceived almost unanimously by
the research community, the latest pace of advancing
MC in the text domain is largely attributed to the at-
tention mechanism that requires cross-encoding and
exchanging information between a context paragraph
and a given query. In creating our neural MC model,
we expanded upon the Bidirectional Attention Flow
(BiDAF) network (Seo et al., 2017) that is one of
the best performing models on the SQuAD dataset
with an Exact Match (EM) and F1 scores of 73.3 and
81.1, respectively. BiDAF computes complementary
context-to-query and query-to-context attention, and
predicts the endpoints of an answer span. Given the
generative nature of the MSMARCO dataset, we pro-
duce instead a sequence of words for a predicted an-
swer length, and use ROUGE (Lin, 2004) and BLEU
(Papineni et al., 2002) as our evaluation metrics.
The main contribution of this paper is an effective
architecture proposed for MC datasets that draw an-
swers from each of multiple context passages. We hy-
pothesize that using the PageRank algorithm to quan-
tify answer quality is inferior to our implicit passage
ranking that we derive directly from the coattention
pipelines, and provide compelling proof in our exper-
imental results. A number of our major design deci-
sions were based on inspecting the MSMARCO data,
as we trained our model on its train set, and analyzed
performance on the development set. The rest of this
paper is structured as follows. In section 2, we define
MC primitives and overview computational flow of
our model. Section 3 renders pre-processed statistical
data of the MSMARCO dataset, and in Section 4 we
present our methodology for evaluating performance,
and report extensive quantitative results over a range
of ablation studies. Summary and identified avenues
for prospective work are provided in Section 5.
2 METHOD
In Figure 1, we provide an overview of our proposed
multiple-pipeline MC model that progresses through
KDIR 2018 - 10th International Conference on Knowledge Discovery and Information Retrieval
62

Product
Softmax
Softmax
Product
Concat
Product
Concat
m
m
GRU
Affinity
Matrix
Affinity
Weights
Attention
Summaries
Attention
Context
Figure 2: Architecture diagram of the coattention encoder that simultaneously induces attention contexts for both the query Q
and passage P, and fuses them together to output the U matrix. The encoder execution order is shown on the right.
a series of contextual, attention, prediction, and eval-
uation layers we describe next.
2.1 Word Embeddings
We define a machine comprehension primitive in text
word space as the triplet λ
w
= (q
w
,P
w
,A
w
), where q
w
the query, P
w
= {p
(1)
w
,..., p
(n)
w
} a set of n context pas-
sages, and A
w
= {a
(1)
w
,...,a
(m)
w
} a collection of m ref-
erence, or gold answers. Drawn from a pre-fixed vo-
cabulary V , each of q
w
, p
(i)
w
, and a
( j)
w
is a sequence of
tokens that are first mapped to a sparse one-hot vec-
tor representation ∈ R
|V |×1
, and are then transformed
to dense d-dimensional vectors using an embedding
matrix E ∈ R
d×|V |
(Mikolov et al., 2013a; Mikolov
et al., 2013b; Pennington et al., 2014). We use the
colon notation v
1:k
to denote the sequence (v
1
,...,v
k
)
of k vectors, and a text of length T words is therefore
represented as a sequence of d-dimensional word vec-
tors x
1:T
∈ R
d
. In the embedding space, components
of the triplet λ
x
= (q
x
,P
x
,A
x
) unfold to the sequences
q
x
= x
1:|q|
, p
(i)
x
= x
1:|p
(i)
|
, and a
( j)
x
= x
1:|a
( j)
|
that ren-
der a query, context passage, and answer, respectively,
where cardinalities |q|, |p
(i)
|, and |a
( j)
| are denoted
invariably to any of w or x projection spaces. At any
time, our system responds to querying both the for-
ward and backward transforms λ
w
λ
x
.
2.2 Contextual RNN
Our first pipeline stage contextualizes word vector
representations of the query q
x
paired with each of the
context passages p
(i)
x
, by feeding them to a set of n in-
dependent recurrent neural networks. We chose to use
the Gated Recurrent Unit (GRU) (Cho et al., 2014;
Chung et al., 2014) variant of RNN that captures
long term dependencies of the input as it encodes
each word x
t
into a sequence h
t
= RNN(h
t−1
,x
t
).
GRU performs similarly but is computationally more
efficient than LSTM (Hochreiter and Schmidhuber,
1997). We denote B = GRU(A,h
0
) to indicate that
the matrix B is comprised of the output states of a
unidirectional GRU-based RNN, where each column
of A is an input word vector and h
0
is the starting hid-
den state. Word vectors of each of the query-passage
pairs are fed through the same GRU block and com-
putationally follow the set of formulas
Q
0
= GRU(q
x
,0) ∈ R
h×|q|
P = GRU(p
x
,Q
0
[: |q|]) ∈ R
h×|p|
Q = tanh(W
(Q)
Q
0
) ∈ R
h×|q|
,
where Q
0
is an intermediate query representation of
the GRU output layer, and W
(Q)
is a weight matrix to
learn. In the remainder of this discussion, we follow
a concise matrix notation, as we review computation
Ranking Quality of Answers Drawn from Independent Evident Passages in Neural Machine Comprehension
63

of a single pipeline of the architecture, and drop pas-
sage enumeration (i) altogether for clarity. Q
0
follows
a non-linear projection step to produce Q and ensures
the query and passage reside in state spaces of no lin-
ear relation. To simulate the comprehension test prac-
tice of ‘read the query before the passage’, we route
the final hidden state of query encoding to the initial
hidden state for encoding the context passage.
2.3 Coattention Encoder
In this section, we provide a brief overview of the
attention mechanism (Xiong et al., 2017; Seo et al.,
2017; Andress and Zanoci, 2017). From the contex-
tual stage, a pair of Q and P matrices enter each a
coattention pipeline (Figure 2) to produce final pas-
sage encoding. First, we compute all-word-pairs sim-
ilarities between a context passage and a query to pro-
duce the affinity matrix L
L = P
T
W
(L)
Q ∈ R
|p|×|q|
,
where W
(L)
∈ R
h×h
is a trainable weight matrix. An
affinity element l
i j
holds the similarity between word i
in the context passage and word j in the query. Next,
L is normalized over rows and columns to produce
attention weights in the shape of matrices A
Q
and A
P
,
respectively
A
Q
= softmax(L) ∈ R
|p|×|q|
A
P
= softmax(L
T
) ∈ R
|q|×|p|
,
where softmax(·) is a row-wise operator. Using the
attention weights, we compute attention summaries
for the query
C
Q
= PA
Q
∈ R
h×|q|
,
where for each word k in the query, we compute a
weighted average over the entire word vectors of the
passage, using the weights in the k-th row of A
Q
. To
calculate the summaries of each word in the context
passage, we first concatenate the original state encod-
ing of the query Q with the query attention summaries
C
Q
and compute the attention summaries for the con-
text
C
P
= [Q;C
Q
]A
P
∈ R
2h×|p|
,
where [·; ·] is a row-bound matrix concatenation.
Likewise we fuse the native passage encoding P and
the summarized passage attention C
P
in the concate-
nated matrix [P;C
P
] ∈ R
3h×|p|
that is identified as the
final knowledge representation of the coattention en-
coder.
The last operational step of the encoder tempo-
rally merges different parts of the coattention context
using a dedicated GRU
U = GRU([P;C
P
],0) ∈ R
3h×|p|
,
where matrix U is the output of the coattention en-
coder that is passed to the following prediction layer
of the MC pipeline.
2.4 Decoder
In the MSMARCO dataset, answer complexity ranges
widely from simply binary or an entity name, through
a contiguous phrase confined to a single context pas-
sage, to possibly non-contiguous text that might cross
passage boundaries. Nonetheless our initial data anal-
ysis revealed that 82.6 percent of the dataset answers
are composed of a contiguous sequence of tokens con-
tained in its entirety in one passage. Our design pre-
dicts not only one (Rajpurkar et al., 2016) but n an-
swer spans, each delimited by a begin and end word
positions in a passage, and provides span concatena-
tion to address non-contiguity. We use a linear projec-
tion to convert coattention word vectors to scores and
apply softmax to obtain the probability distribution of
a span begin index s
b
over the entire passage context
p(s
b
) = softmax(W
(s)
U) ∈ R
|p|
,
where W
(s)
is a weight vector ∈ R
1×3h
. Using another
GRU node, we project U onto a different hyperspace
U
0
before obtaining posterior probabilities of the span
end point s
e
U
0
= GRU(U, 0) ∈ R
3h×|p|
p(s
e
) = softmax(W
(e)
U
0
) ∈ R
|p|
,
where W
(e)
has the same dimensionality as W
(s)
. Our
prediction for the answer span S follows
S = argmax
1≤s
b
≤s
e
≤|p|
p(s
b
)p(s
e
),
that we overload as S = {s
b
,s
e
}. Each of the individ-
ual passage decoders emits S that is conveyed to the
next layer for comprehension evaluation.
2.5 Deferred Passage Ranking
In both the MSMARCO and TriviaQA datasets, con-
textual passages to draw answers from are extracted
from open web pages. Passages provided to either hu-
man judges or MC systems have the attractive prop-
erty of ranked order presentation from the perspective
of the search engine. Perceived more as a suggestion
rather than an imperative requisite to follow, human
crowdsourced answers may not abide by a page rank-
ing protocol to best match an answer to a query.
In their model, Tan et al. (2017) feed the web-
page origin order directly to a passage ranking task
that they chose to integrate into the coattention en-
coder. This had led to an improvement of answer span
KDIR 2018 - 10th International Conference on Knowledge Discovery and Information Retrieval
64

Table 2: MC component statistics of train and development sets, including per-query average of passages and answers.
Queries Passages Answers Mean Passages Mean Answers
train 82,326 676,193 90,306 8.21 1.09
dev 10,047 82,360 10,973 8.19 1.09
Table 3: Distribution of per-query passage count [1,12] extracted from the train and development sets.
1 2 3 4 5 6 7 8 9 10 11 12
train 3 43 316 1,249 3,224 5,854 10,239 19,682 27,378 14,335 1 2
dev 0 5 39 145 399 713 1,291 2,444 3,319 1,692 0 0
Algorithm 1: Deferred Passage Ranking.
1: input: MC primitive λ
w
, predicted answers A
p
2: output: ranked passage scores R ←
/
0
3: A
r
← answers(λ
w
)
4: for i = 1 to num passages(λ
w
) do
5: s ← 0
6: for j = 1 to num answers(λ
w
) do
7: if null(A
r
[ j]) then
8: s ← s + 0
9: else
10: s ← s+ROUGE or BLEU(A
p
[i],A
r
[ j])
11: end if
12: end for
13: R ← R ∪ (s/num answers(λ
w
)
14: end for
15: return sort(R)
prediction by about 2.5 percentage points, and also
allows for more efficient training. However, by using
attention pooling their method predicts from an inher-
ently biased context. Instead, we propose an MC sys-
tem that throughout the entire machine comprehen-
sion task remains impartial to subdivided context that
enters our pipelines. We evaluate all the query-bound
passages and rate context spans either independently
or concatenated, by scoring answers individually first
and then as a collection. This process is further illus-
trated in Algorithm 1. Moreover, implicitly producing
a rank of passage scoring at the last step of the evalua-
tion stage (Figure 1), merits the analysis of compara-
tive performance between our unbiased passage order
and MSMARCO web-page ranking, to facilitate the
testing of our hypothesis.
3 MSMARCO DATASET
Version 1.1 of the MSMARCO dataset consists of
102,023 queries with their corresponding answers, of
which 82,326 are used for training, 10,047 for devel-
opment, and 9,650 for test. Intended primarily for of-
Table 4: Distribution of per-query answer count [0,4] drawn
from the train and development sets.
0 1 2 3 4
train 2,183 70,616 8,912 594 21
dev 293 8,608 1,076 67 3
Table 5: Distribution of passage-bound contiguous and
passage-straddled non-contiguous answer spans drawn
from the train and development sets.
Contiguous Spans Non-Contiguous Spans
train 635,047 110,596
dev 77,042 13,405
ficial leaderboard submissions, the test set is released
to the public either without or with incorrect answers.
In this work, we chose to report main evaluation re-
sults on the development set.
In Table 2, we list aggregates of MC components
for the train and development collections, and high-
light per-query average of context passages and an-
swers at about 8.2 and 1.1, respectively. Table 3 fur-
ther expands on passage distribution and shows over
87 percent of the queries have between seven to ten
context passages to draw the answers from. Similarly,
Table 4 shows answer distribution with at most four
answers per-query, as the majority of nearly 86 per-
cent of queries have a single answer. A small subset
of queries, at about 2.6 percentage points, have no an-
swers at all.
Answers presented in the MSMARCO dataset
may not be syntactically fluent and potentially require
reasoning across multiple context passages. Still, our
initial data analysis, as evidenced by Table 5, shows
that more than 83 percent of answers comprise con-
tiguous spans of text confined to a single passage,
where the remaining 17 percent are formed of non-
contiguous text fragments bound to either one or mul-
tiple passages. This data firmly supports our proposed
MC model that reasons over both a single and multi-
ple answer spans. Table 6 follows to show distribution
of context-unaware answers that include about 7.5
percent of binary answers to Yes/No question types,
Ranking Quality of Answers Drawn from Independent Evident Passages in Neural Machine Comprehension
65

(a) Query Types (b) Queries (c) Passages (d) Answers
Figure 3: Train set histograms of (a) query types, and word length of (b) queries, (c) passages, and (d) answers.
(a) Query Types (b) Queries (c) Passages (d) Answers
Figure 4: Development set histograms of (a) query types, and word length of (b) queries, (c) passages, and (d) answers.
Table 6: Distribution of binary answers to Yes/No type
questions and special-case misconstrued answers drawn
from the train and development sets.
Binary Misconstrued
train 6,728 136
dev 755 18
and inconsequential cases of misconstrued answers.
The latter are formed of non-standard English tokens
that often transpire in online forum discussions. For
instance, words like ‘yez’, ‘maxico’, and ‘crockery’.
The distributions of query segment types and word
length for each the queries, context passages, and an-
swers in the train and development sets are shown in
Figure 3 and Figure 4, respectively. Histograms are
consistent on both sets, barring the passage maximal
length of 321 vs. 192 words. Over half of the queries
belong to the description category, the numeric class
is second with 28.3 percent, as entity, location, and
person trail behind. Notably a little over fifty percent
of MC examples have short answers of ten words or
less, with an average answer length of fourteen words.
4 EMPIRICAL EVALUATION
In this section, we provide an extensive quantitative
analysis of our neural MC architecture. To benchmark
answer quality for generated text, we expand our pre-
dicted spans and abide by MSMARCO scoring of the
longest common subsequence ROUGE-L (Lin, 2004)
and the unigram BLEU-1 (Papineni et al., 2002) for
performance metrics. We denote these measurements
as ROUGE and BLEU for brevity.
4.1 Experimental Setup
To evaluate our system in practice, we have imple-
mented our neural MC model (Figure 1) natively
in R (R Core Team, 2013). Our linguistic process
commences by tokenizing and lowercasing queries,
context passages and answers into vocabularies of
371,807 and 110,310 words for the train and devel-
opment sets, respectively. We chose to train our own
word vectors using Word2Vec (Mikolov et al., 2013a)
with dimensionality d = 100. The GRU hidden state
dimension h was set to 100, as all weight matrices and
vectors were bootstrapped using Xavier initialization
(Glorot and Bengio, 2010). Components of MC prim-
itives in word space, λ
w
, that enter our pipeline are
each of a variable length, as our system avoids any of
truncation or padding to uniformly shape each of the
query and context passages, a practice often used to
reduce training time (Andress and Zanoci, 2017).
We trained our model on MSMARCO train set
with the Adam stochastic gradient optimizer (Kingma
and Ba, 2014) for ten epochs, using its provided de-
fault settings. Five percent of the train split was allo-
cated for validation and used for hyperparameter tun-
ing, with final choices based on both loss and perfor-
mance behavior. To mitigate overfitting the train data
in our model, we used both dropout (Srivastava et al.,
2014) at a rate of 0.2 to regularize our network, and
early termination of the training process by monitor-
ing the loss after each epoch. We use the basic cross-
KDIR 2018 - 10th International Conference on Knowledge Discovery and Information Retrieval
66
0.2090
0.2095
0.2100
1 2 3 4 5 6 7 8 9 10
Epoch
ROUGE Score
(a) ROUGE
0.1352
0.1356
0.1360
0.1364
1 2 3 4 5 6 7 8 9 10
Epoch
BLEU Score
(b) BLEU
Figure 5: Development performance as a function of the stochastic optimization epoch for (a) ROUGE and (b) BLEU score
metrics. Our best model is produced around the seventh epoch.
description
entity
location
numeric
person
0.0 0.1 0.2
Metric Score
Query Type
rouge
bleu
(a) Query Type
how
what
when
where
which
who
why
0.0 0.1 0.2 0.3
Metric Score
Question Type
rouge
bleu
(b) Question Type
Figure 6: Breakdown of development model performance based on different types of (a) queries and (b) questions. Shown for
each the ROUGE and BLEU score metrics.
entropy loss with the objective function to minimize
L = −
1
N
∑
i
a
(i)
b
log p
(i)
(s
b
) + a
(i)
e
log p
(i)
(s
e
),
where N is the number of aggregate context pas-
sages in the train set (Table 2), and the pair denoted
{a
(i)
b
,a
(i)
e
} are the ground-truth endpoint labels for a
gold answer converted to a span that has the longest
common subsequence (LCS) in the i-th context pas-
sage. Our best model is produced right about crossing
seven epochs for both the ROUGE and BLEU perfor-
mance metrics, as shown in Figure 5.
In a single span mode, we evaluate each query-
bound context passage individually for any of none,
single, or multiple answer scenarios, as is outlined in
Algorithm 1. All of the queries that have no reference
answer, and for that matter gold answers that are not
well formed, are assigned uniformly a score of zero.
Otherwise, each answer is rated independently first,
and the mean of all the answer scores makes up the fi-
nal rating of the currently evaluated text passage. The
answer quality we report for the query culminates in
the score of its highest ranked passage. Our produced
passage ranking is contrasted against the dataset order
and moreover, it feeds into the following multi-span
stage and aids to prioritize span selection. Algorithm
1 is slightly modified in rendering multi-span mode,
as the outer loop iterates over concatenated spans.
4.2 Experimental Results
We report our results on MSMARCO development
set in ROUGE and BLEU performance metrics, and
unless noted otherwise, we uniformly use normalized
score figures in the [0,1] range.
The first set of ablation experiments we conducted
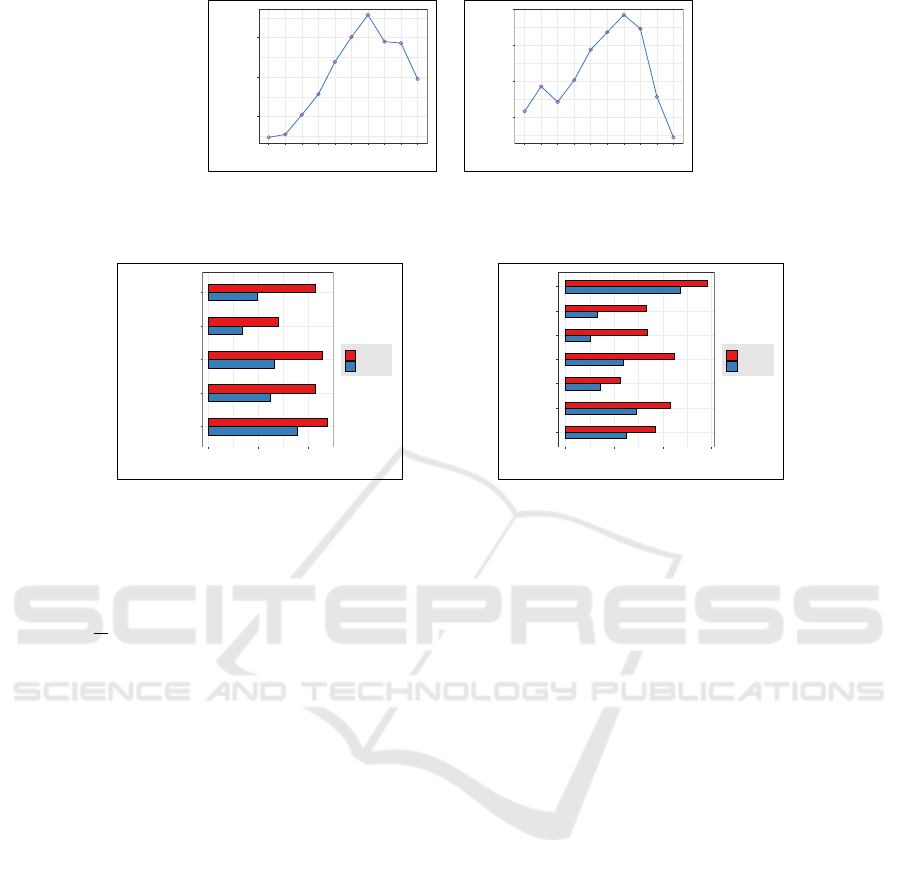
let us better understand how various components in
our training methodology impact our overall system
performance. In Figure 6(a), we show our model be-
havior over query intent segments that the dataset cre-
ators solicited through classification based on crowd-
source labeled data. As expected, we performed best
on the description segment that identifies over fifty
percent of the dataset queries (Figure 4). The location
category came closely second and followed by a simi-
lar performance for the entity and person type classes.
However, despite a relative large share of examples,
about a third, the numeric grouping is our least per-
forming, due primarily to the difficulty to contextu-
alize a single number. From an alternate perspective,
performance as a function of the query question type
is illustrated in Figure 6(b). We note that only 68.8
percent of the entire MSMARCO query set explic-
itly contain ‘what’, ‘how’, ‘where’ question type key-
words (Nguyen et al., 2016), even though the remain-
ing queries might have an identical expressive goal.
Surprisingly, we achieved our top performance, 0.28
ROUGE, on ‘why’ headed questions that are gener-
Ranking Quality of Answers Drawn from Independent Evident Passages in Neural Machine Comprehension
67
1
2
3
4
5
6
7
8
9
10
0% 2% 4% 6% 8%
Passage Rank
rouge
bleu
Figure 7: Distribution of development set examples based on top-scoring passage ranking. Shown for each the ROUGE and
BLEU score metrics.
0.0
0.1
0.2
0.3
0.4
0.5
50 75 100
Passage Length
Metric Score
rouge
bleu
(a) Passage Length
0.0
0.2
0.4
0.6
0 25 50 75 100
Answer Length
Metric Score
rouge
bleu
(b) Answer Length
Figure 8: Development model performance as a function of (a) passage length and (b) answer length. Shown for each the
ROUGE and BLEU score metrics.
ally perceived more challenging in question answer-
ing systems (Yu et al., 2016), although they represent
a fairly small sample of 1.8 percentage points of the
dataset queries. On the more simpler ‘what’ questions
that are most prominent with 42.2 percent of queries,
we are inline with average system performance.
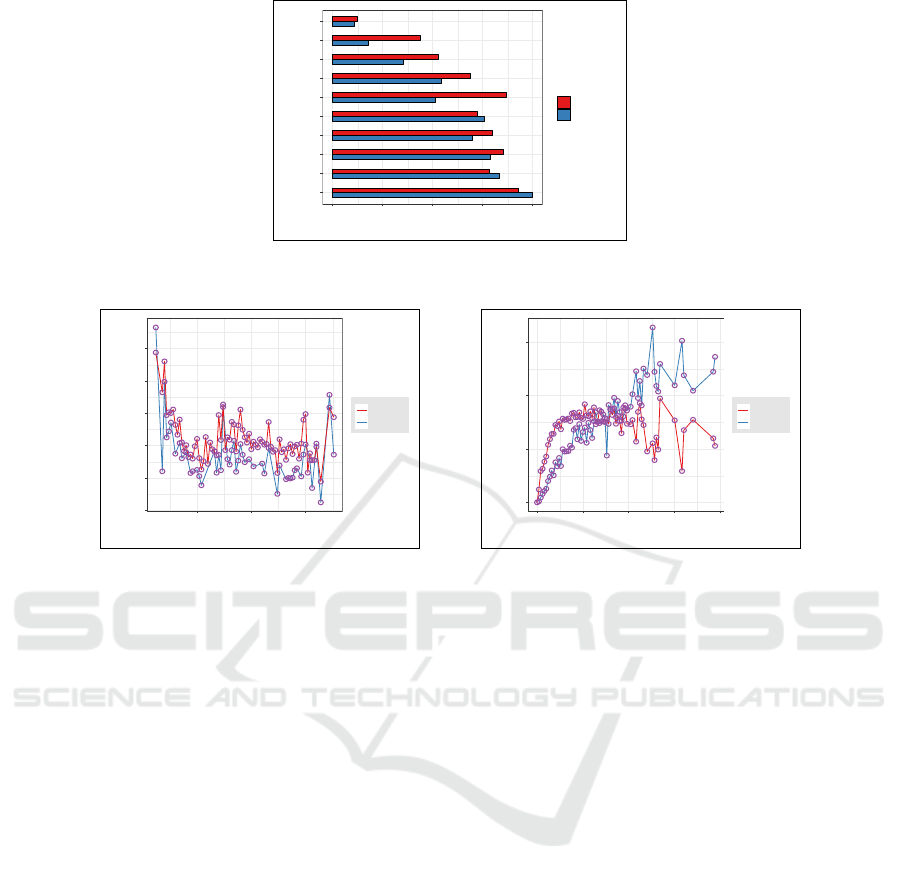
Next, we tested our hypothesis and contrasted per-
formance impact of ranked web pages for search rel-
evancy with ranked passages for answer prediction.
The former was obtained by the Bing search engine
and the latter is based entirely on our quality metrics
that were produced by multiple coattention engines.
We note that for each query, the passage enumeration
outlined in the dataset matches the ranked order of
the originating web pages. In Figure 7, we present the
distribution of our top passage ranking in percentage
points of examples, across the range of ten passage
enumerations (Table 3). The first enumerated passage
also ranks as our top scorer for the highest share of
examples, however it only claims a little over eight
percent of the queries. Stated differently, the quality
of answers drawn from the first passage is likely to
decline for about 92% of the examples. Similarly, the
succeeding top-ranked page enumerations appear to
drop moderately in their example proportion, and thus
we expect for them a slightly larger performance fall
off. This markedly supports our hypothesis that MC
performance might be impacted unfavorably for ex-
plicit out-of-domain context order. We note that dis-
tribution percentages do not add up to one hundred,
since passages with a zero score assume no ranking.
Figure 8 shows our model performance as a func-
tion of (a) context passage length and (b) answer
length. Apart from spiky performance behavior ap-
parent for passages shorter than 25 words, ROUGE
and BLEU scores follow a trend of relative constant
performance for passages of up to 100 words, and
jagged again for larger context. This observation con-
curs with the histogram of Figure 4(c) that highlights
only a few samples of passage length under 25 words
or larger than 100 words. Our consistent performance
over increased passage lengths suggests an apprecia-
ble signal-to-noise ratio for determining an answer
span. On the other hand, our model performs poorly
on extremely short-text answers of up to a handful of
words, mostly attributed to a compromised context,
and then the rate climbs precipitously till about 25-
word length, after which it levels off for ROUGE and
increases moderately for BLEU. Table 7 supplements
the graphic plots of Figure 8 with a statistical sum-
mary and shows the average ROUGE results over ei-
ther passage length or answer length are more con-
KDIR 2018 - 10th International Conference on Knowledge Discovery and Information Retrieval
68

Table 7: Summary statistics of development model performance as a function of passage length and answer length. Shown
for each the ROUGE and BLEU scoring metrics.
Passage Length Answer Length
Min Max Mean Min Max Mean
ROUGE 0.09 0.49 0.24 0.05 0.39 0.28
BLEU 0.02 0.56 0.17 0.01 0.66 0.29
sistent than the BLEU measures. However, the maxi-
mal score favors the BLEU metric over both passage
and answer length parameters, with an uncharacteris-
tic performance disparity of 0.27 over answer length.
MC systems that commonly use a single predicted
span of words for quality rating, often fall short in ren-
dering non-contiguous answers. Notably for the MS-
MARCO dataset, non-contiguous answers take up a
sizable proportion of about seventeen percent of the
examples (Table 5). To address this shortcoming, our
model retains predicted spans, S
(i)
, from all the query-
bound passages, and that facilitates a multi-span an-
swer mode in our evaluation layer (Figure 1). A user
settable hyperparameter controls the number of spans
to expand each to words and further concatenate all
words from multiple spans to a single text sequence.
The sequence is then paired with the reference an-
swers, provided by the dataset, to commence our LCS
evaluation. In Table 8, we compare the performance
of our GRU-based model to both a previously pub-
lished LSTM-based architecture and a recent native
BiDAF implementation by the MSMARCO develop-
ment team, all evaluated on the development set. Our
performance for non-contiguous answers improves
system quality by about nine percentage points as the
number of predicted spans increases from one to two,
and then tapers off with a diminishing performance
return for three and four spans. We expected this be-
havior as top ranked passages in single span mode are
selected first for the multi-span method, and hence the
lesser contribution from lower ranked passages.
At the time of this paper submission, our top
scores on the dataset development set, ROUGE of
23.54 and BLEU of 15.25, would rank seventh on
MSMARCO V1.1 leaderboard
1
for test-set evalu-
ated models that are identified with published liter-
ature links. Our model performs slightly over a native
BiDAF baseline with an average ROUGE of 22.56.
5 CONCLUSIONS
In this work, we introduced an effective MC neural-
model to regulate quality ranking of answers drawn
from multiple context passages. Primarily motivated
1
http://www.msmarco.org/leaders.aspx
Table 8: ROUGE and BLEU percentage scores for human
judges and neural models evaluated on MSMARCO devel-
opment set. Our performance is shown for a varying num-
ber of predicted spans to address non-contiguous answers.
Model Spans ROUGE BLEU
Human interpreted NA 47.00 46.00
GRU-based (our work)
1 21.02 13.63
2 22.91 14.84
3 23.33 15.12
4 23.54 15.25
Native BiDAF baseline 1 22.56 10.96
(MSMARCO team, 2018)
LSTM-based 1 12.08 9.30
(Higgins and Nho, 2017)
by the more realistic MSMARCO dataset, our model
combines multiple coattention spans to seamlessly
address answers that straddle passage bounds. A task
proven both challenging and almost impractical to su-
pervise in state-of-the-art MC systems that only sup-
port a single span. One of the key insights into our
study is the considerable performance gains achieved
when using our coattention-based passage ranking,
compared to applying directly the query relevance or-
der of the originated web-document pages, as pre-
sented in the dataset. Our model performance appears
to lag behind the rating of average human compre-
hension on MSMARCO, but despite its simplicity is
ahead of a leaderboard top-performing model that was
trained on the SQuAD dataset.
Aiming in this work for a decent but not top per-
formance, one topic for further study would be to ex-
plore bidirectional GRU networks in the contextual
layer to improve our system performance. A more di-
rect progression of our work is to evolve into a task
that handles efficiently answers of extremely short-
text sequences, which are potentially unsearchable in
the corresponding context. One of unanswered ques-
tions in our work that we plan to investigate is a gen-
eralized approach that satisfies non-contiguous an-
swers confined to a single passage. We look forward
to adapt our model to the recently introduced Trivi-
aQA dataset that incorporates multiple evidence doc-
uments per-query as well, however each comprises
a much increased search space of several thousand
words. The above intuitions are generally purposed
Ranking Quality of Answers Drawn from Independent Evident Passages in Neural Machine Comprehension
69

to benefit an improved understanding of how to miti-
gate computational complexity in an MC engine. Fi-
nally, we plan to experiment with MSMARCO V2.1
that was just released and comprises over one million
user queries. This version allows to explore additional
evaluation metrics to overcome semantic-equivalence
limitations of ROUGE and BLEU.
ACKNOWLEDGMENTS
We would like to thank the anonymous reviewers for
their insightful suggestions and feedback.
REFERENCES
Andress, J. and Zanoci, C. (2017). Coattention-
based neural network for question answer-
ing. Technical report, Stanford University.
http://stanford.edu/class/cs224n/reports/2762015.pdf.
Chen, Z., Yang, R., Cao, B., Zhao, Z., Cai, D., and He,
X. (2017). Smarnet: Teaching machines to read
and comprehend like human. CoRR, abs/1710.02772.
http://arxiv.org/abs/1710.02772.
Cho, K., van Merrienboer, B., Bahdanau, D., and Ben-
gio, Y. (2014). On the properties of neural machine
translation: Encoder-decoder approaches. CoRR,
abs/1409.1259. http://arxiv.org/abs/1409.1259.
Chung, J., G
¨
ulc¸ehre, c., Cho, K., and Bengio, Y. (2014).
Empirical evaluation of gated recurrent neural net-
works on sequence modeling. CoRR, abs/1412.3555.
http://arxiv.org/abs/1412.3555.
Cui, Y., Chen, Z., Wei, S., Wang, S., Liu, T., and Hu,
G. (2016). Attention-over-attention neural networks
for reading comprehension. CoRR, abs/1607.04423.
http://arxiv.org/abs/1607.04423.
Dhingra, B., Liu, H., Cohen, W. W., and Salakhut-
dinov, R. (2017). Gated-attention readers for
text comprehension. CoRR, abs/1606.01549.
http://arxiv.org/abs/1606.01549.
Glorot, X. and Bengio, Y. (2010). Understanding the diffi-
culty of training deep feedforward neural networks. In
Artificial Intelligence and Statistics, pages 249–256,
Sardinia, Italy.
Higgins, B. and Nho, E. (2017). LSTM
encoder-decoder architecture with atten-
tion mechanism for machine comprehen-
sion. Technical report, Stanford University.
http://stanford.edu/class/cs224n/reports/2784756.pdf.
Hoang, C. D. V., Cohn, T., and Haffari, G. (2016). In-
corporating side information into recurrent neural net-
work language models. In Human Language Tech-
nologies: North American Chapter of the Association
for Computational Linguistics (NAACL), pages 1250–
1255, San Diego, California.
Hochreiter, S. and Schmidhuber, J. (1997). Long short-term
memory. Neural Computation, 9(8):1735–1780.
Joshi, M., Choi, E., Weld, D., and Zettlemoyer, L.
(2017). TriviaQA: A large scale distantly super-
vised challenge dataset for reading comprehension.
In Annual Meeting of the Association for Computa-
tional Linguistics (ACL), pages 1601–1611, Vancou-
ver, Canada.
Kingma, D. P. and Ba, J. (2014). Adam: A method
for stochastic optimization. CoRR, abs/1412.6980.
http://arxiv.org/abs/1412.6980.
Lee, K., Kwiatkowski, T., Parikh, A. P., and Das, D. (2016).
Learning recurrent span representations for extrac-
tive question answering. CoRR, abs/1611.01436.
http://arxiv.org/abs/1611.01436.
Lin, C. (2004). ROUGE: a package for automatic evaluation
of summaries. In Workshop on Text Summarization
Branches Out of the Association for Computational
Linguistics (ACL).
Luong, M., Pham, H., and Manning, C. D. (2015).
Effective approaches to attention-based neural
machine translation. CoRR, abs/1508.04025.
http://arxiv.org/abs/1508.04025.
Mikolov, T., Chen, K., Corrado, G. S., and Dean, J.
(2013a). Efficient estimation of word represen-
tations in vector space. CoRR, abs/1301.3781.
http://arxiv.org/abs/1301.3781.
Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., and
Dean, J. (2013b). Distributed representations of words
and phrases and their compositionality. In Advances in
Neural Information Processing Systems (NIPS), pages
3111–3119. Curran Associates, Inc., Red Hook, NY.
Nguyen, T., Rosenberg, M., Song, X., Gao, J., Ti-
wary, S., Majumder, R., and Deng, L. (2016). MS
MARCO: A human generated MAchine Reading
COmprehension dataset. CoRR, abs/1611.09268.
http://arxiv.org/abs/1611.09268.
Papineni, K., Roukos, S., Ward, T., and jing Zhu, W. (2002).
BLEU: a method for automatic evaluation of machine
translation. In Annual Meeting of the Association for
Computational Linguistics (ACL).
Pennington, J., Socher, R., and Manning, C. D. (2014).
GloVe: Global vectors for word representation. In
Empirical Methods in Natural Language Processing
(EMNLP), pages 1532–1543, Doha, Qatar.
R Core Team (2013). R: A Language and Environment
for Statistical Computing. R Foundation for Sta-
tistical Computing, Vienna, Austria. http://www.R-
project.org/.
Raiman, J. and Miller, J. (2017). Globally normal-
ized reader. In Empirical Methods in Natural
Language Processing (EMNLP), pages 1059–1069,
Copenhagen, Denmark.
Rajpurkar, P., Zhang, J., Lopyrev, K., and Liang, P. (2016).
SQuAD: 100,000+ questions for machine compre-
hension of text. In Empirical Methods in Natural
Language Processing (EMNLP), pages 2383–2392,
Austin, Texas.
Seo, M. J., Kembhavi, A., Farhadi, A., and Ha-
jishirzi, H. (2017). Bidirectional attention flow for
machine comprehension. CoRR, abs/1611.01603.
http://arxiv.org/abs/1611.01603.
KDIR 2018 - 10th International Conference on Knowledge Discovery and Information Retrieval
70

Shen, Y., Huang, P., Gao, J., and Chen, W. (2016).
ReasoNet: Learning to stop reading in ma-
chine comprehension. CoRR, abs/1609.05284.
http://arxiv.org/abs/1609.05284,.
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I.,
and Salakhutdinov, R. (2014). Dropout: A simple way
to prevent neural networks from overfitting. Machine
Learning Research, 15(1):1929–1958.
Sutskever, I., Martens, J., and Hinton, G. (2011). Gener-
ating text with recurrent neural networks. In Inter-
national Conference on Machine Learning (ICML),
pages 1017–1024, Bellevue, Washington.
Sutskever, I., Vinyals, O., and Le, Q. V. (2014). Se-
quence to sequence learning with neural networks. In
Advances in Neural Information Processing Systems
(NIPS), pages 3104–3112. Curran Associates, Inc.,
Red Hook, NY.
Tan, C., Wei, F., Yang, N., Lv, W., and Zhou, M. (2017).
S-net: From answer extraction to answer genera-
tion for machine reading comprehension. CoRR,
abs/1706.04815. http://arxiv.org/abs/1706.04815,.
Tran, K. M., Bisazza, A., and Monz, C. (2016). Recur-
rent memory networks for language modeling. In Hu-
man Language Technologies: North American Chap-
ter of the Association for Computational Linguistics
(NAACL), pages 321–331, San Diego, California.
Trischler, A., Wang, T., Yuan, X., Harris, J., Sor-
doni, A., Bachman, P., and Suleman, K. (2016).
Newsqa: A machine comprehension dataset. CoRR,
abs/1611.09830. http://arxiv.org/abs/1611.09830.
Wang, S. and Jiang, J. (2016). Machine comprehen-
sion using Match-LSTM and answer pointer. CoRR,
abs/1608.07905. http://arxiv.org/abs/1608.07905.
Wang, W., Yang, N., Wei, F., Chang, B., and Zhou, M.
(2017). Gated self-matching networks for reading
comprehension and question answering. In Annual
Meeting of the Association for Computational Lin-
guistics (ACL), pages 189–198, Vancouver, Canada.
Weissenborn, D., Wiese, G., and Seiffe, L. (2017).
Fastqa: A simple and efficient neural architecture
for question answering. CoRR, abs/1703.04816.
http://arxiv.org/abs/1703.04816.
Xiong, C., Zhong, V., and Socher, R. (2017). Dynamic
coattention networks for question answering. CoRR,
abs/1611.01604. http://arxiv.org/abs/1611.01604.
Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhudi-
nov, R., Zemel, R., and Bengio, Y. (2015). Show,
attend and tell: Neural image caption generation
with visual attention. In International Conference on
Machine Learning (ICML), pages 2048–2057, Lille,
France.
Yu, Y., Zhang, W., Hasan, K. S., Yu, M., Xiang, B., and
Zhou, B. (2016). End-to-end reading comprehen-
sion with dynamic answer chunk ranking. CoRR,
abs/1610.09996. http://arxiv.org/abs/1610.09996.
APPENDIX
Table 9 shows a sample of an MC primitive in text
word space drawn from the MSMARCO dataset and
consists of a query, query type, six context passages,
and a single reference answer. The bold text span in
the first context passage matches the gold answer.
Table 9: An entry sample of the MSMARCO dataset con-
sisting of a query, query type, six context passages, and a
single reference answer.
Query walgreens store sales average
Query Type numeric
Passages
1. the average walgreens salary ranges from approxi-
mately 15000 per year for customer service asso-
ciate cashier to 179900 per year for district manager
average walgreens hourly pay ranges from approx-
imately 735 per hour for laboratory technician to
6890 per hour for pharmacy manager salary infor-
mation comes from 7810 data points collected di-
rectly from employees users and jobs on indeed
2. the average revenue in 2011 of a starbuck store was
1078000 up from 1011000 in 2010 the average ticket
total purchase at domestic starbuck stores in no vem-
ber 2007 was reported at 636 in 2008 the average
ticket was flat 00 change
3. in fiscal 2014 walgreens opened a total of 184 new
locations and acquired 84 locations for a net de-
crease of 273 after relocations and closings how big
are your stores the average size for a typical wal-
greens is about 14500 square feet and the sales floor
averages about 11000 square feet how do we select
locations for new stores there are several factors that
walgreens takes into account such as major inter-
sections traffic patterns demographics and locations
near hospitals
4. th store in 1984 reaching 4 billion in sales in 1987
and 5 billion two years later walgreens ended the
1980s with 1484 stores 53 billion in revenues and
154 million in profits however profit margins re-
mained just below 3 percent of sales and returns on
assets of less than 10 percent
5. the number of walgreen stores has risen from 5000 in
2005 to more than 8000 at present the average square
footage per store stood at approximately 10200 and
we forecast the figure to remain constant over our
review period walgreen earned 303 as average front
- end revenue per store square foot in 2012
6. your walgreens store select a store from the search
results to make it your walgreens store and save time
getting what you need your walgreens store will be
the default location for picking up prescriptions pho-
tos in store orders and finding deals in the weekly ad
Gold Answer approximately 15000 per year
Ranking Quality of Answers Drawn from Independent Evident Passages in Neural Machine Comprehension
71
