
Computational Modelling Auditory Awareness
Yu Su
1,2
, Jingyu Wang
1
, Ke Zhang
1
, Kurosh Madani
2
and Xianyu Wang
1
1
Northwestern Polytechnical University (NPU), 127 Youyi Xilu, Xi’an 710072, Shaanxi, China
2
Universit Paris-Est, Signals, Images, and Intelli gent Systems Laboratory (LISSI / EA 3956), University Paris-Est Creteil,
Senart-FB Institute of Technology, 36-37 rue Charpak, 77127 Lieusaint, France
Keywords:
Auditory Awareness, Saliency Detection, Deep Learning.
Abstract:
Research i n the human voice and environment sound recognition has been well studied during the past de-
cades. Nowadays, modeling auditory awareness has received more and more attention. Its basic concept is
to imitate the human auditory system to give artificial intelligence the auditory perception ability. In order
to successfully mimic human auditory mechanism, several models have been proposed in the past decades.
In view of deep learning (DL) al gorithms has better classification performance than conventional approaches
(such as GMM and HMM), the latest research works mainly focused on building auditory awareness models
based on deep architectures. In this survey, we will offer a quality and compendious survey on recent audi-
tory awareness models and development trend. This article includes t hree parts: i) classical auditory saliency
detection method and developments during the past decades, ii) the application of machine learning i n ASD.
Finally, summarizing comments and development trends in this filed will be given.
1 INTRODUCTION
Auditory cognition is an important part of the human
perception system which helps human to perceive the
surrounding environment accurately. Neurobiologist
generally believes that the saliency-based selective at-
tention mechanism could be the fastest way for hu-
mans to make responses to prominent stimulus recei-
ved from surrounding environment. Hence, the bio-
inspired saliency d e te ction a pproaches could be regar-
ded a s a fea sib le way for comp utational modeling the
human awareness for artificial intelligence to percept
the surrounding environment precisely.
Auditory saliency detection (ASD) is one of the
most important research fields of realizing machine
awareness which aims at detecting the abnormal or
conspicuous sound events in the surrounding envi-
ronment. For example, when a rescue robot encoun-
ters an emergency, such a s an explosion, tremendous
amounts of salient stimulus are received simultane-
ously by the sensors o f both visual and auditory chan-
nels. However, if the image of target need for rescue
is blocked by some objects in the field of view or the
image quality is n ot good, the rela te d sound signals to
this incident could play a p ivotal role in the process of
environme ntal perception for intelligent awareness.
A considerable amount of approaches has been
presented to dete c t the auditory saliency property
from sound signals over the past decades. Almost all
the auditory saliency-driven awareness models are ba-
sed on the idea of au ditory saliency m ap (ASM). To be
specific, ASM is d erived from the concept o f the vi-
sual salient map, which is first prop osed by (Itti et al.,
1998) where to reveal the saliency of a sound signa l
in a two-dimension ima ge and make the saliency of
sound clips more intuitive to researchers.
Recently, a growing n umber of researchers have
begun to apply neural networks for sound events clas-
sification . At present, th e deep architectures have
conqu e red the field o f image and speech recognition,
but th e use of ASD still falls be hind. Researchers be-
lieve that in the next few years, deep neur al networks
based methods will provide a better solution for im-
proving the performance of ASD and make it possible
to put into practical applications.
In this work, we will present an eluc idatory sur-
vey on recent developments and indicate the future
trends in A SD. The rest of this paper is organized as
follows. We will first introduce three classical ASD
models and improved techniques in section 2. Then,
a survey on th e application of various dee p models in
acoustic classification will be presented in section 3.
Finally, concludes the main trends of ASD and out-
look for the future will be given in section 4.
160
Su, Y., Wang, J., Zhang, K., Madani, K. and Wang, X.
Computational Modelling Auditory Awareness.
DOI: 10.5220/0006925401600167
In Proceedings of the 10th International Joint Conference on Computational Intelligence (IJCCI 2018), pages 160-167
ISBN: 978-989-758-327-8
Copyright © 2018 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

2 AUDITORY SALIENCY MAP
Before discussing various auditor y saliency detection
models, we first depict three classical models which
are the first proposed computation al models for ASD.
2.1 Classical ASD Models
The reason why the sound saliency can be transfor-
med into visual representa tion is that visual and aud i-
tory perception c hannels have perceptual correlations
in high-level perceptual processing. (Li et al., 2008)
condu c te d a theoretical and experimental research on
the relevance of audio-visual perception in formation,
point out tha t there are correlations be tween images
and sounds in human perception system. Moreover,
the perception of auditory saliency could be converted
into the perception of saliency of the visual channel.
This result provides a theoretical basis and a method
to realize computational models o f ASD.
Based on this result, several ASD m odels have
been proposed for salient sound detection. Kayser
first proposed an auditory saliency map (ASM) ba-
sed on Ittis visual saliency map in (Kayser et al.,
2005). Afterward, based on Kaysers work , two im-
proved ASM approache s were proposed by (Kalinli
and Nara yanan, 2008) and (Duangudom and An der-
son, 2007).
The auditory saliency model proposed by Kayser
is based on the spectrogram of input sound signals a nd
the auditory salien cy m aps were obtained by using the
center-surround difference operator and linear com-
bination to convert auditory saliency into image sa-
liency for further analyzing. The center-surround me-
chanism was applied to compare e a ch feature maps
obtained at different scales. Then normalize them to
facilitate th ose maps that contain highly prominent
peaks. These maps are folded across different scales
to yield the saliency maps for each feature. Finally,
linear combined the saliency maps of each feature to
acquire the auditory saliency map. The structure of
ASM which is identical to the visual saliency map is
shown in Figur e 1.
In order to improve the detection accuracy of
ASM, the model presented in (Kalinli and Naray-
anan, 2008) added the characteristics of or ie ntation
and pitch as new sound features. The inform ation of
orientation is extracted from the spectrum at angles
of 45 degree s and 135 degrees. Orientatio n features
simulate the auditory neuron’s response to dynamic
ripples in the primary aud itory cortex. Since the pitch
is the most basic element of sound, therefore, Kalinli
also considered extracting the p itch as an auditory fe-
ature.
Figure 1: Kaysers Auditory Sal iency Map.
(Duangudom and Anderson, 200 7) proposed the
third classical ASM in which the time-frequency re-
ceiver domain model and a daptive suppression were
used to provide the final auditory saliency map. The
model presented in this paper is basically the same
as Kayser’s a uditory saliency map, but this model
extracted three different kinds of featu res: global
energy, time modulation, spectral modulation and
high temporal- spectral modulation.
These models have b een pr oved to be effective,
however, they all use simple sound s or speeches to
test th eir models. Kayser and Duan gudom tested their
models on simple sounds with noises. Results show
that Kaysers model matches psychoacoustic exp eri-
ment results of human saliency perception. Duan-
gudom uses the same type of sounds but his model
gives lower achievement than Kaysers result. The
model proposed by Kalinli has been tested only on
promin ent syllables in speech. As the environm ent
sound does not contain a definite pitch and its instab i-
lity characteristics, the sound saliency detection accu-
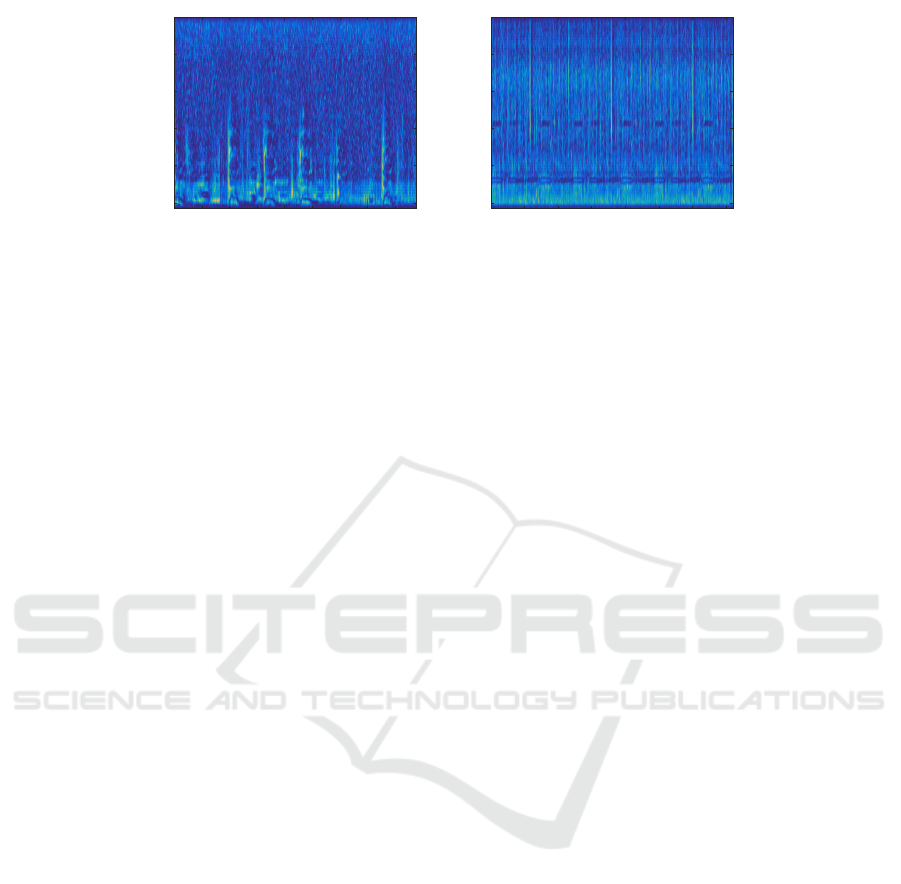
racy of these models are doubtful. Figure 2 shows
the real environmen t sound (dog bargin g and crickets
with rain) saliency d e te ction result of Kayser’s model.
The yellow part of the ASM repr esents the conspicu-
ous part of a sound clip while the blue part re presents
the background noises. It is shown from the results
that the accuracy and robustness of Kayser’s appro -
ach will d ecrease sharply when the background n oise
is relatively strong and overlaps the salient so unds.
Computational Modelling Auditory Awareness
161
Small Dog
1000 2000 3000 4000 5000 6000 7000 8000
50
100
150
200
250
(a)
Rain and Crickets
2000 4000 6000 8000 10000 12000 14000
50
100
150
200
250
(b)
Figure 2: The auditory saliency map of Kaysers model.
The other two classical models which based on the si-
milar detection principle c ould also confront the same
limitation.
2.2 Improved ASD Models
In order to solve th e drawbacks of apply ing only audi-
tory saliency map for extraction features, many rese-
arches have proposed several new ASD models during
the past decades. Based on the theory that the auditory
saliency of a soun d event is obtaine d by me asuring the
difference in the tim e domain between the sound and
its sur round ing sounds, (Ka ya and Elhilali, 2012) pro-
posed a novel model which only defined over time.
Unlike the previously mentioned three auditory sa-
liency maps which transform the input sound events
into the spectrogram at first, th is auditory salien cy
map treats the input signals as a one-dimensional tem-
poral input. The model uses rich high-dimensional
feature space to de fine auditory events a nd eac h audi-
tory dimension was processed a c ross multiple scales
but only considers the tempo ral saliency of the sound.
Research shows that the three classical models
only performed well when detecting the saliency of
short-term sound signals. For overcoming this draw-
back, (Botteldooren and De Coensel, 2009) proposed
an auditory saliency map for detecting the saliency in
long-ter m sound signals. This model first formed a
sonic e nvironment by 1/3 octave band spectrograms
of different sound signals and implemented the met-
hod propo sed in (Zwicker and Fastl, 2013) for calcu-
lating a simplified cochlea. Considering the energy
masking effects, f or one sound source, all the ot-
her sound sources can be considered as the b ack-
ground noise. Thus, the specific loud ness versus time
map contains only non-zero values for those time an d
space portions of e a ch source , which are not obscu-
red by the sum of all other sources. T hen, the same
approa c h for extracting the multi-scale feature maps
and the process of forming the final ASM proposed
in classical approach mentioned above is applied to
acquire the final saliency map . To provide the es-
sential higher-leve l cognitive information , wh ile re-
ferring to the limited knowledge of the attention me-
chanism, a simple feedback mechanism is applied to
simulate top-down attention mechanisms. In order to
validate the efficiency of this model, it has been used
to study the ability of typical urban parks to mask road
traffic noise. Results showed that it can effectively
mask the noise gene rated by traffics while this model
showed how pe rceptual masking could work in addi-
tion to energetic or physio logical masking to improve
the mental image of a sonic environment.
In order to un derstand how does human divert our
attention in different voices over time, (De Coensel
and Botteldooren, 2010) pr oposed a model for mi-
micking human top-down and bottom-up attention
mechanisms. The m odel consists of four parts. Each
input sounds a nd their summation are first converted
to spectrums through the Gammatone filterbank sepa-
rately. Then, the spectrogram of signals summation
is calculated by Kaysers ASM to obtain the salien cy
map S and Time-Frequency masks for the spectro-
grams M
i
of each sound resources was calculated at
the same time. Afterward, T-F masked spectrograms
M
i
and auditory saliency map S are combined to yield
the saliency score of each acoustic signal via:
S
i
(t) =
Z
M
i
(t, f )S(t, f )d f (1)
It should be noticed that this equation hypothe-
sis that saliency combined across frequency channels.
After saliency scores calculation, Coensel proposed
an attentio n model which mainly based on a f unction
model proposed by (Knudsen, 2007) while implement
the winner-takes-all competition to identify the most
salient sound. The model was tested with the sound
of tr affic an d its surroundings while the results proved
that this mode l can mask undesired so und signals.
Inspired by the research re sults of bird auditory
system, a task-related sound locating method through
interaural time difference and interaural leve l diffe-
IJCCI 2018 - 10th International Joint Conference on Computational Intelligence
162

rence was presented in (Mosadeghzad et a l., 2015).
After locating the input sounds, the Gammatone filter-
bank h as been used to decomp ose the left and right in-
puts in the frequency domain. Then , a saliency scor e
was acquired by multiplying the sum of the peaks
with the number of peaks in spectrograms of all the
frames. Finally, this saliency-based fusion framework
was applied to the iCub robot a nd tested it in real time
to identify the real speaker when two people were tal-
king. Results showed that although the model is still
inadequ ate, howeve r, it is a feasible way to sim ulate
the human cognitive characteristics to some extent.
Almost a ll the mod els men tioned a bove could
achieve acceptable or even prominent experiment re-
sults, however, the sound data used in their experi-
ment is human voices, simple sound clips (short re-
cordings with no background noises) or A few sylla-
bles played by one musical instrument. Meanwhile,
the previously introduced auditory saliency models
are main ly based on the local spatiotemporal con trast
and little global saliency information has been taken
into account. Considering the u nstable and non-linear
characteristics of environment sound, it is difficult to
prove that these models are effective enough in salient
sound detection tasks when the input is complex en-
vironm ent recordings.
Therefore, some researchers start to consider ot-
her methods to successfully detect the auditory sa-
liency in real envirnment. (Schauerte and Stief el-
hagen, 2013) proposed a Bayesian Surprise Model-
based auditory saliency detection mod el to lower the
computation time. The surprising means the statisti-
cal abnormal values based on the signal which is ob-
served before. First, the time-frequen cy analysis and
Bayesian probability frame of the sound signals was
analyzed by fixed discrete cosine transform. Then,
used the Gamma model and ba sed on the pr ior expe-
rience and the current signal to dete c t the frequency
saliency. Mea nwhile, a decay factor was applied to re-
duce the confidence of the prior experience to ensure
the computes efficiency. Th e mean value of saliency
of each frequency was regarded as the final saliency.
Finally, the oriented evaluation method was used to
quantitative estimate the acquired f requency saliency,
to analyze whether the saliency of each f requency was
real.
(Wang et al., 2015) proposed a bio-inspired mo-
del to detect the salient environment sounds for rea-
lizing intelligent perception. This approach first cal-
culated the Short-term Shannon entropy to estimate
the background noise level of the input signals over
the entire time period. Meanwhile, aiming to reduce
the impa ct from time length on the accur acy of sa-
liency detection, Wang proposed an Inhibition of Re-
turn (IOR) based saliency select model. After calcula-
ting the Short-term Shannon entropy, the sound signal
was divided in to several significant so und clips and
analyzed the temporal and frequency saliency of each
clip. In the temporal domain, the saliency was obtai-
ned b y analyzing the Mel Frequen cy Cepstral Co effi-
cient (MFCC) curve. I n the frequency domain, the
model obtained the frequency saliency through the
PSD curve o f the sounds. The prominent features
of the temporal domain and frequency domain were
then filtered by the IOR calculation model. Mean-
while, the image saliency was acquir ed by calcula-
ting the red- green channel of opponent color space
on the log scale spec trums of the input sound signals.
Finally, each saliency map was combined through a
heteroge neous information fusion method to produce
the auditory saliency map. In the experiment, the mo-
del has been tested with environment sound, except
backgr ound noise, which contains more than one con-
spicuous sound. Results showed that the accuracy of
this mode l is much high e r than Kaysers model.
To conclude, the conventional ASD models are
based on the theory of saliency map while several
improved models use the statistical method or bio-
inspired approach to detect the prominent sounds.
The conventional models which are based on local
features have been proved to be effective to some ex-
tent, but it has to be noticed that the experimental data
are simple recordings. The bio-inspired model pre-
sented in (Wang et al., 2015) validated its efficiency
with real environment mixtures, how ever, the Shan-
non entropy-based ap proach will cost a lot of compu-
tational resources. Meanwhile, almost all the featu-
res mentioned in these models are manually selected
which could not fully conform to the characteristics of
human auditory system and will definitely lose some
important information.
3 AUDITORY AWARENESS WITH
DEEP LEARNING
Environm e nt sounds always exist with the higher le -
vel noise than indoor sound signals and always con-
tains more than one salien t sounds. This characte-
ristic increased the difficulty of auditory saliency de-
tection or recognition tasks. Most of the conven-
tional ap proache s proposed for sounds recognition
or salient sounds detection tasks through predefined
features such as MFCC and Gammatone Frequency
Cepstral Coefficient ( GFCC) w hich compress an d re-
duce details (Chachada and Kuo, 2013) , which means
some needed details have been neglected. Compared
with the conventional sound eve nt detection methods
Computational Modelling Auditory Awareness
163

using manually selected featur es, neural network mo-
dels can direc tly take spectrograms and even raw wa-
veforms as inputs to train the networks wh ile selec ting
the features itself. Therefore, a growing number of
researchers believe that the deep neural architectu -
res which simulate the learnin g mechanism of human
could significantly improve the performance in acou-
stic detection and classification tasks.
Deep neural networks, also known as deep lear-
ning, is part of a broade r family of machine learning
methods based on lea rning data representations, it is
an algorithm that attempts to abstract high-level data
using multiple processing layers consisting of com-
plex structures or multiple nonlinear transfor mations.
Deep learning architectures such as deep neural net-
works, convolutional neural networks, and recurrent
neural networks have been applied to fields includ ing
computer vision, speech recognition and audio reco g-
nition, which show superior performa nce than con-
ventional classifiers. The benefit of deep learning is to
use unsupervised or semi-supervised featu re learning
and h ie rarchical feature extraction alg orithms instead
of manually acquiring features. This characteristic
of DL can effectively reduce the problems caused by
predefined features in environment sound classifica-
tion and reco gnition.
(Mohamed e t a l., 2012) applied the generative pre-
trained input b ased d eep belief networks (DBN) for
acoustic modeling in phone recognition. (Genc oglu
et al. , 2014) proposed a novel feature-based acoustic
events recognition m ethod with the deep neural net-
work (DNN) classifiers. The features consisted of
Mel energy features an d 4 more frames around it. The
pre-train ed DNN with 5 hid den layers performed well
in the exper iment when compared with several tradi-
tional approache s (Li et al., 2017). (Espi et al., 20 14)
proposed a deep lear ning (DL) based AED mode l. In
this literature, a high-resolution spectrograms patch is
treated as the feature. The patch is a window of sound
spectrogram frames stacked together and used as the
input instead of the predefined features for deep neu-
ral networks (DNN).
In recent years, the log-mel features and MFCC
features of sounds which is represented by spectr o-
grams a re commonly used as inputs to train deep mo-
dels for sound classification, hence, th e convolutional
neural networks (CNN), which able to extrac t higher-
level features tha t are invariant to local spectral and
temporal variations, based sound classification appro-
aches have drawn a lot of attention in recent ye a rs.
A deep model consisting of 2 convolutional layers
with max-poo ling layer and 2 fully connected lay-
ers is presented in (Piczak, 2015), which firstly pro-
vide the evidence that CNN can be effectively used in
classifying environment sounds. (Salamon and Bello,
2017) proposed a mod el which comp rised of 3 con-
volutional layers interleaved with 2 pooling opera-
tions, followed by 2 fully connected layers. Most
works, including the above-mentioned networks, in
auditory event recognition follow similar strategies,
where sig nals lasting from tens to hun dreds of ms are
modeled first. (Takahashi et al., 2018) proposed a
9 layer CNN networks which inspired by VGG Net
(Simonyan and Zisserman, 2014) with signals lasting
multiple seconds handled as a single input. Further-
more, the labeled data is one of the main barriers to
training deep ne ural networks, and available d a ta sets
of environmental sound recordings are still very limi-
ted. Therefore, the above-mentioned literature all use
data augmentation to acquire more training da tabase.
In (Salamon and Bello, 2017), the experiment result
also proved that th e classifying accuracy of CNN will
be better when data augmentation was applied.
Environm e nt sound always exists as mixtures, an d
there can be multiple sound sources that belong to the
same c la ss. Furth ermore, mo nophonic sound event
detection systems (conventional auditory events de-
tection approaches) handle the polyphonic data by de-
tecting only the prominen t event, resu lting in a loss of
informa tion in realistic environments (Mesaros et al.,
2010). These factors main ly represent the challenges
over acoustic event detection in real-life situations. If
deep neural m odels only have the ability to classify
and recognize individual sounds, it will greatly limit
the practical app lication of neural n e tworks based ar-
tificial intelligence. H e nce, polyphon ic detection is an
essential ability for artificial intelligence to perform
well in the comp lex environm e nt.
Compared with monophonic sound event d e-
tection which deals with a single sound event at
a time instance, polyphonic sound events dete ction
aims at detec ting simultaneously happened and mul-
tiple overlapped sound events. (Cakir et al., 2015)
proposed a multi-label DNNs for polyphonic sound
event detection in realistic environments. The in-
puts are first annotated frame by frame to mark out
the active sound events in each frame. Recurrent
neural networks (RNN) could directly use their in-
ternal state to pr ocess sequen ces of inputs in audio
recordings. RNN has the ability to remember past
states which make it c ould avoid the need for pos-
tprocessing or smoothing steps. The application of
RNN have obtained excellent r esults on complex au-
dio detection tasks, such as spe e ch recognition (Gra-
ves et al., 2013) and p olyphonic pia no note transcrip-
tion (Bock and Schedl, 2012 ). Motivated by this, (Pa-
rascandolo et al., 2016) proposed a bi-direction al long
short-term memory RNN ba sed approach to polypho-
IJCCI 2018 - 10th International Joint Conference on Computational Intelligence
164

nic sound event detection in real life recordings.
According to the ability that RNN can learn the
longer term temporal information in the audio signals,
combined RNN with CNN could achieve better per-
formance in complex sound event detection tasks. A
combined CNN and RNN two complementary clas-
sification methods which is called CRNN are presen-
ted in (Cakir et al., 2017). The higher level fe a tures
are first extracted by convolutional layers, then, af-
ter pooling in the frequency domain, these features
are fed into recurrent layers to acquire sound event
activity probabilities. Ex periment r e sult shows a clear
improvement of the proposed ar chitecture wh en com-
pared with CNN a nd RNN in polyphonic sound event
detection. (Adavanne et al., 2017) propose to use
low-level spatial features extrac ted from multichan-
nel audio for sound event detection with a CRNN.
Furthermore, the author extended convolutional re-
current neura l networks to handle multiple feature
classes and process feature maps using bi-dir e ctional
LSTMs. Experimen t result showed that with binau-
ral spatial features, the accuracy is higher than using
monaural features.
The m ost popular feature to train DNNs, an d their
variants, are log-mel features and MFCC features.
However, a filter bank that is designed from percep-
tual evidence is not always guaranteed to be the best
filter bank in a statistical modeling f ramework (Sai-
nath et al., 2015). Inspired by this, a growing num-
ber of researchers start to use raw waveforms as in -
puts to avoid information lost for trainin g neural net-
works. (Sainath et al., 2015) proposed a Convolu-
tional, Long Short-Term Memory Deep Neural Net-
work (CLDNN) acoustic model which trained on over
2,000 hours o f speech and achieve a competitive per-
formance with log-mel based deep models. Rese-
arch result sh ows that a pplying LSTM directly will
cause excessive time steps, hence, the original re-
cordings are first processed by a time convolutional
layer (tConv). Then, the frame-level feature produ-
ced by tConv is passed to the CLDNNs. In the CLD-
NNs, convolution layers are used to reduce frequency
domain changes, LSTM layers are used for long-time
domain modeling and DNN is the classifier.
(Dai et al., 2017) found that most waveform-based
models have generally used very few (less than two)
convolutional layers, which might be insufficient for
building high-level discriminative f eatures. Hence,
the author proposes a very deep convolutional neural
networks with waveforms as inputs. In order to have
a better represen tation of sounds, large receptive field
in the first convolutional layer are applied to mimic
bandp a ss filters, while very small receptive fields are
used to control th e model capacity. Meanwhile, fully
connected layers and dropout function ar e abandoned
as well. Experiment result showed that with the layers
of model gained, the performance gain e d.
Computational modeling of auditory awareness
plays a major role in a large variety of artificial intelli-
gence applications. To be specific, a bottom-up atten-
tion mechanism specifically designed for efficient au-
ditory surveillance demonstrated powerful detection
of alarming sound events such as gunshots and scre -
ams in natural scenes (Hu et al., 2010). However,
due to the insufficiency of the databa se, current deep
model-based metho ds commonly use single sounds or
artificially synthesized mixtures to train th e networks
rather than the real environmental sounds. Meanw-
hile, manually-selected has been proved that the loss
of inform a tion can not be avoided, but use raw wa-
veforms as input need not only more layers but also
large receptive fields in the first layer which demand
a high quality of hardware. Fu rthermore, the con-
clusion from (Sainath et al., 2015; Dai et al., 2017)
clearly showed that training deep architectures with
waveforms could only match the perform a nce of the
model using log-mel features.
4 CONCLUSIONS
We conduct a survey on auditory saliency map ba-
sed models and recent deep neural networks based
approa c hes in the resear ch field of modeling acou stic
perception in this paper. The existing methods could
be classified into two categories: c onvolution te chni-
ques based on ASM and other methods. The first
kind of approaches was based on visual saliency ma p
and they are e asy to co mpute. However, depending
on the experiment results we can conclude that they
are not efficient enough in simple sound saliency de-
tection, no t to mention the environment sounds which
has more complex comp osition and structures. Even
the second kind of techniques performed better than
the first one, experimen t results showed that there is
still vast room to improve the current techniques.
One major barrier to the application of acoustic
perception models is the absenc e of a universally ap-
plicable and accurate human auditory perception mo-
del. Existing models are proposed for specific tasks
and the perform ance will be greatly reduced when
they are used to detect othe r kinds of sound. Another
important problem is the lack of a universal environ-
ment sound database. Although th ere is some sound
database, most of the units are just simple sounds.
Furthermore, the current research works showed that
the accur a cy could be improved but the com putatio-
nal complexity will raise as well. This means tha t the
Computational Modelling Auditory Awareness
165

existing method could not dete ct the salient so unds in
real time. Therefore , the application of acoustic per-
ception models on the artificial intelligence for un-
derstandin g the rea l environment is still severely con-
strained.
The novelty detection a pproaches show a possible
way of applying DL in auditory saliency detection.
Novelty detection aims at recognizing situations in
which unusual events occur. Plethoric novelty b ased
approa c hes have been proposed in medical diagno-
sis (Clifton et al., 2011) , electronic IT security (Pa-
tcha an d Park, 2 007) and damage inspection (Surace
and Worden, 2010). Only in recent years, novelty de-
tection attracts the attention of researchers in the field
of auditory perception. (Principi et al., 2015) p resen-
ted a system to deal with acoustic novelty. When a b-
normal events occurred , this system could alert the
users to help them take appropriate decisions. (Ma r-
chi et al., 2017) presented a b road and extensive eva-
luation of state-of-the-art methods focus on novelty
detection an d show evidence that RNN-based autoen-
coders significantly outperfor m other methods. In
practical application, we assume tha t after training
DNN or its variants by tremendous sound samples
of different classes an d different sound scenes, wh ile
training the model to judge what kind of acoustic
events are possible to exist in the cu rrent scene. After
all, the model could be used to detect whether there
are some abnormal or salient sounds appea red in the
current environment. This could be regarded as re-
cognizing the novelty or saliency sound in the mixtu-
res through deep architec tures.
Deep neur al networks clear ly have the potential to
improve the performance of environment sound per-
ception and further help to build pra ctical artificial
awareness. However, no competitive research results
have bee n achieved compa red to its ap plications in vi-
sual awareness, great effort is still needed in the fu-
ture.
FUNDING
This article was supported by the China Scholars-
hip Council [Grant Nos. 201606290083] for 1.5-year
study at th e University Paris-Est. This research was
also supported by the National Science Foundation
of China under Grants 61502391 and by the Natural
Science Basic Research Plan in Shaanxi Province of
China under [Gran t Nos. 2017JM6043].
REFERENCES
Adavanne, S., Pertila, P., and Virtanen, T. (2017). Sound
event detection using spatial features and convoluti-
onal recurrent neural network. In 2017 IEEE Inter-
national Conference on Acoustics, Speech and Signal
Processing (ICASSP). I EEE.
Bock, S. and Schedl, M. (2012). Polyphonic piano note
transcription with recurrent neural networks. In 2012
IEEE International Conference on Acoustics, Speech
and Signal Processing (ICASSP). IEEE.
Botteldooren, D. and De Coensel, B. (2009). Informatio-
nal masking and attention f ocussing on environmental
sound. In Proceedings of the NAG/DAGA meeting.
Cakir, E., Heittola, T., Huttunen, H., and Virtanen, T.
(2015). Polyphonic sound event detection using multi
label deep neural networks. In 2015 International
Joint Conference on Neural Networks (IJCNN). IEE E.
Cakir, E., Parascandolo, G., Heittola, T., Huttunen, H., and
Virtanen, T. (2017). Convolutional recurrent neu-
ral networks for polyphonic sound event detection.
IEEE/ACM Transactions on Audio, Speech, and Lan-
guage Processing, 25(6):1291–1303.
Chachada, S. and Kuo, C .-C. J. (2013). Environmental
sound recognition: A survey. In 2013 Asia-Pacific Sig-
nal and Information Processing Association Annual
Summit and Conference. IEEE.
Clifton, L., Clifton, D. A., Watkinson, P. J., and Taras-
senko, L. (2011). Identification of patient deteriora-
tion in vital-sign data using one-class support vector
machines. In Computer Science and Information Sy-
stems (FedCSIS), 2011 Federated Conference on, pa-
ges 125–131. IEEE.
Dai, W., Dai, C., Qu, S., Li, J., and Das, S. (2017).
Very deep convolutional neural networks for raw wa-
veforms. In 2017 IEEE International Conference on
Acoustics, Speech and Signal Processing (ICASSP).
IEEE.
De Coensel, B. and Botteldooren, D. (2010). A model
of saliency-based auditory attention to environmental
sound. In 20th International Congress on Acoustics
(ICA-2010), pages 1–8.
Duangudom, V. and Anderson, D. V. (2007). Using au-
ditory saliency to interpret complex auditory scenes.
The Journal of the Acoustical Society of America,
121(5):3119–3119.
Espi, M., Fujimoto, M., Kubo, Y., and Nakatani, T. (2014).
Spectrogram patch based acoustic event detection and
classification in speech overlapping conditions. In
2014 4th Joint Workshop on Hands-free Speech Com-
munication and Microphone Arrays (HSCMA). IEEE.
Gencoglu, O., Virtanen, T., and Huttunen, H. (2014). Re-
cognition of acoustic events using deep neural net-
works. In Signal Processing Conference (EUSIPCO),
2014 Proceedings of the 22nd European, pages 506–
510. IEEE.
Graves, A., rahman Mohamed, A., and Hinton, G. (2013).
Speech recognition with deep recurrent neural net-
works. In 2013 IEEE International Conference on
Acoustics, Speech and Signal Processing. IEEE.
IJCCI 2018 - 10th International Joint Conference on Computational Intelligence
166

Hu, R., Hang, B., Ma, Y., and Dong, S. (2010). A bottom-up
audio att ention model for surveillance. In 2010 IEEE
International Conference on Multimedia and Expo.
IEEE.
Itti, L., Koch, C., and Niebur, E . (1998). A model of
saliency-based visual attention for rapid scene analy-
sis. IEEE Transactions on Pattern Analysis and Ma-
chine Intelligence, 20(11):1254–1259.
Kalinli, O. and Narayanan, S. (2008). A top-down auditory
attention model for learning task dependent influences
on prominence detection in speech. In 2008 IEEE In-
ternational Conference on A coustics, Speech and Sig-
nal Processing. IEEE.
Kaya, E. M. and Elhilali, M. (2012). A temporal saliency
map for modeling auditory attention. In 2012 46th An-
nual Conference on Information Sciences and Systems
(CISS). IEEE .
Kayser, C., Petkov, C. I., Lippert, M., and Logothetis, N. K.
(2005). Mechanisms for allocating auditory atten-
tion: An auditory saliency map. Current Biology,
15(21):1943–1947.
Knudsen, E. I. (2007). Fundamental components of atten-
tion. Annual Review of Neuroscience, 30(1):57–78.
Li, J., D ai, W., Metze, F., Qu, S., and Das, S. (2017). A
comparison of deep learning methods for environmen-
tal sound detection. In 2017 IEEE International Con-
ference on Acoustics, Speech and Signal Processing
(ICASSP). IEEE.
Li, X., Tao, D., Maybank, S. J., and Yuan, Y. (2008). Visual
music and musical vision. Neurocomputing, 71(10-
12):2023–2028.
Marchi, E., Vesperini, F., Squartini, S., and Schuller, B.
(2017). Deep recurrent neural network-based autoen-
coders for acoustic novel ty detection. Computational
Intelligence and Neuroscience, 2017:1–14.
Mesaros, A., Heittola, T., Eronen, A., and Vi rtanen, T.
(2010). Acoustic event detection in real life recor-
dings. In Signal Processing Conference, 2010 18th
European, pages 1267–1271. IEEE.
Mohamed, A.-R., Dahl, G. E., and Hinton, G. (2012).
Acoustic modeling using deep belief networks. IEEE
Transactions on Audio, Speech, and Language Pro-
cessing, 20(1):14–22.
Mosadeghzad, M., Rea, F., Tata, M. S., Brayda, L., and San-
dini, G. (2015). Saliency based sensor fusion of bro-
adband sound localizer for humanoids. In 2015 IEEE
International Conference on Multisensor Fusion and
Integration for Intelligent Systems (MFI ) . IEEE.
Parascandolo, G., Huttunen, H., and Virtanen, T. (2016).
Recurrent neural networks for polyphonic sound event
detection in r eal life recordings. In 2016 IEEE Inter-
national Conference on Acoustics, Speech and Signal
Processing (ICASSP). IEEE.
Patcha, A. and Park, J.-M. (2007). An overview of ano-
maly detection techniques: Existing solutions and
latest technological trends. Computer Networks,
51(12):3448–3470.
Piczak, K. J. (2015). Environmental sound classification
with convolutional neural networks. In 2015 IEEE
25th International Workshop on Machine Learning for
Signal Processing ( MLSP). IEEE.
Principi, E., Squartini, S., Bonfigli, R., Ferroni, G., and
Piazza, F. (2015). An integrated system for voice
command recognition and emergency detection based
on audio signals. Expert Systems w ith A pplications,
42(13):5668–5683.
Sainath, T. N., Weiss, R. J., Senior, A., Wilson, K. W.,
and Vinyals, O. (2015). Learning the speech f ront-
end with raw waveform cldnns. In Sixteenth Annual
Conference of the International Speech Communica-
tion Association.
Salamon, J. and Bello, J. P. (2017). Deep convolutional neu-
ral networks and data augmentation for environmental
sound classification. IEEE Signal Processing Letters,
24(3):279–283.
Schauerte, B. and Stiefelhagen, R. ( 2013). ”wow!” bayesian
surprise for salient acoustic event detection. In 2013
IEEE International Conference on Acoustics, Speech
and Signal Processing. IEEE.
Simonyan, K. and Zisserman, A. (2014). Very deep con-
volutional networks for large-scale image recognition.
arXiv preprint arXiv:1409.1556.
Surace, C. and Worden, K. (2010). Novelty detection in
a changing environment: A negative selection ap-
proach. Mechanical Systems and Signal Processing,
24(4):1114–1128.
Takahashi, N., Gygli, M., and Gool, L. V. (2018). AENet:
Learning deep audio features for video analysis. IEEE
Transactions on Multimedia, 20(3):513–524.
Wang, J., Zhang, K., Madani, K., and Sabourin, C. (2015).
Salient environmental sound detection framework for
machine awareness. Neurocomputing, 152:444–454.
Zwicker, E. and Fastl, H. (2013). Psychoacoustics: Facts
and models, volume 22. Springer Sci ence & Business
Media.
Computational Modelling Auditory Awareness
167
