
Tag Recommendation for Open Government Data
by Multi-label Classification and Particular Noun Phrase Extraction
Yasuhiro Yamada
1
and Tetsuya Nakatoh
2
1
Institute of Science and Engineering, Academic Assembly, Shimane University,
1060 Nishikawatsu-cho, Matsue-shi, Shimane, 690-8504, Japan
2
Research Institute for Information Technology, Kyushu University,
744 Motooka, Nishi-ku, Fukuoka, 819-0395, Japan
Keywords:
Open Government Data, E-Government, Tag Recommendation, Multi-label Classification, Metadata.
Abstract:
Open government data (OGD) is statistical data made and published by governments. Administrators often
give tags to the metadata of OGD. Tags, which are a collection of a single word or multiple words, express
the data. Tags are useful to understand the data without actually reading the data and also to search for OGD.
However, administrators have to understand the data in detail in order to assign tags. We take two different
approaches for giving appropriate tags to OGD. First, we use a multi-label classification technique to give
tags to OGD from tags in the training data. Second, we extract particular noun phrases from the metadata
of OGD by calculating the difference between the frequency of a noun phrase and the frequencies of single
words within the noun phrase. Experiments using 196,587 datasets on Data.gov show that the accuracy of
prediction by the multi-label classification method is enough to develop a tag recommendation system. Also,
the experiments show that our extraction method of particular noun phrases extracts some infrequent tags of
the datasets.
1 INTRODUCTION
Open government data (OGD) is statistical data pu-
blished by governments on their websites. The ca-
tegories of the data a re various, for example, budget,
education, health and finance. One purpose of OGD is
to enable anyone to freely access and reuse this data
1
.
The U.S. Government publishes OGD on the site
“Data.gov
2
”. This site had 196,587 datasets on Sep-
tember 12th , 2017. The Japanese government started
publishing OGD on the site “Data.go.jp
3
”. This site
had 18,717 datasets on Mar ch 21st, 2017 . Some local
governments also have publishe d their data o n their
own sites.
There are three kinds of stakeholders to recognize
the benefits of OGD : publishers, re-users, and con-
sumers (K¨oster and Su´a rez, 2016). Re-users develop
applications using OGD. Consumers obtain useful in-
formation from OGD and use the applications deve-
loped by re-users.
1
Open definition 2.1. http://opendefinition.org/od/2.1/en/
(accessed Jan. 23rd, 2018)
2
https://www.data.gov
3
http://www.data.go.jp
When government agents publish OGD on the
Web, they generally create metadata about their OGD.
Examples of metadata of OGD are the id, the title, the
description, the tags, and the publish date of the OGD.
This paper focuses on the tags, which are descriptive
keywords of OGD. The tags are useful for understan-
ding the content of OGD without actually reading da-
taset files. The tags also help re-users and consumers
to search for OGD that they want. A search by tags
enables them to find the desired OGD with accuracy
because tags are important words about the OGD.
We collected 196,587 datasets from Data.gov.
Each dataset has one or more resources (files). In to-
tal, the datasets have 1,105,063 resources. The num-
ber of datasets with tags is 73,304 (37.3%) . The other
123,283 datasets do not have tags. Publishe rs have to
understand the OGD in de ta il to give the tags. This
means that giving appropriate tags to the OGD is dif-
ficult and burdensom e work. Therefore, a system to
recommend tags automatically is needed.
The lack of consistency in tags negates the advan-
tage of tags in searches. For example, different pu-
blishers select d ifferent tags for the same OGD. It is
important to select appropr ia te ta gs from a common
tag set. Also, when publishers give new tags to an
Yamada, Y. and Nakatoh, T.
Tag Recommendation for Open Government Data by Multi-label Classification and Particular Noun Phrase Extraction.
DOI: 10.5220/0006937800830091
In Proceedings of the 10th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2018) - Volume 3: KMIS, pages 83-91
ISBN: 978-989-758-330-8
Copyright © 2018 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
83

Table 1: Target of this paper.
frequent tags (words) infrequent tags (words)
tags labeled manually
in an OGD portal site
multi-label classificat ion (It is difficult to predict infrequent tags by
multi-label classification techniques.)
tags not used in the
above site
(Tags in this cell will be in the
above frequent tags.)
particular tags ext raction from t he title and
the description of a dataset and its resources
OGD, th ey again come up with different tags. It is a
significant task to extract tags that are not in the com-
mon tag set from the OGD.
This paper takes two different approaches to re-
commend tags for OGD (see Table 1). The first target
is to use a multi-label classification techn ique to pre-
dict appropriate tags for a dataset from tags used in an
OGD portal site. The multi-label classification techni-
que learns classifiers for tags from datasets which
have already been given tags. Then, it predic ts tags
for a dataset without tags by using the learned classi-
fiers. However, it is difficult to predict tags which ar e
infrequent in the datasets because the amount of data
of infrequent tags is too small for learning (Jain et al.,
2016).
The second target is to extract new tags from the
title and the description of the OGD. There are vari-
ous viewpoints with respect to appropriate tags for the
OGD. A tag recommendation system sho uld display
candidate tags from various viewpoints. We apply a
term weighting method in (Yamada et al., 2018) to
extract particular tags in the OGD. The extracted tags
are noun phrases. The idea is simple: a noun phrase
is considered particular if the nouns within the noun
phrase appear only in the phrase. On the other hand,
frequent words will appear in tags of multi-labe l clas-
sification because they are commonly used in the da-
tasets.
The contributions of this paper are summarized as
follows:
• The first target is tags labeled manually in an
OGD portal site. We verify the accuracy of three
typical multi-label classification meth ods for da-
tasets with tags on Data .gov. We use 196,587 da-
tasets on Data.g ov in exp eriments. The result of
multi-label classification shows that the accuracy
of prediction by the multi-label classification met-
hod is enough to develop a tag reco mmendation
system.
• The seco nd target is nou n phrases which are not
in the above tags. We propose a method for
extracting particular noun phrases as tags from
the title and description of th e datasets and their
resources. The experiments of particular nou n
phrase extraction show that our method extracts
some infrequent tags of the datasets.
This paper is organiz ed as follows. Sectio n 2
describes related re search. Section 3 shows statis-
tics about the tags of datasets of OGD on Data.gov.
Section 4 describes multi-label classification for
OGD. Section 5 describes particular tag extraction
from OGD. Section 6 shows experiments applying
the multi-label classification and the particular tag ex-
traction. Finally, our conclusions are presented in
Section 7.
2 RELATED WORK
In this section, we describe two kinds of related rese-
arch: open government data and tag recommendation.
2.1 Open Government Data
OGD of governments is published on their data ca-
talog sites. The CKAN platform
4
is often utilized to
publish open governmen t data (Oliveira et al., 2016).
It is desired that OGD is published with machine-
readable and non-proprietar y data formats such as
CSV and XML
5
. The data formats o f OGD are va-
ried and include, for example, PDF, XLSX, CSV,
XML, and HTML. Oliveira et al. reported that the
CSV format is the most used data format in Brazilian
OGD portals (Oliveira et al., 201 6). Corrˆea and Zan-
der repo rted that about 13% of dataset files in some
main open data portals around the world are PDF for-
mats (Corrˆea and Zander, 2017). Most OGD on the
Japanese government OGD portal site Data.go.jp are
PDF o r HTML files.
Some other proposed research studies support pu-
blishers of OGD (Corrˆea and Zander, 2017; Tam-
bouris et al., 2017). Corrˆea and Zander investiga-
ted methods and tools for extracting tables in PDF
files (Corrˆea and Zander, 2017 ). A lot of OGD have
tables because they are statistical da ta. Therefore, it is
important to translate tables in PDF files into a non-
proprietary open format such as CSV. Linked open
data is the most desira ble format of OGD. Howe-
ver, it is difficult for pub lishers serving as government
agents to make OGD satisfy the requirement for lin-
ked open data because traditio nally they do not have
4
http://ckan.org
5
5-star open data. http://5stardata.info/en/ (accessed Jan.
25th, 2018)
KMIS 2018 - 10th International Conference on Knowledge Management and Information Sharing
84

the required skills. Tambouris et al. presented tools
to help the publishers make linked open data from va-
rious file formats(Tambouris et al., 2017). Our paper
focuses on tags as metadata of O G D. However, w e
could not find research to support the publishers in
the task of labeling tags of OGD.
As a reuse of OGD, some OGD portal sites of go-
vernments have introduced app lications using OGD.
Some applicatio ns using OGD of the Japanese go-
vernment are introduce d on Data.g o.jp. For exam-
ple, th e Japan Seismic Haza rd Information Station
6
was established by the N a tional Research Institute for
Earth Science and Disaster Resilience to help prevent
and prepare for earthquake disasters. Vasa and Ta-
milseva m developed a web application that uses data
from the Department of Agriculture in India (Vasa
and Tamilselvam, 2014). This application helps users
select recipes ba sed on real-time food prices.
2.2 Tag Recommendation
One approach to tag recommendation is multi-label
classification. Given a set of training examples each
of which consists of a fea ture vector and a set of la-
bels, the learning of multi-label classification consists
of generating a cla ssifier for the labels. Then, using
the classifier, the multi-label classification pre dicts la-
bels from an examp le without labels. For further in-
formation, refer to previous surveys that de scribe the
definition of multi-label classification, algorithms, da-
tasets, and evaluation measures (Herrera et al., 2016;
Tsoumaka s et al., 2010).
Some research has dealt with a large number of
labels (Babbar and Sch¨olkopf, 2017; Jain et al., 2 016;
Prabhu and Va rma, 2 014; Xu et al., 2016). Compa-
red with the datasets in (Babbar and Sch¨olkopf , 2017 ;
Jain et al., 2016; Prabhu and Varma, 2014; Xu et al.,
2016), the datasets of Data.gov considered in th e pre-
sent paper are also considered to be extreme. We ve-
rify the accuracy of three typical multi-label classifi-
cation methods for the datasets in Section 6.1.
Another approach is to extract a c andidate term,
which is a single word or multiple words, as an ap-
propriate tag from texts other than tags (Martins et al.,
2016; Ribeiro et al., 2015). Ribe iro et al. extracted
candidate terms from the publication metadata of r e -
searchers (Ribeiro et al., 2015). Martins et al. dealt
with the title and descriptions of a target object (Mar-
tins et al., 2016). In the present study, the co llec tive
target from which to extract tags is the title and the
description of a dataset and its resources on Data.gov.
Candidate terms in the present paper are noun phra-
ses.
6
http://www.j-shis.bosai.go.jp/en/
Some research h a s prop osed metrics for calcula-
ting the relevance of a candidate term as tag recom-
mendation for an object. Vene tis et al. and Ribeiro et
al. used three kinds of metrics: term frequency, the tf-
idf of a term, and the coverage of terms (Ribeiro et al.,
2015; Venetis et al., 2011 ). The present paper focuses
on the discriminative power of a tag. In contrast to
popularity, which means th a t a tag is assigne d to nu-
merous objects, a tag with discriminative power dis-
tinguishes a small numb er of sp e cific objects from ot-
her objects. For example, metrics for the discrimina-
bility are the I nverse Feature Frequency (Figueiredo
et al., 2013; Martins et al., 2016) and the document
frequency of a term. When limited to noun phrases
as candidate terms, we propose a new method to cal-
culate the discriminative power of a noun p hrase in
Section 5.
3 STATISTICS OF TAGS IN
DATA.GOV
This section describes the statistics of tags in
Data.gov, wh ich is the OGD portal site of the U. S.
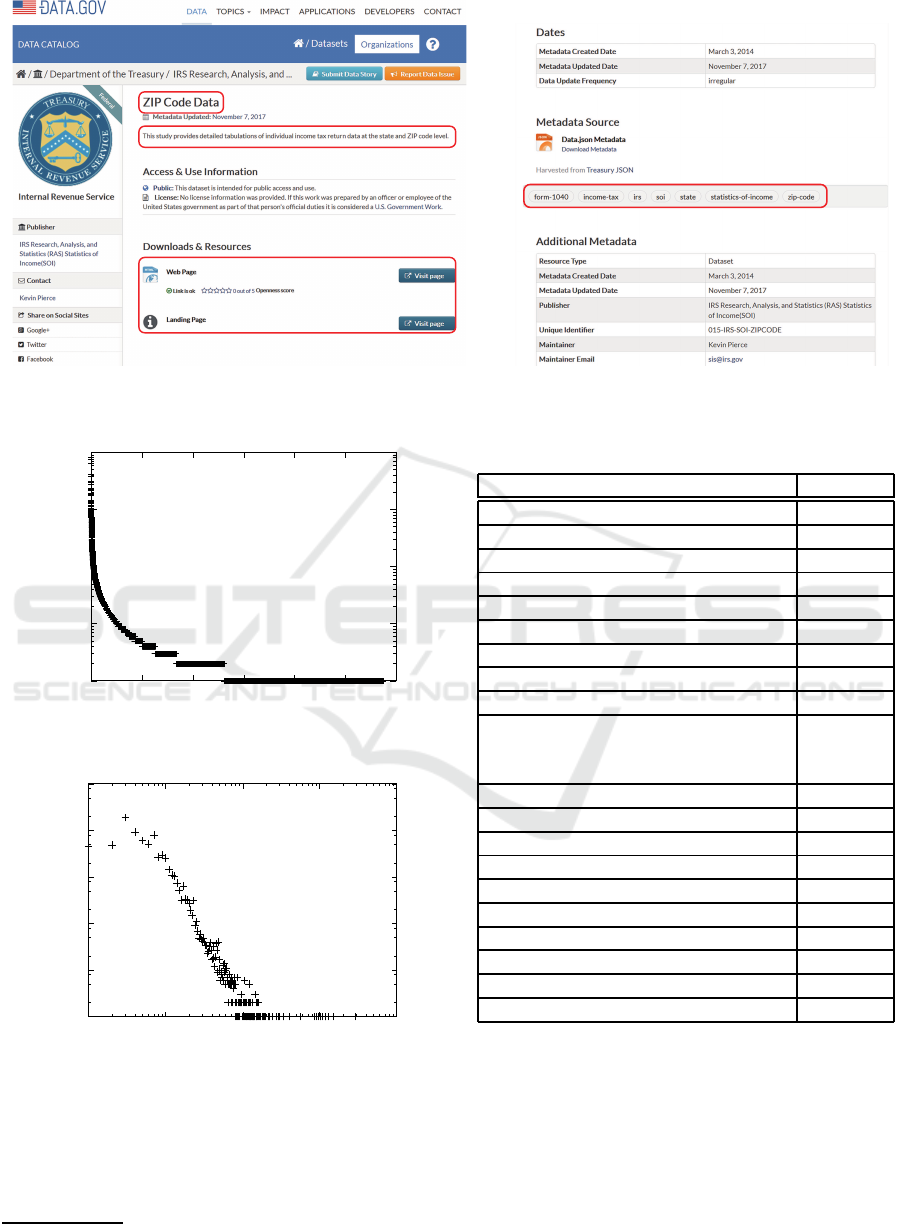
Government. Figure 1 is a Web page of OGD on
Data.gov. The left side of the figure is the top of the
page, and the right side is the rest of the pa ge. The
left side describes the title, the description of a data-
set, and the right side shows the date, tags, and other
informa tion. A dataset has one or more resource fi-
les. The metadata of a dataset includes the title, the
description, and the tags of the dataset.
We collected 196,587 datasets of Data.gov on
September 12, 2017. The number of all tags in th e
datasets is 57,430. Figure 2 shows the number of da-
tasets that each tag appears. The tags are ranked ac-
cording to the number of datasets in which they ap-
pear. The vertical axis is in log scale. We see that
most of the tags are in frequent. The numb e r of tags
appearin g once in the datasets is 31,332 (54.6%). The
number of tags whose frequency is less than or equal
to 10 is 52,435 (91.3%). On the o ther hand, the num-
ber of tags whose frequency is greater than or equal to
1,000 is 41 (0.0007%). Table 2 sh ows the top 20 mo st
frequent tags. Table 3 lists examples of tags appearing
once.
Figure 3 shows the number of tags in a d a ta set.
Both axes are in log scale. The nu mber of datasets
with tags is 73,304. On the other hand, 123,283 data-
sets (62.7%) do not have tags. Therefore, a tag recom-
mendation system is needed. The number of datasets
with only one tag is 4,608. The maximum number of
Tag Recommendation for Open Government Data by Multi-label Classification and Particular Noun Phrase Extraction
85
Title
Description
Resources
(a)
Tags
(b)
Figure 1: Web page
7
of OGD on Data.gov.
1
10
100
1000
10000
0 10000 20000 30000 40000 50000 60000
#dataset
rank
Figure 2: Number of datasets that each tag appears.
1
10
100
1000
10000
100000
1 10 100 1000 10000
#dataset
#tag in a dataset
Figure 3: Number of tags in a dataset.
tags that a dataset has is 2,932, and the average num-
ber of tags in the 73,304 datasets is 6.59.
7
https://catalog.data.gov/dataset/zip-code-data
Table 2: Top 20 most frequent tags on Data.gov.
tag #datasets
animal-studies 7,997
project 7,514
coral-reef 7,513
coral 7,477
aquatic-habitats 7,445
transect 7,442
marine-systems 7,432
photo-quadra t 7,432
completed 6,459
general-manageme nt-natural-
resources-management-wildlife-
management
6,433
general-manageme nt-inventory 4,070
waterfowl 4,046
earth-science 3,868
annual-narrative 3,063
pocillopora 2,988
annual-narrative-report 2,730
porites 2,698
oceans 2,357
general-manageme nt-monitoring 2,262
montipora 2,136
4 TAG RECOMMENDATION
USING MULTI-LABEL
CLASSIFICATION
The first approach to recommend tags for OG D
is multi-label classification. The target tags are
KMIS 2018 - 10th International Conference on Knowledge Management and Information Sharing
86

Table 3: Examples of tags appearing once.
ecological- history
lmi-energy-data
nest-tree-co ndition
water-qu ality-data-standards
yellow-billed-magp ie
washington-suburban-sanitary-commission
depository-institution
recreation-information-database
human-conflict
ones which have alre ady be en used in the datasets.
Let L = {l
1
, l
2
, . . . , l
m
} be a set of labels, and D =
{(x
x
x
1
,Y
1
), (x
x
x
2
,Y
2
), . . . (x
x
x
n
,Y
n
)} be a set of training ex-
amples where x
x
x
i
is the feature vector and Y
i
⊆ L. The
multi-label learning task is to m ake a classifier for L
from D. Then, given an unlabeled example x
x
x, the clas-
sifier predicts labels for x
x
x.
When we apply the multi-label classification to
the da tasets on the site Data.gov, we make the feature
vector x
x
x
i
of a dataset as a vector for the weighting of
nouns appearin g in the title of the dataset. The weig-
hting is the term frequency of a noun in the title. The
set of labels Y
i
correspo nds to the tags in a dataset.
We employ the one-vs-rest strategy, which ge-
nerates classifiers for eac h la bel to distinguish a la -
bel from other labels. We use suppo rt vector ma-
chine, random forests (Breiman, 2001) and multin o-
mial naive Bayes (Manning et al., 2008) methods for
making a classifier that distinguishes a label from the
rest. The methods are implemented by scikit- learn
8
.
We compare the accuracy of the three ty pical methods
in expe riments.
5 PARTICULAR NOUN PHRASE
EXTRACTION
The multi-label classification in th e previous section
uses tags already given to OGD. This classification,
therefore, can select only from the tags, and it can-
not predict words which are not in the tags. The se-
cond appro ach considers extracting words as appro-
priate tags from the OGD rather than using the tags.
We counted the words in each tag of the datasets
on Data.gov. We foun d that 36,340 (63.3%) of a ll
57,430 tags consist of multiple words
9
. When limi-
ted to tags whose frequency is less than 6 in the da ta-
sets, 32,139 (65.8%) of 48,856 tags consist of multi-
ple words. Therefore, many infrequen t tags are mul-
tiple words, such as noun p hrases.
8
http://scikit-learn.org/stable/
9
Words in a tag are joined by the character “-” on Data.gov.
First, we extract noun phrases from the title and
the de scription of a dataset and its resources of OGD.
We see them as a text. We use patterns for the noun
phrases reported in (Kang et al., 2015). The p atterns
are as follows:
< NP >::=< Pre >< NN > | < NN >
| < NP > “in” < NP >
< Mod >::= “jj”|“nn”|“nn$”|“np”
< Pre >::=< Mod > | < Pre >< Mod >
< NN >::= “nn”|“np”|“nns”
where “jj” means adjective, “nn ” means noun, “np”
means proper noun, “nn$” means possessive noun,
“nns” means plural noun, and “in” means preposition.
We use TreeTagger
10
for morphological analysis of
these En glish texts.
Next, we examine the frequ ency of noun ph rases
in the datasets. Frequent noun phrases are commonly
used in many of the datasets. Therefo re, the phra-
ses are im portant. Such phrases would have alrea dy
extracted manually as tags. We look a t the discrimi-
native p ower of noun phrases in the da tasets. The
simplest metric for the discriminability is document
frequency of a noun phrase. In the case of OGD, the
docume nt frequency of a noun phrase is defined as the
number of datasets that the phrase appears. H owever,
there are a lot of infrequent phrases with the same do-
cument freque ncy based on Zipf’s law. We can not
distinguish the infrequent phrases from the view point
of the discriminability.
We extract particular noun phrases for each da-
taset by modifying the term weighting method for
noun phrases proposed in (Yamada et al., 2018)
11
. It
is n a tural that the frequency of word s within a noun
phrase np is hig her tha n the frequency of np itself in a
set of datasets because np includes the words. Howe-
ver, if a noun phrase does not satisfy th is natural as-
sumption, then the words mostly appear only within
the noun phrase. That is, the words are related to only
the noun phrase. Therefore, the noun phrase is consi-
dered to be particular in the datasets.
Let np = w
1
w
2
··· w
m
be a noun phra se which
matches the ab ove pattern in a dataset, where “
”
is a space, and w
1
, w
2
, ··· , w
m
are words. If the
words w
1
, w
2
, ···, w
m
appear within only the noun
phrase np, then the words are strongly associated
with only the phrase. In addition, the frequency of
w
1
, w
2
, ··· , w
m
and np is the same.
The average of the difference between the fre-
quency of noun p hrase np = w
1
w
2
··· w
m
and the
10
http://www.cis.uni-muenchen.de/ schmid/tools/ TreeTag-
ger/
11
In (Yamada et al., 2018), a noun phrase is defined as
nouns appearing successively in a text.
Tag Recommendation for Open Government Data by Multi-label Classification and Particular Noun Phrase Extraction
87

frequency of words w
1
, w
2
, . . . , w
m
is defined as fol-
lows:
diff(np) =
1
m
m
∑
i=1
(freq(w
i
) − freq(np)) (1)
where freq(∗) is the total frequency of ∗ in all data-
sets. Clear ly, freq(w
i
) ≥ freq(np). The smaller the va-
lue of diff(np) is, the more particular the noun phrase
is.
We assume that np = w
1
w
2
w
3
. If freq(np) =
freq(w
1
) = freq(w
2
) = freq(w
3
) = 10, the n diff(np) =
1
3
{(10 − 10) + (10 − 10) + (10 − 10)} = 0. If
freq(w
1
) = 20, freq(w
2
) = 50, and freq(w
3
) = 110,
then diff(np) =
1
3
{(20 − 10) + (50 − 10) + (110 −
10)} = 50.
The proposed particular noun phrase extraction
proced ure for OGD follows the steps below. Given a
set D of da tasets with the title and the description of a
dataset and its resources, the procedure counts th e to-
tal frequency of words and noun phrases in D. Th e n,
it calc ulates the formula 1 of all noun p hrases in each
dataset. Finally, it sorts the noun phrases by diff(np)
for each dataset and outputs the sorted noun phrases.
Noun phrases which are output by th e pro cedure
are not always infrequent in the datasets. However,
we can consider that noun phra ses with a small va-
lue of diff(np) a re particular even if the phrases ap-
pear in some datasets. As d e scribed in Section 1 , it
is desirable that a ta g recomm endation system out-
puts candidate tags from various viewpoints and pu-
blishers of OGD select appropriate tags from the ca n-
didates. This section proposed a new viewpoint about
the discriminability of tags.
6 EXPERIMENT
This section shows experiments of multi-label clas-
sification for OGD on Data.gov by using the sup-
port vector machine, the random forest and multino-
mial naive Bayes methods. Th is section also shows
noun phrases extracted by the method of the previous
section.
6.1 Multi-label Classification
6.1.1 Dataset
We collected 196,587 datasets of Data. gov on Sep-
tember 12, 2017. The total number of tags in the da-
tasets is 57,430. From datasets with tags, the training
data are 9 0% of the data sets selected randomly, and
the test data are the rest of the data sets. In advance, we
eliminated tags which appear less tha n twenty times
Table 4: Training data and test data in the experiment of
multi-label classification.
# of all data sets 68,832
# of datasets in training data 62 ,203
# of datasets in test data 6,629
# of tags in training data 2,917
# of words in training data 26,187
in the training da ta because it is difficult to predict in-
frequent tags in the training data and the learning time
is too long. After the elimination, the number of tags
in the training data is 2,917. We also eliminated tags
that appear in the test data but do not appear in the
training data because it is im possible to predict the
tags. Tab le 4 shows the statistics of the training and
test data. Each da ta set in the training and the test data
is vectorized by using th e term frequency of nouns in
the title of each dataset.
6.1.2 Evaluation Measures
We use the micro f measure, the macro f measure
and the average precision to evaluate the tags pre-
dicted by a classifier (Tsoumakas et al., 2010). Let
T = {t
1
,t
2
, . . . ,t
n
} be a set of tags in the tr aining data.
First, we define the recall and the precision of tag t
i
in
the da tasets as follows:
recall
t
i
=
T P
t
i
T P
t
i
+ FN
t
i
,
precision
t
i
=
T P
t
i
T P
t
i
+ FP
t
i
,
where TP
t
i
denotes the n umber of examples in the test
data with corr e ctly predicted tag t
i
, FN
t
i
is the number
of examples that have t
i
but are not predicted t
i
by a
classifier, and FP
t
i
is the number of examples that do
not have t
i
but are predicted t
i
by a classifier.
Then, the f measure of t
i
is defined as follows:
f
measure
t
i
=
2 × recall
t
i
× precision
t
i
recall
t
i
+ precision
t
i
.
We descr ibe an exception, which is that a tag t
i
appears in the training data but does not appear in the
test data, to calculate the f mea sure. In this case, if
a classifier does not predict t
i
in all examples of the
test data, then both recall
t
i
and precision
t
i
are 1. The-
refore, f
measure
t
i
is 1. If it predicts t
i
in any of the
examples, then recall
t
i
is 1 but precision
t
i
is 0. The-
refore, f
measure
t
i
is 0.
The macro f measure of all tags is defined as fol-
low:
macro
f measure =
1
n
n
∑
i=1
f
measure
t
i
where n is the cardinal num ber of T.
KMIS 2018 - 10th International Conference on Knowledge Management and Information Sharing
88

We define the micro re call and precision of all tags
as f ollows:
micro
recall =
∑
n
i=1
T P
t
i
∑
n
i=1
T P
t
i
+
∑
n
i=1
FN
t
i
,
micro
precision =
∑
n
i=1
T P
t
i
∑
n
i=1
T P
t
i
+
∑
n
i=1
FP
t
i
.
Then, the micro f measure for all tags is defined
as f ollows:
micro
f measure =
2 × micro
recall × micro precision
micro recall + micro precision
.
The average precision evaluates the rank of tags
predicted by th e classifiers. First, we define precision
at rank k as follows:
precision(k) =
1
k
k
∑
i=1
r
i
where r
i
= 1 if a tag at rank i is one of the tags of an
example in the test data; otherwise, r
i
= 0. Then, the
average precision is defined as follows:
average
precision =
1
|E|
|E|
∑
i=1
1
|Y
i
|
n
∑
k=1
r
k
× precision(k)
where |E| is the nu mber of examples in the test data,
|Y
i
| is the number of tags of the i-th example in the
test d a ta , and n is the cardinal numb er of T .
6.1.3 Result
We implemented the function predict
prob() in scikit-
learn to order tags for an examp le in the test data when
using the random forest and multinomial naive Bayes
methods. The function predict
prob() return s proba-
bility estimates. In the experime nts on the micro and
the macro f measure, we see tags for which the pro -
bability estimate is g reater than 0.5 as predicted tags.
The support vector machine predicts whether each tag
should be assigned to the example using the function
pred() in scikit-learn. Therefore, the predicted tags
are not ordered. This is the reason that the cell of
the average precision of the support vector machine is
blank in Ta ble 5.
Table 5 shows the results for each method. Th e
support vector machine provided the best results
among the methods. The results for the r andom forest
are approximately the same as those for the su pport
vector machine and are better than the results for the
multinomia l naive Bayes method. Roughly speaking,
the random forest and the support vector machine can
correctly predict three out of four tags that are assig-
ned to an example. Moreover, when th ey predict four
tags for an example, three out of the four tags are cor-
rect.
0
0.2
0.4
0.6
0.8
1
10 100 1000 10000
f measure
frequency of each tag in training data
Figure 4: F measure for each frequency of t ags in training
data using the random forest.
Figure 4 shows the f measure for each freque ncy
of tags in the training data using the random forest.
The horizontal axis is plotted on a log scale. Many
of the frequent tags in the train ing data have a high
f measure. On the other hand, some tags for which
the f measure is 0 appear fewer than 100 times in the
training d ata.
As shown in Table 5, the ma cro f measure of all
methods is lower than the micro f measure. The ma-
cro f measure is the average of the f measures of all
tags. Therefore, if a tag is infrequent in the test data
and the f measure of the tag is 0, the macro f measure
is decreased. On the other hand, the micro f measure
is not significantly affected.
Figure 4 and Table 5 show that the f measure
of some infrequen t tags in the training data is low,
even th ough we eliminated tags that a ppear less than
twenty times in the data in advance. This shows that
predicting inf requent ta gs using the multi-label clas-
sification is difficult.
There are two different app roaches to deal with
this pr oblem. The first approac h is to improve an al-
gorithm of multi-label classification for infrequent la-
bels. Jain et al. proposed PfastreXML, which is a
multi-label classification algorithm for predictin g in-
frequent labels (Jain et al., 2016). Another approach
is to re-sample examples in the training data (Haixiang
et al., 2017). For example, over-sampling increa-
ses examples of infrequent labels. SMOTE (Chawla
et al., 2002) selects k nearest neighbors of an example
of an infrequent label an d then makes a new example
between the neighbor s and the example. Using these
approa c hes to rec ommend tags of OGD is the subject
of a future study.
The average precision of the random forest met-
hod is 0.766. For example, if an example in the
test data has two tags, which are predicted to h ave
ranks 1 and 4, then the average precision is 0.750.
If an example has seven tags, which are predicted to
have ranks ranging from 2 to 8, then the average pre-
Tag Recommendation for Open Government Data by Multi-label Classification and Particular Noun Phrase Extraction
89

Table 5: Results for multi-label classification methods.
micro f measure macro f measure average precision
support vector machine 0.775 0.597 —
random fo rest 0.763 0.538 0.766
multinomia l naive Bayes 0.597 0.244 0.619
1
10
100
1000
10000
100000
1 10 100 1000
#datasets
#different noun phrases in a dataset
Figure 5: Number of different noun phrases extracted by
our method from a dataset and the number of datasets with
each number of the different phrases.
cision is 0.754.
We consider developing a tag recommendation sy-
stem for publishers of OGD. After inputting the title
of the OGD into the system, the system displays a p-
proxim ately twenty predicted tags, each of which has
a degree of recommendation. The publisher then se-
lects appropriate tags from the predicted tags. Based
on the experiments, we can reasonably conclu de that
the random forest provides good results because cor-
rect tags are ranked at the top of prediction.
6.2 Particular Noun Phrase Extraction
We extracted a total of 3 ,912,648 noun phrases from
the title and description of 196,587 datasets and their
resources. The number of different noun phrases ex-
tracted was 6 45,183. Figure 5 shows the number of
different noun phrases extracted by the proposed met-
hod from a dataset and the number of datasets with
each number of different phrases. The numbers of da-
tasets that were not extracted no un phrases and that
which had only one noun phrase are 277 and 1,003,
respectively. The maximum and average numbers of
different noun phrases extracted from a dataset are
745 and 19.9, re spectively.
A total of 3,448 different noun phrases out of
the top noun phrases extracted by the proposed met-
hod fr om datasets are included in the 57,430 tags of
Data.gov. Figure 6 shows the freque ncy of tags of
Data.gov that are the same as noun phrases extracted
by the proposed method. The tags are sorted in as-
cending order of frequency. The freque ncy as tags of
1
10
100
1000
10000
0 2000 4000
frequency of tags
rank
Figure 6: Frequency of tags of Data.gov which are the same
as noun phrases extracted by our method.
2,827 of the 3,448 noun phrases is less than 10. The-
refore, the noun phrase extraction method proposed
in Section 5 extracted noun phrases corresponding to
infrequent tags on Data.gov.
Since the fr e quency of prepositions is high, noun
phrases with prepositions tend to increase the value in
formu la 1. We should have excepted the frequency of
them from the calculation of the formula 1.
We proposed a method by which to calculate the
discriminative power of no un phrases in a n ew light.
It is desirable and natural that the re are various view-
points with respect to appropriate tags for OGD, such
as the p opularity and the coverage of tags, as descri-
bed in Section 2. Again, su ppose that we develop a
tag rec ommendation system that displays candidate
tags. The system sh ould display candidate tags ex-
tracted b ased on various viewpoints, and publishers
of OGD can then select correct tags from among the
candidates.
7 CONCLUSION
This pap er examined tag recommendations for open
government data. The two different approaches are
multi-label classification and particular noun phr ase
extraction. We applied three multi- label classification
methods, the support vector machine, the random fo-
rest and the multinomial naive Bayes. Although the
random forest rec eived a good result fo r a tag rec om-
mendation system, further improvement of the accu-
racy of prediction is important. Our particular noun
phrase extraction method extracted some noun phra-
KMIS 2018 - 10th International Conference on Knowledge Management and Information Sharing
90

ses which are the same a s infrequent tags on Data.gov.
Our futu re work is to re commend tags which are
infrequent in training data. In our curr ent experi-
ments, we eliminated tags which appe a r fewer than
twenty times in the d a ta sets in advance. Nevertheless,
the accuracy of infreque nt tags in training data was
low. Infreq uent tags tend to express the con crete con-
tent of OGD. Therefore, infrequent tags are important
to understand OGD without actually reading the data.
Future work includes the d evelopment of a Web
system which recommends tags when users input the
OGD in formation. The system displays candidate
tags output by multi-label classification a nd on e s ex-
tracted by various viewpoints including our particular
noun phrase extraction.
ACKNOWLEDGEMENTS
This work was partially supported by JSPS KA-
KENHI Gr ant Numbers 15K00426.
REFERENCES
Babbar, R. and Sch¨olkopf, B. (2017). Dismec: Distribu-
ted sparse machines for extreme multi-label classifi-
cation. In Proceedings of the 10th ACM International
Conference on Web Search and Data Mining, pages
721–729. ACM.
Breiman, L. (2001). Random forests. Machine Learning,
45(1):5–32.
Chawla, N. V., Bowyer, K. W., Hall, L. O., and Kegel-
meyer, W. P. (2002). Smote: Synthetic minority over-
sampling technique. J. A rtif. Int. Res., 16(1):321–357.
Corrˆea, A. S. and Zander, P.-O. (2017). Unleashing tabular
content to open data: A survey on pdf table extraction
methods and tools. In Proceedings of the 18th Annual
International Conference on Digital Government Re-
search, pages 54–63. ACM.
Figueiredo, F., Pinto, H., Bel´em, F., Aleida, J., Gonc¸alves,
M., Fernandes, D., and Moura, E. (2013). Assessing
the quality of textual features in social media. Infor-
mation Processing and Management, 49(1):222–247.
Haixiang, G., Yijing, L., Shang, J., Mingyun, G., Yua-
nyue, H., and Bing, G. (2017). Learning from class-
imbalanced data: Review of methods and applicati-
ons. Expert Systems With Applications, 73:220–239.
Herrera, F., Charte, F., Rivera, A. J., and del Jesus, M. J.
(2016). Multilabel Classification: Problem Analysis,
Metrics and Techniques. Springer Publishing Com-
pany, Incorporated, 1st edition.
Jain, H., Prabhu, Y., and Varma, M. (2016). Extreme multi-
label loss functions for recommendation, tagging, ran-
king & other missing label applications. In Procee-
dings of the 22nd ACM SIGKDD International Confe-
rence on Knowledge Discovery and Data Mining, pa-
ges 935–944. ACM.
Kang, N., Doornenbal, M. A., and Schijvenaars, R. J. A.
(2015). Elsevier journal finder: Recommending jour-
nals for your paper. In Proceedings of the 9th ACM
Conference on Recommender Systems, pages 261–
264. ACM.
K¨oster, V. and Su´arez, G. (2016). Open data for develop-
ment: Experience of uruguay. In Proceedings of the
9th International Conference on Theory and Practice
of Electronic Governance, pages 207–210. ACM.
Manning, C. D., Raghavan, P., and Sch¨utze, H. (2008). In-
troduction to Information Retrieval. Cambridge Uni-
versity Press.
Martins, E. F., Bel´em, F. M., Almeida, J. M., and
Gonc¸alves, M. A. (2016). On cold start for associa-
tive tag recommendation. J. Assoc. Inf. Sci. Technol.,
67(1):83–105.
Oliveira, M. I. S., de Oliveira, H. R., Oliveira, L. A., and
L´oscio, B. F. ( 2016). Open government data portals
analysis: The brazilian case. In Proceedings of the
17th International D igital Government Research Con-
ference on Digital Government Research, pages 415–
424. ACM.
Prabhu, Y. and Varma, M. (2014). Fastxml: A fast, accurate
and stable tree-classifier for extreme multi-label l ear-
ning. In Proceedings of the 20th ACM SIGKDD In-
ternational Conference on Knowledge Discovery and
Data Mining, pages 263–272. ACM.
Ribeiro, I. S., Santos, R. L., Gonc¸alves, M. A., and Laen-
der, A. H. (2015). On tag r ecommendation for exper-
tise profiling: A case study in the scientific domain.
In Proceedings of the 8th ACM International Confe-
rence on Web Search and Data Mining, pages 189–
198. ACM.
Tambouris, E., Kalampokis, E ., and Tarabanis, K. (2017).
Visualizing linked open statistical data to support pu-
blic administration. In Proceedings of the 18th Annual
International Conference on Digital Government Re-
search, pages 149–154. AC M.
Tsoumakas, G., Katakis, I., and Vlahavas, I. (2010). Mi-
ning multi - label data. In Data Mining and Knowledge
Discovery Handbook, pages 667–685.
Vasa, M. and Tamilselvam, S. (2014). Building apps with
open data in india: An experience. In Proceedings
of the 1st International Workshop on Inclusive Web
Programming - Programming on the Web with Open
Data for Societal Applications, pages 1–7. ACM.
Venetis, P., Koutrika, G., and Garcia-Molina, H. (2011). On
the selection of tags for tag clouds. In Proceedings of
the 4th ACM International Conference on Web Search
and Data Mining, pages 835–844. ACM.
Xu, C., Tao, D., and Xu, C. (2016). Robust extreme
multi-label learning. In Proceedings of the 22nd
ACM SIGKDD International Conference on Know-
ledge Discovery and Data Mining, pages 1275–1284.
ACM.
Yamada, Y., Himeno, Y., and Nakatoh, T. (2018). Weig-
hting of noun phrases based on local frequency of
nouns. In Recent Advances on Soft Computing and
Data Mining - Proceedings of the 3rd International
Conference on Soft Computing and Data Mining, pa-
ges 436–445. Springer.
Tag Recommendation for Open Government Data by Multi-label Classification and Particular Noun Phrase Extraction
91
