
A Semantically Aware Explainable Recommender System using
Asymmetric Matrix Factorization
Mohammed Alshammari, Olfa Nasraoui and Behnoush Abdollahi
Knowledge Discovery and Web Mining Lab, CECS Department, University of Louisville, Louisville, Kentucky 40292, U.S.A.
Keywords:
Recommender Systems, Semantic Web, Collaborative Filtering, Matrix Factorization.
Abstract:
Matrix factorization is an accurate collaborative filtering method for predicting user preferences. However,
it is a black box system that lacks transparency, providing little information about both users and items in
comparison with white box systems. White box systems can easily generate explanations, relying on the rich
information foundation that these systems exploit in an explicit manner. However, the accuracy of recommen-
dations is generally low. In this work, we take advantage of the Semantic Web in the process of building a
black box model which can make recommendations that can be explained. Our experiments show that our
proposed method succeeds in producing lower error rates and in explaining its outputs.
1 INTRODUCTION
Collaborative filtering (CF) uses only rating data to
predict user preferences. Because it does not require
content, CF is generally better able to handle complex
domains where content is hard to collect or to encode.
In addition, because it is based on users’ collective
activity or ratings, CF is better able to make serendi-
pitous suggestions that share little content-based simi-
larity with a user’s past preferences. One well-known
CF technique that has shown powerful predictive abi-
lity is Matrix Factorization (MF) (Koren et al., 2009).
Like other black box models, MF is accurate; howe-
ver, because the recommendations are not explaina-
ble, it is not transparent.
The Semantic Web (SW) is a platform for struc-
tured data that is considered a rich resource for ex-
tracting additional knowledge and meaning about
users and items (Bizer et al., 2009), in addition to the
explicit preference ratings available on hand. In this
paper, we present a new MF recommendation strategy
that exploits additional SW resources for explanation
generation.
2 RELATED WORK
Building user models or profiles is a fundamental
task in many recommender systems. For this re-
ason, and because the SW is a platform of linked
data, there have been many efforts using the SW
in this area. The SW was has also been utilized
to build meaning-aware user models and user profi-
les within the Web personalization and Web Mining
fields (Stumme et al., 2002) (Berendt et al., 2002).
Reference (Berendt et al., 2005) emphasized that the
SW will play an important role in Web Mining be-
cause of its capability to make information on the Web
machine-processable and understandable. The com-
bination of SW and Web Mining was also studied in
(Stumme et al., 2006) where SW technologies impro-
ved the Web Mining results. In addition, (Nasraoui
et al., 2008) built user profiles by integrating seman-
tics obtained from ontologies, website structures, and
implicit user activity data (clicks).
Furthermore, (Achananuparp et al., 2007) used
web page textual content data along with the Word-
Net ontology (Miller, 1995) to build a semantically
enhanced user model that can help in personalization
and understanding user needs in information retrieval.
In the context of building MF models, (BenAbdal-
lah et al., 2010) proposed an asymmetric factorization
technique for leveraging more domains in building an
MF model. This approach was later used by (Abdol-
lahi and Nasraoui, 2014) to learn a MF recommen-
dation system that can handle the cold start problem.
The method is based on building the MF model using
one domain and then using another domain to learn
the final version of the model.
Explainability has been studied in the context of
recommendations with several different methods. For
instance, (Bilgic and Mooney, 2005) proposed several
268
Alshammari, M., Nasraoui, O. and Abdollahi, B.
A Semantically Aware Explainable Recommender System using Asymmetric Matrix Factorization.
DOI: 10.5220/0006937902680273
In Proceedings of the 10th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2018) - Volume 1: KDIR, pages 268-273
ISBN: 978-989-758-330-8
Copyright © 2018 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

recommendation explanation styles, such as Neighbor
Style Explanation (NSE), Influence Style Explanation
(ISE), and Keyword Style Explanation (KSE), it has
also been explored by (Symeonidis et al., 2008). Her-
locher et al. (Herlocker et al., 2000) argued that ex-
planations are needed to enhance the performance of
CF recommender systems. In their work, they explo-
red 21 explanation interfaces, where they eliminated
the recommended items and kept only the explanati-
ons for users to choose from, They found that, from a
promotion point of view, the best interface that users
voted for was a histogram-like explanation interface.
Other interfaces included past performance, table of
neighbors’ ratings, and similarity to other movies ra-
ted. Later, (Vig et al., 2009) used community tags to
explain recommendations. The researchers categori-
zed explanations into three types, as follows: item-
based, where an explanation is created based on ot-
her similar items; user-based, where the system relies
on other similar users to explain its recommendation;
and feature-based, where features, such as genre, are
used to justify the output. It is worth mentioning that
this work used the KSE explanation style. An exam-
ple of an explanation could be as follows: This mo-
vie is being recommended to you because it is tag-
ged with mystery which is present in the tags of mo-
vies you liked before. Another study that used KSE
as the explanation style is (McCarthy et al., 2004) in
which the researchers designed a Content-based Fil-
tering model for recommending digital cameras. This
system explains recommendations by converting ca-
meras’ components, such as memory size and reso-
lution, into sentences. Then, users can choose what
set of the explained features meet their requirements.
In (Zhang et al., 2014), the authors built a CF recom-
mender system that relies on the Latent Factor Models
technique to produce accurate recommendations with
attached explanations that are generated using senti-
ment analysis of users’ reviews. Moreover, a solution
was proposed in (Abdollahi and Nasraoui, 2016) and
(Abdollahi and Nasraoui, 2016b) for black box MF
using the ratings in a user’s neighborhood to generate
explanations. An explanation is generated based on
how neighbors rated the recommended item, and the
explanation style is NSE.
3 PROPOSED METHOD
Semantic data represents a rich source of knowledge
about both users and items. For instance, it is possible
to identify users who clearly show an interest in mo-
vies where certain actors play leading roles. Such me-
aningful knowledge can be used to generate meaning-
ful explanations for recommended movies. However,
to maintain transparency, it is desired to have these ex-
planations consistent with the actual MF model that is
built from rating data. In other words, we would like
to build a MF model that takes into account not only
user preference ratings but also potentially meaning-
ful explanations for these ratings. For this purpose,
we propose including available semantic knowledge
that could later be used for explanations, in the pro-
cess of learning a low-dimensional latent space repre-
sentation of users and items. This process will need to
incorporate information from two different domains,
namely the domain of semantic knowledge for the ex-
planations, and the domain of ratings for recommen-
dations. One approach for accomplishing this multi-
domain task is using Asymmetric MF (BenAbdallah
et al., 2010) (Abdollahi and Nasraoui, 2014) which
is a two step, multi-domain process. In the first step,
a semantic latent space model is built using the ex-
planation semantics of either or both users and items.
Then, the semantic latent space model vectors from
the first step are transferred to the second MF step,
where users’ explicit preference, such as rating, are
used to update the final recommendation model. In
this way, the final latent space vectors will strive to re-
construct the ratings used as input data in the second
step, while being anchored in the semantic explana-
tion data used in the first step of the factorization.
The flowchart of the proposed method, namely
Asymmetric Semantic Explainable MF with User-
Item-based (ASEMF UIB) semantic explainability
graph, is shown in Figure 1. The method consists
of two phases, as follows: the knowledge foundation
phase and model-building phase. In the first phase
(Knowledge Foundation), both the semantic explai-
nability graph and known ratings are prepared to be
used by the model-building algorithm in the second
phase, which will be devoted to learning the MF mo-
del using these semantics. The first semantic explai-
nability graph for all users relative to all items is con-
structed based on a specific semantic feature (such as
the actor for movie items).
First, an item by a semantic feature matrix is built
as follows:
S
I
f ,i
=
(
1 i f f possessed byi,
0 otherwise.
(1)
where f represents a semantic feature, such as an ac-
tor; i denotes an item (in this paper, a movie); and I is
the set of all items. We then compute a second matrix
for each user and semantic feature as follows:
S
U
f ,u
=
(
N f possessed by itemsliked by u,
0 otherwise.
(2)
A Semantically Aware Explainable Recommender System using Asymmetric Matrix Factorization
269
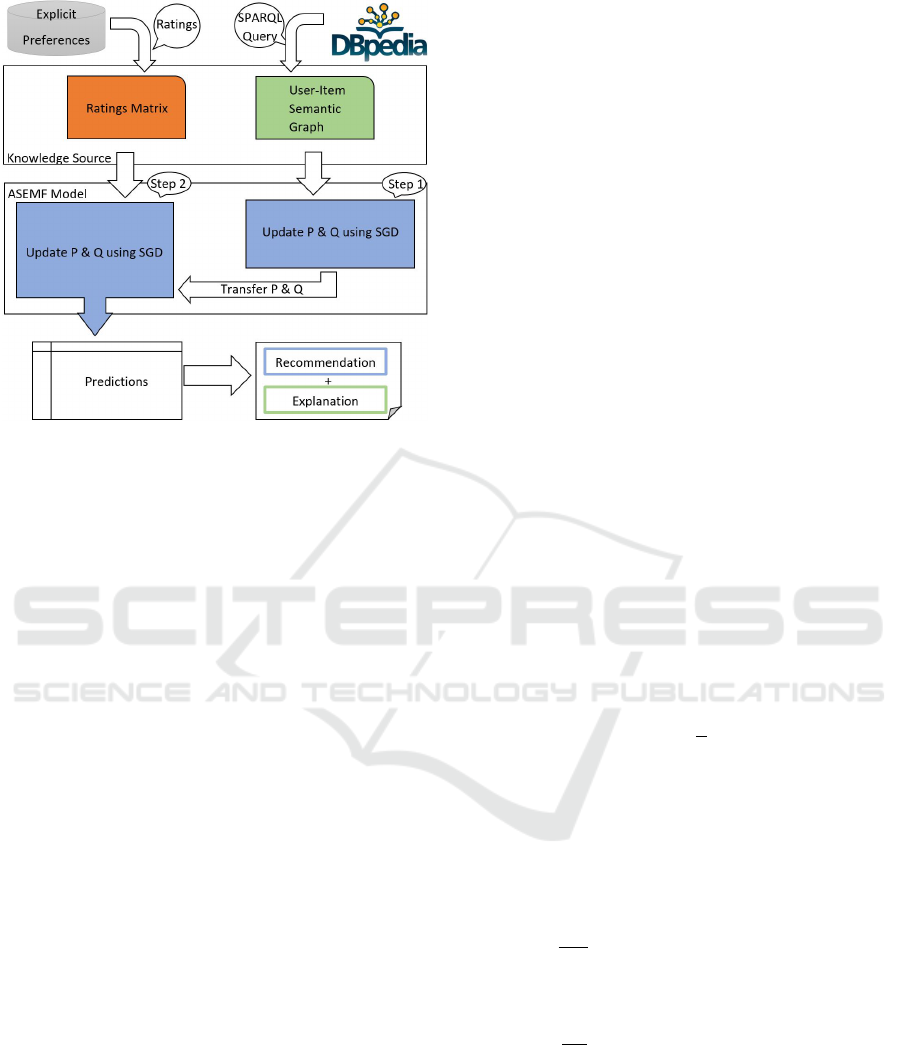
Figure 1: Flowchart for Asymmetric Semantic Explainable
Matrix Factorization (ASEMF).
Here, U is set of all users and f is a semantic feature,
as in the previous matrix. Moreover, u represents a
user, and N is the number of times each semantic fea-
ture f was present in items that user u had rated in the
past.
The previous two matrices can be combined into
a score indicating how likely a user is to like an item
based on how certain semantic features are preferred
by the user and how likely those semantic features are
to be present in the item. The combined score is com-
puted using:
S
UI
u,i
=
(
S
U
f ,u
· S
I
f ,i
i f S
U
f ,u
· S
I
f ,i
> θ
s
,
0 otherwise.
(3)
The resulting matrix contains explainable items.
An explainable item is an item that has a certain pro-
bability of possessing a semantic property (such as
having a certain starring actor) that seems to be pos-
sessed by many of the items liked by the target user
based on previous ratings. Here, θ
s
is a threshold for
items to be considered explainable. In this study, we
set θ
s
to 0 when building the model, meaning that all
items that have even a very small probability of being
starred by actors who seem to be liked by the target
user are considered explainable.
In this study, we focused on only the actors to il-
lustrate our approach using the most widely employed
public domain benchmark dataset which happens to
be about movies. However, our technique applies to
other properties, such as the director and writer which
will be tested in the future. In fact, other domains
have different properties and richer ontologies; howe-
ver, the currently used public benchmark data are li-
mited.
It is important to mention that the concept of ex-
plainability means explaining why a user would be
interested in a recommended item (in the case of the
example of the experimental data used in this paper,
the item is a movie), and we propose to do this based
on semantics underlying the item and domain while
using MF to build the recommendation model. The
idea of using a two-step MF approach to integrate
two domains is called Asymmetric MF. The reason
of choosing MF is because of its ability to handle big
data and because it is one of the most commonly used
and most powerful and versatile modeling methods
for recommendations (Koren et al., 2009). In addi-
tion, it is chosen because it is a black box technique
that lacks the power to explain its predictions.
In the next phase (model building), the model is
built by going through two steps. The first step is lear-
ning the initial model’s latent factors using the seman-
tic explainability graph that was defined in equation 3.
MF aims to perform the following factorization:
S
UI
UxI
' P
UxK
Q
T
IxK
(4)
Here, K is the number of features, I denotes the num-
ber of items (e.g., movie), and U is the number of
users. P
uxk
represents the user lower rank dimensi-
onal space, where Q
T
ixk
denotes the item lower rank
dimensional space.
The objective function to be minimized over the se-
mantic explainability graph is as follows:
J =
∑
u,i∈S
(S
UI
u,i
− p
u
q
T
i
)
2
+
β
2
(k p
u
k
2
+ k q
i
k
2
) (5)
where β is a coefficient for the regularization term and
S is the set of user-item with non-zero explainability
score S
UI
ui
> 0. Since J is convex with respect to either
p or q, stochastic gradient descent is used to update p
and q in an alternating manner. The gradient of J with
respect to p
u
is
∂J
∂p
u
= −2 (S
UI
u,i
− p
u
q
T
i
)q
i
+ βp
u
(6)
The gradient of J with respect to q
i
is
∂J
∂q
i
= −2(S
UI
u,i
− p
u
q
T
i
)p
u
+ βq
i
(7)
Thus, the update rules are given by
p
(t+1)
u
← p
(t)
u
+ α(2(S
UI
u,i
− p
(t)
u
(q
(t)
i
)
T
)q
(t)
i
− βp
(t)
u
)
(8)
q
(t+1)
i
← q
(t)
i
+ α(2(S
UI
u,i
− p
(t)
u
(q
(t)
i
)
T
)p
(t)
u
− βq
(t)
i
)
(9)
KDIR 2018 - 10th International Conference on Knowledge Discovery and Information Retrieval
270

In the second step of the model building phase, a
MF model is built using the known ratings, as follows:
R
UxI
' P
UxK
Q
T
IxK
(10)
where R
UxI
represents the ratings matrix. The ob-
jective function to be minimized over known ratings
is
J =
∑
u,i∈R
(R
u,i
− p
u
q
T
i
)
2
+
β
2
(k p
u
k
2
+ k q
i
k
2
) (11)
Where R is the set of user-rating pairs ui given ratings
in R. The update rules can be shown to be:
p
(t+1)
u
← p
(t)
u
+ α(2(R
u,i
− p
(t)
u
(q
(t)
i
)
T
)q
(t)
i
− βp
(t)
u
)
(12)
q
(t+1)
i
← q
(t)
i
+ α(2(R
u,i
− p
(t)
u
(q
(t)
i
)
T
)p
(t)
u
− βq
(t)
i
)
(13)
In this study, we use two sources of knowledge
to build the model: the explainability graph and the
known ratings. In the second step, weak explainabi-
lity scores will be taken over by the known ratings.
However, if the explainability score is high in the first
step, it will still be high in the second step and will
take over the known ratings. It is likely that the num-
ber of iterations of MF updates in the second step will
affect how likely the second domain (the ratings) will
be to take over the first domain (semantics of items).
In general, we can expect those users who show an
interest in items with a semantic property (movies
starring certain actors) to obtain better explainable re-
commendations using our proposed two-step model.
Our method is not foolproof; it strives to optimize
both explainability and predictive accuracy simulta-
neously, and hence, one of these criteria may weigh
more heavily in the final optimum.
4 EXPERIMENTAL EVALUATION
We use the MovieLens 100K dataset. Movies from
the MovieLens 100K and DBpedia
1
are first matched,
resulting in a reduction of the total number of ratings
to 60K. The ratings are normalized as follows:
R
ui
=
R
ui
− min
i
max
i
− min
i
(14)
where u and i are the user and item, respectively. The
hyper parameters are α = 0.01 and β = 0.1. They are
tuned to their optimal values using cross-validation.
The experiments are run 10 times, and the training
portion of the dataset is 90%; the latest 10 % is allo-
cated to the test set.
1
small DBpedia.org
Figure 2: The left three graphs show a comparison of the
MEP, MER, and xF-score between the methods using the
semantic explainability graph versus θ
s
. The three right
graphs show a comparison of the MEP, MER, and xF-score
between the methods using the neighborhood explainability
graph versus θ
n
.
We compared our model to three baseline approaches,
as follows: basic MF (Koren et al., 2009), Explaina-
ble MF (EMF) (Abdollahi and Nasraoui, 2016), and
basic Asymmetric MF (AMF) (Abdollahi and Nasra-
oui, 2014), which is a hybrid approach.
We first evaluate the prediction accuracy, and hence
the error rate using the Root Mean Square Error
(RMSE):
RMSE =
s
1
| T |
∑
(u,i)∈T
r
0
ui
− r
ui
2
(15)
where T represents the total number of predictions,
r
0
ui
is the predicted rating of item i by user u, and r
ui
is the real rating of item i by user u.
As illustrated in Table 1, we carried out a signi-
ficance test to compare the RMSE of our approach
with the baseline methods at K = 10. The p-value
= 4.49e-15 between ASEMF UIB and MF, 1.46e-13
between ASEMF UIB and EMF, 1.77e-21 between
ASEMF UIB and AMF. This indicates that our met-
hod significantly outperforms other methods.
Since our approach aims to recommend explaina-
ble items, we also evaluated all the approaches using
the explainability metrics MEP, MER, and xF-score
(Abdollahi and Nasraoui, 2016) to show how much
all the approaches recommend explainable items in
the top 10. MEP is the Mean Explainability Preci-
A Semantically Aware Explainable Recommender System using Asymmetric Matrix Factorization
271

Table 1: RMSE versus number of latent factors K.
ASEMF UIB denote our proposed method, namely Asym-
metric Semantic Explainable Matrix Factorization augmen-
ted with User-Item based semantic explainability graphs.
K MF EMF AMF ASEMF UIB
10 0.2221 0.2188 0.2386 0.2059
20 0.2503 0.2461 0.2756 0.2047
30 0.2866 0.2771 0.315 0.204
40 0.3283 0.3176 0.3508 0.2039
50 0.3844 0.3639 0.3833 0.2038
sion, the ratio of recommended and explainable items
to the total number of recommended items. MER is
the Mean Explainability Recall, the ratio of recom-
mended and explainable items to the total number of
explainable items. The xF-score is the harmonic mean
of MEP and MER. The definitions of MEP, MER, and
xF-score are (Abdollahi and Nasraoui, 2016):
MEP =
1
|U |
∑
u∈U
|R
rec
∩W |
|R|
(16)
MER =
1
|U |
∑
u∈U
|R
rec
∩W |
|W |
(17)
xF − score = 2 ∗
MEP ∗ MER
MEP + MER
(18)
Here, U represents the total number of users, R
rec
is the set of recommended items, and W denotes
the set of explainable items. In this type of evalua-
tion, we compared our method with the baseline met-
hods using MEP, MER, and xF-score, computed ba-
sed on two different explainability graphs. The first
graph is the semantic explainability graph S
UI
that
we constructed (see equation 3). The second graph
is the neighborhood explainability graph (Abdollahi
and Nasraoui, 2016), and it is defined as follows:
W
ui
=
(
|N
0
(u)|
|N
k
(u)|
i f
|N
0
(u)|
|N
k
(u)|
> θ
n
0 otherwise
(19)
where N
0
(u) is the set of neighbors of user u who ra-
ted item i, and N
k
(u) represents the list of k nearest
neighbors of u. θ
n
is a threshold for considering item
i as an explainable item to user u or not.
The results are shown in the three left line charts
in Figure 2 and they indicate that when comparing
all methods based on using the explainability metrics
that are computed based on the semantic explaina-
bility graph (see equation 3), the baseline methods
EMF and MF perform better using MEP and MER
metrics with θ
s
= 0. However, with increasing θ
s
,
which means putting more constraints on items for
them to be considered semantically explainable, our
proposed ASEMF UIB method outperforms all three
other methods, thus succeeding in producing more ex-
plainable items in the top 10 than the other methods
do. The xF-score shows that our proposed method is
the top performer.
We also compared all methods using the explaina-
bility metrics, based on the neighborhood explainabi-
lity graph (see equation 19). The three line charts on
the right in Figure 2 show that with θ
n
= 0 the base-
line method Asymmetric MF (AMF) (Abdollahi and
Nasraoui, 2014) is the best. This can be attributed to
the fact that this method updates only the users’ la-
tent space in the second step of building the model,
while leaving the items’ latent space fixed, resulting
in a bigger effect of neighbors in the recommendation
process. Nevertheless, with increasing θ
n
, our pro-
posed ASEMF UIB method performs better using all
three metrics, namely the MEP, MER, xF-score.
5 CONCLUSIONS
MF is a powerful CF technique for predicting ratings
for unseen items. However, it is unable to explain
its output. We addressed this limitation by using the
Semantic Web to provide a solution for increasing
the transparency of MF while preserving its accuracy.
The experimental results indicate that our proposed
method, which leverages SW in building an explai-
nable MF, outperformed the baseline approaches in
terms of error rate and explainability metrics, MEP,
MER, and xF-score, especially when placing more
constraints on items to be considered semantically ex-
plainable. In the future, we plan to expand our ex-
planations to richer semantics, and to perform more
comprehensive experiments, including hybrid recom-
mender baselines, and additional domains.
ACKNOWLEDGMENTS
This research was partially supported by KSEF Award
KSEF-3113-RDE017.
REFERENCES
Abdollahi, B. and Nasraoui, O. (2014). A cross-modal
warm-up solution for the cold-start problem in colla-
borative filtering recommender systems. In Procee-
dings of the 2014 ACM Conference on Web Science,
WebSci ’14, pages 257–258, New York, NY, USA.
ACM.
Abdollahi, B. and Nasraoui, O. (2016). Explainable ma-
trix factorization for collaborative filtering. In Pro-
KDIR 2018 - 10th International Conference on Knowledge Discovery and Information Retrieval
272

ceedings of the 25th International Conference Com-
panion on World Wide Web. ACM Press.
Achananuparp, P., Han, H., Nasraoui, O., and Johnson, R.
(2007). Semantically enhanced user modeling. In
Proceedings of the 2007 ACM symposium on Applied
computing, pages 1335–1339, Seoul, Korea. ACM.
BenAbdallah, J., Caicedo, J. C., Gonzalez, F. A., and Nas-
raoui, O. (2010). Multimodal image annotation using
non-negative matrix factorization. In Proceedings of
the 2010 IEEE/WIC/ACM International Conference
on Web Intelligence and Intelligent Agent Technology
- Volume 01, WI-IAT ’10, pages 128–135, Washing-
ton, DC, USA. IEEE Computer Society.
Berendt, B., Hotho, A., and Stumme, G. (2002). Towards
semantic web mining. In Proceedings of the First In-
ternational Semantic Web Conference on The Seman-
tic Web, ISWC ’02, pages 264–278, London, UK, UK.
Springer-Verlag.
Berendt, B., Hotho, A., and Stumme, G. (2005). Semantic
web mining and the representation, analysis, and evo-
lution of web space. In Proceedings of RAWS 2005
Workshop, pages 1–16.
Bilgic, M. and Mooney, R. J. (2005). Explaining recom-
mendations: Satisfaction vs. promotion. In Beyond
Personalization Workshop, IUI, volume 5, page 153.
Herlocker, J. L., Konstan, J. A., and Riedl, J. (2000). Ex-
plaining collaborative filtering recommendations. In
Proceedings of the 2000 ACM conference on Compu-
ter supported cooperative work, pages 241–250, Phi-
ladelphia, Pennsylvania, USA. ACM.
Koren, Y., Bell, R., and Volinsky, C. (2009). Matrix factori-
zation techniques for recommender systems. Compu-
ter, 42(8):30–37.
McCarthy, K., Reilly, J., McGinty, L., and Smyth, B.
(2004). Thinking positively-explanatory feedback for
conversational recommender systems. In Proceedings
of the European Conference on Case-Based Reaso-
ning (ECCBR-04) Explanation Workshop, pages 115–
124.
Miller, G. A. (1995). Wordnet: A lexical database for eng-
lish. Commun. ACM, 38(11):39–41.
Nasraoui, O., Soliman, M., Saka, E., Badia, A., and Ger-
main, R. (2008). A web usage mining framework for
mining evolving user profiles in dynamic web sites.
IEEE transactions on knowledge and data engineer-
ing, 20(2):202–215.
Stumme, G., Berendt, B., and Hotho, A. (2002). Usage
mining for and on the semantic web. In Proc. NSF
Workshop on Next Generation Data Mining, pages
77–86, Baltimore.
Stumme, G., Hotho, A., and Berendt, B. (2006). Semantic
web mining: State of the art and future directions. J.
Web Sem., 4(2):124–143.
Vig, J., Sen, S., and Riedl, J. (2009). Tagsplanations: Ex-
plaining recommendations using tags. In Proceedings
of the 14th International Conference on Intelligent
User Interfaces, IUI ’09, pages 47–56, New York, NY,
USA. ACM.
Zhang, Y., Lai, G., Zhang, M., Zhang, Y., Liu, Y., and Ma,
S. (2014). Explicit factor models for explainable re-
commendation based on phrase-level sentiment analy-
sis. In Proceedings of the 37th International ACM SI-
GIR Conference on Research & Development in
Information Retrieval, SIGIR ’14, pages 83–92, New
York, NY, USA. ACM.
A Semantically Aware Explainable Recommender System using Asymmetric Matrix Factorization
273
