
Coarse-to-Fine Clothing Image Generation with Progressively
Constructed Conditional GAN
Youngki Kwon
1
, Soomin Kim
1
, Donggeun Yoo
2
and Sung-Eui Yoon
1
1
School of Computing, KAIST, Daejeon, Republic of Korea
2
Lunit Inc, Seoul, Republic of Korea
Keywords:
Generative Adversarial Networks, Image Conditional Image Generation, Cloth Image Generation, Coarse-to-
Fine
Abstract:
Clothing image generation is a task of generating clothing product images from input fashion images of people
dressed. Results of existing GAN based methods often contain visual artifact with the global consistency issue.
To solve this issue, we split the difficult single image generation process into relatively easy multiple stages for
image generation process. We thus propose a coarse-to-fine strategy for the image-conditional image genera-
tion model, with a multi-stage network training method, called rough-to-detail training. We incrementally add
a decoder block for each stage that progressively configures an intermediate target image, to make the genera-
tor network appropriate for rough-to-detail training. With this coarse-to-fine process, our model can generate
from small size images with rough structures to large size images with details. To validate our model, we
perform various quantitative comparisons and human perception study on the LookBook dataset. Compared
to other conditional GAN methods, our model can create visually pleasing 256 ×256 clothing images, while
keeping the global structure and containing details of target images.
1 INTRODUCTION
When we see pictures of celebrities, we often want
to know what clothes he or she wears and where we
can buy those clothes. For this, we first need to per-
form the image search with pictures of celebrity as
queries. However, results might contain irrelevant
images, fundamentally because pictures of celebrities
and cloth product images belong to different dom-
ains. Generally, a picture of celebrities consists of
a clothing object, that we are looking for, and unne-
cessary regions such as background. A clothing pro-
duct image, however, contains only clothing objects
themselves. This semantic and visual gap between
two domains can be obstacles for searching intended
clothing product images. To avoid this, we utilize clo-
thing image generation.
In this paper, we define a clothing image gene-
ration as a task of creating clothing images (product
images) from any input images of people dressed.
The generated images must contain an apparel-like
object with details consistent with the input images.
The resulting images must be realistic and visually
plausible, as well (Figure 1).
Our problem of clothing image generating can be
approached in the perspective of image-conditional
image generation. In image-conditional image ge-
neration problem, the conditional Generative Ad-
versarial Network (GAN)have shown remarkable re-
sults (Pathak et al., 2016; Iizuka et al., 2017; Isola
et al., 2017; Lassner et al., 2017; Ledig et al., 2017;
Zhu et al., 2017). In practice, however, result ima-
ges generated by GAN often contain visual artifacts
with a global consistency issue, which means ob-
jects in an image can be structurally collapsed. It
can be worse in high-resolution images. To miti-
gate these artifacts, many studies have applied vari-
ous computer vision techniques to GAN. The coarse-
to-fine strategy is one of the classical approaches
in computer vision (Szeliski, 2010) for structured
prediction, and GAN with coarse-to-fine approaches
have shown acceptable results, even when generating
a high-resolution image (Zhang et al., 2016; Zhao
et al., 2017; Denton et al., 2015; Karras et al., 2017;
Mathieu et al., 2015). Unfortunately, previous studies
have used multiple pairs of generators and discrimi-
nators for stages in order to implement this strategy,
causing an excessive amount of network parameters.
Main Contributions. In this paper, we propose
a novel image-conditional image generation model,
rough-to-detail conditional GAN, for clothing image
generation. Our model is designed to utilize the
coarse-to-fine approach to produce visually pleasing
Kwon, Y., Kim, S., Yoo, D. and Yoon, S.
Coarse-to-Fine Clothing Image Generation with Progressively Constructed Conditional GAN.
DOI: 10.5220/0007306900830090
In Proceedings of the 14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2019), pages 83-90
ISBN: 978-989-758-354-4
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
83

(a)
(b)
Figure 1: Examples of clothing images generated by our model. (a) are fashion model images as input. (b) are product images
generated by our model conditioned on the input images (a).
clothing images in a high resolution. During network
training, our model progressively constructs a gene-
rator for a target image via adding decoder blocks se-
quentially (Section 3.3). In this way with only a sin-
gle pair of a generator and a discriminator, we can use
network parameters in a compact way, and thus allow
to use a large minibatch size during optimization for
accurate gradients, resulting in high-quality image ge-
neration (Salimans et al., 2016).
Compared to other conditional GAN models, re-
sult images generated by our model both look like re-
alistic and contain detailed apparel-like objects con-
sistent with the input images (Section 5.2). As a re-
sult, our result image achieves better performance in
quantitative evaluation with various metrics such as
RMSE, SSIM, and Recall@K (Section 5.1) as well as
human evaluation (Section 5.3).
2 RELATED WORKS
2.1 Image-conditional Image
Generation
In the field of image-conditional image generation,
conditional GAN based approaches have been domi-
nant. They show remarkable results for various appli-
cations: image inpainting (Pathak et al., 2016; Iizuka
et al., 2017), interactive image editing (Brock et al.,
2016), super-resolution imaging (Ledig et al., 2017),
domain-transfer (Kim et al., 2017b), and image-to-
image translation (Zhu et al., 2017; Isola et al., 2017).
(Isola et al., 2017) have proposed a general pur-
pose image-conditional image generation model cal-
led pix2pix, which supports the relatively high re-
solution result images (256 × 256) and has become
a widely-used model for this problem. (Yoo et al.,
2016) have proposed a clothing image generation mo-
del, which generates clothing images at 64 × 64 reso-
lution.
CycleGAN (Zhu et al., 2017) and Disco-
GAN (Kim et al., 2017b) conduct image-conditional
image generation with unpaired image datasets. Cy-
cleGAN supports up to 256 × 256 resolution images.
It works well when changing the style, while keeping
a shape of an object in an input, but it is difficult to
change shape itself. DiscoGAN is relatively easy to
change shape itself, unlike CycleGAN. However, it
supports a relatively low resolution (64 × 64).
In this paper, we propose a clothing image genera-
tion model based on pix2pix. Our method is designed
by adopting a coarse-to-fine strategy to cope with clo-
thing image generation where a large-shape change is
required.
2.2 Coarse-to-fine Strategy
Similar to ours, GAN approaches adopting the coarse-
to-fine strategy to generate detailed images have been
proposed. (Denton et al., 2015) have proposed a
multi-stage image generation process consisting of
several GANs. This iterative generation process can
produce sharper images. (Mathieu et al., 2015) have
proposed a multi-scale network to predict future video
frames with the similar approach. (Zhao et al., 2017)
have shown image-conditional image generation from
an input cloth image to a cloth image in a different-
view via two-stage image generation process.
(Karras et al., 2017) have proposed GAN trai-
ning method, called progressive growing. This met-
hod progressively adds a block on the generator and
discriminator to generate the target resolution image.
Based on this concept, it can generate high-resolution
face images from a noise vector. However, this ap-
proach produced images from a noise vector, so it
was not directly designed for image-conditional con-
straints like our clothing image generation problem.
Except for (Karras et al., 2017), aforementioned
VISAPP 2019 - 14th International Conference on Computer Vision Theory and Applications
84

studies require a multi-network configuration using
pairs of generators and discriminators for stages. As
a result, it causes a large model size. (Karras et al.,
2017) have implemented a coarse-to-fine approach
with a single pair of a generator and a discriminator,
but they are not designed for image-conditional con-
straints. So, they can not be applied to our problem
directly.
Instead of using multiple, separate pairs of genera-
tors and discriminators, our model progressively con-
figures the network to be appropriate for each stage.
Furthermore, we design our approach for respecting
image-conditional constraints.
3 Rough-to-Detail GAN
We propose a new image-conditional image genera-
tion model, named rough-to-detail GAN (rtdGAN).
The rtdGAN is a conditional GAN based image gene-
ration model that is trained in a coarse-to-fine man-
ner, in order to solve the global consistency pro-
blem (Goodfellow, 2016). This problem causes in-
consistent structures on generated images, especially
in high resolution. In this section, we introduce
the architecture of rough-to-detail GAN, objective
function, and rough-to-detail training.
3.1 Architecture Design
Our model is based on a conditional GAN, which con-
sists of a generator G = {G
E
, G
D
} and a discriminator
D. G consists of an encoder G
E
and a decoder G
D
,
where G
E
= {g
1
e
, . . . , g
M
e
}, G
D
= {g
1
d
, . . . , g
M
d
}, g
j
e
is
an j-th encoder block and g
j
d
is an j-th decoder block,
and M is the number of blocks in each encoder and
decoder.
The encoder maps an input image x to a latent vec-
tor. Each encoder block g
j
e
produces a down-sampled
feature map, which contains higher level information
as an output of its prior block g
j−1
e
. We use a general
stride-convolution block as the encoder block.
The decoder generates an image from the latent
vector. Each decoder block g
j
d
is designed to produce
an up-sampled and refined result with the result of
its prior block g
j−1
d
. Therefore, a number of decoder
blocks determines a size of an image generated by G.
We use a modified version of the residual block (He
et al., 2016) as the decoder block. The detailed infor-
mation of the residual block is provided in Figure 2b.
The entire structure of our G is similar to U-Net (Ron-
neberger et al., 2015), which can preserve contents of
the input image x via skip-connection between g
j
e
and
g
j
d
. The skip-connection is used for reducing the in-
formation loss caused by the bottleneck between the
encoder and the decoder.
We implement a coarse-to-fine strategy through
manipulating the structure of the decoder G
D
. Our
generator G can control the size of result image via
adding decoder blocks. Given N stages of our rough-
to-detail training, let G
i
to be a generator G at the
stage i. At stage i = 1, G
1
(the generator of the first
row in Figure 2a) generates a small image, aiming to
achieve the coarsest version of the target image via an
asymmetric encoder-decoder structure, where G
E
has
M encoder blocks and G
D
has only M −N +1 decoder
blocks. As we have more stages, we have additional
decoder blocks on the generator. In the end, at stage
i = N, G
N
(the generator of the last row in Figure 2a)
creates a larger image containing details of the target
image via the symmetric encoder-decoder structure,
where G
E
and G
D
have M blocks.
Note that we did not make our encoder structure
to grow during the training process. If the encoder
network grows, it also suggests that the input image
should start with a very small input image, indicating
that the information of the pixel area required for cre-
ating the clothes image in the input image can be lost
compared to a bigger size input. Therefore, there is
a possibility that the error created by this lost infor-
mation might spread through the network as the stage
progressed. To prevent this potential loss of pixel in-
formation, we freeze the encoder structure so that it
can deal with as large images as possible.
We utilize the patch discriminator D, which deter-
mines whether the local patch of an image is real or
not, while a general discriminator examines the entire
image. This approach is more beneficial for descri-
bing high-frequency details (Isola et al., 2017; Zhu
et al., 2017). The detailed architecture of each net-
work is summarized in the supplementary material.
3.2 Objective Function
Our objective function consists of three loss terms:
Adversarial loss, Content loss, and Laplacian loss.
The adversarial loss is used for generating realistic
images and content loss has beneficial to force low-
frequency correctness between the result image and
the target image (Isola et al., 2017). The Laplacian
loss is utilized to sharpen the result image.
The adversarial loss is used to generate an image
indistinguishable with a real image. The loss is the
same to the objective of the conditional GAN, which
is expressed as:
L
adv
(G
i
, D) = E
x
i
,y
i
[D(x
i
, y
i
)] − E
x,x
i
[D(x
i
, G
i
(x))],
(1)
Coarse-to-Fine Clothing Image Generation with Progressively Constructed Conditional GAN
85

...
Input Generator Input & Fake DiscriminatorStage
1
2
N
Target
Training progresses
Add a decoder block
Add a decoder block
Add a decoder block
!"
!
# $
!
" %
(a)
Element-wise
Addition
1 × 1 Conv
Upsample
1 × 1 Conv
Upsample
LReLU
BN
L
R
𝛼
𝑔
#
$
𝑔
#
$%&
⋅ = 𝐿 𝑔
#
$ %&
⋅ + 𝛼𝑅 𝑔
#
$%&
⋅
𝑔
#
$%&
(⋅)
Fade
-in 0 < 𝛼 < 1
Stabilize
𝛼 = 1
(b)
Figure 2: (a) shows overview of rough-to-detail training. At the first stage, the generator G
1
works with a target image y
1
,
which has the coarse-structure of the image. As the training goes on, we incrementally add a decoder block g
M−N+i
d
on the
decoder part of G
i
for generating larger images with finer details. (b) shows the structure of a decoder block. The flow of
a previous result, g
j−1
d
(·), is divided into two flows. The left-hand flow is used to resize and enhance previous results. The
right-hand flow is to generate details of the image. a is a weighted term introduced for stably using the newly added decoder
block. For the smooth fade-in, a increments from 0 to 1. After a fade-in, a is fixed to 1.
where y
i
is a target real image for the stage i, x is the
original input image, G
i
(x) is the fake image, x
i
is a
resized image of x whose size is same to y
i
.
The content loss is used for generating a near
ground-truth target image. The content loss is an L1
loss between a real image and a generated image, and
is defined as follows:
L
con
(G
i
) = E
x,y
i
[k y
i
− G
i
(x) k
1
].
(2)
We use a Laplacian loss to generate a sharper
image. The Laplacian loss is an L1 loss between the
Laplacian filtered real image and the generated image.
Note that the Laplacian filtered image has been wi-
dely used for applications related to high-frequency
information such as edge detection (Marr and Hild-
reth, 1980) and edge-preserving inpainting (Kim
et al., 2017a). The Laplacian loss is defined as the
following:
L
lap
(G
i
) = E
x,y
i
[k Lap(y
i
) − Lap(G
i
(x)) k
1
],
(3)
where Lap(·) is a Laplacian filtered image, which
is approximated with the difference of Gaussians
(DoG) (Szeliski, 2010) in our case.
Our final objective is then defined as follows:
G
∗
i
= argmin
G
i
max
D
λ
adv
L
adv
(G
i
, D)+
λ
con
L
con
(G
i
) + λ
lap
L
lap
(G
i
),
(4)
where λ
adv
, λ
con
, λ
lap
are parameters that balance
three loss terms.
3.3 Rough-to-Detail Training
To realize our goal, we use rough-to-detail network
training that performs a coarse-to-fine image gene-
ration through N stages. Through this training algo-
rithm, our model gradually creates multiple scales of
the target image from a coarse-scale to a fine-scale.
At a stage i, the model upsamples and refines the
result of the previous stage i − 1 to produce an inter-
mediate target image y
i
of the stage i. In this manner,
the network learns the overall structure of the target
image and then learns its details gradually. By re-
peating this process, our model finally generates the
target image y
N
. An overview of rough-to-detail is
shown in Figure 2a. We first explain how to generate
intermediate target images, followed by our learning
process at each stage.
Intermediate Target Images. The goal of a stage i
is to create representative structural characteristics at
its chosen scale from the original target image y. To
do this, we prepare an intermediate target image y
i
for
the stage i. For this purpose, we utilize the Gaussian
image pyramid representation.
Let the total pyramid level to be N and
the Gaussian image pyramid representation y
g
=
{y
0
g
, . . . , y
N−1
g
} given the H ×W original target image
y. Each level of pyramid y
i
g
is generated by a sequence
of the Gaussian blur and down-sample on y
i−1
g
. As a
result, the top of the pyramid is the smallest image
y
N−1
g
, which has size of
H
2
N−1
×
W
2
N−1
, and contains the
coarsest structure of the input image. The bottom of
VISAPP 2019 - 14th International Conference on Computer Vision Theory and Applications
86

the pyramid is the largest image y
0
g
, which has size of
H ×W and it is the original image y.
Learning Process at each Stage. Because the size of
a target image is different at every stage, we should
setup G
i
to generate a target image y
i
for the stage i.
As we mentioned in Section 3.1, the number of deco-
der blocks determines the size of an image generated
by G
i
. So, we setup G
i
via adding a block g
M−N+i
d
on
the decoder G
D
.
As shown in Figure 2a, in the first stage, our trai-
ning starts with an asymmetric encoder-decoder net-
work G
1
which consists of an encoder with M encoder
blocks and a decoder with M − N +1 decoder blocks.
In the last stage, our training works with the symme-
tric encoder-decoder network G
N
, which consists of
the encoder with M encoder blocks and an incremen-
tally modified decoder with M decoder blocks. Our
learning process for each stage progresses with a se-
quence of three steps: Preparation, Fade-in, and Sta-
bilization.
• Preparation is the process of setting up the net-
work to generate a target image y
i
for the stage i. We
set (N − i)-th level of the Gaussian pyramid represen-
tation y
N−i
g
as the intermediate target image y
i
. We
add a residual block g
M−N+i
d
to the decoder G
D
of the
generator G
i
for increasing the resolution.
• Fade-in and Stabilization are introduced for
stably updating network parameters. Fade-in is per-
formed for avoiding a sudden shock caused by a ne-
wly added decoder block g
M−N+i
d
on G
D
of G
i
. To
avoid such a problem, we use a weighting term α to
regulate the influence of the decoder block, which is
added for generating details of a result image. α in-
crements linearly from 0 to 1 per every epoch. After
the fade-in, the network is further trained for stabili-
zation.
4 EXPERIMENT SETTING
In this section, we explain various experiment settings
used for validating the effectiveness of our proposed
rtdGAN model. We compare the quality of result
images with two other methods: pix2pix(Isola et al.,
2017) and PLDT(Yoo et al., 2016). We trained PLDT
and pix2pix on the LookBook dataset using the source
codes released by authors. We follow the training pro-
tocols described in their papers.
Dataset. LookBook (Yoo et al., 2016) is a dataset
for the clothing image generation problem. It is made
up of pairs of images of people dressed and clothing
product images that they are wearing. LookBook in-
cludes a total of 9,732 top product images and 75,016
fashion model images; see Figure 3(a) and (f).
For training, we resize all images to 256 × 256.
We use ten percents of clothing images and its associ-
ated model images as the test split, and the remaining
images are used as the train split. In the test split, we
did data cleaning by removing redundant images that
are in both splits.
4.1 Implementation Details
A decoder block g
d
has two ad-hoc blocks: ToRGB
and Skip. The ToRGB block converts an intermedi-
ate generator result into an RGB image. We use this
ad-hoc block for every stage except the last stage N,
because the results of the generator in those stages
are not RGB images. The ToRGB block consists of
LeakyReLU (He et al., 2015) with 0.2 slope, 1 × 1
Convolution, and Tanh. Skip is for the channel re-
duction before the element-wise addition. Skip con-
sists of upsampling by a factor of 2 and 1 × 1 convo-
lution.
To generate result images (Figure 1), we use the
total stage number N as 3 given the input resolution
of 256 × 256; one can use more stages for higher re-
solutions. In fade-in, we train D and G
i
for 40 epochs.
In stabilization, we train D and G
i
for another 40 epo-
chs. All models are trained using the Adam optimi-
zer (Kingma and Adam, 2015), where initial learning
rate is 0.0002, momentum parameters β
1
is 0, and β
2
is 0.99. Mini-batch sizes of each stage are 60, 40, and
20 from the stage 1 to the stage 3, respectively. Also,
target resolutions from the stage 1 to 3 are 64, 128,
and 256.
We use the conditional version of the Wasserstein
loss (Arjovsky et al., 2017; Gulrajani et al., 2017) as
the adversarial loss. In our settings, the weight for
gradient penalty is 10 and the number of critic is 1.
All of balancing parameters (λ
adv
, λ
con
, λ
lap
) in Equa-
tion 4 is 1.
5 RESULTS
We use there different evaluation metrics to compare
tested methods. We also conduct user study for eva-
luating human perception on different results.
RMSE and SSIM. We measure a quantitative per-
formance via measuring the similarity between ge-
nerated images and its target ground-truth product
images. We use two well-known metrics: Root
Mean Square Error (RMSE) and Structural Similarity
(SSIM) (Wang et al., 2004).
Recall@K. If a generated image is similar to a tar-
get image, it should be easy to find the target image
Coarse-to-Fine Clothing Image Generation with Progressively Constructed Conditional GAN
87

Input Ours - 3 stage
256 X 256
Ours - 1 stage
256 X 256
Pix2Pix
256 X 256
PLDT
64 X 64
(a) (b) (c) (d) (e)
Ground-Truth
256 X 256
(f)
Figure 3: Examples of clothing image generation results. (a) Input fashion model images from the LookBook test split. (b)
Results by our model with three stages of rough-to-detail training. (c) Results by our model with only a single stage of rough-
to-detail training. (d) and (e) show results of other conditional GANs methods, Pix2Pix (Isola et al., 2017) and PLDT (Yoo
et al., 2016), respectively. (f) Ground truth target clothing images. Our results with three stages show well-constructed
structures with fine-details.
in image search when we use the generated image as
a query. Assuming this property, we perform image
search for evaluating our model. We use the query
image generated from a fashion model image to find
the corresponding ground-truth clothing image in the
test split. For measuring the quality of image search,
we use recall@k as metric. To perform image se-
arch, we extract image features via pre-trained den-
senet (Huang et al., 2017).
5.1 Quantitative Evaluation
A quantitative comparison is reported in Table 1. Our
model with three stages achieves better RMSE, SSIM,
and recall@60 results over the prior methods. Based
on these results, we can conclude that our model can
generate more similar images to target clothing ima-
ges than other models.
Examples of product image search are shown in
Figure 4. In the second and third rows, the ground-
truth target clothing images are located in the top-1
among retrieved results. This result is achieved by
the high similarity between our generated images and
their ground-truth images.
Table 1: RMSE, SSIM, and Recall@60 results of our model
with other conditional GAN methods of PLDT and Pix2Pix.
Method RMSE SSIM Recall@60
PLDT
(Yoo et al., 2016) 0.2921 0.4096 0.1787
Pix2Pix
(Isola et al., 2017) 0.3009 0.5570 0.1873
Ours
(3 stages) 0.2590 0.5967 0.3373
5.2 Qualitative Evaluation
We also conduct qualitative comparisons between
ours and other methods, which are shown in Figure 3.
PLDT (e) tends to generate blurry images, because
its target resolution is 64 × 64, while our model and
Pix2Pix (d) can generate 256 × 256 resolution ima-
ges. Pix2Pix (d) results do not have fine patterns nor
colors contained in the target image, even if they are
quite realistic.
We also test our method even with one stage,
which adopts the symmetric encoder and decoders for
the generator and thus does not contain our rough-to-
detail training that is guided by our intermediate tar-
get images. Our method with a single stage (c) can
generate clothing images with an appropriate pattern
VISAPP 2019 - 14th International Conference on Computer Vision Theory and Applications
88
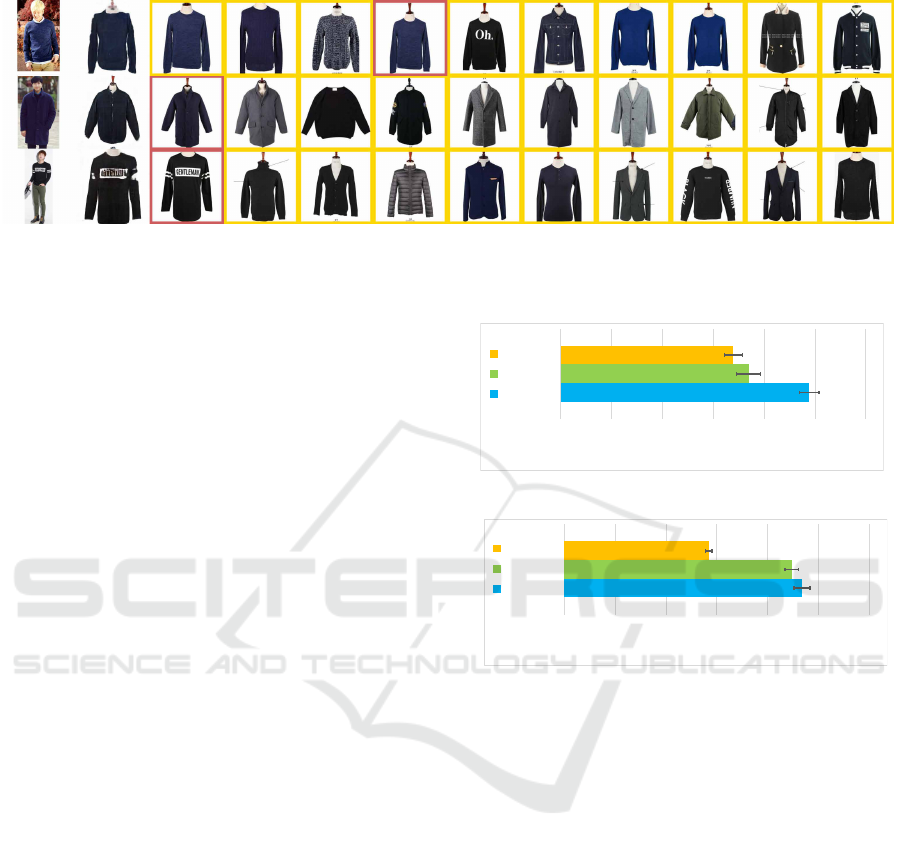
(a)
Input
(b)
Query
(c)
Top-10 Result
Figure 4: Examples of clothing product search results. (a) Input fashion model images from the LookBook test split. (b)
Generated clothing images by our model. (c) Top-10 image search result. Results in the red box indicate the ground-truth
clothing images.
and colors based on an input image. However, all of
these results contain blurry silhouette compared to in-
put images.
On the other hand, our method with three stages
(b) shows visually pleasing results, while producing
global structures with fine details. Furthermore, our
model can generate various type of clothing images.
In the last row of Figure 3, ours can generate a skirt
image, whereas two prior techniques (d) and (e) still
generate sweater-like clothing images.
5.3 Human Evaluation
Although RMSE, SSIM, and Recall@K measure si-
milarity between generated images and target images,
they cannot fully reflect the quality according to the
human perception. To complement this limitation of
the quantitative measures, we evaluate the quality of
result images through human perception, as well.
We randomly select 70 model images that are as-
sociated with different product images in the test split.
For each model image, three clothing images are ge-
nerated by ours with three stages, Pix2Pix, and PLDT.
All result images are evaluated in at its original size
without any resizing. Given model images and their
resulting images by different methods, 30 users are
asked to perform two tasks related to realism and si-
milarity aspects, as follows:
1. Realism: Rank result images in the order that they
look like real clothing images.
2. Similarity: Rank result images in the order that
they reflect details from input model images.
To compare results of different methods, we cal-
culate the average human rank computed by ranks gi-
ven by users. Figure 5 shows the 95% confidence in-
terval of the average human rank in each task. Our
model achieves the best average human rank on “Rea-
lism”, indicating that users thought that our results are
1.70
1.85
2.45
0.00 0.50 1.00 1.50 2.00 2.50 3.00
Average human rank
Ours
Pix2Pix
PLDT
(a) Realism rank
1.42
2.24
2.34
0.00 0.50 1.00 1.50 2.00 2.50 3.00
Average human rank
Ours
Pix2Pix
PLDT
(b) Similarity rank
Figure 5: Average human rank about image quality of ours
and other conditional GAN methods, Pix2Pix (Isola et al.,
2017) and PLDT (Yoo et al., 2016), with 95% confidence
intervals.
more realistic compared to other methods. Moreover,
Figure 5b also shows that our model also achieves the
best average human rank on “Similarity”, suggesting
that our model can generate clothing images that have
details from input model images, compared to other
methods.
6 CONCLUSION
In this paper, we have proposed rough-to-detail condi-
tional GAN (rtdGAN) for the clothing image genera-
tion problem. To solve the problem, we have split the
difficult single stage image generation process into a
relatively easy multi-stages image generation process.
We have applied the coarse-to-fine strategy on the
image-conditional image generation model and pro-
posed a new training method called rough-to-detail
Coarse-to-Fine Clothing Image Generation with Progressively Constructed Conditional GAN
89

training. We have also designed a generator network
that is suitable for the proposed training method. To
validate our proposed model, we have conducted ex-
tensive evaluations on the LookBook dataset. Compa-
red to other conditional GAN models, our model can
generate visually pleasing 256 × 256 clothing images
while keeping global structures and containing details
of target images.
ACKNOWLEDGEMENTS
We are thankful to the anonymous reviewers for
their comments. This work is supported by SW
StarLab program (IITP-2015-0-00199), and NRF
(NRF2017M3C4A7066317). Prof. Yoon is a corre-
sponding author of the paper.
REFERENCES
Arjovsky, M., Chintala, S., and Bottou, L. (2017). Was-
serstein gan. In International Conference on Machine
Learning (ICML).
Brock, A., Lim, T., Ritchie, J. M., and Weston, N. (2016).
Neural photo editing with introspective adversarial
networks. arXiv preprint arXiv:1609.07093.
Denton, E. L., Chintala, S., Fergus, R., et al. (2015). Deep
generative image models using a laplacian pyramid of
adversarial networks. In Advances in neural informa-
tion processing systems, pages 1486–1494.
Goodfellow, I. (2016). Nips 2016 tutorial: Generative ad-
versarial networks. arXiv preprint arXiv:1701.00160.
Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V., and
Courville, A. C. (2017). Improved training of wasser-
stein gans. In Advances in Neural Information Pro-
cessing Systems, pages 5767–5777.
He, K., Zhang, X., Ren, S., and Sun, J. (2015). Delving
deep into rectifiers: Surpassing human-level perfor-
mance on imagenet classification. In Proceedings of
the IEEE international conference on computer vi-
sion, pages 1026–1034.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep resi-
dual learning for image recognition. In Proceedings of
the IEEE conference on computer vision and pattern
recognition, pages 770–778.
Huang, G., Liu, Z., van der Maaten, L., and Weinber-
ger, K. Q. (2017). Densely connected convolutional
networks. In Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition, pages
4700–4708.
Iizuka, S., Simo-Serra, E., and Ishikawa, H. (2017). Glo-
bally and locally consistent image completion. ACM
Transactions on Graphics (TOG), 36(4):107.
Isola, P., Zhu, J.-Y., Zhou, T., and Efros, A. A. (2017).
Image-to-image translation with conditional adversa-
rial networks. In The IEEE Conference on Computer
Vision and Pattern Recognition (CVPR).
Karras, T., Aila, T., Laine, S., and Lehtinen, J. (2017). Pro-
gressive growing of gans for improved quality, stabi-
lity, and variation. In International Conference on Le-
arning Representations (ICLR).
Kim, S., Kim, T., Kim, M. H., and Yoon, S.-E. (2017a).
Image completion with intrinsic reflectance guidance.
In Proc. British Machine Vision Conference (BMVC
2017).
Kim, T., Cha, M., Kim, H., Lee, J. K., and Kim, J. (2017b).
Learning to discover cross-domain relations with ge-
nerative adversarial networks. In ICML.
Kingma, D. and Adam, J. B. (2015). Adam: A method for
stochastic optimization. In International Conference
on Learning Representations (ICLR).
Lassner, C., Pons-Moll, G., and Gehler, P. V. (2017). A
generative model of people in clothing. In The IEEE
International Conference on Computer Vision (ICCV).
Ledig, C., Theis, L., Husz
´
ar, F., Caballero, J., Cunning-
ham, A., Acosta, A., Aitken, A. P., Tejani, A., Totz, J.,
Wang, Z., et al. (2017). Photo-realistic single image
super-resolution using a generative adversarial net-
work. In The IEEE Conference on Computer Vision
and Pattern Recognition (CVPR), pages 4681–4690.
Marr, D. and Hildreth, E. (1980). Theory of edge detection.
Proc. R. Soc. Lond. B, 207(1167):187–217.
Mathieu, M., Couprie, C., and LeCun, Y. (2015). Deep
multi-scale video prediction beyond mean square er-
ror. arXiv preprint arXiv:1511.05440.
Pathak, D., Krahenbuhl, P., Donahue, J., Darrell, T., and
Efros, A. A. (2016). Context encoders: Feature lear-
ning by inpainting. In The IEEE Conference on Com-
puter Vision and Pattern Recognition (CVPR).
Ronneberger, O., Fischer, P., and Brox, T. (2015). U-
net: Convolutional networks for biomedical image
segmentation. In International Conference on Medi-
cal Image Computing and Computer-Assisted Inter-
vention, pages 234–241. Springer.
Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V.,
Radford, A., and Chen, X. (2016). Improved techni-
ques for training gans. In Advances in Neural Infor-
mation Processing Systems, pages 2234–2242.
Szeliski, R. (2010). Computer vision: algorithms and ap-
plications. Springer Science & Business Media.
Wang, Z., Bovik, A. C., Sheikh, H. R., and Simoncelli, E. P.
(2004). Image quality assessment: from error visi-
bility to structural similarity. IEEE transactions on
image processing, 13(4):600–612.
Yoo, D., Kim, N., Park, S., Paek, A. S., and Kweon, I. S.
(2016). Pixel-level domain transfer. In European Con-
ference on Computer Vision, pages 517–532. Springer.
Zhang, H., Xu, T., Li, H., Zhang, S., Huang, X., Wang,
X., and Metaxas, D. (2016). Stackgan: Text to photo-
realistic image synthesis with stacked generative ad-
versarial networks. arXiv preprint arXiv:1612.03242.
Zhao, B., Wu, X., Cheng, Z.-Q., Liu, H., Jie, Z., and Feng,
J. (2017). Multi-view image generation from a single-
view. arXiv preprint arXiv:1704.04886.
Zhu, J.-Y., Park, T., Isola, P., and Efros, A. A. (2017).
Unpaired image-to-image translation using cycle-
consistent adversarial networks. In The IEEE Inter-
national Conference on Computer Vision (ICCV).
VISAPP 2019 - 14th International Conference on Computer Vision Theory and Applications
90
