
Grapheme Approach to Recognizing Letters based on Medial
Representation
Anna Lipkina and Leonid Mestetskiy
Faculty of Computational Mathematics and Cybernetics, Lomonosov Moscow State University,
Leninskiye Gory 1-52, Moscow, Russia
Keywords:
Digital Text Image, Digital Font, Grapheme, Medial Representation, Aggregated Skeleton Graph.
Abstract:
In this paper we propose a new concept of mathematical model of characters’ grapheme which nowadays is
not strictly formalized and a method of constructing graphemes based on the continuous medial representation
of letters in digital images. We also suggest the recognition method of the printed text image on the basis
of mathematical model of the grapheme used at generation of features and for classifier construction. The
results of experiments confirming the efficiency of the grapheme approach, high quality of text recognition in
different font variants and in different qualities of the text image are presented.
1 MOTIVATION
The concept of grapheme (Osetrova, 2006) is funda-
mental in writing and in reading. A literate person
recognizes letters written or printed in different fonts,
on paper or stone, on walls and on clothing. The ba-
sis of recognition is the schematic images of letters,
which are called graphemes. The grapheme is the
most general scheme of the alphabet symbol, and any
literate person, even a child, can draw it. The school
teaches reading and writing based on graphemes. Ho-
wever, text recognition software does not use this con-
cept explicitly. Graphemes are used by philologists
in their theoretical constructions, as well as designers
when creating computer fonts. Both those and others
do without the strict definition of the concept of grap-
heme. If you try to create algorithms for recognizing
the characters of the alphabet based on graphemes,
then you need to more strictly define this concept and
the ways of its description and construction.
In this article we make such an attempt. We want
to define the schematic descriptions of the characters
of the alphabet so that they can be obtained from any
font, and so that the letters can be recognized in all ot-
her fonts. To solve this problem, we propose a method
of obtaining graphemes in the form of graphs from
digital images of letters of a font and a method of re-
cognizing characters of other fonts based on a compa-
rison with graphemes. The main hypothesis is that to
build a universal set of graphemes a single type font
is enough, and the remaining fonts can be recognized
by this set. Thus, the purpose of the study is to imple-
ment and test the grapheme approach for recognizing
letters.
2 INTRODUCTION
When a literate person reads the text, he can immedi-
ately determine by the form of the symbol what let-
ter this symbol depicts. He can do it regardless of
the different variants of the artistic style of the sym-
bol (with serif, italic, straight, decorative, etc. (Para-
Type, 2008)). That is, there is exists an ”image” of
the letter, which can be easily recognized by a human
and easily distinguished from such ”images” of other
letters. This ”image” is called grapheme (Osetrova,
2006).
Definition 2.1. Letter — a single character of the al-
phabet.
In the process of development of writing and
cursive writing (Solomonik, 2017)(Zaliznyak, 2002)
there are appeared multiple font styles: lowercase and
capital writing, and later — different spellings of the
same letter. Often these spellings can be quite dif-
ferent, although they denote the pronunciation of the
same sound, for example: A and a. To describe these
differences, the concept of grapheme is introduced:
Definition 2.2. Grapheme — writing unit, some
graphical primitive that has the form of a geometric
graph and depicts the canonical notation of a letter.
Lipkina, A. and Mestetskiy, L.
Grapheme Approach to Recognizing Letters based on Medial Representation.
DOI: 10.5220/0007366603510358
In Proceedings of the 14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2019), pages 351-358
ISBN: 978-989-758-354-4
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
351

Grapheme can be represented as images of letters
in a thin font, for example, as in Fig. 1.
Figure 1: Images of Cyrillic letters in Lato font and vertices
of geometric graphs.
Graphemes must have the following properties:
1. Any two graphemes are well distinguishable.
2. Let images I
1
and I
2
represent the same grapheme.
Then the difference between I
1
and I
2
is insigni-
ficant. Thus, similarity is determined by some si-
milarity measure between I
1
and I
2
.
The concept of graphemes is introduced by desig-
ners and type designers in the verbal form, using the
”general” design of the shapes of letters. That is, there
is no formal definition of a grapheme. This paper
proposes a mathematical description of this ”general”
construction (grapheme) and tests the hypothesis that
such a description is sufficient to recognize letters in
many different fonts.
3 THE STRUCTURE OF THE
ALGORITHM OF LETTERS’
CLASSIFICATION
The algorithm actually consists of two parts:
1. Construction of a mathematical model of a grap-
heme.
2. Development of an algorithm based on the con-
structed model that recognizes the letter in the
image.
The idea of constructing a mathematical model of
a grapheme is to construct a skeleton graph of a binary
image of a letter and remove some edges from it.
The conceptual approach to the recognition algo-
rithm is as follows: a skeleton of a binary image of
a letter is built, in this graph a subgraph is searched
in some way, equivalent to the standard mathematical
description of the grapheme as it is similar.
We define several basic concepts.
Definition 3.1. Figure — set of points on the plane.
Definition 3.2. Empty circle of the figure — circle
lying entirely in the figure.
Definition 3.3. Inscribed empty circle of the figure —
empty circle that are not contained in no other empty
circle of the figure.
Definition 3.4. Skeletal representation of the figure
— set of centers of all inscribed empty circles of the
figure (see Fig. 2).
Figure 2: Skeletal representation of the figure.
In fact, the skeletal representation of a figure is a
graph S, called skeleton (skeleton graph) of the figure.
The vertices of the graph are the centers of the inscri-
bed empty circles having either one or three common
points with the boundary of the figure, and the edges
are the lines from the centers of the inscribed empty
circles touching the boundary at exactly 2 points. The
skeletal representation of a figure is discussed in more
detail in (Mestetskiy, 2009).
Definition 3.5. Silhouette of a skeleton graph — a
figure consisting of the union of all inscribed empty
circles whose centers lie in the skeleton graph S . De-
signation: V
S
.
Definition 3.6. Clipping of a skeleton graph (with
a parameter α) — the process of regularization of
a skeleton graph S based on the removal of non-
essential edges from the skeleton graph (see Fig. 3).
In the process of such removal, a minimal subgraph
S
0
of the original skeleton graph arises, for which
H(V
S
, V
S
0
) 6 α is executed, where H(V
S
, V
S
0
) —
Hausdorff distance (Hausdorff, 1965) between the sil-
houette of the skeleton graph S and the silhouette of
the skeleton graph S
0
.
Figure 3: Example of a skeleton without a clipping (left)
and with a clipping (right).
4 BUILDING A MATHEMATICAL
MODEL OF A GRAPHEME
To build a mathematical model of the grapheme it is
proposed to make two steps:
1. Segmentation of text images into images of indi-
vidual characters (graphemes).
2. Selection of the structural description (mathema-
tical model) of the image of each grapheme.
VISAPP 2019 - 14th International Conference on Computer Vision Theory and Applications
352

The second step is divided into the following
steps: obtaining a skeletal graph of image letter; ag-
gregation of a skeleton graph and processing of a ske-
letal graph, namely the removal of noise edges.
4.1 Obtaining a Skeleton Graph
The construction of a skeleton figure graph is descri-
bed in detail in (Mestetskiy, 2009) and contains the
following basic steps:
1. Approximation of the original figure F by a poly-
gon of minimal perimeter M.
2. The construction of the Voronoi diagram of (Me-
stetskiy, 2009) for the vertices and the sides of the
polygon M.
3. The removal of some of the segments of the Voro-
noi diagram.
4. The rectilinear approximation of the parabolic ed-
ges of the Voronoi diagram.
After constructing the skeleton graph, its subse-
quent clipping with the parameter α is performed. It
is made in order to highlight the main elements of the
skeleton graph, independent of minor changes in the
boundaries of the symbol image.
4.2 The Aggregation of the Skeleton
Graph
The resulting skeleton graph contains only the follo-
wing types of vertices: vertices of degree 1 (leaves),
vertices of degree 2, vertices of degree 3 (forks).
The main information about the skeletal graph are
leaves and forks, as well as types of connections be-
tween them. To select these connections, the aggre-
gation operation of the skeleton graph is performed:
”gluing” into one chain of all such consecutive edges
whose incident vertices have degree either 1 or 2. Af-
ter such ”glue” only leaves and forks are left (see Fig.
4).
Figure 4: An example of an aggregated skeleton graph.
White color marks the vertices of degree 2 of the original
graph.
After aggregation, the skeleton graph become a
hypergraph S
agg,1
whose vertices are leaves and forks,
and whose edges are selected chains.
4.3 Designations and Concepts
1. The input binary image of the symbol is conside-
red. B — minimum square rectangular frame with
horizontal and vertical sides, limiting the given
symbol. B
H
and B
W
— frame height and width
B respectively.
2. Let e — non-aggregated edge of skeletal graph S.
v
1
(e), v
2
(e) — end vertices of this edge without
taking into account any order.
3. l(e) — length of edge e. It is calculated through
the Euclidean distance between two points v
1
(e)
and v
2
(e):
l(e) =
q
v
1
(e)
x
− v
2
(e)
x
2
+
v
1
(e)
y
− v
2
(e)
y
2
.
4. For an edge (chain) e
agg
hypergraph S
agg
through
v
1
(e), v
2
(e) the end vertices of this chain are de-
noted.
5. The edge e
agg
of the designated hypergraph S
agg
consists of n consecutive edges of the origi-
nal graph S that connected into this chain e
agg
:
{e
1
agg
, e
2
agg
, . . . , e
n
agg
}.
6. l(e
agg
) — length of chain e
agg
. It is calculated as
the sum of the lengths of all edges included in this
chain:
l(e
agg
) =
n
∑
i=1
l(e
i
agg
).
7. deg v — degree of vertex v.
Definition 4.1. Let d = [v
1
(e
ag
), v
2
(e
agg
)] be given.
Among all vertices of the chain e
agg
exists the vertex
v
h
that the most distant from the segment d. On three
points v
1
(e
g
), v
2
(e
g
), v
h
a circle can be formed. Then
approximating arc is the arc of the smallest length
bounded by points v
1
(e
g
), v
2
(e
g
) (see Fig. 5).
Definition 4.2. Angle of the curvature of the chain —
the central angle of its approximating arc.
Comment. In the case where three points
v
1
(e
agg
), v
2
(e
agg
), v
h
lie on the same line or when
there are no vertices in the e
agg
chain, the curvature
angle of the chain is assumed to be 0.
Figure 5: Example of approximating chain
[a, C, D, E, F, G, B] arc L and central angle BOA
Grapheme Approach to Recognizing Letters based on Medial Representation
353

4.4 Removal of Noisy Edges
After regularization and aggregation of the skeleton
graph, in S
agg,1
noise edges may still be contained.
This is evident in the letters depicted in serif fonts
(ParaType, 2008).
Serif is a kind of decoration for the letter, and their
presence or absence does not prevent a person to re-
cognize which letter is depicted. Thus, in the grap-
heme model, the serif letters should not be included.
Therefore the next step in constructing a mathemati-
cal model of a grapheme is removing edges that are
serifs from S
agg,1
(see Fig. 6). Let E
S
be the set of
edges of a hypergraph S
agg,1
that are serifs.
(a) (b) (c)
Figure 6: 6a: the skeleton of the letter in a serif font; 6b:
the same skeleton with the removed edges from E
S
; 6c: the
skeleton of letter in sans serif.
For the set E
S
the following features can be dis-
tinguished:
1. |E
S
| > 2, that is, if the notches in the skeletal
graph are present, their amount is not less than
two.
2. ∀ e
agg
∈ E
S
the following features are typical:
— exactly one of the vertices {v
1
(e
agg
), v
2
(e
agg
)}
is leaf, and exactly one of them is a fork;
— the length of edge l(e
agg
) does not exceed some
threshold L(B);
— the central angle 2 beta of approximating e
agg
arc is not less than some threshold A.
The algorithm for removing noisy edges from
S
agg,1
:
1. Determination of the set E
S
based on its features.
2. Removing all edges from E
S
from the aggregated
skeleton graph S
agg,1
.
Since vertices of degree 2 may occur after remo-
val, the aggregation of the skeleton is necessary to be
made again.
The hypergraph obtained after edge removal and
re-aggregation is denoted by S
agg,2
. It is the proposed
mathematical model of the grapheme.
5 GRAPHEME RECOGNITION
At this stage from S
age,2
features will be allocated for
the subsequent construction of the classifier graphe-
mes.
5.1 Feature Generation
In this method it is proposed to allocate 2 types of
descriptions: top-level features F
a
and bottom-level
features F
d
. They have the following properties:
— If from hypergraphs S
0
agg,2
, S
00
agg,2
identical top-
level features F
0
a
= F
00
a
are allocated, the bottom-
level features F
0
d
and F
00
d
lie in one feature space.
— If from hypergraphs S
0
agg,2
, S
00
agg,2
different top-
level features F
0
a
6= F
00
a
are allocated, then the
bottom-level features F
0
d
and F
00
d
lie in different
feature spaces.
5.2 Top-level Features
The idea of constructing top-level features is based on
the analysis of the vertex position in the hypergraph
S
agg,2
.
The frame B in which the grapheme is enclosed
is divided into n equal parts by horizontal lines and m
equal parts by vertical lines.
In each of the resulting n · m rectangles the num-
ber of leaves and the number of forks are counted, and
these numbers are added to the top-level feature des-
cription. In addition as a part of top-level feature the
number of connected components of the grapheme is
considered (see Fig. 7).
(a)
1 0 1
0 0 0
1 0 1
(b)
0 0 0
1 1 0
0 0 0
(c)
Figure 7: 7a: skeleton S
agg,2
of letter ”K” and splitting the
frame into 9 rectangles
(n = m = 3); 7b: number of leaves in each rectangle; 7c:
number of forks in each rectangle.
VISAPP 2019 - 14th International Conference on Computer Vision Theory and Applications
354

5.3 Bottom-level Features
We consider that the feature description of the top-
level F
a
is fixed. It means that the structure of the
hypergraph S
agg,2
is actually fixed: for each of the
n · m partition rectangles, the number of leaves and
forks that fall into it is known, and the number of ed-
ges of the hypergraph associated with each partition
rectangle is also known. Thus, it is now possible to
generate a fixed number of features for each of the
n · m rectangles. The rectangles themselves are or-
dered from left to right and from top to bottom for
certainty of the feature space.
Feature description of the lower level F
d
is propo-
sed to generate from the edge structure S
agg,2
.
5.4 Generating Features from an Edge
Let [A, B] be an edge of hypergraph S
agg,2
. The mask
of splitting this edge into k parts is fixed:
Z
k
= [z
1
, z
2
, . . . , z
k
], z
j
∈ (0, 1) ∀ j = 1, k.
The starting vertex is fixed (without limiting the gene-
rality we assume that it is A). We apply the partition
Z
k
to the edge [A, B] starting from the vertex A as fol-
lows: the edge [A, B] is divided by k points, counting
from the point A, by k + 1 segments s
i
so that:
j
∑
i=1
l(s
i
) = z
j
l([A, B]) ∀ j = 1, k.
Let the ends of segments s
i
have coordinates C
i−1
, C
i
:
s
i
= [C
i−1
, C
i
] ∀i = 1, k + 1.
Note that C
0
= A and C
k+1
= B. Also mark that
−→
b =
−−→
AC
1
.
It is proposed to highlight the following bottom-
level features:
1. Vectors
−→
AC
i
, i = 1, k + 1 are considered. Let m
i
=
||
−→
AC
i
||
2
, i = 1, k + 1. These vectors are normali-
zed to their lengths:
−→
c
i
=
−→
AC
i
m
i
, i = 1, k + 1.
As features, the coordinates of the resulting vec-
tors
−→
c
i
, i = 1, k + 1 are taken sequentially (by i).
2. Let
−→
g = (1, 0). The following oriented angles are
added sequentially (by i) as features:
∠(
−→
g ,
−→
AC
i
), i = 1, k + 1.
3. The following oriented angles:
∠(
−−−→
C
i
C
i−1
,
−−−→
C
i
C
i+1
), i = 1, k.
4. The ratio of the lengths of adjacent vectors:
m
i
m
i−1
, i = 2, k + 1.
Thus, for each edge e its bottom-level features
description f
e
consists of 5k + 3 elements.
5.5 Generating Features for a Single
Rectangle
Let R be the current considered rectangular area in
partition of box B. For reasons of ordering the fea-
tures, the hypergraph vertex S
agg,2
, caught in R , are
sorted by polar angle (in the case of equality of po-
lar angles — in length relative to the lower left corner
R ). We denote the characteristic description of the
domain R by f
R
.
First, consider all the leaves, then all the forks. In
all cases, the starting vertex will be the current vertex
in question
1. v is a leaf. Then features f
e
are generated for the
corresponding edge e, and they are added to the
final feature description f
R
.
2. v is a fork. Consider the corresponding three out-
going edges of the vector
−→
b
1
,
−→
b
2
,
−→
b
3
. The outgoing
edges are sorted in ascending order of the oriented
angles ∠(
−→
b
i
,
−→
g ), i = 1, 2, 3, then for them featu-
res f
e
are generated. The resulting features are
added in the sorting order of the edges to the final
feature description f
R
.
5.6 Feature Generation for Grapheme
Bottom-level features F
d
for a grapheme are obtained
by combining the features f
R
in the order of ordering
rectangular areas R .
5.7 Classifier Training
Now, within each attribute of the top-level feature F
a
,
it is possible to train its classifier — each on its own
feature space corresponding to its feature space of the
bottom-level F
d
.
At the training stage, a labeled training dataset
(X
tr
, Y
tr
) is taken, where x ∈ X
tr
— binarized sym-
bol image, y ∈ Y
tr
— corresponding image class.
The learning algorithm consists of the following
steps:
1. For the entire training dataset (X
tr
, Y
tr
) select the
top-level features and use them to construct a clas-
sification dictionary D.
Grapheme Approach to Recognizing Letters based on Medial Representation
355
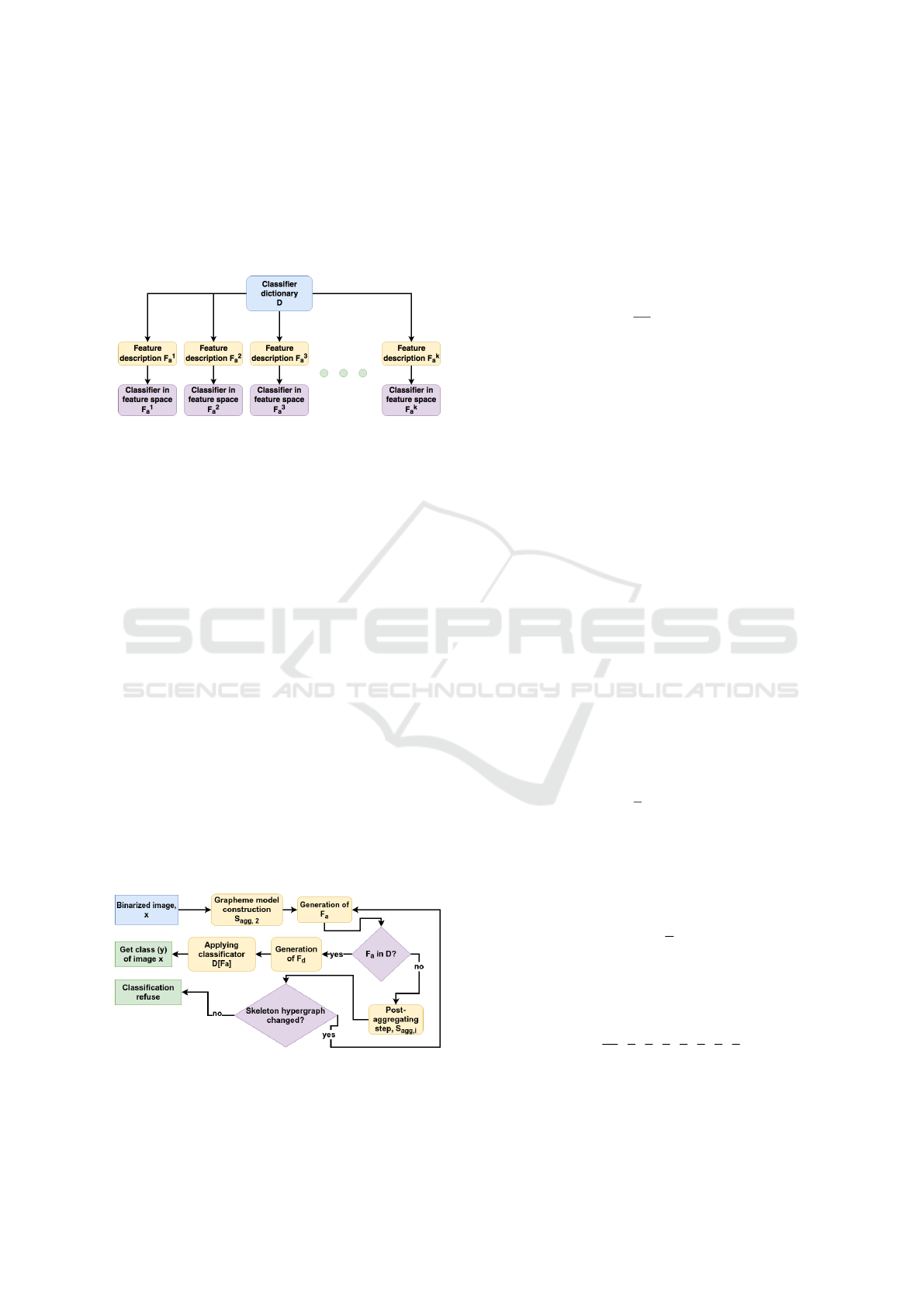
2. For each unique top-level feature F
a
, select the
objects that have this feature F
a
. For each of these
objects construct a bottom-level feature F
d
. As
the result a new subsample of objects from the F
d
feature space is selected, with which the classifier
is trained (see Fig. 8).
Figure 8: Classification dictionary D structure.
5.8 Classification Algorithm
Let we have a new object x (binary image of a single
character), and it must be classified. To classify it, the
following steps are needed:
1. The selection of a mathematical model of grap-
heme S
agg,2
from x.
2. Building top-level features F
a
from S
agg,2
.
3. Check if F
a
in the classification dictionary D, that
is obtained at the training stage. If the feature is
not present, the operation of postprocessing of the
skeleton graph is performed. If it is present then
skip to the next step.
4. The construction of bottom-level feature F
d
, the
application to it of the corresponding trained clas-
sifier and receiving a response.
The idea of post-processing is as follows: conti-
nuation of the search of the subgraph, which may be
classified according to the trained classification dicti-
onary D. If such a graph was not found, the classifi-
cation rejection will be returned
The final algorithm can be seen in Fig. 9.
Figure 9: Binarized image classification algorithm.
5.9 Quality Metric
Classification accuracy is used as a quality metric.
Let a be a classification algorithm, (X
te
, Y
te
) —
test sample, |X
te
| = n
te
, X
i
te
— i-th test sample object,
Y
i
te
— its true class. Then the classification accuracy
is calculated from the test sample according to the fol-
lowing formula:
Q(a, (X
te
, Y
te
)) =
1
n
te
n
te
∑
i=1
I[Y
i
te
= a(X
i
te
)].
6 COMPUTATIONAL
EXPERIMENTS
6.1 Training Dataset
For constructing a training dataset 88 different fonts
were selected, 33 letters of the Russian alphabet in lo-
wercase and uppercase versions (that is, only 66 grap-
hemes) in three font sizes were generated from each:
30, 50, 100 pixels. Image generation was performed
without smoothing, that is, immediately in binary for-
mat. The training sample size (X
tr
, Y
tr
) is n
tr
= 17424
binarized letter images. As a true class Y
i
tr
for the ob-
ject X
i
tr
of the training dataset the letter in lowercase
was taken.
6.2 Parameters of the Proposed
Algorithm
1. Parameter of clipping is α = 0.06 · B
H
.
2. Threshold for trimming by length:
L(B) =
2
7
max(B
H
, B
W
).
3. The trimming threshold for length at the post-
processing stage increases in 1.8 times:
L
0
(B) = 1.8 · L(B) (κ = 1.8).
4. The trimming threshold for angle:
A =
π
5
.
5. At the stage of extraction of top-level features n =
m = 3 is supposed.
6. The fixed grid is assumed to be equal to:
Z
8
=
1
50
,
1
5
,
1
3
,
2
5
,
1
2
,
3
5
,
2
3
,
4
5
.
7. As classifiers at bottom-level is considered
Random forest (Ho, 1995).
VISAPP 2019 - 14th International Conference on Computer Vision Theory and Applications
356

6.3 Basic Algorithm
As the base algorithm (baseline) has been selected
convolutional neural network (CNN) (LeCun et al.,
1998)(Bishop, 2006), the architecture of which is
shown in Fig. 10:
Figure 10: Neural network architecture.
Decoding of designations:
• k × k Conv f — convolution layer with kernel of
size k × k and f output filters (channels);
• k ×k MaxPooling — max-pooling layer with ker-
nel of size k × k;
• ReLU — ReLU layer (Glorot et al., 2011), (Jarrett
et al., 2009);
• Global Average Pooling — global average-
pooling layer (Lin et al., 2013);
• FC (Fully Connected) m — a fully connected
layer with an output layer of m neurons (Bishop,
2006).
For reasons of solving the classification pro-
blem over the output layer (x
1
, x
2
, . . . , x
33
), softmax-
activation is performed from 33 neurons:
y
j
= softmax(x
j
) =
e
x
j
33
∑
j=1
e
x
j
, j = 1, 33.
Let C be a number of classes in the classification
problem. Cross-entropy is taken here as the optimized
loss function.
L(y
i
, ˆy
i
) = −
C
∑
j=1
y
j
i
log ˆy
j
i
L(Y
tr
, ˆy) =
1
n
tr
n
tr
∑
i=1
L(y
i
, ˆy
i
),
where ˆy
i
∈ [0, 1]
C
— prediction of the network on
i-th object, ˆy — prediction of the network on the entire
training dataset, y
i
— vector describing the observed
value: y
i
∈ [0, 1]
C
,
∑
C
j=1
y
j
i
= 1 and if i-th object has
class j (i.e. Y
i
tr
= j) then y
j
i
= 1.
Remark. Since the input images can be of different
sizes, at the training stage the data in the neural net-
work was supplied by a batch consisting of 1 image.
6.4 Experiment 1
As a test dataset, the same 88 fonts that were used
in the training were taken, but a different font size,
which is 80 pixels. So n
te
= 5800. Images of letters
are generated using the program, that is, high-quality
images, without noise and binarized. The results of
two methods (structural analysis (SA) is the recogni-
tion method described in the article) are presented in
the table 1:
Table 1: The results of the two methods.
SA CNN
Quality, Q 0.99689 0.99862
Refusal rate 0.00086 0
6.5 Experiment 2
The test dataset consists of 50 fonts that were not used
when learning (FontsDatabase, 2018). The font size is
80 pixels, n
te
= 3300. Images of letters are generated
using the program. The results are presented in the
table 2:
Table 2: The results of the two methods.
SA CNN
Quality, Q 0.97 0.96515
Refusal rate 0.01364 0
6.6 Experiment 3
The test dataset consists of the same 50 fonts as in the
previous 6.5 experiment, and the same size. First, the
document is generated (.doc) with all the letters from
the test sample, then this document is converted into a
.png image with a resolution of 300 dpi. The images
from the RGB color representation were converted to
gray tones Y by the formula:
Y = 0.299R + 0.587G + 0.114B.
The images were then binarized using the Otsu
method (Otsu, 1979).
The results are presented in the table 3:
Table 3: The results of the two methods.
SA CNN
Quality, Q 0.94818 0.94454
Refusal rate 0.01485 0
6.7 Experiment 4
In this experiment, 18 sampled fonts from 50 fonts
of the 6.5 experiment are taken as a test dataset. The
Grapheme Approach to Recognizing Letters based on Medial Representation
357

font size is assumed to be 80 pixels, n
te
= 1188. The
document is generated (.doc) with all the letters from
the test sample, then this document is printed. Then
the obtained samples are scanned with a resolution of
300 dpi. That is, the images are of lower quality than
in the previous case (see Fig. 11).
Figure 11: Example letter from the input image
The results are presented in the table 4:
Table 4: The results of the two methods.
SA CNN
Quality, Q 0.95538 0.94696
Refusal rate 0.01263 0
6.8 Analysis of Experiments
The experiments show that: the quality of the propo-
sed method is not worse than the selected basic algo-
rithm and it has a small proportion of refuses from the
classification, which increases with the deterioration
of image quality.
7 CONCLUSIONS
This paper proposes a formalization of the concept of
”grapheme”, namely a mathematical model of grap-
heme.
On the basis of this model, a method of genera-
ting features used for the subsequent construction of
the algorithm of classification of images of letters is
proposed (that is, the measure of similarity between
mathematical models of graphs is determined). Also
in this article the algorithm of recognition of the text
on the image is proposed.
The advantages of the proposed letters recognition
method: independence from the size, type of font and
type of lettering; allocation of the general structure
(mathematical model of grapheme) for letters, which
is enough to recognize letters in new fonts; interpre-
tability of features.
The disadvantages of the method: the presence of
refuses of classification and the dependence of the re-
cognition quality from the quality of the binarization
of the image.
The experiments confirm that the proposed mat-
hematical model of the grapheme has shown its effi-
ciency.
The objectives of further research are:
1. Improvement of top-level and bottom-level featu-
res.
2. Solution to the problem of classification refuses.
3. Modification of the iterative part (postprocessing)
of the classification algorithm.
ACKNOWLEDGEMENTS
The work was funded by Russian Foundation of Basic
Research grant No. 17- 01-00917.
REFERENCES
Bishop, C. (2006). Pattern recognition and machine lear-
ning. Springer.
FontsDatabase (2018). https://www.fontsquirrel.com/.
Glorot, X., Bordes, A., and Bengio, Y. (2011). Deep sparse
rectifier neural networks. In Proceedings of the four-
teenth international conference on artificial intelli-
gence and statistics, pages 315–323.
Hausdorff, F. (1965). Grundz
¨
uge der mengenlehre (reprint;
originally published in leipzig in 1914). Chelsea, New
York.
Ho, T. K. (1995). Random decision forests. In Docu-
ment analysis and recognition, 1995., proceedings of
the third international conference on, volume 1, pages
278–282. IEEE.
Jarrett, K., Kavukcuoglu, K., LeCun, Y., et al. (2009). What
is the best multi-stage architecture for object recogni-
tion? In Computer Vision, 2009 IEEE 12th Internati-
onal Conference on, pages 2146–2153. IEEE.
LeCun, Y., Bottou, L., Bengio, Y., and Haffner, P. (1998).
Gradient-based learning applied to document recogni-
tion. Proceedings of the IEEE, 86(11):2278–2324.
Lin, M., Chen, Q., and Yan, S. (2013). Network in network.
arXiv preprint arXiv:1312.4400.
Mestetskiy, L. M. (2009). Continuous morphology of bi-
nary images: figures, skeletons, circulars (In Rus-
sian). FIZMATLIT.
Osetrova, O. V. (2006). Semiotics of the font (In Rus-
sian). Bulletin of Voronezh state University. Se-
ries:Philology. Journalism.
Otsu, N. (1979). A threshold selection method from gray-
level histograms. IEEE transactions on systems, man,
and cybernetics, 9(1):62–66.
ParaType (2008). Digital Fonts (In Russian). ParaType.
Solomonik, A. (2017). About language and languages (In
Russian). Publishing House ’Sputnik+’.
Zaliznyak, A. A. (2002). Russian nominal inflection by ap-
plication of selected works on modern Russian lan-
guage and General linguistics (In Russian). languages
of Slavic culture.
VISAPP 2019 - 14th International Conference on Computer Vision Theory and Applications
358
