
Facial Image Generation by Generative Adversarial Networks using
Weighted Conditions
Hiroki Adachi, Hiroshi Fukui, Takayoshi Yamashita and Hironobu Fujiyoshi
Chubu University, Kasugai, Aichi, Japan
Keywords:
Conditional Generative Adversarial Networks, CelebA Dataset.
Abstract:
CGANs are generative models that depend on Deep Learning and can generate images that meet given con-
ditions. However, if a network has a deep architecture, conditions do not provide enough information, so
unnatural images are generated. In this paper, we propose a facial image generation method by introducing
weighted conditions to CGANs. Weighted condition vectors are input in each layer of a generator, and then
a discriminator is extend to multi-tasks so as to recognize input conditions. This approach can step-by-step
reflect conditions inputted to the generator at every layer, fulfill the input conditions, and generate high quality
images. We demonstrate the effectiveness of our method in both subjective and objective evaluation experi-
ments.
1 INTRODUCTION
Generative Adversarial Networks (GANs) (Goodfel-
low et al., 2014) have received great research inte-
rests recently because this method is able to gene-
rate images or sentences using random noise vec-
tors. Therefore, many methods have been propo-
sed on the basis of learning techniques of GANs.
Conditional GANs (CGANs) (Mirza and Osindero,
2014)(Reed et al., 2016) can generate images that ful-
fil certain conditions by inputting class labels, text,
and so on as conditions. GANs and CGANs are gene-
rally constructed by Multi Layer Perceptrons (MLPs),
which causes these have various problems such as un-
stable training, making it difficult to generate high-
quality images. High-quality images can be generated
by Deep Convolutional GANs (DCGANs) (Radford
et al., 2016) and by replacing fully connected lay-
ers of CGANs with convolution layers (Conditional
DCGANs) (Gauthier, 2014). Specifically, DCGANs
are able to make training more stable by adding vari-
ous training techniques. Recently proposed methods
include unsupervised learning that can generate ima-
ges like CGANs as an auxiliary task (Chen et al.,
2016), and a method to improve the quality of gene-
rated images (Augustus et al., 2017). Moreover, the
latest state-of-the-art method, Progressive Growing
GANs (PGGANs) (Karras et al., 2018), can generate
high quality, natural-looking images by using a hier-
archical training process.
However, CGANs and Conditional DCGANs have a
problem in that inputted conditions vanish near the
output layer, so the generated images become unna-
tural when deep architecture networks such as PG-
GANs are used because conditions are inputted in
only the first layer. Therefore, in this paper, we pro-
pose a facial image generation method by introducing
weighted conditions to CGANs. The proposed met-
hod generates images that stepwisely reflect conditi-
ons by inputting weighted conditions to a generator.
Additionally, to reflect conditions further after adver-
sarial learning of the generator, a discriminator ex-
pands multi-tasks so as to recognize conditions input
to the generator. Furthermore, we construct an enco-
der to extract the feature quantity of the input image
and propose a learning method that can reconstruct
images by inputting the extracted feature quantity to
the generator of the proposed method.
2 RELATED WORKS
2.1 Generative Adversarial Networks
GANs (Goodfellow et al., 2014) are generative mo-
dels using Deep Learning that consist of two net-
works: a generator and a discriminator. The generator
generates an image that deceives the discriminator by
using noise vectors as input. The discriminator accu-
Adachi H., Fukui H., Yamashita T. and Fujiyoshi H.
Facial Image Generation by Generative Adversarial Networks using Weighted Conditions.
DOI: 10.5220/0007377601390145
In Proceedings of the 14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 14th International Conference on
Computer Vision Theory and Applications), pages 139-145
ISBN: 978-989-758-354-4
Copyright
c
14th International Conference on Computer Vision Theory and Applications by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
139
rately classifies between inputted real images and ge-
nerated images. The objective function of GANs is
given as
min
G
max
D
V (D,C) = E
x
x
x∼P
data
(x
x
x)
[logD(x
x
x)] +
E
z
z
z∼P(z
z
z)
[log(1 − D(
˜
x
x
x))], (1)
where z
z
z ∈ R
100
is noise vectors sampled from distri-
bution p(z
z
z) such as N (0, I) or U[−1, 1],
˜
x
x
x is ima-
ges generated by the generator, and x
x
x is real images.
By adversarial learning of the generator and discri-
minator, images not included in training samples can
be generated. Also, unlike a Variational Autoenco-
der (VAE) (Kingma and Welling, 2014), GANs are
able to generate images that are not blurry because
they do not calculate error in pixel units. Vanilla
GANs have difficulty generating specific images be-
cause only noise vectors are inputted. CGANs (Mirza
and Osindero, 2014) are able to generate images that
fulfill conditions by using conditions such as class la-
bels and text corresponding to images. The objective
function of CGANs is given as
min
G
max
D
V (D, C ) = E
x
x
x∼P
data
(x
x
x)
[logD(x
x
x|y
y
y)] +
E
z
z
z∼P(z
z
z)
[log(1 − D(
ˆ
x
x
x|y
y
y))], (2)
where
ˆ
x
x
x is G(z
z
z|y
y
y) obtained by inputting the noise
vector z
z
z and conditions y
y
y to the generator. Vanilla
GANs or CGANs have difficulty generating clear
images because of the way the MLP is configured.
To overcome this problem, DCGANs (Radford et al.,
2016), Conditional DCGANs (Gauthier, 2014), and
PGGANs (Karras et al., 2018) in which Deep Convo-
lutional Neural Network (DCNN) (Yann et al., 1998)
that have a convolutional layer and Batch Normali-
zation (Sergey and Christian, 2015) are introduced
have been proposed and are able to generate high-
quality images. In particular, PGGANs can stably ge-
nerate high-resolution natural images by first genera-
ting global information, gradually adding a convolu-
tional layer to the network, generating detailed infor-
mation, and imposing a penalty for errors called Was-
serstein GANs Gradient Penalty (WGANs-GP) (Gul-
rajani et al., 2017).
2.2 Reconstruction Input Images
Many methods have been proposed that reconstruct
input data with an encoder such as VAE. A Conditio-
nal Adversarial Autoencoder (CAAE) (Zhang et al.,
2017) extracts rich feature vectors after inputting
high-dimensional facial images to an encoder. Then,
by inputting the condition of age in addition to the
extracted feature vector to the generator, CAAE can
㻯㼛㼚㼢㼛㼘㼡㼠㼕㼛㼚
㻸㼑㼍㼗㼥㻌㻾㼑㻸㼁
㻯㼛㼚㼢㼛㼘㼡㼠㼕㼛㼚
㻸㼑㼍㼗㼥㻌㻾㼑㻸㼁
㻼㼕㼤㼑㼘㻌㼣㼕㼟㼑㻌㻺㼛㼞㼙
㻺㼛㼕㼟㼑㻌㼂㼑㼏㼠㼛㼞
㻠㽢㻠
㻤㽢㻤 㻝㻢㽢㻝㻢 㻢㻠㽢㻢㻠㻟㻞㽢㻟㻞
㻝㻞㻤㽢㻝㻞㻤
㻌㻯㼛㼚㼢㻌㻝㽢㻝
㻌㻯㼛㼚㼢㻌㻝㽢㻝 㻌㻯㼛㼚㼢㻌㻝㽢㻝 㻌㻯㼛㼚㼢㻌㻝㽢㻝
㻌㻯㼛㼚㼢㻌㻝㽢㻝
㻌㻯㼛㼚㼢㻌㻝㽢㻝
㻌㻯㼛㼚㼐㼕㼠㼕㼛㼚
㼟㼕㼓㼙㼛㼕㼐
㼟㼕㼓㼙㼛㼕㼐
㼟㼕㼓㼙㼛㼕㼐
㼟㼕㼓㼙㼛㼕㼐
㼟㼕㼓㼙㼛㼕㼐
㼟㼕㼓㼙㼛㼕㼐
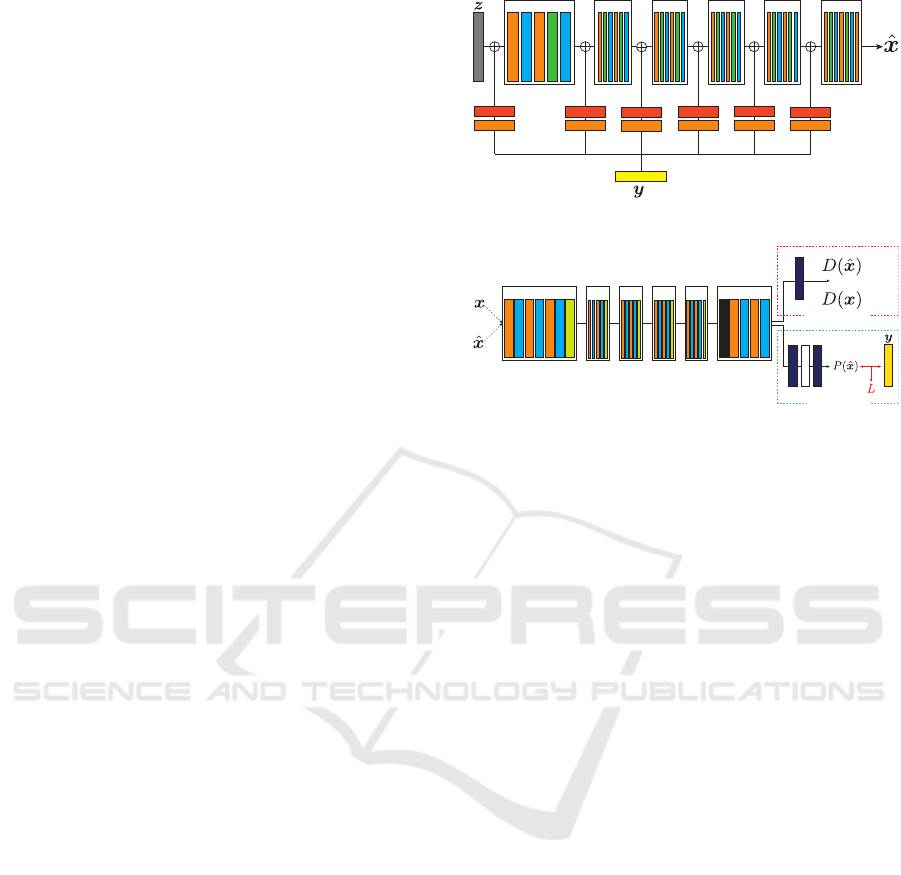
Figure 1: Generator adopted in proposed method.
㻯㼛㼚㼢㼛㼘㼡㼠㼕㼛㼚
㻸㼑㼍㼗㼥㻌㻾㼑㻸㼁
㻯㼛㼚㼢㼛㼘㼡㼠㼕㼛㼚
㻯㼛㼚㼢㼛㼘㼡㼠㼕㼛㼚
㻸㼑㼍㼗㼥㻌㻾㼑㻸㼁
㻭㼢㼑㼞㼍㼓㼑㻌㻼㼛㼛㼘㼕㼚㼓
㻸㼑㼍㼗㼥㻌㻾㼑㻸㼁
㻝㻞㻤㽢㻝㻞㻤
㻢㻠㽢㻢㻠
㻟㻞㽢㻟㻞
㻝㻢㽢㻝㻢
㻤㽢㻤
㻾㼑㻸㼁
㻲㻯
㻲㻯
㻾㼑㼏㼛㼓㼚㼕㼠㼕㼛㼚㻌㻮㼞㼍㼚㼏㼔
㼛㼞
㻭㼐㼢㼑㼞㼟㼍㼞㼕㼍㼘㻌㻮㼞㼍㼚㼏㼔
㻲㻯
㻯㼛㼚㼢㼛㼘㼡㼠㼕㼛㼚
㻸㼑㼍㼗㼥㻌㻾㼑㻸㼁
㻯㼛㼚㼢㼛㼘㼡㼠㼕㼛㼚
㻸㼑㼍㼗㼥㻌㻾㼑㻸㼁
㻹㼕㼚㼕㼎㼍㼠㼏㼔㻌㻿㼠㼐㼐㼑㼢
㻠㽢㻠
㻯㼛㼚㼐㼕㼠㼕㼛㼚
Figure 2: Discriminator adopted in proposed method.
change the input facial image to various ages. Bidi-
rectional GANs (BiGANs) (Donahue et al., 2017) use
a learning method that inputs not only generated ima-
ges and real images but also the noise vector inputted
to the generator in addition to features obtained from
the encoder. α-GANs (Rosca et al., 2017) are similar
to BiGANs but are separating networks that recognize
the noise vector and the output of the encoder. Also,
α-GANs add the L1 norm between the training data
and generated data as reconstruction loss. These met-
hods are able to generate clear images by adversarial
learning.
3 PROPOSED METHOD:
WEIGHTED CONDITIONS AND
MULTI-TASK LEARNING
In this paper, we propose a facial image generation
method that inputs weighted conditions to the genera-
tor and recognizes conditions in the discriminator. We
also propose a method that reconstructs inputted ima-
ges by using the encoder and the generator in the pro-
posed method. First, we describe the learning man-
ner of the generator in 3.1 and leaning manner of the
multi-task discriminator in 3.2. Then we present the
learning algorithm using the encoder and generator in
3.3.
VISAPP 14th International Conference on Computer Vision Theory and Applications - 14th International Conference on Computer Vision
Theory and Applications
140

3.1 Introduced Weight: Learning of
Generator
In previous CGANs, conditions vanish near the output
layer because the conditional vector y
y
y ∈ {0, 1} is only
in the input layer. Thus, the generator in the proposed
method inputs conditions to a hidden layer other than
the input layer in like a skip connection. This appro-
ach can certainly reflect conditions until the near the
output layer. In addition, previous facial image ge-
neration methods directly input the binary condition
vector to the generator. On the other hand, the pro-
posed method applies 1 × 1 convolution process and
sigmoid function to the condition vector y
y
y expressed
in binary and inputs its output to the generator. There-
fore, we represent a continuous value y
y
y from 0 to 1 as
a condition vector. Moreover, each condition can be
weighted because the filter size of the convolutional
process is 1 × 1. By weighting conditions, the propo-
sed method is able to stepwisely reflect conditions in
such a way as to whole the generator because the most
suitable conditions can be reflected at the time of ge-
neration in each layer. Furthermore, we use Pixelwise
Normalization instead of Batch Normalization. Pixel-
wise Normalization is a normalization method used in
PGGANs that is able to improve the quality of gene-
rated images. Pixelwise Normalization is represented
as
b
x,y
=
a
x,y
1
N
∑
N−1
j=0
(a
j
x,y
)
2
+ ε
, (3)
where N is the number of feature maps, a
x,y
and b
x,y
is
the feature vector before and after and ε = 10
−8
. This
series of processes is indicated in Figure 1.
3.2 Multi-task Discriminator
The discriminator inputs real or generated images and
simultaneously considers inputted conditions to dis-
tinguish between the real images or generated ones
are inputted to the discriminator, which simultane-
ously considers inputted conditions to distinguish be-
tween the images. The discriminator in our proposed
method improves multi-tasks so as to recognize given
conditions when the generator generates images. Fi-
gure 2 shows a multi-task network. The adversarial
branch and recognition branch in Figure 2 represent
a previous task of GANs and condition recognition,
respectively. In CGANs and Conditional DCGANs,
conditions are also given to the discriminator, but in
the proposed method add the recognition branch. It is
able to be considered alternative input conditions by
minimizing the condition recognition error, which is
computed by using the conditions inputted to the ge-
nerator. Minibatch Stddev is the standard deviation
for Mini Batch calibration. This proposed method at
PGGANs is able to generate diverse images.
Condition recognition error is added to the objective
function of previous CGANs. Thereby, adversarial le-
arning of the generator reflects more conditions. The
objective function of our proposed method is indica-
ted as
min
G
max
D
V (D, G) = E
x
x
x∼P
data
(x
x
x)
[logD(x
x
x)] +
E
z
z
z∼P(z
z
z)
[log(1 − D(
˜
x
x
x)] ∧ min L, (4)
where L is condition recognition error. If a dataset
of real facial images is used, our proposed method
finds it difficult or impossible to recognize the images
by using the softmax function and cross entropy error
because multiple facial attributes in this dataset are re-
presented in binary. When mean square error is used,
the recognition branch of the number of attributes to
be recognized is required and calculation cost is high.
Hence, we calculate error by sigmoid cross entropy
because we calculate recognition error of multiple fa-
cial attributes with a one the recognition branch.
3.3 Obtain Feature Vector: Encoder
and Fine-tunned Generator
Generative methods such as α-GANs and BiGANs
use adversarial learning and an encoder and generate
images without fine-tunned the generator. Therefore,
generative methods frequently generate unclear ima-
ges in initial learning. In addition, previous techni-
ques are high cost because they require multiple net-
works to be updated. Thus, we propose a way of lear-
ning that uses an encoder and a fine-tuned generator.
Clear facial images can be generated from initial le-
arning using the fine-tuned generator, and our method
generates images that maintain the identity of input-
ted images by inputting features obtained from the en-
coder to generator. Algorithm 1 details the proposed
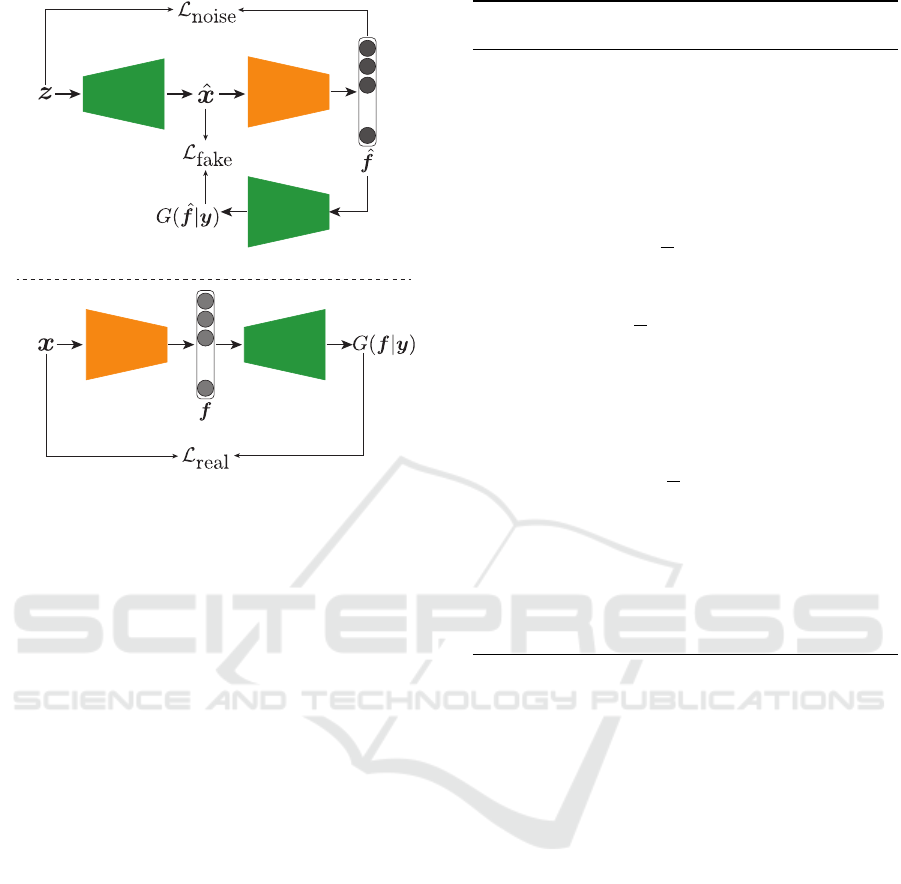
learning process, and Figure 3 is illustration of prior.
Both f
f
f and
ˆ
f
f
f are features output from the Encoder,
but the former is real images, and latter is generated
images. Moreover, all L in Algorithm 1 are Mean
Squared Error, but these errors are different. L
real
is the error of real images and their reconstructions,
L
noise
is error of the noise vector and embedded fea-
tures of image generated from the noise vector, and
L
f ake
is error of reconstructed images and image ge-
nerated from the noise vector. In our proposed lear-
ning algorithm fixes parameters of the generator and
updates only the encoder.
Facial Image Generation by Generative Adversarial Networks using Weighted Conditions
141
(QFRGHU *HQHUDWRU
*HQHUDWRU
(QFRGHU
*HQHUDWRU
D
E
Figure 3: Training process using encoder and fine-tuned ge-
nerator. (a) Reconstruction process using generated images
from noise vector. (b) Reconstruction process using real
images. Light gray and dark gray circles are feature vector
which embedded real images and fake ones from, respecti-
vely.
4 EXPERIMENT
We evaluate the quality of facial images generated in
the proposed method. Moreover, we evaluate the ef-
fectiveness of the multi-task Discriminator and weig-
hted condition Generator.
4.1 Experimental Details
In this experiment, facial images generated using
the conventional methods (Conditional DCGANs and
Conditional PGGANs) and DCGANs and PGGANs
using the proposed method (Weighted Condition
DCGANs and Weighted Condition PGGANs) are
compared. We use CelebA Dataset (Ziwei et al.,
2015) which contains at 200,000 facial images du-
ring training of every methods. For the condition, a
five-dimensional condition vector y
y
y is created using
five attributes (Male, Bangs, Eyeglasses, Goatee, and
Smiling) of 40 kinds of face attributes given to each
image of CelebA Dataset. Moreover, the noise vector
of 512-dimension sampling from a normal distribu-
tion is input to the generator. We compare the quality
of generated images in objective and subjective eva-
Algorithm 1: Training process using encoder and fine-tuned
generator. m is batch size and λ = 0.1.
for Number of training iterations do
• Sampling minibatch of m noise data, training data,
and conditions z
z
z
m
∈ P(z
z
z), x
x
x
m
∈ P(x
x
x) and y
y
y
m
∈ P(y
y
y).
if Reconstruction of generated images from noise vec-
tor z
z
z then
L
noise
=
1
m
m
∑
i=1
[z
z
z − E(
ˆ
x
x
x|y
y
y)]
2
i
L
f ake
=
1
m
m
∑
i=1
h
G(z
z
z|y
y
y) − G(
ˆ
f
f
f |y
y
y)
i
2
i
else if Reconstruction using real images then
CH = {R, G, B}
L
real
=
∑
i∈CH
"
1
m
m
∑
j=0
(x
x
x − G( f
f
f |y
y
y))
2
j
#
i
end if
L = exp(λ(L
noise
+ L
f ake
+ L
real
))
• Updating the encoder by using Adam optimizer.
end for
luations. In the objective evaluation, Inception Score
and Fr
´
echet Inception Distance (FID) are used. The
Inception Score is the average result of 10 evaluati-
ons. In the subjective evaluation, we use 150 images
every method and in 21 subjects evaluate generated
images in terms the quality and condition fulfilment.
We create the simple user interface for the subjective
evaluation.
4.2 Experimental Results
Figure 4 shows facial images generated by each met-
hod. In the visual evaluation, images generated by all
method are able to clearly show faces, and whether
the generated facial images reflected inputted condi-
tions is determined. Figure 4 (a) to (d) show all met-
hods were able to generate images of the same quality.
Comparing DCGANs in (a) and (c) and PGGANs in
(b) and (d), PGGANs generate facial images that look
more natural. Also, previous methods in (a) and (b)
set the gender to neutral when inputted attributes are
Eyeglasses+Smiling. Additionally, for Male+Goatee,
previous methods reflect smiling in a few images. By
contrast, our method in (c) and (d) is able to generate
images that fulfill indicated conditions.
VISAPP 14th International Conference on Computer Vision Theory and Applications - 14th International Conference on Computer Vision
Theory and Applications
142

㻹㼍㼘㼑
㻿㼙㼕㼘㼕㼚㼓
㻹㼍㼘㼑㻗㻳㼛㼍㼠㼑㼑
㻹㼍㼘㼑
㻿㼙㼕㼘㼕㼚㼓
㻹㼍㼘㼑㻗㻳㼛㼍㼠㼑㼑
㻹㼍㼘㼑㻗㻳㼛㼍㼠㼑㼑
㻿㼙㼕㼘㼕㼚㼓
㻹㼍㼘㼑
㻔㼍㻕㻌
㻱㼥㼑㼓㼘㼍㼟㼟㼑㼟㻗㻿㼙㼕㼘㼕㼚㼓
㻱㼥㼑㼓㼘㼍㼟㼟㼑㼟㻗㻿㼙㼕㼘㼕㼚㼓
㻱㼥㼑㼓㼘㼍㼟㼟㼑㼟㻗㻿㼙㼕㼘㼕㼚㼓
㻹㼍㼘㼑
㻿㼙㼕㼘㼕㼚㼓
㻹㼍㼘㼑㻗㻳㼛㼍㼠㼑㼑
㻱㼥㼑㼓㼘㼍㼟㼟㼑㼟㻗㻿㼙㼕㼘㼕㼚㼓
㻔㼏㻕㻌
㻔㼐㻕㻌
㻔㼎㻕
Figure 4: Facial images generated by different methods. Both (a) and (b) are generated by previous methods. (c) and (d) are
generated by our method. (a) and (c) show results for DCGANs. (b) and (d) show results for PGGANs.
Moreover, Figure 5 shows Weighted Condition
PGGANs can also generate natural high-quality fa-
cial images that fulfill condition and have higher re-
solution. Thus, Weighted Condition PGGANs can
generate high-resolution images with clear facial de-
tails. Figure 6 shows facial images reconstructed by
㻹㼍㼘㼑
㻹㼍㼘㼑㻌㻗㻌㻿㼙㼕㼘㼕㼚㼓
㻺㼛㻌㻮㼑㼍㼞㼐㻌㻗㻌㻿㼙㼕㼘㼕㼚㼓
㻮㼘㼛㼚㼐㻌㻴㼍㼕㼞㻌㻗㻌㻺㼛㻌㻮㼑㼍㼞㼐㻌㻗㻌㻿㼙㼕㼘㼕㼚㼓
Figure 5: Facial images [192×256 pixels] generated by
Weighted Condition PGGANs. Used facial conditions are
Male, Blond Hair, Eyeglasses, No Beard, and Smiling.
using the proposed algorithm. In this image genera-
tion experiment, we input facial attributes given real
images to the encoder and generator. Reconstructed
images cannot completely maintain real images iden-
tity but can maintain facial attributes, face direction,
and background color. Therefore, we are able to argue
that the generator of our proposed method can extract
global features of images inputted to the encoder.
The results of evaluating the generated image quan-
titatively are shown in Table 1. Note that generated
image are 128×128[pixels] in all methods. Weighted
,QSXWLPDJHV
5HFRQVWUXFWHGLPDJHV
Figure 6: Input images and images reconstructed by our
algorithm.
Condition DCGANs has a 0.03 lower Inception Score
and 21.3 lower FID than Conditional DCGANs. In
the subjective evaluation, Conditional DCGANs sco-
res higher than our Weighted Condition DCGANs.
Conditional PGGANs and our Weighted Condition
PGGANs have similar Inception Scores, but our met-
hod has higher FID and subjective evaluation score. It
is possible to confirm Inception Score is close to real
images score when compare PGGANs and DCGANs.
Both Weighted Condition PGGANs and DCGANs
drastically reduce FID, especially PGGANs. There-
fore, we argue that Weighted Condition PGGANs can
improve the quality of generated images, but we think
that some conditions vanish because the network of
PGGANs is very deep. Thus, our proposed method
effectively generates facial images that fulfil conditi-
ons by using a deep architecture network.
4.3 Effective Multi-tasks and Weighted
Conditions
To evaluate the effectiveness of introducing condition
recognition to the discriminator and weighted condi-
tions to the generator, we built two networks and then
compared objective evaluation results of generated fa-
cial images. In the first network, Recognition Branch
is removed from our discriminator, and in the second
network, convolutional layers of conditions are remo-
ved from our generator. Table 2 shows evaluation re-
Facial Image Generation by Generative Adversarial Networks using Weighted Conditions
143
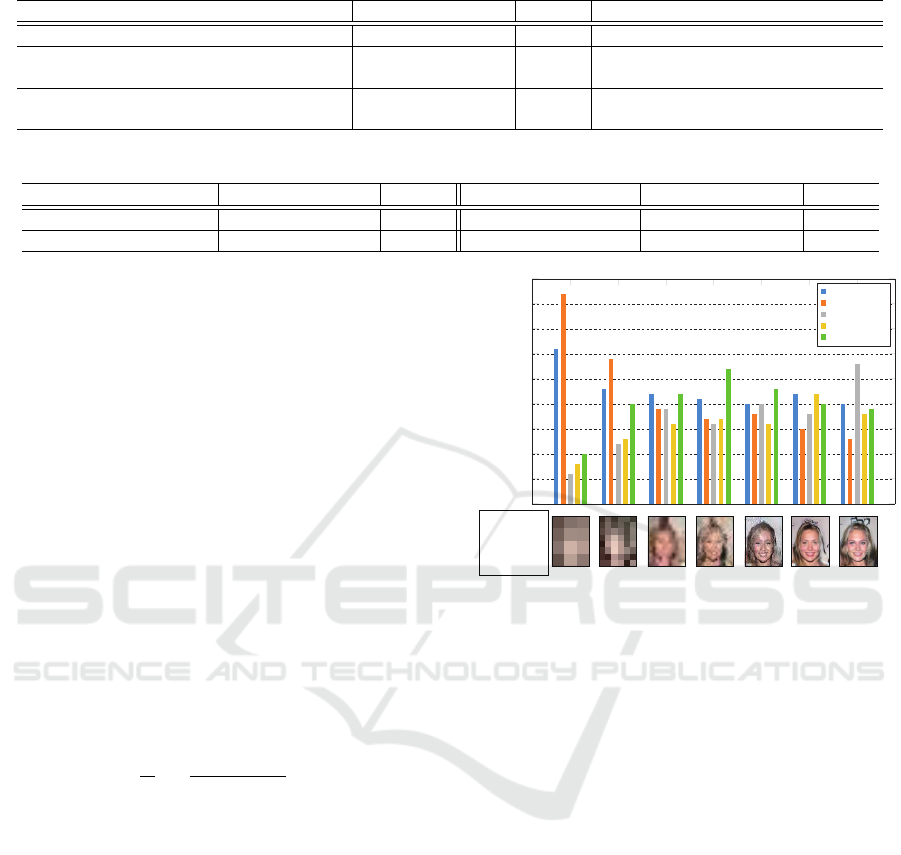
Table 1: Evaluation results for various evaluation methods
Methods Inception Score ↑ FID ↓ Subjective Evaluation (21 people) ↑
Real Images 1.97 - -
Conditional DCGANs 1.70 402.4 53.1
Weighted Condition DCGANs (Proposed) 1.67 381.1 46.9
Conditional PGGANs 1.68 450.4 44.5
Weighted Condition PGGANs (Proposed) 1.73 387.6 55.5
Table 2: Comparison Inception Score and FID with and without conditions recognition and weighted conditions.
Recognized Conditions Inception Score ↑ FID ↓ Weighted Conditions Inception Score ↑ FID ↓
X 1.73 387.6 X 1.73 387.6
1.62 397.6 1.65 401.1
sults. According to results, Inception Score was about
0.1 lower and FID 10.0 higher when the discriminator
did not have condition recognition. Moreover, the In-
ception Score was about 0.1 lower and FID 13.5 hig-
her when the generator did not have weighted condi-
tions. Therefore, high quality and natural images can
be generated by introducing weighted conditions to
the generator and Recognition Branch to the discri-
minator.
4.4 Discussion
The reason the proposed method generated facial ima-
ges that fulfilled indicated conditions is assumed to
be that optimal facial attributes in each layer were re-
flected by weighted conditions. Therefore, we visu-
alize the contribution of weighted conditions to the
generator. Contribution rates are calculated with a
weight filter in each convolutional layer. Contribution
rate C
t
is given as
C
t
=
1
N
N
∑
n=1
|W
t,n
|
∑
M
m=1
|W
m,n
|
, (5)
where N, M, W and t are the number of filters, num-
ber of attributes, weight filter, and a target attribute,
respectively. Figure 7 shows the contribution rates of
Male, Blond Hair, Eyeglasses, No Beard, and Smiling
to images generated at each resolution by Weighted
Condition PGGANs. Blond Hair + No Beard + Smi-
ling contribute more to middle images. Contribution
rates of Male and Blond Hair are highest in low re-
solution and then tend to decrease as resolution beco-
mes higher. The contribution rate of smiling increases
from the input layer to hidden layers and then decre-
ases toward the output layer. Furthermore, the contri-
bution rates of Eyeglasses and No Beard are highest
in high resolution images. Facial expressions are cle-
arly generated after the layer where the contribution
ratio of Smiling is the highest. Thus, in low resolu-
tion, global facial attributes have higher contribution
rates, and in high resolution, detailed facial attributes
㻹㼍㼘㼑
㻱㼥㼑㼓㼘㼍㼟㼟㼑㼟
㻺㼛㻌㻮㼑㼍㼞㼐
㻌㻮㼘㼛㼚㼐㻌㻴㼍㼕㼞
㻿㼙㼕㼘㼕㼚㼓
㻦㻌㻜
㻦㻌㻝
㻦㻌㻝㻌
㻦㻌㻝
㻦㻌㻜
㻠㽢㻟㻌㻌㻌㻌 㻤㽢㻢㻌㻌㻌㻌
㻝㻢㽢㻝㻞㻌㻌㻌㻌 㻟㻞㽢㻞㻠㻌㻌㻌㻌 㻢㻠㽢㻠㻤㻌㻌㻌㻌 㻝㻞㻤㽢㻥㻢㻌㻌㻌㻌 㻞㻡㻢㽢㻝㻥㻞㻌㻌㻌㻌
㻮㼘㼛㼏㼗㻝
㻮㼘㼛㼏㼗㻞
㻮㼘㼛㼏㼗㻟 㻮㼘㼛㼏㼗㻠
㻮㼘㼛㼏㼗㻡
㻮㼘㼛㼏㼗㻢
㻮㼘㼛㼏㼗㻣
㻯㼛㼚㼠㼞㼕㼎㼡㼠㼕㼛㼚㻌㻾㼍㼠㼑㻌㻔㻑㻕
㻹㼍㼘㼑
㻱㼥㼑㼓㼘㼍㼟㼟㼑㼟
㻺㼛㻌㻮㼑㼍㼞㼐
㻌㻮㼘㼛㼚㼐㻌㻴㼍㼕㼞
㻿㼙㼕㼘㼕㼚㼓
㻠㻡㻌㻌㻌㻌
㻠㻜㻌㻌㻌㻌
㻟㻡㻌㻌㻌㻌
㻟㻜㻌㻌㻌㻌
㻞㻡㻌㻌㻌㻌
㻞㻜㻌㻌㻌㻌
㻝㻡㻌㻌㻌㻌
㻝㻜㻌㻌㻌㻌
㻡㻌㻌㻌㻌
㻜㻌㻌㻌㻌
Figure 7: Contribution rate and generated image at each
depth.
have higher contribution rates, so our proposed met-
hod seems to be able to generate natural facial images
that fulfill conditions.
5 CONCLUSIONS AND FUTURE
WORKS
In this paper, we proposed a facial image genera-
tion method that introduces weighted conditions to
both DCGANs and PGGANs and a new image recon-
struction algorithm with an encoder. Condition can
be stepwisely reflected by inputting weighted condi-
tions. Moreover, conditions inputted to the generator
can be easily reflected by a multi-task discriminator.
The proposed method is able to generate facial ima-
ges that fulfil conditions in both DCGANs and PG-
GANs. Evaluation results showed our method is able
to drastically reduce the Fr
´
echet Inception Distance
(FID) score compared with previous methods. The
encoder using our algorithm can obtain effective fe-
atures in input image reconstruction. However, our
algorithm has difficulty completely reconstructing in-
put images. In future work, we will increase the reso-
VISAPP 14th International Conference on Computer Vision Theory and Applications - 14th International Conference on Computer Vision
Theory and Applications
144

lution of the generated images and attempt to stabilize
image generation.
REFERENCES
Augustus, O., Christopher, O., and Jonathon, S. (2017).
Conditional image synthesis with auxiliary classifier
gans. In International Conference on Machine Lear-
ning.
Chen, X., Duan, Y., Houthooft, R., Schulman, J., Sutskever,
I., and Abbeel, P. (2016). Infogan: Interpretable re-
presentation learning by information maximizing ge-
nerative adversarial nets. In Neural Information Pro-
cessing Systems.
Donahue, J., Philipp, K., and Darrell, T. (2017). Adversa-
rial Feature Learning. In International Conference on
Learning Representation.
Gauthier, J. (2014). Conditional generative adversarial nets
for convolutional face generation. In Convolutional
Neural Networks for Visual Recognition.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B.,
Warde-Farley, D., Ozair, S., Courville, A., and Ben-
gio, Y. (2014). Generative adversarial nets. In Neural
Information Processing Systems Conference.
Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V., and
Courville, A. C. (2017). Improved training of wasser-
stein gans. In Neural Information Processing Systems.
Karras, T., Aila, T. A., Laine, S., and Lehtinen, J. (2018).
Progressive growing of gans for improved quality, sta-
bility, and variation. In International Conference on
Learning Representation.
Kingma, D. P. and Welling, M. (2014). Auto-encoding va-
riational bayes. In International Conference on Lear-
ning Representation.
Mirza, M. and Osindero, S. (2014). Conditional generative
adversarial nets. In arXiv.
Radford, A., Metz, L., and Chintala, S. (2016). Unsuper-
vised representation learning with deep convolutio-
nal generative adversarial networks. In International
Conference on Learning Representation.
Reed, S., Akata, Z., Yan, X., Logeswaran, L., Schiele, B.,
and Lee, H. (2016). Generative adversarial text to
image synthesis. In International Conference on Ma-
chine Learning.
Rosca, M., Lakshminarayanan, B., Warde-Farley, D., and
Mohamed, S. (2017). Variational Approaches for
Auto-Encoding Generative Adversarial Networks. In
arXiv.
Sergey, I. and Christian, S. (2015). Batch normalization:
Accelerating deep network training by reducing in-
ternal covariate shift. In International Conference on
Machine Learning.
Yann, L., Leon, B., Yoshua, B., and Patrick, H. (1998).
Gradient-based learning applied to document recog-
nition. In Proceedings of the IEEE.
Zhang, Z., Song, Y., and Qi, H. (2017). Age progres-
sion/regression by conditional adversarial autoenco-
der. In International Conference on Conputer Vison
and Pattern Recognition.
Ziwei, L., Ping, L., Xiaogang, W., and Xiaoou, T. (2015).
Deep learning face attributes in the wild. In Internati-
onal Conference on Computer Vision.
Facial Image Generation by Generative Adversarial Networks using Weighted Conditions
145
