
Action Anticipation from Multimodal Data
Tiziana Rotondo
1
, Giovanni Maria Farinella
1,2
, Valeria Tomaselli
3
and Sebastiano Battiato
1,2
1
Department of Mathematics and Computer Science, University of Catania, Italy
2
ICAR-CNR, Palermo, Italy
3
STMicroelectronics, Catania, Italy
Keywords:
Action Anticipation, Multimodal Learning, Siamese Network.
Abstract:
The idea of multi-sensor data fusion is to combine the data coming from different sensors to provide more
accurate and complementary information to solve a specific task. Our goal is to build a shared representation
related to data coming from different domains, such as images, audio signal, heart rate, acceleration, et c., in
order to anticipate daily activities of a user wearing multimodal sensors. To this aim, we consider the Stanford-
ECM Dataset which contains syncronized data acquired with different sensors: video, acceleration and heart
rate signals. The dataset i s adapted to our action prediction task by identifying the transitions from the generic
“Unknown” class to a specific “Activity”. We discuss and compare a Siamese Network with the Multi Layer
Perceptron and the 1D CNN where the input is an unknown observation and the output is the next activity to
be observed. The feature representations obtained with the considered deep architecture are classified with
SVM or KNN classifiers. Experimental results pointed out that prediction from multimodal data seems a
feasible task, suggesting that multimodality improves both classification and prediction. Nevertheless, the
task of reliably predicting next actions is still open and requires more investigations as well as the availability
of multimodal dataset, specifically built for prediction purposes.
1 INTRODUCTION
The prediction of the future is a challenge that has al-
ways fascinated human s. As reported in (Lan et al.,
2014), given a short video or an image, humans can
predict what is going to happen in the near future. The
overall design of machines that anticipate future acti-
ons is still an op en issue in Computer Vision. In th e
state of the art, there are many a pplications in robotics
and health care that use this predictive characteristic.
For example, (Chan et al. , 2017) proposed a RNN
model for anticipating accidents in dashcam videos.
(Koppu la and Saxena, 2016; Furnari et al., 2017) stu-
died how to enable robots to anticipate human-object
interactions from visual input, in order to provide ad e -
quate assistance to the user. (Koppu la et al., 2016;
Mainprice and Beren son, 2013; Duarte et al., 2018)
studied how to anticipate human activities for impro-
ving the collabora tion between human and robot. In
(Damen e t al., 2018), the authors propose a new data-
set, called Epic-Kitchen Dataset, and action and anti-
cipation challenges have been investigated.
In this paper we consider the pro blem of pre-
dicting user actions. Since the information in the real
world comes from different sources and can b e cap-
tured by different sensors, our goal is to predict an
action before it happens from multimodal observed
data.
Multimodal learning aims to build models that are
able to process information from different modalities,
semantically related, to create a shared representation
of them. For example, given an image of a dog and
the word “dog ”, we want to projec t these data in a
representation space that takes a ccount of both source
domains.
As reported in (Srivastava and Salakhutdinov,
2014), each modality is characterized b y different
statistical p roperties, and hence each one of it c an
add valuable and complementary information to the
shared representation. A good model for multimodal
learning must satisfy certain properties. In fact the
shared rep resentation must be such that resemblance
in the shared space of representation implies that the
similarity of the inputs can be easily obta ined even in
the absence of some modalities.
Another aspect, not less important than the previ-
ous one, is represented by the data; in particular, they
are c ollected at different samplin g frequencies, there-
154
Rotondo, T., Farinella, G., Tomaselli, V. and Battiato, S.
Action Anticipation from Multimodal Data.
DOI: 10.5220/0007379001540161
In Proceedings of the 14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2019), pages 154-161
ISBN: 978-989-758-354-4
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

fore, before to features captioning, it is necessary to
synchro nize the various inputs in order to have all the
related modalities p roperly aligned.
This paper presents a study of predicting a future
action from currently observed multimodal d ata. To
this aim , th e Stanford-ECM Dataset (Naka mura et al.,
2017) has been considered. It comprises video, acce-
leration and h e art rate data. We adapted this dataset
to extract transitions from unknown to specific acti-
vities. Siamese network with Multi Layer Perceptron
and 1D CNN are used for predicting next activity just
from features extracted from the previous temporal
sequence, labeled as “Unknown”. The feature repre-
sentations obtaine d with the considered deep architec-
ture are classified with SVM or KNN classifier.
The prediction accuracy o f th e tested models is
compare d with respect to the classic a ction classi-
fication which is c onsidered as a baselin e. Results
demonstra te that th e presented system is effective in
predic-ting activity from an unknown observation and
suggest that multimodality improves both classifica-
tion and prediction in some cases. This confir ms that
data from different sensors can be exploited to en-
hance the representation of the surroundin g context,
similarly to what happens for human beings, that ela-
borate information coming f rom their eyes, ears, skin,
etc. to h ave a global and more reliable view of the
surrounding world.
The remainder of the paper is organized as fol-
lows. Sec tion 2 reviews the related work. Section 3
describes the dataset u sed in this paper. Section 4 d e -
tails the building blocks of our system while section
5 presents the expe rimental settings and discusses the
results. Finally, co nclusions are given in Section 6.
2 RELATED WORKS
We focus our review to related work w hich focus on
action anticipation an d multimodal learning.
2.1 Action Anticipation
The goal of action anticipation is to detect and recog-
nize a human ac tion be fore it happens. T he work of
(Gao et al., 2017) proposes a Reinf orced Encoder-
Decoder (RED) network for action anticipation that
takes multiple rep resentations as input and learns to
anticipate a sequence of future representations. These
anticipated represen ta tions are processed by a c la ssifi-
cation network for action classification. In (Lan et al. ,
2014), it is presented a hierarchical model that repre-
sents the human movements to infer future actions
from a static image or a short video clip. In (Ma et a l.,
2016), the authors proposed a method to improve trai-
ning of temporal deep models to learn activity pro-
gression for activity detection and ea rly recognition
tasks. Since in the state of the art ther e are not suffi-
ciently large datasets for action anticipation task , the
work o f (Damen et al., 2018 ) proposes a new data-
set, called Epic-Kitchen Dataset. The authors sh ow
the great potential of the d ataset for push ing appro-
aches that target fine-grained video understanding to
new frontier s.
2.2 Multimodal Learning
In this work, we are interested in considering mul-
timodal inputs to address action anticipation. One
of th e first paper on Multimodal Learning is (Ngiam
et al., 2011) where video and audio signals are used
as input. The aim of the work is to embed the inputs
into a shared representation in order to be able to use
only a single modality at test time. The creation of
a shared representation has also been treated in oth er
works. In particular (Srivastava and Salakhutdinov,
2014; Aytar et al. , 2017) build representations that are
useful for several tasks, such as cross-modal retrieval
or transferring classifiers between modalities.
In (Nakamura et al., 2017), a model for rea soning
on multimodal data to jointly predict activities and
energy expenditures is proposed. In particula r, they
consider Egocen tric videos augmented with heart rate
and acceler ation signals. In ( Wu e t al., 2017), an on-
wrist motion trigg ered sensing system for a nticipating
daily intention is proposed. The authors in troduce a
RNN method to anticipate intention and a policy net-
work to reduce computation requirement.
3 DATASET
There are few publicly available multimoda l datasets
in litera ture. Table 1 shows the relevant multimo-
dal datasets together with main characteristics a nd
the presence of transitions between actions. Since
sequences with transitions amo ng activities are nee-
ded, in our experiments, we considered the egocen-
tric multimodal dataset, called Stanford-ECM Data-
set (Nakamu ra et al., 201 7). This dataset comprises
31 hours of egocentric video (113 videos) synchroni-
zed with acceleration and heart rate data. The video
and triaxial accelerations were captured with a mobile
phone equipped with a 720 ×1280 resolution camera
at 30fps and 30Hz, resp e ctively. The lengths of the vi-
deos range from 3 minutes to about 51 minu te s. The
heart rate was collected with a wrist sensor every 5
seconds (0.2 Hz). These multimodal data were time-
Action Anticipation from Multimodal Data
155

Table 1: Relevant multimodal datasets together with main characteristics. T he second and third columns indicate the acquisi-
tion modality. Fourth column i ndicates the number of acti on class, whereas column five is related to the number of subjects
involved into the acquisition. The last two columns are related to the r esolution of frames and the presence of transitions
between actions.
Dataset First Person Third Person ♯ Class ♯ Subjects Resolution Transition
Multimodal Egocentric Activity Dataset (Song et al., 20 16) X ✗ 20 - 1280x720 ✗
Daily Intention Dataset (Wu et al., 2017) X ✗ 34 3 640x480 X
Epic-Kitchen Dataset (Damen et al., 2018) X ✗ 149 32 1920x1080 ✗
CMU-MMAC Dataset (Torre et al., 2009) X X 31 39 800x600 X
Stanford-ECM Dataset (Nakamura et al., 2017) X ✗ 24 10 720x1280 X
Table 2: Activity classes of Stanford-ECM Dataset.
Activity Activity
1.BicyclingUphill 13.Shopping
2.Running 14.Strolling
3.Bicycling 15.FoodPreparation
4.PlayingWithChildren 16.TalkingStanding
5.ResistanceTraning 17.TalkingSitting
6.AscendingStairs 18.SittingTasks
7.Calisthenics 19.Meeting
8.Walking 20.Eating
9.DescendingStairs 21.StandingInLine
10.Cooking 22.Riding
11.Presenting 23.Reading
12.Driving 24.Background
synchro nized through Bluetoo th. Cubic polynomial
interpolation was used to fill any gap in heart rate data.
Finally, data have been aligned consid ering millise-
cond level at 30 Hz.
The activity classes p resent in the Stanford ECM-
Dataset are listed in Table 2. There are 24 classes in
total. “Background” is a miscellaneous activity class
which includes activities such as taking pictures or
parking a bicycle. The dataset has a lso an additio-
nal class, unknown, tha t is related to part of the d a ta
before or after an action oc c urs.
Since this d ataset was c reated for classification
task, we have reviewed it to be compliant to our action
prediction task.
We considered a transition, suitable to build trai-
ning and test sets: Unknown/Activity, where “Acti-
vity” means a gener ic activity different from “back-
ground” and “unknown”. We cut each video around
the Unknown/Activity transitions including 64 fra-
mes before and 64 after the transitions point. Since
some transitions were represented w ith few sam-
ples, we have concentrated the analysis to the fol-
lowing 9 activities: Bicycling, Playing With Child-
ren, Walking, Strolling, Food Preparation, Talking
Standing, Talking Sitting, Sitting Tasks and Shop-
ping. Hence, the fin al dataset contains 309 transitions
Unknown/Activity.
4 PROPOSED AP PROACH
The proposed approach is synthetically sketched in
Figure 1. The model con sid ers the three modalities vi-
deo, a cceleration and heart rate as input after a feature
extraction process. More over details of the different
component of our approach will be g iven.
4.1 Problem
Let b e y
t
= (v
t
,a
t
,hr
t
)
T
the input vector at time t
where v
t
∈ R
2
is a video, a
t
∈ R
3
is an acceleration
signal an d hr
t
∈ R is a heart rate data, we define the
feature representation of video, acceleration and he-
art r ate signal as x
v
t
, x
a
t
and x
hr
t
and x
t
= (x
v
t
,x
a
t
,x
hr
t
)
T
the features vector at time t. Given x
t
as input, we
want to predict the label label
t+1
of the next action by
observing only data before the activity starts.
4.2 Features Extraction
In this section we descr ibe the feature representation
x
v
t
, x
a
t
and x
hr
t
for each signal. The extraction of vi-
deo an d acceleration features is similar to (Nakamura
et al., 2017).
For visual data, features are extracted from the
pooling layer five of the Inception CNN architecture
(Szegedy et al., 2015) pretrained on ImageNet (Deng
et al., 2009). Each video frame has been transfor-
med into a x
v
t
feature vector of 1024 dimension . For
acceleration data, we extracted features from raw sig-
nals thr ough a temporal sliding window p rocess con-
sidering a window size of 32fps. Time-domain featu-
res and frequency-domain features are extracted fr om
raw signals. For time-domain features, mean, stan-
dard deviation, skewness, kurtosis, percentiles (10th,
25th, 50th, 75th, 9 0th), acceleration count for each
axis a nd correlation co e fficients betwe e n each axis are
computed. For frequency-domain features, we con-
sider the spectral entropy J = −
N/2
∑
i=0
¯
P
i
·log
2
¯
P
i
where
¯
P
i
is the normalized power spectra l density computed
from Shor t Time Fourier Transform (STFT). Then,
VISAPP 2019 - 14th International Conference on Computer Vision Theory and Applications
156

Figure 1: Pipeline of our anticipation approach.
the obtained f e atures fr om the se domain s are co nca-
tenated and x
a
t
is a 36-dimensional vector.
For heart rate data, the features are extracted f rom
the time-series of the raw signals. Mean and standard
deviation are calculated to compute a x
hr
t
∈R
2
vector.
4.3 Temporal Pyramid
We represent features in a temporal pyra mid fashion
(Pirsiavash and Ramanan, 2012) composed by three
level. The top level (j=0) is an histogram over th e
full temporal extent of a data, the next level (j=1 ) is
the concatenation of two h istograms obtained by tem-
porally segmenting each m odality into two half s, the
last level (j= 2) is the concatenation of four histograms
obtained by temporally segmenting each previous his-
togram into two h alves. In this way, 7 histograms are
obtained corresponding to a 1024 ×7 visual features,
36×7 acceleration features, and 2 ×7 hea rt rate featu -
res. All features are concatenated into a single vector
x
t
= (x
v
t
,x
a
t
,x
hr
t
)
T
of 7434 components.
4.4 Data Augmentation
Since we have few transition samples, data augmen-
tation technique is used to expand the train ing set to
prevent over-fitting. In this pa per, the permutation
Unknown/Activity is considered. Each unknown se-
quence is paired with all the possible seq uences of
activity. For example, we combined the unknown clip
related to “walking” a c tivity with every other acti-
vity. The label of each augmented transition is chan-
ged from 0-8 to 0-1, as follows: if unknown and th e
activity belong to the same class (e.g. unknown rela-
ted to walking and the following ac tivity is walking),
we assign a label 1, othe rwise a label 0 is assigned if
unknown and the activity are different ( e.g. unknown
related to walking and activity is related to food pre-
paration).
The obtained dataset is strongly unbalanced. Ta-
ble 3 compares the number of sequences before and
after augmentation. Some classes, such as Shopping
or Food Preparation, are poorly represented therefore
it is necessary to down-sample the dataset. We con-
sider the square of minimum value of the number of
original activity tra nsitions (11
2
= 121) from seq uen-
ces with label 1 and 15 4 sequences from sequences
with label 0 for each class, in order to balance activi-
ties classes and unknown class. The final da ta set has
12177 sequences.
4.5 Learning Approach
Our goal is to build an embedding space where the
unknown sequen c es, wh ic h are related to the past, are
close to those of future activities. In this regard, we
use Siamese networks (Brom ley et al., 1993; Koch
et al., 2 015) which consist of twin networks that share
weights and accept two different inputs. After lear-
ning proc e ss, two similar im a ges should be mapped
by the network to close points in the feature space be-
cause e ach network computes the same function. Du-
ring training the two networks extract features from
two inputs, while the final shared neuron measures
the distance between the two feature vectors.
In our experiment, since the Siamese network
will be trained to make representations of features of
”Unknown” sequenc e s and next ”Activity” very c lose
in the embedding space, one stream of the Siamese
network processes the unknown features wherea s the
other stream processes those related to the activity.
Euclidean metric is used as distan ce between inputs.
The con trastive loss function (Hadsell et al., 200 6) is
used for training purposes:
Y
√
D + (1 −Y)
p
max(1 −D,0) (1)
where Y is the ground tr uth activity label and D is the
euclidean distance betwee n two fea ture po ints.
Action Anticipation from Multimodal Data
157

Table 3: Number of sequences for each activity before and after augmentation.
Activity ♯ of original activity transitions ♯ of augmented activity transitions ♯ of final transitions
Bicycling 18 4482 1353
Walking 79 19671 1353
Shopping 11 2739 1353
Talking Standing 26 6474 1353
Sitting Tasks 17 4233 1353
Playing With Children 32 7968 1353
Strolling 32 7968 1353
Food Preparation 14 3486 1353
Talking Sitting 20 4980 1353
TOT 249 62001 12177
Figure 2: a) 1D CNN Architectures. b) MultiLayer Perceptron architecture.
We c onsider two different architectures for Sia-
mese network: Multilayer Perceptron (Bishop, 2006)
and 1D Convolutional Neural Network (CNN) (Kira-
nyaz et al., 201 6; Lee et al., 2017) . Figure 2 shows
the architecture of the used networks. For Multilayer
Perceptron, two hidden layers are considered with a
number of n eurons of 4000 and 3000 respectively. For
1D CNN, three convolutional layers are used with a
number of filters of 32, 64 and 2, respectively, (all of
size 3 ×1) and a relu activation function. The output
of each convolutional layer is reduced in size using a
max-pooling layer that halves the number of featu res.
4.6 Classification and P rediction
Our aim is to predict next ac tivity from an unknown
clip. To our knowledge, in the state of the art, there
are not results on action anticipation from multimo-
dal data, therefore we consider as baseline the classi-
fication of activity sequences and the classification of
unknown sequence s. A k-nearest-neighbor classifica-
tion algorithm (K-NN) and a support vector machin e
(SVM) are used for classification purposes.
5 EXPERIMENTS
In this section, the results of the propo sed approach
are shown and discussed. Our model is evaluated on
Stanford-ECM Dataset. The fe ature representations
obtained with the considered deep architectures are
classified with SVM or KNN classifier.
5.1 Setup
We randomly split our data into disjoint training (2 49
sequences) and testing sets (60 sequences) for trai-
ning and testing purposes. For Siamese Network, the
Adam op timizer is considered with batch size of 249
samples. Variable learn ing rate is used starting fr om
0.001. In the Multilayer Perceptron, in order to pre-
vent overfitting, we apply a dropo ut procedure during
training. We evaluate K-NN for different values of k
and SVM for different kernels. In K-NN classifier,
we consider two different we ights: uniform and dis-
tance. The first assigns equal weights to all poin ts,
while distance weight assigns weights proportional to
the inverse of the distance from the query point.
VISAPP 2019 - 14th International Conference on Computer Vision Theory and Applications
158
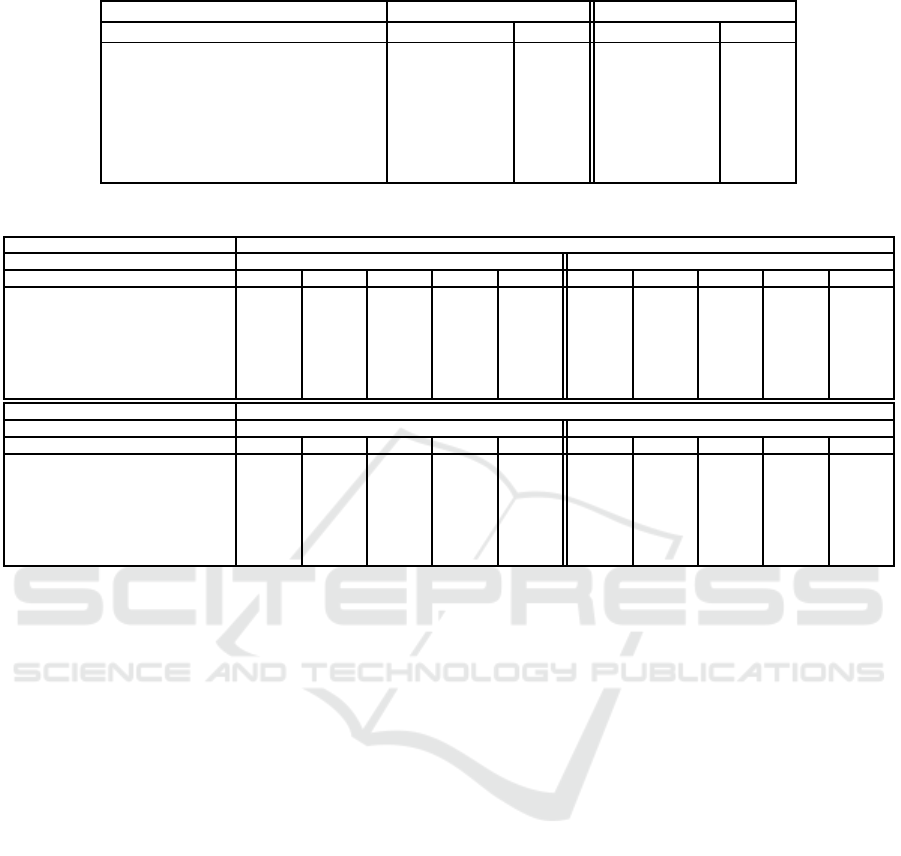
Table 4: SVM Results.
Classification Prediction
Modality (♯ Features) Linear Kernel RBF Linear Kernel RBF
Acceleration (252) 31.67% 46.67% 31.67% 46.67%
Heart rate (14) 33.33% 28.33% 33.33% 35%
Video(7168) 66.67% 68.33% 60% 56.67%
Acceleration+Heart rate (266) 36.67% 50% 38.33% 48.33%
Video+Acceleration (7420) 70% 71.67% 68.33% 68.33%
Video+Heart rate(7182) 66.67% 66.67% 60% 63.33%
Video+Acceleration+Heart rate (7434) 70% 68.33% 68.33% 68.33%
Table 5: K-NN Results.
Classification
Modality (♯ Features) weights=uniform weights= distance
k = 1 k = 3 k = 5 k = 7 k = 9 k = 1 k = 3 k = 5 k = 7 k = 9
Acceleration (252) 41.67% 53.33% 48.33% 45% 45% 41.67% 51.67% 46.67% 50% 50%
Heart rate (14) 23.33% 21.67% 18.33% 23.33% 31.67% 23.33% 20% 15% 15% 15%
Video(7168) 63.33% 61.67% 61.67% 61.67% 60% 63.33% 61.67% 63.33% 66.67% 63.33%
Acceleration+ Heart ra te (266) 38.33% 46.67% 48.33% 45% 43.33% 38.33% 43.33% 45% 48.33% 46.67%
Video+Acceleration (7420) 61.67% 61.67% 63.33% 63.33% 61.67% 61.67% 58.33% 61.67% 65% 65%
Video+Heart rate(7182) 63.33% 61.67% 61.67% 61.67% 60% 63.33% 61.67% 65% 65% 63.33%
Video+Acceleration+Heart rate (7434) 60% 65% 63.33% 63.33% 58.33% 60% 61.67% 63.33% 65% 63.33%
Prediction
Modality (♯ Features) weights=uniform weights= distance
k = 1 k = 3 k = 5 k = 7 k = 9 k = 1 k = 3 k = 5 k = 7 k = 9
Acceleration (252) 41.67% 53.33% 48.33% 45% 45% 41.67% 51.67% 46.67% 50% 50%
Heart rate (14) 20% 26.67% 26.67% 25% 35% 20% 20% 20% 23.33% 26.67%
Video(7168) 55% 56.67% 60% 56.67% 60% 55% 58.33% 58.33% 56.67% 63.33%
Acceleration+ Heart ra te (266) 33.33% 46.67% 48.33% 45% 48.33% 33.33% 41.67% 45% 45% 48.33%
Video+Acceleration (7420) 53.33% 58.33% 60% 60% 56.67% 53.33% 61.67% 58.33% 60% 60%
Video+Heart rate(7182) 55% 56.67% 60% 56.67% 60% 55% 58.33% 58.33% 56.67% 63.33%
Video+Acceleration+Heart rate (7434) 53.33% 58.33% 61.67% 60% 56.67% 53.33% 61.67% 60% 60% 58.33%
5.2 Baseline
In order to better evaluate our approach, we define a
baseline where the values of accuracy in classifica-
tion and in prediction are compared. In classification,
the features relate d to activity sequence, extracted as
described in Session 4.2, are c lassified, while in pre-
diction we con sider the classification of features rela-
ted to unknown clips.
The Tables 4 and 5 show the values of accuracy fo r
each signals and c ombinatio ns o f all of them. For ex-
ample, if we con sid er the accur acy values of video fe-
atures, in Table 4, we can see that, with a linea r kernel,
we obtain an accur a cy value of 66.67% in classifica-
tion and a value of 60% in p rediction; if w e combine
video features with acceleration data, for instance, the
values are 70% in classification and 68.33% in pre-
diction. These results suggest two conclusions. The
first is tha t, as it is easily und erstandable, the values
of accuracy in classification a re higher than those in
prediction, but not so much higher, therefore it is pos-
sible to anticipate the future ac tion. The second is that
most o f the information comes fr om the video, but if
we combine video with another signal, such as ac ce-
leration, the value of accuracy increases. The same
conclusions are obtained with K-NN classifier.
5.3 Siamese Network
Our goal is to predict the label of the next action by
observing only data before the activity starts. Our ba-
seline suggests that it is necessary to fill the gap bet-
ween the accuracy of c la ssification and that of the pr e-
diction. As discussed in pr evious section 4, we consi-
der a Siamese network for our purpo se. Two different
architecture s are used: Multilayer Perceptron and a
1D CNN. The interesting point is that with a 1D CNN
we can consider three convolutional layers therefore
our output has dimension of 1860 while w ith a MLP
we have only two layers and the output size is 3 000.
Table 6 and Table 7 show the results of the Siamese
network. The tables list the obtained accuracy with
K-NN and SVM classifier both for classification and
anticipation. With a Siamese Network composed by a
Multilayer Perceptron, results on anticipation a re not
so good and are even worse, in most cases, than those
obtained by the baseline. This could be due to the dif-
ficulty of the MLP to learn from a very tiny dataset.
More in details, the number of parameters of the net-
work (7434x4 000x3000) is too big with respe ct to the
dataset size. Table 7 shows r esults obtained by trai-
ning the considered classifiers on the representation
learned through a Siamese Network, by exploiting a
1D convolutional layer architecture.
Action Anticipation from Multimodal Data
159

Table 6: Siamese Network Results considering a MultiLayer P erceptron architecture.
KNN
Classification Prediction
k Baseline Siamese Baseline Siamese
weights=uniform weights=distance weights=uniform weights= distance weights=uniform weights= distance weights =uniform weights= distance
1 60% 60% 58.33% 58.33% 53.33% 53.33% 55% 55%
3 65% 61.67% 60% 60% 58.33% 61.67% 55% 55%
5 63.33% 63.33% 58.33% 58.33% 61.67% 60% 55% 55%
7 63.33% 65% 56.67% 56.67% 60% 60% 53.33% 53.33%
9 58.33% 63.33% 56.67% 56.67% 56.67% 58.33 % 53.33% 53.33%
SVM
Linear Kernel RBF Linear Kernel RBF Linear Kernel RBF Linear Kernel RBF
70% 68.33% 58.33% 46.67% 68.33% 68.33% 55% 56.67%
Table 7: Siamese Network Results considering a 1D CNN architecture.
KNN
Classification Prediction
k Baseline Siamese Baseline Siamese
weights=uniform weights=distance weights=uniform weights= distance weights=uniform weights= distance weights =uniform weights= distance
1 60% 60% 50% 50% 53.33% 53.33% 55% 55%
3 65% 61.67% 50% 53.33% 58.33% 61.67% 51.67% 58.33%
5 63.33% 63.33% 55% 55% 61.67% 60% 63.33% 66.67%
7 63.33% 65% 55% 58.33% 60% 60% 63.33% 65%
9 58.33% 63.33% 55% 60% 56.67% 58.33 % 58.33% 65%
SVM
Linear Kernel RBF Linear Kernel RBF Linear Kernel RBF Linear Kernel RBF
70% 68.33% 71.67% 65% 68.33% 68.33% 60% 60%
The best values of accuracy are obtained with K-
NN for k equals 5 and k equals 7. Indeed , if we
compare the acc uracy values of our baseline in the
Table 7 for k = 5 and weights=distan c e, we have
63.33% for classification, 60% for prediction whereas
the Siamese network overcomes these values obtai-
ning a 66.67% of accuracy. For k=7, results show that
the accuracy value with a Siamese network is equal
to 6 5%, in other words, the same value of accur acy
obtained for classification baseline. It is also interes-
ting to note that the representation generated b y the
Siamese Network is n ot suitable in this case for clas-
sification task; in fact, accuracy ac hieved in classifi-
cation is quite lower than that of the simple baseline.
This could be due to the fact that the Siamese network
has been trained to solve the c hallenge of ma king re-
presentations of features of ”Unknown” sequence and
next ”Activity” very clo se in the embe dding space
with few samples. The results achieved with the SVM
classifier do not reac h the accuracy of the b a seline.
6 CONCLUSION
This work presents preliminary results o n action an-
ticipation from multimodal data. In particu la r, the
Stanford-ECM Dataset has been considered to ad-
dress the problem. We compared the performances
of different architecture and classifiers. Our prelimi-
nary results su ggest that mu lti- modality imp roves
both classification and prediction, but we couldn’t
deeply take advantage of deep learning approaches
on multi-modal data due to a very limited dataset for
training the methods. Future works could b e aimed to
improve the overall pip e line in order to fill the gap be-
tween classification and prediction performances and
to test algorithm on bigger multimodal datasets, spe -
cifically built with th e aim of addressing prediction
and anticipation.
ACKNOWLEDGEMENTS
This research is supported by STMicro electronics and
Piano della Ricerca 2016-2 018 Linea di Intervento 2
of DMI, University of Catania. We also thank the aut-
hors of (Nakamura et al., 2017) for providing the ori-
ginal Stanford-ECM dataset.
REFERENCES
Aytar, Y., Vondrick, C., and Torralba, A. (2017).
See, hear, and read: Deep aligned representations.
abs/1706.00932.
Bishop, C. M. (2006). Patter Recognition and Machine Le-
arning (Information Science and Statistics). Springer-
Verlag, Berlin, Hei delberg.
Bromley, J., Guyon, I., LeCun, Y., S¨ackinger, E., and Shah,
R. (1993). Signature verification using a ”siamese”
time delay neural network. In Proceedings of the 6th
International Conference on Neural Information Pro-
cessing Systems, pages 737–744, San Fr ancisco, CA,
USA. Morgan Kaufmann Publishers Inc.
Chan, F.-H., Chen, Y. -T., Xiang, Y., and Sun, M. (2017).
Anticipating accidents in dashcam videos. In Lai,
S.-H., Lepetit, V., Nishino, K., and S ato, Y., editors,
Asian Conference on Computer Vision, pages 136–
153, Cham. Springer International P ublishing.
VISAPP 2019 - 14th International Conference on Computer Vision Theory and Applications
160

Damen, D., Doughty, H., Farinella, G. M., Fidler, S., Fur-
nari, A., Kazakos, E., Moltisanti, D., Munro, J., Per-
rett, T., Price, W., and Wray, M. (2018). Scaling ego-
centric vision: The epic-kitchens dataset. European
Conference on Computer Vision.
Deng, J., Dong, W., Socher, R., Li, L. J., Li, K., and Fei-Fei,
L. (2009). Imagenet: A large-scale hierarchical image
database. In IEEE Conference on Computer Vision
and Pattern Recognition, pages 248–255.
Duarte, N., Tasevski, J., Coco, M. I., R akovic, M., and
Santos-Victor, J. (2018). Action anticipation: Reading
the intentions of humans and robots. IEEE Robotics
and Automation Letters, abs/1802.02788.
Furnari, A., Battiato, S., Grauman, K ., and Farinella, G. M.
(2017). Next-active-object prediction from egocentric
videos. Journal of Visual Communication and Image
Representation, 49:401 – 411.
Gao, J., Yang, Z., and Nevatia, R. (2017). RED: reinfor-
ced encoder-decoder networks for action anticipation.
British Machine Vision Conference, abs/1707.04818.
Hadsell, R., Chopra, S., and LeCun, Y. (2006). Dimensio-
nality reduction by learning an invariant mapping. In
IEEE Computer Society Conference on Computer Vi-
sion and Pattern Recognition (CVPR’06), volume 2,
pages 1735–1742.
Kiranyaz, S., Ince, T., and Gabbouj, M. (2016). Real-time
patient-specific ecg classification by 1-d convolutional
neural networks. IEEE Transactions on Biomedical
Engineering, 63(3):664–675.
Koch, G., Zemel, R., and Salakhutdinov, R. (2015). Sia-
mese neural networks for one-shot image recognition.
In ICML Deep Learning Workshop.
Koppula, H. S., Jain, A., and Saxena, A. (2016). cipatory
planning for human-robot teams. In Experimental Ro-
botics: The 14th International Symposium on Experi-
mental Robotics.
Koppula, H. S. and Saxena, A. (2016). Anticipating human
activities using object affordances for reactive robo-
tic response. IEEE Trans. Pattern Anal. Mach. Intell.,
38(1):14–29.
Lan, T., Chen, T.-C., and Savarese, S. (2014). A hierar-
chical representation f or future action prediction. In
European Conference on Computer Vision – ECCV,
pages 689–704, Cham. Springer International Publis-
hing.
Lee, S.-M., Yoon, S. M., and Cho, H. (2017). Human acti-
vity recognition from accelerometer data using convo-
lutional neural network. In IEEE International Confe-
rence on Big Data and Smart Computing (BigComp),
pages 131–134.
Ma, S., Sigal, L., and Sclaroff, S. (2016). Learning activity
progression in lst ms for activity detection and early
detection. In IEEE Conference on Computer Vision
and Pattern Recognition (CVPR), pages 1942–1950.
Mainprice, J. and Berenson, D. (2013). Human-robot colla-
borative manipulation planning using early prediction
of human motion. In IEEE/RSJ International Confe-
rence on Intelligent Robots and Systems, pages 299–
306.
Nakamura, K. , Yeung, S., Al ahi, A., and Fei-Fei, L. (2017).
Jointly learning energy expenditures and activities
using egocentric multimodal signals. In IEEE Con-
ference on Computer Vision and Pattern Recognition
(CVPR), pages 6817–6826.
Ngiam, J., Khosla, A., Kim, M., Nam, J., Lee, H., and Ng,
A. Y. (2011). Multimodal deep learning. In Procee-
dings of the 28th International Conference on Interna-
tional Conference on Machine Learning, pages 689–
696, USA. Omnipress.
Pirsiavash, H. and Ramanan, D. (2012). Detecting activities
of daily living in first-person camera views. In IEEE
Conference on Computer Vision and Pattern Recogni-
tion, pages 2847–2854.
Song, S., Cheung, N., Chandrasekhar, V., Mandal, B., and
Lin, J. (2016). Egocentric activity r ecognition with
multimodal fisher vector. abs/1601.06603.
Srivastava, N. and Salakhutdinov, R. (2014). Multimodal
learning with deep boltzmann machines. Journal of
Machine Learning Research, 15:2949–2980.
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Angue-
lov, D., Erhan, D., Vanhoucke, V., and Rabinovich, A.
(2015). Going deeper with convolutions. In The IEEE
Conference on Computer Vision and Pattern Recogni-
tion (CVPR), pages 1–9.
Torre, F. D., Hodgins, J. K., Montano, J., and Valcarcel,
S. (2009). Detailed human data acquisition of kit -
chen activities: the cmu-multimodal activity database
(cmu-mmac). In CHI 2009 Workshop. Developing
Shared Home Behavior Datasets to Advance HCI and
Ubiquitous Computing Research.
Wu, T., Chien, T., Chan, C., Hu, C., and Sun, M. (2017).
Anticipating daily intention using on-wrist motion
triggered sensing. Intenational Conference on Conm-
puter Vision, abs/1710.07477.
Action Anticipation from Multimodal Data
161
