
Active Object Search with a Mobile Device
for People with Visual Impairments
Jacobus C. Lock, Grzegorz Cielniak and Nicola Bellotto
Lincoln Centre for Autonomous Systems (L-CAS), University of Lincoln, Lincoln, U.K.
Keywords:
Active Vision, Object Search, Visual Impairment, Markov Decision Process.
Abstract:
Modern smartphones can provide a multitude of services to assist people with visual impairments, and their
cameras in particular can be useful for assisting with tasks, such as reading signs or searching for objects
in unknown environments. Previous research has looked at ways to solve these problems by processing the
camera’s video feed, but very little work has been done in actively guiding the user towards specific points
of interest, maximising the effectiveness of the underlying visual algorithms. In this paper, we propose a
control algorithm based on a Markov Decision Process that uses a smartphone’s camera to generate real-
time instructions to guide a user towards a target object. The solution is part of a more general active vision
application for people with visual impairments. An initial implementation of the system on a smartphone was
experimentally evaluated with participants with healthy eyesight to determine the performance of the control
algorithm. The results show the effectiveness of our solution and its potential application to help people with
visual impairments find objects in unknown environments.
1 INTRODUCTION
It is estimated that almost half a billion people wor-
ldwide live with mild to severe visual impairments
or total blindness (Bourne et al., 2017) and signifi-
cant effort is being made to enable these people to
lead more independent lives. Modern improvements
in mobile computing power and image processing
techniques have provided researchers with new and
powerful tools to solve this problem. The work pre-
sented here is part of a project to assist people with
visual impairments to navigate and find objects in
unknown environments with the aid of a smartphone.
The proposed system implements ideas from the field
of active vision (Bajcsy et al., 2017), but replaces the
typical electro-mechanical actuators of a moving ca-
mera with the body (i.e. arm, hand) of the user hol-
ding the smartphone, as pictured in Figure 1, expan-
ding upon concepts originally proposed in (Bellotto,
2013) and (Lock et al., 2017).
The goal of our active search system is to under-
stand the user’s surroundings and determine what the
next best course of action is to reach the target object
based on what is currently within view and what has
been observed in the past. To this end, we implemen-
ted a smartphone guidance system based on a Mar-
kov Decision Process (MDP) (Bellman, 1957) that
Figure 1: The system in use during an experiment.
generates, in real-time, a series of instructions for the
user to point to the target, depending on a previously-
learned spatial distribution of known objects and on
the camera’s current view. This work includes three
main contributions:
• an MDP-based human controller that can guide a
user in a visual search task;
• a data-based transition model for the MDP which
includes spatial relations between known objects;
• a set of user experiments that prove the effective-
ness of our active search implementation.
Section 2 discusses other relevant work done in
476
Lock, J., Cielniak, G. and Bellotto, N.
Active Object Search with a Mobile Device for People with Visual Impairments.
DOI: 10.5220/0007582304760485
In Proceedings of the 14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2019), pages 476-485
ISBN: 978-989-758-354-4
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

this field, followed by a general explanation of the
active vision system for human guidance in Section 3,
and a detailed explanation of the human-control mo-
dule in Section 4. The experimental results are pre-
sented in Section 5, after which we conclude the pa-
per and discuss future work in Section 6.
2 PREVIOUS WORK
Assistive technology for people living with visual im-
pairments is a growing research area (Manduchi and
Coughlan, 2012; Khoo and Zhu, 2016). In recent ye-
ars, the increase in mobile processing power and com-
puter vision improvements have led to research in the
use of smartphone cameras to augment or enhance
a user’s vision and help them find objects or other
points of interest. Earlier attempts at the problem in-
volved placing special markers or barcodes around an
environment, which the user then scans with a smartp-
hone or similar mobile device (Gude et al., 2013; Ian-
nizzotto et al., 2005; Manduchi, 2012). This device
then uses some feedback mode, e.g. Braille or sound,
to guide the user towards the target.
Another approach is to discard tags completely
and rely on computer vision to perform the object
detection, something that has become more practi-
cal with recent improvements to feature detectors and
deep networks (Huang et al., 2017; Redmon et al.,
2016). SIFT and SURF-based object detectors have
also been used to detect known objects, when they are
in the camera’s view, and to guide the user to them
using sonified instructions (Schauerte et al., 2012).
These type of systems is more flexible than the tag-
based ones, but it has the same drawback of being
passive, in the sense that it relies on having the object
within the camera’s view in the first place. Also, no
clear performance metrics are reported in the previous
paper. The VizWiz system (Bigham et al., 2010) of-
floads the object recognition tasks to an Amazon Me-
chanical Turk worker who then provides feedback on
where the object of interest is located relative to the
user. The VizWiz has the advantage of being fairly
robust and is able to classify a great deal of objects
with little effort from the user and can provide natural,
human-generated and curated directions. However,
this approach does not enhance user independence,
since a person with visual impairments is now behol-
den to an online worker instead of a relative, friend or
bystander. Furthermore, a good internet connection
is required on the device, possibly limiting its use in
some poor-reception areas.
Previous researchers have implemented active se-
arch and perception strategies in robots and image
classifiers (Bajcsy et al., 2017) in an attempt to op-
timise their classification and planning tasks, for ex-
ample by exploiting the structured nature of human
environments and object placements. Two research
teams have recently implemented an active object se-
arch strategy into their image classifiers (Caicedo and
Lazebnik, 2015; Gonzalez-Garcia et al., 2015). Their
approaches use different methods but conceptually si-
milar models to generate windows of interest for vi-
sual classification. The size and locations of the win-
dows within the image are generated using the spatial
relationship between objects, taken from the SUNCG
and PASCAL datasets (Song et al., 2017; Everingham
et al., 2010), and are iteratively changed based on the
output from the respective models. The advantage of
their approaches is that fewer windows are genera-
ted and submitted to the classifier, resulting in lower
object classification times while still keeping state-of-
the-art results for accuracy.
Similar strategies have been incorporated on robo-
tic platforms to improve autonomous object search,
manipulation and localisation tasks. For example,
some researchers have developed a planning algo-
rithm for a robotic manipulator that performs an op-
timal object search in a cluttered environment (Dogar
et al., 2014). Another team implemented an MDP ge-
nerating an optimal object search strategy in a room
over a belief state of object positions and configurati-
ons (Aydemir et al., 2011). However, the authors trai-
ned their MDP using a custom object-placement and
configuration scenario, so their results are sensitive to
changes within this distribution.
In summary, much research has been conducted
on recognition of and guidance towards target objects,
including active vision solutions for image classifiers
and robotic systems. However, to our knowledge, no
previous work has been done on active object search
and guidance for humans, which would especially be-
nefit people with visual impairments. In this paper,
we implement such an active vision system with a hu-
man in the loop that guides the user towards an out-
of-view target object. Our system exploits prior kno-
wledge of the objects spatial distribution within an
indoor environment, learned from a dataset of real-
world images, and the history of past object observa-
tions made during the search.
3 ACTIVE VISION SYSTEM
The work presented in this paper is a fundamental step
towards a more general project’s goal to develop a
stand-alone system that can guide a person with visual
impairments to his/her destination with minimal user
Active Object Search with a Mobile Device for People with Visual Impairments
477

Figure 2: System control loop: r is the reference object, e
the error signal, u and u
∗
the original and interpreted control
signals and y is the current object observation. K, H and P
are the control, human and sensor blocks respectively.
input or intervention. A complete system diagram is
given is Figure 2. This closed-loop system is con-
ceptually similar to other classical control problems,
where the difference between desired and actual state
of a process is used to generate a control signal that
changes the process itself.
In this case, the reference signal, r, is the object
the user wishes to capture with the smartphone’s ca-
mera. The goal of the control block, K, is to generate
human interpretable instructions, u, to guide the user
towards the target object. The process to be controlled
involves a human, H, who interprets the instruction
and executes a physical action, u
∗
, to actually mani-
pulate the smartphone’s camera, P. A new observa-
tion, y, with the camera is then fed back to the loop
and the error signal, e, is updated accordingly.
Here we focus in particular on the implementation
of the control module K. Two important points are
considered in the design of the controller. Firstly, K
must be scenario-agnostic, meaning that objects could
be placed in different places with unknown a pri-
ori information. Secondly, since each person could
interpret the instruction u differently (i.e. different
transformation block H), the controller must be ro-
bust enough to handle such incorrect interpretations.
For example, one person might interpret and execute
an ‘UP’ instruction correctly (i.e. u w u
∗
), while anot-
her might interpret it correctly, but execute the wrong
action. This risk can be mitigated by the use of clear
and simple instructions that helps u
∗
be as close as
possible to u. The implementation of this controller is
discussed in detail next.
4 HUMAN-CONTROL MODULE
Our active search system guides the user by genera-
ting a set of waypoints that need to be observed by the
camera, tracing a path that will eventually lead to the
target object. Note that the actual location of the latter
is unknown, meaning that the system will guide the
user towards the most likely location where the ob-
ject might be found, based on its internal knowledge
of spatial relations between objects (e.g. a computer
monitor is more likely to be above than below a desk).
This path is generated one waypoint at a time and is
updated with every new object observation captured
by the camera, or after a re-orientation of the latter
beyond a certain angle. We tackle the problem using
an MDP, the design and implementation of which are
discussed in the following sub-sections.
4.1 MDP for Human Control
An MDP produces a policy of optimal actions for an
agent to take in any given pre-defined state. In this
case, the agent is defined as the guidance system and
the policy is used to generate the next waypoint on
the search path towards the target object. We as-
sume fully observable states and known state transi-
tions probabilities. The MDP is represented by the
5-tuple
(S, A, T, R, γ), (1)
where S is a set of possible agent’ states, A is a set
of possible actions the agent can take in any given
state, T is a set of state transition probabilities from
state s to state s
0
, with s, s
0
∈ S, and R is the reward
the agent receives for reaching state s
0
after executing
action a ∈ A in state s. The scalar γ is a discount fac-
tor that prioritises immediate over long-term rewards
and which affects the model’s convergence rate (Rus-
sell and Norvig, 2009). Each of these elements are
defined and discussed next.
4.1.1 States
The state is a combination of parameters that defines
the agent’s world and decision process. Our state vec-
tor is defined as
s = ho, n, vi, (2)
where o is the current object in viewed by the camera,
n is the number of steps taken since the search started,
and v is a binary variable that keeps track of whether
a waypoint for the current state was already generated
during the current object search.
4.1.2 Actions
The policy produced by an MDP defines the action
the agent will take when it finds itself in any given
state. In this case, the action is the direction of the
next waypoint relatively to the current device’s pose.
The possible actions are given by
A = {UP, DOW N, LEFT, RIGHT }. (3)
VISAPP 2019 - 14th International Conference on Computer Vision Theory and Applications
478

Figure 3: Example of action policies generated by the MDP
to guide the user in pointing the camera from a random star-
ting object (e.g. monitor) to a target object (e.g. mug).
To illustrate an example of actions sequence, let us
consider the scene in Figure 3, which contains a num-
ber of simple, distinct objects (red boxes). The MDP
guides the user in pointing the camera to the target ob-
ject (the mug at the bottom-left of the figure). It does
this by inferring the current state, which depends on
the object currently observed by the camera, and ge-
nerating an action, or instruction, that leads the user to
the target object. An action is considered completed,
and therefore a new state reached, when the camera
has rotated more than a predefined angle or a new ob-
ject is detected.
4.1.3 State Transition Probabilities
The state transition T defines the probability of the
agent switching from state s to state s
0
due to action a,
i.e. the probability of observing object o
0
after object
o due to a pan/tilt rotation of the camera. Therefore, T
represents the spatial relationships between the diffe-
rent objects in our environment model. These spatial
relationships are learned from a dataset during an ini-
tial training process, which is discussed more in detail
in Section 4.2.1.
4.1.4 Reward Function
The reward R is the immediate reward that the agent
receives after transitioning from state s to state s
0
. The
goal of the agent is to maximise its cumulative reward
and it is very important to fine-tune R correctly for
producing an effective action policy. In order to en-
courage the agent to find the target object as fast as
possible, a relatively large positive reward should be
assigned for successfully reaching the goal state, and
a negative one in any other case. These parameters
must be finely balanced to ensure effective object se-
arch behaviour.
4.2 System Implementation
This section describe the actual implementation de-
tails of the MDP for active object search, inclu-
ding initial training and software deployment on our
smartphone device.
4.2.1 MDP Training
A policy that defines the optimal action for an agent
to take for any given state is generated through a trai-
ning process that involves letting the agent explore
the entire state-space and iteratively improve its de-
cision function, i.e. policy, in order to reach the target
state in a way that maximises its cumulative reward.
This method, called Q-learning (Watkins and Dayan,
1992), does not require a model of the agent’s en-
vironment during training, allowing the policy to be
used in many different scenarios.
Currently there are 7 objects encoded into the sy-
stem, plus a ‘nothing’ instance where nothing of note
is observed. Our initial implementation considers a
simple office desk scenario containing the following
objects:
o ∈ O = {monitor, mouse, keyboard, window,
mug, stationery, desk, nothing}.
(4)
The spatial relationships between the objects in
O are extracted from the OpenImage dataset (Krasin
et al., 2017), which consists of 1.74M images con-
taining 14.6M manually drawn and labelled bounding
boxes around objects (see Figure 4 for some exam-
ples). The dataset is primarily aimed toward object
recognition researchers to benchmark their models. In
our case though, the bounding boxes and object labels
are used to extract the spatial relationships between
the different objects in O. Since the camera perspecti-
ves and absolute distances between the objects in the
images are not given, we can only extract the relati-
onships in the basic action terms specified in A, e.g.
we can only say that object 1 is above object 2, but not
how far above. Our relatively simple action-space is
therefore suitable for the limited dataset information.
Figure 5 shows the spatial relationship between a
subset of O (desk, keyboard and mouse). For exam-
ple, when the agent is in state s = ho = mouse, n, vi
and is searching for the object o
target
= keyboard,
there is a strong probability that the target object is on
the mouse’s LEFT . The MDP of course will consider
all of the objects’ spatial relationships when genera-
ting the optimal policy.
The agent’s target state is then any state where
s = ho = o
target
, n, vi. This gives a total of 14 termi-
nal states (7×2) per policy, since the target object can
Active Object Search with a Mobile Device for People with Visual Impairments
479

Figure 4: Examples of images from the OpenImage dataset
containing objects from our set O (Krasin et al., 2017).
be found at any point in the search or in a position
that was previously explored by the user. Each target
object has its own unique policy file.
The reward function was hand-crafted and the pa-
rameters were empirically selected. The function va-
lues can be found in Table 1. The reward punishes
the agent for every step it takes without finding the
target object. The reward becomes increasingly nega-
tives as the agent progresses without finding the tar-
get (n > n
max
) or when it generates the same waypoint
more than once (v = true) during the same search.
Conversely, it gives a significant positive reward when
the target object is found.
Figure 5: Examples of the spatial relationships between
the desk, keyboard and mouse objects. Each square corre-
sponds to the probability of executing an action (top square
for UP, left square for LEFT , etc.)
Table 1: The reward functions for the MDP.
r(o = o
target
) 10000
r(v = true) -10
r(n > n
max
) -10
otherwise r(·) -1
We force the MDP to generate a maximum of 11
(inclusive) steps to the target, with 11 being the lon-
gest possible route on the action grid (more details
about the grid are in Section 4.2.2). A search could
take longer than 11 steps, but the MDP considers that
the maximum, which is convenient for keeping a ma-
nageable state-space and a simple reward function.
The MDP therefore has a total of 154 reachable states
(s
tot
= 11 × 7 × 2).
The lack of absolute spatial information in the
OpenImage dataset generates ambiguities, which ma-
kes it hard for the model to converge to a single, opti-
mal solution. We therefore opted to use the more con-
servative state-action-reward-state-action (SARSA)
algorithm (Rummery and Niranjan, 1994). SARSA
is an on-policy algorithm that allows us to control the
level of exploration vs. exploitation that makes it ea-
sier to find a solution, although this is not guaranteed
to be optimal.
The MDP is trained until it converges to the opti-
mal policy, or for a total of approximately 17 million
episodes. The parameter α, which controls the ex-
ploration vs. exploitation behaviour during training,
maximises the exploration when set to 1 and the ex-
ploitation when 0. We therefore set α to be a function
of the training episodes, starting with a high explora-
tion value and exponentially changing to exploitation
VISAPP 2019 - 14th International Conference on Computer Vision Theory and Applications
480

as the training progresses:
α = exp
−i
10 s
tot
− 0.001, (5)
where i is the episode index. The discount factor γ is
set to 0.95 to prioritise long-term rewards and guaran-
tee convergence.
Our MDP has a relatively small state-action space.
Therefore, a solution can be found within a reasona-
ble amount of time. However, it should be noted that
adjusting the angle interval, or adding more actions or
objects, can easily lead to an intractable space size.
4.2.2 Waypoints Generation
The system uses a 6×6 discretised radial grid to sim-
plify the tracking and waypoint generation processes.
The grid spans 120
◦
in both the pan and tilt dimen-
sions, giving a resolution of 20
◦
per grid cell. A po-
licy action is converted by the system into a new se-
arch waypoint centred on a cell of the radial grid, e.g.
an ‘UP’ action will generate a waypoint one grid cell
above the camera’s current orientation. Note that this
cell is not part of the MDP’ state and the radial grid is
only used to discretise the pan-tilt movements of the
camera and to guarantee a minimum angular variation
between subsequent actions.
The system uses the waypoint’s location to pro-
vide the user with guidance instructions (i.e. u in Fi-
gure 2). The policy actions, and waypoints by exten-
sion, are relative to the current camera’s pan-tilt orien-
tation. The grid is also wrapped so, if the location of
a waypoint exceeds the 120
◦
limit, the same waypoint
is moved to the opposite side of the grid, effectively
limiting the search space to a 120
◦
×120
◦
area.
4.2.3 Smartphone Application
We incorporated the trained system into an app (see
Figure 6) for an Asus ZenPhone AR smartphone,
running Android 7.0, with Google’s augmented rea-
lity toolkit (ARCore), which provides the necessary
3D pose of the device. No further software or har-
dware modifications were required. This app is re-
sponsible for generating the guidance instructions and
tracking the camera sensor (K and P blocks in Fi-
gure 2) throughout a search session. Tracking the ca-
mera’s pose allows the app to infer the current state
and choose the optimal action to take next.
The system determines the state values for n
(number of search steps so far) and v (waypoint al-
ready visited or not) described in Section 4.1.1, by
recording the previous positions and waypoint loca-
tions. The camera provides the ID of the object cur-
rently within view, which is assigned to the state va-
Figure 6: A screenshot of the smartphone interface showing
an example of guidance instruction (down-left in this case)
towards a waypoint and the QR-object scanner area.
riable o. In the current implementation, we did not
use a real object detector, but we simulated it with 7
different QR codes, one for each unique object, and a
camera-based QR code scanner from Android’s ma-
chine learning API (MLKit). This simplification gua-
rantees full observability of the state and let us fo-
cus on the performance of the MDP-based controller
in the following experiments. Moreover, to speed up
the image processing and avoid scanning multiple QR
codes, we only used the central part of the camera’s
frame, which is 300 × 300 pixels. This choice also
defines the precision required in pointing the camera
towards the object (see Figure 6).
In a real application for people with visual impair-
ments, the position of the waypoint would be given to
the user by a set of audio or vibrotactile instructions.
However, since we are mainly interested in evaluating
the control algorithm of our system and not the inter-
face (K and not u), our current prototype generates
guidance instructions with four on-screen arrows (see
Figure 6). Obviously, this visual interface is only used
for debugging and experimental evaluation of the con-
troller, and it will be replaced by an opportune audio
interface, e.g. (Bellotto, 2013), at a second stage.
5 EXPERIMENTS
To evaluate our system, we designed a set of expe-
riments that determined how effective the MDP and
its policies are at guiding the user in an object search
task with the smartphone’s camera. Since the focus
of this work is on the algorithm for active object se-
arch, and not on the actual human performance, in the
following experiments the system was tested by parti-
Active Object Search with a Mobile Device for People with Visual Impairments
481

Figure 7: A snapshot of the environment used for the expe-
riments. Each QR code represents an object.
cipants without any significant visual impairment. As
explained in the previous section, this simplified the
experimental design, allowing us to use the smartp-
hone’s display for the guidance instructions.
5.1 Experimental Design
For the experiment, the MDP policies were integra-
ted into an Android application that uses the camera
to provide observation data and track the pose and
viewing direction. Guidance instructions towards the
waypoints were visualised on the screen, which the
participants were allowed to use. The experimental
environment mimicked a typical office desk layout
and contained 7 different objects (i.e. encoded QR co-
des), one of which could be selected for each experi-
ment run. See Figure 7 for a snapshot of the environ-
ment.
For each experiment, the participant was placed
approximately at 1m from the closest barcodes and
was asked to remain on that spot during the experi-
ment. The participant started by pressing a button on
the app, which randomly selected a target object and
then guided the user towards it. Since the participants
were allowed to use the smartphone’s display, the tar-
get was randomly selected by the app without infor-
ming them, at least until it was found. This prevented
the participants from learning the target objects’ loca-
tions between subsequent runs of the experiment.
To avoid pointing at uncluttered edges of the se-
arch space, where the system had difficulty guiding
the user back to the centre, we set a search step-limit
of 15, which means the search was terminated when
the number of waypoints generated by the system ex-
ceeded 15. A search run therefore ended when the
participant either successfully found the target object
by pointing the phone camera to it and scanning the
barcode, or exceeded the waypoint limit. After this,
the participant then restarted from the central posi-
tion, generating a new random target object and repe-
ating the experiment.
Table 2: Results for the TAR, number of steps and time to
target means and standard deviations for each participant.
Participant TAR [%] Num. Steps Time [s]
s1 94 7.2 ± 5.4 29 ± 22
s2 79 6.7 ± 4.8 34 ± 5.1
s3 91 6.3 ± 4.9 31 ± 21
s4 79 6.7 ± 4.3 37 ± 5.6
s5 76 7.2 ± 4.9 33 ± 14
s6 60 8.2 ± 5.4 24 ± 10
s7 86 8.5 ± 5.8 31 ± 16
s8 88 5.1 ± 4.0 39 ± 21
s9 98 7.2 ± 5.4 39 ± 18
s10 67 6.6 ± 5.4 26 ± 12
We recorded 10 searches per object, giving us a to-
tal number of 70 search samples per participant. The
system was tested by 10 participants, mostly from our
research group. Our final dataset consisted therefore
of 700 search samples, which are analysed next.
5.2 Results
We identified 3 different measures to evaluate the sy-
stem’s performance: target acquisition rate (TAR),
number of steps to the target and the total time it took
to find a target object. We present and discuss the re-
sults for each of these parameters in the next sections.
The results for each individual participant are presen-
ted in Table 2, while those across all the participants
are shown in Table 3. To provide a baseline measure
for the ideal case, we ran a number of simulations in
an environment mimicking the experiment setup with
a “virtual” user who perfectly executes the policy, i.e.
u = u
∗
. The TAR and steps to target results for the
simulation are included in Table 3.
5.2.1 Target Acquisition Rate
The TAR is a measure of how successful the sy-
stem was at directing a participant to the target ob-
Table 3: The means and standard deviations for the entire
participant population for the experiments and simulations.
Experiments Simulations
TAR [%] 82 ± 11 99.7
Num. Steps 6.8 ± 5.1 5.4
Time [s] 34 ± 23 –
VISAPP 2019 - 14th International Conference on Computer Vision Theory and Applications
482
ject within our 15-step limit. It is simply calculated
as a ratio between the number of completed searches
vs. the total number of searches. Please note, howe-
ver, that this ratio depends also on the step-limit and
should not be taken as an absolute measure of perfor-
mance (i.e. if the step limit was much bigger, the TAR
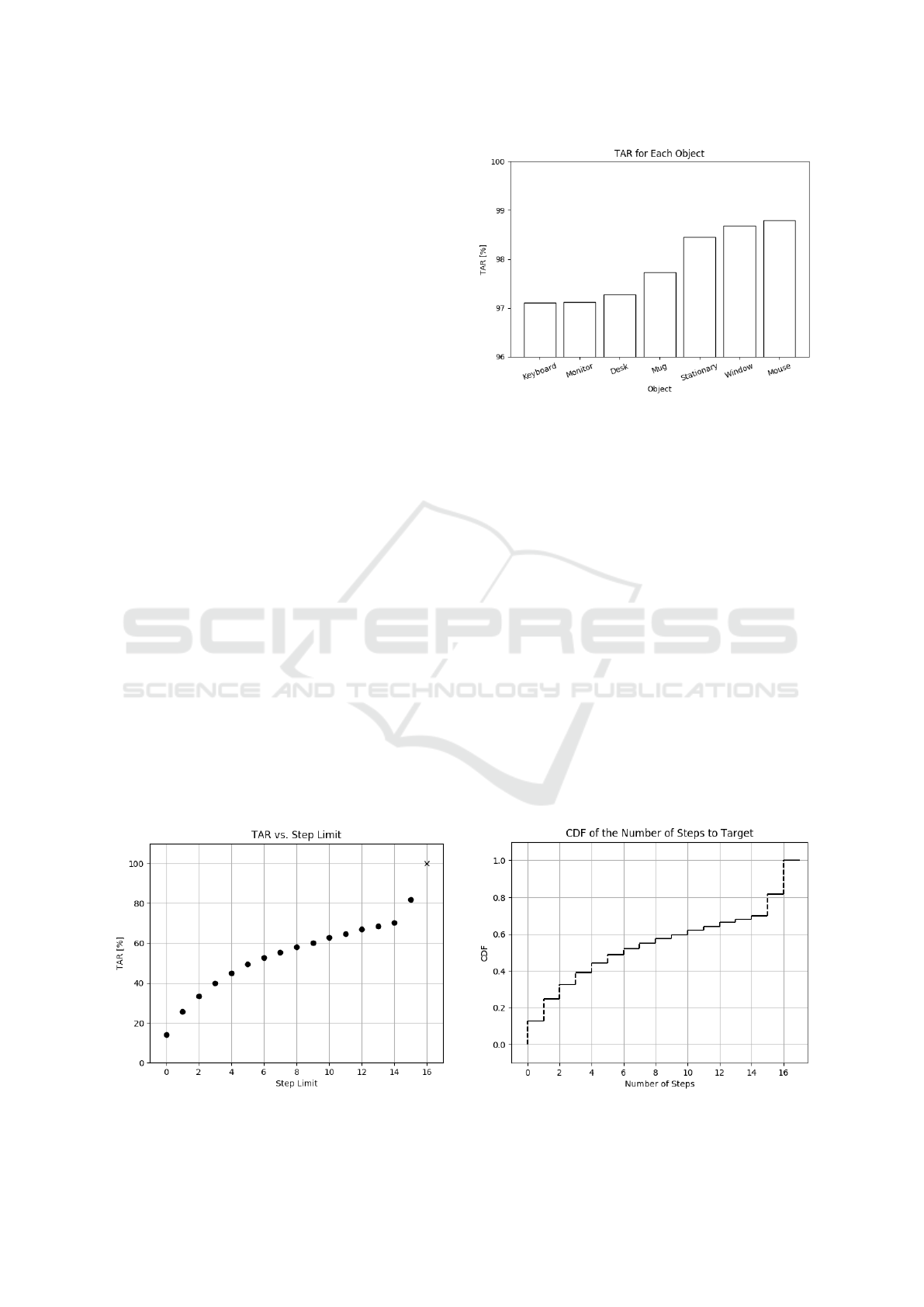
would tend to 100%). Figure 8 shows the TAR as a
function of the step-limit and it shows that there is a
gradual increase in the TAR as the step limit increa-
ses, but tapers off as the step-limit increases.
Table 2 shows a fairly consistent spread for the
TAR across the participants. The inter-participant
spread in Table 3 (σ = 11%) is fairly significant, per-
haps indicating that the user’s search behaviour and
strategy affects the target acquisition performance,
but with an average TAR of 82%, it is clear that the
system successfully finds the target object during the
vast majority of searches.
Figure 9 shows the TAR for each object in our
set O. There are TAR variations for the different
objects, with the smaller objects typically being the
hardest to find. However, the differences are not ex-
treme and indicate that all the objects in O are roughly
equally hard to locate. This is also displayed in the si-
mulation’s TAR in Table 3, which could not achieve
100% because of the difficulty the agent had in fin-
ding the objects on the fringes of the environment.
Failure cases were typically caused by the system
entering a no-recovery state where the user was di-
rected into dead-space with no spatial information
(e.g. ceiling or wall section). In this case the system
could not observe useful clues to intelligently guide
the user. Possible improvements for future versions
of the algorithm would be to implement some fall-
back method that can detect a no-recovery state (e.g.
exceeding a set number of steps/time without any new
object observation) and guide the user back to a posi-
Figure 8: TAR as a function of the step limit for a search.
The ‘x’ indicates the cases that exceeded the 15-step limit.
Figure 9: The TAR for each of the objects within O.
tion where to restart the search.
5.2.2 Number of Steps to Target
The number of steps to the target indicates the number
of waypoints the system generated for the participant
during the guidance process. This is a good indication
of system performance, where less waypoints means
faster target acquisition and therefore better object se-
arch strategy. Figure 10 shows the cumulative distri-
bution of the number of steps to the target for all the
participants.
The number of waypoints each participant requi-
red is fairly evenly spread across all of the partici-
pants, with the majority of searches ending within
a few search steps. The population mean and stan-
dard deviation is 6.8 and 5.1 waypoints, respecti-
vely. This is a reasonable result, since most target ob-
jects were placed within approximately 4 grid squares
away from the participants’ initial looking directions.
The relatively high standard deviation is due to the
aforementioned no-recovery states and could be redu-
Figure 10: The cumulative distribution of the participants’
number of steps taken to find a target object.
Active Object Search with a Mobile Device for People with Visual Impairments
483
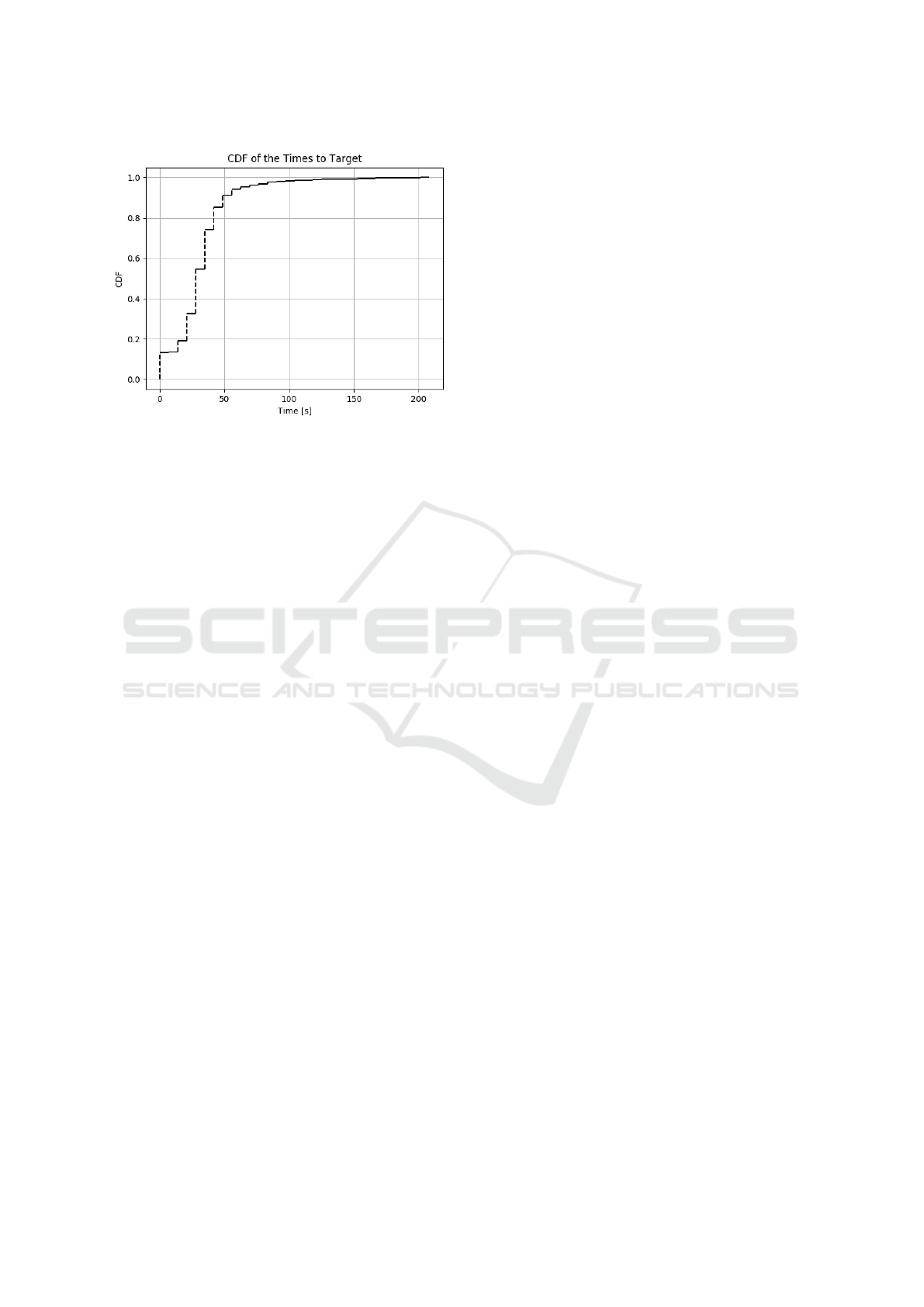
Figure 11: The cumulative distribution of the participants’
time taken to find a target object.
ced by opportune mitigation strategies to avoid unin-
formative areas.
5.2.3 Time to Target
The cumulative distribution of the time it took the
participants to reach the target object is given in Fi-
gure 11. We see that the distribution is heavily skewed
to the bottom with a long tail. The mean and standard
deviation of the data is 34s and 23s respectively.
In comparison to the remotely-assisted VizWiz sy-
stem (Bigham et al., 2010) covered in the related work
(mean 92s, standard deviation 37.7s), our results look
very encouraging, although there might be variations
in case of participants with visual impairments.
6 CONCLUSIONS
In this work we presented and tested an MDP-based
system to guide a person with visual impairments to-
wards a target object with no prior knowledge of the
environment. We implemented the system in an An-
droid app and tested it with sighted users to determine
the effectiveness of the active object search algorithm.
We found that it works generally well, even when
compared to alternative human-guided systems. Ho-
wever, the solution can be improved by refining the
search strategy and implementing an automatic fail-
state recovery when the user points to an empty sce-
nario, like a blank wall. Furthermore, a purpose-built
dataset with clear object spatial relations would ena-
ble the creation of a more accurate transition model
for the MDP controller.
Future work will include the replacement of the
QR codes with a real vision-based object detector,
possibly extending the number of items and actions.
However, in order to consider the uncertainty introdu-
ced by such detector, the MDP will have to be repla-
ced by a Partially Observable MDP (POMDP), taking
into account that the objects are not perfectly obser-
vable and humans might not follow the guidance in-
structions accurately. Further directions of research
include on-line learning techniques for model adapta-
tion that better follow the user profile of each indivi-
dual and the possible performance change over time.
REFERENCES
Aydemir, A., Sj
¨
o
¨
o, K., Folkesson, J., Pronobis, A., and Jens-
felt, P. (2011). Search in the real world: Active vi-
sual object search based on spatial relations. In Robo-
tics and Automation (ICRA), 2011 IEEE International
Conference on, pages 2818–2824. IEEE.
Bajcsy, R., Aloimonos, Y., and Tsotsos, J. K. (2017). Re-
visiting active perception. Autonomous Robots, pages
1–20.
Bellman, R. (1957). A markovian decision process. Journal
of Mathematics and Mechanics, pages 679–684.
Bellotto, N. (2013). A Multimodal Smartphone Interface
for Active Perception by Visually Impaired. In IEEE
SMC International Workshop on Human Machine Sy-
stems, Cyborgs and Enhancing Devices (HUMAS-
CEND).
Bigham, J. P., Jayant, C., Miller, A., White, B., and Yeh,
T. (2010). Vizwiz:: Locateit-enabling blind people
to locate objects in their environment. In Computer
Vision and Pattern Recognition Workshops (CVPRW),
2010 IEEE Computer Society Conference on, pages
65–72. IEEE.
Bourne, R. R., Flaxman, S. R., Braithwaite, T., Cicinelli,
M. V., Das, A., Jonas, J. B., Keeffe, J., Kempen, J. H.,
Leasher, J., Limburg, H., et al. (2017). Magnitude,
temporal trends, and projections of the global preva-
lence of blindness and distance and near vision im-
pairment: a systematic review and meta-analysis. The
Lancet Global Health, 5(9):e888–e897.
Caicedo, J. C. and Lazebnik, S. (2015). Active object loca-
lization with deep reinforcement learning. In Procee-
dings of the IEEE International Conference on Com-
puter Vision, pages 2488–2496.
Dogar, M. R., Koval, M. C., Tallavajhula, A., and Srinivasa,
S. S. (2014). Object search by manipulation. Autono-
mous Robots, 36(1-2):153–167.
Everingham, M., Van Gool, L., Williams, C. K. I., Winn,
J., and Zisserman, A. (2010). The pascal visual ob-
ject classes (voc) challenge. International Journal of
Computer Vision, 88(2):303–338.
Gonzalez-Garcia, A., Vezhnevets, A., and Ferrari, V.
(2015). An active search strategy for efficient object
class detection. In Proceedings of the IEEE Confe-
rence on Computer Vision and Pattern Recognition,
pages 3022–3031.
VISAPP 2019 - 14th International Conference on Computer Vision Theory and Applications
484

Gude, R., Østerby, M., and Soltveit, S. (2013). Blind navi-
gation and object recognition. Laboratory for Compu-
tational Stochastics, University of Aarhus, Denmark.
Huang, J., Rathod, V., Sun, C., Zhu, M., Korattikara, A., Fa-
thi, A., Fischer, I., Wojna, Z., Song, Y., Guadarrama,
S., et al. (2017). Speed/accuracy trade-offs for mo-
dern convolutional object detectors. In IEEE CVPR,
volume 4.
Iannizzotto, G., Costanzo, C., Lanzafame, P., and La Rosa,
F. (2005). Badge3d for visually impaired. In Compu-
ter Vision and Pattern Recognition-Workshops, 2005.
CVPR Workshops. IEEE Computer Society Confe-
rence on, pages 29–29. IEEE.
Khoo, W. L. and Zhu, Z. (2016). Multimodal and alternative
perception for the visually impaired: a survey. Journal
of Assistive Technologies, 10(1):11–26.
Krasin, I., Duerig, T., Alldrin, N., Ferrari, V., Abu-El-
Haija, S., Kuznetsova, A., Rom, H., Uijlings, J.,
Popov, S., Kamali, S., Malloci, M., Pont-Tuset,
J., Veit, A., Belongie, S., Gomes, V., Gupta, A.,
Sun, C., Chechik, G., Cai, D., Feng, Z., Nara-
yanan, D., and Murphy, K. (2017). Openima-
ges: A public dataset for large-scale multi-label and
multi-class image classification. Dataset availa-
ble from https://storage.googleapis.com/openimages/
web/index.html.
Lock, J., Cielniak, G., and Bellotto, N. (2017). Portable na-
vigations system with adaptive multimodal interface
for the blind. AAAI Spring Symposium.
Manduchi, R. (2012). Mobile vision as assistive technology
for the blind: An experimental study. In International
Conference on Computers for Handicapped Persons,
pages 9–16. Springer.
Manduchi, R. and Coughlan, J. (2012). (Computer) Vi-
sion Without Sight. Communications of the ACM,
55(1):96–104.
Redmon, J., Divvala, S., Girshick, R., and Farhadi, A.
(2016). You only look once: Unified, real-time object
detection. In Proceedings of the IEEE conference on
computer vision and pattern recognition, pages 779–
788.
Rummery, G. A. and Niranjan, M. (1994). On-line Q-
learning using connectionist systems, volume 37. Uni-
versity of Cambridge, Department of Engineering
Cambridge, England.
Russell, S. and Norvig, P. (2009). Artificial Intelligence: A
Modern Approach. Prentice Hall.
Schauerte, B., Martinez, M., Constantinescu, A., and
Stiefelhagen, R. (2012). An assistive vision system for
the blind that helps find lost things. In International
Conference on Computers for Handicapped Persons,
pages 566–572. Springer.
Song, S., Yu, F., Zeng, A., Chang, A. X., Savva, M., and
Funkhouser, T. (2017). Semantic scene completion
from a single depth image. IEEE Conference on Com-
puter Vision and Pattern Recognition.
Watkins, C. J. C. H. and Dayan, P. (1992). Q-learning. Ma-
chine Learning, 8(3):279–292.
Active Object Search with a Mobile Device for People with Visual Impairments
485
