
Organizational Engineering Processes: Integration of the
Cause-and-Effect Analysis in the Detection of Exception Kinds
Dulce Pacheco
1 a
, David Aveiro
1,2 b
and Nelson Tenório
3 c
1
Madeira Interactive Technologies Institute, Funchal, Portugal
2
Faculdade de Ciências Exatas e da Engenharia, University of Madeira, Funchal, Portugal
3
Instituto Cesumar de Ciência, Tecnologia e Inovação (ICETI), Maringá, Paraná, Brazil
Keywords: Causal Analysis, Ishikawa Diagram, Organizational Change, Organizational Engineering, Organizations.
Abstract: Enterprises are dynamic systems that struggle to adapt to the constant changes in their environment. The
complexity of these systems frequently originates inefficiencies that turn into the loss of resources and might
even compromise organizations’ viability. Control and G.O.D. (sub)organizations allow enterprises to specify
measures and viability norms that help to identify, acknowledge, and handle exceptions. Organizational
engineering processes are deployed to treat dysfunctions within the G.O.D. organization but often fail to
eliminate or circumvent the root cause of it. In this paper, we propose an extension in the model to allow a
thorough investigation of the root causes of dysfunctions within the organizational engineering processes.
Grounded on the seven guidelines for Information System Research in the design-science paradigm, we claim
that the organizational engineering process should be supplemented with a systematic and broader
investigation of causes, namely the Ishikawa approach of cause-and-effect analysis. The main contributions
of this paper are the improvement of the organizational engineering process for handling unexpected
exceptions in reactive change dynamics and the freely available Dysfunctions Bank with common
dysfunctions and its probable causes. This work should trigger a reduction in the number of organizational
dysfunctions and help to keep updated the organizational self and the organization’s ontological model.
1 INTRODUCTION
Organizations are dynamic systems that run in
complex and ever-changing environments. The
competitiveness of the global economy in the 21
st
century requires effective enterprises that can
continuously adapt. Organizations try to respond to
these changes by increasing self-awareness, by better
structuring their procedures, and by implementing
better information systems, especially in critical
processes. Still, unexpected exceptions (problems)
are common. Therefore, workers spend a large
amount of their working time handling unexpected
exceptions (Aveiro, 2010), which makes it an
expansive process that may even compromise the
viability of the whole enterprise (Aveiro, 2010;
Aveiro et al., 2010; March, 1999; Saastamoinen and
White, 1995).
a
https://orcid.org/0000-0002-3983-434X
b
https://orcid.org/0000-0001-6453-3648
c
https://orcid.org/0000-0002-7339-013X
Determining why a system is performing poorly
is a key task within organizations, but it also
represents one of the major challenges posed by
unstructured systems (Smith, 1998). The complexity
to detect the cause might be related to the fact that a
single cause can have multiple effects and an effect
can also have various causes (Ishikawa, 1986).
Having a model that includes a systemic approach to
the investigation of the root cause of the unexpected
exceptions and the registration of the organizational
knowledge related to it, may represent noteworthy
savings when handling future exceptions and be the
foundation of a more effective organization. We
argue that the integration of the cause-and-effect
analysis (Ishikawa, 1986) in the processes of
organizational engineering within the G.O.D.
Organization (Aveiro, 2010) may bring significant
advances to enterprises’ competitiveness.
This work starts by reviewing the literature
connected to enterprise ontology models in the scope
Pacheco, D., Aveiro, D. and Tenório, N.
Organizational Engineering Processes: Integration of the Cause-and-Effect Analysis in the Detection of Exception Kinds.
DOI: 10.5220/0008364904790486
In Proceedings of the 11th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2019), pages 479-486
ISBN: 978-989-758-382-7
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
479

of the Enterprise Engineering discipline, and related
work on the analysis of causes. Then we present our
proposal, detail the application of the model and
conclude with comments on future work.
2 RELATED WORK
Previous researchers refer that the function
perspective of an organization is associated with the
aspect of behavior (Dietz, 2006). However, recent
views over the function perspective of an
organization represent it as a more complex and
dynamic model (e.g., Aveiro, 2010). The normative
aspect refers to the existence of commonly expected
values (that is, norms) for the vital proprieties of the
system (Aveiro, 2010). A deviation from such norms
implies a state of dysfunctions that may compromise
the viability of an organization (Aveiro, 2010).
Therefore, dealing with malfunctions is also another
central aspect of the function perspective, especially
when it changes the organization artifacts (Aveiro,
2010). An organization artifact (OA) is “a construct
of an organization like a business rule (e.g., if invoice
arrives, checklist of expected items) or an actor role
(e.g., library member)” (Aveiro et al., 2011, p. 17).
Current developments in the discipline of
Enterprise Engineering [namely the models of the
Control Organization (CO) and the G.O.D.
Organizations (Generation, Operationalization and
Discontinuation Organization; GO)] come to include
the concepts of organizational change and
development into the DEMO (Design & Engineering
Methodology for Organizations) framework, as the
current notions in DEMO do not fully address the
issue of change (Dietz, 2006).
2.1 Organizational Dysfunctions and
Dynamics of Reactive Change
Organizational dysfunctions are deviations of the
organizational norms, either by not complying with
the current rule or by not meeting with what is
expected (Christensen and Bickhard, 2002). The
viability of the organization will depend on a timely
and adequate response to such dysfunctions (i.e.,
incidents) (Aveiro, 2010; Pacheco and Aveiro, 2019).
Organizations can deal with these dysfunctions with
reactive change strategies to eliminate or circumvent
that event. Reactive change dynamics may be
implemented either by resilience or by microgenesis
strategies (Aveiro, 2010).
Malfunctions are quite frequent and the handling
of these exceptions can take almost half of the total
working time (Saastamoinen and White, 1995).
Therefore, handling and recovering from
dysfunctions is an expensive organizational process
(Saastamoinen and White, 1995), even though most
management teams do not realize it. The Complex
Adaptive Systems (CAO) theory advocates that, to
solve new exceptions, rule pieces that constitute
current resilience strategies may be reused in reactive
change strategies (Aveiro et al., 2011; Holland,
1996). Information on the history of organizational
change is an asset in moments where change is again
needed (Aveiro et al., 2011) as it can make the change
management processes more effective (Aveiro et al.,
2011). However, previous studies show that
information regarding the handling of past exceptions
is seldom registered (Saastamoinen and White, 1995)
and quickly lost, as actors can easily forget the
sequence of tasks they have executed to handle an
exception a few months back.
The main causes which are identified in the
literature for not changing both the organizational
reality and the ontological model of the organization
that undergo change processes are two (Aveiro et al.,
2011; March, 1999; Saastamoinen and White, 1995):
Firstly, the absence of explicit representation of the
specific exceptions and actions that were executed for
handling the dysfunction and which organizational
artifacts where engineered to solve the malfunction
(Saastamoinen and White, 1995); Secondly, the
removal of human agents from a certain
organizational actor role which had established and
tacitly memorized specific (i.e., informal) rules to
handle particular exceptions occurring in such actor
role (Saastamoinen and White, 1995). If the
organization misses to capture the reactive change
dynamics and insert it in its reality and ontological
model it will result that, over time, the organization
will be less aware of itself and less prepared to deal
with change (Aveiro et al., 2011).
2.2 The Control Organization and the
G.O.D. Organization
It is argued that both the CO and the GO exist in every
organization and those are responsible for handling
the reactive change processes (Aveiro, 2010). The CO
and GO allow the modeling of the function
perspective of an organization as a DEMO based
design artifact (Aveiro, 2010; Aveiro et al., 2011,
2010).
If the dysfunction is expected, adequate resilience
strategies should exist already and the CO can deploy
them to eliminate or circumvent the causes (Aveiro,
2010; Aveiro et al., 2011; Christensen and Bickhard,
KEOD 2019 - 11th International Conference on Knowledge Engineering and Ontology Development
480

2002). The ontological model of the CO is the
conceptualization of a generic organization
considered to exist in every enterprise and responsible
for controlling its viability (Aveiro et al., 2011). That
is, the ontological model of the CO is a default subset
of the ontological model of every organization
(Aveiro, 2010; Aveiro et al., 2011).
If no applicable rules exist to deal with one
specific dysfunction, it is considered to be an
unexpected exception (Aveiro, 2010; Aveiro et al.,
2011). In this last case, a microgenesis strategy is
applied by the GO, starting an organizational
engineering process (OEP) to identify the root cause
of the dysfunction and the necessary acts to adjust the
OA and eliminate or circumvent the unexpected
exception (Aveiro, 2010; Aveiro et al., 2011),
changing the organizational self (Aveiro, 2010). This
type of exceptions must be solved with human
intervention and with innovative OA (Mourão and
Antunes, 2007). An OEP can be initiated for two
different reasons: because there is no associated and
known expected exception causing the dysfunction;
or because all resilience strategies have been tried
without success (Aveiro, 2010). In the OEP, there is
an intertwining play between three major categories
of acts: unexpected exception handling acts, OA state
changes and OA operationalization acts (Aveiro,
2010). Based on previous work (Mourão and
Antunes, 2007), Aveiro argues that all OEP starts
with the detection of an unexpected exception, that is
monitored and leads to a diagnostic (Aveiro, 2010;
Mourão and Antunes, 2007). Recovery actions may
be applied to eliminate or circumvent the unexpected
exception (Aveiro, 2010; Mourão and Antunes,
2007). In this sense, the primary purpose of the GO is
to preserve an updated organizational self and an
updated ontological model (Aveiro, 2010).
The responsibilities for the handling and follow
up of OEP should be clear (Mourão and Antunes,
2007) so that actors can stay accountable for their
decisions. According to Aveiro (2010), the actor role
‘handler of the OEP’ is crucial, as s/he coordinates the
several acts needed to change the organizational self,
either by the operationalization or discontinuation of
OA, as shown in the Actor Transaction Diagram (see
Aveiro, 2010, p. 120). The Object Fact Diagram of
OEP, under the GO, presents its classes, fact types,
and results (see Aveiro, 2010, p. 115), while the
Monitoring, Diagnosis, Exception and Recovery
Table (MDERT) consolidates the information of the
dysfunction monitoring, as well as its diagnosis (see
Aveiro, 2010, p. 117).
2.3 Analysis of Causes
To accurately detect the root cause, a detailed
assessment of the dysfunction and exception is
required (Mourão and Antunes, 2007). The diagnosis
should be an iterative process where different actors
may collaboratively contribute (Mourão and Antunes,
2007). To aid in the handling of current unexpected
exceptions, the organization should keep the record
of past monitoring, diagnosis and recovery facts.
During the diagnosis phase, the responsible agent
should review past dysfunctions related to that same
viability norm or to other norms that might have
suffered from similar exception kinds (Aveiro, 2010).
A consultation with actors that have been previously
involved in the monitoring and diagnosis of akin
dysfunctions might also help (Aveiro, 2010). The
actor's perception over the exception may change
along the iterative process of diagnostic, especially
when new facts are uncovered (Mourão and Antunes,
2007). The diagnosis, usually performed by the agent
responsible for the OEP, should collect the
information needed to detect the root cause of the
exception (Aveiro, 2010). The monitoring phase
includes the necessary actions to control the progress
of the OEP, making sure that updated information
about the exception is available to the agents that need
it (Aveiro, 2010; Mourão and Antunes, 2007).
Consequently, monitoring actions might bring
environmental information to the system (Mourão
and Antunes, 2007). During and after the diagnosis,
actors may implement different recovery actions, as
new data is obtained (Mourão and Antunes, 2007).
The information about applied recovery actions
should be kept (Mourão and Antunes, 2007). Based
on the information collected in the diagnosis phase, a
bundle of OA is generated, operationalized (or
discontinued) and approved, to solve the exception
handled by the OEP (Aveiro, 2010).
Authors argue that the concept of root cause seeks
to prevent a diagnosis from stopping too quickly
(Smith, 1998), but it should not be taken too far, as
well. Hence, it is argued that detecting the root cause
is to identify where effective action can be taken to
prevent dysfunction recurrence (Smith, 1998). The
literature presents different frameworks to detect root
causes of exceptions (Bilsel and Lin, 2012; Ishikawa,
1986; Smith, 1998). The cause-and-effect diagram by
Ishikawa is one of the most popular frameworks
(Bilsel and Lin, 2012), as it recognizes that an effect
can have more than one cause and that one cause can
provoke more than one effect. The cause-and-effect
diagram allows to group causes by categories,
Organizational Engineering Processes: Integration of the Cause-and-Effect Analysis in the Detection of Exception Kinds
481

contributing to a more structured and broader analysis
(Bilsel and Lin, 2012).
2.3.1 The Cause-and-Effect Diagram by
Ishikawa
The cause-and-effect diagram (also called Fishbone
or Ishikawa diagram) was created under the discipline
of Quality Control, by Kaoru Ishikawa (1986), in the
early 1940s, as one of the seven basic tools for quality
control. That is a problem-solving tool that helps to
systematically investigate and analyze all the real or
potential causes of the exceptions (Bilsel and Lin,
2012; Ishikawa, 1986). The diagram can be built
collaboratively, allowing to combine diverse
expertise and skills (Bilsel and Lin, 2012).
Furthermore, it sets the focus on the causes of the
problem and omits complaints or other irrelevant
discussions (Bilsel and Lin, 2012). Its format allows
an easy graphical grasp of the unexpected exception
and causes (Bilsel and Lin, 2012). On the other side,
the cause-and-effect diagram does not conveniently
represent the interrelations among different causes,
does not differentiate the strength of the various
causes and can become visually disordered (Bilsel
and Lin, 2012). This diagram is more effective when
the analysis is focused on a particular exception, as it
will narrow down the scope of the analysis (Smith,
1998).
The cause-and-effect diagram is usually pictured
with four to six main categories of causes that lead to
the problem (Bilsel and Lin, 2012). The most
common representation includes the categories of
equipment, process, people, materials, environment,
and management (see Figure 1). However, other
categories may also be included, more related to the
business sector or the goal of the analysis (e.g.,
methods, machine, measurement, employee,
suppliers, skills, systems, product, promotion, policy)
(Bilsel and Lin, 2012; Ishikawa, 1986; Smith, 1998).
Figure 1: Example of a cause-and-effect diagram.
The cause-and-effect diagram starts by clearly
identifying the problem (Bilsel and Lin, 2012). Then,
the agent responsible for finding the root cause should
brainstorm, with the main actors involved in that
dysfunction, what could have been the probable or
real causes for that exception. At this stage it is
important to keep asking, in a string of questions and
answers, ‘why did this happen’ until getting to the
root cause, that is, identifying where effective action
can be taken to prevent that exception to occur again
(Smith, 1998). After determining the leading causes
(real or potential) and categorizing them, the actors
need to review the full list, plan and deploy the
necessary actions to eliminate or circumvent the
exception (Smith, 1998).
3 DETECTION OF EXCEPTION
KINDS: THE
CAUSE-AND-EFFECT
ANALYSIS
Aveiro (2010) specifies that an actor must be
designated to handle the OEP and, consequently,
monitor, diagnosis, and identify the root cause.
However, the author does not specify which
methodology the agent should follow for the
detection of the exception kinds. Other researchers
(Mourão and Antunes, 2007) attribute a classification
to the exceptional situations that take place in the
diagnosis and in the exception handling strategies but
focus solely on promptly defining recovery actions to
eliminate or circumvent the dysfunction, not in
detecting and eliminating the root cause of the
exception. In the GO, the choice of cause and the
choice of the solution are later qualitatively evaluated
in the Dysfunctions Diagnosis and Actions Table
(Aveiro, 2010), however, the criteria for this
evaluation is also not clear in the model. Furthermore,
in the examples provided in the literature (Aveiro,
2010; e.g., Aveiro et al., 2011), we can see that the
choice of cause is frequently evaluated as bad and that
dysfunctions reoccur. This may indicate that efforts
to solve the exceptions do not eradicate the root cause
behind the exception, that is, the OEP is inefficient.
This inefficiency might be related to an inappropriate
detection of the root cause, what might lead to
inadequate actions, as these acts are not directed to
eliminate the right exception kind. Consequently, the
reoccurrence of dysfunctions that have been poorly
handled in past OEPs is common. These repeated
dysfunctions bring extra costs to the organization
(e.g., costs in labor time, materials, customer
KEOD 2019 - 11th International Conference on Knowledge Engineering and Ontology Development
482

dissatisfaction, product replacement) that might even
compromise the viability of the whole organization
and that could have been avoided if the OEP deployed
after the first dysfunction occurrence was well
handled. Based on the literature, we propose to add to
the OEPs the cause-and-effect analysis by Ishikawa.
Considering the methodology of the seven guidelines
for Information System Research in the design-
science paradigm (Hevner et al., 2004), we
hypothesize that a more systematic and broader
approach to the analysis of the exception kinds may
lead to more accurate detection of causes and,
consequently, to the deployment of suitable actions to
eliminate or circumvent the exceptions, preventing its
reoccurrence.
The GO (Aveiro, 2010) claims that each
dysfunction has a single cause. Other authors have
focused their work in recovery acts to circumvent
problems, but without the focus on eliminating its
causes (Mourão and Antunes, 2007). If no acts are
defined to detect and eliminate the root cause of the
problem, most probably it will persist in time and
later on create new constraints within the
organization. Our approach entices actors to identify
more than a single cause for the dysfunction in more
than one category. This approach corroborates
previous authors who claim the miscellaneous nature
of causes and effects (Ishikawa, 1986).
For each ‘exception kind’, an ‘exception
category’ should be identified from the list of
standard categories, or by creating a new one, if none
of the existing applies. Enterprises frequently struggle
to identify the root cause of the exceptions. However,
there are common dysfunctions that may occur in
different enterprises that belong to the same industry.
Malfunctions connected to support areas (e.g.,
finance, human resources) may also be shared among
organizations from different economic sectors.
Therefore, to help in the continuous improvement and
to encourage benchmarking practices, the authors of
this model will gather a Dysfunctions Bank (DB) with
common dysfunctions, along with their probable
exception kinds and categories, that will be freely
available online. The information on the DB will be
collected through research and voluntarily supplied
by the enterprises that use this model.
To represent our framework, we have updated the
model of the GO, namely the Object Fact Diagram
(OFD) of the Fact Model and the Actor Transaction
Diagram (ATD) of the Construction Model. We argue
to create a new object class EXCEPTION
CATEGORY so that we can specify the category of
each exception kind. To keep a record of the original
fact resulting from the actions of this aspect of an
OEP, we have specified the associated binary fact
types and the unary result kinds:
[exception category] created in [exception kind]
[exception category] has been created
The OFD was also updated to include the new
class, fact type, and result (see Figure 2). The ATD
gains a new transaction kind that we call
categorization (see Figure 3). This new transaction
and corresponding executing actor role are associated
with the new result kind specified in the OFD (see
Figures 2 and 3).
In our model, following previous authors (Bilsel
and Lin, 2012), we advocate that the detection of
exception kinds should be an iterative process, where
different actors can collaborate and actively
contribute with their expertise and competencies
(Bilsel and Lin, 2012).
Figure 2: Proposal of new partial OFD of the GO (adapted from Aveiro, 2010, p. 115).
Organizational Engineering Processes: Integration of the Cause-and-Effect Analysis in the Detection of Exception Kinds
483
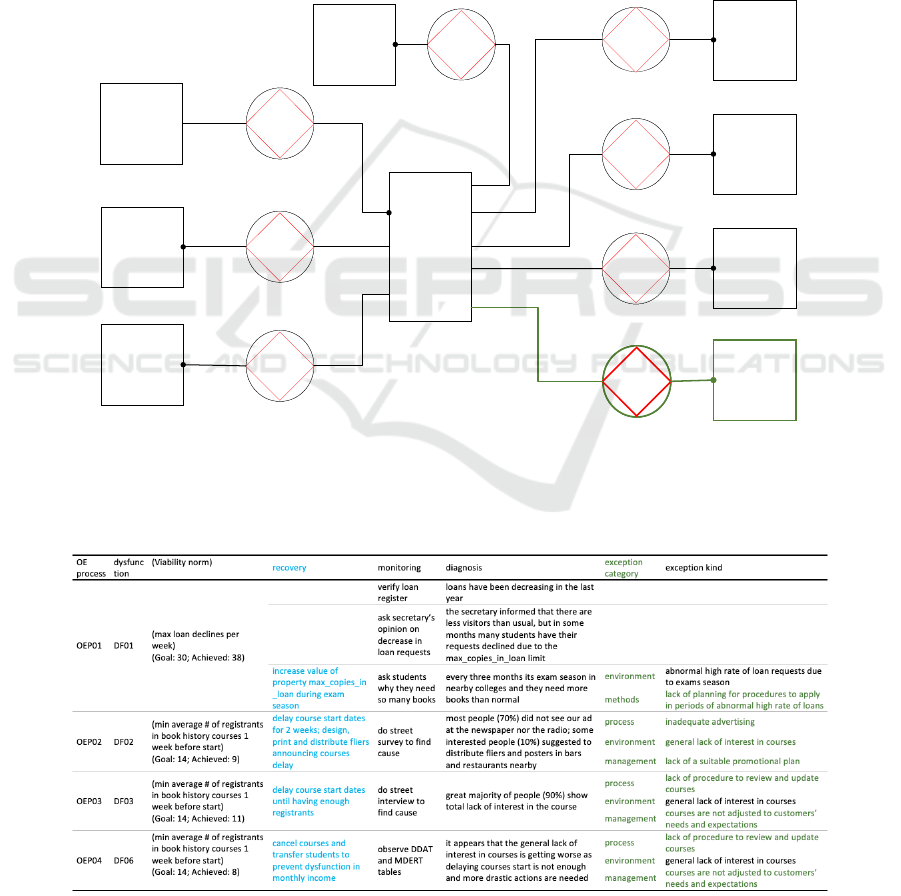
At this stage, to truly understand the situation and
detect its causes, experience and records play an
important role. As the actor gathers more information
about the unexpected exception, her/his perception
over the problem may change. Recovery strategies are
usually defined based on a quick analysis of the
dysfunction and without the previous detection of
causes. Consequently, recovery strategies should be
promptly deployed to minimize the risks and
circumvent the exception, while the investigation of
the causes is still on-going.
Data related to the unexpected exception is
gathered in the Monitoring, Diagnosis, Exception and
Recovery Table (MDERT), to which we propose some
changes. The column ‘recovery’ presents the strategies
that intend to circumvent the exception. Therefore, to
improve its readability, we advocate that the column
‘recovery’ should be moved to the left, to be just after
the ‘dysfunction’ (see Table 1). To register the
‘exception category’, we have added a new column,
just before the column ‘exception kind’ (see Table 1).
Each dysfunction can have more than one cause and
more than one category (see Table 1).
Figure 3: Proposal of new partial ATD of the GO (adapted from Aveiro, 2010, p. 120).
Table 1: Proposal of a new Monitoring, Diagnosis, Exception and Recovery Table (MDERT) of a library (adapted from
Aveiro, 2010, p. 117).
initiation
GT01
initiation
GT01
GA01
initiator
GA01
handler
escalation
GT02
escalation
GT02
GA02
new handler
recovery
GT06
recovery
GT06
GA06
recoverer
GA03
monitorer
GA04
diagnoser
monitoring
GT03
monitoring
GT03
diagnosis
GT04
diagnosis
GT04
detection
GT05
detection
GT05
GA05
detector
finishing
GT07
finishing
GT07
GA07
finisher
categorization
GT08
categorization
GT08
GA08
categorizer
KEOD 2019 - 11th International Conference on Knowledge Engineering and Ontology Development
484

We extended the literature by adding to the model
of the GO, a systematic and broader analysis of
causes. The main advantages of this approach are the
capability of reducing the re-occurrence of
dysfunctions, as the thorough analysis of causes
should eliminate the root cause of that specific
exception and even prevent other dysfunctions that
have not yet arisen. Consequently, it should lower
workers’ stress level and improve their well-being.
The Ishikawa cause-and-effect analysis suggests that
the actor thinks through the problem to identify the
different causes that might have caused the
malfunction, instead of focusing just on the most
immediate one, which brings a global view of the
effect and its causes. The actor then defines the
needed actions to eliminate or circumvent the
exception.
We have created this model to be accessible by
any enterprise worldwide. Therefore, our model does
not establish standard categories to classify the
identified causes, as it might create an extra layer of
complexity when applying this framework to
different organizations. Having the exception kinds
grouped by categories brings valuable insights to the
management teams, as it easily allows a global
analysis of the most common causes of dysfunctions
and, consequently, reveals what needs to be acted on
(e.g., if an enterprise has 40% of its exception kinds
in the category people it means that human resources
are making several mistakes and that should be
further investigate to be mitigated). This model of
including the analysis of cause-and-effect in the OEPs
can be both applied as a response to unexpected
exceptions (reactive change), but also in the OEPs
that aim to detect opportunities for improvement
(proactive change).
3.1 Model Application
We will use the MDERT (see Table 1) to demonstrate
the application of our model. It includes the fact
instances of the object classes and fact types for the
case of the library (adapted from Aveiro, 2010). To
facilitate the understanding of the data available in the
MDERT, we added the third column, ‘viability
norm’, from the Dysfunctions Table (adapted from
Aveiro, 2010, p. 106). To be easily distinguished, all
the information copied from the Dysfunctions Table
is in parenthesis.
An OEP is initiated because it was detected an
event that does not comply with the organizational
viability norm (DF01) and for which no resilience
strategy is yet defined. In the case of the library, for
the DF01, we can see that the viability norm
‘maximum loan declines per week’ had the goal of
30, but 38 were already registered (see Table 1).
Consequently, an agent started the OEP01 to handle
this dysfunction. The actor designated to handle the
OEP will start with the monitoring phase, namely by
observing the dysfunction and doing a quick
assessment. Based on this, the agent will define
recovery actions. In this application, the recovery
action defined for OEP01, as defined in Aveiro
(2010), was of increasing the number of loans
permitted over the exam season (see Table 1).
After the quick recovery actions, the actor
responsible for the OEP01 may focus on the
diagnosis. In this example, the agent concluded that
s/he should ‘ask students why they need so many
books’ and got to find out that nearby colleges usually
have an exam season every three weeks, which leads
students to request more books during that period.
The exception kind registered was ‘abnormal high
rate of loan requests due to exams season’.
Considering the model that we proposed in this paper,
we need to categorize this exception kind. Since the
abnormal books request is an external factor, we
propose to insert it in the category ‘environment’ (see
Table 1). Another addition of our model is that the
actors need to think through the exception and try to
find other causes for this problem. This is especially
important when the exception kind is external and,
consequently, the organization cannot do much to
circumvent it. In this example, the actor concludes
that there was another significant exception kind
under the category of ‘methods’, namely the ‘lack of
planning for procedures to apply in periods of
abnormal high rate of loans’. More categories and
exception kinds could be identified. On Table 1, we
can find other examples of causes and its categories
for DF02, DF03, and DF06.
With the information about the relevant exception
kinds, the actor may devise needed actions to
eliminate or circumvent these exception kinds and
report it to the management team. The information in
the MDERT must be transmitted to the higher levels
of the organization so they can be informed about the
dysfunctions being identified and the measures that
are implemented to overcome these exceptions.
Having the exception kinds grouped by categories
permits a broader view of the most frequent type of
exception kinds registered.
Organizational Engineering Processes: Integration of the Cause-and-Effect Analysis in the Detection of Exception Kinds
485

4 CONCLUSIONS AND FUTURE
WORK
The global economy demands more effective and
dynamic enterprises that can continuously adapt to
the changing environment, culture, technology, and
requirements. Enterprises try to respond to this
challenge by better structuring its internal
organization and increase its self-awareness, usually
with the help of complex information systems.
However, unexpected exceptions are common and
handling these exceptions can take almost half of the
total working time, which represents both a high cost
and a threat to the viability of the enterprise. Better
detection and management of this unexpected
exceptions should translate in financial savings, in a
lower stress level in workers, as the unforeseen
situations would be less frequent, and to keep updated
the organizational self and the organization’s
ontological model. This represents a significant
advance to the competitiveness of the enterprises.
This paper intends to contribute to the literature in
the disciplines of Enterprise Engineering and
Enterprise Ontology, by extending the current model
of the G.O.D. Organization to include a broader
analysis of exceptions kinds and, consequently,
contribute to higher effectiveness and viability of
organizations. The Dysfunctions Bank and the data
collected on the most common categories of
exception kinds are highly valuable to the
management team, as it allows them to deploy
focused actions to overcome these limitations. This
model can also be applied to both reactive and
proactive change dynamics, and it may be used by
any enterprise, of any industry and any location. This
framework offers important implications for practice
and the sustainable economic growth of the
organizations.
A key limitation of this model is the lack of
empirical proof. Authors plan to deploy a test pilot to
assess the validity of the model. The results of the
study will be evaluated in terms of choice of causes,
choice of solutions, and general performance.
ACKNOWLEDGMENTS
This work is supported by the Regional Development
European Fund (Interreg), project FIMAC MAC-
2.3d-181 (MAC-2014-2020).
REFERENCES
Aveiro, D., 2010. G.O.D. (Generation, Operationalization
& Discontinuation) and Control (sub)organizations: A
DEMO-based approach for continuous real-time
management of organizational change caused by
exceptions. Universidade Técnica de Lisboa.
Aveiro, D., Silva, A.R., Tribolet, J., 2010. Towards a
G.O.D. Organization for Organizational Self-
Awareness. In: Albani, A., Dietz, J.L.G. (Eds.), Lecture
Notes in Business Information Processing. Springer
Berlin Heidelberg, pp. 16–30.
Aveiro, D., Silva, A.R., Tribolet, J., 2011. Control
organization: A DEMO based specification and
extension. In: Albani, A., Dietz, J.L.G. (Eds.), Lecture
Notes in Business Information Processing. Springer
Berlin Heidelberg, pp. 16–30.
Bilsel, R.U., Lin, D.K.J., 2012. Ishikawa cause and effect
diagrams using capture recapture techniques. Qual.
Technol. Quant. Manag. 9, 137–152.
Christensen, W.D., Bickhard, M.H., 2002. The Process
Dynamics of Normative Function. Monist 85, 3–28.
Dietz, J.L.G., 2006. Enterprise ontology: Theory and
methodology. Springer, Leipzig, Germany.
Hevner, A.R., March, S.T., Park, J., Ram, S., 2004. Design
science in information systems research. MIS Q. 28,
75–105.
Holland, J.H., 1996. Hidden Order: How Adaptation Builds
Complexity. Basic Books, New York, NY, USA.
Ishikawa, K., 1986. Guide to Quality Control, 2nd Revise.
ed. Asian Productivity Organization, Tokyo, Japan.
March, J.G., 1999. The pursuit of organizational
intelligence: Decisions and Learning in Organizations.
Blackwell Business, Cambridge, MA, USA.
Mourão, H., Antunes, P., 2007. Supporting effective
unexpected exceptions handling in workflow
management systems. Proc. 22nd Annu. ACM Symp.
Appl. Comput. 1242–1249.
Pacheco, D., Aveiro, D., 2019. Cause-and-Effect Analysis
in the Organizational Engineering Processes of the
G.O.D. Organization. In: Proceedings of the 19th
CIAO! Enterprise Engineering Working Conference
Posters. CIAO Network, Lisbon, Portugal.
Saastamoinen, H., White, G.M., 1995. On Handling
Exceptions. In: Comstock, N., Ellis, C. (Eds.),
Proceedings of Conference on Organizational
Computing Systems. ACM, New York, NY, USA, pp.
302–310.
Smith, G.F., 1998. Quality Problem Solving. ASQ Quality
Press, Milwaukee, Wisconsin.
KEOD 2019 - 11th International Conference on Knowledge Engineering and Ontology Development
486
