
Session Similarity based Approach for Alleviating Cold-start Session
Problem in e-Commerce for Top-N Recommendations
Ramazan Esmeli
1 a
, Mohamed Bader-El-Den
1 b
and Hassana Abdullahi
2 c
1
School of Computing, University of Portsmouth, Lion Terrace, Portsmouth, U.K.
2
School of Mathematics and Physics, University of Portsmouth, Lion Terrace, Portsmouth, U.K.
Keywords:
Cold-start Sessions, Recommender Systems, Session-based Recommender Systems.
Abstract:
Cold-Start problem is one of the main challenges for the recommender systems. There are many methods
developed for traditional recommender systems to alleviate the drawback of cold-start user and item problems.
However, to the best of our knowledge, in session based recommender systems cold-start session problem still
needs to be investigated. In this paper, we propose a session similarity-based method to alleviate drawback of
cold-start sessions in e-commerce domain, in which there are no interacted items in the sessions that can help
to identify users’ preferences. In the proposed method, product recommendations are given based on the most
similar sessions that are found using session features such as session start time, location, etc. Computational
experiments on two real-world datasets show that when the proposed method applied, there is a significant
improvement on the performance of recommender systems in terms of recall and precision metrics comparing
to random recommendations for cold-start sessions.
1 INTRODUCTION
Recommender Systems (RS) are widely used in many
digital platforms including e-commerce, video and
music since RS can help retrieve and recommend
most relevant items from massive item options. Al-
though RS are important, they suffer several setbacks.
For example, in the e-commerce domain, when a
user visits anonymously or visits without browsing
any item, providing product recommendations will
be challenging since there is little or no information
about the user. According to a dataset released by
DIGINETICA
1
, it is found that 62.3% of the users
are not registered in the system (Wu and Yan, 2017;
Esmeli et al., 2019a). This is known as cold-start
problem (Son, 2016). There are two types of cold-
start problems in RS (Son, 2016; Herce-Zelaya et al.,
2020), namely, cold-start item problem and cold-start
user problem. Cold-start item problem is when a new
item added to a system or database has few or no user-
new item interactions, while in cold-start user prob-
lem, a new user who is not registered to the system
a
https://orcid.org/0000-0002-2634-6224
b
https://orcid.org/0000-0002-1123-6823
c
https://orcid.org/0000-0003-2347-6848
1
http://diginetica.com/
starts browsing items or is a newly registered user
who has no previous history, making it difficult for
RS algorithms to identify this user’s preferences.
Generally, in cold-start item problems, content-
based approaches are preferred (Lika et al., 2014; An-
waar et al., 2018; Esmeli et al., 2019b). For example,
using items’ content features, similar items are ranked
and recommended. On the other hand, since it is not
easy to give specific product recommendations for the
cold-start user, random or most popular items are rec-
ommended(Son, 2016; Esmeli et al., 2020). There-
fore, in both cases, the accuracy of the RS can be low.
There are several approaches that have been proposed
to alleviate new user and item problems (Son, 2016;
Herce-Zelaya et al., 2020; Silva et al., 2019). Users’
demographic data (Son, 2016; Silva et al., 2019) is
the most commonly used data where similar users
are found using their demographic information and
items these users interacted are recommended for the
new user. Also, in some works (Safoury and Salah,
2013; Bouadjenek et al., 2016), user demographic la-
bels are matched with product features. For instance,
the match between Movie’s age group and user’s age
group products were recommended. Furthermore,
users’ account are associated with their social media
profiles (Carrer-Neto et al., 2012; Rosli et al., 2015;
Bouadjenek et al., 2016). In this case, their social
Esmeli, R., Bader-El-Den, M. and Abdullahi, H.
Session Similarity based Approach for Alleviating Cold-start Session Problem in e-Commerce for Top-N Recommendations.
DOI: 10.5220/0010107001790186
In Proceedings of the 12th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2020) - Volume 1: KDIR, pages 179-186
ISBN: 978-989-758-474-9
Copyright
c
2020 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
179

media accounts can provide useful information about
users preferences such as the pages, movies and books
they like, and these details can be used to create better
recommendations.
In this paper, we propose a method for solving
cold-start user problem for Session based RS(SBRS)
in e-commerce domain where no user prior informa-
tion is available. Our proposed method uses session
features such as the time session started, location de-
tails where users are connected to the website, the
platform they use (mobile or desktop platform), etc.
to find similar sessions. From these sessions, using
their last interacted item, we create product recom-
mendations. A final recommendation list is created
applying ”majority voting” (Aledo et al., 2017) ap-
proach from recommendation pool created from sim-
ilar sessions. Computational experiments show that
our proposed approach has improved performance of
RS when compared to random item RS. The main
contributions of this paper are as follows:
1. a framework for cold-start session is introduced.
2. majority voting based recommendation creation
process is designed.
3. proposed framework has been validated and com-
pared with random item recommendation using
two real-world datasets.
The remainder of the paper is organised as follows. In
Section 2, we present a literature review of the rele-
vant studies in e-commerce domain for solving cold-
start problems. Section 3 introduces the proposed
framework. Section 4 presents the comparative ex-
periments of the proposed framework involving two
real-world RS datasets. Finally, Section 5 draws con-
clusions and provides future research directions.
2 RELATED WORKS
In this section, we provide the most relevant works
related to cold-start problem in e-commerce domain.
As cold-start problems are the major problems of the
RS, they have gained a lot of attention from the sci-
entific community. Approaches for solving cold-start
problems can be grouped into three categories based
on the solution approach followed. These are: (i)
content-based approaches such as demographic infor-
mation or individual labels for items, (ii) approaches
that extract and use user’s external data (for example,
information from social media) and (iii) approaches
that use initial information provided by users.
Regarding content-based approach (Safoury and
Salah, 2013) designed a method that takes users’ de-
mographic information and movies’ attributes into
consideration to create a recommendation list based
on the similarity of these features. They aimed to re-
duce the impact of cold-start movie problem that have
little user interactions. Also, in (Lika et al., 2014), au-
thors used classification algorithms using users’ de-
mographic information in order to identify similar
users. Their proposed classification algorithms were
integrated into pure Collaborative Filtering (CF) algo-
rithms.
Moreover, in another work (Ralph et al., 2020)
user and item descriptions are mined to find relation-
ships between items and users. Relationships were
created by text mining (item, user descriptions) and
vectors for each document were created. These vec-
tors were used to find similar products for the new
user based on cosine similarity. Clustering is an-
other method applied for alleviating cold-start user
problem in CF (Pereira and Hruschka, 2015; Zhang
et al., 2013). Zhang et al. (2013) applied bi-clustering
that combines user and item features to associate like
minded users with items. For the association, they
predicted ratings for unrated items from like-minded
user clusters and similar item clusters. Pereira and Hr-
uschka (2015) designed a framework that combines
simultaneous co-clustering learning with CF in order
to alleviate new user problem. In their method, users’
demographic information was used for clustering pur-
pose.
Users’ external data such as social media data is
used to reduce the effect of cold-start problems (Sa-
hebi and Cohen, 2011; Castillejo et al., 2012; Tian and
Liang, 2017; Sedhain et al., 2014; Guy et al., 2010).
For example, Guy et al. (2010) trained a model using
Matrix Factorisation (MF) that learn latent factors for
social tags. These factors were used to find relevant
items for new users. Moreover, in (Tian and Liang,
2017) trust relationship in the social media is utilised,
in which users’ friends were categorised as trusted
users and based on their preferences, new recommen-
dations were created for the new user. Similarly, He
and Chu (2010) presented a method that takes a user’s
social media preferences and influence from friends
into account for alleviating cold-start user problem.
Lastly, using randomly collected user preferences
for new items is another approach for reducing the
effect of cold-start problem. An example of this ap-
proach can be seen in (Aharon et al., 2015). The au-
thors designed an online method that randomly asks
a group of user for their preferences for newly added
items. Based on the collected preferences, new items
are recommended to other like-minded users. Their
method showed a significant performance improve-
ment in terms of Root Mean Square Error (RMSE)
evaluation metric.
KDIR 2020 - 12th International Conference on Knowledge Discovery and Information Retrieval
180

2.1 Limitation of Previous Works and
Proposed Contributions
Previous works showed improvement on alleviating
cold-start problem when users and items have fea-
tures (tags, preferences, social media). However,
in e-commerce domain users can visit the website
anonymously or without any data description. Con-
sequently, SBRS suffers while providing product rec-
ommendations. In order to decrease the effect of cold-
start session problem in the e-commerce domain, we
propose a framework that can find most similar ses-
sions based on the session attributes (user location,
time user visited, device type, etc.) which does not
require any user input.
The framework provides recommendations for the
most similar sessions, and using majority voting strat-
egy, final recommendation list is created for the cold-
start session.
3 FRAMEWORK
In order to get more accurate product recommenda-
tions, a framework that utilises session features is de-
signed (Figure 1). Since in cold-start sessions, there
are no item interactions, identifying users’ exact in-
tention in the session is very challenging. However,
product recommendations can be estimated from ses-
sions that have similar features with cold-start ses-
sion. This framework helps to find the most similar
sessions and create a product recommendation pool
using the item interactions of these sessions. Based on
the majority voting method final recommendation list
is created. The reason for choosing majority voting
is to choose top n n ∈ {10, 20, 30}) high confidence
(high frequency) recommended items from similar
sessions.
The designed framework has three main steps.
These are;
1. Data preparation, which includes session log col-
lection and pre-processing. In pre-processing, the
sessions have less than two item interactions are
eliminated in order to have a meaningful RS mod-
els in the sense of creating item relation.
2. Second phase is designed for training the nearest
neighbour model that helps to find the most 20
similar sessions from train dataset when a set of
features is provided as input. Test dataset con-
sists of session logs created in the last week of
the whole duration of session logs. Also, in test
dataset interacted items are hidden where these
items are used for validation purpose. Also, the
features of each test session are used to find the
most similar sessions in train dataset.
3. Final phase of the framework is necessary for cre-
ating recommendation list using majority voting
method, in which top n (n ∈ {10, 20, 30}) high-
est number of appeared items in the recommen-
dations from each session are selected. In this
phase recommendations from similar sessions are
derived using different RS models. These are
Item-Item KNN, Random and Session Popular-
ity based recommendations. We use same pa-
rameter settings for these models, as explained
in (Hidasi et al., 2015). In these models, next
item recommendations are given based on the
last clicked item. After collecting recommenda-
tions from similar sessions and selecting most fre-
quented items, a final recommendation list is cre-
ated. Then the final created recommendation list
is evaluated with ground truth items in the test ses-
sion. Evaluation metrics used in this paper are re-
call and precision, which are very common in the
RS domain (Silva et al., 2019).
The details of the second and third phases of the
framework are presented in following subsections.
3.1 Training Nearest Neighbour Model
This step consists of feature selection to train the near-
est neighbour model and to find top n
s
nearest ses-
sions.
For the model training, we set n = 100 as neigh-
bours, and other parameters have remained as default
for the nearest neighbour algorithm as shown in
2
.
Selected features from session specifications are:
1. day of the week: This feature indicates which day
of the week the session has started.
2. hour of the day: Show the hour of the day the
session has started.
3. day of the year: This feature represents which day
of the year session started. This is important since
users in a specific season can look for a particular
group of items.
4. device type(mobile, desktop): Shows what kind
of platform user uses in order to visit the e-
commerce platform.
5. operator system: Shows the operating system the
device used to connect to e-commerce platform
uses such as Windows 10, IOS, Android, etc.
6. longitude: Shows longitude information of the lo-
cation that the user is connected from.
2
https://scikit-learn.org/stable/modules/neighbors.html
Session Similarity based Approach for Alleviating Cold-start Session Problem in e-Commerce for Top-N Recommendations
181
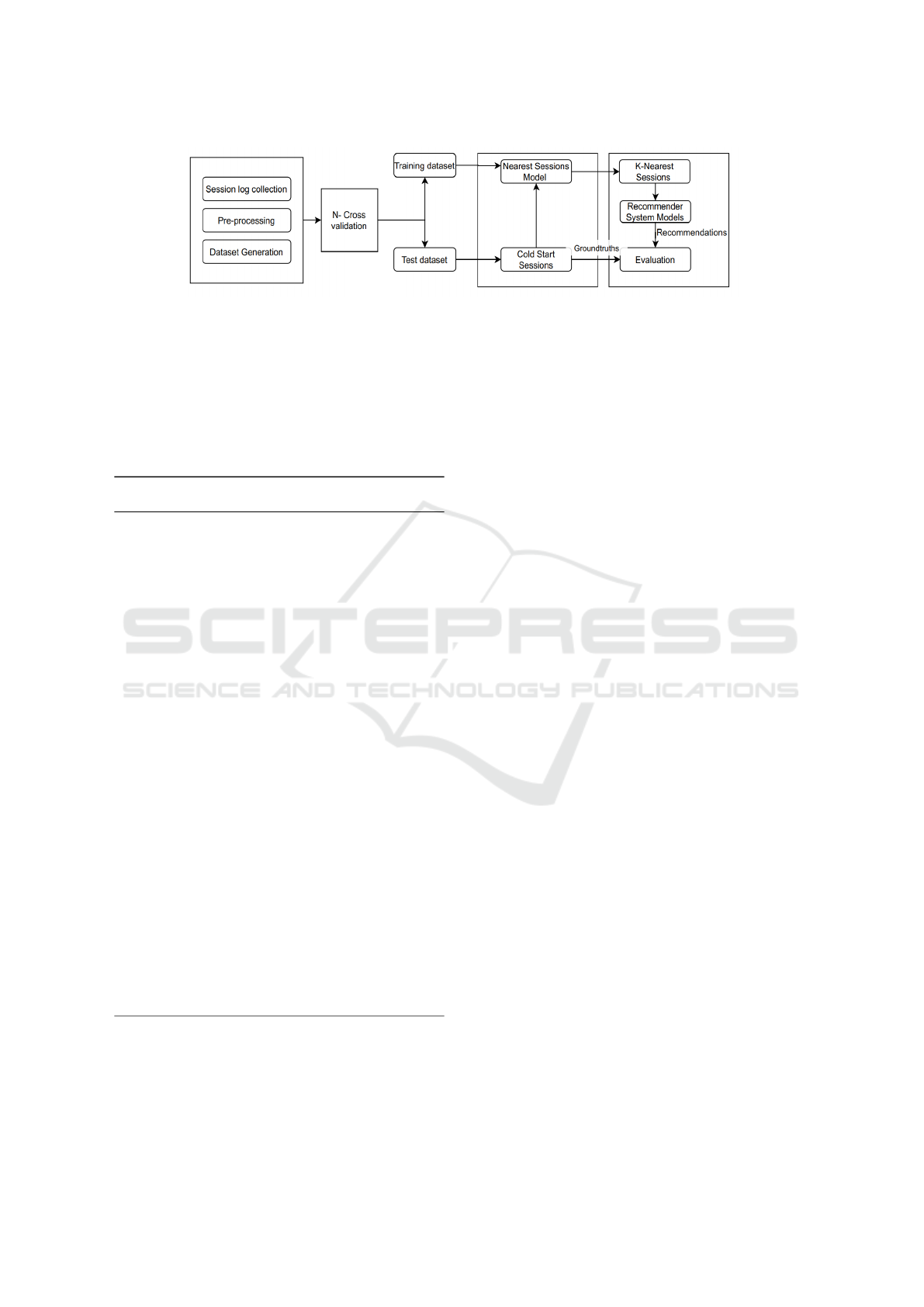
Figure 1: Framework for alleviating cold-start session problem.
7. latitude: Indicates latitude information of the lo-
cation that the user is connected from.
Except for longitude, latitude, day of the year and
hour of the day, other features are categorical. There-
fore in order to represent these features, one-hot en-
coding is applied. After applying one-hot encoding,
we have 34 features to represent each session. As
Algorithm 1: Hybrid approach for cold-start user session
problem.
dataset for training D.
dataset for testing T .
RS
M
= TrainModel(D) // Item-Item KNN and
Session Pop based models
NN = TrainNNModel(D) // Nearest Neighbour
model to find similar sessions
for each n
c
in N cross validation do
t = Selected Test Sessions // select 1000
sessions in each cross-validation iteration
for each s
s
in t do
GT
s
s
// ground truth items of s
s
S = NN(s
s
) // get N
s
∈ {10, 20, 30, 40}
similar sessions S based on feature of s
s
r = {}
for each s in S do
r
s
= RS
M
(s)
r = r ∪ r
s
// Collect recommended items
r
s
from each similar session s based on the
last clicked item of s
end for
r = Rank(r) // Rank recommendation List
based on Majority voting
r
f inal
// create final recommendation list by
top N ∈ {10, 20, 30} highest voted items.
Evaluate(r
f inal
, GT
s
s
)
evaluate using recall and precision metrics.
end for
end for
seen in Algorithm 1, after creating nearest neighbour
model, for each session we find n
s
∈ {10, 20, 30, 40}
most similar sessions S. These sessions are used as
seed sessions in order to retrieve product recommen-
dations r
s
with the last interacted item of each session.
This step is explained in detail in the next subsection.
3.2 Training Recommender System
Models and Creating Final
Recommendation List
In this paper, three different RS models are imple-
mented. These are Item-Item KNN, Session-Based
Popularity and Random RS models. In order to design
these models, we apply a similar approach to (Hidasi
et al., 2015). Also, the parameters for the models are
kept the same as shown in (Hidasi et al., 2015). We
give details of the parameters used in each RS model
as follows;
1. Random Based RS: This recommender model
does not get any special parameters.
2. Session Popularity Based RS: Session Popularity
predictor that gives higher scores to items with
higher number of occurrences in the session. Ties
are broken up by adding the popularity score of
the itemHidasi et al. (2015). We set top
n
= 100
for items in each session with top 100 highest
score.
3. Item-Item KNN based RS: This recommender
model gives prediction scores for a selected set of
items on how likely they are the next items in the
session. Parameters for this recommender model
are: n
sims
= 100 which indicates the number of
recommended items that only give back non-zero
scores to the n
sims
most similar items. lmbd = 20
is a regularisation parameter that exempts simi-
lar items with incidental co-occurrences. al pha =
0.5 is the cosine normalisation value that balances
the similarity between two items.
Train dataset is used in order to create RS mod-
els. For each session in the test dataset, most sim-
ilar sessions are found. One hundred recommended
items are retrieved and added to the recommendation
list pool by using last interacted item in each simi-
lar session. Final recommendation is created using
majority voting method, in which highest frequent
N(N ∈ (10, 20, 30)) items are selected as final recom-
mendation list.
KDIR 2020 - 12th International Conference on Knowledge Discovery and Information Retrieval
182
4 EXPERIMENTS AND RESULTS
We conduct a set of experiments to validate the per-
formance of our proposed framework on cold-start
sessions. For evaluation and comparison of our
method, we use two performance metrics based on
Item-Item KNN, and Random and Session Popularity
based models.
4.1 Dataset Specifications
In this paper, we use two real world datasets collected
from e-commerce platforms by a UK based personal-
isation company. For pre-processing, sessions which
have less than two item interactions are eliminated
to have better correlation between items. Table 1
shows the number of sessions, items and interactions
of datasets before and after pre-processing.
Table 1: Statistics about datasets.
Dataset #session #item #interaction
ds 1 2490591 10811 4892053
ds 2 1190897 2316 2211056
After Pre-processing
ds 1 461627 9605 2479139
ds 2 186239 2260 1052636
Since we use session features (time, day of the
week, operating system, etc.) in order to create ses-
sion similarities, we provide statistics about these fea-
tures.
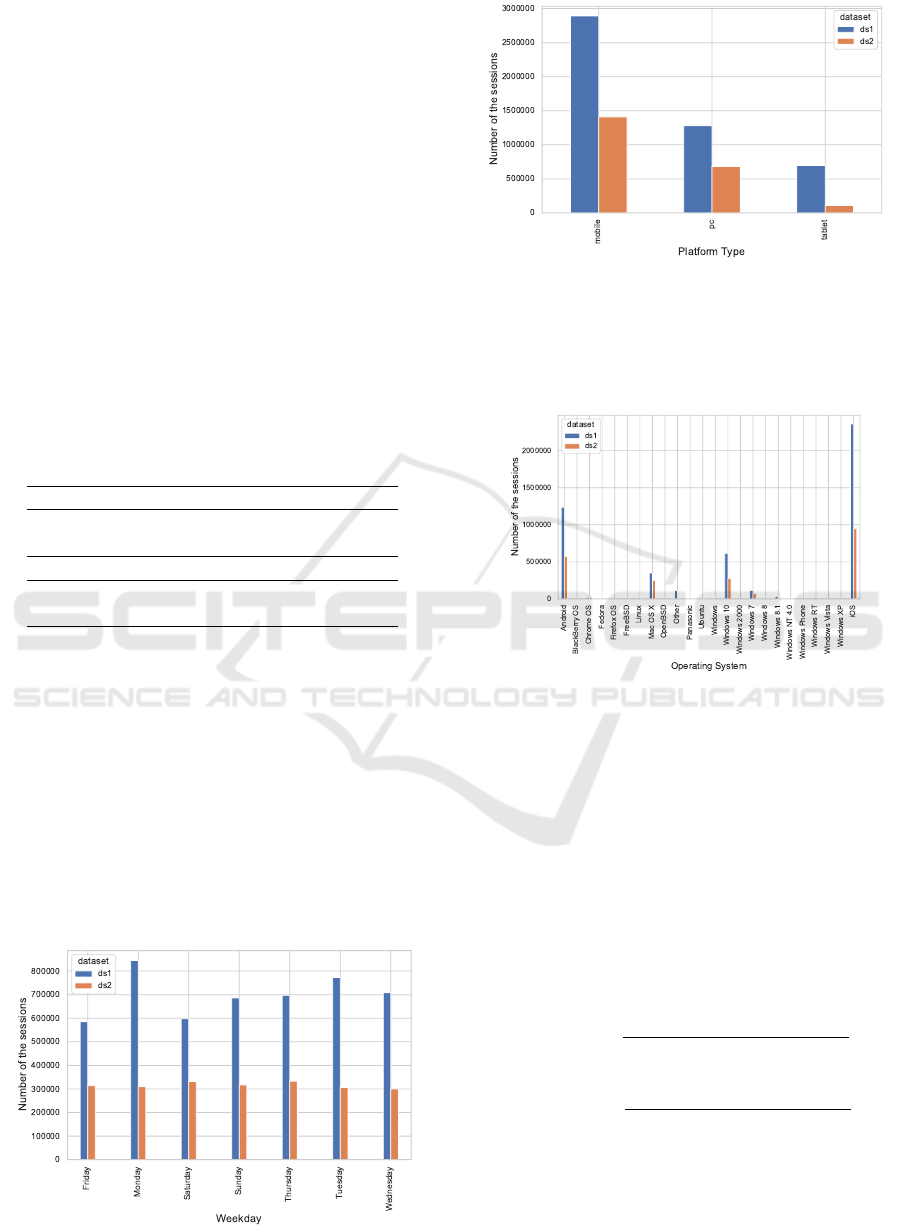
Figure 2 shows the number of the user interac-
tions with e-commerce platform by the day of week
for both dataset. Monday is the highest number of
user interactions for ds 1, while Thursday and Satur-
day are the highest number of user interactions days
for the ds 2. Moreover, Figure 3 presents statistical
analysis of the number of user interactions by used
platform by users. It can be seen that both datasets
have similar trend for the platforms.
Figure 2: User interaction statistics by day of week.
Figure 3: User interaction statistics by platform.
Figure 4 shows the number of user interactions by
operating systems used. Similar to Figure 3, Figure 4
also shows similar trends for number of user interac-
tions by used operating systems.
Figure 4: User interaction statistics by platform.
4.2 Evaluation Metrics
To assess the performance of the proposed frame-
work, precision and recall metrics are used. In RS
domain, recall@n is the ratio between the length of
correct predicted items within top n recommenda-
tions and the length of test items (ground truth) and
precision@n is the ratio between the length of cor-
rect predicted items within top n recommendations
and the length of total recommended items. They are
computed as follows:
recall@n =
|relevant recommendations|
|relevant items|
(1)
precision@n =
|relevant recommendations|
|total recommendations|
(2)
After having final ranked recommended items,
we evaluate the proposed models with above men-
tioned metrics for top n recommendations where n ∈
{10, 20, 30} since users are more interested in the rec-
ommendations in top of the recommendation list.
Session Similarity based Approach for Alleviating Cold-start Session Problem in e-Commerce for Top-N Recommendations
183

Table 2: Performance comparison of RS models on proposed framework with different N
s
parameter.
Models p@10 r@10 p@20 r@20 p@30 r@30 N s
ds 1
KNN 0.028 0.278 0.018 0.363 0.014 0.418
Session Pop 0.005 0.045 0.003 0.068 0.003 0.090
Random RS 0.000 0.000 0.000 0.000 0.000 0.001
KNN cold-start 0.001 0.007 0.001 0.013 0.001 0.021
n=10
Session Pop cold-start 0.001 0.013 0.001 0.022 0.001 0.030
KNN cold-start 0.002 0.021 0.002 0.033 0.001 0.038
n=20
Session Pop cold-start 0.001 0.007 0.001 0.016 0.001 0.037
KNN cold-start 0.002 0.021 0.002 0.041 0.002 0.062
n=30
Session Pop cold-start 0.001 0.011 0.001 0.018 0.001 0.027
KNN cold-start 0.002 0.023 0.002 0.036 0.002 0.05
n=40
Session Pop cold-start 0.001 0.011 0.001 0.019 0.001 0.026
ds 2
KNN 0.038 0.382 0.025 0.491 0.019 0.558
Session Pop 0.007 0.073 0.010 0.202 0.008 0.236
Random RS 0.001 0.006 0.000 0.009 0.000 0.013
KNN cold-start 0.004 0.044 0.004 0.082 0.004 0.116
n=10
Session Pop cold-start 0.003 0.026 0.002 0.041 0.003 0.075
KNN cold-start 0.007 0.067 0.006 0.109 0.005 0.147
n=20
Session Pop cold-start 0.004 0.044 0.004 0.071 0.004 0.112
KNN cold-start 0.006 0.064 0.006 0.120 0.005 0.164
n=30
Session Pop cold-start 0.002 0.023 0.002 0.041 0.002 0.061
KNN cold-start 0.007 0.069 0.006 0.125 0.005 0.164
n=40
Session Pop cold-start 0.002 0.018 0.002 0.041 0.002 0.062
4.3 Experiments
The main aim of the experiments is to measure the
accuracy of the recommendations of the proposed
framework for cold-start sessions comparing to ran-
dom item recommendations. The fundamental idea
of our approach is that similar sessions which have
similar features can share similar user preferences.
Nearest neighbour and RS models are created
using train dataset. Moreover, for each n
s
∈
{10, 20, 30, 40} value, a new nearest neighbour model
is created. For each created nearest neighbour model,
final recommendation list is created using two differ-
ent RS model.
For each similar session s ∈ s
1
, s
2
...s
n
s
, we derive
100 product recommendations from each RS model
and create a final recommendation list based on ma-
jority voting method. We illustrate how majority vot-
ing works in small example; lets say recommended
items from session s
1
are {i
1
, i
2
, i
100
, i
10
}, and rec-
ommendations from s
2
are {i
1
, i
7
, i
100
, i
34
}. So, items
{i
1
&i
100
} are the same recommended times found in
both sessions {s
1
, s
2
...s
n
s
}. Therefore, items i
1
and
i
100
are selected and added to the final recommen-
dation list. The final recommendation list is ranked
based on the the number of vote each item gets. For
instance, if item i
1
appeared 10 times in the recom-
mendations while i
3
appeared 6 times, then i
1
is listed
before i
3
. After the recommendation list is ranked
based on the votes, we evaluate the RS accuracy by
selecting top n items from the ranked list using recall
and precision metrics.
4.4 Results
Table 2 shows the results of the proposed framework
applied to two different RS models. We report RS
models’ performance on top n (n ∈ {10, 20, 30}) rec-
ommendations using recall@n (r), precision@n (p)
metrics. N
s
shows the selected number of similar ses-
sions for each test session, which are derived from
the nearest neighbour model based on test session fea-
tures. In our experiments, we use random RS model
as the baseline to evaluate the performance of our pro-
posed framework. Random RS models are commonly
used in the case where there is a lack of prior infor-
mation (e.g. item interactions, user preferences, asso-
ciated social media account, etc.) about the user (Ne-
gre et al., 2013; Rohani et al., 2014; Castillejo et al.,
2012).
KDIR 2020 - 12th International Conference on Knowledge Discovery and Information Retrieval
184

Experiments results show that regardless of the N
s
parameter, when the proposed framework applied, RS
models show better performance than Random RS for
both datasets. It can be seen from the results that
when RS does not have any information about the
new session (cold-start session), the performance of
RS is low. However, where a session has interacted
items, the performance of the RS models improves
significantly. For example, when sessions have inter-
acted items, experiment results show that Item-Item
KNN based RS can show around 41% and 55 % re-
call scores in ds 1 and ds 2 respectively.
On the other hand, when the proposed framework
is applied to two well-known RS models, it can be
seen that the recall score can increase significantly in
comparison with random RS model in cold-start ses-
sions. In the results table, we also show the impact of
N
s
parameter on RS performance. The results indicate
that increasing N
s
parameter after a certain point does
not help improve the results. We found that N
s
= 30
is the best value for achieving the best RS accuracy
score. Moreover, in each N
s
parameter and dataset,
the experiment results showed that Item-Item KNN
based RS is better than Session Popularity based RS
model.
4.5 Conclusion
Cold-start problems are major problems of the RS. In
this paper, we introduced a novel framework that can
deal with the cold-start problem for the new sessions
that have no prior user information such as item in-
teractions. The proposed framework can find similar
sessions based on session features such as time ses-
sion started, users’ location, users’ platform, etc. and
create recommendations from these sessions. Com-
putational experiments using two datasets proved that
the proposed framework significantly improved rec-
ommendation accuracy and alleviate cold-start user
session problem. We applied the proposed framework
on Item-Item KNN and Session Popularity based RS
models. Nevertheless, the proposed framework is a
general framework that can be applied to different
kinds of RS model, including Deep-Learning based
models (Hidasi et al., 2015; Gabriel De Souza et al.,
2019; Ludewig et al., 2019).
For future work, other session-based datasets
could be tested on the framework to substantiate the
robustness of the proposed framework. Also, clus-
tering approach (Zhang et al., 2013; Yanxiang et al.,
2013; Bader-El-Den et al., 2018) can be applied to
find similar sessions. For example, in the first step,
sessions can be clustered into groups, and based on
new session features the cluster group that session
belongs to can be identified then most similar ses-
sions from that cluster can be used in order to create
a recommendation list. Also, other available session
features can be included for nearest neighbour model
creation to find similar sessions that can represent new
sessions more accurately.
REFERENCES
Aharon, M., Anava, O., Avigdor-Elgrabli, N., Drachsler-
Cohen, D., Golan, S., and Somekh, O. (2015). Ex-
cuseme: Asking users to help in item cold-start rec-
ommendations. In Proceedings of the 9th ACM Con-
ference on Recommender Systems, pages 83–90.
Aledo, J. A., G
´
amez, J. A., and Molina, D. (2017). Tack-
ling the supervised label ranking problem by bagging
weak learners. Information Fusion, 35:38–50.
Anwaar, F., Iltaf, N., Afzal, H., and Nawaz, R. (2018). Hrs-
ce: A hybrid framework to integrate content embed-
dings in recommender systems for cold start items.
Journal of computational science, 29:9–18.
Bader-El-Den, M., Teitei, E., and Perry, T. (2018). Biased
random forest for dealing with the class imbalance
problem. IEEE transactions on neural networks and
learning systems, 30(7):2163–2172.
Bouadjenek, M. R., Hacid, H., and Bouzeghoub, M. (2016).
Social networks and information retrieval, how are
they converging? a survey, a taxonomy and an analy-
sis of social information retrieval approaches and plat-
forms. Information Systems, 56:1–18.
Carrer-Neto, W., Hern
´
andez-Alcaraz, M. L., Valencia-
Garc
´
ıa, R., and Garc
´
ıa-S
´
anchez, F. (2012). Social
knowledge-based recommender system. application to
the movies domain. Expert Systems with applications,
39(12):10990–11000.
Castillejo, E., Almeida, A., and L
´
opez-De-Ipi
˜
na, D. (2012).
Alleviating cold-user start problem with users’ social
network data in recommendation systems. In Work-
shop on Preference Learning: Problems and Applica-
tions in AI (PL-12) at ECAI, pages 28–33.
Esmeli, R., Bader-El-Den, M., and Abdullahi, H. (2019a).
Improving session based recommendation by diver-
sity awareness. In UK Workshop on Computational
Intelligence, pages 319–330. Springer.
Esmeli, R., Bader-El-Den, M., Abdullahi, H., and Hender-
son, D. (2020). Improving session-based recommen-
dation adopting linear regression based re-ranking. In
IEEE World Congress on Computational Intelligence
(WCCI) 2020. Institute of Electrical and Electronics
Engineers.
Esmeli, R., Bader-El-Den, M., and Mohasseb, A. (2019b).
Context and short term user intention aware hybrid
session based recommendation system. In 2019 IEEE
International Symposium on INnovations in Intelli-
gent SysTems and Applications (INISTA), pages 1–6.
IEEE.
Gabriel De Souza, P. M., Jannach, D., and Da Cunha, A. M.
(2019). Contextual hybrid session-based news recom-
Session Similarity based Approach for Alleviating Cold-start Session Problem in e-Commerce for Top-N Recommendations
185

mendation with recurrent neural networks. IEEE Ac-
cess, 7:169185–169203.
Guy, I., Zwerdling, N., Ronen, I., Carmel, D., and Uziel, E.
(2010). Social media recommendation based on peo-
ple and tags. In Proceedings of the 33rd international
ACM SIGIR conference on Research and development
in information retrieval, pages 194–201.
He, J. and Chu, W. W. (2010). A social network-based rec-
ommender system (snrs). In Data mining for social
network data, pages 47–74. Springer.
Herce-Zelaya, J., Porcel, C., Bernab
´
e-Moreno, J., Tejeda-
Lorente, A., and Herrera-Viedma, E. (2020). New
technique to alleviate the cold start problem in recom-
mender systems using information from social media
and random decision forests. Information Sciences.
Hidasi, B., Karatzoglou, A., Baltrunas, L., and Tikk,
D. (2015). Session-based recommendations
with recurrent neural networks. arXiv preprint
arXiv:1511.06939.
Lika, B., Kolomvatsos, K., and Hadjiefthymiades, S.
(2014). Facing the cold start problem in recom-
mender systems. Expert Systems with Applications,
41(4):2065–2073.
Ludewig, M., Mauro, N., Latifi, S., and Jannach, D. (2019).
Performance comparison of neural and non-neural ap-
proaches to session-based recommendation. In Pro-
ceedings of the 13th ACM Conference on Recom-
mender Systems, pages 462–466.
Negre, E., Ravat, F., Teste, O., and Tournier, R. (2013).
Cold-start recommender system problem within a
multidimensional data warehouse. In IEEE 7th Inter-
national Conference on Research Challenges in Infor-
mation Science (RCIS), pages 1–8. IEEE.
Pereira, A. L. V. and Hruschka, E. R. (2015). Simultane-
ous co-clustering and learning to address the cold start
problem in recommender systems. Knowledge-Based
Systems, 82:11–19.
Ralph, D., Li, Y., Wills, G., and Green, N. G. (2020). Rec-
ommendations from cold starts in big data. Comput-
ing, pages 1–22.
Rohani, V. A., Kasirun, Z. M., Kumar, S., and Shamshir-
band, S. (2014). An effective recommender algorithm
for cold-start problem in academic social networks.
Mathematical Problems in Engineering, 2014.
Rosli, A. N., You, T., Ha, I., Chung, K.-Y., and Jo, G.-S.
(2015). Alleviating the cold-start problem by incor-
porating movies facebook pages. Cluster Computing,
18(1):187–197.
Safoury, L. and Salah, A. (2013). Exploiting user demo-
graphic attributes for solving cold-start problem in
recommender system. Lecture Notes on Software En-
gineering, 1(3):303–307.
Sahebi, S. and Cohen, W. W. (2011). Community-based
recommendations: a solution to the cold start prob-
lem. In Workshop on recommender systems and the
social web, RSWEB, page 60.
Sedhain, S., Sanner, S., Braziunas, D., Xie, L., and Chris-
tensen, J. (2014). Social collaborative filtering for
cold-start recommendations. In Proceedings of the
8th ACM Conference on Recommender systems, pages
345–348.
Silva, N., Carvalho, D., Pereira, A. C., Mourao, F., and
Rocha, L. (2019). The pure cold-start problem: A
deep study about how to conquer first-time users
in recommendations domains. Information Systems,
80:1–12.
Son, L. H. (2016). Dealing with the new user cold-start
problem in recommender systems: A comparative re-
view. Information Systems, 58:87–104.
Tian, H. and Liang, P. (2017). Personalized service rec-
ommendation based on trust relationship. Scientific
Programming, 2017.
Wu, C. and Yan, M. (2017). Session-aware information em-
bedding for e-commerce product recommendation. In
Proceedings of the 2017 ACM on conference on in-
formation and knowledge management, pages 2379–
2382. ACM.
Yanxiang, L., Deke, G., Fei, C., and Honghui, C. (2013).
User-based clustering with top-n recommendation on
cold-start problem. In 2013 third international con-
ference on intelligent system design and engineering
applications, pages 1585–1589. IEEE.
Zhang, D., Hsu, C.-H., Chen, M., Chen, Q., Xiong, N.,
and Lloret, J. (2013). Cold-start recommendation us-
ing bi-clustering and fusion for large-scale social rec-
ommender systems. IEEE Transactions on Emerging
Topics in Computing, 2(2):239–250.
KDIR 2020 - 12th International Conference on Knowledge Discovery and Information Retrieval
186
