
SatelliteNER: An Effective Named Entity Recognition Model for the
Satellite Domain
Omid Jafari
1 a
, Parth Nagarkar
1 b
, Bhagwan Thatte
2
and Carl Ingram
3
1
Computer Science Department, New Mexico State University, Las Cruces, NM, U.S.A.
2
Protos Software, Tempe, AZ, U.S.A.
3
Vigilant Technologies, Tempe, AZ, U.S.A.
Keywords:
Natural Language Processing, Named Entity Recognition, Spacy.
Abstract:
Named Entity Recognition (NER) is an important task that detects special type of entities in a given text.
Existing NER techniques are optimized to find commonly used entities such as person or organization names.
They are not specifically designed to find custom entities. In this paper, we present an end-to-end framework,
called SatelliteNER, that its objective is to specifically find entities in the Satellite domain. The workflow
of our proposed framework can be further generalized to different domains. The design of SatelliteNER in-
cludes effective modules for preprocessing, auto-labeling and collection of training data. We present a detailed
analysis and show that the performance of SatelliteNER is superior to the state-of-the-art NER techniques for
detecting entities in the Satellite domain.
1 INTRODUCTION
Nowadays, large amounts of data is generated daily.
Textual data is generated by news articles, social me-
dia such as Twitter, Wikipedia, etc. Managing these
large data and extracting useful information from
them is an important task that can be achieved using
Natural Language Processing (NLP). NLP is an arti-
ficial intelligence domain dedicated to processing and
analyzing human languages. NLP includes many sub-
domains such as Named Entity Recognition (NER),
Entity Linking, Sentiment Analysis, Text Summariza-
tion, Topic Modeling, and Speech Processing.
NER focuses on recognizing various entity types
such as persons, organizations, products, locations,
etc., and these entity types can be different based on
the application that NER tool is built for (Nadeau and
Sekine, 2007). Some of the early applications of NER
included name searching systems in order to identify
human names in a given data (Thompson and Dozier,
1997), question answering systems where entities are
extracted from the given question in order to find bet-
ter search results (Florian et al., 2003), and document
summarization systems where NER is used to iden-
tify important parts of the text (Hassel, 2003). Along
a
https://orcid.org/0000-0003-3422-2755
b
https://orcid.org/0000-0001-6284-9251
with having NER tools for different human languages
(e.g., English, French, Chinese, etc.), domain-specific
NER software and tools have been created with the
consideration that all sciences and applications have a
growing need for NLP. For instance, NER is used in
the medical field (Abacha and Zweigenbaum, 2011),
for the legal documents (Dozier et al., 2010), for
tweets (Ritter et al., 2011), and for historical docu-
ments (Grover et al., 2008).
Nowadays, many nations around the world are ca-
pable of launching satellites into the Earth’s orbit. Ac-
cording to a report from (Union of Concerned Scien-
tists, 2020), as of Apr 1, 2020, there are 2, 666 satel-
lites currently in the orbit of Earth. With every satel-
lite launch, tons of new data is generated on social
media and news websites. For instance, running the
“satellite launch” query in Google News, returns 190
results over only one week, or getting a report for the
same query using (talkwalker.com, 2020), tells us that
1.7k tweets have been posted in one week. A tool, that
can automatically detect satellite entities from differ-
ent sources of textual data, will be useful for differ-
ent space agencies and defense institutions around the
world. To the best of our knowledge, there is no ex-
isting NER tool that can detect satellite entities. The
goal of this paper is to improve the performance of de-
tecting satellite entities of state-of-the-art NER tools.
100
Jafari, O., Nagarkar, P., Thatte, B. and Ingram, C.
SatelliteNER: An Effective Named Entity Recognition Model for the Satellite Domain.
DOI: 10.5220/0010147401000107
In Proceedings of the 12th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2020) - Volume 3: KMIS, pages 100-107
ISBN: 978-989-758-474-9
Copyright
c
2020 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

1.1 Contributions of This Paper
Although comparing NER tools has been done before,
the existing works (Section 3) have only evaluated the
pre-trained and original models of the NER tools, and
the evaluation metrics are based on three general en-
tity types. No existing work focuses on improving
the accuracy of detecting custom entities (for a given
domain) on existing state-of-the-art NER tools. The
following are the contributions of this paper:
1. We compare the performance of state-of-the-art
open-source and paid NER tools for detecting en-
tities in a specific domain (i.e. satellite domain).
2. We present a workflow for auto-generation of
training and testing data for our specific domain.
3. We create a new domain-specific model called
SatelliteNER, trained using the auto-labeled data.
4. Finally, we present a detailed analysis on the per-
formance of SatelliteNER and compare it with
state-of-the-art NER tools.
Note that, while this paper focuses on the satellite do-
main, we believe that the end-to-end methodology for
creating an effective custom NER model presented in
this paper can be beneficial for other domains as well.
The rest of the paper is organized as follows: In
section 2, we give a brief overview of the current
methods used in the NER tools. In section 3, we
present an overview of the related works to this paper.
Section 4 focuses on presenting our end-to-end frame-
work for building our domain-specific NER tool. In
section 5, we perform an experimental evaluation of
our domain-specific tool against general NER tools,
and finally, in section 6, we conclude our work.
2 BACKGROUND
NER approaches can be broadly summarized into two
categories: 1. Rule-based approaches, where a gram-
matical condition is used to detect entities, 2. Ma-
chine learning-based approaches where a classifier is
built on a large amount of labeled data. Following, we
will briefly explain the first two approaches to better
get familiar with the concepts used in NER.
2.1 Rule-based
Rule-based approach was first used in (Rau, 1991)
where their goal was to identify company names from
financial news articles. Rule-based approaches in
NER use manual patterns similar to regular expres-
sions in order to match a sequence of words. Instead
of matching each word separately using the white
space before and after it, it is possible for these meth-
ods to identify several words as a single token. There
are several phases of rule matchers that will go over
the text multiple times and try to identify the entities
using partial matches, the context of the words, and
full matches. Rule-based methods can achieve high
accuracy, but they require significant manual effort by
experienced linguists to create hand-crafted rules.
2.2 Machine Learning-based
The main issue with rule-based approaches is that
rules are manually handcrafted for a specific domain
and not possible to be applied everywhere. There-
fore, machine learning-based approaches are being
utilized nowadays either in a combination with rule-
based methods or by themselves.
Machine learning approaches require a large
amount of labeled data to study the features of a given
text and generate rules from them. These features pro-
vide an abstraction of the text and include data such as
word morphology, part-of-speech tags, and local syn-
taxes. After the features of the given text are found us-
ing machine learning techniques, different supervised
learning algorithms such as Hidden Markov Mod-
els (HMM) (Eddy, 1996), Decision Trees (Quinlan,
1986), Support Vector Machines (SVM) (Hearst et al.,
1998), and Conditional Random Fields (CRF) (Laf-
ferty et al., 2001) can be applied to generate matching
rules. It is worth mentioning that instead of super-
vised learning algorithms, semi-supervised and unsu-
pervised algorithms can also be used for this purpose.
One way to provide text features to the supervised
learning algorithms is by having an experienced lin-
guistic researcher to generate them, but this process
can be automated by using deep neural networks. Two
neural network types are mostly used for this purpose:
Convolutional Neural Networks (CNN) and Recur-
rent Neural Networks (RNN). CNNs were first pro-
posed in (Collobert and Weston, 2008). For RNNs,
since they only consider the context right before the
input and get biased by the nearest input, an alterna-
tive variant called Long Short-term Memory (LSTM)
replaced them. LSTMs are capable of learning long-
term dependencies, and the bidirectional architecture
of LSTMs is capable of also considering the future
context. Bidirectional LSTMs were first used in NLP
tasks in (Graves et al., 2013) and were later combined
with CRF to also use the sentence-level tag informa-
tion from the CRF layer (Huang et al., 2015).
SatelliteNER: An Effective Named Entity Recognition Model for the Satellite Domain
101

3 RELATED WORK
In this section, we first introduce the NER tools that
are going to be used in our experiments, and after that,
we explain the differences of this paper with similar
works. The following state-of-the-art techniques are
selected for the experiments:
1. Stanford NER (Finkel et al., 2005) was intro-
duced to improve on the NER tasks by using Gibbs
sampling and CRF to gather non-local information
and Viterbi algorithm for the most likely state infer-
ence of the CRF output. The code is implemented
in Java and it has the following three models for the
English language: 1) “3 class” which supports Loca-
tion, Person, and Organization entities. It was trained
on the CoNLL 2003, MUC 6, and MUC 7 training
datasets, 2) “4 class” which supports Location, Per-
son, Organization, and Misc entities. It was trained
on the CoNLL 2003 dataset, and 3) “7 class” which
supports Location, Person, Organization, Money, Per-
cent, Date, and Time. It was trained on the MUC 6
and MUC 7 datasets. For simplicity and since the en-
tities in the 7 class model are not important in our
domain, Stanford NER will refer to the 4 class model
for the rest of the paper.
2. Spacy
1
was first introduced in 2015 that used
linear models to detect named entities, and it was
implemented in Python. Later, as new versions
were released, it changed its architecture to neural
networks. The latest stable version (v2.3) was re-
leased in June 2020 and it uses Bloom embeddings
to generate representations of the given text. Fur-
thermore, Spacy uses CNNs since they are com-
putationally cheaper and achieve the same amount
of accuracy compared to other neural network ar-
chitectures. Spacy is designed for production use
and has interesting features such as GPU support
and transfer learning support. Spacy has three pre-
trained models for the English language: 1) the small
model which was trained on the OntoNotes 5 dataset,
2) the medium model which was trained on a re-
duced version of the OntoNotes 5 and GloVe Com-
mon Crawl datasets, and 3) the large model which
was trained on the OntoNotes 5 and GloVe Com-
mon Crawl datasets. All of these models are able
to recognize PERSON, NORP, FAC, ORG, GPE,
LOC, PRODUCT, EVENT, WORK OF ART, LAW,
LANGUAGE, DATE, TIME, PERCENT, MONEY,
QUANTITY, ORDINAL, and CARDINAL entities.
3. Google Natural Language API
2
was first
released in 2016 as a general availability ver-
sion (v1). It is a service provided by Google
1
https://spacy.io
2
https://cloud.google.com/natural-language
that is capable of performing several NLP tasks,
one of which is called entity analysis that can
detect UNKNOWN, PERSON, LOCATION, OR-
GANIZATION, EVENT, WORK OF ART, CON-
SUMER GOOD, OTHER, PHONE NUMBER, AD-
DRESS, DATE, NUMBER, and PRICE entities. The
benefit of using this service is that it lifts the process-
ing power from end-users’ machines and all of the
processing happens on the Google servers. Therefore,
users can easily send API requests via different meth-
ods and fetch the results without needing to worry
about the processing power of their machine. How-
ever, there is a cost associated with this service. The
first 5, 000 documents in each month are free and after
that, every 1, 000 document costs $0.50. Google Nat-
ural Language also allows users to train their models,
but there are separate costs associated with this task
and the models will be removed every 6 months.
4. Microsoft Text Analytics API
3
is another
cloud-based service which was introduced in 2016.
Similar to Google’s service, the low-level details of
the architecture behind this API is not exposed by the
developers. The cost of using this service is free for
the first 5, 000 documents each month and after that,
every 1, 000 document will cost $1, and this tool can
detect Person, PersonType, Location, Organization,
Event, Product, Skill, Address, PhoneNumber, Email,
URL, IP, DateTime, and Quantity entities. The down-
side of service is that up to this date, it does not allow
building and training custom models.
5. Stanza (Qi et al., 2020) is a tool developed by
the same developers of Stanford NER. Stanza uses a
Bi-LSTM neural network trained on the contextual-
ized string representations and a CRF decoder to per-
form NER. This tool is written in Python and utilizes
PyTorch library to enable GPU processing and im-
prove speed. Moreover, its English model is capable
of recognizing PERSON, NORP, FAC, ORG, GPE,
LOC, PRODUCT, EVENT, WORK OF ART, LAW,
LANGUAGE, DATE, TIME, PERCENT, MONEY,
QUANTITY, ORDINAL, and CARDINAL entities.
There have been several recent papers on the com-
parison and evaluation of different NER tools. In
(Jiang et al., 2016), the authors have selected several
NER tools such as Stanford NER, Spacy, etc., and
have compared the performance of these tools on a
dataset containing annotated PERSON, LOCATION,
and ORGANIZATION entities. In (Won et al., 2018),
the comparison between NER tools is performed on
the historical corpora. Datasets chosen in this study
are written in early-modern English and modern En-
glish which has helped identify the effect of language
3
https://azure.microsoft.com/en-us/services/
cognitive-services/text-analytics
KMIS 2020 - 12th International Conference on Knowledge Management and Information Systems
102
Exclude Wikipedia
URLs
2. Google News
List of Space
Agencies
List of Orbital
Launch Rockets
1. Wikipedia
Organization
Rocket
Exclude YouTube
URLs
List of
Satellites
4. Space-Track
Fetch <p> Tags
3. Scraper
Minimum Text
Characters: 125
URLs
Split Sentences
5. Tokenizer
Text
Keep Sentences
with at least
Organization or
Rocket or Satellite
Org
Rocket
Sat
Auto-labeling Module
Training
Dataset
Validation
Dataset
Model Trainer
Module
Train with
Training Set
spaCy
Tune with
Training Set
Training
Dataset
Testing
Dataset
Testing Module
Use Sample of
Training Set
Strategy 1
Use Testing
Set
Strategy 2
Use Testing
Set
Strategy 3
Permutate
Entities
Model
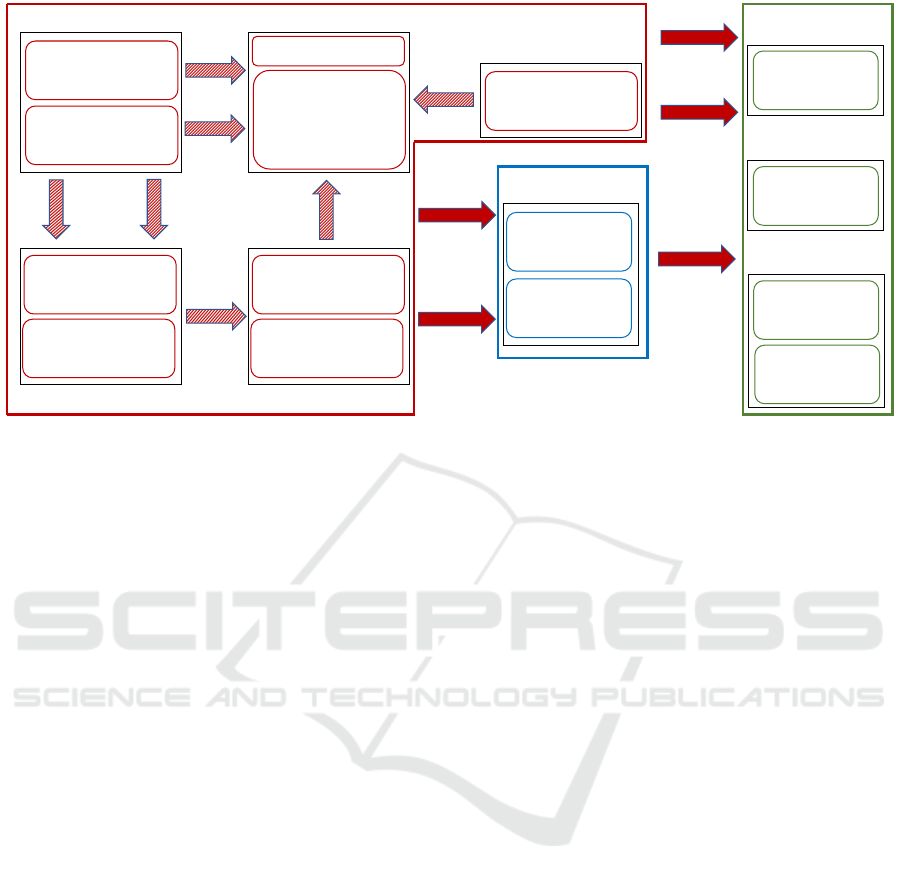
Figure 1: Architecture of SatelliteNER.
changes over time on the NER tools performance.
Another work (Schmitt et al., 2019) was published to
show the comparison of several NER tools in regards
to detecting PERSON, LOCATION, and ORGANI-
ZATION entities in two datasets related to news arti-
cles. Finally, in (Ribeiro et al., 2020), authors have
proposed a methodology for testing NLP tasks called
CheckList. One of the main tests that CheckList in-
troduces is the Invariance test (INV), where changing
the entities (e.g. changing person names) should not
affect the performance of a tool.
4 SatelliteNER CREATION
In this section, we describe the end-to-end workflow
of creating an effective NER model for detecting en-
tities in the satellite domain, called SatelliteNER. Fig-
ure 1 shows the workflow of SatelliteNER.
4.1 Choosing the Base NER Technique
We choose Spacy to build our SatelliteNER model
since it offers rich features and parameters when train-
ing a model. There are two ways to build a domain-
specific model in Spacy: 1) Updating the current
models and 2) Building from scratch.
The main problem that can happen in updating a
current model is known as the Catastrophic Forget-
ting problem. What happens is that when the model
is updated with the new training data, it forgets what
was learned before. To deal with this problem, we
use the Pseudo-rehearsal strategy, which means that
we first use the current model on our training data to
find entities and then add those recognized entities to
the training data. This way, the model will not forget
the weights that were learned before and also its pre-
vious entities. As a result, the model will be able to
detect the original entities and the ones we add using
our training data. However, since there can be com-
mon entities in the Pseudo-rehearsal strategy and one
of them being chosen (e.g. Product vs SatelliteName),
the resultant model in this strategy is not efficient.
For the other strategy, which is building the model
from scratch, we must make sure that enough training
data is fed into the model. Spacy suggests using at
least a few hundred training examples. Therefore, we
use an automatic dataset generation workflow which
is explained in Section 4.2.
We experimentally show the difference of these
two strategies in Table 1. It can be seen that for the
reasons mentioned earlier, the second strategy (build-
ing the model from scratch) is more effective.
4.2 Efficient Generation of Training
and Testing Data
Large amounts of training data is required to build an
accurate neural network-based model. For the NER
models, the training data should represent the data
that we want to predict in the future. For instance,
a model trained on news articles is best capable of de-
tecting named entities in news articles. Moreover, the
training data should be annotated with the labels that
SatelliteNER: An Effective Named Entity Recognition Model for the Satellite Domain
103

Table 1: Variations of Trained Models.
Base Model Psuedo-rehearsal Training Size F-Score Training Time (mins)
None (From Scratch) No 25, 628 91.958 39
Spacy Original Model Yes 25, 628 84.99 142
we want the model to predict in the future. For exam-
ple, we cannot expect a model to predict organization
entities in a text when it was trained only on person la-
bels. All of the NER tools require hundreds and thou-
sands of training data to show a good performance.
For example, the OntoNotes 5 dataset that Spacy is
using contains 1, 445, 000 English words. Manually
annotating these large datasets is a very slow process
and not applicable to sensitive applications that re-
quire ready-to-use systems in a short time. Therefore,
we have to come up with an automatic strategy to gen-
erate our training data.
After a model is trained on a given data, it can be
used to make predictions and detect the named enti-
ties. However, the results will be biased if we use the
same training data to evaluate the model in the predic-
tion step. To find out that the trained model is capa-
ble of not only detecting named entities in the train-
ing data but also from any given text (this concept is
called generalization in machine learning), we need
to prepare an additional dataset called testing dataset.
The data in this dataset should be different from our
training data, but it should contain the same labels
since the model is only capable of detecting those la-
bels. The labels in the testing data are used to evaluate
the model and show the performance of it according
to different metrics.
All satellites require an orbital launch rocket to
send them into the orbit. Also, it is possible for the
same model of satellite to belong to several space
agencies. For example, Badr satellite belonging to
Pakistan’s national space agency was launched using
a Zenit rocket in 2001 and another Badr satellite be-
longing to Saudi Arabia was launched on an Ariane
rocket in 2008. Our goal is to identify all of these en-
tities; hence, our satellite model is custom built to de-
tect the orgName, rocketName, and satelliteName en-
tities. We use Wikipedia to find governmental and pri-
vate space agency names.
4,5
Then, we use Wikipedia
to find the list of orbital launch systems (i.e. rockets)
for each country
6
and choose them for the agencies
that we chose in the previous step.
At the next step, we use Google news API to
4
https://en.wikipedia.org/wiki/List of government
space agencies
5
https://en.wikipedia.org/wiki/List of private
spaceflight companies
6
https://en.wikipedia.org/wiki/List of orbital launch
systems
search for every combination in the form of [organiza-
tion + rocket + “launch”] using the organizations and
rockets that we found in the previous step with the
goal of finding news articles about the organizations
launching those specific rockets. We limit the API to
only return the first 250 results and in some cases,
the total number of results is less than 250. From
the returned results, we remove the URLs containing
the “wikipedia”, “youtube”, “.ppt”, or “comments”
words because our intention is to only get news arti-
cles. So, we end up with 3, 243 URLs without consid-
ering the duplicates. Next, we use the BeautifulSoup
package to scrape the URLs and getting text contained
in <p> tags with a minimum number of 125 charac-
ters. The text is also tokenized into sentences using
the NLTK package. The result is 129, 316 sentences,
but not all of them contain the words that we have
searched for; thus, more processing is required.
Since the goal was to also detect satellite names,
we use the Space-Track
7
website to get a list of all
satellites that have been launched so far. Only the
main word within the satellite name is kept (e.g.
Starlink-31 and Starlink-32 both become Starlink)
and we carefully review the names and remove the
common names such as “launch”, “step”, “wind”, etc.
At this step, we analyze the scraped sentences and
using the list of organizations, rockets, and satellites,
we only keep sentences containing at least one of
those (since we have removed numbers from satellite
names, we check 95% similarity instead of an exact
match for satellite names). As a result, we get 26, 128
sentences out of which 25, 628 of them are used as
our training data. Moreover, we also need evaluation
data in the training phase that will be used to check
the model accuracy and losses at each iteration and
tune hyper-parameters. We use the remaining 500
sentences of the results for this purpose.
For the testing dataset, we use three strategies: 1)
We use 500 of the sentences from the training set
(these are the sentences that model has seen before
in the training phase), 2) We use the auto-labeling
technique that we used to generate our training set
with new organizations and rockets (since the orga-
nizations, rockets, and URLs will be different from
the training set, they will also contain different satel-
lites and these data will be new to the model) and ran-
domly choose 500 sentences from the results, and 3)
7
https://www.space-track.org
KMIS 2020 - 12th International Conference on Knowledge Management and Information Systems
104

The third strategy is similar to the evaluation done in
(Ribeiro et al., 2020) which is called invariance test-
ing. In this strategy, we use the same sentences in
the second strategy but randomly shuffle the entities.
Since we have three entities and in some sentences,
only one of them exists, we first create a list of all en-
tities in the training set. Then, for each sentence, we
randomly replace the entities with the entities from
the created list and remove them from the list. This
way, we can make sure that all entities in the sen-
tences are changed.
5 EXPERIMENTS
In this section, we evaluate the models that we trained
and compare them with state-of-the-art NER tools.
Experiments were run on a machine with the follow-
ing specifications: Intel Core i7-6700, 16GB RAM,
2TB HDD, Python 3.6, and Ubuntu 18.04 operating
system. All experiments are executed on one core of
CPU except Stanza which uses all cores and does not
have an option to change the number of cores. Also,
default parameters are used for all experiments. We
compare our trained model with the following alter-
natives:
• Spacy Orig: This alternative is the original En-
glish model of Spacy.
• StanfordNer: As stated in Section 3, the 4 class
model of Stanford NER in used our experiments.
• Stanza: We use English model of Stanza.
• GoogleNER: Here, we use the Cloud Natural
Language API service from Google.
• MicrosoftNER: We use the Text Analytics API
service from Microsoft.
5.1 Evaluation Criteria
Since the tools have different entity labels (e.g.
rocketName in our model vs PRODUCT in the orig-
inal model of Spacy), it is not possible to compare
them and perform the evaluation based on them. For
instance, both rockets and satellites in our model, can
show up as a PRODUCT in the other tools. As a re-
sult, we use the following metrics in our evaluation:
• Precision: In our testing data, we have the orga-
nization name, rocket name, and satellite name la-
bels, and as long as those entities are returned by
the different tools under any entity type, we count
them as a true positive. Moreover, it is highly pos-
sible that tools and models return entities that are
neither related to our domain nor equal to the test-
ing data. We define these entities as false pos-
itives. The precision metric will show the ratio
of true positives over the total number of detected
entities. In other words, this metric will help us
understand how well a model is in returning only
the true positives and not unrelated entities.
• Recall: The entities in the testing set that should
be detected by the NER tools but not detected by
them are called false negatives. The recall metric
will tell us how well a model is in finding all of
the true positives and is a ratio of true positives
over all entities in the testing set.
• F1 Score: There are times that improving on re-
call can result in a decrease in precision. The F1
Score (also known as F-measure) will combine
precision and recall and find a weighted average
of them. This metric can be used to show the over-
all performance of a tool.
• Processing Time: The time taken to recognize
the entities is also an important factor especially in
real-time applications. Some tools require loading
different models and some require making API
calls. We consider all of the aforementioned times
as the processing time.
5.2 Discussion of the Results
Precision: Figure 2 shows the precision for all of the
techniques. SatelliteNER has the best precision since
it is only detecting the entities that we are looking for,
and thus, has a very low number of false positives.
All other NER tools are behaving similarly in terms of
precision and return similar number of false positives.
Recall: Figure 3 shows the recall of the NER tech-
niques. We observe that SatelliteNER has a high re-
call in testing dataset 1 since this is the dataset it was
trained on and a recall of more than 50% in testing
datasets 2 and 3. Stanza and Spacy Orig have a bet-
ter recall compared to StanfordNer since they utilize
neural network-based models. The architecture and
neural network of MicrosoftNER and GoogleNER are
not released but results show that GoogleNER is per-
forming better in these testing datasets.
F1 Score: Figure 4 shows the F1 Score results. Since
F1 Score is a weighted average of Precision and Re-
call and due to its high precision, SatelliteNER has the
highest F1 Score in the tested datasets. Furthermore,
all other tools have a similar F1 Score with Stanza and
Spacy Orig being slightly better.
Processing Time: Figure 5 shows the total process-
ing time required to detect entities in a given text. We
feed the sentences one at a time to the NER tools and
SatelliteNER: An Effective Named Entity Recognition Model for the Satellite Domain
105

0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Recall
SatelliteNER Spacy_Orig StanfordNer Stanza GoogleNER MicrosoftNER
0
0.2
0.4
0.6
0.8
1
Precision
Testing Dataset 1
0
0.2
0.4
0.6
0.8
1
Precision
Testing Dataset 2
0
0.2
0.4
0.6
0.8
1
Precision
Testing Dataset 3
Figure 2: Comparison of the Precision of the SatelliteNER model against alternative tools.
0
0.2
0.4
0.6
0.8
1
Recall
Testing Dataset 1
0
0.2
0.4
0.6
0.8
1
Recall
Testing Dataset 2
0
0.2
0.4
0.6
0.8
1
Recall
Testing Dataset 3
Figure 3: Comparison of the Recall of the SatelliteNER model against alternative tools.
0
0.2
0.4
0.6
0.8
1
F1 Score
Testing Dataset 1
0
0.2
0.4
0.6
0.8
1
F1 Score
Testing Dataset 2
0
0.2
0.4
0.6
0.8
1
F1 Score
Testing Dataset 3
Figure 4: Comparison of the F1 Score of the SatelliteNER model against alternative tools.
0
50
100
150
200
250
300
350
Processing Time (s)
Testing Dataset 1
0
50
100
150
200
250
300
350
Processing Time (s)
Testing Dataset 2
0
50
100
150
200
250
300
350
Processing Time (s)
Testing Dataset 3
Figure 5: Comparison of the Processing Time of the SatelliteNER model against alternative tools.
evaluate the returned entities. While Figures 2, 3, and
4 show that Stanza has a better accuracy, it is signif-
icantly slower than Spacy Orig since the underlying
neural network in Stanza (BiLSTM) is slower than the
network in Spacy Orig (CNN). Also, Stanza mentions
in its documentation that it performs very slow when
sentences are fed to it one by one instead of a whole
corpus; however, for the experiments to be fair, we
use the same testing methods for all NER techniques.
MicrosoftNER and GoogleNER are slow since they
are API-based tools and require network operations
to send the requests and receive the results. More-
over, since SatelliteNER has to only look for three en-
tities (i.e. Organizations, Rockets, and Satellites), it is
faster than Spacy Orig.
KMIS 2020 - 12th International Conference on Knowledge Management and Information Systems
106

6 CONCLUSIONS AND FUTURE
WORK
Named Entity Recognition (NER) is a famous task in
Natural Language Processing that is aimed at detect-
ing different entities in a given text. Natural Language
Processing analysis in the satellite domain is neces-
sary because of the increasing data growth in this do-
main and also the importance of this domain. In this
paper, we present an effective NER model specifi-
cally engineered for the satellite domain called Satel-
liteNER. To build this model, we generate training,
validation, and testing datasets in an automated man-
ner. By doing this, the dataset annotation can happen
at a fast pace without the need for a human to manu-
ally perform the annotation task. Experiments using
three different testing strategies show the benefit of
SatelliteNER over existing NER tools. In the future,
we plan to improve accuracy by including human-in-
the-loop in the labeling process and by fine-tuning the
underlying neural network parameters. Furthermore,
we intend to build transformer-based custom models
that can achieve a higher accuracy.
REFERENCES
Abacha, A. B. and Zweigenbaum, P. (2011). Medical entity
recognition: A comparaison of semantic and statisti-
cal methods. In Proceedings of BioNLP 2011 Work-
shop, pages 56–64.
Collobert, R. and Weston, J. (2008). A unified architec-
ture for natural language processing: Deep neural net-
works with multitask learning. In Proceedings of the
25th international conference on Machine learning,
pages 160–167.
Dozier, C., Kondadadi, R., Light, M., Vachher, A., Veera-
machaneni, S., and Wudali, R. (2010). Named entity
recognition and resolution in legal text. In Semantic
Processing of Legal Texts, pages 27–43. Springer.
Eddy, S. R. (1996). Hidden markov models. Current opin-
ion in structural biology, 6(3):361–365.
Finkel, J. R., Grenager, T., and Manning, C. D. (2005).
Incorporating non-local information into information
extraction systems by gibbs sampling. In Proceed-
ings of the 43rd Annual Meeting of the Association for
Computational Linguistics (ACL’05), pages 363–370.
Florian, R., Ittycheriah, A., Jing, H., and Zhang, T. (2003).
Named entity recognition through classifier combina-
tion. In Proceedings of the seventh conference on Nat-
ural language learning at HLT-NAACL 2003, pages
168–171.
Graves, A., Mohamed, A.-r., and Hinton, G. (2013).
Speech recognition with deep recurrent neural net-
works. In 2013 IEEE international conference on
acoustics, speech and signal processing, pages 6645–
6649. IEEE.
Grover, C., Givon, S., Tobin, R., and Ball, J. (2008). Named
entity recognition for digitised historical texts. In
LREC.
Hassel, M. (2003). Exploitation of named entities
in automatic text summarization for swedish. In
NODALIDA’03–14th Nordic Conferenceon Compu-
tational Linguistics, Reykjavik, Iceland, May 30–31
2003, page 9.
Hearst, M. A., Dumais, S. T., Osuna, E., Platt, J., and
Scholkopf, B. (1998). Support vector machines. IEEE
Intelligent Systems and their applications, 13(4):18–
28.
Huang, Z., Xu, W., and Yu, K. (2015). Bidirectional
lstm-crf models for sequence tagging. arXiv preprint
arXiv:1508.01991.
Jiang, R., Banchs, R. E., and Li, H. (2016). Evaluating and
combining name entity recognition systems. In Pro-
ceedings of the Sixth Named Entity Workshop, pages
21–27.
Lafferty, J., McCallum, A., and Pereira, F. C. (2001). Con-
ditional random fields: Probabilistic models for seg-
menting and labeling sequence data.
Nadeau, D. and Sekine, S. (2007). A survey of named entity
recognition and classification. Lingvisticae Investiga-
tiones, 30(1):3–26.
Qi, P., Zhang, Y., Zhang, Y., Bolton, J., and Manning, C. D.
(2020). Stanza: A python natural language process-
ing toolkit for many human languages. arXiv preprint
arXiv:2003.07082.
Quinlan, J. R. (1986). Induction of decision trees. Machine
learning, 1(1):81–106.
Rau, L. F. (1991). Extracting company names from text.
In Proceedings The Seventh IEEE Conference on Ar-
tificial Intelligence Application, pages 29–30. IEEE
Computer Society.
Ribeiro, M. T., Wu, T., Guestrin, C., and Singh, S. (2020).
Beyond accuracy: Behavioral testing of nlp models
with checklist. arXiv preprint arXiv:2005.04118.
Ritter, A., Clark, S., Etzioni, O., et al. (2011). Named entity
recognition in tweets: an experimental study. In Pro-
ceedings of the 2011 conference on empirical methods
in natural language processing, pages 1524–1534.
Schmitt, X., Kubler, S., Robert, J., Papadakis, M., and Le-
Traon, Y. (2019). A replicable comparison study of
ner software: Stanfordnlp, nltk, opennlp, spacy, gate.
In 2019 Sixth International Conference on Social Net-
works Analysis, Management and Security (SNAMS),
pages 338–343. IEEE.
talkwalker.com (2020). https://www.talkwalker.com/social-
media-analytics-search.
Thompson, P. and Dozier, C. (1997). Name searching and
information retrieval. In Second Conference on Em-
pirical Methods in Natural Language Processing.
Union of Concerned Scientists (2020).
https://www.ucsusa.org/resources/satellite-database.
Won, M., Murrieta-Flores, P., and Martins, B. (2018). en-
semble named entity recognition (ner): evaluating ner
tools in the identification of place names in historical
corpora. Frontiers in Digital Humanities, 5:2.
SatelliteNER: An Effective Named Entity Recognition Model for the Satellite Domain
107
