
Towards an On-line Handwriting Recognition Interface for Health
Service Providers using Electronic Medical Records
Viktor Mikhael M. Dela Cruz, Christian E. Pulmano and Ma. Regina Justina E. Estuar
Ateneo de Manila Univeristy, Katipunan Avenue, Quezon City, Metro Manila, Philippines
Keywords:
Electronic Health Records, Handwriting Recognition, Health Informatics, Usability.
Abstract:
The 2019 Universal Health Care Act in the Philippines has allowed healthcare service providers to have a
second look at using electronic medical records (EMRs) in their practice with tools that enable servicing the
poorest of the poor and coursing payments via EMR. A review of first world country narratives, however, show
evidence of the substandard usability of EMRs. Physician work is impeded as almost two-thirds of consultation
time is spent documenting on an EMR instead conversing with patients face-to-face. This paper describes a
handwriting recognition interface for EMR data entry that is user-friendly and is unobstructive to the patient-
physician relationship. An initial prototype tested by medical students showed a handwriting recognition
accuracy of 34% while a second testing by health service providers showed a handwriting recognition accuracy
of 42%. Findings show that recognition is challenged by specialized words and accidental markings which
cause extra spaces and extra symbols. Additional features to the system as well as possible augmentations to
improve accuracy and efficiency through ontology, machine learning, and AI are also roadmapped.
1 INTRODUCTION
The promulgation of the 2019 Universal Health Care
Act (UHC) in the Philippines ushers a new era of
health care in the country (Congress of the Philip-
pines, 2018). In line with leveraging the latest in
health technology to facilitate efficient health services
delivery, section 36 of the Universal Health Care Act
requires health service providers and insurers to uti-
lize the electronic health record (EHR), interchange-
ably referred to as electronic medical record (EMR)
(Congress of the Philippines, 2018).
An EMR is an electronic record of an individ-
ual’s health-related information that can be managed
by official clinicians and staff of a health care orga-
nization (Horowitz et al., 2008). It contains patient
information such as diagnoses, medicines, tests, al-
lergies, immunizations, and treatment plans (National
Cancer Institute, 2019). Physicians are able to access
core functions such as viewing, documentation and
care management, ordering, messaging, analysis and
reporting, patient-directed functionality, and billing
through EMRs (Smelcer et al., 2009).
Barriers such as high initial financial costs, slow
and uncertain financial payoffs, and high initial physi-
cian time costs deter medical practitioners from uti-
lizing EMRs (Miller and Sim, 2004) despite EMRs
providing many benefits (Hillestad et al., 2005; Men-
achemi and Collum, 2011; Ben-Assuli et al., 2013;
Blumenthal and Glaser, 2007) and being implemented
on a global scale (McConnell, 2004). One underly-
ing cause of barriers to using EMRs is their poor us-
ability as most EMRs are not intuitive and have in-
terfaces that are not user-friendly (Miller and Sim,
2004; Smelcer et al., 2009; Belden et al., 2009;
Hill Jr et al., 2013). Almost 3 in every 4 physicians
agree that EMRs contribute great stress that leads to
burnout. However, studies show that this stress can
be greatly reduced by improving user interfaces and
including the users into the system design process
(Stanford Medicine, 2018; Gardner et al., 2018).
A solution that may improve the usability of
EMRs, decrease the time spent by physicians encod-
ing in EMRs, and ultimately increase adoption and
usage rate of EMRs is by giving physicians the ability
to manually scribe their patient encounter during con-
sultation. Most EMRs only allow free-text typing as
an off-the-shelf way of data entry but many physicians
still prefer to write (Smelcer et al., 2009; Tsoromokos
et al., 2017; Arvary, 2002). Additionally, electronic
charting can take up to 238.4% longer than manually
writing on paper (Hill Jr et al., 2013; Poissant et al.,
2005). It makes sense, therefore, to integrate hand-
writing recognition as an out-of-the-box functionality
Dela Cruz, V., Pulmano, C. and Estuar, M.
Towards an On-line Handwriting Recognition Interface for Health Service Providers using Electronic Medical Records.
DOI: 10.5220/0008944403830390
In Proceedings of the 13th International Joint Conference on Biomedical Engineering Systems and Technologies (BIOSTEC 2020) - Volume 5: HEALTHINF, pages 383-390
ISBN: 978-989-758-398-8; ISSN: 2184-4305
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
383

to modern EMRs as a way of unobtrusively replacing
old-fashioned paper charting without adding the extra
time taken to type nor the hassle of changing already
successful habituated workflow.
While handwriting recognition systems for
medicine have been implemented (Kumar et al.,
2016; Roy et al., 2017a; Roy et al., 2017b), only few
are concerned with on-line handwriting recognition
(Chen et al., 2010; Bandyopadhyay and Mukherjee,
2014; Holzinger et al., 2010). These systems, albeit
innovative and aim to contribute positively, may still
cause stress and prove to be counterproductive with-
out proper user feedback and assessment. This paper
describes a more user-friendly, less time-consuming,
and more usable means of data entry for EMRs
through a handwriting recognition interface that is
designed for the physician. The approach involves
utilizing open-source technologies and implementing
hardware-agnosticism to open possibilities for low
cost deployment of the solution. Furthermore,
iterative development phases are practiced to ensure
proper incorporation of the user in the design process.
The rest of the paper reports prototype initial re-
sults and findings as well as additional features and
possible augmentations that will be done in next it-
erations in order to improve handwriting recognition
accuracy and efficiency, and EMR usability.
2 HANDWRITING
RECOGNITION IN MEDICAL
CONTEXT
Innovative solutions to cumbersome data entry in the
field of health are speech and handwriting recogni-
tion. In the case of the latter, there have been vari-
ous attempts to explore the subject matter and either
develop new software or optimize currently existing
solutions.
A survey was conducted to determine interest in
handwriting applications for EMRs (Arvary, 2002).
The survey was distributed over 411 primary care
physicians (PCPs) and garnered a total of 156 re-
sponses. The survey showed that 78% of the respon-
dents agreed that digital ink would be a useful sup-
plement to EMRs. Furthermore, no subgroup showed
less than 73% support for handwriting implementa-
tions on EMRs.
The DPP4BIT application is a web-based technol-
ogy that allows editing, management, import, and ex-
port of any document in digital form created for the
purpose of digital recording and handling of medical
equipment (Tsoromokos et al., 2017). Using Anoto’s
digital pen, DPP4BIT is able to perform on-line hand-
writing recognition on digital forms that are managed
by Health Care Units. A pilot test showed that 90% of
nursing staff found the setup absolutely user-friendly,
85% of users felt more confident using the digital pen,
and work efficiency and speed was highly improved.
One study proposed improving the recognition
component by incorporating medical knowledge into
the recognizer (Chen et al., 2010). This integration
provided a 5% increase in accuracy of recognition
from a ”BestConfidence” module that selects word
candidates with the highest confidence (Chen et al.,
2010). This was achieved by augmenting the post-
processing phase of recognition on a semantic level
with a medical knowledge model.
Another study developed an on-line handwriting
recognition system that recognizes India’s second
most used language, Bengali, or Bangla, for the pur-
pose of web-based telemedicine in rural medical cen-
ters (Bandyopadhyay and Mukherjee, 2014). This
paved the way for low-cost, virtual medical consul-
tations between doctors and remote patients where
physical visits were either not needed or impossible
(Bandyopadhyay and Mukherjee, 2014). This was
achieved by utilizing shape-based features and em-
ploying pattern recognition techniques.
It is noteworthy that these studies have been im-
plemented in health systems in parts of the world such
as the United States, India, and Germany, and it can
be safely presumed that there are many more of the
same in other nations. This further strengthens the
need for an efficient, effective, and satisfactory health
system within the Philippines.
3 PROTOTYPE
IMPLEMENTATION
On-line handwriting recognition involves accepting
handwriting input from a digital surface, analyzing
factors such as upward and downward strokes as well
as spaces and time from pen up and pen down, and
then processing the input in order to classify which
characters or words the input approximates to.
For this purpose, the graphical library MyScrip-
tJS was used (MyScript, 2019). MyScriptJS is a
JavaScript library that can be used in any web appli-
cation to bring handwriting recognition.
Handwriting recognition is requested by supply-
ing user-correspondent application keys and a pre-
ferred language to the appropriate API URL. This
request is sent to the MyScriptJS server for process-
ing by their recognizer. MyScript performs three key
processes simultaneously in order to find the closest
HEALTHINF 2020 - 13th International Conference on Health Informatics
384

recognition result. These processes are symbol clas-
sification, segmentation, and linguistic-based analy-
sis. The finished result is sent back to the client
in MyScript’s JSON Interactive Ink eXchange (JIIX)
format.
Figure 1 illustrates a simple implementation of
the handwriting interface using MyScriptJS written
in JavaScript as accessed on a desktop PC. Users
are greeted with a generous writing area and a text
field that shows the corresponding word recognition
of what they write after scribing.
Figure 1: MyScript implementation prototype accessed on
a desktop PC.
The interface was deployed on a private server us-
ing Google services as a means of testing and pro-
totyping. Current features of the prototype include
a full-fledged handwriting recognition module, input
fields for correct text translations and optional identi-
fiers, and the option to either export data locally or to
a private cloud database. The basic flow of a test is
depicted in Figure 2.
Figure 2: Flow of tasks during a prototype test.
4 RESULTS, DISCUSSION,
AND RESEARCH ROADMAP
4.1 Local Experiment
As an initial evaluation of the prototype’s capabili-
ties, students in their 3rd year of studying medicine in
the Philippines were asked to write down 5 common
words used or written by physicians during consulta-
tions. The students were given the choice of using the
prototype on a PC or on a mobile device. After their
testing, the students were asked to take note of the
words they wrote and what were actually recognized.
Figure 3 illustrates a sample use case of the proto-
type. The 10 students who participated in the testing
were able to produce a total of 50 samples which were
manually categorized into four classifications: accu-
rate, wrong, ”with extra characters”, and ”with extra
spaces”. From the 50 samples, the prototype was able
to achieve an accuracy of 34%. Breaking the num-
bers down, the prototype was able to get 17 out of 50
recognitions correct while it got 16 out of 50 recog-
nitions wrong. Furthermore, 10 out of 50 recogni-
tions, albeit correct, were padded with extra charac-
ters and 7 out 50 recognitions, even though correct,
were padded with extra spaces.
Three students used the prototype on a PC while
the other seven tested it on a mobile device. However,
this was not enough to produce significantly different
results. Those who used PCs with the mouse to write
were able to get similar results as those who used mo-
bile devices with fingers to write.
Figure 3: Sample handwriting test case.
After further observation of the local experiment
handwriting samples, some conjectures made to ex-
plain the errors include accidental markings such as
can be seen in the bottom left of Figure 4, slant hand-
writing direction such as in the case of Figure 5,
and poor recognition handling of the letter ”i” such
as in the case of Figure 6 which shows overempha-
sized superscript dots on the letter i’s. With these in
mind, punctuation marks with dots such as the ques-
tion mark (?) and the exclamation point (!) may cause
problems with recognition. Additionally, words writ-
ten on an unequal number of lines may also challenge
the handwriting recognition.
4.2 Real-world Scenario Experiment
In an attempt to gather data from real-world scenar-
ios, a second testing of the prototype was conducted
by health professionals during a series of clinic visits.
Towards an On-line Handwriting Recognition Interface for Health Service Providers using Electronic Medical Records
385

Figure 4: Handwriting test case with wrong recognition due
to accidental marking.
Figure 5: Handwriting test case with wrong recognition due
to slant handwriting.
Figure 6: Handwriting test case with wrong recognition due
to overemphasized superscript dots.
Participants were composed of allied health profes-
sionals working in health establishments based in the
Western Visayas region of Philippines. A total of 15
clinics were visited and 9 respondents agreed to test,
2 of which were nurses, 3 were midwives, and 4 were
doctors.
Participants of the test were asked to write a ran-
dom first name, a random diagnosis, and a random
prescription. The first case was to assess the proto-
type’s name recognition, while the second case was to
assess the extent of medical-related terms the proto-
type can recognize, and the last case was to assess the
prototype’s number and symbol recognition. More-
over, the participants were asked to write with their
pointer finger on a mobile phone sporting a 6.2 inch
display which effectively provided a writing surface
that was 4.5 inches in width and 2 inches in height at
any given time.
Data gathered included the correct words, the ac-
tual recognized words, and the respective stroke ob-
jects that composed each test. Upon test completion,
data collected was sent to a private database for stor-
age and further analysis.
Script and cursive handwriting styles were the two
handwriting styles observed where script was used
generally while cursive was used only by doctors.
Figures 7 and 8 illustrate good representatives of the
general look of the received script and cursive hand-
writing samples.
Figure 7: Sample test case written in script.
Figure 8: Sample test case written in cursive.
The 9 respondents were able to produce a total
of 27 phrases (9 names, 9 diagnoses, 9 prescriptions)
that comprised of 100 words. For the second testing,
the prototype was able to achieve an overall accuracy
of 42% where accurate means perfect recognition in-
cluding capitalization. Further analysis showed that
the prototype was able to achieve an accuracy of 55%
with names, 38% with diagnoses, and 0% with pre-
scriptions. Additionally, an accuracy of 48% and 29%
HEALTHINF 2020 - 13th International Conference on Health Informatics
386

on script and cursive handwriting styles respectively
were also achieved. However, extra characters and
extra spaces occurred more frequently in this round
of testing compared to the first testing.
In the case of names, it was observed that com-
mon names were easily recognized but more unique
ones challenged the prototype. Moreover, in the case
of diagnoses, disregarding less detailed handwriting,
the prototype was able to recognize those composed
of common words such as ”Upper Respiratory Tract
Infection” and ”Dengue Fever” but had difficulties
with specialized ones such as ”Tonsillopharyngitis”.
Furthermore, in the case of prescriptions, the proto-
type performed poorly in recognizing symbols such
as the number sign (#), abbreviations such as ”BID”
or ”sig”, and numbers that were less defined such as
the ”500” depicted in Figure 8.
4.3 Research Roadmap
The next steps involves exploring ways to improve
the current handwriting recognition implementation.
Two possible augmentations may be integrating med-
ical ontologies for word suggestions and comparing
recognitions to a local best approximate for word cor-
rection. These, as well as other additions, will be fur-
ther explicated in the succeeding sections.
At the end state of research, EMR data entry will
then only follow a simple 3-step process: (1) a physi-
cian writes down notes on the interface during consul-
tation, (2) the interface processes handwriting input
and trains itself, and (3) the interface extracts and au-
tomatically maps key clinical text to their respective
EMR fields. Figure 9 outlines the process flow once
all features have been studied and implemented.
4.3.1 Medical Ontologies for Word Suggestion
A novel attempt in aiding handwriting recognition is
by introducing an artificial intelligence that searches
a medical ontology for related concepts that may aug-
ment the current text input written by the user. A med-
ical ontology is a model of the knowledge from a clin-
ical domain (Jovic et al., 2007). It contains all of the
relevant concepts related to the diagnostics, treatment,
clinical procedures and patient data. Essentially, on-
tologies are designed in a way that allows fluid knowl-
edge inference and reasoning. This may allow the
handwriting recognition to provide quick text correc-
tion and beneficial word suggestions as users scribe.
While medical ontologies have been extensively
studied and have been proven to be beneficial (Za-
man et al., 2017; Mate et al., 2015; Cases et al.,
2014; Washington et al., 2009; Sarntivijai et al., 2016;
Maarouf et al., 2017; Scheuermann et al., 2009), the
application of these has yet been explored in the con-
text of text correction and word suggestion for med-
ical handwriting recognition systems. Medical on-
tologies used in the previous studies include the Hu-
man Phenotype Ontology (HPO) (Robinson et al.,
2008) and the Ontology for General Medical Science
(OGMS) (Scheuermann et al., 2009). The OGMS will
serve as the pilot medical ontology utilized in the con-
tinuation of this study.
The OGMS is a framework of terms that encom-
passes the field of diseases, from causes and mani-
festations to diagnostic acts, as recognized and inter-
preted in the clinic (Scheuermann et al., 2009). It in-
cludes very general terms used in the clinical settings
such as ”patient”, ”diagnosis”, and ”disease”. This
will provide the handwriting recognition interface a
good backbone for ontological text input augmenta-
tion.
4.3.2 Local Best Approximate for Correction
MyScriptJS uses Interactive Ink in order to processes
user input in real time (MyScript, 2019). Through
Interactive Ink, given some handwriting, MyScriptJS
is able to transform each character into a stroke object
which includes an array of x and y’s which are the cur-
rent coordinates of the pointer on the surface, an array
of t’s which is the current timestamp of the pointer
event, an array of p’s which is the current pressure
information associated to the event, and a pointerId
which is an identifier for the current pointer. Each of
the properties are recorded per unit of time until all
strokes are finished.
An attempt in improving the accuracy of the hand-
writing recognition can be made by adding a func-
tion that compares the MyScriptJS text translation to
a best approximate recognition from a local knowl-
edge base. The local knowledge base contains previ-
ous strokes and their corresponding text translations.
This will be built using data structures such as ar-
rays and objects using JavaScript but is still subject to
change once efficiency comparisons have been made
with data structure implementations from other pro-
gram languages.
The proposed process is depicted in Figure 10.
Strokes will simultaneously be processed by the
MyScriptJS server and by the local knowledge base.
The local knowledge base will check for an entry
that closely matches the current strokes. If there is a
match, the match will be offered to the user as a sug-
gestion. The user can then decide if the best approx-
imate from the local knowledge base is better than
the MyScriptJS text translation by either keeping the
current translation or selecting the suggestion. The
record is updated in the knowledge base or is added
Towards an On-line Handwriting Recognition Interface for Health Service Providers using Electronic Medical Records
387

Figure 9: Goal process flow following simple 3-step EMR data entry.
to the knowledge base if it does not currently exist.
Through this, the knowledge base can learn over
time as more strokes are recorded along with their cor-
responding user-selected correct text. Additionally,
the handwriting recognition interface will be able to
give out more accurate suggestions. It is possible to
look at superseding the MyScriptJS text translations
with the local best approximates once a high-enough
confidence level is achieved.
4.3.3 Clinical Text Extraction
Once the handwriting input has been converted, the
resulting plain text is fed into a clinical text analyzer
to be able to filter only the words, phrases, and sen-
tences that are important for the EMR to store. For
this purpose, the natural language processing system
cTAKES will be used (Savova et al., 2010). Devel-
oped by the Mayo Clinic, cTAKES is an open-source
NLP system that allows the extraction of information
from clinical free-text. cTAKES prides itself in be-
ing powerful, fast, scalable, modular, portable, and
free. Some of what it can do with clinical texts are
event discovery, negation and uncertainty detection,
time expression discovery, as well as detect certain
keywords that fall under a certain Unified Medical
Language System (UMLS) classification.
4.3.4 Integration within an EMR
SHINEOS+ is a web and mobile-based system that
aims to address the data management needs of doc-
tors, nurses, midwives, and other allied health profes-
sionals in the Philippines (The Secured Health Infor-
mation Network Exchange, 2019). The SHINEOS+
EMR service sports a number of features such as
patient profiling and consultation recording, inter-
network referral, automated reminders, and ePre-
scriptions.
Within SHINEOS+, physicians are able to cre-
ate profiles for their patients as well as add consul-
tation entries for them. A patient record contains ba-
sic information such as name, gender, age, birthday,
and record location. Consultation data includes com-
plaints and vitals and physicals at time of consulta-
tion.
After filtering the text from the handwriting inter-
face and extracting key clinical text, the resulting set
HEALTHINF 2020 - 13th International Conference on Health Informatics
388
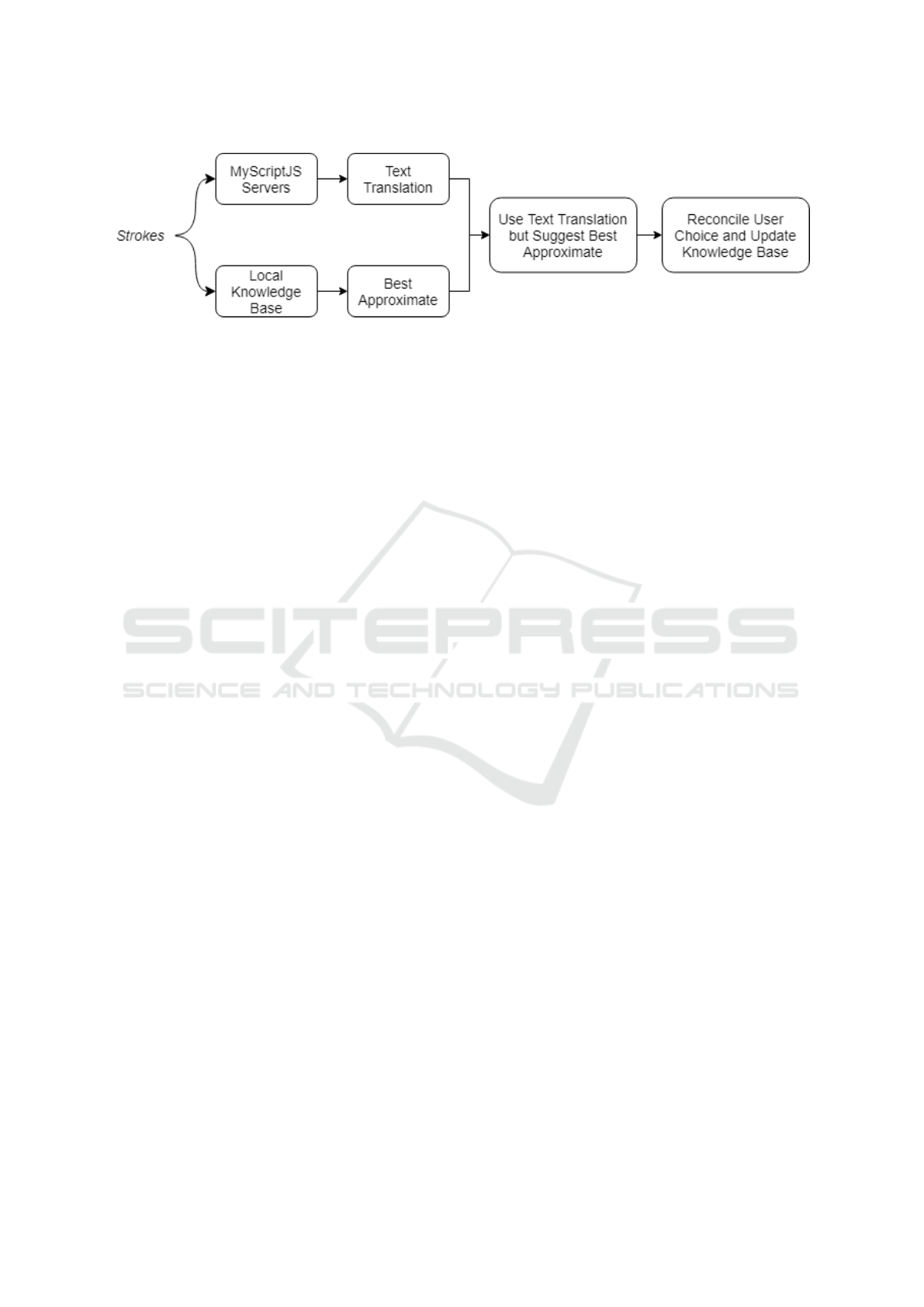
Figure 10: Methodology for accuracy improvement.
of strings will be automatically mapped to their corre-
sponding fields in the SHINEOS+ EMR service, cre-
ating a seamless transition from handwritten script to
digitized text without breaking natural workflow.
5 CONCLUSIONS
This paper looked into the poor usability of modern-
day EMRs and described a handwriting recognition
interface that captures physician handwriting in real-
time and converts the digital input into plain text.
The interface was tested by various health practition-
ers and the results were reported. Future additions to
greatly extend the interface’s functionality, practical-
ity, and usability were also discussed.
The Universal Healthcare Act in the Philippines is
changing the nation’s healthcare landscape. With the
UHC in play, EMRs are now at the forefront of health
services. However, as beneficial as EMRs are, the
rapid advancement of technology has changed their
requirement from being functional to being usable.
Inefficient and unwieldy health systems cannot be tol-
erated in today’s fast moving world where patients
come by the dozens. It is in the best interest of this re-
search that physicians are given the proper tools to use
so that they can worry less about compliance and fo-
cus more on tending to others. A handwriting recog-
nition interface that can serve as a plug-in to existing
EMRs hopes to be beneficial in providing a seamless
interface in doctor-patient interaction.
ACKNOWLEDGEMENTS
The researchers would like to thank the Ateneo
School of Science and Engineering as well as the De-
partment of Science and Technology for subsidizing
this study through the SOSE Industry Grant and the
DOST-ERDT grant respectively. Additionally, the re-
searchers would also like to thank the Ateneo Center
for Computing Competency Research (ACCCRE) for
their support.
REFERENCES
Arvary, G. (2002). A primary care physician perspective
survey on the limited use of handwriting and pen com-
puting in the electronic medical record. Journal of In-
novation in Health Informatics, 10(3):161–172.
Bandyopadhyay, A. and Mukherjee, B. (2014). Web based
bangla online handwritten prescription system for
telemedicine through multimedia conferencing. Inter-
national Journal of Advanced Research in Computer
Engineering & Technology (IJARCET), 3(12).
Belden, J. L., Grayson, R., and Barnes, J. (2009). Defin-
ing and testing emr usability: Principles and proposed
methods of emr usability evaluation and rating. Tech-
nical report, Healthcare Information and Management
Systems Society (HIMSS).
Ben-Assuli, O., Shabtai, I., and Leshno, M. (2013). The im-
pact of ehr and hie on reducing avoidable admissions:
controlling main differential diagnoses. BMC Medical
Informatics and Decision Making, 13(1):49.
Blumenthal, D. and Glaser, J. P. (2007). Information tech-
nology comes to medicine.
Cases, M., Briggs, K., Steger-Hartmann, T., Pognan, F.,
Marc, P., Klein
¨
oder, T., Schwab, C., Pastor, M.,
Wichard, J., and Sanz, F. (2014). The etox data-
sharing project to advance in silico drug-induced tox-
icity prediction. International journal of molecular
sciences, 15(11):21136–21154.
Chen, Q., Gong, T., Li, L., Tan, C. L., and Pang, B. C.
(2010). A medical knowledge based postprocessing
approach for doctor’s handwriting recognition. In
2010 12th International Conference on Frontiers in
Handwriting Recognition, pages 45–50. IEEE.
Congress of the Philippines (2018). An act instituting uni-
versal health care for all filipinos, prescribing reforms
in the health care system, and appropriating funds
therefor.
Gardner, R. L., Cooper, E., Haskell, J., Harris, D. A.,
Poplau, S., Kroth, P. J., and Linzer, M. (2018). Physi-
cian stress and burnout: the impact of health infor-
mation technology. Journal of the American Medical
Informatics Association, 26(2):106–114.
Towards an On-line Handwriting Recognition Interface for Health Service Providers using Electronic Medical Records
389

Hill Jr, R. G., Sears, L. M., and Melanson, S. W. (2013).
4000 clicks: a productivity analysis of electronic med-
ical records in a community hospital ed. The American
journal of emergency medicine, 31(11):1591–1594.
Hillestad, R., Bigelow, J., Bower, A., Girosi, F., Meili, R.,
Scoville, R., and Taylor, R. (2005). Can electronic
medical record systems transform health care? poten-
tial health benefits, savings, and costs. Health affairs,
24(5):1103–1117.
Holzinger, A., Schl
¨
”ogl, M., Peischl, B., and Debevc, M.
(2010). Optimization of a handwriting recognition
algorithm for a mobile enterprise health information
system on the basis of real-life usability research. In
International Conference on E-Business and Telecom-
munications, pages 97–111. Springer.
Horowitz, J., Mon, D., Bernstein, B., and Bell, K. (2008).
Defining key health information technology terms.
Department of Health and Human Services, Office
of the National Coordinator for Health Information
Technology.
Jovic, A., Prcela, M., and Gamberger, D. (2007). Ontolo-
gies in medical knowledge representation. In 2007
29th International Conference on Information Tech-
nology Interfaces, pages 535–540. IEEE.
Kumar, S., Sahu, N., Deep, A., Gavel, K., and Ghost, R.
(2016). Offline handwriting character recognition (for
use of medical purpose) using neural network.
Maarouf, H., Taboada, M., Rodriguez, H., Arias, M., Sesar,
´
A., and Sobrido, M. J. (2017). An ontology-aware in-
tegration of clinical models, terminologies and guide-
lines: an exploratory study of the scale for the assess-
ment and rating of ataxia (sara). BMC medical infor-
matics and decision making, 17(1):159.
Mate, S., K
¨
opcke, F., Toddenroth, D., Martin, M.,
Prokosch, H.-U., B
¨
urkle, T., and Ganslandt, T. (2015).
Ontology-based data integration between clinical and
research systems. PloS one, 10(1):e0116656.
McConnell, H. (2004). International efforts in imple-
menting national health information infrastructure and
electronic health records. World hospitals and health
services: the official journal of the International Hos-
pital Federation, 40(1):33–7.
Menachemi, N. and Collum, T. H. (2011). Benefits and
drawbacks of electronic health record systems. Risk
management and healthcare policy, 4:47.
Miller, R. H. and Sim, I. (2004). Physicians’ use of elec-
tronic medical records: barriers and solutions. Health
affairs, 23(2):116–126.
MyScript (2019). About myscriptjs.
National Cancer Institute (2019). Definition of electronic
medical record.
Poissant, L., Pereira, J., Tamblyn, R., and Kawasumi, Y.
(2005). The Impact of Electronic Health Records on
Time Efficiency of Physicians and Nurses: A System-
atic Review. Journal of the American Medical Infor-
matics Association, 12(5):505–516.
Robinson, P. N., K
¨
ohler, S., Bauer, S., Seelow, D., Horn,
D., and Mundlos, S. (2008). The human phenotype
ontology: a tool for annotating and analyzing human
hereditary disease. The American Journal of Human
Genetics, 83(5):610–615.
Roy, P. P., Bhunia, A. K., Das, A., Dhar, P., and Pal, U.
(2017a). Keyword spotting in doctor’s handwriting on
medical prescriptions. Expert Systems with Applica-
tions, 76:113–128.
Roy, P. P., Bhunia, A. K., Das, A., Dhar, P., and Pal, U.
(2017b). Keyword spotting in doctor’s handwriting
on medical prescriptions. Expert Systems with Appli-
cations, 76:113–128.
Sarntivijai, S., Vasant, D., Jupp, S., Saunders, G., Bento,
A. P., Gonzalez, D., Betts, J., Hasan, S., Koscielny,
G., Dunham, I., et al. (2016). Linking rare and com-
mon disease: mapping clinical disease-phenotypes to
ontologies in therapeutic target validation. Journal of
biomedical semantics, 7(1):8.
Savova, G. K., Masanz, J. J., Ogren, P. V., Zheng, J., Sohn,
S., Kipper-Schuler, K. C., and Chute, C. G. (2010).
Mayo clinical text analysis and knowledge extraction
system (ctakes): architecture, component evaluation
and applications. Journal of the American Medical
Informatics Association, 17(5):507–513.
Scheuermann, R. H., Ceusters, W., and Smith, B. (2009).
Toward an ontological treatment of disease and di-
agnosis. Summit on translational bioinformatics,
2009:116.
Smelcer, J. B., Miller-Jacobs, H., and Kantrovich, L.
(2009). Usability of electronic medical records. Jour-
nal of usability studies, 4(2):70–84.
Stanford Medicine, T. H. P. (2018). How doctors feel about
electronic health records.
The Secured Health Information Network Exchange (2019).
About shineos+.
Tsoromokos, D., Tsaloukidis, N., Zarakovitis, D., and
Lazakidou, A. (2017). Use of the dpp4bit system for
the management of hospital medical equipment. In
ICIMTH, pages 161–164.
Washington, N. L., Haendel, M. A., Mungall, C. J.,
Ashburner, M., Westerfield, M., and Lewis, S. E.
(2009). Linking human diseases to animal models us-
ing ontology-based phenotype annotation. PLoS biol-
ogy, 7(11):e1000247.
Zaman, S., Sarntivijai, S., and Abernethy, D. R. (2017). Use
of biomedical ontologies for integration of biologi-
cal knowledge for learning and prediction of adverse
drug reactions. Gene regulation and systems biology,
11:1177625017696075.
HEALTHINF 2020 - 13th International Conference on Health Informatics
390
