
Configural Representation of Facial Action Units for Spontaneous Facial
Expression Recognition in the Wild
Nazil Perveen
a
and Chalavadi Krishna Mohan
b
Department of Computer Science and Engineering, IIT Hyderabad, Hyderabad, India
Keywords:
Facial Expression Recognition, Configural Features, Facial Action Units, Facial Action Coding System.
Abstract:
In this paper, we propose an approach for spontaneous expression recognition in the wild using configural
representation of facial action units. Since all configural features do not contribute to the formation of fa-
cial expressions, we consider configural features from only those facial regions where significant movement
is observed. These chosen configural features are used to identify the relevant facial action units, which are
combined to recognize facial expressions. Such combinational rules are also known as coding system. How-
ever, the existing coding systems incur significant overlap among facial action units across expressions, we
propose to use a coding system based on subjective interpretation of the expressions to reduce the overlap
between facial action units, which leads to better recognition performance while recognizing expressions.
The proposed approach is evaluated for various facial expression recognition tasks on different datasets: (a)
expression recognition in controlled environment on two benchmark datasets, CK+ and JAFFE, (b) sponta-
neous expression recognition on two wild datasets, SFEW and AFEW, (c) laughter localization on MAHNOB
laughter dataset, and (d) recognizing posed and spontaneous smiles on UVA-NEMO smile dataset.
1 INTRODUCTION
Humans communicate in multiple ways like verbal,
spoken, non-verbal, and unspoken. Facial expressions
are considered to be the best way of communicating
the message in non-verbal and unspoken way. Among
all the body expressions, face is considered to play the
vital role in communicating with others through its
expressions. Ekman (1957) categorize human facial
expression into seven universal categories of angry,
disgust, fear, happy, neutral, sad, and surprise. Facial
expression recognition is used ubiquitously in differ-
ent areas of human life like psychology, autism, con-
sumer neuro-science, neuro-marketing, media testing
and advertisement, investigations, etc. Bartlett et al.
(2003); Perveen et al. (2012); Perveen et al. (2018);
Perveen et al. (2016); Zhan et al. (2008). However,
with growing requirements, the need of relating it
with human computer interaction (HCI) system be-
comes one of the most extensive area of research in
pattern recognition and computer vision.
Human behavior is highly dependant on the signal
that brain emits as these signals result in movement of
a
https://orcid.org/0000-0001-8522-7068
b
https://orcid.org/0000-0002-7316-0836
one or more combination of muscles for the necessary
action. Similarly, facial expression recognition are the
results of the movement of facial muscles triggered
by the single nerve known as a facial nerve in human
psychology Snell (2008). However, owing to the dif-
ficulties in tracking of facial muscles, the other widely
used approach for the facial expression recognition is
the implementation of multiple coding systems of dif-
ferent facial parts whose combination results to one of
the facial expressions. This technique is known as fa-
cial action coding system (FACS), introduced in 1969,
which was later implemented and further improved
by Ekman and Friesen (1976). Facial action cod-
ing system is basically the combination of multiple
facial action units (FAUs), where each FAUs corre-
sponds to a single facial muscle activity. Due to sub-
jective observations of facial action units (FAUs), one
FAU can be mis-interpreted as another FAU. Also,
manual labelling of the FAUs in datasets are labo-
rious, time-taking, and error prone. But, with the
current methodologies like, active appearance model
(AAM), active shape model (ASM), and constrained
local model (CLM), the automatic formation of FAUs
have become less error prone, which reduces the task
of manual labelling to some extent.
The proposed work is motivated by Kotsia and
Perveen, N. and Mohan, C.
Configural Representation of Facial Action Units for Spontaneous Facial Expression Recognition in the Wild.
DOI: 10.5220/0009099700930102
In Proceedings of the 15th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2020) - Volume 4: VISAPP, pages
93-102
ISBN: 978-989-758-402-2; ISSN: 2184-4321
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
93

Pitas (2007) and Benitez-Quiroz et al. (2016). Us-
ing geometric distances, Kotsia and Pitas (2007) rec-
ognize facial expressions in one of the two ways:
(a) by tracking the facial features and its deforma-
tion throughout the videos (b) by detecting the fa-
cial action units (FAUs) and combining them with
the multiple rules for evaluating expressions. In both
the ways, authors use multi-class support vector ma-
chine to classify the facial expressions where user has
to manually define the candide-grid Ahlberg (2001)
onto the face for facial feature tracking. This ap-
proach achieves a recognition performance of 99.7%
on CK+ dataset with feature tracking and 95.1% us-
ing FAUs detection. Benitez-Quiroz et al. (2016)
proposes the automatic facial action unit recognition
from any given face image in real time by consid-
ering all categories of geometric difference, angles,
and triangles that exist in the face. All possible dis-
tances are extracted among the 66 facial landmark
points and Delaunay triangle distance is calculated
with all possible angles (≤ 360) imposed on the fa-
cial landmarks and resulting in the features vector
of dimension R
2466
. Along with facial action unit
recognition, the basic expressions and compounded
expressions generated during the experimentation are
listed. However, an approach described by Irene is
semi-automatic, as for the given frame, the user has to
manually define the candide-grid Ahlberg (2001) over
the face for proper tracking of the facial features. In
our approach, we do not require such manual grid for
tracking of the facial features. And contrary to the ap-
proach described by Benitez-Quiroz et al. (2016), we
do not require large dimensions of the feature vector.
The onset form of videos is sufficient for the complete
pipeline of the proposed method.
The main objective of the proposed framework is
to develop a simple and efficient approach for recog-
nizing facial expression in spontaneous environments.
We use the facial action coding system (FACS) for
recognizing facial expressions, as humans also rec-
ognize facial expression through facial templates and
its multiple combinations Ekman and Friesen (1976).
Following are the observations from the reviewed
works presented above:
1. Existing video based facial expression recogni-
tion systems generally consider all possible dis-
tances and angles among facial landmark points
distributed over the facial regions to capture the
configural features. Most of these configural fea-
tures do not contain relevant information about
facial expressions but rather result in high inter-
expression similarity. Moreover, calculating such
features adds extra computational overhead.
2. The existing facial action coding system (FACS)
incurs significant overlap in facial action units
(FAUs) across different expressions, which leads
to misclassification.
In order to address the above issues, we propose
the framework, which comprises of the following:
• To reduce inter-expression similarity, we consider
configural features for only those facial regions
where significant movement is observed during
expressions.
• To reduce overlap in the facial action units across
expressions, we introduce a coding system, which
are least computational expensive.
• Since existing approaches address expression
recognition and expression localization in isola-
tion, we evaluate the efficacy of the proposed ap-
proach on (a) spontaneous expression recognition
in wild (b) laughter localization, and (c) recogni-
tion of posed and spontaneous smiles.
The rest of the section is organized as follows:
Section 2 presents the proposed framework. Section 3
and 4 discuss the experimental evaluation of proposed
approach in constrained datasets and unconstrained
datasets, respectively. Section 5 list experiments of
the proposed approach on laughter localization and
posed versus spontaneous smile classification. Sec-
tion 6 gives the conclusion.
2 PROPOSED WORK
In this section, we present the proposed approach for
automatic spontaneous facial expression recognition
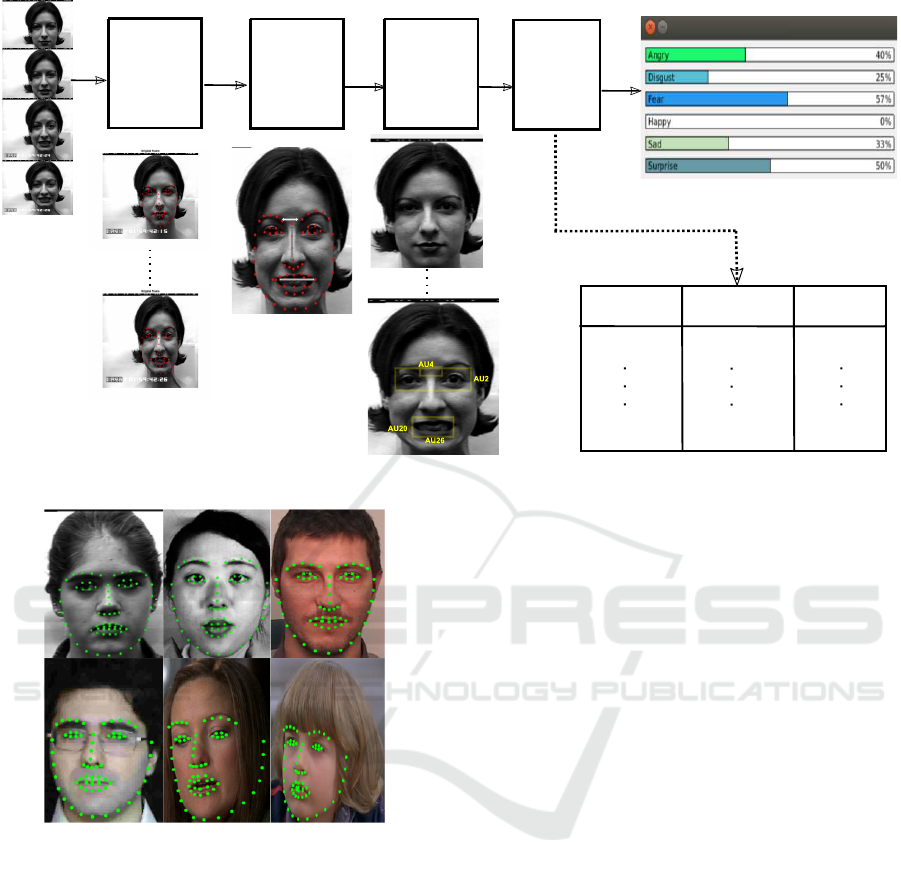
in the wild. Figure 1 presents the block diagram of
the proposed approach. The framework consists of
four major steps: (i) face and landmark detection, (ii)
configural feature generation, (iii) facial action unit
(FAUs) recognition, and (iv) facial action coding sys-
tem (FACS) and expression recognition, which are
detailed below:
2.1 Face and Landmarks Detection
In order to recognize facial expressions, the most im-
portant step is to detect the face in the video and lo-
calize it for further processing. We use discrimina-
tive response map fitting method (DRMF) by Asthana
et al. (2013), for face detection, localization, and land-
marks fitting. Figure 2 shows some of the exam-
ples from each dataset used in our experimentation.
In general, two modeling approaches are commonly
used for facial landmark fitting: 1) holistic model-
ing and, 2) part-based modeling. Because of certain
VISAPP 2020 - 15th International Conference on Computer Vision Theory and Applications
94
Coding Rules
EMFACS
Lie-to-me FACS
Angry
Surprise
4+5+7+23
4+7+23
1+2+5+26
2+5+26
Face detection
and
facial
landmarks
fitting
Configural
features
generation
Facial
action unit
formation
Facial
action coding
system
Figure 1: Block diagram of the proposed spontaneous facial expression recognition in wild environment.
Figure 2: Face detection and landmarks fitting over the fa-
cial parts using discriminative response map fitting method
Asthana et al. (2013) on different datasets, which are used
in experimental evaluation.
drawbacks in holistic modeling like facial features are
extracted using facial texture and warping techniques,
due to, which variations in the facial movement are
not captured properly. Also, general issues like oc-
clusions and 3-D shape of face is not easily modelled
using holistic modeling Albrecht et al. (2008). There-
fore we use DRMF, as it follows part-based modelling
by detecting the facial parts and then using these fa-
cial part parameters response maps are created. These
response maps with the help of weak learners and a
regression technique learn the robust functions to up-
date the shape parameters. This updation goes on till
it obtains the best fitting score. Face detection and
proper landmark fitting are the most crucial and im-
portant stage of our whole approach, as the next stages
is heavily dependent on the correct and accurate de-
tection of face and landmark localization on it.
Let V =
n
f
1
, f
2
, ··· , f
i
, ··· , f
n
o
be the video
consisting of n frames. From each frame f
i
a set of t
landmarks points are extracted, which is represented
as
P
i
=
n
~p
i,1
, ~p
i,2
, · ·· ,~p
i,k
, · ·· ,~p
i,t
o
, (1)
where ~p
i, j
=
x
j
,y
j
and t = 66. All landmark
points in the training images are normalized as men-
tioned in Asthana et al. (2013).
2.2 Configural Feature Generation
Once we obtain the facial landmarks points, the next
step is to calculate the distance among these landmark
points to generate configural features
C
i
=
n
c
i,1
, c
i,2
, · ·· ,c
i,l
, · ·· , c
i,s
o
. (2)
Here, C
i
∈ R
i×s
where s is the number of config-
ural features. And each c
i,l
is generated from the pair
of landmark points ~p
i,k
defined in equation 1, i.e
c
i,l
= k ~p
i, j
1
− ~p
i, j
2
k, (3)
where j
1
, j
2
∈
1,2, · ·· ,t
and j
1
6= j
2
.
Once the set of configural features C
i
within the
given frame f
i
are obtained, the next step is to deter-
mine facial action units (FAUs) from these configural
features.
Configural Representation of Facial Action Units for Spontaneous Facial Expression Recognition in the Wild
95

Figure 3: Facial action units considered in Lie-to-me series for expression evaluation Ekman (2009).
2.3 Facial Action Unit (FAU) Formation
In this stage, the configural features C
i
obtained from
above stage are used to determine the facial action
units A
i
. Table 1 shows the landmarks and corre-
sponding configural features involved in the FAUs
formation. In our approach, we consider 12 basic
FAUs for six universal expressions.
Some configural features are evaluated by calcu-
lating average of the landmark points, this is because
those landmark position are very near to each other
and resembles in the similar movements during facial
movements. Once FAUs are obtained, the final step is
to combine these FAUs to form facial expressions. Let
us consider A
i
be the set of facial action units (FAUs)
for frame f
i
represented as
A
i
=
n
a
i,1
, a
i,2
, · ·· ,a
i,q
, · ·· , a
i,r
o
, (4)
where r ∈
1,2, · ·· ,12
. From equation 2 each a
i,q
is generated from c
i,s
such that
a
i,q
=
(
1,if ∀ k c
1,s
− c
i,s
k > T and i > 1
0,otherwise.
(5)
In the above equation, T is the threshold value that
holds the amount of displacement occurring for con-
figural features across the frames with respect to neu-
tral frame, which aids in formation of facial action
units. As specified in equation 4, each FAU is the
combination of multiple configural features. This
threshold value T is determined empirically. In next
sub-section we describe how to combine the facial ac-
tion units obtained for facial expression recognition.
Table 1: Facial action units and their respective landmarks
used for computing distances within a frame.
Function
Landmarks involve
(configural features)
FAU 1 Inner Brow Raiser
c
i,1
=k ~p
i,22
−~p
i,40
k
c
i,2
=k ~p
i,23
−~p
i,43
k
c
i,3
=k ~p
i,18
−~p
i,37
k
c
i,4
=k ~p
i,27
−~p
i,46
k
FAU 2 Outer Brow Raiser
c
i,5
=k
~p
i,20
+~p
i,21
2
−
~p
i,38
+~p
i,39
2
k
c
i,6
=k
~p
i,24
+~p
i,25
2
−
~p
i,44
+~p
i,45
2
k
FAU 4 Brow Lowerer
c
i,7
=k ~p
i,22
−~p
i,23
k
FAU 5 Upper Lid Raiser
Similar to c
i,5
, c
i,6
, and
c
i,8
=k
~p
i,38
+~p
i,39
2
−
~p
i,41
+~p
i,42
2
k
c
i,9
=k
~p
i,44
+~p
i,45
2
−
~p
i,47
+~p
i,48
2
k
FAU 7 Lid Tightener Similar to c
i,8
and c
i,9
FAU 9 Nose Wrinkler
c
i,10
=k ~p
i,28
−~p
i,30
k
FAU 10 Upper Lip Raiser
c
i,11
=k ~p
i,61
−~p
i,66
k
c
i,12
=k ~p
i,63
−~p
i,64
k
c
i,13
=k ~p
i,33
−~p
i,55
k
c
i,14
=k ~p
i,34
−~p
i,52
k
c
i,15
=k ~p
i,35
−~p
i,53
k
c
i,16
=k ~p
i,42
−~p
i,49
k
c
i,17
=k ~p
i,47
−~p
i,55
k
FAU 12 Lip Corner Puller
c
i,18
=k ~p
i,49
−~p
i,55
k
c
i,19
=k
~p
i,40
+~p
i,41
+~p
i,42
3
−~p
i,49
k
c
i,20
=k
~p
i,43
+~p
i,47
+~p
i,48
3
−~p
i,55
k
FAU 15 Lip Corner Depressor
Similar to c
i,19
and c
i,20
FAU 20 Lip Stretcher
c
i,21
=k ~p
i,49
−~p
i,55
k
FAU 23 Lip Tightener
c
i,22
=k ~p
i,52
−~p
i,58
k
FAU 26 Jaw Drop
Similar to c
i,22
and
c
i,23
=k ~p
i,51
−~p
i,59
k
c
i,24
=k ~p
i,53
−~p
i,57
k
2.4 Facial Action Coding System
(FACS) and Expression Recognition
Facial action coding system (FACS) is very old tech-
nique, which researchers and psychologists have used
over the years for recognition of expressions. In this
work, we propose to use a coding system, namely,
VISAPP 2020 - 15th International Conference on Computer Vision Theory and Applications
96

“Lie-to-me” FACS (L-FACS). Lie-to-me is the tele-
vision drama series guided by Ekman (2009), one of
the pioneer in the area of facial expression recogni-
tion. The FACS used in this drama series are shown
in Figure 3.
In this drama series, an investigation agency tries
to solve the investigating cases with the help of body
language, facial expressions, and human psychology.
The commonly used approaches to combine these fa-
cial action units are known as emotional FACS (EM-
FACS) and FACS-AID (FACS affect interpretation
dictionary). Also, different researchers explored mul-
tiple combinations based on their applications needs
Kotsia and Pitas (2007)-Benitez-Quiroz et al. (2016).
However, we observed significant overlap among the
FAUs across the expressions in EMFACS and FACS-
AID. Therefore, we follow the subjective interpreta-
tion of facial movements during expression formation
such that overlapping among the facial action units
across the facial expressions is as low as possible.
For example, from Figure 3 and Table 2, it can be
observed that FAU-10 (upper lip raiser) is more suit-
able than FAU-15 (lip corner depressor) for recogniz-
ing disgust expression. Thus, by forming a new cod-
ing rule “9+10” for disgust instead of “9+15” reduces
the overlap of FAU-15 that exists between the disgust
and sad expressions in EM-FACS. Similarly, for every
subjective interpretation, corresponding FAU combi-
nations are assigned in L-FACS to recognize facial ex-
pressions. Table 2 gives the complete description of
FAUs combination used in EM-FACS and L-FACS.
The frame level decisions obtained using L-FACS are
then combined to give the decision for a video. The
combination is based on most occurring expression
across the frame level decisions to determine the ex-
pression class for a particular video.
Table 2: FAUs combination from two different coding
schemes.
Expressions
Facial action units
(EKMAN FACS)
Facial action units
(L-FACS)
Angry 4+5+7+23 4+7+23
Disgust 9+15 9+10
Fear 1+2+4+5+7+20+26 2+4+5+20
Happy 6+12 12
Sad 1+4+15 1+15
Surprise 1+2+5+26 2+5+26
3 EXPERIMENTAL EVALUATION
OF CONSTRAINED DATASETS
In this section, we evaluate the proposed approach on
benchmark datasets, namely, Cohn-Kanade-extended
and japanese female facial expression dataset.
3.1 Results on Cohn-Kanade-Extended
(CK+)
CK+ Lucey et al. (2010) dataset consist of total 593
posed expression sequences from 123 subjects cap-
tured in the duration of 10-60 frames. It contains
videos where the expression formation is from neutral
to apex expressions under controlled settings. This
dataset consist of 69% females, 81% Euro-american,
13% Afro-american, and 6% other groups. The poses
ranges from fully frontal to 30 degree facial views
of resolution 640 × 480 with 8-bit grayscale. The
entire dataset has been categorize into seven facial
expressions with their corresponding emotion labels
and FAUs labels. Out of these seven expression, we
have consider following six expressions, namely, an-
gry, disgust, fear, happy, sad, and surprise in the pro-
posed approach. Table 3 presents comparison of the
proposed approach with state of the art approaches.
The confusion matrices for the proposed approach us-
ing EMFACS and L-FACS are presented in Figure 4
and Figure 5, respectively. It can be observed that
proposed approach performs better than existing EM-
FACS as disgust is misclassified by sad using EM-
FACS, which is due to common FAU-15 but using L-
FACS this misclassification is handled easily. Due to
such proper selection of configural features and by re-
ducing the overlap of facial action units across the ex-
pressions, we achieve the better results than existing
coding systems.
Table 3: Performance comparison with the recent ap-
proaches on CK+ datasets.
Methods Accuracy (%)
Cross-lingual discriminative learning
with posterior regularization Ganchev and Das (2013)
74.4
Joint Patch and Multi-label Learning
with SVM Zhao et al. (2016)
78.0
Distance-weighted manifold learning Jing and Bo (2016) 80.7
Sparse representation based
emotion recognition Lee et al. (2014)
84.4
Deep CNN with multi-layer restricted
boltzmann machine Liu et al. (2013)
92.0
3D-CNN with deformable action parts Liu et al. (2014b) 92.4
Configural features with lie-to-me
(with T>3)
92.88
It is to be noted that we used only L-FACS
for facial expression recognition in below mentioned
datasets.
3.2 Results on Japanese Female Facial
Expression (JAFFE)
JAFFE Lyons et al. (1998) dataset is posed facial ex-
pression dataset consist of 6 basic expressions and
neutral expressions. It contains 213 gray scale images
from 10 subjects mostly consisting of frontal facial
Configural Representation of Facial Action Units for Spontaneous Facial Expression Recognition in the Wild
97

Figure 4: Confusion matrix for CK+ dataset using EM-
FACS mentioned in Table 2. Using EMFACS, the proposed
work obtain 71.19% accuracy.
Figure 5: Confusion matrix for CK+ dataset using L-FACS
mentioned in Table 2. Using L-FACS, the proposed work
obtains 92.88% accuracy.
views. Our method mainly design for the evaluation
of expression in videos. As this dataset contain neu-
tral expression image for each subject, we are able to
evaluate our proposed framework performance on it.
Table 4 presents the performance comparison of the
proposed approach with recent state of the art meth-
ods. Figure 6 gives the confusion matrix evaluated us-
ing relevant configural features with L-FACS coding
system. As FAU-2 and FAU-5 are the common facial
action units in fear and surprise expressions, it can be
observed that fear examples are mostly mis-classified
as surprise.
Table 4: Performance comparison with the recent ap-
proaches on JAFFE dataset.
Methods Accuracy (%)
Active shape model and
support vector machineLei et al. (2009)
89.5
Modified classification and regression tree
using LBP and supervised descent methodHappy and Routray (2015)
90.72
Distance weighted manifold learning Jing and Bo (2016) 91
Local binary pattern (LBP)
and salient patches extraction
with SVMHappy and Routray (2015)
91.78
Configure features with L-FACS
(with T >3)
92.22
Figure 6: Confusion matrix for JAFFE dataset using L-
FACS mentioned in Table 4. Using L-FACS, the proposed
work obtain 92.22% accuracy in recognizing facial expres-
sions (with T>3).
4 EXPERIMENTAL EVALUATION
OF UNCONSTRAINED
DATASETS
The viability of the proposed approach is also shown
on spontaneous and wild datasets, namely, static fa-
cial expression in wild (SFEW) and acted facial ex-
pression in wild (AFEW).
4.1 Results on Static Facial Expression
in Wild (SFEW)
SFEW Dhall et al. (2011) is the collection of static
images of six basic facial expressions and one neu-
tral expression. It consists of three level of subject
dependency for facial expressions evaluations, i.e.
strictly person specific (SPS), partial person indepen-
dent (PPI), and strictly person independent (SPI). The
proposed approach requires neutral images, which
can only be obtained from onset expression videos.
As onset videos are a part of the SPS level of SFEW
dataset, we evaluate our approach on same. Table 5
shows the performance of SFEW dataset compared to
recent approaches. The confusion matrix on SFEW
SPS dataset is shown in Figure 7.
Table 5: Performance comparison with recent approaches
on SFEW dataset.
Methods Accuracy (%)
Transfer learning Ng et al. (2015) 48.56
Multiple deep network learning Yu et al. (2015) 55.96
Hierarchial committee of deep
convolution neural networkKim et al. (2015)
52.8
Configural features with L-FACS
(with T >3)
67.0
VISAPP 2020 - 15th International Conference on Computer Vision Theory and Applications
98

Figure 7: Confusion matrix for SFEW dataset using L-
FACS mentioned in Table 5. Using L-FACS, the proposed
approach obtains 67.0% accuracy in recognizing facial ex-
pressions (with T>3).
4.2 Results on Acted Facial Expression
in Wild (AFEW)
AFEW Dhall et al. (2012) is the dynamic movie video
corpus consisting of six universal facial expressions
and one neutral expression in the wild environment.
The training set consists of 723 movie clips and val-
idation set contains 383 movie clips. Figure 8 shows
subjects labelled as sad but it can be observed that
they do not exhibit any facial actions (FAU-1 and
FAU-15), which can be classified as sad. Table 6
shows the performance comparison of existing work
with the proposed approach on AFEW dataset. The
confusion matrix on AFEW dataset on both training
and validation dataset is shown in Figures 9.
Figure 8: (a) represents the subjects from sad expressions
(b) represents the corresponding subjects from neutral ex-
pressions. It can be easily observed that, no facial move-
ments is present on both the expressions, due to which sad
is also mis-classified as neutral.
Table 6: Performance comparison with the recent ap-
proaches on AFEW dataset.
Methods Accuracy (%)
TOP-k HOG Feature Fusion
with Multiple Kernel Learning Chen et al. (2014)
40.2
Combining Multimodal Features
with Hierarchical Classifier FusionSun et al. (2014)
42.32
Combining Multiple Kernel Methods
on Riemannian ManifoldLiu et al. (2014a)
48.52
Combining Modality Specific
Deep Neural Network ModelsKahou et al. (2013)
49.49
Contrasting and Combining
Least Squares Based LearnersKaya et al. (2015)
52.30
AU-aware facialfeature relations
(two face scales) with Audio fusionYao et al. (2015)
53.80
Recurrent Neural Network Ebrahimi Kahou et al. (2015)
68.463
Configural features with L-FACS
(with T >3)
71.54
Figure 9: Confusion matrix for AFEW dataset using L-
FACS. The proposed work obtains 71.54% accuracy.
5 EXPERIMENTAL EVALUATION
OF LAUGHTER
LOCALIZATION AND POSED
VERSUS SPONTANEOUS
SMILES RECOGNITION
The efficacy of the proposed approach is also ex-
tended for laughter localization for untrimmed videos
on MAHNOB laughter dataset and for posed and
spontaneous smile recognition on UVA-NEMO smile
dataset.
5.1 Results on MAHNOB-laughter
Dataset and UVA-NEMO-smile
Dataset
MAHNOB Petridis et al. (2013) is a audio-visual
laughter dataset, where video is recorded at 25 fps
and microphone is used for audio data. There are
191 samples of 22 subjects where there are 12 males
and 10 females, in total 28 posed laughter videos,
Configural Representation of Facial Action Units for Spontaneous Facial Expression Recognition in the Wild
99

121 spontaneous and 42 speech features are recorded.
Also, UVA-NEMO Dibeklioglu et al. (2012) is a
smile dataset, which consist of 643 posed and 597
spontaneous smile videos by 400 subjects, under con-
trolled illumination condition at 50 fps. We use
both datasets to check the authenticity of our ap-
proach through laughter localization and posed ver-
sus spontaneous laughter recognition in videos. Ta-
Table 7: Experimental results on two different laughter
datasets for posed and spontaneous facial expression recog-
nition and for expression localization.
Posed
(%)
Spontaneous
(%)
Expression
Localization.
(%)
MAHNOB
Petridis et al. (2013)
71.42 86.77 89.017
UVA-Nemo
Smile dataset
Dibeklioglu et al. (2012)
80.56 85.69 —
ble 7 gives the performance measures on the laugh-
ter datasets for laughter localization and for detect-
ing posed and spontaneous laughter. For laughter lo-
calization, we keep track of the most prominent FAU
in laughter(smile), i.e AU-12, and its occurrences are
compared with the annotation provided by the author.
The recognition performance on MAHNOB laughter
dataset is 89.017%. The graph plot in Figure 10 shows
the AU-12 activation in spontaneous videos and Fig-
ure 11 shows the AU-12 activation in posed videos.
However, for smile dataset, laughter localization is
not evaluated as the videos are very small and dataset
is also not meant for this purpose. For the case of pre-
dicting posed and spontaneous laughter in the videos,
we keep track of the duration when AU-12 is active
in the frame sequences. We notice that in most of
the posed videos the duration of activation of AU-12
is very less and they occur frequently as compared
to the sustainable activation of AU-12 in spontaneous
videos. Along with this, the proposed approach also
keeps track of the threshold value T mentioned in sec-
tion 3 for AU-12. In case of spontaneous laughter as
shown in Figure 12, the T value starts from some min-
imum value (T>3) and reaches a peak value where
laughter expression is at the apex and sustains across
the video without decreasing. And if the value of
T fluctuates frequently across the frames then such
videos are considered as posed. This is demonstrated
using Figures 13 and 14. The T value plot shows
that T value starts from some minimum (T>3) and
reaches a peak value at the apex point of laughter and
then decreases gradually across the video.
Figure 10: Activation of FAU-12 is plotted for the subject
S001 001
spontaneous laughter
from mahnob laughter
dataset. The above plot shows the continuity in the acti-
vation of FAU-12 through out the videos once the laughter
is started (approximately from frame number 870).
Figure 11: Activation of FAU-12 is plotted for the subject
S009 003
posed laughter
from mahnob laughter dataset.
Discontinuity of laughter can be noticed by discontinued ac-
tivation of the FAU-12 (approximately from frame number
39 and 175).
Figure 12: T value plot for predicting the spontaneous
laughter (or smiles) in the video.
6 CONCLUSIONS
This paper presents a novel approach for selecting
configural features and a subjective interpretation
based coding system L-FACS. The efficacy of the pro-
posed approach is demonstrated on onset to apex cat-
egories of videos for facial expression recognition on
the following tasks: (i) facial expression recognition
in controlled environments, (ii) spontaneous expres-
sion recognition in wild environments, (iii) laughter
VISAPP 2020 - 15th International Conference on Computer Vision Theory and Applications
100
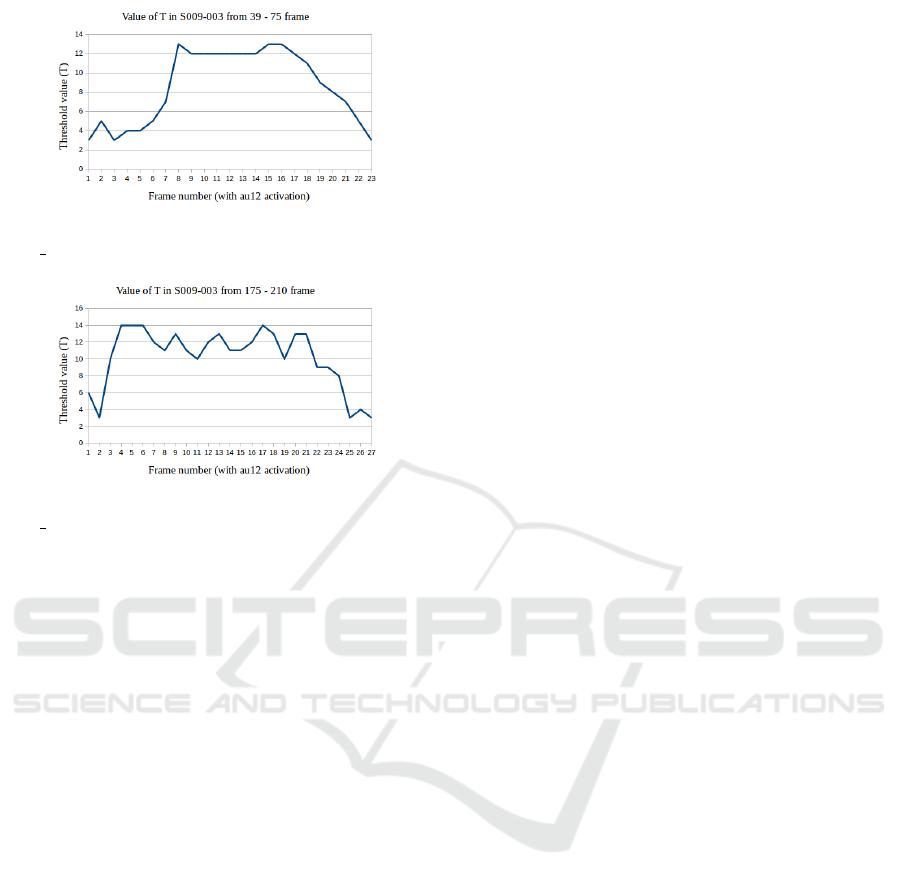
Figure 13: T value plot for posed laughter. Subject
S009 003 is tracked from frame number 39-75.
Figure 14: T value plot for posed laughter. Subject
S009 003 is tracked from frame number 175-210.
localization on large videos, and (iv) posed and spon-
taneous smile recognition. The selection of configural
features combined with L-FACS is shown to outper-
form state of the art approaches. By combining frame
level decisions to classify a video into a particular ex-
pression, the proposed approach handles scaling and
pose-related issues that may arise in a few frames of
the video. In future, we would like to extend our ap-
proach for estimating the intensity of facial expres-
sions for any categories of videos (apex/offset) in an
unconstrained environment.
REFERENCES
Ahlberg, J. (2001). Candide-3 - an updated parameterised
face. Technical report.
Albrecht, T., Luthi, M., and Vetter, T. (2008). A statisti-
cal deformation prior for non-rigid image and shape
registration. In 2008 IEEE Conference on Computer
Vision and Pattern Recognition, pages 1–8.
Asthana, A., Zafeiriou, S., Cheng, S., and Pantic, M.
(2013). Robust discriminative response map fitting
with constrained local models. In 2013 IEEE Con-
ference on Computer Vision and Pattern Recognition,
pages 3444–3451.
Bartlett, M. S., Littlewort, G., Fasel, I., and Movellan, J. R.
(2003). Real time face detection and facial expression
recognition: Development and applications to human
computer interaction. In Computer Vision and Pat-
tern Recognition Workshop, 2003. CVPRW’03. Con-
ference on, volume 5, pages 53–53. IEEE.
Benitez-Quiroz, C. F., Srinivasan, R., and Martinez, A. M.
(2016). Emotionet: An accurate, real-time algorithm
for the automatic annotation of a million facial expres-
sions in the wild. In 2016 IEEE Conference on Com-
puter Vision and Pattern Recognition (CVPR), pages
5562–5570.
Chen, J., Chen, Z., Chi, Z., and Fu, H. (2014). Emotion
recognition in the wild with feature fusion and multi-
ple kernel learning. In Proceedings of the 16th Inter-
national Conference on Multimodal Interaction, ICMI
’14, pages 508–513, New York, NY, USA. ACM.
Dhall, A., Goecke, R., Lucey, S., and Gedeon, T. (2011).
Static facial expression analysis in tough conditions:
Data, evaluation protocol and benchmark. In 2011
IEEE International Conference on Computer Vision
Workshops (ICCV Workshops), pages 2106–2112.
Dhall, A., Goecke, R., Lucey, S., and Gedeon, T. (2012).
Collecting large, richly annotated facial-expression
databases from movies. IEEE MultiMedia, 19(3):34–
41.
Dibeklioglu, H., Salah, A. A., and Gevers, T. (2012). Are
You Really Smiling at Me? Spontaneous versus Posed
Enjoyment Smiles, pages 525–538. Springer Berlin
Heidelberg, Berlin, Heidelberg.
Ebrahimi Kahou, S., Michalski, V., Konda, K., Memise-
vic, R., and Pal, C. (2015). Recurrent neural networks
for emotion recognition in video. In Proceedings of
the 2015 ACM on International Conference on Mul-
timodal Interaction, ICMI ’15, pages 467–474, New
York, NY, USA. ACM.
Ekman (2009). Lie-to-me. http://www.paulekman.com/
lie-to-me/.
Ekman, P. (1957). A methodological discussion of nonver-
bal behavior. The Journal of psychology, 43(1):141–
149.
Ekman, P. and Friesen, W. V. (1976). Measuring facial
movement. Environmental psychology and nonverbal
behavior, 1(1):56–75.
Ganchev, K. and Das, D. (2013). Cross-lingual discrimina-
tive learning of sequence models with posterior regu-
larization. In EMNLP, pages 1996–2006.
Happy, S. and Routray, A. (2015). Automatic facial ex-
pression recognition using features of salient facial
patches. IEEE transactions on Affective Computing,
6(1):1–12.
Jing, D. and Bo, L. (2016). Distance-weighted mani-
fold learning in facial expression recognition. In In-
dustrial Electronics and Applications (ICIEA), 2016
IEEE 11th Conference on, pages 1771–1775. IEEE.
Kahou, S. E., Pal, C., Bouthillier, X., Froumenty, P.,
G
¨
ulc¸ehre, C¸ ., Memisevic, R., Vincent, P., Courville,
A., Bengio, Y., Ferrari, R. C., et al. (2013). Combin-
ing modality specific deep neural networks for emo-
tion recognition in video. In Proceedings of the 15th
ACM on International conference on multimodal in-
teraction, pages 543–550. ACM.
Kaya, H., G
¨
urpinar, F., Afshar, S., and Salah, A. A. (2015).
Contrasting and combining least squares based learn-
ers for emotion recognition in the wild. In Proceed-
ings of the 2015 ACM on International Conference
Configural Representation of Facial Action Units for Spontaneous Facial Expression Recognition in the Wild
101

on Multimodal Interaction, ICMI ’15, pages 459–466,
New York, NY, USA. ACM.
Kim, B.-K., Lee, H., Roh, J., and Lee, S.-Y. (2015). Hier-
archical committee of deep cnns with exponentially-
weighted decision fusion for static facial expression
recognition. In Proceedings of the 2015 ACM on Inter-
national Conference on Multimodal Interaction, ICMI
’15, pages 427–434, New York, NY, USA. ACM.
Kotsia, I. and Pitas, I. (2007). Facial expression recognition
in image sequences using geometric deformation fea-
tures and support vector machines. IEEE Transactions
on Image Processing, 16(1):172–187.
Lee, S. H., Plataniotis, K. N., and Ro, Y. M. (2014). Intra-
class variation reduction using training expression im-
ages for sparse representation based facial expression
recognition. IEEE Transactions on Affective Comput-
ing, 5(3):340–351.
Lei, G., Li, X.-h., Zhou, J.-l., and Gong, X.-g. (2009). Geo-
metric feature based facial expression recognition us-
ing multiclass support vector machines. In Granular
Computing, 2009, GRC’09. IEEE International Con-
ference on, pages 318–321. IEEE.
Liu, M., Li, S., Shan, S., and Chen, X. (2013). Au-aware
deep networks for facial expression recognition. In
2013 10th IEEE International Conference and Work-
shops on Automatic Face and Gesture Recognition
(FG), pages 1–6.
Liu, M., Wang, R., Li, S., Shan, S., Huang, Z., and Chen,
X. (2014a). Combining multiple kernel methods on
riemannian manifold for emotion recognition in the
wild. In Proceedings of the 16th International Con-
ference on Multimodal Interaction, ICMI ’14, pages
494–501, New York, NY, USA. ACM.
Liu, P., Han, S., Meng, Z., and Tong, Y. (2014b). Fa-
cial expression recognition via a boosted deep belief
network. In Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition, pages
1805–1812.
Lucey, P., Cohn, J. F., Kanade, T., Saragih, J., Ambadar, Z.,
and Matthews, I. (2010). The extended cohn-kanade
dataset (ck+): A complete dataset for action unit and
emotion-specified expression. In 2010 IEEE Com-
puter Society Conference on Computer Vision and
Pattern Recognition - Workshops, pages 94–101.
Lyons, M., Akamatsu, S., Kamachi, M., and Gyoba,
J. (1998). Coding facial expressions with gabor
wavelets. In Proceedings Third IEEE International
Conference on Automatic Face and Gesture Recogni-
tion, pages 200–205.
Ng, H.-W., Nguyen, V. D., Vonikakis, V., and Winkler, S.
(2015). Deep learning for emotion recognition on
small datasets using transfer learning. In Proceedings
of the 2015 ACM on International Conference on Mul-
timodal Interaction, ICMI ’15, pages 443–449, New
York, NY, USA. ACM.
Perveen, N., Gupta, S., and Verma, K. (2012). Facial ex-
pression recognition using facial characteristic points
and gini index. In 2012 Students Conference on Engi-
neering and Systems, pages 1–6.
Perveen, N., Roy, D., and Mohan, C. K. (2018). Sponta-
neous expression recognition using universal attribute
model. IEEE Transactions on Image Processing,
27(11):5575–5584.
Perveen, N., Singh, D., and Mohan, C. K. (2016). Sponta-
neous facial expression recognition: A part based ap-
proach. In 2016 15th IEEE International Conference
on Machine Learning and Applications (ICMLA),
pages 819–824.
Petridis, S., Martinez, B., and Pantic, M. (2013). The mah-
nob laughter database. Image and Vision Computing,
31(2):186 – 202. Affect Analysis In Continuous Input.
Snell, R. (2008). Clinical Anatomy by Regions. Lippincott
Williams & Wilkins.
Sun, B., Li, L., Zuo, T., Chen, Y., Zhou, G., and Wu, X.
(2014). Combining multimodal features with hierar-
chical classifier fusion for emotion recognition in the
wild. In Proceedings of the 16th International Con-
ference on Multimodal Interaction, ICMI ’14, pages
481–486, New York, NY, USA. ACM.
Yao, A., Shao, J., Ma, N., and Chen, Y. (2015). Captur-
ing au-aware facial features and their latent relations
for emotion recognition in the wild. In Proceedings of
the 2015 ACM on International Conference on Mul-
timodal Interaction, ICMI ’15, pages 451–458, New
York, NY, USA. ACM.
Yu, X., Zhang, S., Yan, Z., Yang, F., Huang, J., Dunbar,
N. E., Jensen, M. L., Burgoon, J. K., and Metaxas,
D. N. (2015). Is interactional dissynchrony a clue to
deception? insights from automated analysis of non-
verbal visual cues. IEEE Transactions on Cybernetics,
45(3):492–506.
Zhan, C., Li, W., Ogunbona, P., and Safaei, F. (2008).
A real-time facial expression recognition system for
online games. Int. J. Comput. Games Technol.,
2008:10:1–10:7.
Zhao, K., Chu, W. S., la Torre, F. D., Cohn, J. F., and Zhang,
H. (2016). Joint patch and multi-label learning for
facial action unit and holistic expression recognition.
IEEE Transactions on Image Processing, 25(8):3931–
3946.
VISAPP 2020 - 15th International Conference on Computer Vision Theory and Applications
102
