
Adding Temporal Dimension to Ontology Learning Models for
Depression Signs Detection from Social Media Texts
Patricia Martin-Rodilla
a
Information Retrieval Lab (IRLab), Facultade de Informática, University of A Coruña, Spain
Keywords: Ontology Learning, Time, Ontology Evolution, Text Mining, Social Media, Depression, Early Risk Prediction.
Abstract: Approaches to early detection of depression based on individual’s language are receiving increasing attention,
with detection software systems based on lexical, grammatical or discursive components applied to medical
corpus or social media texts. However, these first detection systems are defragmented, each attending to a
specific feature or linguistic level, and not addressing a more conceptual level. Existing ontology learning
(OL) methods extract the ontology referred in the text. In addition, existing systems perform language analysis
for the detection of depression as a snapshot of each individual, regardless of their temporal dimension. Is it
possible that suitable linguistic features to detect early signs of depression vary over time? And the underlying
ontology? This paper presents a model that adds the temporal component to current ontology learning models
to perform evolutionary analysis of both linguistic and ontological features to texts from social networks. The
model has been applied to an external corpus of depression from social media texts, with a two-fold goal: 1)
validating the model by contrasting it with OL models without temporal component 2) producing a corpus of
evolutionary OL results applied to the depression detection from social media texts.
1 INTRODUCTION
Depression is considered one of the most common
mental illness and one of the main diseases in recent
decades. Due to its complex diagnosis and variability
of presentations in different people, interdisciplinary
research approaches have become the most successful
methods for early risk prediction (Losada et al.,
2018a) and depression detection, combining
information about patient’s profile, doctor’s
experience, well-tested medical questionnaires and
semiautomatic analysis for assisting doctors to
analyze indicators. Within this last category, patient
language is a powerful indicator of personality traits
and emotions, and provides valuable clues about
mental health, presenting good results as auxiliary
indicators for helping doctors in an early risk
prediction of depression (Al-Mosaiwi & Johnstone,
2018, 2019; Pennebaker, Mehl, & Niederhoffer,
2003).
This connection between depression and
distinctive linguistic patterns have serve to create
promising software systems for assisting depression
early prediction. These systems have been tested
a
http://orcid.org/0000-0002-1540-883X
using textual corpus from clinical sessions or from
social networks, and classified them (Brewster, 2006;
Hazman, El-Beltagy, & Rafea, 2011; Wimalasuriya
& Dejing, 2010) regarding the linguistic parameters
analyzed for each system. Most of them are focused
on lexical or grammatical features (propositions or
pronouns) or ontological, discursive or topic-based
features. The ontological level, relating the
underlined ontology with the language patterns used
by the patient, offers important information about the
universe of discourse of the patient (Gruber, 1995), as
well as how the patient refers to its discourse
universe.
However, as far as we know, the temporal
component of this language pattern analysis,
especially at ontological or discursive levels, is not
considering as a feature in the current software
systems. This means that the information
corresponding to changes in patient language patterns
is not tracked or analyzed. The historical information
of the patients is one of the most valuable inputs for
doctors in the detection, diagnosis and evaluation of
mental illnesses. In addition, temporal dimension is
crucial in order to reveal early signs of psychological
Martin-Rodilla, P.
Adding Temporal Dimension to Ontology Learning Models for Depression Signs Detection from Social Media Texts.
DOI: 10.5220/0009351903230330
In Proceedings of the 15th International Conference on Evaluation of Novel Approaches to Software Engineering (ENASE 2020), pages 323-330
ISBN: 978-989-758-421-3
Copyright
c
2020 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
323

disorders trying to detect some indicators of
appearance of initial signs of depression and
understanding the evolution of an individual from the
early stages (e.g. mood changes, lack of sleep) to
severe stages (e.g. suicidal thoughts).
Focusing only in the ontological component of the
language patterns, this paper proposes a model that
adds the temporal component to current ontology
learning models, allowing us to perform evolutionary
analysis of both linguistic and ontological features to
texts from social networks. The model has been
applied to an external corpus of depression from
social media texts. The application shows how we can
add the temporal dimension to existing ontology
learning models in a real case, as well as produces a
valuable corpus of ontological and linguistic pattern
results over time in depression contexts.
2 BACKGROUND
Two main areas are related with our proposal: 1)
ontology learning methods from English unstructured
text from social networks, and 2) existing works
specifically focused on depression detection
software, contextualizing the application of our
proposal to this field.
2.1 Ontology Learning
Ontology Learning is defined as the discovering of
the underlined ontology from textual sources
(Hazman et al., 2011). As an ontology, we understand
here “an explicit, formal specification of a shared
conceptualization of a domain of interest” (Gruber,
1995). Thus, the underlined ontology of a given text
allow us to extract information about a) concepts and
relations referred in the source texts and b) linguistic
patterns used for referring to these concepts and
relations. This information conforms a relevant input
in the language studies, including applications of
ontology learning in biomedical or legal domain
(Morales, Scherer, & Levitan, 2017).
Firstly, we can find in literature initial approaches
trying to extract in a semiautomatic or automatic way
some ontological information from linguistic
patterns, such as processes relations or event mining
(Reuter & Cimiano, 2012). Regarding these studies,
most of them present high scores on recognition in a
limited functional environment or limited to a specific
domain or tasks.
Secondly, there are existing attempts for enriching
ontology learning with text mining techniques from
2000, e.g. some workshops in ECAI conference
(Staab, Maedche, Nedellec, & Wiemer-Hastings,
2000), to present. Main concerns here includes topical
concepts and concept definitions agreement within
the corresponding community, learning associations
from texts, Named Entity and Terminology
extraction, Acquisition of selected restrictions from
texts, Word Sense disambiguation or computation of
concept lattices from texts. We can also classify all
these text mining works in function of the kind of
technological technique employed: supervised (based
on previous annotations) vs. unsupervised.
Wimalasuriya survey (Wimalasuriya & Dejing, 2010)
presents the most common software architecture for
this kind of techniques, as well as some examples of
classical applications domains. In addition, some
authors (Asim, Wasim, Khan, Mahmood, & Abbasi,
2018; Brewster, 2006; Hazman et al., 2011;
Shamsfard & Barforoush, 2003; Somodevilla, Ayala,
& Pineda, 2018; Wimalasuriya & Dejing, 2010)
recently perform exhaustive reviews of the current
software methods for ontology learning. All these
methods have been successfully applied to a wide
variety of domains, which makes ontology learning a
solid area to consider when we want to extract
complex information (linguistically and conceptually
based) from unstructured sources.
Regarding ontology learning in social media
contexts, most of the approaches focused on
extracting parts of the ontology (Asim et al., 2018;
Breslin, 2012; Reuter & Cimiano, 2012), such as
concepts or events, particularizing approaches for
texts with shorter length and interaction
characteristics similar to dialogue (posts-based
interactions).
In summary, ontology learning is a promising area
with successful applications both at the level of
manual analysis and semi-automation. However,
none of the current methods recently reviewed (Asim
et al., 2018; Wimalasuriya & Dejing, 2010), even in
social media contexts, have specific temporality
support. This means that current methods extract the
underlying ontology as a snapshot of the text at a
specific time. In reported applications, this snapshot
condenses enough information. However, it does not
allow the study of the evolution in the underlying
ontology of the text or its linguistic patterns over
time. Because of our needs in the domain of mental
illness, we think that the inclusion of a temporary
layer to the ontology learning methods will facilitate
this evolutionary analysis and allow us a better
investigation of the connection and evolution of
linguistic and ontological patterns in depression
contexts.
ENASE 2020 - 15th International Conference on Evaluation of Novel Approaches to Software Engineering
324

2.2 Depression Signals and Early Risk
Prediction from Social Media
Language and depression studies are recently gaining
importance in research (Al-Mosaiwi & Johnstone,
2018; Kiss & Vicsi, 2017; Kokanovic et al., 2013;
Morales et al., 2017). Until recently, it was very
difficult to obtain reliable data on depression from
any source (from medical reports, due to their
classified character; from social networks, due to
their confidentiality, reliability and true diagnosis
problems). From 2016, The Early Risk Prediction on
the Internet (eRisk) (D. Losada, Crestani, & Parapar,
2017; David E. Losada et al., 2018) workshop
explores the interaction between language and mental
disorders in online social media. In particular, the
workshop proposed to address the early detection of
depression in an automatic way and released a corpus
of social media users who suffered from depression.
The results of the workshop showed that there is a
large spectrum of techniques that can be used to
detect this mental illness. In this paper, we use the
eRisk corpus to validate our model.
Specific works on depression detection from
social media texts are a field relatively new, with
promising approaches. Most of them works with
depression lexicons from Twitter (De Choudhury,
Gamon, Counts, & Horvitz, 2013), or for Reddit and
micro-blogs platforms (Coppersmith, Dredze, &
Harman, 2014; David E Losada & Gamallo, 2018). It
is also necessary to highlight that the Computational
Linguistics and Clinical Psychology Workshop
(clpsych.org) has recently organized "shared tasks" of
depression and post-traumatic disorders, performing
content analysis in support forums for people with
disorders (Resnik, Resnik, & Mitchell, 2014). These
tasks were oriented to automatic classification (do not
focus on early prediction or temporal analysis) but,
still, they will be valuable references for our research.
In addition, there are a few initiatives related to them,
such as personality and health mining competitions as
CLEF eHealth (http://sites.google.com/view/clef-
ehealth-2018/home) or PAN (http://pan.webis.de).
Al these works indicate the possibilities of
depression prediction from social media. However,
ontology learning applications with temporal
component to this field are still barely unexplored.
The method proposed here tries to solve some of these
shortcomings, contributing with ontological
information and their temporal evolutionary analysis
to all this set of technologies, methods and
approaches.
3 PROPOSAL: A
TEMPORAL-BASED
ONTOLOGY LEARNING
METHOD
As we previously detailed, ontological information
extracted from texts can be a very valuable input in
the early detection of signs of depression from social
networks. However, the application of any of the
current ontology learning methods lacks the
necessary temporal approach that allows an
evolutionary analysis.
Employing the current methods of ontology
learning it is possible to make two approaches: 1)
treat the entire corpus as a large text, so we would
obtain an aggregated underlined ontology (result of
evaluating all the texts at once) or 2) treat each corpus
document as a separate text, so we would obtain an
underlined ontology for each of the analysed texts.
Note here two important aspects of both approaches:
neither deals with a temporary component, so, in the
first case, we only have one ontology at a given time
(without evolutionary analysis), and in the second
case, we have several ontologies but no connection
between them, so we cannot perform evolutionary
analysis either. This absence of a temporary
component also severely penalizes applications to
short and disconnected texts such as those derived
from social networks and, as we have explained
before, temporal analysis is a crucial analysis in
mental illness application domains.
In order to fill this gap, we present a proposal to
add a temporary layer to existing ontology learning
methods. Using ontology learning principles as a
basis, we developed the proposal from scratch but in
highly modular schema, as the pipeline shows in
Figure 1.
The initial input is a corpus or collection of free-
style textual documents. Following the ontology
methods existing methods, we decide to apply the
second approach studied above for the discovery of
ontological information: extract an ontology for each
existing text in the corpus or collection. Thus, each
corpus analysed produced a set of underlined
ontologies (not only one) that allow us to perform
evolutionary analysis of the information. Phase I of
the pipeline runs the ontology learning (OL) model
chosen for extracting candidates for concepts and
their relationships for each existing text. The result of
Phase I is a ranked set of candidates for concepts and
relationships for each document. Then, the pipeline
consults the temporal information available in the
collection. Phase II is responsible for resolving, stor-
Adding Temporal Dimension to Ontology Learning Models for Depression Signs Detection from Social Media Texts
325
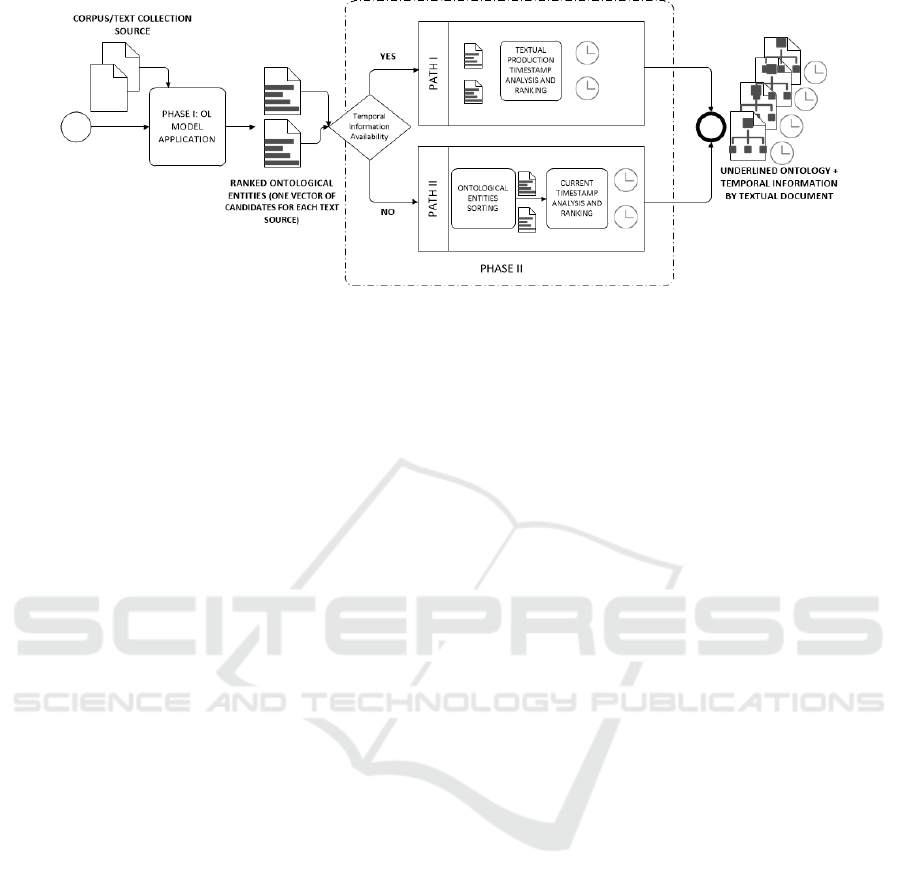
Figure 1: BPMN model (OMG, 2011) of the proposal pipeline, adding temporal dimension to OL methods.
ing and keeping the temporary information of the
ontological extraction process updated. In the phase
II the pipeline evaluates the given corpus regarding
temporal information available:
If the corpus has temporary information about the
production of texts (that is, when a due text is written
and / or added to the corpus), the pipeline creates the
necessary entities to maintain that information in each
of the candidates for concepts and relationships, as a
label of them (PATH I).
If the corpus does not have this information, the
pipeline creates the necessary entities to maintain
temporary information in real time of the analysis
performed, that is, it will assign a timestamp to each
of the candidates for concepts and relationships, as a
label of them (PATH II). This will allow us to
perform ontology learning evolutionary analysis also
in collections of texts or corpus without prior
temporal information. Thus, we can order our texts
and perform an evolutionary analysis as well, but with
temporal labels relative to the analysis itself and not
to the date of production of the texts.
Each of the paths of the pipeline produces the
ontological information with the temporal layer
completed, one result by each analysed text presented
in the original corpus/collection.
As a result, we can maintain the temporal
traceability of the production of the texts in the corpus
analysed in the case of the PATH I, performing
evolutionary analysis of the ontological information
and the linguistic patterns contained on it. For
example, we could now know what concepts appear
and disappear from the ontology over time or in a
range of dates, or if a linguistic pattern (the use of a
term for a concept, or the use of a particular verb for
a relationship between concepts) is maintained or
varies over time. In our specific case in depression
detection, this is especially useful given the studies
that relate this type of linguistic-ontological patterns
and specific disease states, allowing its analysis as a
differential factor in much greater depth. In the case
of PATH II, in corpus that do not have temporary
information on the production of the texts, the module
for ordering the documents by the user is necessary to
perform a relative evolutionary analysis.
This prior arrangement serves as a reference
timestamp for the evolutionary analysis (the first
document will be analysed before and its associated
ontology and information will carry a timestamp prior
to the last document) so that an analysis similar to that
of PATH I can be performed but only relative in the
corpus itself. Thus, we can also analyse what
concepts appear and disappear from the ontology over
time or if a linguistic pattern (the use of a term for a
concept, or the use of a particular verb for a
relationship between concepts) is maintained or
varies, but we cannot place it in its real time of
production. Next paragraphs detail the proposed
definitions and calculus for the PHASE II paths.
Taking C
n
as the input collection of n documents
written in free style that we want to analyse, we
formalized for PATH I the following results:
V
d,
Vector of ontology learning candidates extracted:
for one document d, p pieces of text (posts in social
media) and k ontological entities extracted:
V
d
=
(1)
CValue
d =
(2)
CValue
d
, Vector of ontology learning score values (c-
value): for one document d and k ontological entities
extracted and C-value score calculated for these k
entities.
, Set of ranked aggregated vectors of
candidates for the C
n
collection, with k ontological
entities extracted and their C-values scores. For each
d document in C
n
, PATH I searches, temporal
ENASE 2020 - 15th International Conference on Evaluation of Novel Approaches to Software Engineering
326

information available in the corpus (although this
aspect of the pipeline does not correspond to the
scope of the paper, it possible to see a possible
temporal information search implementations here
(Rust, 2018).
(3)
For each d document in C
n
with temporal information,
PATH I calculates:
T (O
n
) =
tprod
(4a)
T (O
n
): Set of resultant values of assigning to each
ontological entity (extracted from the n document)
their corresponding timestamp referred to the input
corpus information t
prod
.
Regarding PATH II, we define D
u,d
as the set of d
documents of the collection ordered by the user.
Then, using this order as a temporal reference, PATH
II calculates V
d
, CValue
d
and
applying same
PATH I formulae. Then, for each d document in C
n,
PATH II stamps current temporal information of the
system. For each d document in C
n
with temporal
information, PATH I calculates:
T’ (O
n
) =
tcurrent
(4b)
T’ (O
n
): Set of resultant values of assigning to each
ontological entity (extracted from the n document)
their corresponding current relative timestamp t
current
.
Note that the proposed pipeline has been defined
independently of the ontology learning method
selected, the domain of application or the corpus used
as a source. Thus, our proposal could serve as a
general solution for the need of a temporal layer in
current ontology learning methods. In the next
section, we particularize the application by selecting
all these aspects to illustrate the entire pipeline
proposal.
4 VALIDATION: APPLICATION
TO A SOCIAL MEDIA
DEPRESSION CORPUS
Within the scope of our proposal, it was necessary to
apply and evaluate the proposed pipeline with respect
to its ability to resolve, store and keep updated the
temporary information in a real corpus. Performing a
specific application of the pipeline requires defining
a) the ontology learning method chosen b) the
application domain and c) the corpus or collection
used as a source (the pipeline input).
Regarding the ontology method employed, the
review detailed in section 2 offer us a relevant pool of
methods and their current reliability, strengths and
weaknesses. Very few methods reviewed above
presents open-source implementations that allow us
to use them as initial method for our pipeline
implementation. From them, the C-value (Frantzi,
Ananiadou, & Mima, 2000) method presents better
behaviour in ontology learning, especially in concepts
extraction (Asim et al., 2018). C-value domain-
independent method is a well-known ontology
learning method that calculates a C-value score for
each text analysed, in function of linguistic and
statistical parameters, and giving as a result a vector
of ontological entities candidates ranked by the C-
value score. It presents especially good behaviour in
the semi-automatic extraction of multi-word and
nested ontological concepts from English corpora
(Asim et al., 2018). In addition, C-value have been
previously used in the medical domain with good
results (Lossio-Ventura, Jonquet, Roche, & Teisseire,
2013). C-value have been tested and previously
implemented in several platforms. We have used an
updated open source implementation of the algorithm
for English language (Conde, 2018) as a base for
adding the temporal dimension and implementing our
pipeline. All these reasons made us choose C-value as
a starting learning ontology method to illustrate our
pipeline and apply it to a real corpus.
The application domain (mental illness) and the
corpus chosen is due to our interest on depression
detection based on language patterns through
software systems. The original eRisk corpus (D.
Losada & F. Crestani, 2016; D. E. Losada & F.
Crestani, 2016) contains 2-year textual interactions
on Reddit from 892 users, divided into two groups:
137 subjects have explicitly declared that they have
been diagnosed with depression by medical
professionals, and the remaining 755 subjects are a
control group. All details regarding data acquisition,
initial annotations, depression diagnosis criteria, data
cleaning and legal treatment etc. are reported by the
original authors (D. E. Losada & F. Crestani, 2016).
We have applied the proposed pipeline to the
depression corpus:
1. Each eRisk document presents Reddit posts from
a subject (that it could be in the depression group
or in the control group) in JSON format. In Phase
I, the pipeline implements C-value algorithm,
obtaining a ranked vector of candidates to
Adding Temporal Dimension to Ontology Learning Models for Depression Signs Detection from Social Media Texts
327

ontological entities with their corresponding
ontological C-value score.
2. Then, the pipeline checks again the eRisk corpus,
searching for temporal information (Rust, 2018).
Due to eRisk corpus contains temporal
information of each post of the Reddit production
timestamp, the pipeline decides executing PATH
I algorithm (see
Figure 1).
3. In PATH I, the pipeline storages the timestamp of
each Reddit post for each JSON document
(corresponding to each subject in the collection).
This information is aligned to their corresponding
vector of ontological entities candidates for each
post. As a result, the pipeline obtains a vector of
ontological concepts aligned with their timestamp
of production. This allow us to perform
evolutionary analysis on the ontology, answering
questions regarding the ontological evolution over
the 2 years of data for each subject.
The execution of the pipeline would be similar in case
of the pipeline would execute PATH II but ordering
the corpus documents (See Figure 1). The proposed
method in form of a pipeline have allowed us to track
and maintain temporal information for each
ontological vector of the C-value algorithm output
vector. Figure 2 shows a screenshot of the final output
of the pipeline (PATH I) for our depression corpus
application. We selected a few p posts of the one
subject, showing the original texts and their
corresponding ontological entities extracted,
including temporal information of the production of
the texts.
5 DISCUSSION
The proposed method represents the first known
approach to the combination of ontology learning
methods with temporal analysis to allow ontological
evolutionary analysis. Due to the innovative nature of
the proposal, it is not possible to evaluate the results
obtained with existing benchmarks, beyond the good
results already reported (Asim et al., 2018) of the
ontology learning methods from unstructured
sources.
Said that, evaluating at a qualitative level, the
results obtained add value compared to traditional
methods of ontology learning: we will have, in
addition to the underlying ontology, evolutionary
information, as seen in our case of depression corpus
application. In the case of relative evolutionary
analysis (PATH II), the pipeline presents an
alternative solution to have a chronological reference
in form of timestamp for the ontological information
extracted during the analysis itself. More work is
needed to validate its usefulness in specific
application contexts.
Other known restrictions are 1) results
dependence on the original language of the texts from
corpus or collection and 2) results dependence on the
performance of the chosen ontology learning method.
In the first case, because most of them only support
English, we value as future work exploring the
possibilities of ontology learning methods for other
languages and studying the possibilities of language
generalization of the method.
In the second case, ontology learning (as emergent
research area) present some needs in terms of
methods and tools for evaluating and comparing
results. This means that the evaluation of the
information extracted is based mainly on a principle
of utility, satisfaction and quality perceived by the
user who will use the information extracted to make
decisions. In fact, “not so much consensus about a
delimit task of automatic extraction of ontologies”
(Buitelaar, Cimiano, & Magnini, 2005). Said that, this
lack of evaluation possibilities difficult the
comparison between approaches and the evaluation
of the results, with very few raw results published and
in non-standard formats, that could serve as a gold
standard for improving the approaches. For this
reason, we make available both the pipeline
implementation as an adaptation of the selected
ontology learning method to our pipeline in a public
repository (Martin-Rodilla, 2019). In addition, we
offer our results of extracted ontology for depression
with temporal component with the source corpus (D.
Losada & F. Crestani, 2016; D. E. Losada & F.
Crestani, 2016) under petition for research purposes,
producing a corpus of evolutionary OL results applied
to the depression detection from social media texts.
These contributions try to collaborate to the
proliferation of research resources for comparison,
dissemination and evaluation in this area.
6 CONCLUSIONS
This paper presents a double contribution:
1) a pipeline model that adds the temporal component
to current ontology learning models, performing
evolutionary analysis of both linguistic and
ontological features extracted form unstructured texts
and 2) an application case of the method to an external
corpus on depression prediction from social media
texts.
ENASE 2020 - 15th International Conference on Evaluation of Novel Approaches to Software Engineering
328

Figure 2: Original texts for a depressed subject from the depression corpus and the corresponding pipeline output: ontological
entities vector and their temporal information results.
We are at a favourable time to investigate
depression signs, due to the existence of validated
collections of reliable diagnosis’s data.
In the first case, the method adds value to the
existing ontology learning method and approaches,
allowing the evolutionary analysis of their current
outputs. However, more work is needed in order to
test the pipeline method in different application
scenarios and input corpus. In the second case, the
application showed here constitutes a valuable dataset
itself for continuing researching on the software
prediction and detection of first signs of the
depression phenomenon, with complex and varied
features that requires interdisciplinary perspectives.
ACKNOWLEDGEMENTS
Funding by “Ministerio de Ciencia, Innovación y
Universidades” of the Government of Spain (research
grant RTI2018-093336-B-C21, co-funded by the
European Regional Development Fund,
ERDF/FEDER program).
REFERENCES
Al-Mosaiwi, M., & Johnstone, T. (2018). In an absolute
state: Elevated use of absolutist words is a marker
specific to anxiety, depression, and suicidal ideation.
Clinical Psychological Science, 6(4), 529-542.
Al-Mosaiwi, M., & Johnstone, T. (2019). In an absolute
state: Elevated use of absolutist words is a marker
specific to anxiety, depression, and suicidal ideation:
Corrigendum.
Asim, M. N., Wasim, M., Khan, M. U. G., Mahmood, W.,
& Abbasi, H. M. (2018). A survey of ontology learning
techniques and applications. Database, 2018.
Breslin, J., Ellison, N., Shanahan, J., and Tufekci, Z.
(2012). Proceedings of the 6th International
Conference on Weblogs and Social Media (ICWSM -
12).
Brewster, C. (2006). Ontology Learning from Text:
Methods, Evaluation and Applications. Computational
Linguistics - COLI, 32, 569-572.
doi:10.1162/coli.2006.32.4.569
Buitelaar, P., Cimiano, P., & Magnini, B. (2005). Ontology
learning from text: methods, evaluation and
applications (Vol. 123): IOS press.
Conde, A. (2018). Neuw84 Github account: c-value
algortihm implementation. Retrieved from
https://github.com/Neuw84/CValue-TermExtraction
Coppersmith, G., Dredze, M., & Harman, C. (2014).
Quantifying Mental Health Signals in Twitter. Paper
presented at the Workshop on Computational
Linguistics and Clinical Psychology: From Linguistic
Signal to Clinical Reality, Baltimore, Maryland, USA.
De Choudhury, M., Gamon, M., Counts, S., & Horvitz, E.
(2013). Predicting depression via social media. Paper
presented at the Seventh international AAAI
conference on weblogs and social media.
Frantzi, K., Ananiadou, S., & Mima, H. (2000). Automatic
recognition of multi-word terms:. the C-value/NC-
value method. International Journal on Digital
Libraries, 3(2), 115-130. doi:10.1007/s007999900023
Gruber, T. R. (1995). Toward principles for the design of
ontologies used for knowledge sharing? International
Journal of Human-Computer Studies, 43(5), 907-928.
doi:https://doi.org/10.1006/ijhc.1995.1081
Hazman, M., El-Beltagy, S. R., & Rafea, A. (2011). A
survey of ontology learning approaches. International
Journal of Computer Applications, 22(9), 36-43.
Kiss, G., & Vicsi, K. (2017). Comparison of read and
spontaneous speech in case of automatic detection of
depression. Paper presented at the 2017 8th IEEE
International Conference on Cognitive
Infocommunications (CogInfoCom).
Kokanovic, R., Butler, E., Halilovich, H., Palmer, V.,
Griffiths, F., Dowrick, C., & Gunn, J. (2013). Maps,
models, and narratives: the ways people talk about
depression. Qualitative Health Research, 23(1), 114-
125.
Losada, D., & Crestani, F. (2016). A Test Collection for
Research on Depression and Language use. Retrieved
Adding Temporal Dimension to Ontology Learning Models for Depression Signs Detection from Social Media Texts
329

from: https://tec.citius.usc.es/ir/code/dc.html
Losada, D., Crestani, F., & Parapar, J. (2017). eRISK 2017:
CLEF Lab on Early Risk Prediction on the Internet:
Experimental Foundations.
Losada, D. E., & Crestani, F. (2016). A test collection for
research on depression and language use. Paper
presented at the International Conference of the Cross-
Language Evaluation Forum for European Languages.
Losada, D. E., Crestani, F., & Parapar, J. (2018a). Overview
of eRisk: Early Risk Prediction on the Internet.
https://doi.org/10.1007/978-3-319-98932-7_30
Losada, D. E., & Gamallo, P. (2018). Evaluating and
improving lexical resources for detecting signs of
depression in text. Language Resources and
Evaluation, 1-24.
Lossio-Ventura, J. A., Jonquet, C., Roche, M., & Teisseire,
M. (2013). Combining c-value and keyword extraction
methods for biomedical terms extraction. Paper
presented at the LBM: Languages in Biology and
Medicine.
Martin-Rodilla, P. (2019). OL Temporal Layer Depression
Project. Retrieved from
https://github.com/patrimrodilla/OLTemporalLayer_D
epression
Morales, M., Scherer, S., & Levitan, R. (2017). A cross-
modal review of indicators for depression detection
systems. Paper presented at the Proceedings of the
Fourth Workshop on Computational Linguistics and
Clinical Psychology—From Linguistic Signal to
Clinical Reality.
OMG. (2011). Business process model and notation
(BPMN 2.0), formal/2011-01-03, OMG,
http://www.omg.org/spec/BPMN/2.0 (May 2011).
Pennebaker, J., Mehl, M., & Niederhoffer, K. (2003).
Psychological Aspects of Natural Language Use: Our
Words, Our Selves. Annual review of psychology, 54,
547-577.
doi:10.1146/annurev.psych.54.101601.145041
Resnik, P., Resnik, R., & Mitchell, M. (2014). Proceedings
of the Workshop on Computational Linguistics and
Clinical Psychology: From Linguistic Signal to
Clinical Reality.
Reuter, T., & Cimiano, P. (2012). Event-based
classification of social media streams. Paper presented
at the Proceedings of the 2nd ACM International
Conference on Multimedia Retrieval, Hong Kong,
China.
Rust. (2018). Rust Project: Crate regex. Retrieved from
https://docs.rs/regex/1.3.1/regex/
Shamsfard, M., & Barforoush, A. A. (2003). The state of
the art in ontology learning: a framework for
comparison. Knowl. Eng. Rev., 18(4), 293-316.
doi:10.1017/s0269888903000687
Somodevilla, M., Ayala, D., & Pineda, I. (2018). An
Overview on Ontology Learning Tasks. Computación y
Sistemas, 22. doi:10.13053/cys-22-1-2790
Staab, S., Maedche, A., Nedellec, C., & Wiemer-Hastings,
P. M. (2000). Proceedings of the First Workshop on
Ontology Learning OL'2000, Berlin, Germany, August
25, 2000.
Wimalasuriya, D. C., & Dejing, D. (2010). Ontology-based
information extraction: An introduction and a survey of
current approaches. Journal of Information Science,
36(3), 306-323. Retrieved from
https://doi.org/10.1177/0165551509360123
ENASE 2020 - 15th International Conference on Evaluation of Novel Approaches to Software Engineering
330
