
Symmetric Skip Connection Wasserstein GAN for High-resolution Facial
Image Inpainting
Jireh Jam
1 a
, Connah Kendrick
1 b
, Vincent Drouard
2 c
, Kevin Walker
2 d
, Gee-Sern Hsu
3 e
and
Moi Hoon Yap
1 f
1
Manchester Metropolitan University, Manchester, U.K
2
Image Metrics Ltd, Manchester, U.K
3
National Taiwan University of Science&Technology, Taipei, Taiwan
Keywords:
Inpainting, Generative Neural Networks, Hallucinations, Realism.
Abstract:
The state-of-the-art facial image inpainting methods achieved promising results but face realism preservation
remains a challenge. This is due to limitations such as; failures in preserving edges and blurry artefacts. To
overcome these limitations, we propose a Symmetric Skip Connection Wasserstein Generative Adversarial
Network (S-WGAN) for high-resolution facial image inpainting. The architecture is an encoder-decoder with
convolutional blocks, linked by skip connections. The encoder is a feature extractor that captures data abstrac-
tions of an input image to learn an end-to-end mapping from an input (binary masked image) to the ground-
truth. The decoder uses learned abstractions to reconstruct the image. With skip connections, S-WGAN
transfers image details to the decoder. Additionally, we propose a Wasserstein-Perceptual loss function to pre-
serve colour and maintain realism on a reconstructed image. We evaluate our method and the state-of-the-art
methods on CelebA-HQ dataset. Our results show S-WGAN produces sharper and more realistic images when
visually compared with other methods. The quantitative measures show our proposed S-WGAN achieves the
best Structure Similarity Index Measure (SSIM) of 0.94.
1 INTRODUCTION
Historically, inpainting is an ancient technique that
was performed by professional artists to restore dam-
aged paintings in museums. These defects (scratches,
cracks, dust and spots) were inpainted by hand to re-
store and maintain the image quality. The evolution
of computers in the last century and its frequent daily
use has encouraged inpainting to take a digital for-
mat (Efros and Leung, 1999; Bertalmio et al., 2000;
Criminisi et al., 2004; Pathak et al., 2016; Liu et al.,
2018a; Yang et al., 2017; Yan et al., 2018) as an image
restoration technique. Image inpainting aims to fill in
missing pixels caused by a defect based on pixel sim-
ilarity information (Bertalmio et al., 2000).
The state-of-the-art approaches are two cate-
gories: conventional and deep learning-based meth-
ods. Conventional methods (Efros and Leung, 1999;
a
https://orcid.org/0000-0003-2309-4655
b
https://orcid.org/0000-0002-3623-6598
c
https://orcid.org/0000-0001-7055-9609
d
https://orcid.org/0000-0002-3009-3311
e
https://orcid.org/0000-0003-2631-0448
f
https://orcid.org/0000-0001-7681-4287
(a) (b) (c) (d)
Figure 1: Images showing some issues by state of the
art: (a) Poor performance on holes with arbitrary sizes; (b)
Lack of edge-preserving technique; (c) Blurry artefacts; and
(d) Poor performance on high-resolution images and image
completion with mask at the border region.
Criminisi et al., 2004; Barnes et al., 2009; Sun et al.,
2005) use image statistics of best-fitting pixels to
fill in missing regions (defects). However, these ap-
proaches often fail to produce images with plausi-
ble visual semantics. With the evolution in research,
deep learning-based methods (Pathak et al., 2016; Liu
et al., 2018a; Iizuka et al., 2017; Yu et al., 2018; Yan
et al., 2018; Yang et al., 2017; Park et al., 2020) en-
code the semantic context of an image into feature
space and fill in missing pixels on images by hallu-
cinations (Yang et al., 2017) through the use of gen-
erative neural network. Although deep learning ap-
proaches achieve excellent performance in facial in-
Jam, J., Kendrick, C., Drouard, V., Walker, K., Hsu, G. and Yap, M.
Symmetric Skip Connection Wasserstein GAN for High-resolution Facial Image Inpainting.
DOI: 10.5220/0010188700350044
In Proceedings of the 16th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2021) - Volume 4: VISAPP, pages
35-44
ISBN: 978-989-758-488-6
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
35

painting, there are some limitations of state of the art
as illustrated in Figure 1. These are cases, where Fig-
ure 1(a) shows poor performance on holes with arbi-
trary sizes; Figure 1(b) illustrates the lack of edge-
preserving using the existing technique; Figure 1(c)
depicts the blurry artefacts; and Figure 1(d) demon-
strates the poor performance on high-resolution im-
ages and image completion with mask at border re-
gion.
To correctly predict missing parts of a face and
preserve its realism, we propose S-WGAN with the
following contributions:
• We propose a new framework with Wasserstein
Generative Adversarial Network (WGAN) that
uses symmetric skip connection to preserve image
details.
• We define a new combined loss function based on
RGB and feature space.
• We demonstrate that our loss, combined with
our S-WGAN, can achieve better results than the
state-of-the-art algorithms.
2 PREVIOUS WORK
Pathak et al. (Pathak et al., 2016) proposed to use
GANs (Goodfellow et al., 2014) with a context-
encoder similar to (Vincent et al., 2010; Le et al.,
2011) and AlexNet (Krizhevsky et al., 2012) for im-
age inpainting despite poor hallucinations. Results
show more artefacts and blur with randomised hole-
to-image mask regions. Iizuka et al. (Iizuka et al.,
2017) used a local and global discriminator to assess
coherency and consistency of predicted pixels, and re-
placed the fully-connected layer of the generator with
dilated convolutions (Yu and Koltun, 2015). Iizuka
et al. (Iizuka et al., 2017) method failed to capture
long-ranged textured information, however they used
Poisson Blending by Perez et al. (P
´
erez et al., 2003)
to process the output image. Yang et al. (Yang et al.,
2017) proposed a multi-scale neural patch synthesis
based on style transfer (Johnson et al., 2016; Ulyanov
et al., 2016; Li and Wand, 2016), but failed to guar-
antee content and texture of high-resolution images
with difficulty on irregular mask inpainting task. Yeh
et al. (Yeh et al., 2017) introduced a spatial atten-
tion mechanism in deep convolutional GAN (Radford
et al., 2015) combined with context loss but this al-
gorithm suffers misalignment on closest encoding in
latent space. It performs poorly in handling of high-
resolution and complex scene images. Li et al. (Li
et al., 2017) used face parsing network combined with
a generator (encoder-decoder) and two discriminators
optimised by a semantic parsing loss to ensure local-
global consistency and pixel fidelity. However, de-
spite excellent performance, neighbouring pixels fail
to establish spatial connections leading to colour in-
consistencies. Li et al. (Li et al., 2018) introduced
reflection symmetry into face completion and used
two networks, to establish a correspondence between
missing pixels on two half-faces optimised using a
symmetry loss defined on VGGFace (Parkhi et al.,
2015). However, this network fails to preserve struc-
tural information and is computationally costly.
Liu et al. (Liu et al., 2018a) used partial convo-
lution to replace typical convolutions (Ulyanov et al.,
2018) with an automatic mask-updating step. This
technique masks and renormalise convolutions to tar-
get only valid pixels. However, it performs poorly
on sparsely structured images and binary masks with
huge holes and no quantitative evaluation report on
facial images. Yan et al. (Yan et al., 2018) used
deep feature rearrangement by adding a particular
shift-connection layer to the U-Net architecture (Ron-
neberger et al., 2015), but lacks efficiency with no
guarantee in computational speed. Yu et al. (Yu
et al., 2018) proposed a dual-stage network convolu-
tional network combined with a contextual attention
layer that learns the location of feature information
from background patches to generate missing content.
However, this network lacks pixel-wise consistency
on high-resolution images. Liu et al. (Liu and Jung,
2019) proposed a multi-scale feature extraction pow-
ered by a multi-level generative network optimised by
content and texture losses based on Mean Square Er-
ror (`
2
) and Structure Similarity Index (MS-SSIM), to
capture features at various levels. This model strug-
gles with larger masks and fails to preserve structure
in unaligned facial images. Li et al. (Li et al., 2019)
proposed a nested GAN for facial inpainting, that uses
a residual connection structure to transport informa-
tion and interpolate feature map in deeper layer and
shallow layer. Wang et al. (Wang et al., 2019) intro-
duced a Laplacian approach based on residual learn-
ing (He et al., 2016) to propagate high-frequency de-
tails and predict missing information. Despite the
significant contributions by the methods above to the
field of inpainting, the absence of preserved realism
on facial images from a compact latent feature is still
challenging due to larger and irregular masks.
3 PROPOSED FRAMEWORK
Our proposed model uses skip connections with di-
lated convolution across the network, to perform im-
age inpainting. We discuss the architecture and loss
VISAPP 2021 - 16th International Conference on Computer Vision Theory and Applications
36
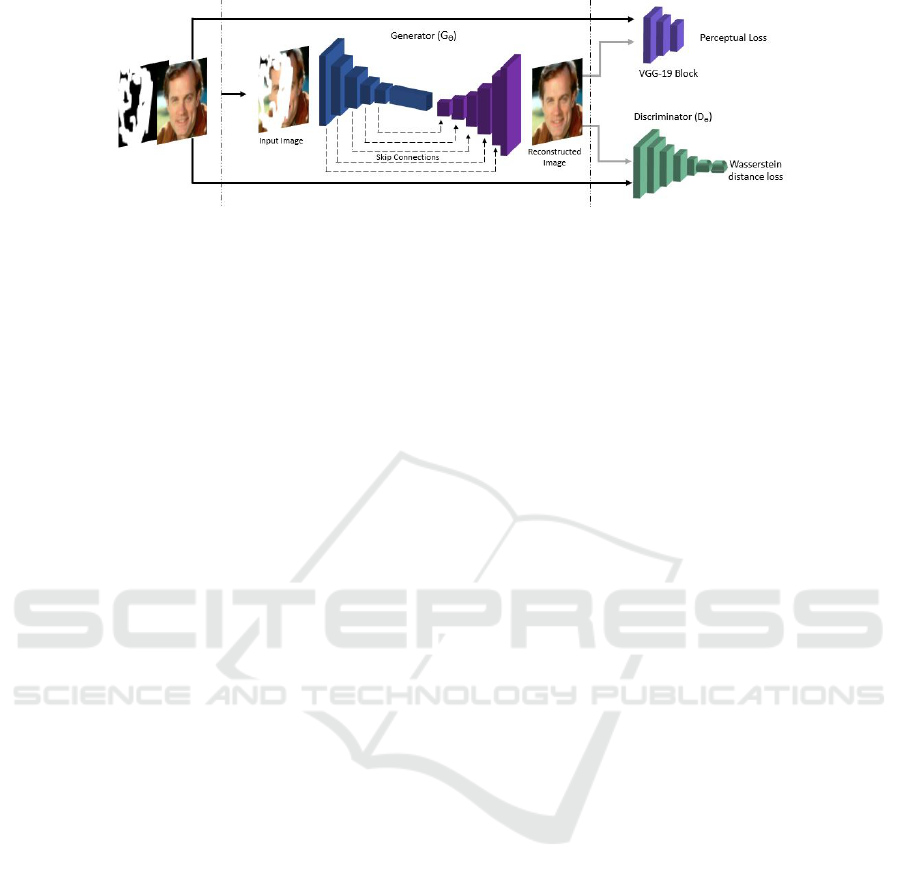
Figure 2: S-WGAN framework. The dilated convolution and deconvolution with the element-wise sum of feature maps (skip
connection) combined with a Wasserstein network. The skip connections in the diagram ensure local pixel-level accuracy of
the feature details to be retained.
function of S-WGAN in the following sections
3.1 Architecture
Figure 2 shows the overall framework of our proposed
S-WGAN. The network is designed to have a gener-
ator (G
θ
) and a discriminator (D
θ
). We define G
θ
as
an encoder-decoder framework with dilated convolu-
tions and symmetric skip connections. Figure 3 shows
the process of dilated convolution. Dilated convolu-
tions (Yu and Koltun, 2015), combined with skip con-
nections, are critical to the design of our model as:
• It broadens the receptive fields to capture more
contextual information without parameter accre-
tion and computational complexity, which are pre-
served and transferred by skip connections to cor-
responding deconvolution layers.
• It detects fine details and maintains high-
resolution feature maps, and achieves end-to-end
feature learning with a better local minimum (high
restoration performance).
• It has shown considerable improvement of accu-
racy in segmentation task (Yu and Koltun, 2015;
Chen et al., 2017a; Chen et al., 2017b).
Generator (G
θ
). The effectiveness of feature en-
coding is improved by having an encoder of ten-
convolutional layers, with a kernel size of 5 and di-
lation rate of 2, designed to match the size of the out-
put image. This technique enables our model to learn
larger spatial filters and help reduce volume (Rose-
brock, 2019). Each block of convolution in excep-
tion of the final layer has Leaky ReLU activation and
max-pooling operation of pool size 2 × 2. We apply
a dropout regularisation with a probability value of
0.25 in the 4th and final layer of the encoder. The
dropout layer randomly disconnects nodes and adjust
the weights to propagate information to the decoder
without overfitting.
Decoder. The decoder are five blocks of deconvo-
lutional layers, with learnable upsampling layers that
recover image details using the same kernel size and
dilation rate of the generator. The corresponding fea-
ture maps in the decoder are asymmetrically linked by
element-wise skip connections to reach an optimum
size. The final layer in the decoder is Tanh activation.
Dilated Convolutions. We express the dilated
convolution based on the network input in Equation 1:
I
0
(m,n)
=
M
∑
i=1
N
∑
j=1
(M
I
)(m+d
r
×i,n +d
r
× j)∗ω
(i, j)
(1)
where I
0
(m,n)
is the output feature map of the dilated
convolution from the input M
I
= (I (1 − M )) + M
and the filter is given by ω
(i, j)
. The dilation rate pa-
rameter (d
r
) reverts to normal when d
r
= 1.
It is advantageous to use dilated convolution com-
pared to using typical convolutional layers combined
with pooling. The reason for this is that a small kernel
size of k ×k can enlarge into k+ (k− 1)(d
r
−1) based
on the dilated stride d
r
, thus allowing a flexible recep-
tive field of fine-detail contextual information while
maintaining high-quality resolution.
The inpainting solver G
θ
may result in predic-
tions G
θ
(
ˆ
z) of the missing region, that may be rea-
sonable or ill-posed. We include as part of our net-
work D
θ
, adopted from (Arjovsky et al., 2017) to pro-
vide improved stability and enhanced discrimination
for photo-realistic images. With ongoing adversarial
training, the discriminator is unable to distinguish real
data from fake ones. Equation 2 shows the reconstruc-
tion of the image during training from G
θ
:
G
θ
(I
R
) = I M + (1 − M) G
θ
(
ˆ
z) (2)
where I
R
is the reconstructed image, I is the ground-
truth, (
ˆ
z) is the predictions, is the element-wise
multiplication and M is the binary mask, represented
in 0 and 1. In our case 0 is the context of the entire
image and 1 is the missing regions.
Equation 3 adopted from (Arjovsky et al., 2017)
refers to the Wasserstein discriminator.
max
D
V
W GAN
= E
x∼p
r
[(D
θ
(I)] − E
z∼p
z
[D(G
θ
(I
R
))]
(3)
Symmetric Skip Connection Wasserstein GAN for High-resolution Facial Image Inpainting
37

Figure 3: Illustration of dilated convolution process. Convolving a 3 × 3 kernel over a 7 × 7 input with a dilation factor of 2
(i.e., i = 7, k = 3, d
r
= 2, s = 1 and p = 0) (Dumoulin and Visin, 2016). The accretion of receptive field is in linearity with
the parameters (Yu and Koltun, 2015). A 5 × 5 kernel will have the same receptive field view as over a 7 ×7 input at dilation
rate=2 whilst only using 9 parameters over a 512 × 512 input.
where D is the discriminator and P
r
is real data distri-
bution. G is the generator of our network and P
z
is the
distribution.
3.2 Loss Function
Perceptual Loss. Instead of using the typical `
2
-
loss function used in (Pathak et al., 2016), we use
a new combination of loss functions, luminance (L
l
)
and feature loss. Pixel-wise reconstruction and fea-
ture space loss are not new to inpainting (Yeh et al.,
2017; Yu et al., 2018; Johnson et al., 2016). We define
a luminance guided L
l
that uses `
1
-loss as a base to
compute the loss using a range of constant pixel val-
ues in the RGB space. This preserves colour and lu-
minance and does not over penalise large errors (Zhao
et al., 2016). We use the L
l
to adjust our perceptual
loss, thus minimising any error >1. Also, the L
l
al-
lows better evaluation of the predictions to match the
ground-truth. More specifically, we express the lumi-
nance loss (L
l
) based on `
1
as:
L
l
= ||K (x
i
−
ˆ
z
i
)||
1
(4)
where i is the pixel index with x
i
and
ˆ
z
i
as pixel values
of the ground-truth and the predictions, constraint by
a constant K. Our feature loss L
f
is a feature based
`
2
-loss, rather than being computed directly on the
image we computed the loss in a feature space. To
achieve this, we adopt a pre-trained VGG-16 model
trained on ImageNet (Krizhevsky et al., 2012), and
use it as a feature extractor in our loss function. More
specifically we use the output of block3-convolution3
of this model to generate image feature. We use the
`
2
as base to compute our loss function, which is the
same as the perceptual loss proposed by Johnson et al.
(Johnson et al., 2016). The advantage of using feature
space is that a particular filter determines the extrac-
tion of feature maps, from low-level to high-level so-
phisticated features. To reconstruct quality images,
we compute our loss function with feature maps de-
termined by block3-conv3, resized to the same size as
masks and generated images. The reason is that using
another output for example block4-conv4 or block5-
conv5 will result in poor quality, as the network starts
to expand the view at these layers due to more filters
used. Our feature loss is expressed as follows:
L
f
=
1
N
∑
iεφ
(φ
i
[M
I
i
] − φ
i
[I
R
i
])
2
(5)
where M
I
is the input image, I
R
is the reconstructed
image and N is dimensions obtained from φ feature
maps with high-level representational abstractions ex-
tracted from the third block convolution layer. By
combining L
l
and L
f
we obtained:
L
p
= L
l
+ L
f
(6)
By using L
p
the model learns to produce finer details
in the predicted features and output without any blurry
artefacts. We add the Wasserstein loss (L
w
) improves
convergence in GANs and its the mean difference be-
tween two images. Finally the entire model trains
end-to-end with back-propagation and uses the global
Wasserstein-perceptual loss function (L
wp
) defined in
Equation 7, to optimise G
θ
and D
θ
to learn reason-
able predictions. Our goal is to reconstruct an image
I
R
from M
I
by training the generator G
θ
to learn and
preserve image details.
L
wp
= L
w
+ L
p
(7)
4 EXPERIMENT
This section describes the dataset, binary masks and
the implementation.
4.1 Dataset and Irregular Binary Mask
Our experiment focuses on high-resolution face im-
ages and irregular binary masks. The benchmark
dataset for high-resolution face images is CelebA-HQ
dataset (Karras et al., 2017), which was curated from
the CelebA dataset (Liu et al., 2018b) and contained
VISAPP 2021 - 16th International Conference on Computer Vision Theory and Applications
38

(a) (b) (c) (d)
Figure 4: Sample images from CelebA-HQ Dataset (Karras
et al., 2017).
(a) GT (b) Mask (c) Input
Figure 5: Process of input generation: a) CelebA-HQ im-
age; b) Binary mask image (Iskakov, 2018); and c) Corre-
sponding masked image (input image).
30,000 images. Figure 4 shows a few samples from
the CelebA-HQ dataset.
To create irregular holes on images, we use the
Quickdraw irregular mask dataset (Iskakov, 2018),
available for public use and is divided into 50,000
train and 10,000 test masks. The images are of size
512 × 512 pixels.
4.2 Implementation
We used the Keras library with TensorFlow back-
end to implement and design our network. With our
choice of the dataset, we followed the experiment set-
tings of state of the art (Liu et al., 2018a) and split our
data into 27,000 images for training and 3,000 images
for testing.
We perform normalised floating-point representa-
tion on the image to set the intensity values of the pix-
els in the range -1,1 and apply the mask on the image
to obtain our input, as shown in Figure 5. We initial-
ize pre-trained weights from VGG-16 to compute our
loss function. We use a learning rate of 10
−4
in G
θ
and 10
−12
in D
θ
and optimise the training process us-
ing the Adam optimiser (Kingma and Ba, 2014). We
use a Quadro P6000 GPU machine to train these mod-
els. According to our hardware conditions, we use a
batch-size of 5 in each epoch for input images with
shape 512×512× 3. It takes 0.193 seconds to predict
missing pixels of any size created by binary mask on
an image and ten days to train 100 epochs.
5 RESULTS
We assess the performance of the inpainting methods
qualitatively and quantitatively in this section.
5.1 Qualitative Comparisons
Consider the importance of visual and semantic co-
herence; we conducted a qualitative comparison of
our test dataset. First, we implemented a WGAN ap-
proach with L
f
and L
w
. We observed an induced pat-
tern and pitiable colour on the images, as shown in
Figure 6(d). We introduced dilated convolution, skip
connections combined with end-to-end training using
L
wp
to handle the induced pattern and match the lu-
minance of the original images.
We compare our model with three popular meth-
ods:
• CE: Context-Encoder method by Pathak et al.
(Pathak et al., 2016).
• PConv: Image Inpainting for irregular holes us-
ing partial convolutions by Liu et al. (Liu et al.,
2018a).
• WGAN: Wasserstein GAN method with percep-
tual loss.
We test our S-WGAN against state of the art on
CelebA-HQ 512 × 512 test dataset and show the re-
sults in Figure 6. Based on visual inspection, Fig-
ure 6(b) illustrates blurry generated by the Pathak et
al.’s CE method (Pathak et al., 2016). On the other
hand, PConv (Liu et al., 2018a) generates clear im-
ages but with residues of the binary mask left on the
images as shown in Figure 6(c). WGAN induced pat-
tern and low-contrast images, shown in Figure 6(d).
Overall, our proposed S-WGAN, as shown in Fig-
ure 6(e), produced the best visual results when com-
pared to the ground-truth in Figure 6(f).
5.2 Quantitative Comparisons
We select some popular image quality metrics includ-
ing `
1
, `
2
, Peak Signal to Noise Ratio (PSNR), SSIM
to evaluate the performance quantitatively. Table 1
shows the results from our experiment compared to
state of the art (Pathak et al., 2016; Liu et al., 2018a)
for image inpainting with our S-WGAN in bold.
For `
2
and `
1
, the lower the value, the better the
image quality. `
2
measures the average squared in-
tensity difference of pixels while `
1
measures the
magnitude of error between the ground-truth image
and the reconstructed image. Conversely, for PSNR
and SSIM, the higher the value, the closer the im-
age quality to the ground-truth. Based on observa-
tion from Table 1, S-WGAN achieves lower `
1
, `
2
,
Symmetric Skip Connection Wasserstein GAN for High-resolution Facial Image Inpainting
39

(a) (b) (c) (d) (e) (f)
(a) (b) (c) (d) (e) (f)
(a) INPUT (b) CE (c) PConv (d) WGAN (e) S-WGAN (f) GT
Figure 6: Qualitative comparison of our proposed S-WGAN with the state-of-the-art methods on CelebA-HQ: (a) Input
masked-image; (b) CE (Pathak et al., 2016); (c) PConv (Liu et al., 2018a); (d) WGAN; (e) S-WGAN (proposed method);
and (f) Ground-truth image.
Table 1: Quantitative comparison of various performance
assessment metrics on 3,000 test images from the CelebA-
HQ dataset. † Lower is better. ] Higher is better.
Method `
2
† `
1
† PSNR ] SSIM ]
WGAN 3562.13 87.03 13.50 0.56
CE 133.481 129.30 27.71 0.76
PConv 124.62 105.94 28.82 0.90
S-WGAN 81.03 66.09 29.87 0.94
higher PSNR and higher SSIM values in comparison
with CE (Pathak et al., 2016) and PConv (Liu et al.,
2018a), which suggests that S-WGAN provide more
accurate predictions than the state-of-the-art inpaint-
ing algorithm.
6 ABLATION STUDY
To justify the S-WGAN framework and validate the
effectiveness of L
p
, we conduct experiments and
show intermediate results using different alterations
of the S-WGAN on CelebA-HQ dataset. Firstly, we
conduct investigations on the WGAN and WGAN
with skip connection (WGAN-S) using the L
f
, and
observed a slight improvement in texture and struc-
ture of the reconstructed masked regions of the im-
ages. Figure 7 (b) and (c) show changes influ-
enced by skip connections. We observed that visu-
ally and quantitatively, the WGAN-S performs better
than WGAN model but not satisfactory as shown in
the first part of Table 2. Secondly, we improve the
WGAN-S model by including dilated convolutions to
each block, and additional convolution layers to ob-
tain our WGANSD model. We train the WGANSD
with the L
f
and train the S-WGAN model with our
new combined loss function. We noticed that train-
ing with the L
f
improved our results slightly, but not
satisfactorily. To verify the differences of these mod-
els, we conduct a qualitative and quantitative evalua-
tion. Visually, within the yellow rectangle on Figure 7
comparing columns (d) and (e), the S-WGAN result
in column (e) improved with significantly enhanced
local detail when compared with column (d) and the
original on column (f). Also, in quantitative evalu-
ation shown in Table 2, we observe that S-WGAN
trained end-to-end with L
wp
predicts reasonable out-
puts with finer details. We also show more qualita-
tively results in Figure 8 to demonstrate the S-WGAN
produces images with preserved realism.
To validate our S-WGANs’ representational abil-
ity generalised to other masks e.g. Nvidia mask (Liu
et al., 2018a), we use the various architectures of
our model to conduct experiments during the ablation
studies. We apply the Nvidia mask as the masking
method and show our results in Figure 9.
VISAPP 2021 - 16th International Conference on Computer Vision Theory and Applications
40

(a) INPUT (b) WGAN (c) WGAN-S (d) WGANSD (e) S-WGAN (f) GT
Figure 7: Qualitative comparison of results using different architectures (Johnson et al., 2016) on CelebA-HQ (Karras et al.,
2017). (a) Input masked image (b) Inpainted image by WGAN (c) Improved WGAN with skip connections (WGAN-S) (d)
Improved WGAN with skip connection and dilated convolution (WGANSD) (e) Complete network with L
p
(f) Ground-Truth
image. The yellow box indicates the region where other models failed to inpaint successfully completely. This region in (e)
shows the effectiveness of L
p
on the inpainted image.
(a) (b) (c) (d) (e) (f)
(a) INPUT (b) WGAN (c) WGAN-S (d) WGANSD (e) S-WGAN (f) GT
Figure 8: Qualitative comparison of results using different architectures with the perceptual loss (Johnson et al., 2016)
on CelebA-HQ (Karras et al., 2017). (a) Input masked image; (b) inpainted image by WGAN; (c) Improved WGAN with
skip connection; (d) improved WGAN with skip connection and dilated convolution (e) Complete network with L
p
; (f) The
ground-Truth image.
(a) INPUT (b) WGAN (c) WGAN-S (d) WGANSD (e) S-WGAN (f) GT
(a) INPUT (b) WGAN (c) WGAN-S (d) WGANSD (e) S-WGAN (f) GT
Figure 9: Qualitative evaluation of different architectures with perceptual loss (Johnson et al., 2016) on CelebA-HQ (Karras
et al., 2017) and Nvidia Mask. (a) Input masked image; (b) Inpainted image by WGAN; (c) Improved WGAN with skip
connection; (d) Improved WGAN with skip connection and dilated convolution; (e) Complete network with L
p
; (f) The
ground-Truth image.
Symmetric Skip Connection Wasserstein GAN for High-resolution Facial Image Inpainting
41

Table 2: Quantitative difference of results based on different
architectures (WGAN), WGAN-S, WGANSD with L
f
, and
S-WGAN trained with L
p
. † Lower is better. ] Higher is
better.
Method `
2
† `
1
† PSNR ] SSIM ]
WGAN 3562.13 87.03 13.50 0.56
WGAN-S 151.4 69.59 27.01 0.87
WGANSD 145.82 65.15 29.26 0.92
S-WGAN 81.03 66.09 29.87 0.94
7 DISCUSSION
Our proposed S-WGAN with dilated convolu-
tion and skip connections trained end-to-end with
Wasserstein-perceptual loss function outperforms the
state-of-the-art. Our model can learn the end-to-end
mapping of input images from a large-scale dataset
to predict missing pixels of the binary mask regions
on the image. Our S-WGANautomatically learns and
identifies missing pixels from the input and encodes
them as feature representations, to be reconstructed in
the decoder. Skip connections help to transfer image
details forwardly and find local minimum by back-
ward propagation.
Our experiments show the benefit of skip connec-
tion combined with Wasserstein-perceptual loss for
image inpainting. We have visually compared our
proposed method with state of the art (Pathak et al.,
2016; Liu et al., 2018a) in Figure 6. To verify the
effectiveness of our network, we carried out exper-
iments with regular convolutions and used the L
f
.
We noticed that the generated images had checkboard
artefacts with pitiable visual similarity compared to
the original image, as shown in Figure 6(d). We intro-
duced skip connections with dilated convolution and
our new loss function, and obtained improved results
that are semantically reasonable with preserved real-
ism in all aspects.
Compared to existing methods, the generator of
our S-WGAN learns specific structures in natural im-
ages by minimising L
p
with an enhanced hallucinat-
ing ability powered by symmetric skip connections.
Based on Figure 6, our S-WGAN can handle irregu-
larly shaped binary mask without any blurry artefacts
and has shown edge-preserving and mask completion
at border regions on the output images. Additionally,
using the Wasserstein discriminator enables the over-
all network to perform better. This boost the experi-
mental performance of our network to achieve state-
of-the-art results in inpainting task on high-resolution
images.
One limitation is a consistent practice of other in-
painting methods in the preprocessing step. Most
preprocessing ignores the fact that the image has to
be converted into normalised floating points repre-
sentations and an inverse-normalisation on the out-
put image, which contributes to the colour discrepan-
cies on the output image, that leads to expensive post-
processing. We have been able to solve this using S-
WGAN with a new combination of the loss function
that preserves colour and image detail.
8 CONCLUSION AND FUTURE
WORK
In this paper, we propose S-WGAN. Our network
can generate images, which are semantically and vi-
sually plausible with preserved realism of facial fea-
tures. We achieved this with a network structure that
can widen the receptive field in each block to capture
more information and forward to the corresponding
deconvolutional blocks. Additionally, we introduced
a new combined loss function based on luminance
and feature space combined with Wasserstein loss.
Our network was able to generate high-resolution im-
ages from input covered with arbitrary binary mask
shape and achieve a better performance compared
to the state-of-the-art methods. The proposed net-
work has shown the effectiveness of skip connections
with dilated convolutions as a capture and refining
mechanism of contextual information combined with
WGAN. For future work, we aim to extend our model
to inpaint coarse and fine wrinkles extracted from
wrinkle detectors (Yap et al., 2018) with preserved re-
alism.
ACKNOWLEDGEMENTS
The authors would like to thank The Royal Soci-
ety (Grant number: IF160006 and INF/PHD/180007).
We gratefully acknowledge the support of NVIDIA
Corporation with the donation of the Quadro P6000
and SCAN UK for providing DGX A100 servers used
for this research.
REFERENCES
Arjovsky, M., Chintala, S., and Bottou, L. (2017). Wasser-
stein gan. arXiv preprint arXiv:1701.07875.
Barnes, C., Shechtman, E., Finkelstein, A., and Goldman,
D. B. (2009). Patchmatch: A randomized correspon-
dence algorithm for structural image editing. ACM
Transactions on Graphics (ToG), 28(3):24.
VISAPP 2021 - 16th International Conference on Computer Vision Theory and Applications
42

Bertalmio, M., Sapiro, G., Caselles, V., and Ballester, C.
(2000). Image inpainting. In Proceedings of the 27th
annual conference on Computer graphics and interac-
tive techniques, pages 417–424. ACM Press/Addison-
Wesley Publishing Co.
Chen, L.-C., Papandreou, G., Kokkinos, I., Murphy, K., and
Yuille, A. L. (2017a). Deeplab: Semantic image seg-
mentation with deep convolutional nets, atrous convo-
lution, and fully connected crfs. IEEE transactions on
pattern analysis and machine intelligence, 40(4):834–
848.
Chen, L.-C., Papandreou, G., Schroff, F., and Adam,
H. (2017b). Rethinking atrous convolution for
semantic image segmentation. arXiv preprint
arXiv:1706.05587.
Criminisi, A., P
´
erez, P., and Toyama, K. (2004). Region
filling and object removal by exemplar-based image
inpainting. IEEE Transactions on image processing,
13(9):1200–1212.
Dumoulin, V. and Visin, F. (2016). A guide to convo-
lution arithmetic for deep learning. arXiv preprint
arXiv:1603.07285.
Efros, A. A. and Leung, T. K. (1999). Texture synthesis by
non-parametric sampling. In iccv, page 1033. IEEE.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B.,
Warde-Farley, D., Ozair, S., Courville, A., and Ben-
gio, Y. (2014). Generative adversarial nets. In
Advances in neural information processing systems,
pages 2672–2680.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep resid-
ual learning for image recognition. In Proceedings of
the IEEE conference on computer vision and pattern
recognition, pages 770–778.
Iizuka, S., Simo-Serra, E., and Ishikawa, H. (2017). Glob-
ally and locally consistent image completion. ACM
Transactions on Graphics (TOG), 36(4):107.
Iskakov, K. (2018). Semi-parametric image inpainting.
arXiv preprint arXiv:1807.02855.
Johnson, J., Alahi, A., and Fei-Fei, L. (2016). Perceptual
losses for real-time style transfer and super-resolution.
In European conference on computer vision, pages
694–711. Springer.
Karras, T., Aila, T., Laine, S., and Lehtinen, J. (2017). Pro-
gressive growing of gans for improved quality, stabil-
ity, and variation. arXiv preprint arXiv:1710.10196.
Kingma, D. P. and Ba, J. (2014). Adam: A
method for stochastic optimization. arXiv preprint
arXiv:1412.6980.
Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2012). Im-
agenet classification with deep convolutional neural
networks. In Advances in neural information process-
ing systems, pages 1097–1105.
Le, Q. V., Ngiam, J., Coates, A., Lahiri, A., Prochnow,
B., and Ng, A. Y. (2011). On optimization methods
for deep learning. In Proceedings of the 28th Inter-
national Conference on International Conference on
Machine Learning, pages 265–272. Omnipress.
Li, C. and Wand, M. (2016). Combining markov random
fields and convolutional neural networks for image
synthesis. In Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition, pages
2479–2486.
Li, X., Liu, M., Zhu, J., Zuo, W., Wang, M., Hu, G.,
and Zhang, L. (2018). Learning symmetry consis-
tent deep cnns for face completion. arXiv preprint
arXiv:1812.07741.
Li, Y., Liu, S., Yang, J., and Yang, M.-H. (2017). Gen-
erative face completion. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recogni-
tion, pages 3911–3919.
Li, Z., Zhu, H., Cao, L., Jiao, L., Zhong, Y., and Ma, A.
(2019). Face inpainting via nested generative adver-
sarial networks. IEEE Access, 7:155462–155471.
Liu, G., Reda, F. A., Shih, K. J., Wang, T.-C., Tao, A., and
Catanzaro, B. (2018a). Image inpainting for irregu-
lar holes using partial convolutions. arXiv preprint
arXiv:1804.07723.
Liu, J. and Jung, C. (2019). Facial image inpainting using
multi-level generative network. In 2019 IEEE Interna-
tional Conference on Multimedia and Expo (ICME),
pages 1168–1173. IEEE.
Liu, Z., Luo, P., Wang, X., and Tang, X. (2018b). Large-
scale celebfaces attributes (celeba) dataset. Retrieved
August, 15:2018.
Park, T., Zhu, J.-Y., Wang, O., Lu, J., Shechtman, E., Efros,
A., and Zhang, R. (2020). Swapping autoencoder for
deep image manipulation. Advances in Neural Infor-
mation Processing Systems, 33.
Parkhi, O. M., Vedaldi, A., and Zisserman, A. (2015). Deep
face recognition.
Pathak, D., Krahenbuhl, P., Donahue, J., Darrell, T., and
Efros, A. A. (2016). Context encoders: Feature learn-
ing by inpainting. In Proceedings of the IEEE Con-
ference on Computer Vision and Pattern Recognition,
pages 2536–2544.
P
´
erez, P., Gangnet, M., and Blake, A. (2003). Poisson im-
age editing. In ACM SIGGRAPH 2003 Papers, pages
313–318.
Radford, A., Metz, L., and Chintala, S. (2015). Unsu-
pervised representation learning with deep convolu-
tional generative adversarial networks. arXiv preprint
arXiv:1511.06434.
Ronneberger, O., Fischer, P., and Brox, T. (2015). U-net:
Convolutional networks for biomedical image seg-
mentation. In International Conference on Medical
image computing and computer-assisted intervention,
pages 234–241. Springer.
Rosebrock, A. (2019). Deep Learning for Computer Vision
with Python. PyImageSearch.com, 2.1.0 edition.
Sun, J., Yuan, L., Jia, J., and Shum, H.-Y. (2005). Im-
age completion with structure propagation. In ACM
Transactions on Graphics (ToG), volume 24, pages
861–868. ACM.
Ulyanov, D., Lebedev, V., Vedaldi, A., and Lempitsky, V. S.
(2016). Texture networks: Feed-forward synthesis of
textures and stylized images. In ICML, pages 1349–
1357.
Ulyanov, D., Vedaldi, A., and Lempitsky, V. (2018). Deep
image prior. In Proceedings of the IEEE Conference
Symmetric Skip Connection Wasserstein GAN for High-resolution Facial Image Inpainting
43

on Computer Vision and Pattern Recognition, pages
9446–9454.
Vincent, P., Larochelle, H., Lajoie, I., Bengio, Y., and
Manzagol, P.-A. (2010). Stacked denoising autoen-
coders: Learning useful representations in a deep net-
work with a local denoising criterion. Journal of ma-
chine learning research, 11(Dec):3371–3408.
Wang, Q., Fan, H., Sun, G., Cong, Y., and Tang, Y. (2019).
Laplacian pyramid adversarial network for face com-
pletion. Pattern Recognition, 88:493–505.
Yan, Z., Li, X., Li, M., Zuo, W., and Shan, S. (2018). Shift-
net: Image inpainting via deep feature rearrangement.
In Proceedings of the European Conference on Com-
puter Vision (ECCV), pages 1–17.
Yang, C., Lu, X., Lin, Z., Shechtman, E., Wang, O., and
Li, H. (2017). High-resolution image inpainting using
multi-scale neural patch synthesis. In The IEEE Con-
ference on Computer Vision and Pattern Recognition
(CVPR), volume 1, page 3.
Yap, M. H., Alarifi, J., Ng, C.-C., Batool, N., and Walker, K.
(2018). Automated facial wrinkles annotator. In Pro-
ceedings of the European Conference on Computer Vi-
sion (ECCV), pages 0–0.
Yeh, R. A., Chen, C., Lim, T.-Y., Schwing, A. G.,
Hasegawa-Johnson, M., and Do, M. N. (2017). Se-
mantic image inpainting with deep generative models.
In CVPR, volume 2, page 4.
Yu, F. and Koltun, V. (2015). Multi-scale context ag-
gregation by dilated convolutions. arXiv preprint
arXiv:1511.07122.
Yu, J., Lin, Z., Yang, J., Shen, X., Lu, X., and Huang, T. S.
(2018). Generative image inpainting with contextual
attention. arXiv preprint.
Zhao, H., Gallo, O., Frosio, I., and Kautz, J. (2016).
Loss functions for image restoration with neural net-
works. IEEE Transactions on Computational Imag-
ing, 3(1):47–57.
VISAPP 2021 - 16th International Conference on Computer Vision Theory and Applications
44
