
Determining Policy Communication Effectiveness: A Lexical Link
Analysis Approach
Claire Dyer, Brian Wood, Ying Zhao
a
and Douglas J. MacKinnon
Naval Postgraduate School, Monterey, CA, U.S.A.
Keywords:
Lexical Link Analysis, LLA, Text Mining, Match and Gap Analysis, Communication, Organizational
Communication, Policy Communication.
Abstract:
Military policies are often promulgated from the echelon II and III level, but it is often difficult to ascertain
whether they are interpreted and implemented as intended. There is often a communication gap. This article
seeks to determine if data mining tools such as lexical link analysis can measure that gap in quantitative terms.
It starts by examining how lexical link analysis can determine how policies are communicated through the
various echelons, assessing whether lexical link analysis can be used to determine if policies are interpreted
and redistributed as intended, and exploring what this data tells us about policy communication and the im-
plications for policy execution. The author uses lexical link analysis to reveal if there is a degree of policy
mismatch at lower echelon levels and makes assessments about this mismatch based on established commu-
nication theory. This paper validated that Naval aircrew’s understanding of policies is of vital importance
and higher policy tends to be interpreted and reissued with greater specificity as it moves down the chain of
command as exemplified between Echelons IV and V.
1 INTRODUCTION (Dyer, 2020)
The U.S. Navy is separated into multiple levels of
leadership and organization. Upper-level policies are
written and expected to be executed down the chain-
of-command. Policies promulgated by echelon II and
III commands may not have the desired effect origi-
nally intended. Discovering this communication mis-
match often can be difficult and commonly it is not
discovered until thousands, if not millions, of dollars
are spent and many manpower and training hours are
wasted. To mitigate this, big data analytics may help
inform the Navy’s organizational communication and
make it more effective.
This paper assessed attributes of the current so-
ciotechnical system (STS), or the technical, social,
organizational, and environmental aspects of a sys-
tem, used to conduct F/A-18 flight training events.
The researchers emphasized the importance of inter-
actions between hardware, software, and people, and
related processes to support the interactions. The pre-
vious researchers also acknowledged system capabil-
ity needs, recommended subsequent technical and so-
cial requirements, and suggested improvements to the
a
https://orcid.org/0000-0001-8350-4033
STS and the administering of training events (Holness
and Wood, 2018).
Training effectiveness depends on the quality of
the training devices provided, instruction, syllabi,
feedback systems, and the supporting resources that
make up the vast majority of the U.S. department of
defense (DoD) funding. In order to improve military
capability, we need to fully grasp the efficacy of cur-
rent Fleet operational training. We intend to do this
by examining the effectiveness of the communication
that dictates the syllabi and resources that apply to the
operator’s training.
This research identifies gaps and successes of or-
ganizational communication within the Navy Air Sys-
tems Command (NAVAIR) and other high-level com-
mands as they pertain to the promulgation and exe-
cution of organization policies that affect and inform
training syllabi and resources. An analysis of this
communication results in recommendations regarding
mismatches and how these may be remedied. This pa-
per utilized big data analysis tools, specifically Lex-
ical Link Analysis (LLA), to determine how the syl-
labi and supporting resources accomplish underlying
readiness objectives set forth at the echelon II and III
levels. The research resulted in recommendations and
follow-on research that explore the environmental and
Dyer, C., Wood, B., Zhao, Y. and MacKinnon, D.
Determining Policy Communication Effectiveness: A Lexical Link Analysis Approach.
DOI: 10.5220/0010640700003064
In Proceedings of the 13th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2021) - Volume 1: KDIR, pages 103-109
ISBN: 978-989-758-533-3; ISSN: 2184-3228
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
103

organizational aspects of flight training with the goal
of implementing an improved design for F/A-18 flight
training events.
2 BIG DATA AND CONTENT
ANALYSIS
There has been a good deal of research conducted to
link big data with organizational communication, but
the bulk of that research has centered around lever-
aging big data to improve marketing and public re-
lations efforts (Wiencierz and R
¨
ottger, 2017). In
their suggestions for future research, Wiencierz and
R
¨
ottger suggest that data analysis could enable man-
agement, or any communicator for that matter, to an-
alyze issues and influence such issues strategically.
This implies that data analysis could identify misin-
terpretation of communication. A more specialized
field of data analysis, content analysis, allows the re-
searcher to objectively, systematically, and quantita-
tively extract meaningful content from large volumes
of text (Neuendorf, 2016). Prior to 1997 much of
content analysis was conducted in the field of jour-
nalism and that analysis was done manually (Guo
et al., 2016). Today, there are a number of automated
tools available to accomplish such analysis (Slapin
and Proksch, 2014; Guo et al., 2016). Lexical link
analysis (LLA) is an unsupervised topic modeling
method detail in Section 3.
NAVAIR provided a list of possible documents re-
lated to the F/A-18 Strike Fighter Advanced Readi-
ness Program (SFARP). After a review, the re-
searchers selected and compared the 17 primary poli-
cies and instructions governing SFARP to determine
correlation.
3 LEXICAL LINK ANALYSIS
(LLA)
We use LLA as an example of deep models (Zhao
et al., 2015) (Quantum Intelligence, 2015). In an
LLA, we describe the characteristics of a complex
system using a list of attributes or features with spe-
cific vocabularies or lexical terms. For example, we
can describe a system using word pairs or bi-grams as
lexical terms extracted from text data.
Figure 1 shows an example of such a word net-
work discovered from text data. “human learning”
and “human interface” are two bi-gram word pairs.
For a text document, words are represented as nodes
and word pairs as the links between nodes. A word
center (e.g., “human” in Figure 1) is formed around
a word node connected with a list of other words
to form more word pairs with the center word “hu-
man.” In contrast to human-annotated word networks,
such as WordNet (Miller, 1995), LLA automatically
discovers word pairs, divides them into clusters and
themes, and displays them as word networks.
LLA is related to but significantly different from
the methods such as bag-of-words (BOW) meth-
ods, Automap (CASOS, 2009), Latent Dirichlet Al-
location (LDA) (Blei et al., 2003), Latent Seman-
tic Analysis (LSA) (Dumais et al., 1988), Proba-
bilistic Latent Semantic Analysis (PLSA) (Hofmann,
1999) and can be jointly used with named entity ex-
traction (NEE) (InXight, 1997; MUC-7, 1998), part
of speech (POS) methods (Toutanova and Manning,
2000). LLA is related to unsupervised learning algo-
rithms such as k-means, principal component analy-
sis (PCA), and spectral clustering (Ng et al., 2002).
LLA can be applied to both structured and unstruc-
tured data. Because it uses an improved community
detection method to find clusters, it can find more
interesting groups than the traditional spectral based
methods such as PCA, LDA, and LSA. LLA can also
compare matches and gaps easily among documents
or repositories of documents, which is the focus of
this paper.
We applied LLA in use cases to facilitate the dis-
covery of high-value information in different appli-
cation domains. LLA outputs smart data such as se-
mantic and social networks (Zhao et al., 2012), pat-
terns such as rules, associations (Zhao et al., 2016a),
themes and topics (Zhao et al., 2017b). The themes
and topics discovered by LLA are further divided into
the popular or authoritative, emerging and anomalous
information categories. Information users can use
authoritative information to discover leadership and
archetypes in a social network (Zhao et al., 2016b),
use emerging information to discover high-value in-
formation from crowdsourcing (Zhao et al., 2017a),
Figure 1: An example of lexical link analysis.
KDIR 2021 - 13th International Conference on Knowledge Discovery and Information Retrieval
104
and use anomalous associations to identify fraudulent
behavior and imposters (Zhao et al., 2016b).
The output of LLA includes a file of associations
where word pairs (for unstructured data) or lexical
features (for structured data) are linked together.
4 LLA RESULTS
4.1 Themes Discovered
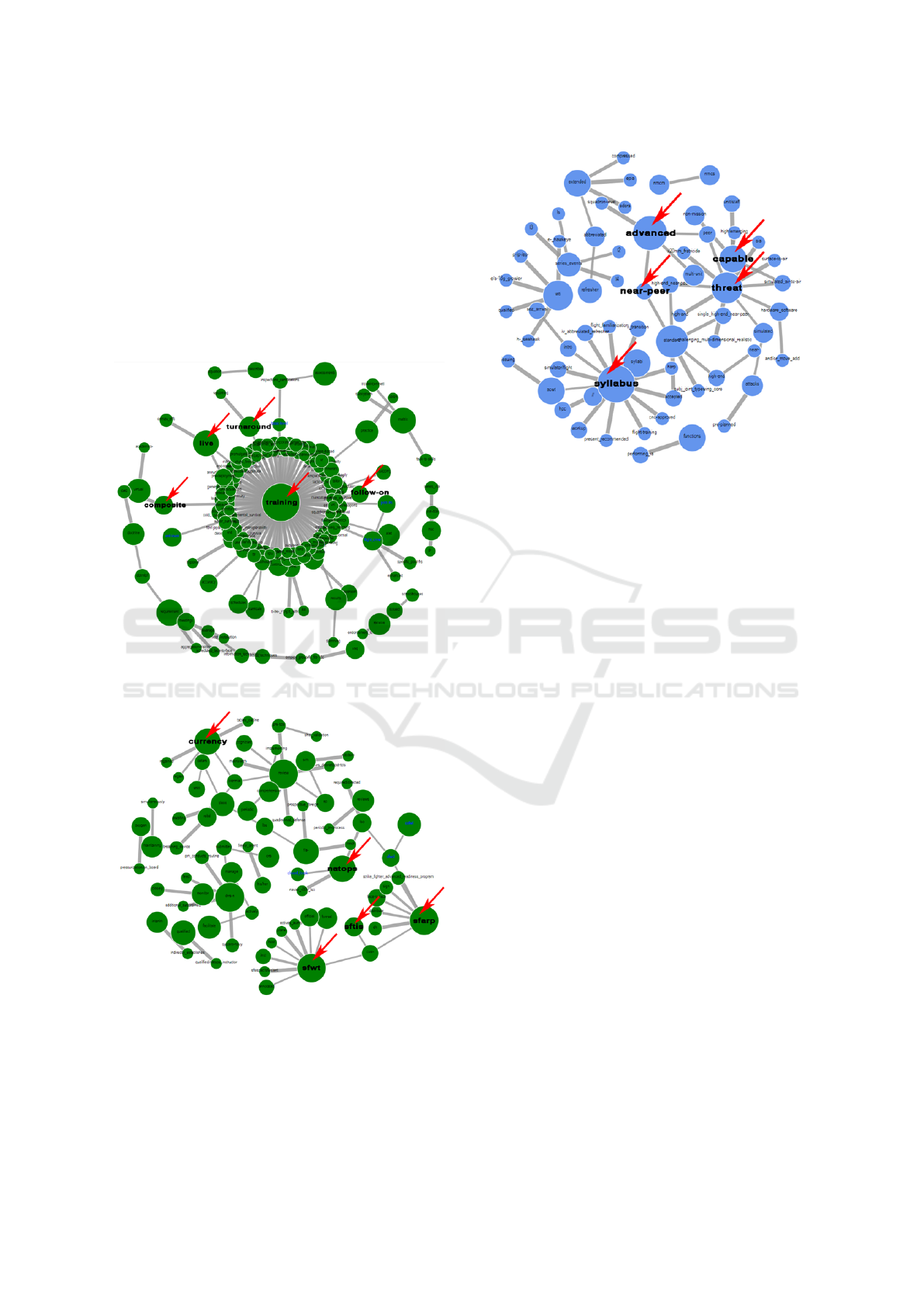
Figure 2: Theme 147 - Training Theme Word Cloud.
Figure 3: Theme 125 - SFARP Theme Word Cloud.
We observed correlation within the Word Cloud vi-
sualization from the LLA outputs. Figure 2, Fig-
ure 3, and Figure 4 display three of the key dis-
covered themes found through LLA. The visualiza-
Figure 4: Theme 137 - Syllabus Theme Word Cloud.
tions display a significant trend between the 17 in-
structions examined. Of particular note, Theme 147
in Figure 2, the training theme, displays that some
of the most significant bi-grams found in this theme
are live training, turnaround training, follow-on train-
ing, and composite training. This implies that sig-
nificant emphasis was put on these themes through-
out the 17 instructions. Furthermore, Theme 125 in
Figure 3, the SFARP theme, reveals a trend between
Strike Fighter Weapons and Tactics (SFWT), Strike
Fighter Weapons and Tactics Instructors (SFTIs),
Naval Air Training, Operating Procedures Standard-
ization (NATOPS), and currency. Lastly, Figure 4
depicts Theme 1, the syllabus theme word cloud, re-
vealing an emphasis on advanced, capable, near-peer
threats throughout the training syllabi.
Theme 147 in Figure 2, is perhaps the second
most relevant theme of this study. The theme’s key-
words are “live training” and “training matrix.” In this
theme, 138 word pairs matched across the 17 docu-
ments and the consensus—percentage of words that
matched between documents—was 17%. The highest
consensus among all the themes was only 18%, i.e.,
Theme 113—readiness standards, conditions), indi-
cating there is not exactly a high degree of homogeny
across the 17 documents. As briefly mentioned above,
authors expect this to an extent as higher echelons
use more broad language to convey their intent while
lower echelons interpret that intent and give their in-
structions using more specificity.
There is only 7% percent consensus for Theme
125 – SFARP. This is essential to the paper since the
primary topic of the research is how these policies in-
fluence training, specifically SFARP. For this theme,
CSFWPL 3710.14G, Joint Typewing Core Standard
Determining Policy Communication Effectiveness: A Lexical Link Analysis Approach
105

Operating Procedures (SOP) scored the highest node
match. Authors expected this high degree of node
match since the publisher is at the echelon IV level
which directly governs SFARP. CSFWPL 1525.1G,
CNAL 5440.3, and SFWSPACINST 3500.3B scored
the next highest on this theme. Again, this is gener-
ally expected because of their position in the chain of
command.
Theme 137 in Figure 4, “syllabus,” scores 10%
which is relatively high compared to the highest
consensus score. Naval Aviation Warfighting De-
velopment Center (NAWDC) had the highest node
matches—actual word-for-word bi-gram matches be-
tween documents—on this theme (52) which is con-
sistent considering it is the source of air combat train-
ing and tactics development, the primary source for
training syllabi. COMNAVAIRLANT had the second
highest node matches in this theme with a total of 47.
Again, this is consistent with their mission to provide
training to east coast squadrons.
4.2 Match Matrix
Figure 5 shows a match matrix view of the 17 doc-
uments. The numbers shown indicate a reference to
the number of terms or word categories (i.e., themes)
found among the documents. For example, in the
first row of Figure 5, USFF CPF 3501-3D matched
across all documents for 725 themes out of 2510
themes (Uniqueness Score or total themes found in
the document). Moving to the right across Fig-
ure 5, USFF CPF 3501-3D has a match score with
USFFC 300015A of 411 or about 16.4%.
4.3 Matches and Gaps between
Echelons and Organization
Relations
The instructions examined span across five echelons
as depicted in Figure 6. Upon first inspection, one
can glean from the Chord Diagrams from the LLA
outputs that the instructions at the highest echelons
have the greatest degree of symmetry. The further
down the chain of command, the greater the diver-
gence. For example, Figure 7 shows Commander U.S.
Pacific Fleet (CPF)—an echelon II command—has a
great deal of symmetry between itself and U.S. Fleet
Forces Command (USFFC)—another echelon II com-
mand. The next highest degree of symmetry is be-
tween itself and Commander, Naval Air Forces At-
lantic (CNAL)—an echelon III command. Further,
Strike Fighter Weapons School Pacific (SFWSP) has
the least degree of symmetry among all the instruc-
tions examined as seen in Figure 8.
Initially, Pearson’s Correlation Coefficient (r)
—the measure of linear relationship between two data
sets—showed no or very weak correlation between
the data sets. However, when compared between
Match Score and Uniqueness Score or, algebraically
in Figure 10, where x equals the Match Score and
y equals the Uniqueness Score, the analyst notes a
very strong correlation between Echelon I instruc-
tions and a progressively weaker correlation as the an-
alyst moves down the echelons Figure 11 and this is
consistent with previous research results (Frey, 2018).
The correlations and the Chord Diagrams visually
reveal a strong linear relationship at higher echelons.
This could be attributed to a higher degree of under-
standing at higher echelons. More likely, however,
the lower r below Echelon III is due to a higher de-
gree of specificity at lower echelons. In other words,
higher echelons may be more correlated because they
use broad, overarching language to relay their intent;
while lower echelons interpret that intent and specifi-
cally state through their instructions how they are go-
ing to achieve the intent of their parent commands.
4.4 Match Matrix of Echelons
Figure 9 depicts the Match Matrix for the 17 instruc-
tions analyzed organized by echelon. The cells in yel-
low represent bi-gram matches between echelons one
step apart. Those in pink represent bi-gram matches
between echelons two steps apart. Those in green rep-
resent bi-gram matches between echelons three steps
apart, whereas orange represents bi-gram matches be-
tween echelons four steps apart. The cells in grey rep-
resent bi-gram matches at the same echelon and will
be disregarded as they generally do not issue direction
to themselves or commands at the same echelon level.
From this matrix, the researcher notes the highest de-
gree of match at echelons one step apart (i.e., eche-
lon II bi-grams have a higher degree of match with
echelon I, echelon III have a higher degree of match
with echelon II, etc.). This indicates that commands
take the instructions from their parent commands and
promulgate further guidance predominately based on
those instructions and with a lesser regard to instruc-
tions two or three steps above them. Table 7 fur-
ther accentuates this. Here, the researcher averaged
each instruction’s matches for each subordinate ech-
elon and then averaged those averages (e.g., OPNAV
3500.31G has an average of 39.5 matches from eche-
lon II instructions, USFFC 3000.15A has an average
of 51.83 matches from echelon III instructions, and so
on). The bold cells are the average of these numbers
to account for each echelon’s subordinate averages.
KDIR 2021 - 13th International Conference on Knowledge Discovery and Information Retrieval
106

Figure 5: Match Matrix.
Figure 6: Echelon Level of Document Authors.
Figure 7: USFF-CPF 3501-D Chord Diagram Relation.
Figure 8: SFWSP Chord Diagram Relation.
5 CONCLUSION
Organizations typically use vertical communication
and mass media to communicate policy, as is exem-
plified in Naval Aviation through promulgation via its
use of email, message traffic, and command websites.
However, at present, there is no verification that en-
sures policy being understood at lower levels (Whit-
worth, 2011). Naval aircrew’s understanding of poli-
cies is still of vital import since higher policy tends to
Determining Policy Communication Effectiveness: A Lexical Link Analysis Approach
107

Figure 9: Match Matrix of Echlons.
Figure 10: Pearson correlation computation.
be interpreted and reissued with greater specificity as
it moves down the chain of command as exemplified
between Echelons IV and V.
In this paper, we hypothesized that there would be
some degree of mismatch between policies at the vari-
ous levels which was proven. The reason for this mis-
match appears to be due to a higher degree of speci-
ficity in policies at lower level echelons as explained
by their higher Uniqueness Scores.
Between Echelons I and IV, LLA does reveal com-
mon as well as uncommon vectors between docu-
ments from the various levels and subsequently, cor-
relation and differentiation.
ACKNOWLEDGEMENTS
Thanks to the Naval Research Program at the Naval
Postgraduate School, the Office of Naval Research
(ONR), and the SBIR contract N00014-07-M-0071
for the research of Lexical Link Analysis and Col-
laborative Learning Agents at Quantum Intelligence,
Inc. The views and conclusions contained in this doc-
ument are those of the authors and should not be in-
terpreted as representing the official policies, either
expressed or implied of the U.S. Government.
Figure 11: Pearson’s Correlation Coefficient by Echelon
and Total r.
REFERENCES
Blei, D., Ng, A., and Jordan, M. (2003). Latent dirichlet
allocation. volume 3, pages 993–1022.
CASOS (2009). Automap: extract, analyze and represent
relational data from texts. In Center for Computa-
tional Analysis of Social and Organizational Systems.
KDIR 2021 - 13th International Conference on Knowledge Discovery and Information Retrieval
108

Dumais, S. T., Furnas, G. W.and Landauer, T. K., and Deer-
wester, S. (1988). Using latent semantic analysis to
improve information retrieval. pages 281–285.
Dyer, C. L. (2020). Determining policy communication ef-
fectiveness: A lexical analysis approach. Thesis of
Master of Science, Naval Postgraduate School, Mon-
terey, CA, USA.
Frey, B. (2018). The sage encyclopedia of educational re-
search, measurement, and evaluation. pages Vols. 1–4,
Thousand Oaks, CA. SAGE Publications, Inc.
Guo, L., Vargo, C., Pan, Z., Ding, W., and Ishwar, P. (2016).
Big social data analytics in journalism and mass com-
munication: Comparing dictionary-based text analy-
sis and unsupervised topic modeling. volume 93(3),
page 332–359.
Hofmann, T. (1999). Probabilistic latent semantic analysis.
Holness, K. and Wood, B. (2018). Sociotechnical system
evaluation of naval aviation policies, guidance, train-
ing events, and training systems proposal (iref project
id number: Nps-19-n119-a). Monterey, CA: Naval
Postgraduate School.
InXight (1997). Inxight.
Miller, G. A. (1995). Automap: extract, analyze and rep-
resent relational data from textswordnet: a lexical
database for english. volume 38(11).
MUC-7 (1998). In MUC-7: PAPERS: SYSTEMS - Named
Entity Tasks.
Neuendorf, K. A. (2016). In The content analysis guide-
book. Sage.
Ng, A., Jordan, M., and Weiss, Y. (2002). On spectral clus-
tering: analysis and an algorithm. page 849–856. MIT
Press.
Quantum Intelligence, I. (2015). Collaborative learning
agent: Users’ guide.
Slapin, J. and Proksch, S. (2014). In In The Oxford Hand-
book of Legislative Studies.
Toutanova, K. and Manning, C. (2000). Enriching the
knowledge sources used in a maximum entropy part-
ofspeech tagger. In EMNLP/VLC 1999s, page 63–71.
Whitworth, B. (2011). Internal communication. in the iabc
handbook of organizational communication: a guide
to internal communication, public relations, market-
ing, and leadership. page 195–206.
Wiencierz, C. and R
¨
ottger, U. (2017). The use of big
data in corporate communication. volume 22(2), page
258–272.
Zhao, Y., Kendall, W. A., and Young, B. W. (2016a). Big
data and deep analytics applied to the common tac-
tical air picture (ctap) and combat identification(cid).
In Proceedings of the 8th International Joint Confer-
ence on Knowledge Discovery, Knowledge Engineer-
ing and Knowledge Management, volume 1 of IC3K
2016, pages 443–449.
Zhao, Y., MacKinnon, D., and Gallup, S. (2012). Seman-
tic and social networks comparison for the haiti earth-
quake relief operations from apan data sources using
lexical link analysis. In Proceedings of the 17th IC-
CRTS, International Command and Control, Research
and Technology Symposium, ICCRTS 2012.
Zhao, Y., MacKinnon, D., and Gallup, S. (2015). Big data
and deep learning for understanding dod data. In Jour-
nal of Defense Software Engineering, Special Issue:
Data Mining and Metrics.
Zhao, Y., MacKinnon, D., and Zhou, C. (2017a). Dis-
covering high-value information from crowdsourcing.
In Proceedings of the 2017 IEEE/ACM International
Conference on Advances in Social Networks Analysis
and Mining.
Zhao, Y., Mackinnon, D. J., Gallup, S. P., and Billingsley,
J. L. (2016b). Leveraging lexical link analysis to dis-
cover new knowledge. In Military Cyber Affairs, 2(1),
3.
Zhao, Y., Mooren, E., and Derbinsky, N. (2017b). Rein-
forcement learning for modeling large-scale cognitive
reasoning. In Proceedings of the 9th International
Conference on Knowledge Engineering and Ontol-
ogy Development, Nov. 1-3, 2017, Funchal, Portugal.
(KEOD 2017).
Determining Policy Communication Effectiveness: A Lexical Link Analysis Approach
109
