
Mathematical Interpretation of Educational Student’s and Scientific
Studies in Form of Digital Ontologies
Viktor B. Shapovalov
a
and Yevhenii B. Shapovalov
b
The National Center “Junior Academy of Sciences of Ukraine”, 38-44 Degtyarivska Str., Kyiv, 04119, Ukraine
Keywords:
Ontology, IMRAD, Structuration, Scientific Studies, Biogas.
Abstract:
Because of the problem of the large amount of scientific data generated, it is relevant to develop structuring
and processing methods. Using ontology graphs is the modern perspective way of their representation. Con-
sidering that most studies are written based on IMRAD, it was used to provide integration of different studies
at a single structure and provide structuration at all. The different ways to create integrated ontology using IM-
RAD are described. To get the necessary level of abstraction, IMRAD elements as part of a set of the specific
studies were decomposed as levels of abstraction from L1 (general node that describes a branch of science)
to L5 (specific papers with detailed data) depending on the abstraction. The content of each node in the form
of metadata and its further processing is described. The particular way of using proposed modes has been
described in the example of describing studies in biogas production. The mathematical model of the proposed
ontology is developed and presented. It is shown that a set of corteges describes IMRAD representation of the
scientific studies in the form of ontologies.
1 INTRODUCTION
The data nowadays is generated with colossal inten-
sity. Due to this, Big Data processing is a trend (Globa
et al., 2019; Stryzhak et al., 2021). Processing a con-
siderable amount of data in real life is complicated
by the high gain of publishing scientific studies. In
general, it seems like an exponentially growing of the
publications. According to lens.org, in 1900, only
532 M of scientific papers were published, but their
amount in 2015 was near 10 B (figure 1).
Considering the development of STEM, studies
are provided not only by experienced scientists by
youth. Such a considerable number of studies gen-
erated complicated tasks to process such data. One of
the problems of low spreading and usage (in the ex-
ample of Ukraine (Hrynevych et al., 2021; Martyniuk
et al., 2021; Shapovalov et al., 2020b; Stryzhak et al.,
2017)) may be related to difficulties with the process-
ing of science.
Now, scientific studies are published in different
forms of report, such as articles, conference proceed-
ings, books, etc. However, its process is complicated
due to studies are low-structured. Sure, they are all
a
https://orcid.org/0000-0001-6315-649X
b
https://orcid.org/0000-0003-3732-9486
built by a similar structure named IMRAD (Oriokot
et al., 2011; Pardede, 2012). It envisages require-
ments for the paper to consist of some generalized
Introduction, describing used Materials and Methods,
naming the Results of the study and the Discussion by
comparing with other scientific materials or providing
use cases. However, it seems not enough. Here just
some examples of problems due to it:
• it is hard to start the researcher carrier due to com-
plicated process of understanding of the methods
and equipment that need to be used in specific
fields of study;
• it is hard for youth scientists to understand main
parameters that have measured to provide study
analysis;
• for expired scientists, it is hard to analyze and col-
lect data of new studies.
These are only very few cases that are a problem
due to high amount of data of scientific studies. How-
ever, these cases are makes relevant to develop new
methods to provide better structuration and data pro-
cessing of scientific studies.
Sure, there are few solutions for this problem that
provides automated science data processing (Klampfl
et al., 2014; Portenoy and West, 2020; Gorashy
and Salim, 2014; Shakeel et al., 2018; Paschke and
578
Shapovalov, V. and Shapovalov, Y.
Mathematical Interpretation of Educational Studentâ
˘
A
´
Zs and Scientific Studies in Form of Digital Ontologies.
DOI: 10.5220/0012066200003431
In Proceedings of the 2nd Myroslav I. Zhaldak Symposium on Advances in Educational Technology (AET 2021), pages 578-587
ISBN: 978-989-758-662-0
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
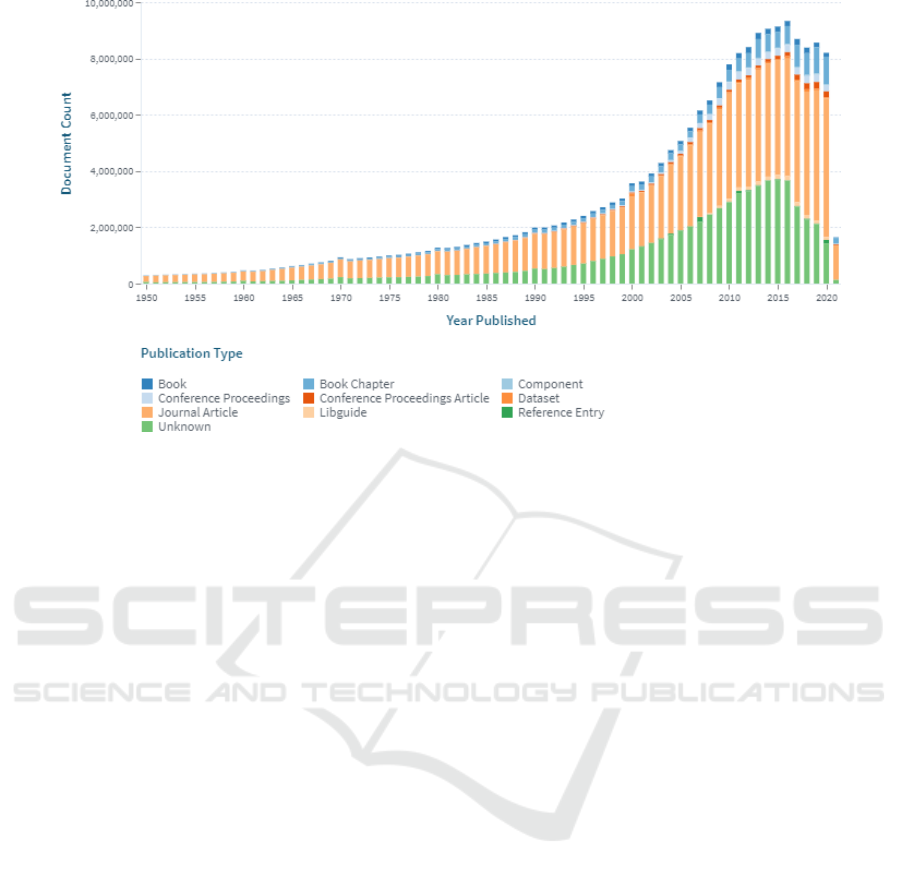
Figure 1: Dynamic of published papers according to Lens.org web service.
Sch
¨
afermeier, 2018), but it seems that they do not take
to account IMRAD. One of the appropriate methods
to solve the problems is ontology taxonomies (Globa
et al., 2015; Mintser et al., 2018; Stryzhak et al.,
2018; Sch
¨
afermeier et al., 2021) with semantic tech-
nologies (Alnemr et al., 2010). Also, ontology tax-
onomies have a lot of advantages, such as the possi-
bility to combine with other types of materials (Gru-
ber et al., 2020), including interactive and web-based
courses (Bovtruk et al., 2020; Slipukhina et al., 2018),
other information technologies (Markova et al., 2019;
Modlo and Semerikov, 2018) and GIS GIS (Stryzhak
et al., 2019). This research aims to develop a model
that can structure the set of the studies using IMRAD.
Previously, it was proposed to provide support us-
ing ontologies for single specific study, but not to cre-
ate glossaries and structured sets of data. To pro-
vide it tools Open provenance, Ontologyt and EXPO
(da Cruz et al., 2012) were developed. Another on-
tology solution in the field of science is MoKi that
provides creation of wiki-based information scientific
sources (Dragoni et al., 2014; Ghidini et al., 2012).
There some specific ontology tools such as Gene on-
tology (Smith, 2008) or Centralized educational en-
vironment (Stryzhak et al., 2021). However, creation
of ontology to structure the set of the studies seems
relevant due lack of approaches to provide it.
2 METHODS OF THE RESEARCH
In the paper, the ontology model has developed us-
ing the main principles of Graph Theory, Set Theory,
and a Theory of Abstraction (Giunchiglia and Walsh,
1992). The graph was modelled using a simple hier-
archical algorithm that foresees using only nodes and
links. So, such a model further may be updated using
the more comprehensive graph building tools such as
weight coefficients. However, without simple mod-
elling, providing it will not be possible. To provide
structuration generally accepted structuring method
IMRAD has been proposed and used.
To model data processing was developed taking
to account the processing possibilities of the Polyhe-
dron system due it has some advantages compare well
known Prot
´
eg
´
e (The Board of Trustees of the Leland
Stanford Junior University, 2020; Ameen et al., 2012)
and OWL tools (Sinha and Couderc, 2012; Soldatova
and King, 2006). Furthermore, the features of cog-
nitive IT-platform tools Filtering, Audit, and Rank-
ing to provide decision-making (Stryzhak et al., 2021;
Shapovalov et al., 2019a,b) were described in equi-
tations to describe the data processing in the ontology
model.
3 RESULTS AND DISCUSSION
3.1 Using IMRAD to Provide Structure
As was noted before, IMRAD is used to prepare sci-
ence papers. So, to provide structuration, it is possi-
ble to use parent nodes that represent IMRAD compo-
nents. IMRAD – Introduction, Methods, Results, and
Discussion. The discussion part can’t be structured by
Mathematical Interpretation of Educational Studentâ
˘
A
´
Zs and Scientific Studies in Form of Digital Ontologies
579
ontology because it contains the obtained data analy-
sis and comparison. That is why discussion will be
represented as the processing of the results.
(D ∈ S) =⇒ (P ∈ S) (1)
where S – study (or set of studies), D – discussion of
studies’ results, P – processing of the results of a set
of studies.
Approximate, ontology can be devoted to a spe-
cific field of science or integrate different fields. De-
pending on it, the ontology will have 5 or 4 abstract
levels of deep. In the case of general ontology, the
parent node will be “Scientific studies”, and its sub-
sidiary nodes will name a specific field. In the case
of a specific ontology, the parent node will name a
specific field. Then it links with elements of IMRAD
structure. Each element of IMRAD has its specific
representation, and it’s in turn linked with more spe-
cific for the study describing the element of IMRAD.
And the leaf node will be a set of specific studies be-
longing to the field. Let’s name each level with L
symbols taking to account position in the hierarchy:
L1 – General name of parent’s node “Scientific stud-
ies”,
L2 – Name of field of the study,
L3 – Part of IMRAD,
L4 – Specific representation of IMRAD (specific
method, used materials, specific type of the re-
sults),
L5 – Specific study where were used specific repre-
sentations of IMRAD L4.
Therefore, the hierarchy in a specific study will
have a form of {L2, L3, L4, L5} or the general ones
will have a form of {L1, L2, L3, L4, L5}. Interoper-
ability of the L2 nodes of two different graphs may be
provided by using the graph constructor. It provides
the possibility to merge graphs in two ways. The first
foresees that graphs will be constructed as a general
graph in the form of {L1, L2, L3, L4, L5} and with
the same name of L1. And the second is to create L1
in the constructor and add there two specific graphs in
the form of {L2, L3, L4, L5}. Schematic representa-
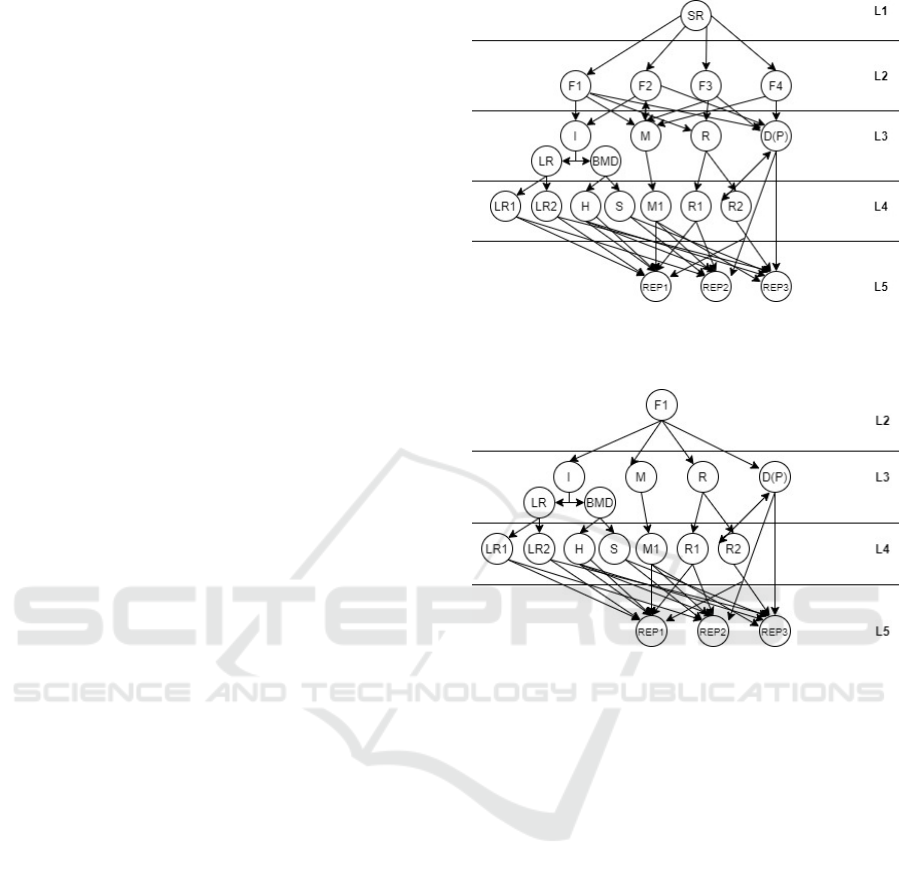
tion of the general ontology is shown in figure 2, and
taxonomy of the specific field is shown in figure 3.
An alternative and a more humanly more human-
readable way to provide abstraction are to revert this
model and begin with L5 and end with L1. In this
case, ontology will have structure form {L5, L4, L3,
L2, L1}. The graph based on the abstraction that be-
gins from specific studies L1 and ends by field of the
research is shown in figure 4.
However, the main disadvantage of such a graph
is evident and is the consequences of the structure:
Figure 2: The taxonomy of the general science report ontol-
ogy, where LR1, LR2, M1, R1, R2 – are abstract classes of
literature review (LR), Methods and results of object.
Figure 3: The taxonomy of the specific field science report
ontology.
the leaf node SR (“Scientific study”) will be not very
useful for users. Anyway, this type of graph may be
built as {L5, L4, L3} and in this case, it will be used to
evaluate the specific report, for example, during quali-
fying work evaluation (PhD or Master’s study). It will
show abstract classes of each specific part of IMRAD
for each specific study and can provide an evaluation
of the set of methods and results that the researcher
obtained. Anyway, in this research, we’ll use the first
way to provide hierarchies in the form of {L2, L3, L4,
L5}, and {L1, L2, L3, L4, L5}.
As it can be seen, the general science report ontol-
ogy is significantly more complicated due to links be-
tween L1 and L2 levels, and also, there will be some
problems with a vast amount of methods, results, etc.
that can be not necessary to the user that looking for
information on the specific field. Also, it will be much
harder to create such type of graphs due it will have
two levels of links “one to many” (see figure 2, links
between L2 and L3 level and links between L4 and
L5 levels) compare to only one in case of specific on-
tology (see figure 3, only links between L4 and L5
levels). It may be unreasonable to create a compli-
AET 2021 - Myroslav I. Zhaldak Symposium on Advances in Educational Technology
580

Figure 4: The graph based on the abstraction that begins
from specific studies L1 and ends by field of the research.
cated graph. Therefore, it seems relevant to provide
both types of hierarchies. To provide it, the ontologies
should be created in specific fields and then merged,
as noted before.
In this case, specific parts of IMRAD will be used
as subsidiaries nodes in the field of the study, and spe-
cific studies will be used as leaf nodes. So, the general
structure of such ontology may be represented as:
{I, M, R,P} ∈ REP (2)
where I – sets of Introduction of all studies, M – set
of Materials and Methods an of all studies, R – set of
Results of all studies, P – processing of the results of
a set of studies; replaces discussion; REP – report (or
set of report).
To provide better systematization and we have
split the introduction into two different parts due to
their specific – basic metadata and literature review;
it is possible to represent the introduction as further:
I = ⟨BMD, LR⟩ (3)
where BMD – is set of basic metadata of study, LR –
set of Sources used for Literature Review.
Basic metadata of the study node linked with
graph nodes that characterized the essential data on
the study, such as hypothesis, object, subject, practi-
cal value, and scientific novelty. And so, a node of
the primary report’s metadata of the study can be pre-
sented as a further equation:
BMD = ⟨H
i
, O
i
, S
i
, PV
i
, S
i
⟩ (4)
where H – hypothesis or hypotheses of each specific
study; O – object of the study; S – the subject of
each specific study; PV – practical value of each spe-
cific study; SC – the scientific novelty of each specific
study.
Each work of the set of the Introductions, Meth-
ods, Results, and Processing of the data (Discussion).
Then each work will be represented as the future:
S
I
= ⟨I
I
, M
I
, R
I
, P
I
⟩ (5)
S
II
= ⟨I
II
, M
II
, R
II
, P
II
⟩ (6)
So, these articles can be integrated into a single
ontology using IMRAD:
⟨S
I
, S
II
⟩ = ⟨I
I
, M
I
, R
I
, P
I
, I
II
, M
II
, R
II
, P
II
⟩ (7)
3.2 Using Taxonomy Nodes as Structure
of Science Data
The main advantages of using such structures are that
some parts of the introduction (for example, key-
word), materials and methods and results elements
(entities and measured parameters) of studies/report
in the same field can coincide and, in this case, such
coinciding sub-nodes will be used as links for them
and provide their interoperability. The proposed ap-
proach uses IMRAD to collect and process the data
with ontologies. In this way, the ontologies are con-
structed not by the specific structure of each work but
by the generally accepted IMRAD structure. The par-
ent node will be a specific area to which a set of the
studies belongs to (L2 =
∑
n
i
RS
Ii
, where L2 – specific
area and RS – set of the represented studies). The L2
node is linked with I, M, R, P nodes (representing IM-
RAD). Each IMRAD node is linked with a specific
node (such as ammonia determination by Nessler’s
method (for methods) or “chicken manure” or “glyc-
erine” (for subjects)) that belongs to such types. And
each specific IMRAD type is linked with leaf nodes of
ontology – specific studies where such entities were
used.
In this case, a few studies/report (REP1, REP2,
and REP3 that belong to L5) will be integrated with
some of the methods or results (M1, R1, R2 that be-
long to L4). So, the L4 level will be used to provide
the structuration of the studies (L5). The user can use
it in both ways: to find which method, result, etc.,
that belong to L4 were used in a specific report that
belongs to L5; and define in which studies belong to
L5 specific method, result, etc. that belong to L4 were
used.
The same approach will be provided for each ele-
ment of the structure. General can be represented as:
L4(M) =
n
∑
i
M
i
(8)
where M
i
– every separated scientific method.
Case of coinciding of the methods may be repre-
sented as single mortises of methods of each study:
M
I
= {M
a
, M
b
, M
c
, M
d
} (9)
M
II
= {M
b
, M
d
, M
f
} (10)
Therefore, in this case, M
b
can be used as a parent
node that connects two different studies. The node
Mathematical Interpretation of Educational Studentâ
˘
A
´
Zs and Scientific Studies in Form of Digital Ontologies
581

M
b
itself will contain general theoretic information on
it, and node S
I
and S
II
will contain information on
the specific case of its usage and measured parameters
using it.
Also, for example, there will be a hierarchical way
of representing and using the keywords:
K
w
(BMD
i
) = Kw
a
Kw
b
, Kw
c
, Kw
d
(11)
where K
w
(BMD
i
) – node of the basic metadata that
integrates all keywords; Kw
i
– specific keyword of
the specific research.
In this case, some of the studies, same as for the
methods, Kw
i
will be elements of two different stud-
ies (Kw
a
, Kw
c
∈ S
I
, S
II
). This will be useful, espe-
cially for students and young scientists looking to find
methods (M
I
) and parameters that can be used in spe-
cific fields and their usage in practice. Also, this way
provides a list of the parameters and methods used in
specific fields.
3.3 Metadata Processing
The metadata of each work will be used for pro-
cessing the data. It may be included for each node.
For example, metadata of L4 nodes will represent the
general information (for example, the essence of the
method itself), and the resulting leaf nodes will con-
tain the specific metadata related to a specific study
(such as specific results of the study obtained using
set methods M; for example, metadata: “5,35”, and
it’s class: “Ammonium nitrogen content, g/l). And
so, metadata with the same class will be processed by
filtering by users’ request or by ranking by providing
the rank of nodes by specific class (or their set) based
on the user’s request. So, each node located on each
level E
i
contains metadata with the abstract level that
corresponds to several levels; for level 1st – it will be
the most abstract metadata, and for 5th – it will be the
most specific.
As can be seen, all data in levels L1-L4 contains
generalized metadata and wouldn’t be used to process
specific study, but just used to get generalized abstract
information on entities used in specific fields. Only
the L5 level contains metadata related to a specific
study and will be used for further processing.
3.4 Using Metadata to Provide Data
Processing
Specific mechanisms “Filtering”, “AUDIT” and
“RANK” of cognitive IT solution Polyhedron are
used to provide processing of the information. It will
be used for the case when different studies will have
the same Class and Type of information, but different
values:
{Class : C1; Type : Number;Value : V 1} ∈ REP1 (12)
{Class : C1; Type : Number;Value : V 2} ∈ REP2 (13)
{Class : C1; Type : Number;Value : V 3} ∈ REP3 (14)
And the values V
1
,V
2
,V
3
can be equal or not equal.
Anyway “Filtering”, “AUDIT” and “RANKING” can
be used to process the data. Filtering can be described
by function if:
If (V
min
< V < V
max
) then (display nodes with such
V)
or
If (V = V
set
) then (display nodes with such V)
where Vmin, Vmax, Vset are maximum, minimum,
and given (set) values, respectively, that inputted by
the user.
The function of AUDIT can also be described as a
function if:
If (V
i
= V
set
) than (mark red such V
i
); for each V
i
.
The ranking is much more complicated and can be
described as:
RANK
abs(i)
=
∑
(OR
i
× IMP
i
×
V
i
V
max
) (15)
where RANK
abs(i)
– ranking rank in absolute value for
i’s node OR
i
– orientation maximum or minimum for
metadata of i’s object (can be +1 or -1); IMP
i
– im-
portance coefficient for metadata of i’s object; V
i
–
the value of metadata of i’s object; V
max
– maximum
value of the set of metadata.
RANK
i
=
RANK
(abs(i)
RANK
max
(16)
where RANK
i
– the relative value of the rank (can be
maximum =1) of each object; RANK
max
– the maxi-
mum value of the RANK for all sets of objects.
3.5 Formalization Description
The object of formalization is specific scientific stud-
ies. The result of formalization is a specialized
research-oriented subject area formed precisely from
existing research and allows to familiarize with the
specialized subject area. Any research essentially has
the same components (which are proposed to be sys-
tematized in the form of graphs) – introduction (land-
scape, object of research, subject of research, nov-
elty, etc.), methods (a set of methods that ensures the
achievement of a scientific result or measurement),
specific achievements and results (e.g., systems and
approaches developed or metrics) and discussion. All
components except the last one can be formalized us-
ing the IMRAD approach in such a way that they form
an ontology of the subject area of a specific field of re-
search. Discussion, in its essence, is finding the place
AET 2021 - Myroslav I. Zhaldak Symposium on Advances in Educational Technology
582

Table 1: Description of the metadata on each ontology of proposed ontology model.
MD(L1) no metadata
MD(L2) {Class: Information about the field; Type: String; Value: Description}
MD(L3) [MD(LR); MD(BMS); MD(M); MD(R)]= LR, BMS, M, R{Class: General information;
Type: String; Value: Describing and detailing of meaning results, methods, literature re-
view, etc.}
MD(L4)
∑
[MD(LR
i
);MD(BMS
i
);{ MD(M
i
);MD(R
i
)] = { Class: Essence of the name (specific
method, results, etc.; Type: String; Value: Describing of way of providing or specific mea-
sured parameter}
MD(L5)
∑
{Class: all metadata of specific study; Type: Number or String; Value: Text or number}
of this research in the system of scientific research –
that is, it is the process of comparing the results of re-
search, numerical and other data with existing other
data and providing explanations of the differences of
this specific stud. In fact, such processing is provided
by the ranking tools and the CIT Polyhedron alterna-
tive.
4 DISCUSSION
4.1 Case of Usage: An Example on
Biogas Production
So, for the specific case of biogas production studies
(Ivanov et al., 2019; Shapovalov et al., 2020a; Plyat-
suk and Chernish, 2014; Bochmann et al., 2020), it
seems relevant to use ontology for a specific field (in
the form of {L2, L3, L4, L5}). In this case, a node
in the L2 line will be single and named “Studies on
anaerobic digestion”. It will be linked with nodes In-
troduction, Methods, Results, and Processing. As for
all other cases, Introduction will be divided into Basic
Metadata and Literature review (L3 level).
Basic Metadata will be linked with nodes Ob-
jects, Subjects, Aims, Practical Value, Scientific nov-
elty, Hypothesis, Keywords, Abstract, Conclusion
(L3 level).
Each of these nodes will be connected with spe-
cific nodes relevant to the set of the structured studies
(L4 level). Each specific L3 will have metadata with
general information on the described object. So, an
example of values of metadata in the “Basic meta-
data” elements node in the L4 level is shown in ta-
ble 2.
*verbs “are defined” or “has provided” etc. and
articles “the”, “a” and “an” aren’t use due to their
huge vitiation and to provide better structuration and
to have more coincidences between nodes and meta-
data
Each such node will be connected with the study
where it was used (L5 level). For example, “Biogas
production from the poultry waste” or “Utilization of
the meat production wastewater using anaerobic di-
gestion”.
The Literature review node (L4 level) will be con-
nected with specific studies used in a set of studies.
Its name will be the name of the study (paper, ar-
ticle, conference processing, thesis, etc.), similar to
the name of the study used to provide structuration
with the addition of the publishing year. For exam-
ple, it can be named “Utilization of the meat produc-
tion wastewater using anaerobic digestion, 2011”. In
addition, each such node should be connected to one
of the few studies used to provide structuration (L5
level).
The most useful will be Methods and Results
nodes. They will be helpful to students and youth sci-
entists who want to be familiar with methods used in
the field and set the measured parameters used in the
field of science. Sure, the established scholars will
use such a tool too to increase outlook. The Materi-
als and Methods node will be divided into Methods,
Equipment, and Materials. An example of material
and methods and results nodes, their links and meta-
data are presented in table 3.
Each such subsidiary node is connected with a leaf
node that is a specific study. For example, the Pro-
cessing node has metadata with type link and its value
in the form of a link to Audit and Ranking tools for
the structured set of studies. Detailed algorithms of
its usage are described before.
Each work has metadata that mostly duplicates the
structure. For this, all numeric and semantic data of
the works is added to a node of the specific work it be-
longs to. Examples of the metadata of the leaf nodes
are presented in the table. It is foreseen to provide
automatically. For example, it will be necessary to
provide filtering, Audit, and ranking. An example of
metadata and its classes (subclasses) of the specific
report node is shown in table 4.
Mathematical Interpretation of Educational Studentâ
˘
A
´
Zs and Scientific Studies in Form of Digital Ontologies
583

Table 2: An example of “Basic metadata” elements nodes in L3 level and linked with them nodes in L4 level.
Parent’s node
(L3)
Metadata of the par-
ent’s node
Linked nodes (L4)
Objects
General
definition
of the
elements
of basic
metadata
“biogas production”, “inhibition”, “waste utilization”
Subjects “Effect of ammonium nitrogen content on biogas production”, “Opti-
mization of the process of waste treatment by optimization of the waste
destruction rate”
Aims “Provide mathematical modeling of the anaerobic digestion of high-
ammonium waste”, “Define of influence of the addition of spirulina to
the process of anaerobic treatment of straw”
Practical
Value
“Main kinetic parameters of the anaerobic digestion”, “Model of am-
monia effect on the anaerobic digestion”
Scientific
novelty
“Relation between ammonia content and biogas production”
Hypothesis
Keywords “Straw”, “Sludge”, “Meat wastewater”, “Biogas”, “Methane”, “Ammo-
nium nitrogen”
Abstract –
Conclusion –
Table 3: An example of material and methods and results nodes links and metadata
Parent’s node Metadata of the father’s
node (type: text)
Linked subsidiary nodes Metadata
Methods General information what is
methods
“Dry organic matter by frying”,
“Methane content in biogas using
gas chromatography”, “Free acid
content by titrimetric method”
Methodology of using of
each specific method (type:
text)
Equipment General information what is
equipment
“Digital microscope”, “Burette”,
“Gas chromatograph”
Description of each spe-
cific equipment (type: array)
Link to ontology of the
equipment (type: text)
Materials General information what is
material
“Straw”, “Sludge”, “Meat wastew-
ater”, “Water”
Description of each specific
materials (type: text)
Results General information what is
results
“Biogas”, “Methane”, “Ammonium
nitrogen”
Description of each mea-
sured parameter (type: text)
4.2 Role of the Proposed Model
Ontology models are the basis of the effective ontol-
ogy creative process. Such models like proposed and
others (for example, ontologies of educational envi-
ronments, will be useful to build a set of the differ-
ent ontologies and have similar conceptual states of
abstraction. Using such approaches and providing se-
mantic technologies can be useful to provide interop-
erability (Alnemr et al., 2010).
Sure, the proposed research focused on the on-
tology of the specific field in the form of {L2, L3,
L4, L5}, but it is proposed to use an integrator of
the ontologies of fields and create general ontology
in the form of {L1, L2, L3, L4, L5}. The proposed
integration is important to provide transdisciplinary
(Dovgyi and Stryzhak, 2021). The proposed approach
will be useful and relevant for most fields. Anyway,
it will be very specific to process humanitarian data
where less standardization and numeric data, but it
seems that some automated tools like recursive re-
ducer (Stryzhak et al., 2018) can process and provide
structuration even in such fields.
4.3 Perspectives of Development
Currently, the proposed approach has a few user sto-
ries implemented by the proposed model. They are
helpful for all scientists, but as the development of
the proposed model was provided in the Navigational
center Of Junior Academy of Sciences of Ukraine,
it has much more advantages for youth students in-
volved in activities of the organization. The mathe-
matical interpretation of educational students and sci-
AET 2021 - Myroslav I. Zhaldak Symposium on Advances in Educational Technology
584
Table 4: An example of metadata and its classes (subclasses) of the specific report node.
Name of class Name of subclass Type Values example
Methods – Array “Dry organic matter by frying”, “Methane
content in biogas using gas chromatog-
raphy”, “Free acid content by titrimetric
method”
Results
Biogas content, ml/ g TS Number “305.15”
Methane content, % Number “55”
Ammonium nitrogen content, g/l Number “3.6”
Materials
Straw/TS content, % Number “95”
Straw/Ammonium nitrogen content, g/l Number “0.3”
Sludge/TS content, % Number “0.05”
Main metadata Keywords Array “Straw”, “Sludge”, “Meat wastewater”,
“Biogas”, “Methane”, “Ammonium nitro-
gen”
entific studies in the form of digital ontologies pro-
vides the possibility to easily manage information of
science studies to simplify finding of relevant studies
and simplify familiarization process with some spe-
cific subject area.
The proposed approach
1) allows very quickly (especially for a young sci-
entist) to research the subject field related to this
field of research by using → Introduction → Key-
words (contains the main terms of the subject field
of specific research) and other components of the
Introduction (for example, scientific novelty for-
mulates the directions of research, which formu-
lates relevant research directions);
2) allows to process numerical research data using
the ranking tool and find such works that are nec-
essary for research;
3) allows you to quickly familiarize with the existing
research methods used in this field → Methods;
4) allows to quickly familiarize with the indicators
used in research in a specific field (→ Results)
Communication with L5 vertices is essential be-
cause it is he who forms the novelty (since the ap-
proaches to the ontological display of subject area
have been known for a long time);
5) allows the researcher/student (young scientist) to
quickly find practical examples where this or that
element of research is used – for example, quickly
find all works where ammonia was measured us-
ing the Nessler method or works where graph the-
ory was used.
In addition, this approach has the potential for de-
velopment, which is as follows:
• the possibility of providing scientometrics based
on ontologies (similar to scientific databases) –
since it is possible to calculate how many times
a particular work has been referred to due to the
connections in such a taxonomy;
• the possibility of interoperability providing with
educational programs;
• the possibility of adding one’s own research for a
few clicks to the general ontology.
5 CONCLUSIONS
It is firstly proposed the model of ontology based on
IMRAD to provide a set of different studies that be-
long to the same field and to provide generation of
the integrated ontology that collected the data of dif-
ferent fields. Using such a method will provide both
structuration of the set of studies by using specific ele-
ments of IMRAD that belongs to the set of the studies
of the same field and processing such studies’ data.
A specific case of usage is shown in the example
creation of such ontology in the field of biogas pro-
duction. It is shown in both model and example using
single sets of keywords, results, methods, etc., to pro-
vide structuring and data processing.
It seems relevant to provide additional further
studies of the proposed model to improve it and make
it even more automatized, for example, by using
weight mechanisms.
The proposed approach in case of providing prop-
erty infrastructure and widespread will provide inter-
operability of data located in papers. Therefore, it will
simplify providing of scitintific studies and simplify
determination of relevance and practic value of scien-
tific works. To provide such interoperability graphs
of specific fields should be created and proivded their
further merging. So, the onotologies type {L2, L3,
L4, L5} must be integrated into single one with form
of {L1, L2, L3, L4, L5}.
Mathematical Interpretation of Educational Studentâ
˘
A
´
Zs and Scientific Studies in Form of Digital Ontologies
585

REFERENCES
Alnemr, R., Paschke, A., and Meinel, C. (2010). Enabling
Reputation Interoperability through Semantic Tech-
nologies. In Proceedings of the 6th International Con-
ference on Semantic Systems, I-SEMANTICS ’10,
New York, NY, USA. Association for Computing Ma-
chinery. https://doi.org/10.1145/1839707.1839723.
Ameen, A., Khan, K. U. R., and Rani, B. P. (2012). Cre-
ation of Ontology in Education Domain. In 2012 IEEE
Fourth International Conference on Technology for
Education, pages 237–238. https://doi.org/10.1109/
T4E.2012.50.
Bochmann, G., Pesta, G., Rachbauer, L., and Gabauer,
W. (2020). Anaerobic Digestion of Pretreated Indus-
trial Residues and Their Energetic Process Integra-
tion. Frontiers in Bioengineering and Biotechnology,
8. https://doi.org/10.3389/fbioe.2020.00487.
Bovtruk, A., Slipukhina, I., Mieniailov, S., Chernega, P.,
and Kurylenko, N. (2020). Development of an elec-
tronic multimedia interactive textbook for physics
study at technical universities. In Bollin, A., Mayr,
H. C., Spivakovsky, A., Tkachuk, M. V., Yakovyna,
V., Yerokhin, A., and Zholtkevych, G., editors, Pro-
ceedings of the 16th International Conference on ICT
in Education, Research and Industrial Applications.
Integration, Harmonization and Knowledge Transfer.
Volume I: Main Conference, Kharkiv, Ukraine, Octo-
ber 06-10, 2020, volume 2740 of CEUR Workshop
Proceedings, pages 159–172. CEUR-WS.org. https:
//ceur-ws.org/Vol-2740/20200159.pdf.
da Cruz, S. M. S., Campos, M. L. M., and Mattoso,
M. (2012). A Foundational Ontology to Support
Scientific Experiments. In Malucelli, A. and Bax,
M. P., editors, Proceedings of Joint V Seminar on
Ontology Research in Brazil and VII International
Workshop on Metamodels, Ontologies and Seman-
tic Technologies, Recife, Brazil, September 19-21,
2012, volume 938 of CEUR Workshop Proceedings,
pages 144–155. CEUR-WS.org. https://ceur-ws.org/
Vol-938/ontobras-most2012 paper12.pdf.
Dovgyi, S. and Stryzhak, O. (2021). Transdisciplinary
Fundamentals of Information-Analytical Activity. In
Ilchenko, M., Uryvsky, L., and Globa, L., editors,
Advances in Information and Communication Tech-
nology and Systems, volume 152 of Lecture Notes
in Networks and Systems, pages 99–126, Cham.
Springer International Publishing. https://doi.org/10.
1007/978-3-030-58359-0 7.
Dragoni, M., Bosca, A., Casu, M., and Rexha, A. (2014).
Modeling, Managing, Exposing, and Linking On-
tologies with a Wiki-based Tool. In Proceedings
of the Ninth International Conference on Language
Resources and Evaluation (LREC’14), pages 1668–
1675, Reykjavik, Iceland. European Language Re-
sources Association (ELRA). http://www.lrec-conf.
org/proceedings/lrec2014/pdf/769 Paper.pdf.
Ghidini, C., Rospocher, M., and Serafini, L. (2012). Con-
ceptual Modeling in Wikis: a Reference Architec-
ture and a Tool. In Proceedings of the 4th Inter-
national Conference on Information, Process, and
Knowledge Management (eKNOW 2012), pages 128–
135. https://www.thinkmind.org/index.php?view=
article&articleid=eknow 2012 6 10 60015.
Giunchiglia, F. and Walsh, T. (1992). A theory of abstrac-
tion. Artificial Intelligence, 57(2):323–389. https:
//doi.org/10.1016/0004-3702(92)90021-O.
Globa, L., Kovalskyi, M., and Stryzhak, O. (2015). In-
creasing Web Services Discovery Relevancy in the
Multi-ontological Environment. In Wili
´
nski, A., Fray,
I. E., and Peja
´
s, J., editors, Soft Computing in Com-
puter and Information Science, volume 342 of Ad-
vances in Intelligent Systems and Computing, pages
335–344, Cham. Springer International Publishing.
https://doi.org/10.1007/978-3-319-15147-2 28.
Globa, L. S., Sulima, S., Skulysh, M. A., Dovgyi, S., and
Stryzhak, O. (2019). Architecture and Operation Al-
gorithms of Mobile Core Network with Virtualization.
In Ortiz, J. H., editor, Mobile Computing, Rijeka. In-
techOpen. https://doi.org/10.5772/intechopen.89608.
Gorashy, Z. and Salim, N. (2014). Systematic literature
review (SLR) automation: A systematic literature re-
view. Journal of Theoretical and Applied Information
Technology, 59(3):661–672.
Gruber, M., Eichst
¨
adt, S., Neumann, J., and Paschke, A.
(2020). Semantic Information in Sensor Networks:
How to Combine Existing Ontologies, Vocabularies
and Data Schemes to Fit a Metrology Use Case. In
2020 IEEE International Workshop on Metrology for
Industry 4.0 & IoT, pages 469–473. https://doi.org/10.
1109/MetroInd4.0IoT48571.2020.9138282.
Hrynevych, L., Morze, N., Vember, V., and Boiko, M.
(2021). Use of digital tools as a component of STEM
education ecosystem. Educational Technology Quar-
terly, 2021(1):118–139. https://doi.org/10.55056/etq.
24.
Ivanov, V., Stabnikov, V., Stabnikova, O., Salyuk, A.,
Shapovalov, E., Ahmed, Z., and Tay, J. H. (2019).
Iron-containing clay and hematite iron ore in slurry-
phase anaerobic digestion of chicken manure. AIMS
Materials Science, 6(5):821–832. https://doi.org/10.
3934/matersci.2019.5.821.
Klampfl, S., Granitzer, M., Jack, K., and Kern, R. (2014).
Unsupervised document structure analysis of digital
scientific articles. International Journal on Digi-
tal Libraries, 14(3):83–99. https://doi.org/10.1007/
s00799-014-0115-1.
Markova, O. M., Semerikov, S. O., Striuk, A. M., Sha-
latska, H. M., Nechypurenko, P. P., and Tron, V. V.
(2019). Implementation of cloud service models in
training of future information technology specialists.
CTE Workshop Proceedings, 6:499–515. https://doi.
org/10.55056/cte.409.
Martyniuk, O. O., Martyniuk, O. S., Pankevych, S.,
and Muzyka, I. (2021). Educational direction of
STEM in the system of realization of blended teach-
ing of physics. Educational Technology Quarterly,
2021(3):347–359. https://doi.org/10.55056/etq.39.
Mintser, O. P., Pryhodnyuk, V. V., Stryzhak, O. Y., and
Shevtsova, O. M. (2018). Transdisciplinary report-
ing of information with interactive documents. Med-
AET 2021 - Myroslav I. Zhaldak Symposium on Advances in Educational Technology
586

ical Informatics and Engineering, (1):47–52. https:
//doi.org/10.11603/mie.1996-1960.2018.1.8891.
Modlo, Y. O. and Semerikov, S. O. (2018). Xcos on Web as
a promising learning tool for Bachelor’s of Electrome-
chanics modeling of technical objects. CTE Work-
shop Proceedings, 5:34–41. https://doi.org/10.55056/
cte.133.
Oriokot, L., Buwembo, W., Munabi, I. G., and Kijjambu,
S. C. (2011). The introduction, methods, results and
discussion (IMRAD) structure: a Survey of its use
in different authoring partnerships in a students’ jour-
nal. BMC Research Notes, 4(1):250. https://doi.org/
10.1186/1756-0500-4-250.
Pardede, P. (2012). Scientific Articles Structure. In
Scientific Writing Workshop, The English Teaching
Study Program of the Christian University of Indone-
sia (UKI), April 29—May 27, 2012. https://www.
researchgate.net/publication/260453687.
Paschke, A. and Sch
¨
afermeier, R. (2018). OntoMaven -
Maven-Based Ontology Development and Manage-
ment of Distributed Ontology Repositories. In Nalepa,
G. J. and Baumeister, J., editors, Synergies Between
Knowledge Engineering and Software Engineering,
pages 251–273, Cham. Springer International Pub-
lishing. https://doi.org/10.1007/978-3-319-64161-4
12.
Plyatsuk, L. and Chernish, E. (2014). Intensification of
Anaerobic Microbiological Degradation of Sewage
Sludge and Gypsum Waste Under Bio-Sulfidogenic
Conditions. The Journal of Solid Waste Technology
and Management, 40(1):10–23. https://doi.org/10.
5276/JSWTM.2014.10.
Portenoy, J. and West, J. D. (2020). Constructing and eval-
uating automated literature review systems. Sciento-
metrics, 125(3):3233–3251. https://doi.org/10.1007/
s11192-020-03490-w.
Sch
¨
afermeier, R., Herre, H., and Paschke, A. (2021). On-
tology Design Patterns for Representing Context in
Ontologies Using Aspect Orientation. In Blomqvist,
E., Hahmann, T., Hammar, K., Hitzler, P., Hoekstra,
R., Mutharaju, R., Poveda-Villal
´
on, M., Shimizu, C.,
Skjæveland, M. G., Solanki, M., Sv
´
atek, V., and Zhou,
L., editors, Advances in Pattern-Based Ontology En-
gineering, extended versions of the papers published
at the Workshop on Ontology Design and Patterns
(WOP), volume 51 of Studies on the Semantic Web,
pages 183–203. IOS Press. https://doi.org/10.3233/
SSW210014.
Shakeel, Y., Kr
¨
uger, J., von Nostitz-Wallwitz, I., Laus-
berger, C., Durand, G. C., Saake, G., and Leich, T.
(2018). (Automated) Literature Analysis: Threats
and Experiences. In Proceedings of the Interna-
tional Workshop on Software Engineering for Sci-
ence, SE4Science ’18, page 20–27, New York, NY,
USA. Association for Computing Machinery. https:
//doi.org/10.1145/3194747.3194748.
Shapovalov, V. B., Shapovalov, Y. B., Bilyk, Z. I., Ata-
mas, A. I., Tarasenko, R. A., and Tron, V. V. (2019a).
Centralized information web-oriented educational en-
vironment of Ukraine. CTE Workshop Proceedings,
6:246–255. https://doi.org/10.55056/cte.383.
Shapovalov, Y., Zhadan, S., Bochmann, G., Salyuk, A.,
and Nykyforov, V. (2020a). Dry anaerobic diges-
tion of chicken manure: A review. Applied Sciences,
10(21):7825. https://doi.org/10.3390/app10217825.
Shapovalov, Y. B., Shapovalov, V. B., Andruszkiewicz, F.,
and Volkova, N. P. (2020b). Analyzing of main trends
of STEM education in Ukraine using stemua.science
statistics. CTE Workshop Proceedings, 7:448–461.
https://doi.org/10.55056/cte.385.
Shapovalov, Y. B., Shapovalov, V. B., and Zaselskiy, V. I.
(2019b). TODOS as digital science-support environ-
ment to provide STEM-education. CTE Workshop
Proceedings, 6:235–245. https://doi.org/10.55056/
cte.382.
Sinha, A. and Couderc, P. (2012). Using OWL ontologies
for selective waste sorting and recycling. In Klinov,
P. and Horridge, M., editors, Proceedings of OWL:
Experiences and Directions Workshop 2012, Herak-
lion, Crete, Greece, May 27-28, 2012, volume 849 of
CEUR Workshop Proceedings. CEUR-WS.org. https:
//ceur-ws.org/Vol-849/paper 16.pdf.
Slipukhina, I. A., Olkhovyk, V. V., Kurchev, O. O., and
Kapranov, V. D. (2018). Development of education
and information portal of physics academic course:
Web design features. Information Technologies and
Learning Tools, 64(2):221–233. https://doi.org/10.
33407/itlt.v64i2.1781.
Smith, B. (2008). Ontology (Science). Nature Precedings.
https://doi.org/10.1038/npre.2008.2027.1.
Soldatova, L. N. and King, R. D. (2006). An ontology of
scientific experiments. Journal of The Royal Soci-
ety Interface, 3(11):795–803. https://doi.org/10.1098/
rsif.2006.0134.
Stryzhak, O., Horborukov, V., Prychodniuk, V., Franchuk,
O., and Chepkov, R. (2021). Decision-making System
Based on The Ontology of The Choice Problem. Jour-
nal of Physics: Conference Series, 1828(1):012007.
https://doi.org/10.1088/1742-6596/1828/1/012007.
Stryzhak, O., Prychodniuk, V., and Podlipaiev, V.
(2019). Model of Transdisciplinary Representation of
GEOspatial Information. In Ilchenko, M., Uryvsky,
L., and Globa, L., editors, Advances in Informa-
tion and Communication Technologies, volume 560
of Lecture Notes in Electrical Engineering, pages 34–
75, Cham. Springer International Publishing. https:
//doi.org/10.1007/978-3-030-16770-7 3.
Stryzhak, O. Y., Prykhodniuk, V. V., Haiko, S. I., and
Shapovalov, V. B. (2018). Vidobrazhennia merezhevoi
informatsii u vyhliadi interaktyvnykh dokumentiv.
Transdystsyplinarnyi pidkhid. Matematychne modeli-
uvannia v ekonomitsi, (3):87–100. http://nbuv.gov.ua/
UJRN/mmve 2018 3 10.
Stryzhak, O. Y., Slipukhina, I. A., Polikhun, N. I., and
Chernetckiy, I. S. (2017). STEM-education: Main
definitions. Information Technologies and Learn-
ing Tools, 62(6):16–33. https://doi.org/10.33407/itlt.
v62i6.1753.
The Board of Trustees of the Leland Stanford Junior Uni-
versity (2020). prot
´
eg
´
e. https://protege.stanford.edu/
products.php.
Mathematical Interpretation of Educational Studentâ
˘
A
´
Zs and Scientific Studies in Form of Digital Ontologies
587
