
Hear Me out: Fusional Approaches for Audio Augmented Temporal
Action Localization
Anurag Bagchi
1 a
, Jazib Mahmood
1 b
, Dolton Fernandes
1 c
and Ravi Kiran Sarvadevabhatla
2 d
1
International Institute of Information Technology, Hyderabad, India
2
Center for Visual Information Technology (CVIT), IIIT Hyderabad, India
Keywords:
Temporal Activity Localization, Graph Convolution Networks, Multi-modal Fusion, Audio.
Abstract:
State of the art architectures for untrimmed video Temporal Action Localization (TAL) have only considered
RGB and Flow modalities, leaving the information-rich audio modality unexploited. Audio fusion has been
explored for the related but an arguably easier problem of trimmed (clip-level) action recognition. However,
TAL poses a unique set of challenges. In this paper, we propose simple but effective fusion-based approaches
for TAL. To the best of our knowledge, our work is the first to jointly consider audio and video modalities for
supervised TAL. We experimentally show that our schemes consistently improve performance for the state-
of-the-art video-only TAL approaches. Specifically, they help achieve a new state-of-the-art performance on
large-scale benchmark datasets - ActivityNet-1.3 (54.34 mAP@0.5) and THUMOS14 (57.18 mAP@0.5). Our
experiments include ablations involving multiple fusion schemes, modality combinations, and TAL architec-
tures. Our code, models, and associated data are available at https://github.com/skelemoa/tal-hmo.
1 INTRODUCTION
With the boom in online video production, video
understanding has become one of the most heavily
researched domains. Temporal Action Localization
(TAL) is one of the most interesting and challenging
problems in the domain. The objective of TAL is to
identify the category (class label) of activities present
in a long, untrimmed, real-world video and their tem-
poral boundaries (start and end time). Apart from in-
heriting the challenges from the related problem of
trimmed (clip-level) video action recognition, TAL
also requires accurate temporal segmentation, i.e. to
precisely locate the start time and end time of action
categories present in a given video.
TAL is an active area of research and several
approaches have been proposed to tackle the prob-
lem (Xu et al., 2020b; Zeng et al., 2019b; Alwassel
et al., 2020; Liu et al., 2021; Liu et al., 2021; Lin
et al., 2021). For the most part, existing approaches
depend solely on the visual modality (RGB, Optical
Flow). An important and obvious source of additional
a
https://orcid.org/0000-0002-9893-9643
b
https://orcid.org/0000-0002-0076-1315
c
https://orcid.org/0000-0002-8926-1156
d
https://orcid.org/0000-0003-4134-1154
information – the audio modality – has been over-
looked. This is surprising since audio has been shown
to be immensely useful for other video-based tasks
such as object localization (Arandjelovic and Zisser-
man, 2017), action recognition (Owens and Efros,
2018; Wu et al., 2016; Long et al., 2018b; Long et al.,
2018a; Owens et al., ) and egocentric action recogni-
tion (Kazakos et al., 2019).
Analyzing the untrimmed videos, it is evident that
the audio track provides crucial complementary infor-
mation regarding the action classes and their temporal
extents. Action class segments in untrimmed videos
are often characterized by signature audio transitions
as the activity progresses (e.g. the rolling of a ball
in a bowling alley culminating in striking of pins, an
aquatic diving event culminating with the sound of a
splash in the water). Depending on the activity, the
associated audio features can supplement and com-
plement their video counterparts if the two feature se-
quences are fused judiciously (Figure 1).
Motivated by the observations mentioned above,
we make the following contributions:
• We propose simple but effective fusion ap-
proaches to combine audio and video modalities
for TAL (Section 3). Our work is the first to
jointly process audio and video modalities for su-
pervised TAL.
144
Bagchi, A., Mahmood, J., Fernandes, D. and Sarvadevabhatla, R.
Hear Me out: Fusional Approaches for Audio Augmented Temporal Action Localization.
DOI: 10.5220/0010832700003124
In Proceedings of the 17th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2022) - Volume 5: VISAPP, pages
144-154
ISBN: 978-989-758-555-5; ISSN: 2184-4321
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

Ground Truth
Visual prediction
Audio prediction
Fusion prediction
2:59 sec Bowling 3:17 sec
2:55 sec Bowling 3:19 sec
3:00 sec Bowling 3:18 sec
2:58 sec Bowling 3:20 sec1:48 sec Bowling 2:10 sec
1:48 sec Having a conversation 2:59 sec
1:48 sec Having a conversation 2:59 sec
1:48 sec Having a conversation 3:00 sec
1:48 sec Having a conversation 2:55 sec
Having a conversation
Figure 1: An example illustrating a scenario where audio modality can help improve peformance over video-only temporal
action localization.
• We show that our fusion schemes can be readily
plugged into existing state-of-the-art video-based
TAL pipelines (Section 3).
• To determine the efficacy of our fusional ap-
proaches, we perform a comparative evaluation
on large-scale benchmark datasets - ActivityNet
and THUMOS14. Our results (Section 6) show
that the proposed schemes consistently boost per-
formance for the state-of-the-art TAL approaches,
resulting in an improved mAP of 52.73 for
ActivityNet-1.3 and 57.18 mAP for THUMOS14.
• Our experiments include ablations involving mul-
tiple fusion schemes, modality combinations, and
TAL architectures.
Our code, models, and associated data are avail-
able at https://github.com/skelemoa/tal-hmo.
2 RELATED WORK
Temporal Action Localization: A popular tech-
nique for Temporal Action Localization is inspired
from the proposal-based approach for object detec-
tion (Girshick, 2015). In this approach, a set of so-
called proposals are generated and subsequently re-
fined to produce the final class and boundary predic-
tions. Many recent approaches employ this proposal-
based formulation (Shou et al., 2016; Zhao et al.,
2017; Xu et al., 2017). Specifically, this is the case
for state-of-the-art approaches we consider in this pa-
per – G-TAD (Xu et al., 2020b), PGCN (Zeng et al.,
2019b) and MUSES baseline (Liu et al., 2021). Both
G-TAD (Xu et al., 2020b) and PGCN (Zeng et al.,
2019b) use graph convolutional networks and the con-
cept of edges to share context and background in-
formation between proposals. MUSES baseline (Liu
et al., 2021) on the other hand, achieves the state-
of-the-art results on the benchmark datasets by em-
ploying a temporal aggregation module, originally in-
tended to account for the frequent camera changes in
their new multi-shot dataset.
The proposal generation schemes in the literature
are either anchor-based (Gao et al., 2017; Gao et al.,
2018; Liu et al., 2018) or generate a boundary prob-
abilty sequence (Lin et al., 2018; Lin et al., 2019;
Su et al., 2020). Past work in this domain also in-
cludes end to end techniques (Buch et al., 2019; Ye-
ung et al., 2015; Lin et al., 2017) which combine
the two stages. Frame-level techniques which require
merging steps to generate boundary predictions also
exist (Shou et al., 2017; Montes et al., 2016; Zeng
et al., 2019a). We augment the proposal-based state of
the art approaches designed solely for visual modality
by incorporating audio into their architectures.
Audio-only based Localization: Speaker diariza-
tion (Wang et al., 2018; Zhang et al., 2019) involves
localization of speaker boundaries and grouping seg-
ments that belong to the same speaker. The DCASE
Challenge (Ono et al., 2020) examines sound event
detection in domestic environments as one of the chal-
lenge tasks (Miyazaki et al., 2020; Hao et al., 2020;
Ebbers and Haeb-Umbach, 2020; Lin and Wang,
2019; Delphin-Poulat and Plapous, 2019; Shi, 2019).
In our action localization setting, note that the audio
modality is unrestricted. It is not confined to speech
or labeled sound events which is the case for audio-
only localization.
Audio-visual Localization: This task is essen-
tially localization of specific events of interest across
modalities. Given a temporal segment of one modal-
ity (auditory or visual), we would like to localize
the temporal segment of the associated content in the
other modality. This is different from our task of tem-
poral action localization (TAL) which focuses on pre-
dicting the class labels and temporal segment bound-
aries of all actions present in a given video.
Fusion Approaches for TAL: Fusion of multiple
modalities is an effective technique for video under-
standing tasks due to its ability to incorporate all the
information available in videos. The fusion schemes
Hear Me out: Fusional Approaches for Audio Augmented Temporal Action Localization
145
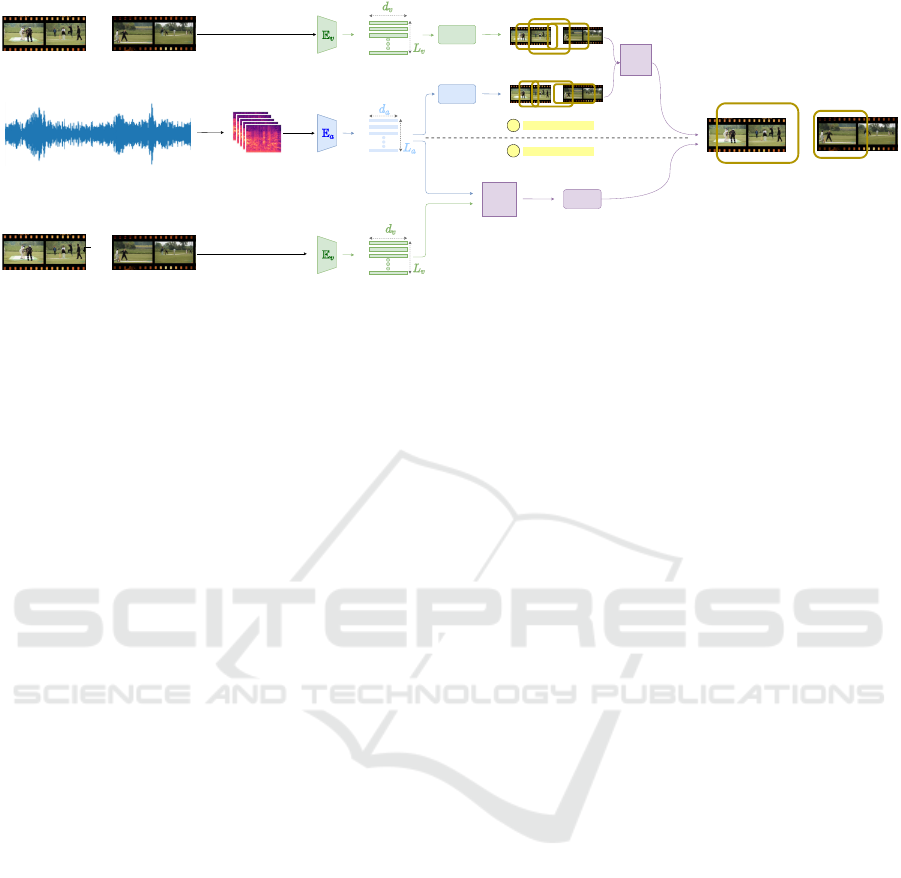
PG/R
PG/R
Proposal
Fusion
PG/R
Encoding
Fusion
PROPOSAL FUSION
ENCODING FUSION
A
B
Final Proposals
...
...
Untrimmed Video
...
...
...
...
Untrimmed Audio
Untrimmed Video
Figure 2: An illustrative overview of our fusion schemes (Section 3).
present in the literature can be divided into 3 broad
categories – early fusion, mid fusion and late fusion.
Late fusion combines the representations closer to
the output end from each individual modality stream.
When per-modality predictions are fused, this tech-
nique is also referred to as decision level fusion. De-
cision level fusion is used in I3D (Carreira and Zis-
serman, 2017) which serves as a feature extractor for
the current state-of-the-art in TAL. However, unlike
the popular classification setting, decision level fu-
sion is challenging for TAL since predictions often
differ in relative temporal extents. PGCN (Zeng et al.,
2019b), introduced earlier, solves this problem by per-
forming Non-Maximal Suppression on the combined
pool of proposals from the two modalities (RGB, Op-
tical Flow). MUSES baseline (Liu et al., 2021) fuses
the RGB and Flow predictions. Mid fusion combines
mid-level feature representations from each individ-
ual modality stream. Feichtenhofer et. al. (Feichten-
hofer et al., 2016) found that fusing RGB and Opti-
cal Flow streams at the last convolutional layer yields
good visual modality features. The resulting mid-
level features have been successfully employed by
well-performing TAL approaches (Lin et al., 2020;
Lin et al., 2019; Lin et al., 2018; Li et al., 2019). In
particular, they are utilized by G-TAD (Zeng et al.,
2019b) to obtain feature representations for each tem-
poral proposal. Early fusion involves fusing the
modalities at the input level. In the few papers that
compare different fusion schemes (Jiang et al., 2018;
Tian et al., 2018), early fusion is generally an inferior
choice.
Apart from within (visual) modality fusion men-
tioned above, audio-visual fusion specifically has
been shown to benefit (trimmed) clip-level action
recognition (Wu et al., 2016; Long et al., 2018b; Long
et al., 2018a; Kazakos et al., 2019) and audio-visual
event localization (Zhou et al., 2021; He et al., 2021;
Xu et al., 2020a). The audio modality has also been
shown to be beneficial for the weakly supervised ver-
sion of TAL (Lee et al., 2021) wherein the boundary
labels for activity instances are absent. However, the
lack of labels is a fundamental performance bottle-
neck compared to the supervised approach.
In our work, we introduce two mid-level fusion
schemes along with decision level fusion to combine
Audio, RGB, Flow modalities for state-of-the-art su-
pervised TAL.
3 PROPOSED FUSION SCHEMES
Processing Stages in Video-only TAL: Temporal
Action Localization can be formulated as the task of
predicting start and end times (t
s
,t
e
) and action la-
bel a for each action in an untrimmed RGB video
V ∈ R
F×3×H×W
, where F is the number of frames,
H and W represent the frame height and width. De-
spite the architectural differences, state of the art TAL
approaches typically consist of three stages: feature
extraction, proposal generation and proposal refine-
ment.
The feature extraction stage transforms a video
into a sequence of feature vectors corresponding to
each visual modality (RGB and Flow). Specifically,
the feature extractor operates on fixed-size snippets
S ∈ R
L×C×H×W
and produces a feature vector f ∈ R
d
v
.
Here, C is the number of channels and L is the num-
ber of frames in the snippet. This results in the feature
vector sequence F
v
∈ R
L
v
×d
v
mentioned above where
L
v
is the number of snippets. This stage is shown as
the component shaded green (containing E
v
) in Fig-
ure 2.
The proposal generation stage processes the fea-
ture sequence mentioned above to generate action
proposals. Each candidate action proposal is associ-
ated with temporal extent (start and end time) relative
to the input video, and a confidence score. In some
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
146

approaches, each proposal is also associated with an
activity class label.
The proposal refinement stage takes the feature se-
quence corresponding to each candidate proposal as
input and refines the boundary predictions and confi-
dence scores. Some approaches modify the class la-
bel predictions as well. The final proposals are gener-
ally obtained by applying nonmaximal suppression to
weed out the redundancies arising from highly over-
lapping proposals. Also, note that some approaches
do not treat proposal generation and refinement as two
different stages. To accommodate this variety, we de-
pict the processing associated with proposal genera-
tion and refinement as a single module titled ‘PG/R’
in Figure 2.
3.1 Incorporating Audio
As with video-only TAL approaches, the first stage of
audio modality processing consists of extracting a se-
quence of features from audio snippets (refer to the
blue shaded module termed E
a
in Figure 2). This
results in the ‘audio’ feature vector sequence F
a
∈
R
L
a
×d
a
mentioned above where L
a
is the number of
audio snippets and d
a
is the length of feature vector
for an audio snippet.
Our objective is to incorporate audio as seamlessly
as possible into existing video-only TAL architec-
tures. To enable flexible integration, we present two
schemes - proposal fusion and encoding fusion. We
describe these schemes next.
3.2 A Proposal Fusion
This is a decision fusion approach and as suggested
by its name, the basic idea is to merge proposals from
the audio and video modalities (see ‘Proposal Fusion’
in Figure 2). To begin with, audio proposals are ob-
tained like the procedure used to obtain video propos-
als. As mentioned earlier, it is straightforward to fuse
action class predictions from each modality by simply
averaging the probabilities. However, TAL propos-
als consist of regression scores for action boundaries,
where averaging across modality does not make much
sense since it is likely to introduce error into the pre-
dictions. This makes the fusion task challenging in
the TAL setting.
To solve this problem while adhering to our ob-
jective of leaving the existing video-only pipeline
untouched, we repurpose the corresponding mod-
ule from the pipelines. Specifically, we use Non-
Maximal Suppression (NMS) for iteratively choos-
ing the best proposals which minimally overlap
with other proposals. In some architectures (e.g.
Linear
Linear
Linear
Linear
Figure 3: Residual Multimodal Attention mechanism with
video-only and audio features as a form of encoding fusion
(Section 3.3).
L
indicates tensor addition.
PGCN (Zeng et al., 2019b)), NMS is applied to
separate proposals from RGB and Flow components
which contribute together as part of the visual modal-
ity. We extend this, by initially pooling visual modal-
ity proposals with audio proposals, and then applying
NMS.
3.3 B
Encoding Fusion
Instead of the late fusion of per-modality proposals
described above, an alternative is to utilize the com-
bined set of audio F
a
and video feature sequences F
v
to generate a single, unified set of proposals. How-
ever, since the encoded representation dimensions
d
a
, d
v
and the number of sequence elements L
a
, L
v
can
be unequal, standard dimension-wise concatenation
techniques are not applicable. To tackle this issue, we
explore four approaches to make the sequence lengths
equal for feature fusion (depicted as purple block ti-
tled ‘Encoding Fusion’ in Figure 2).
For the first two approaches, we revisit the fea-
ture extraction phase and extract audio features at the
frame rate used for videos. As a result, we obtain
a paired sequence of audio and video snippets (i.e.
L
a
= L
v
).
• Concatenation (Concat): The paired sequences
are concatenated along the feature dimension.
• Residual Multimodal Attention (RMAttn): To
refine each modality’s representation using fea-
tures from other modalities, we employ a resid-
ual multimodal attention mechanism (Tian et al.,
2018) as shown in Figure 3.
a
t
0
= σ(a
t
+ f (a
t
, v
t
)) (1)
v
t
0
= σ(v
t
+ f (a
t
, v
t
)) (2)
where f(·) is an additive fusion function, σ(.) is
the hyperbolic tangent function, and , and the sum
of a
t
0
and v
t
0
is used as the joint representation for
the video feature at the timestamp t.
The other two encoding fusion approaches:
Hear Me out: Fusional Approaches for Audio Augmented Temporal Action Localization
147

• Duplicate and Trim (DupTrim): Suppose L
v
<
L
a
and k =
L
a
L
v
. We first duplicate each visual fea-
ture to obtain a sequence of length kL
v
. We then
trim both the audio and visual feature sequences
to a common length L
m
= min(L
a
, kL
v
). A similar
procedure is followed for the other case (L
a
< L
v
).
• Average and Trim (AvgTrim): Suppose L
v
< L
a
and k =
L
a
L
v
. We group audio features into subse-
quences of length k
0
= dke. We then form a new
feature sequence of length L
0
a
by averaging each
k
0
-sized group. Following a procedure similar to
‘DupTrim’ above, we trim the modality sequences
to a common length, i.e. L
m
= min(L
0
a
, L
v
).
For the above approaches involving trimming, the
resulting audio and video sequences are concatenated
along the feature dimension to obtain the fused multi-
modal feature sequence.
For all the approaches, the resulting fused repre-
sentation is processed by a ‘PG/R’ (proposal genera-
tion and refinement) module to obtain the final predic-
tions, similar to its usage mentioned earlier (see Fig-
ure 2). Apart from the fusion schemes, we also note
that each scheme involves additional choices. In our
experiments, we perform a comparative evaluation for
all the resulting combinations.
4 IMPLEMENTATION DETAILS
TAL Video-only Architectures: To determine the
utility of audio modality and to ensure our method
is easily applicable to any video-only TAL approach,
we do not change the architectures and hyperparam-
eters (e.g. snippet length, frame rate, optimizers) for
the baselines. The feature extraction components of
the baselines are summarized in Table 1.
Audio Extraction: For audio, we use VGGish (Her-
shey et al., 2017), a state of the art approach for audio
feature extraction. We use a sampling rate of 16kHz
to extract the audio signal and extract 128-D features
from 1.2s long snippets. For experiments involving
attentional fusion and simple concatenation, we ex-
tract features by centering the 1.2s window about the
snippets used for video feature extraction to maintain
the same feature sequence length for audio and video
modalities. Windows shorter than 1.2s (a few start-
ing and ending ones) are padded with zeros at the end
to specify that no more information is present and to
match the 1.2s window requirement. Although the
opposite (i.e. changing sampling rate for video, keep-
ing the audio setup unchanged) is possible, we pre-
fer the former since the video-only architecture and
(video) data processing can be used as specified orig-
inally, without worrying about the consequences of
such a change on the existing video-only architectural
setup and hyperparameter choices.
Proposal Generation and Refinement (PG/R): For
proposal generation, we consider state of the art ar-
chitectures GTAD(Xu et al., 2020b), BMN(Lin et al.,
2019) and BSN(Lin et al., 2018). Similarly, for pro-
posal refinement, we consider proposals generated
from BMN and BSN, refined in PGCN(Zeng et al.,
2019b) and MUSES(Liu et al., 2021) in our experi-
ments with audio.
Optimization: We train all the architectures except
PGCN and GTAD with their original setting. We use
a batch size of 256 for PGCN and 16 for GTAD. For
training, we use 4 GeForce 2080Ti 11GB GPUs. The
entire codebase is based on the Pytorch library except
for VGGish (Hershey et al., 2017) which is based on
Keras.
5 EXPERIMENTS
5.1 Datasets
To compare our results with the SOTA architectures in
which we incorporate audio, we evaluate our models
on two benchmark datasets for temporal action local-
ization.
Thumos14: (Jiang et al., 2014) contains 1010
untrimmed videos for validation and 1574 for test-
ing. Of these, 200 validation and 213 testing videos
contain temporal annotations spanning 20 activity cat-
egories. Following the standard setup (Xu et al.,
2020b; Zeng et al., 2019b), we use the 200 valida-
tion videos for training and the 213 testing videos for
evaluation.
ActivityNet-1.3: (Caba Heilbron et al., 2015) con-
tains 20k untrimmed videos with 200 action classes
between its training, validation and testing sets. Once
again, following the standard setup (Xu et al., 2020b;
Zeng et al., 2019b) , we train on 10024 videos and test
on the 4926 videos from the validation set.
5.2 Evaluation Protocol
We label a temporal (proposal) prediction (with as-
sociated start and end time) as correct if (i) its Inter-
section Over Union (IOU) with ground-truth exceeds
a pre-determined threshold (ii) the proposal’s label
matches the ground truth counterpart. Following stan-
dard protocols, we evaluate the mean Average Preci-
sion (mAP) scores at IOU thresholds from 0.3 to 0.7
with a step of 0.1 for THUMOS14 (Jiang et al., 2014)
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
148

Table 1: Architectural pipeline components for top-performing TAL approaches. To reduce clutter, only mAP@0.5 is reported.
The ‘+Audio’ group refers to the fusion configuration corresponding to the best results (Section 3).
+Audio
Dataset Setup Id Architecture Visual Features mAP mAP fusion scheme fusion type
THUMOS14(Jiang et al., 2014)
1 GTAD(Xu et al., 2020b) TSN(Wang et al., 2019) 40.20 42.01 encoding Concat
2 PGCN(Zeng et al., 2019b) TSP (Alwassel et al., 2020) 53.50 53.96 encoding AvgTrim
3 MUSES(Liu et al., 2021) I3D(Carreira and Zisserman, 2017) 56.16
1
57.18 encoding Concat
ActivityNet-1.3(Caba Heilbron et al., 2015)
1 GTAD(Xu et al., 2020b) GES(Xiong et al., 2016) 41.50
2
42.17 encoding Concat
2 GTAD(Xu et al., 2020b) TSP (Alwassel et al., 2020) 51.26 54.34 encoding RMAttn
1
From our best run using the official code from (Liu et al., 2021). In the paper, reported mAP is 56.90
2
The result is obtained by repeating the evaluation on the set of videos currently available.
Table 2: [THUMOS14] mAP for MUSES(Liu et al., 2021)
+ I3D(Carreira and Zisserman, 2017) architecture of video-
only, audio only and audio-visual fusional approaches.
mAP@IoU
Fusion Type(scheme) Visual Audio 0.3 0.4 0.5 0.6 0.7
Video-only I3D – 67.91 63.15 56.16 46.07 29.89
Audio-only – VGGish 8.23 6.61 4.73 3.05 1.30
Concat (Encoding) I3D VGGish 70.18 64.98 57.18 45.42 28.86
Dup-Trim (Encoding) I3D VGGish 69.25 64.22 56.53 46.08 30.73
Avg-Trim (Encoding) I3D VGGish 65.10 60.47 53.92 42.87 28.09
RM-Attention (Encoding) I3D VGGish 67.88 63.05 56.19 45.27 29.98
Proposal (Decision) I3D VGGish 52.22 47.42 39.37 30.54 17.36
and {0.5, 0.75, 0.95} for ActivityNet-1.3 (Caba Heil-
bron et al., 2015).
6 RESULTS
The mAP@0.5 results of the best fusion approach for
each video-only baseline can be seen in Table 1. It
can be seen that incorporating audio consistently im-
proves performance across all approaches. In particu-
lar, this incorporation results in a new state-of-the-art
result on both the benchmark TAL datasets. In terms
of fusion approaches, the clear dominance of the en-
coding fusion scheme (Section 3.3) can be seen. The
Residual Multimodal Attention mechanism from this
scheme enables the best performance for the relatively
larger ActivityNet-1.3 dataset. Similarly, our mecha-
nism of resampling the audio modality followed by
a concatenation of per-modality features enables the
best performance for the THUMOS14 dataset. A
fuller comparison of the existing best video-only and
best audio-visual results obtained via our work can be
seen in Tables 2,3. The results once again reinforce
the utility of audio for TAL.
6.1 Ablations
To analyze the utility of the fusion schemes proposed
in Section 3, we compared their performances with
audio-only and video-only methods for the best per-
forming approach in each dataset. Looking at Tables 2
and 3, it is readily evident that fusing audio and video
gives the best results. Specifically, RM-Attention fu-
Table 3: [ActivityNet-1.3] mAP for GTAD(Xu et al.,
2020b) + TSP(Alwassel et al., 2020) of video-only, audio-
only and audio-visual fusional approaches.
mAP@IoU
Fusion Type (scheme) Visual Audio 0.5 0.75 0.95 avg.
Video-only TSP – 51.26 37.12 9.29 35.01
Audio-only – VGGish 43.07 28.27 5.82 28.19
Concat (Encoding) TSP VGGish 52.6 37.55 9.19 36.37
Dup-Trim (Encoding) TSP VGGish 52.31 37.66 9.49 36.47
Avg-Trim (Encoding) TSP VGGish 51.91 37.53 9.55 36.33
RM-Attention (Encoding) TSP VGGish 54.34 37.66 9.29 36.82
Proposal (Decision) TSP VGGish 51.6 37.34 9.41 35.95
sion enables the best result for ActivityNet-1.3 while
simple concat works best for Thumos14. The rea-
son for simple concat’s superior performance for Thu-
mos14 can be explained by the fact that audio content
is less informative regarding the action boundaries in
Thumos14 compared to ActivityNet-1.3. This is also
evident from the audio-only baselines – compare the
second rows of Tables 2,3. We hypothesize that RM-
Attention is more effective at fusing the modalities
than filtering out noise when the audio modality is un-
informative. In contrast, for simple concat, the sepa-
rate, non-modulated contribution of audio and visual
features makes the fusion scheme less susceptible to
noise in any one modality.
DupTrim seems to perform better than AvgTrim,
while both are inferior to simple concatenation. This
indicates that preserving the ideal frame rate for each
modality may not be that crucial to performance and
it is probably better to extract features at the same
rate for each modality rather than artificially mak-
ing them equal after extraction. Among the fusion
schemes, proposal fusion performs the worst for both
ActivityNet-1.3 and Thumos14. This is to be ex-
pected because it just selects the best proposal out
from the audio and visual streams.
The performances of the audio-only baselines for
each dataset suggest that audio information present
in ActivityNet-1.3 is much more indicative of activity
boundaries compared to that in Thumos14. This is
also consistent with the degree of improvement due
to fusion for both datasets.
Hear Me out: Fusional Approaches for Audio Augmented Temporal Action Localization
149

6.2 Class-wise Analysis
To examine the effect of audio at the action class level,
we plot the change in Average Precision (AP) rela-
tive to the video-only score for the best performing
setup. Figure 4 depicts the plot for ActivityNet-1.3,
sorted in decreasing order of AP improvement. The
majority of action classes show positive AP improve-
ment. This correlates with observations made in the
context of aggregate performance (Table 1, Table 3).
The action classes which benefit the most from au-
dio (e.g. ‘Playing Ten Pins’, ‘Curling’, ‘Blow-drying
hair’) tend to have signature audio transitions marking
the beginning and end of the action. The classes at the
opposite end (e.g. ‘Painting’, ‘Doing nails’, ‘Putting
in contact lenses’) are characterized by very little as-
sociation between visual and audio modalities. For
these classes, we empirically observed that ambient
background sounds are present which induce noisy
features. However, the gating mechanism enabled by
Residual Multimodal Attention ensures that the effect
of such noise from the modalities is appropriately mit-
igated. This can be seen from the smaller magnitude
of the drop in AP.
Figure 5 depicts the sorted AP improvement plot
for the relatively smaller Thumos14 dataset. Simi-
lar qualitative trends as for ActivityNet-1.3 mentioned
earlier can be seen, i.e. signature audio transitions
characterizing largest AP improvement classes and
weak inter-modality associations characterizing least
AP improvement classes. However, as mentioned
in the previous section, the relatively weak associa-
tion between audio and video modalities in Thumos14
causes the % of categories which are negatively im-
pacted by audio inclusion to be greater compared to
ActivityNet-1.3.
6.3 Instance-wise Analysis
Modifying the approach used by Alwassel et al. (Al-
wassel et al., 2018) for their approach (DETAD), we
analyze two salient attributes of data to analyze the ef-
fect of adding audio. These attributes are (i) coverage
- the proportion of untrimmed video that the ground
truth instance spans (ii) length (temporal duration)
To measure coverage, we normalize the duration
of an action instance relative to the duration of the
video. Thus, the larger the coverage, the larger the
extent the instance occupies in the video. Note that
coverage lies between 0 and 1. We group the result-
ing coverage values into five buckets: Extra Small
(XS: (0, 0.2]), Small (S: (0.2, 0.4]), Medium (M:
(0.4, 0.6]), Large (L:(0.6, 0.8]), and Extra Large (XL:
(0.8, 1.0]). The length is measured as the instance
duration in seconds. We create five different length
groups: Extra Small (XS: (0, 30]), Small (S: (30, 60]),
Medium (M: (60, 120]), Long (L: (120, 180]), and
Extra Long (XL: > 180).
From the numbers below the bucket labels on the
x-axis in Figures 6 and 7, we see that most action
instances fall in Extra Small buckets. Also, the distri-
butions of coverage and length of the ground truth in-
stances are skewed towards the left (shorter extents).
The change in mAP due to the inclusion of audio
can be viewed in Figures 6 and 7 on a per-bucket ba-
sis. The overall gain in performance for both datasets
is well explained by the overwhelmingly large pro-
portion of the total instances showing improvement
due to audio : 63.3% by coverage and 79.81% by
length for ActivityNet-1.3 and 95.5% by coverage
and length for Thumos14.
From the figures, we see that audio fusion enables
consistent improvements for XS and M instances for
both datasets while for XL instances, the mAP de-
creases or remained unchanged. This can be at-
tributed in part to the fact that the shorter instances
have an audio ‘signature’ for the action that spans the
majority of the instance which assists detection. For
the longer action instances, the action-characteristic
audio spans a small section of the instance which
might not aid detection as much.
6.4 False Positive Analysis
Following (Alwassel et al., 2018), we consider the
following error sub-categories within false positive
predictions:
• Double Detection error: IoU > α and correct label
but not the highest IoU.
• localization error: 0.1 < IoU < α, correct label
• Confusion error: 0.1 < IoU < α, wrong label
• Wrong Label error: IoU > α, wrong label
• Background error: IoU < 0.1
The change in the distribution of possible pre-
diction outcomes with the inclusion of audio can be
viewed in Figure 8. The false-positive errors ex-
cept Background errors have increased. However,
their relative frequency is smaller. The large de-
crease in the number of Background errors more than
mitigates the combined increase in other error sub-
categories, explaining the overall improvement in per-
formance. The trends in false-positive errors also sug-
gest that audio information is most useful in discrimi-
nating between activity instances and the background
in untrimmed videos. In addition, we observe that the
number of true positive predictions (prediction with
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
150
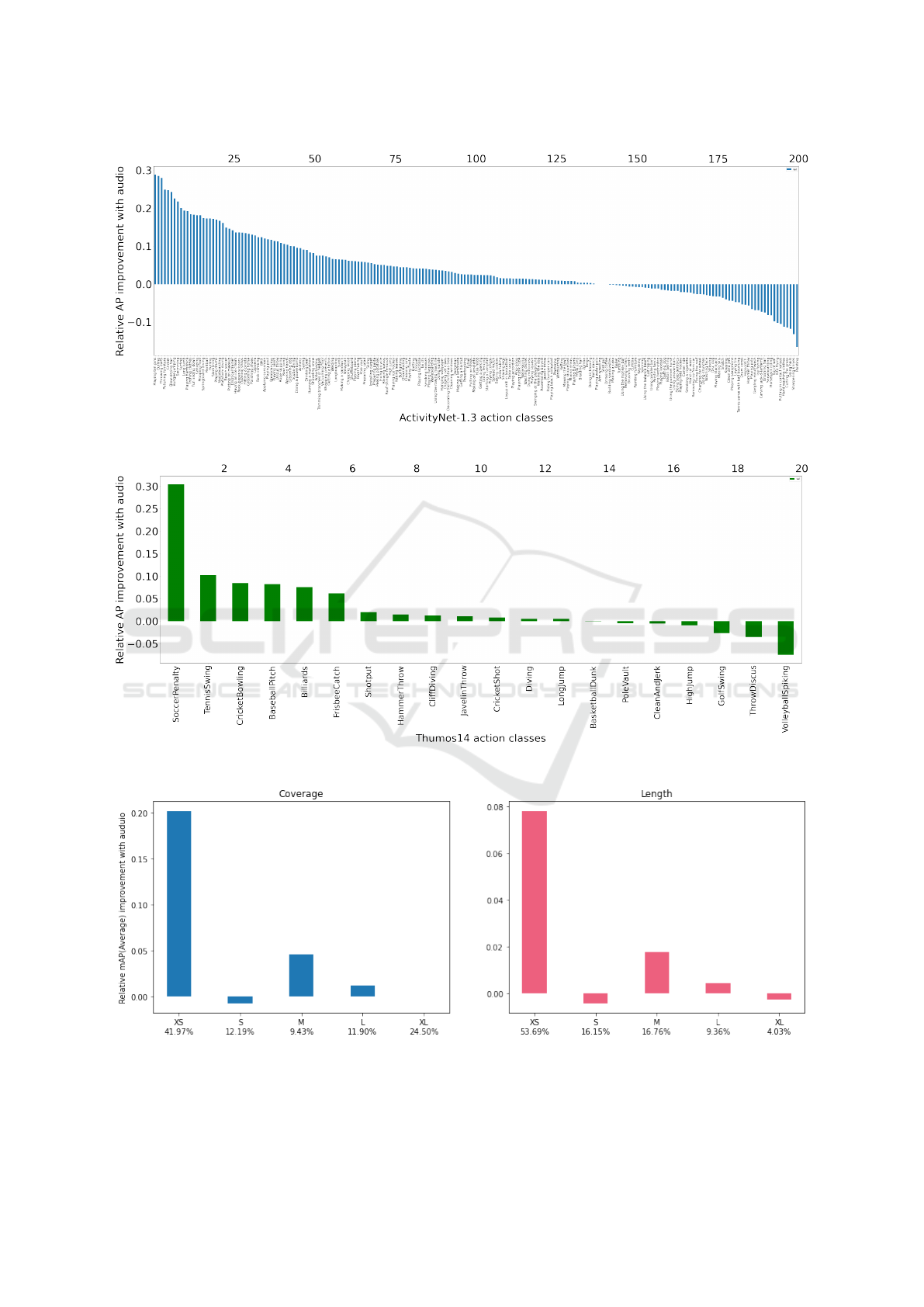
Figure 4: [ActivityNet-1.3] Relative change in per-class AP of the best multimodal setup (Table 1) with inclusion of audio.
Figure 5: [THUMOS14] Relative change in per-class AP of the best multimodal setup (Table 1) with inclusion of audio.
Figure 6: [ActivityNet-1.3] Relative change in average mAP of the best multimodal setup (Table 1) classified by instance
length and coverage, with inclusion of audio. The numbers below X-labels represent the percentage of each type of instance
class in the dataset.
Hear Me out: Fusional Approaches for Audio Augmented Temporal Action Localization
151
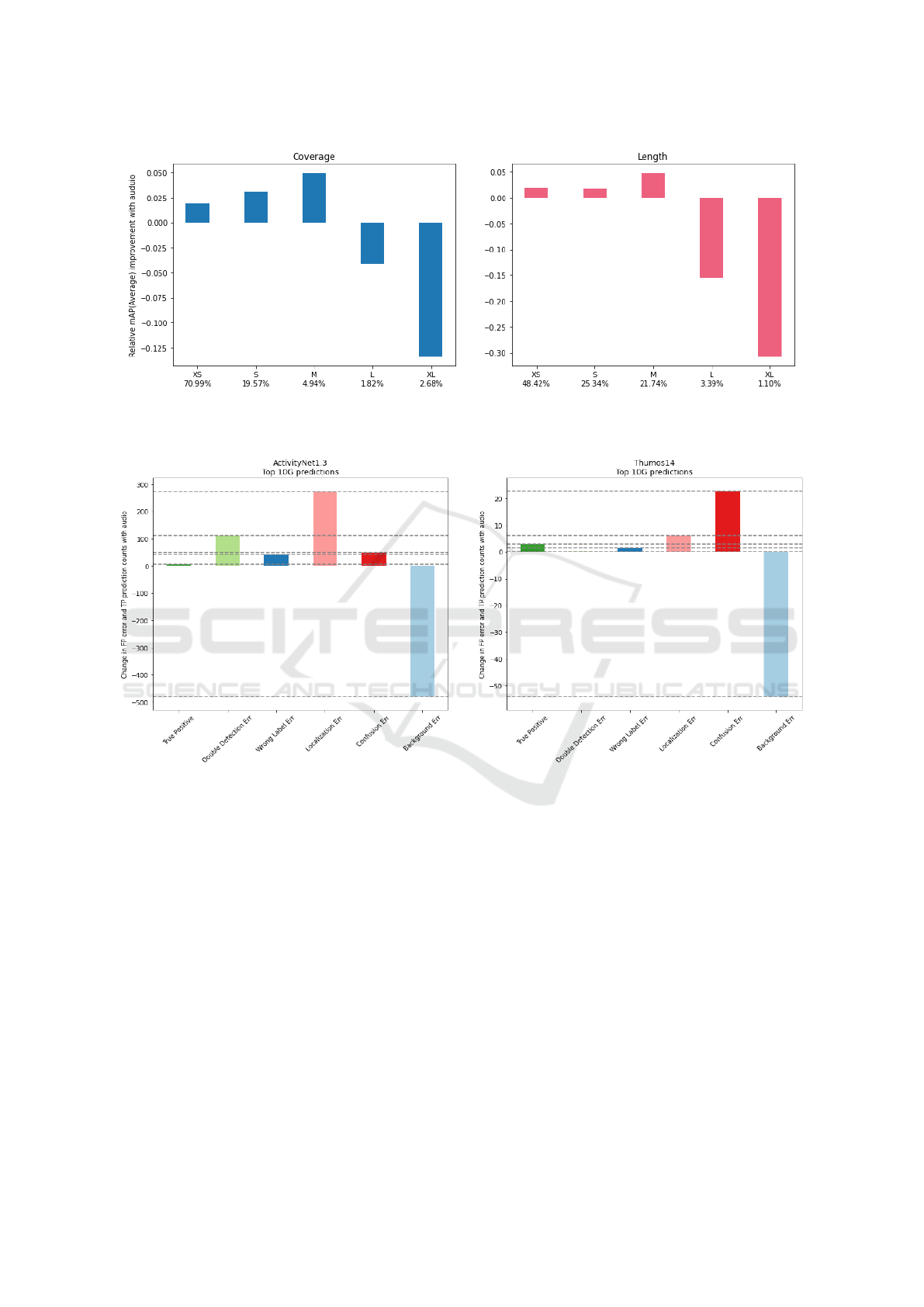
Figure 7: [THUMOS14] Relative change in average mAP of the best multimodal setup (Table 1) classified by instance length
and coverage, with inclusion of audio. The numbers below X-labels represent the percentage of each type of instance class in
the dataset.
Figure 8: Change in number of True Positive (TP) predictions and False Positive (FP) errors of each type of the best mul-
timodal setup (Table 1) for each dataset with the inclusion of audio. The dashed lines are added to distinguish vey close
values.
highest IoU, with IoU > α and correctly predicted la-
bel, where α is the IoU threshold) increase for both
THUMOS14 and ActivityNet-1.3, with the inclusion
of audio.
7 CONCLUSION
In this paper, we have presented multiple simple but
effective fusion schemes for incorporating audio into
existing video-only TAL approaches. To the best of
our knowledge, our multimodal effort is the first of its
kind for fully supervised TAL. An advantage of our
schemes is that they can be readily incorporated into
a variety of video-only TAL architectures – a capabil-
ity we expect to be available for future approaches as
well. Experimental results on two large-scale bench-
mark datasets demonstrate consistent gains due to our
fusion approach over video-only methods and state-
of-the-art performance. Our analysis also sheds light
on the impact of audio availability on overall as well
as per-class performance. Going ahead, we plan to
expand and improve the proposed families of fusion
schemes.
ACKNOWLEDGEMENTS
We wish to acknowledge the support from Me-
iTY towards this work via the IMSA project (Ref.
No.4(16)/2019-ITEA).
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
152

REFERENCES
Alwassel, H., Caba Heilbron, F., Escorcia, V., and Ghanem,
B. (2018). Diagnosing error in temporal action detec-
tors. In ECCV.
Alwassel, H., Giancola, S., and Ghanem, B. (2020). TSP:
temporally-sensitive pretraining of video encoders for
localization tasks. CoRR, abs/2011.11479.
Arandjelovic, R. and Zisserman, A. (2017). Look, listen
and learn. In ICCV.
Buch, S., Escorcia, V., Ghanem, B., Fei-Fei, L., and
Niebles, J. (2019). End-to-end, single-stream tempo-
ral action detection in untrimmed videos. In BMVC.
Caba Heilbron, F., Escorcia, V., Ghanem, B., and Car-
los Niebles, J. (2015). Activitynet: A large-scale
video benchmark for human activity understanding. In
CVPR.
Carreira, J. and Zisserman, A. (2017). Quo vadis, action
recognition? a new model and the kinetics dataset. In
CVPR.
Delphin-Poulat, L. and Plapous, C. (2019). Mean teacher
with data augmentation for dcase 2019 task 4. Tech-
nical report, Orange Labs Lannion, France.
Ebbers, J. and Haeb-Umbach, R. (2020). Convolutional
recurrent neural networks for weakly labeled semi-
supervised sound event detection in domestic environ-
ments. Technical report, DCASE2020 Challenge.
Feichtenhofer, C., Pinz, A., and Zisserman, A. (2016). Con-
volutional two-stream network fusion for video action
recognition.
Gao, J., Chen, K., and Nevatia, R. (2018). CTAP: comple-
mentary temporal action proposal generation. CoRR,
abs/1807.04821.
Gao, J., Yang, Z., Sun, C., Chen, K., and Nevatia, R.
(2017). TURN TAP: temporal unit regression network
for temporal action proposals. CoRR, abs/1703.06189.
Girshick, R. (2015). Fast r-cnn. In ICCV, pages 1440–1448.
Hao, J., Hou, Z., and Peng, W. (2020). Cross-domain sound
event detection: from synthesized audio to real audio.
Technical report, DCASE2020 Challenge.
He, Y., Xu, X., Liu, X., Ou, W., and Lu, H. (2021). Multi-
modal transformer networks with latent interaction for
audio-visual event localization. In ICME.
Hershey, S., Chaudhuri, S., Ellis, D. P., Gemmeke, J. F.,
Jansen, A., Moore, R. C., Plakal, M., Platt, D.,
Saurous, R. A., Seybold, B., et al. (2017). Cnn ar-
chitectures for large-scale audio classification. In
ICASSP.
Jiang, H., Li, Y., Song, S., and Liu, J. (2018). Rethink-
ing Fusion Baselines for Multi-modal Human Action
Recognition: 19th Pacific-Rim Conference on Mul-
timedia, Hefei, China, September 21-22, 2018, Pro-
ceedings, Part III.
Jiang, Y.-G., Liu, J., Roshan Zamir, A., Toderici, G., Laptev,
I., Shah, M., and Sukthankar, R. (2014). THUMOS
challenge: Action recognition with a large number of
classes.
Kazakos, E., Nagrani, A., Zisserman, A., and Damen, D.
(2019). Epic-fusion: Audio-visual temporal binding
for egocentric action recognition. In ICCV.
Lee, J.-T., Jain, M., Park, H., and Yun, S. (2021). Cross-
attentional audio-visual fusion for weakly-supervised
action localization. In ICLR.
Li, X., Lin, T., Liu, X., Gan, C., Zuo, W., Li, C., Long, X.,
He, D., Li, F., and Wen, S. (2019). Deep concept-wise
temporal convolutional networks for action localiza-
tion.
Lin, C., Li, J., Wang, Y., Tai, Y., Luo, D., Cui, Z., Wang, C.,
Li, J., Huang, F., and Ji, R. (2020). Fast learning of
temporal action proposal via dense boundary genera-
tor. Proceedings of the AAAI Conference on Artificial
Intelligence.
Lin, C., Xu, C., Luo, D., Wang, Y., Tai, Y., Wang, C., Li, J.,
Huang, F., and Fu, Y. (2021). Learning salient bound-
ary feature for anchor-free temporal action localiza-
tion. In CVPR, pages 3320–3329.
Lin, L. and Wang, X. (2019). Guided learning convolution
system for dcase 2019 task 4. Technical report, Insti-
tute of Computing Technology, Chinese Academy of
Sciences, Beijing, China.
Lin, T., Liu, X., Li, X., Ding, E., and Wen, S. (2019). BMN:
boundary-matching network for temporal action pro-
posal generation. CoRR, abs/1907.09702.
Lin, T., Zhao, X., and Shou, Z. (2017). Single shot temporal
action detection. CoRR, abs/1710.06236.
Lin, T., Zhao, X., Su, H., Wang, C., and Yang, M. (2018).
BSN: boundary sensitive network for temporal action
proposal generation. CoRR, abs/1806.02964.
Liu, X., Hu, Y., Bai, S., Ding, F., Bai, X., and Torr, P.
H. S. (2021). Multi-shot temporal event localization:
A benchmark. In CVPR, pages 12596–12606.
Liu, Y., Ma, L., Zhang, Y., Liu, W., and Chang, S. (2018).
Multi-granularity generator for temporal action pro-
posal. CoRR, abs/1811.11524.
Long, X., Gan, C., De Melo, G., Liu, X., Li, Y., Li, F., and
Wen, S. (2018a). Multimodal keyless attention fusion
for video classification. In AAAI 2018.
Long, X., Gan, C., de Melo, G., Wu, J., Liu, X., and Wen,
S. (2018b). Attention clusters: Purely attention based
local feature integration for video classification. In
CVPR.
Miyazaki, K., Komatsu, T., Hayashi, T., Watanabe, S.,
Toda, T., and Takeda, K. (2020). Convolution-
augmented transformer for semi-supervised sound
event detection. Technical report, DCASE2020 Chal-
lenge.
Montes, A., Salvador, A., and Gir
´
o-i-Nieto, X. (2016).
Temporal activity detection in untrimmed videos with
recurrent neural networks. CoRR, abs/1608.08128.
Ono, N., Harada, N., Kawaguchi, Y., Mesaros, A., Imoto,
K., Koizumi, Y., , and Komatsu, T. (2020). Proceed-
ings of the Fifth Workshop on Detection and Classifi-
cation of Acoustic Scenes and Events (DCASE 2020).
Owens, A. and Efros, A. A. (2018). Audio-visual scene
analysis with self-supervised multisensory features. In
ECCV.
Owens, A., Wu, J., McDermott, J. H., Freeman, W. T., and
Torralba, A. Learning sight from sound: Ambient
sound provides supervision for visual learning. Int.
J. Comput. Vis.
Hear Me out: Fusional Approaches for Audio Augmented Temporal Action Localization
153

Shi, Z. (2019). Hodgepodge: Sound event detection based
on ensemble of semi-supervised learning methods.
Technical report, Fujitsu Research and Development
Center, Beijing, China.
Shou, Z., Chan, J., Zareian, A., Miyazawa, K., and Chang,
S. (2017). CDC: convolutional-de-convolutional net-
works for precise temporal action localization in
untrimmed videos. CoRR, abs/1703.01515.
Shou, Z., Wang, D., and Chang, S. (2016). Action temporal
localization in untrimmed videos via multi-stage cnns.
CoRR, abs/1601.02129.
Su, H., Gan, W., Wu, W., Yan, J., and Qiao, Y. (2020).
BSN++: complementary boundary regressor with
scale-balanced relation modeling for temporal action
proposal generation. CoRR, abs/2009.07641.
Tian, Y., Shi, J., Li, B., Duan, Z., and Xu, C. (2018). Audio-
visual event localization in unconstrained videos.
Wang, L., Xiong, Y., Wang, Z., Qiao, Y., Lin, D., Tang, X.,
and Van Gool, L. (2019). Temporal segment networks
for action recognition in videos. TPAMI.
Wang, Q., Downey, C., Wan, L., Mansfield, P. A., and
Moreno, I. L. (2018). Speaker diarization with lstm.
In ICASSP.
Wu, Z., Jiang, Y.-G., Wang, X., Ye, H., and Xue, X. (2016).
Multi-stream multi-class fusion of deep networks for
video classification. In ACM Multimedia.
Xiong, Y., Wang, L., Wang, Z., Zhang, B., Song, H., Li, W.,
Lin, D., Qiao, Y., Gool, L. V., and Tang, X. (2016).
Cuhk & ethz & siat submission to activitynet chal-
lenge 2016.
Xu, H., Das, A., and Saenko, K. (2017). R-C3D: region
convolutional 3d network for temporal activity detec-
tion. CoRR, abs/1703.07814.
Xu, H., Zeng, R., Wu, Q., Tan, M., and Gan, C. (2020a).
Cross-modal relation-aware networks for audio-visual
event localization. In ACM Multimedia, pages 3893–
3901.
Xu, M., Zhao, C., Rojas, D. S., Thabet, A., and Ghanem, B.
(2020b). G-tad: Sub-graph localization for temporal
action detection. In CVPR.
Yeung, S., Russakovsky, O., Mori, G., and Fei-Fei, L.
(2015). End-to-end learning of action detection from
frame glimpses in videos. CoRR.
Zeng, R., Gan, C., Chen, P., Huang, W., Wu, Q., and
Tan, M. (2019a). Breaking winner-takes-all: Iterative-
winners-out networks for weakly supervised temporal
action localization. IEEE Transactions on Image Pro-
cessing.
Zeng, R., Huang, W., Tan, M., Rong, Y., Zhao, P., Huang, J.,
and Gan, C. (2019b). Graph convolutional networks
for temporal action localization. In ICCV.
Zhang, A., Wang, Q., Zhu, Z., Paisley, J., and Wang, C.
(2019). Fully supervised speaker diarization. In
ICASSP.
Zhao, Y., Xiong, Y., Wang, L., Wu, Z., Lin, D., and Tang,
X. (2017). Temporal action detection with structured
segment networks. CoRR, abs/1704.06228.
Zhou, J., Zheng, L., Zhong, Y., Hao, S., and Wang, M.
(2021). Positive sample propagation along the audio-
visual event line. In CVPR.
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
154
