
Augmented Radar Points Connectivity based on Image Processing
Techniques for Object Detection and Classification
Mohamed Sabry
1 a
, Ahmed Hussein
2 b
, Amr Elmougy
1 c
and Slim Abdennadher
1 d
1
Computer Engineering Department, German University in Cairo (GUC), Cairo, Egypt
2
IAV GmbH, Intelligent Systems Functions Department, Berlin, Germany
Keywords:
Computer Vision, Image Processing, Radars, Point Clouds, Object Detection and Classification.
Abstract:
Perception and scene understanding are complex modules that require data from multiple types of sensors to
construct a weather-resilient system that can operate in almost all conditions. This is mainly due to drawbacks
of each sensor on its own. The only sensor that is able to work in a variety of conditions is the radar. However,
the sparseness of radar pointclouds from open source datasets makes it under-perform in object classification
tasks. This is compared to the LiDAR, which after constraints and filtration, produces an average of 22,000
points per frame within a grid map image representation of 120 x 120 meters in the real world. Therefore, in
this paper, a preprocessing module is proposed to enable the radar to partially reconnect objects in the scene
from a sparse pointcloud. This adapts the radar to object classification tasks rather than the conventional uses
in automotive applications, such as Adaptive Cruise Control or object tracking. The proposed module is used
as preprocessing step in a Deep Learning pipeline for a classification task. The evaluation was carried out
on the nuScenes dataset, as it contained both radar and LiDAR data, which enables the comparison between
the performance of both modules. After applying the preprocessing module, this work managed to make the
radar-based classification significantly close to the performance of the LiDAR.
1 INTRODUCTION
There have been many studies recently to develop
accurate and efficient pointcloud-based object detec-
tion and classification modules. More focus has been
on the use of LiDAR sensors as they produce dense
pointcloud data that is capable of classifying objects
in the environment around an ego vehicle. Each ob-
ject is represented with a fair amount of points which
gives descriptive spatial information lying within the
geometry of the objects. However, for the automo-
tive industry, LiDARs are still not approved for se-
rial production. This means that automotive man-
ufacturers will need to alter a lot of processes in
their production lines to be able to add LiDAR sen-
sors to their serial production vehicles intended for
autonomy and Advanced Driver Assistant Systems
(ADAS). In addition, the price of the LiDAR sensors
is significantly higher than the automotive as shown
a
https://orcid.org/0000-0002-9721-6291
b
https://orcid.org/0000-0001-6621-4923
c
https://orcid.org/0000-0003-0250-0984
d
https://orcid.org/0000-0003-1817-1855
in (Mohammed et al., 2020). The mentioned price tag
significantly adds to the challenges as well. Unlike
the LiDAR, automotive Radars are approved for se-
rial production vehicles meant for levels 1 and 2 for
autonomy as well as being significantly cheaper as
aforementioned. However, the available online data
from Radars are relatively sparse compared to the Li-
DAR (Caesar et al., 2019).
One of the main challenges for dealing with the
radar data from public access datasets is the afore-
mentioned sparseness of the Radar data. This has
limited the serial production Radars for automotive
applications to Adaptive Cruise Control (ACC) and
automatic braking. When used in other applications
usually meant for the LiDARs and Cameras, such
as object detection and classification, Radars lag be-
hind significantly as can be seen on the nuScenes
Leaderboard for 3D object detection and classifica-
tion. Given the Radars capability of working in var-
ious weather conditions in which other sensors can
fail, such as rain and snow. This resilience can fill
in the gap if it can be applied in applications where
the other sensors excel, such as object detection and
classification.
Sabry, M., Hussein, A., Elmougy, A. and Abdennadher, S.
Augmented Radar Points Connectivity based on Image Processing Techniques for Object Detection and Classification.
DOI: 10.5220/0010860600003124
In Proceedings of the 17th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2022) - Volume 5: VISAPP, pages
535-542
ISBN: 978-989-758-555-5; ISSN: 2184-4321
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
535

To be able to utilize the Radar for 3D object detec-
tion and classification task, this paper proposes a pre-
processing module that can be applied to Radar data
to significantly enhance its object detection and clas-
sification capabilities to be merged with other sensors
for a better overall perception system with more re-
dundancy and robustness. In addition, this will allow
the vehicle to function in the aforementioned weather
conditions where the LiDARs and Cameras fail to
function.
To the best of our knowledge, this is the first ap-
proach to optimize the object classification capabili-
ties of the radar pointcloud based mainly on the Carte-
sian coordinates.
The remainder of this paper is organized as fol-
lows. Section 2 discusses the state of the art. Sec-
tion 3 discusses the proposed radar preprocessing
module. Next, the experimental work is introduced
including the implementation details, the dataset used
and the evaluation metrics in Section 4. Section 5
shows the proposed algorithm object classification re-
sults and the discussion. Finally, Section 6 includes
concluding remarks and future work.
2 STATE OF THE ART
2.1 Radar Only Detection and
Classification
In (Palffy et al., 2020), the authors presented a Radar
based single-frame, multi-class detection method for
moving road users (pedestrian, cyclist, car) which is
based on feature extension and a Convolutional Neu-
ral Network (CNN) for the classification. They uti-
lized low-level Radar cube data. The authors pro-
vided the data format and input shape of the data used.
However, the dataset was not public which eliminated
the opportunity to compare the approach with other
ones. In addition, the authors used the Radar Data to
detect moving objects only, so stationary objects were
excluded from the calculations.
In (Danzer et al., 2019), the authors utilized the
Radar data for car detection using Radar data. How-
ever, the data contained only one class of objects with
is the Car label. In addition, the test set mentioned in
the paper does not include a test case were the their
target vehicle is stationary.
2.2 Radar-camera Fusion-based
Proposals
In (Kim et al., 2020), the authors proposed using
a self-produced short-range FMCW Radar with the
YOLO (Redmon and Farhadi, 2018) network. The
dataset used in this paper was collected by the authors
and is not publicly available. In addition, the data
used is from a ”self-produced short-range FMCW
Radar” that produces 512 points. This denotes that
this is not off the shelf Radar that gives the points in
the Cartesian coordinates directly such as the Radars
that are used in a public dataset such as nuScenes.
In (Nabati and Qi, 2020) the authors focus on the
problem of Radar and camera sensor fusion and pro-
pose a middle-fusion approach to exploit both Radar
and camera data for 3D object detection. Their ap-
proach first uses a center point detection network to
detect objects by identifying their center points on the
image then associates the Radar detections to their
corresponding object’s center point. The associated
Radar detections are used to generate Radar-based
feature maps to complement the image features, and
regress to object properties such as depth, rotation and
velocity. The results obtained were better than the
state-of-the-art camera-based algorithm by more than
12% in the overall nuScenes Detection Score (NDS).
Several other approaches utilized data from
LiDARs, Radars and Cameras for object detec-
tion. (Wang et al., 2020) is an example denoting the
approach.
In this paper, the variables used in (Danzer et al.,
2019) and some of the preprocessing steps used
in (Dung, 2020) were modified and applied along
side an image processing technique to further develop
the object classification capabilities of Radar data for
multiple classes as well as dynamic and static objects.
3 METHODOLOGY
In this section, the main components of the prepro-
cessing algorithm are introduced. The flow of the sec-
tion can be seen in Figure 1.
3.1 Data Concatenation
The first step in the proposed preprocessing module
is the concatenation of multiple frames from previ-
ous timestamps. This is crucial as, in a single times-
tamp, the Radars surrounding the ego vehicle from the
nuScenes dataset produce a maximum of 625 points
(125 points each) with 18 features each. This num-
ber of points is very sparse compared to the num-
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
536
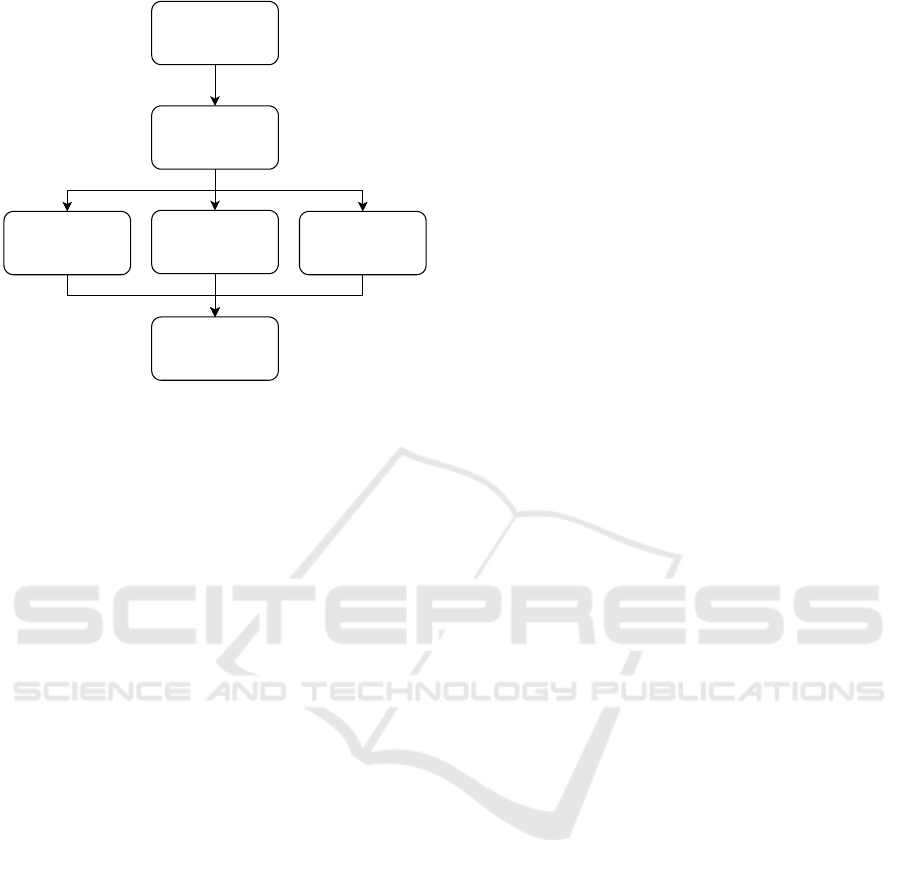
Multi-Frame
Concatenation
Morphological
Operations
Sorted Height
Information
RCS merge
Speed/Density
information
Embedding
PointCloud
Preprocessing
Figure 1: Proposed approach pipeline for Radar improve-
ment for object classification.
ber of points that the LiDAR produces in a single
timestamp. From the testing in this work with the
nuScenes dataset, the LiDAR produced an average of
22,000 points per frame after preprocessing and fil-
tering, as aforementioned. This is one of the obvi-
ous reasons for lack of performance in applications
such as object classification. The concatenated frames
were extracted and compensated by the ego vehicle’s
ego pose in each of the previous timestamps directly
using the nuScenes devkit.
3.2 Initial Information Extraction
After the data is concatenated, points that are found to
be farther than a 60 meter radius from the ego vehicle
are removed. The points are further placed in an im-
age grid map representation with the size of 608x608
pixels representing 120 x 120 meters. Following the
extraction step, the information is then further pro-
cessed by the following steps used in (Dung, 2020):
• The pointcloud location data is converted from
meters into discrete pixel locations to be fitted into
a 608x608 pixels image.
• The discretized location information is used to
sort the unique points from the pointclouds. The
pointclouds’ height information are then normal-
ized to create a heightMap which is a single
608x608 image channel denoting a GridMap rep-
resenting the normalized height information in the
Bird’s eye view form.
• Information denoting the density of points are rep-
resented as in the previous point but the values
within the channel being the normalized counts
for each of the unique values in the discretized
pointcloud. This generated image channel is uti-
lized as the densityMap.
3.3 Information and Relation
Extraction
As aforementioned, the data presented is sparse which
significantly reduces the effectiveness of the prepro-
cessing steps used for Radars. Given this observa-
tion and the available 18 features for each point in the
Radar data, the following features were utilized as a
first step to combine data components:
• The compensated velocities of points were added
as lines drawn with the speed represented in the
color and the direction denoted by the velocity on
the densityMap. This is to try and cover a larger
area to compensate for the sparseness of the radar
data.
• The Radar cross-section (RCS) feature, which is
the area of the object the Radar hits (Knott et al.,
2004), was extracted from each point and used as
an independent channel. This is considered to be a
stable feature to use as it can work with both sta-
tionary and moving objects. This channel is de-
noted as the rcsMap.
As a final step for the information extraction from
the pointcloud, The heightMap alongside the densi-
tyMap with the added compensated velocity informa-
tion and the rcsMap to create a 3 channel Image with
the needed information for the following step.
3.4 Morphological Operations for
Object Connectivity
After extracting the mentioned channels, the points
produced from the Radar were still relatively sparse
with an average of 4500 points from the concate-
nated data compared to an average of 22,000+ points
from the LiDAR in one sample frame only. To over-
come the sparseness issue, the second step from the
data components combination was applied. Apply-
ing Morphological operations on the aforementioned
channels to tackle the task (Comer and Delp III,
1999). This helps in overlapping sparse points from
radar pointclouds which increases connectivity be-
tween points belonging to the same object as a part
of a partial scene reconstruction. For this step, the
equations used can be seen in (1), (2), (3) and (4).
D
r
= X ⊕ H (1)
E
r
= X H (2)
Augmented Radar Points Connectivity based on Image Processing Techniques for Object Detection and Classification
537

C = (X ⊕ H) H (3)
O = (X H) ⊕ H (4)
where H is the structuring element used for the mor-
phological operations, X is the original color image,
E
r
is the eroded image, D
r
is the dilated image, O is
the result of the opening operation on the image and
C is the result of the closing operation on the image.
An example is shown in Figure 2
+ =
-
=
(a)
(b)
Figure 2: The top row shows an example of the dilation
operation applied on a binary image (a). On the left most is
the kernel used for the morphological operation, the middle
is the image which the operation is to be applied on and on
the right most the result of the operation. Furthermore, the
bottom row shows an example of the erosion operation on
an image.
In this paper, the morphological operations were
applied on 3 channels for a color image, with each
channel having a values from 0 to 255.
By trial and error, it was found that applying a
closing operation with 5 dilation iterations followed
by 3 erosion iterations then a final dilation operation
with yet again 5 iterations yields the best results in
this work. This helps maximize the values of objects
in the scene compared to static infrastructure objects
in the scene.
3.5 Deep Neural Network Prediction
After preprocessing the data using the aforemen-
tioned steps, the data is used with the Deep Learning
(DL) network from (Dung, 2020), which is based on
the work of (Li et al., 2020). The network was origi-
nally tested on the KITTI dataset (Geiger et al., 2012)
and has been modified to run on the nuScenes dataset.
The main purpose of the paper is to compare LiDAR
and the modified Radar data head to head, comparing
the same labels to shed the light on the performance
gain of the Radar data after applying the proposed
preprocessing module.
4 EXPERIMENTAL WORK
4.1 Implementation
The proposed approach is implemented in Python us-
ing OpenCV, numpy and pytorch to manipulate the
data. All experiments and tests were carried out on
a computer with an Intel i7-8800K 6-core processor
using 32GB of RAM, running Ubuntu version 18.04,
with a RTX 2080Ti GPU.
4.2 Dataset
As aforementioned, nuScenes was selected as the
publicly available dataset (Caesar et al., 2019) which
contains the needed sensor setup for the testing. The
full dataset provides ground-truth labels for object de-
tection tasks for 1000 scenes with more than 30,000
samples including the training, testing and validation.
The ground-truth is provided as a list containing the
translation, size, orientation, velocity, attributes and
detection names for each object. For the test se-
quences, evaluation results are obtained by submitting
to the nuScenes website. The training was applied on
half the trainval dataset consisting of just over 16,000
samples. The training took around 35 hours for 300
epochs.
For the target of this work which is restricted to
the improvement of the Radar object detection and
classification, the classification was restricted to three
classes, namely vehicles, pedestrians and bicycles.
The nuscenes devkit was used to access the data (Cae-
sar et al., 2019).
As aforementioned, the network from (Dung,
2020) was utilized and modified to fit the nuScenes
dataset. The trainval dataset was used for the Network
training. The training was set for 300 epochs.
4.3 Metrics
For all tests, the evaluation was done by computing
the mean average precision across classes. For each
class, the average precision, transnational, scaling and
orientation errors as well as the nuScenes detection
score (NDS, weighted sum of the individual scores)
were calculated as well. These metrics were extracted
from the nuScenes devkit. These metrics were strictly
used to compare the Radar’s performance against the
LiDAR for moving and stationary objects without tak-
ing velocity into consideration.
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
538

5 RESULTS AND DISCUSSION
The evaluation was done on the mini version of the
dataset as proof of concept. The results based on
the LiDAR data, the concatenated Radar data and the
Radar data with the full proposed module can be seen
in Figure 5, Table 1 and Table 2.
Table 1: A comparison between the results of the LiDAR,
the normal concatenated Radar, and the proposed module.
Approach Object Class AP ATE ASE AOE
LiDAR
Pedestrian
0.543 0.384 0.781 0.576
Concatenated
Radar
0.000 1.000 1.000 1.000
Proposed
Approach
0.475 0.446 0.782 0.685
LiDAR
Vehicle
0.685 0.404 0.780 0.320
Concatenated
Radar
0.000 1.000 1.000 1.000
Proposed
Approach
0.635 0.427 0.781 0.383
LiDAR
Cyclist
0.361 0.420 0.797 0.246
Concatenated
Radar
0.000 1.000 1.000 1.000
Proposed
Approach
0.338 0.449 0.794 0.493
Table 2: Overview quantitative metrics results.
Approach mAP mATE mASE mAOE NDS
LiDAR 0.5297 0.4027 0.7862 0.3804 0.6079
Concatenated
Data
0.0001 1.0000 1.0000 1.0000 0.0001
Proposed
Approach
0.4827 0.4405 0.7858 0.5201 0.5667
No statistics were done on the radar data alone
without any further preprocessing as the visual results
were very poor on their own based on the network
predictions with weights taken from the LiDAR data
as well as the weights trained on the Radar data with-
out any preprocessing as seen in Figure 3. For the
visual results of the comparisons refer to Figure 4.
The proposed approach shows a significant im-
provement over the Radar data without the proposed
module as well as a very similar performance to the
LiDAR based predictions based on the used testing in
this paper. As can be seen in the tables, the overall
results of the proposed approach are satisfactory even
in crowded environments.
Figure 3: Radar alone without any thing training on Radar
data.
5.1 Discussion
The main contribution of the proposed approach is the
introduction of new preprocessing module in the the
object detection and classification pipeline meant for
radar pointclouds to enhance the overall results. It is
worth noting that since the main aim of the paper is
to reduce the gap between the Radar performance and
the LiDAR performance in object detection and clas-
sification based on 3 classes as a proof of concept,
the comparison to the ranking system of the nuScenes
dataset is not straightforward since comparisons are
based on 8 classes in addition to the ability to use all
available sensors from the dataset to be able to pro-
duce the overall performance of the object detection
and classification. However, to the authors knowl-
edge, this is the first paper to address the use of Radar
data pointclouds the same way as the LiDAR point-
clouds and get a very near performance. Through fur-
ther fusion with automotive cameras with this algo-
rithm, the performance can surpass the LiDAR perfor-
mance. This concludes that serial production vehic-
Augmented Radar Points Connectivity based on Image Processing Techniques for Object Detection and Classification
539
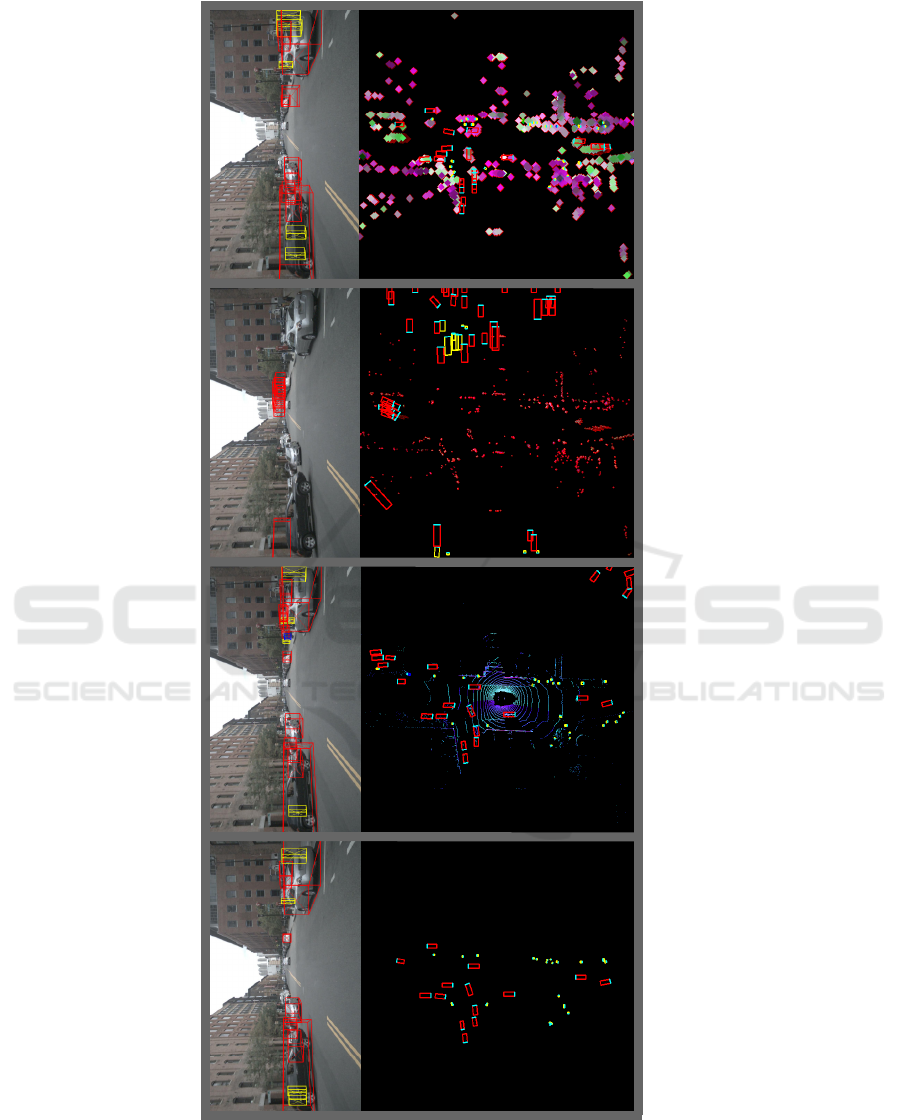
(a) (c)(b) (d)
Figure 4: A visualization for the produced network predictions compared to the ground truth. The top row denotes the
bounding box projections and the bottom row represents a top view of the labels/pointcloud data. (a) represents the ground
truth, (b) represents the predictions on the LiDAR data, (c) represents the prediction on the Radar data based on concatenation
and speed information only and (d) represents the network prediction on the Radar data after the proposed preprocessing
module. The prediction is applied on the pointcloud data from the nuScenes dataset.
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
540

(a)
(b)
(c)
Figure 5: A comparison between the results of (a) the LiDAR , (b) the normal concatenated Radar and (c) the Radar after the
proposed module. The data was extracted from the mini dataset version from nuScenes to test the proposed concept.
Augmented Radar Points Connectivity based on Image Processing Techniques for Object Detection and Classification
541

les can get a LiDAR like performance, if not bet-
ter, using the serial production automotive Radars and
Cameras.
6 CONCLUSION
In this paper, an enhancement preprocessing module
has been proposed for radar data to be able to en-
hance the object classification performance. The pro-
posed theory was tested on the network architecture
based on fpn resnet from (Dung, 2020) and the results
showed that indeed the proposed module provided a
surge in performance compared to just the radar data
without the module and a significant close-in on the
LiDAR performance compared to the ground-truth
data.
As for future work, the proposed algorithm is to be
extended to run on the 8 classes on the Leaderboard of
the nuScenes evaluation server. Furthermore, in order
to improve the accuracy of the object classification to
surpass the LiDAR performance, the radar data is to
be fused with the camera to surpass the LiDAR per-
formance on its own.
REFERENCES
Caesar, H., Bankiti, V., Lang, A. H., Vora, S., Li-
ong, V. E., Xu, Q., Krishnan, A., Pan, Y., Baldan,
G., and Beijbom, O. (2019). nuscenes: A multi-
modal dataset for autonomous driving. arXiv preprint
arXiv:1903.11027.
Comer, M. L. and Delp III, E. J. (1999). Morphological op-
erations for color image processing. Journal of elec-
tronic imaging, 8(3):279–289.
Danzer, A., Griebel, T., Bach, M., and Dietmayer, K.
(2019). 2d car detection in radar data with pointnets.
In 2019 IEEE Intelligent Transportation Systems Con-
ference (ITSC), pages 61–66. IEEE.
Dung, N. M. (2020). Super-fast-
accurate-3d-object-detection-pytorch.
https://github.com/maudzung/Super-Fast-Accurate-
3D-Object-Detection.
Geiger, A., Lenz, P., and Urtasun, R. (2012). Are we ready
for autonomous driving? the kitti vision benchmark
suite. In 2012 IEEE Conference on Computer Vision
and Pattern Recognition, pages 3354–3361. IEEE.
Kim, W., Cho, H., Kim, J., Kim, B., and Lee, S. (2020).
Yolo-based simultaneous target detection and classi-
fication in automotive fmcw radar systems. Sensors,
20(10):2897.
Knott, E. F., Schaeffer, J. F., and Tulley, M. T. (2004). Radar
cross section. SciTech Publishing.
Li, P., Zhao, H., Liu, P., and Cao, F. (2020). Rtm3d:
Real-time monocular 3d detection from object key-
points for autonomous driving. arXiv preprint
arXiv:2001.03343, 2.
Mohammed, A. S., Amamou, A., Ayevide, F. K.,
Kelouwani, S., Agbossou, K., and Zioui, N. (2020).
The perception system of intelligent ground vehicles
in all weather conditions: a systematic literature re-
view. Sensors, 20(22):6532.
Nabati, R. and Qi, H. (2020). Centerfusion: Center-based
radar and camera fusion for 3d object detection. arXiv
preprint arXiv:2011.04841.
Palffy, A., Dong, J., Kooij, J. F., and Gavrila, D. M. (2020).
Cnn based road user detection using the 3d radar cube.
IEEE Robotics and Automation Letters, 5(2):1263–
1270.
Redmon, J. and Farhadi, A. (2018). Yolov3: An incremental
improvement. arXiv preprint arXiv:1804.02767.
Wang, L., Chen, T., Anklam, C., and Goldluecke, B. (2020).
High dimensional frustum pointnet for 3d object de-
tection from camera, lidar, and radar. In 2020 IEEE In-
telligent Vehicles Symposium (IV), pages 1621–1628.
IEEE.
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
542
