
ETL: Efficient Transfer Learning for Face Tasks
Thrupthi Ann John
1 a
, Isha Dua
1 b
, Vineeth N. Balasubramanian
2
and C. V. Jawahar
1
1
Center for Visual Information Technology, International Institute of Information Technology, Hyderabad, India
2
Department of Computer Science and Engineering, Indian Institute of Technology, Hyderabad, India
Keywords:
Face Tasks, Transfer Learning, Efficient Transfer Learning, Face Recognition, Expression Recognition, Age
Prediction, Gender Prediction, Head Pose.
Abstract:
Transfer learning is a popular method for obtaining deep trained models for data-scarce face tasks such as
head pose and emotion. However, current transfer learning methods are inefficient and time-consuming as
they do not fully account for the relationships between related tasks. Moreover, the transferred model is large
and computationally expensive. As an alternative, we propose ETL: a technique that efficiently transfers a
pre-trained model to a new task by retaining only cross-task aware filters, resulting in a sparse transferred
model. We demonstrate the effectiveness of ETL by transferring VGGFace, a popular face recognition model
to four diverse face tasks. Our experiments show that we attain a size reduction up to 97% and an inference
time reduction up to 94% while retaining 99.5% of the baseline transfer learning accuracy.
1 INTRODUCTION
Deep neural networks are widespread in machine
learning, achieving state-of-the-art results in most
face-related tasks. However, they are known to
be highly data and compute-hungry. Massive face
datasets with millions of images, such as VGG-Face2
(Cao et al., 2018) which contains 3M images, or Ms-
Celeb-1M (Guo et al., 2016) which has 10M images
partially solve the first problem. While large datasets
exist for face tasks such as recognition, other tasks
such as age or emotion recognition have compara-
tively very little publicly available data due to the dif-
ficulty of collecting and annotating data. Thus, trans-
fer learning is popular, where we take a model trained
on a ‘primary task’ with lots of data and transfer it to a
secondary task using finetuning. However, the result-
ing model is still large and computationally intensive,
and the transfer learning process is time-consuming
and does not fully utilize the learned filter informa-
tion from the primary model.
Previously, many papers (Oquab et al., 2014;
Razavian et al., 2014) have shown the generalization
capability of deep convolution network across various
tasks. This is possible because tasks are often related,
and when a deep neural network learns to predict a
given task, the feature representation it learns can be
a
https://orcid.org/0000-0002-8557-6564
b
https://orcid.org/0000-0001-5494-059X
adapted to other similar tasks to varying degrees. Sev-
eral efforts in recent years (Donahue et al., 2014;
Khorrami et al., 2015; Long et al., 2014; Zhou et al.,
2014) have found such relationships between tasks
that are diverse but related, such as object detection
to image correspondence (Long et al., 2014), scene
detection to object detection (Zhou et al., 2014) and
expression recognition to facial action units (Khor-
rami et al., 2015). Similarly, it is no new fact that
tasks in the face domain are highly related to each
other. As much as face tasks have to deal with many
variations in images, different face tasks (such as face
recognition, pose estimation, age estimation, emotion
detection) operate on input data that are fairly similar
to each other (John et al., 2021). These face tasks at-
tempt to capture fine-grained differences between the
images. Since the tasks are related and come from the
same domain, learning one task can help learn other
tasks.
To this end, we propose ETL: an efficient transfer
learning method for faces that is based on understand-
ing the impact of different filters in a convolutional
layer of a primary model with respect to the secondary
tasks for which the model is not trained. Figure 1 il-
lustrates our method. We identify convolutional fil-
ters from the primary model that are not relevant to
the secondary task using lasso regression and remove
them in a one-pass pruning step. The resulting sparse
model is then fine-tuned for the respective secondary
248
John, T., Dua, I., Balasubramanian, V. and Jawahar, C.
ETL: Efficient Transfer Learning for Face Tasks.
DOI: 10.5220/0010907700003124
In Proceedings of the 17th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2022) - Volume 5: VISAPP, pages
248-257
ISBN: 978-989-758-555-5; ISSN: 2184-4321
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

Figure 1: Pipeline for efficient transfer of parameters from model trained on primary task like face-recognition to model for
secondary task including gender, emotion, head pose and age in one pass. The ETL technique identifies and preserves the task
related filters only which in turn results in highly sparse network for efficient training of face related tasks.
task. Our method significantly reduces the training
time as compared to training from scratch or stan-
dard transfer learning and produces computationally
light models without compromising on performance.
The proposed approach has application in various do-
mains including ADAS (Dua et al., 2019; Dua et al.,
2020b; Dua et al., 2020a) which requires efficient im-
plementation of face algorithms in real time applica-
tions. The proposed transfer learning technique has
the following advantages:
1. Rapid Transfer Learning. Our approach is non-
iterative, as we identify all non-relevant filters in
a single pass using lasso regression, unlike other
pruning methods which iteratively prune filters
and fine-tune the model.
2. Light-weight Models. Our approach achieves
high compression-ratio, which results in faster
training times and real-time inference times with-
out compromising on accuracy, which is impor-
tant for deployment to low-powered edge devices.
3. Requires Less Data. ETL leverages existing fil-
ters from primary models to train models on tasks
with less available data.
We conduct extensive experiments to validate our
proposed approach and compare it to the standard
transfer learning algorithm. We present our results on
multiple face datasets, covering secondary tasks like
age, gender, emotions and head pose, for which large
datasets do not exist.
2 RELATED WORK
Transfer Learning: In traditional transfer learning
(Bengio, 2012; Bengio et al., 2011; Caruana, 1995;
Aytar and Zisserman, 2011; Lim et al., 2011; Oquab
et al., 2014; Tommasi et al., 2010), a model trained on
a base task is finetuned on a target data set/task. Sev-
eral exploratory studies have investigated best poli-
cies and practices for transfer learning by conduct-
ing large-scale experiments on various tasks. (Zamir
et al., 2018) use a computational approach to recom-
mend the best transfer learning policy between a set
of source and target tasks. They also find structural re-
lationships between vision tasks using this approach.
(Yosinski et al., 2014) provide many recommenda-
tions for best practices in transfer learning. They
quantify the degree to which a particular layer is gen-
eral or specific, i.e., how well features at that layer
transfer from one task to another. They also quantify
the ‘distance’ between different tasks using a compu-
tational approach.
Lightweight Convolution Models: Current deep
learning models show impressive performance at the
cost of having a lot of parameters, which makes them
energy-inefficient and challenging to deploy on low-
end devices. To date, several studies have investi-
gated various architectures for lightweight convolu-
tion models for faster training with minimal loss in
performance. (Szegedy et al., 2015) proposed incep-
tion modules which decrease the channels to expen-
sive 3x3 convolutions. (Chollet, 2017) and (Howard
ETL: Efficient Transfer Learning for Face Tasks
249
et al., 2017) took this further to make 3x3 convo-
lutions completely depthwise separable and sparse.
(Iandola et al., 2016) further reduced parameters by
downsampling late in the network so that convolu-
tion layers have large activation. (Hitawala, 2018),
(Zhang et al., 2018) and (Wu et al., 2018) em-
ployed grouped convolutions to get efficient mod-
els. Recently, (Duong et al., 2019b) and (Sharma
and Foroosh, 2020) proposed lightweight CNN ar-
chitectures designed for face tasks. An alternative
to specially designed CNN architectures is quan-
tized networks (Hubara et al., 2017; Gong et al.,
2014; Kim and Smaragdis, 2016; Rastegari et al.,
2016; Miyashita et al., 2016) which are neural net-
works with extremely low precision. They replace
most arithmetic operations with bitwise operations
and drastically reduce memory and power consump-
tion.
Another strategy is to start with a massive net-
work and reduce its size using pruning or knowledge
distillation. Pruning involves removing connections
from a complete network based on some ranking cri-
terion to obtain a sparse network with similar perfor-
mance as the initial network. Connections may be
pruned at different resolutions, such as at the neuron
or filter level. Recent research (Li et al., 2016; Luo
et al., 2018; He et al., 2018) explored various crite-
ria for ranking convolutional filters and removed the
bottom k% of the filters iteratively. A notable work
is (He et al., 2017), which selects filters by a lasso
regression-based method and least-square reconstruc-
tion in an iterative manner. In contrast, we use lasso
regression to select filters in one pass. Some works
(Lee et al., 2019; Zhang and Stadie, 2020) pruned
connections in one shot, but they operated on the neu-
ron resolution. Recently, various works approached
pruning using the ’Lottery Ticket Hypothesis’ (Fran-
kle and Carbin, 2019) which naturally uncovers sub-
networks whose initialization made them capable of
training effectively.
On the other hand, knowledge distillation starts
with a large trained ’teacher’ model and transfers
the knowledge to a smaller ’student’ model. The
student model is trained on the output distribution
of the teacher model instead of the ground truth la-
bels. Several works (Jin et al., 2019; Antipov et al.,
2017; Duong et al., 2019a) achieved impressive per-
formance with lightweight models using knowledge
distillation on face tasks such as recognition, detec-
tion and age estimation.
Efficient Transfer Learning: While these ap-
proaches solve storage inefficiency, computational
complexity, and power consumption problems, they
are not designed for task transfer. Recent works in
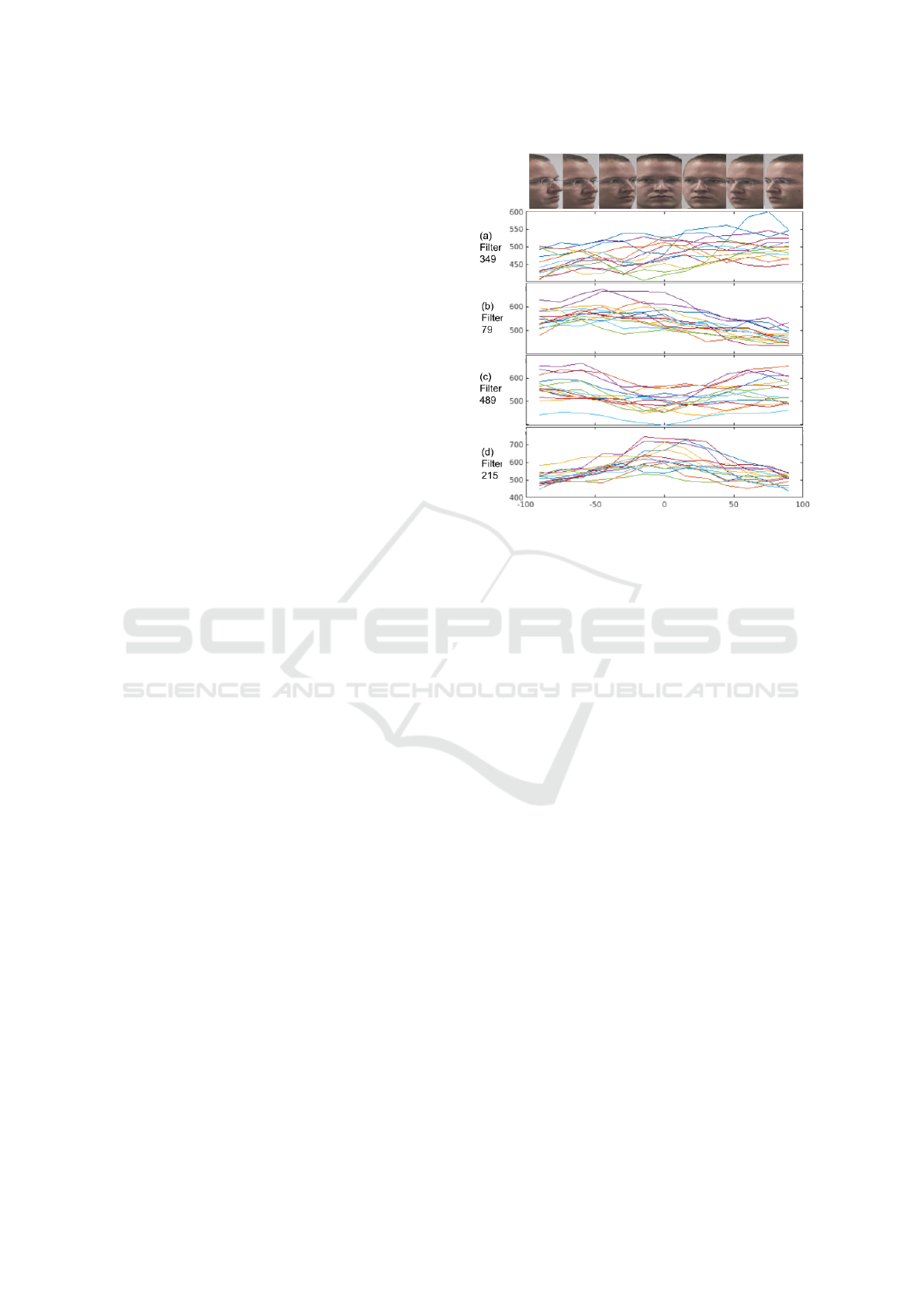
Figure 2: The figure shows the correlation between yaw an-
gle on Head Pose Image Database and average responses of
a few convolutional filters from the last layer of VGG-Face.
The different lines in each graph represent 15 different iden-
tities: (a) high activation for left-facing faces; (b) high re-
sponse for faces facing right; (c) high response for sideways
faces; (d) high response for frontal faces.
NLP (Houlsby et al., 2019; Guo et al., 2021; Zhang
et al., 2020) focused on efficient incremental learn-
ing, where a few additional neurons per task ensures
that catastrophic forgetting does not occur and the re-
sulting efficient model achieves the performance of
separate complete networks for new tasks. (Wang
and Lan, 2017) uses knowledge distillation to trans-
fer from face recognition to non-classification tasks
of alignment and verification by choosing the appro-
priate initializations and targets. (Molchanov et al.,
2016) is a closely related work to ours which per-
forms pruning and transfer learning at the same time.
They alternate between finetuning and pruning until
the required objective of accuracy versus compression
is reached. They finetune all model parameters ini-
tially, and their approach is iterative and slow, unlike
ETL, which transfers the model in one shot.
3 METHODOLOGY
The current practice to obtain face models for a data-
scarce task is to finetune all the filters of a pre-trained
model for the task. However, this method is ineffi-
cient and resource-hungry. Our method ETL relies
on groups of Cross-Task Aware Filters which form a
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
250

Figure 3: Characteristic curves for all filters of the VGG-Face pre-trained model regressed on gender, emotion, head pose and
age. The gray dot shows the knee point. We observe that regression gives a tiny error using as few as ∼100 filters. Adding
more filters to the regression model does not significantly impact the error, indicating that the additional filters do not capture
much information about gender.
Algorithm 1: Create sparse model by removing se-
lected filters.
Input: Model φ with L convolutional layers
having weights {W
φ
1
,W
φ
2
, ...W
φ
L
},
regression weights {β
1
, β
2
, ...β
L
} of
knee-point LASSO models for each
layer
Output: Sparse model φ
0
1 φ
0
← copy of φ with weights
{W
φ
0
1
,W
φ
0
2
, ...W
φ
0
L
}
2 for each convolutional layer l of φ do
3 n
l
← number of non-zero elements of β
l
4 for each non-zero element i in β
l
and j=1
to n
l
do
5 W
φ
0
l
[ j, :, :, :] ← β
l
[i]W
φ
l
[i, :, :, :]
6 if l < L then
7 W
φ
0
l+1
[:, j, :, :] ← W
φ
0
l+1
[:, i, :, :]
8 else
9 Let W
φ
L+1
∈ R
C
L+1
×C
L+2
be the
first linear layer of model φ
10 W
φ
0
L+1
[ j, :] ← W
φ
L+1
[i, :]
11 end
12 end
13 end
small percentage of all the model filters. ETL identi-
fies the optimum filter sets and finetunes them on the
new task. The rest of the filters are discarded before
finetuning, which results in a compact model with re-
duced training time. In the sections below, we show
the existence of such filters and discuss our proposed
procedure for Efficient Transfer Learning.
3.1 Motivation
Do models trained on a face task like recognition con-
tain information about other related face tasks? Ex-
periments show that some convolutional filters (chan-
nels of a convolutional layer) of face recognition
models learn to predict related face tasks such as
head pose, age and gender without additional super-
vision. We call these filters Cross-task Aware Filters
(CRAFTs). We demonstrate the presence of CRAFTs
with the following experiment. The VGG-Face model
(Parkhi et al., 2015) is trained for face recognition
on 2.6 million images. We find CRAFTs for head
pose in its final convolutional layer using the Head
Pose Image Database (Gourier et al., 2004), which
has face images with all attributes kept constant ex-
cept head pose. We pass the dataset images through
the model and plot the mean of each final layer filter
activation map against the yaw of the head. Figure
2 shows some highly correlated filter activations w.r.t
yaw. Some filters give a high response to front-facing
images, whereas others respond strongly to face im-
ages turned to one side. These CRAFTs formed in
the face recognition model without additional super-
vision or explicit training for yaw. We can use them
for transferring the model to predict the yaw of the
head.
The following sections discuss how we find the
optimal CRAFT sets for different secondary tasks like
Age, Head Pose, Gender and Emotions and use them
for efficient transfer learning.
3.2 Finding Optimal Sets of CRAFTs
We now find the optimal CRAFT sets which predict
secondary tasks like Age, Head Pose, Gender and
Emotion. Let D = (I,Y ) be a dataset for a secondary
task where I ∈ R
N×3×W ×H
is the set of N dataset im-
ages and Y ∈ R
N
is the corresponding ground-truth
values. Consider the l
th
convolutional layer of a
model φ having weights W ∈ R
C
l+1
×C
l
×k×k
, which has
C
l+1
output channels/filters. Let φ
l
(I) ∈ R
N×C
l+1
×w×h
be the activation of layer l. Let X ∈ R
N×C
be the av-
erage activations:
X =
1
wh
w
∑
i=1
h
∑
j=1
φ
l
(I)[:, :, i, j] (1)
ETL: Efficient Transfer Learning for Face Tasks
251

We need to choose groups of filters whose acti-
vations are highly correlated with Y . One way to do
this is to rank each filter group based on a correlation
coefficient ρ and pick the highest-ranked filters.
ρ
c
=
Cov(X[:, c],Y )
σ
X[:,c]
σ
Y
(2)
where X[:, c] ∈ R
N
is the activation of the c
th
fil-
ter. However, individually picking filters results in a
greedy solution as we do not consider the interdepen-
dence of filters. Instead of exhaustively checking all
groups of filters in a layer, we use LASSO (Tibshirani,
1996), an L
1
-regularized regression method which se-
lects a subset of filters that best predict Y using the
objective:
min
β
0
,β
1
2N
N
∑
i=1
(Y
i
− β
0
− X
T
i
β
T
i
)
2
+ λ
p
∑
j=1
|β
i
|
(3)
where Y
i
is the ground truth of sample i, X
i
∈ R
C
l+1
is the global average-pooled activation of sample i,
β ∈ R
C
l+1
is the LASSO regression weight vector and λ
is a non-negative regularization parameter which de-
termines the sparseness of the regression weights β.
The number of filters chosen decreases with an in-
crease in λ, as more coefficeints of β become zero.
3.3 Characteristic Curves
Choosing a different λ for each layer is non-trivial as
a change in λ does not cause a corresponding change
in error. In this section, we define a global hyperpa-
rameter that balances the trade-off between sparsity
and error, eliminating the need for per-layer sensitiv-
ity parameters.
To see how error varies with sparsity, we create
characteristic curves for each layer, which is a plot
of the sparsity of filters versus the error for different
values of λ. We train 100 LASSO models by varying
the λ such that the largest λ just makes all the coeffi-
cients zero. The rest of the λ values are chosen using
a geometric sequence such that the ratio of largest to
smallest λ is 1e+4. Figure 3 shows some examples of
characteristic curves for various secondary tasks. We
notice that the characteristic curves are flat-bottomed
for some tasks, i.e. there is no significant change in er-
ror as the sparsity increases. The ‘shape’ of the char-
acteristic curves vary with the secondary task.
We define a global parameter γ, which is the max-
imum allowed increase in error. We define the knee
point of the curve k as the λ value that maximizes the
sparsity while keeping the error within limits.
k =min
i
num(i) such that
RMSE(i) −min(r) < γ(max(r) − min(r))
(4)
where i is the λ value at a point on the characteristic
curve , num(i) is the number of filters chosen when
λ = i, RMSE(i) is the RMS error of the LASSO model
with λ = i and min(r) and max(r) are the minimum
and maximum RMS error values for all the LASSO
models in the curve respectively. A higher γ indicates
that the transferred model will be larger with lower
error and vice versa. We calculate the λ value at knee-
point k for each layer using the chosen γ parameter.
3.4 Obtaining a Sparse Model
In this step, we discard all the filters not chosen by
the LASSO model with λ = k for each convolutional
layer of the model. We follow the procedure in (Li
et al., 2017). Consider the l
th
convolutional layer of
the model φ whose kernel size is k
l
× k
l
. Its weight
matrix W is of size C
l+1
×C
l
× k
l
× k
l
where C
l
refers
to the input channels of layer l and C
l+1
is the number
of output channels of layer l, or the input channels of
layer l + 1. The weight matrix of the l + 1
th
layer
is W
l+1
∈ R
C
l+2
×C
l+1
×k
l+1
×k
l+1
. In order to remove
the i
th
filter from layer l, the output channel weight
W
l
[i, :, :, :] is removed. The corresponding input chan-
nel weight W
l+1
[:, i, :, :] is removed from layer l + 1.
We remove filters from all the layers in one shot ac-
cording to the LASSO model at the chosen knee point
k. Let β be the LASSO regression weight vector and
t ∈ 1..C
l+1
be the index of the filters chosen when
λ = k, which are the non-zero coefficients of β. The
new weight vector of layer l is given by
W
0
l
= β[t]W
l
[t, :, :, :] (5)
The detailed algorithm is given in Algorithm 1.
3.5 Efficient Transfer Learning
Our complete pipeline is given in Figure 1. We be-
gin with an initial model φ pre-trained on a primary
task D
1
. Let D
2
= (I,Y ) be the secondary task. We
first pass the dataset images I through the model φ and
collect the activations at each layer {X
1
, X
2
, ..., X
L
} ac-
cording to Equation 1. We then plot the characteris-
tics curve and find the knee-point k
l
for each layer
using Equation 4. We generate a sparse model φ
0
by
keeping only filters corresponding to the non-zero co-
efficients of the regression weights β
l
of the LASSO
models with λ = k
l
, according to Algorithm 1. Fi-
nally, we finetune the sparse model φ
0
on the dataset
D
2
to obtain the efficient transferred model φ
∗
.
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
252

Table 1: The table shows the comparison of ETL with Transfer Learning in terms of accuracy, FLOPS, size, and inference
time per image on CPU for different face tasks, including gender, emotion, head pose, and age.The percentage reduction in
metrics is given in the brackets. We observe a significant drop in model size, which leads to faster inference time with a slight
loss in the model’s accuracy.
Gender Emotion Head pose Age
Baseline transfer
learning (with full
fine tuning)
Accuracy 97.06 65.92 95.7 51.8
FLOPS 7.38E+11 7.38E+11 7.38E+11 7.38E+11
Size 5.80E+08 5.80E+08 5.80E+08 5.80E+08
Inference 5.469 5.527 5.5169 5.313
ETL (Our method
with sparse fine
tuning)
Accuracy 96.62 (0.5%) 55.16 (16.3%) 94.58 (1.2%) 46.96 (9.3%)
FLOPS 3.26E+11 (55.8%) 2.06E+11 (72.1%) 4.25E+11 (42.4%) 4.16E+11 (43.6%)
Size 2.59E+07 (95.5%) 1.64E+07 (97.2%) 3.39E+07 (94.2%) 3.32E+07 (94.3%)
Inference 0.528 (90.3%) 0.373 (94.2%) 0.4626 (91.6%) 0.47 (91.2%)
4 EXPERIMENTS AND RESULTS
This section shows that ETL achieves fast and pa-
rameter efficient transfer learning for face tasks when
compared to the baseline transfer learning method.
Experiments on several face datasets show that the
ETL models retains up to 99.5% of the baseline ac-
curacy while reducing the size of the baseline model
by 97%, thereby reducing the CPU inference time by
94%.
4.1 Evaluation Metrics
For our experiments, we measure the accuracy, the
FLOPs for a forward pass, the number of parameters
of the model, and the inference time as the criteria to
compare our methods. FLOPS: We calculate FLOPs
as the number of multiplication operations required
for a forward pass. For a model with M convolutional
layers and N linear layers, we calculate the FLOPs as
follows:
FLOPS =
M
∑
i=1
ConvFLOPS
i
+
N
∑
j=1
LinFLOPS
j
(6)
ConvFLOPS
l
= o
l
× i
l
× k
l
× k
l
× w
l
× h
l
(7)
LinFLOPS
l
= n
input
l
× n out put
l
(8)
Here, o
l
and i
l
refer to the number of output and input
channels, the kernel is of size k
l
×k
l
and the activation
map is of size o + l × w
l
× h
l
of convolutional layer l;
and n input
l
and n out put
l
are the number of input
and output features for linear layer l.
Size of the network is the sum of the sizes of
its stored parameters, consisting of various layers’
weights and biases. It affects the resource and time
required for training the deep models. Inference Time
is the time required to predict the output of one im-
age at test time on a CPU. A low inference time signi-
fies the possibility of using the deep model on devices
with restricted resources.
4.2 Experimental Setup
We use the public, pre-trained VGGFace (Parkhi
et al., 2015) model for face recognition as our base
model. Using our efficient transfer learning proce-
dure, we transfer the VGGFace model to the four
tasks mentioned above of gender, emotion, head pose,
and age. We compare the results obtained using the
proposed technique (ETL) with the baseline transfer
learning technique, where all the filters are finetuned
for the new task.
We conduct experiments on four different face
datasets. Annotated Facial Landmarks in the Wild
(AFLW) (Martin Koestinger and Bischof, 2011) is
a large-scale dataset of face images in the wild an-
notated with head pose and landmarks. We use the
‘yaw’ component of the head pose expressed in radi-
ans for our task. AgeDB is a collection of face im-
ages annotated with the age of the person. The val-
ues range from 0 to 101. The AFEW-VA database for
valence and arousal estimation in-the-wild (Kossaifi
et al., 2017; A. Dhall and Gedeon, 2012) is a collec-
tion of per-frame annotations of valence and arousal
for 600 challenging video clips extracted from feature
films. We treat this dataset as a collection of images
(without the temporal component) and use ‘valence’
labels as our task. The CelebA dataset (Liu et al.,
2015) consists of 202,599 face images for which the
ground truth values of 40 attributes are provided. We
use the attribute ‘gender’ in our experiments. The data
sets are randomly split into 75% for training and 25%
for testing.
4.3 Results
We compare our proposed ETL procedure with base-
line transfer learning for the tasks of gender, emotion,
head pose and age. Table 1 summarizes the results of
ETL with γ = 0.01. We observe a significant reduc-
ETL: Efficient Transfer Learning for Face Tasks
253
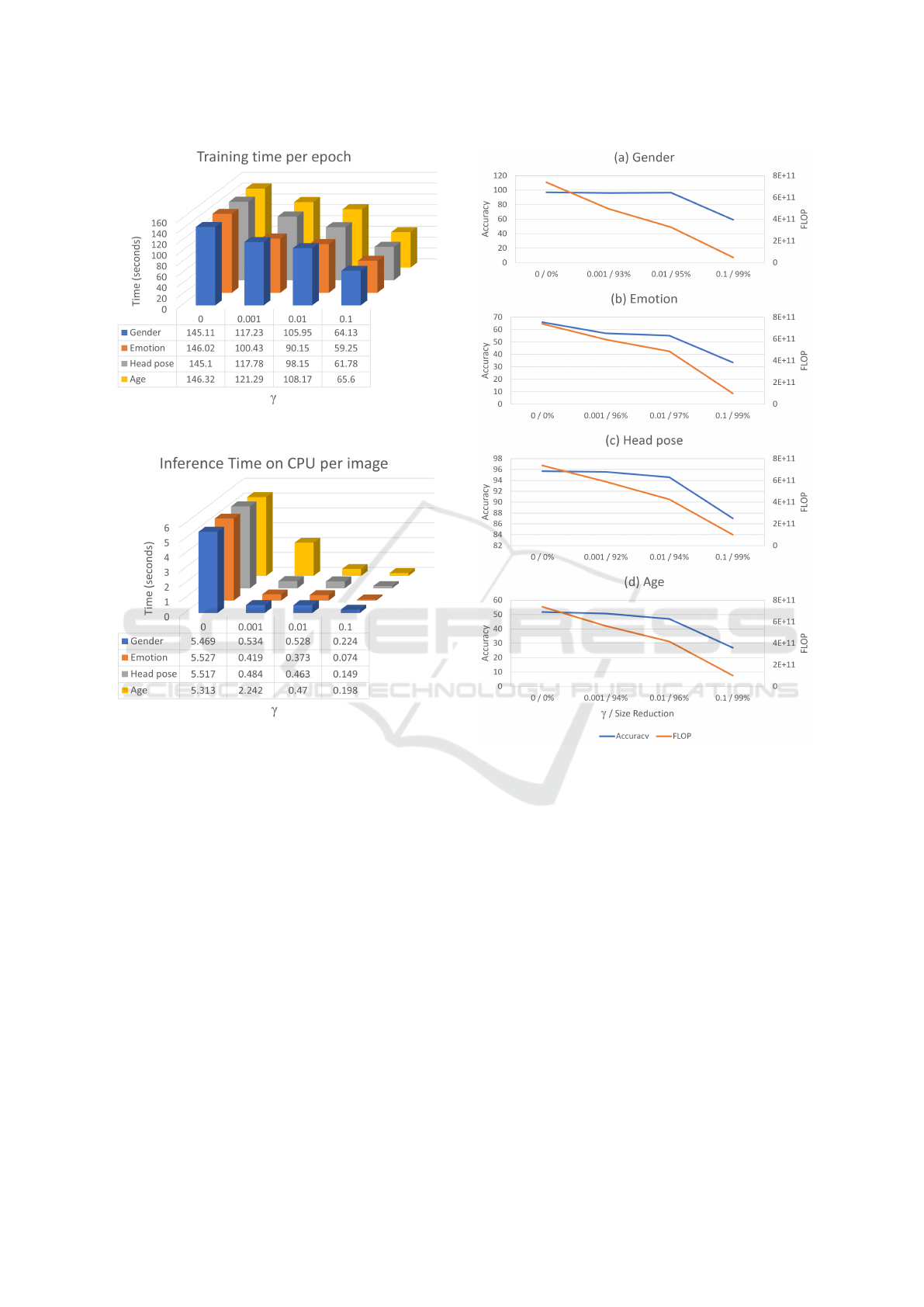
Figure 4: Training time per epoch on GPU for threshold
values between 0 to 0.1.
Figure 5: Inference time on CPU per image at different
threshold values. The increase in threshold value results in
higher real-time performance.
tion of up to 97% in size and 72% in the computa-
tional complexity without much loss of accuracy, as
we can remove many convolutional filters from each
layer without impacting the performance. We observe
from Figure 3 that the characteristics curves for gen-
der and head pose are flat, indicating that most of the
information about secondary tasks exists in very few
filters of each convolutional layer of the VGG-Face
network. Thus, the performance of the ETL models
reaches up to 99.9% of the baseline models. The char-
acteristics curves for emotion and age are not as flat,
resulting in a higher performance drop.
The value of γ controls the model compactness;
higher γ results in fewer parameters at a possible cost
to the performance. To explore this trade-off, we con-
sider different γ values and compare their effect on
accuracy, FLOPs and size to the baseline. Figure 6
presents our results. Using VGGFace as the base net-
Figure 6: The four figures show the accuracy and computa-
tional complexity for the VGG-Face model pruned with dif-
ferent thresholds(γ). For each task, we varied the threshold
from 0.1 to 0.001. A threshold of 0 indicates an unpruned
network, and a threshold of 0.1 corresponds to a highly
sparse network with 99% of filters pruned. We have shown
the accuracy on the left axis and computational cost (num-
ber of flops) on the right axis. The X-axis shows the per-
centage reduction in size along with the respective thresh-
old values on the X-axis. The four figures correspond to the
different face tasks: a) Gender b) Emotion c) Head pose d)
Age.
work, we applied our ETL procedure for four tasks:
gender, emotion, head pose and age with γ values of 0,
0.1, 0.01 and 0.001. The figure shows that the FLOPs
reduce monotonically as γ changes. We observe that
as γ increases, the model size and computational com-
plexity reduces significantly with only a minor reduc-
tion of accuracy. Thus, the threshold is a reliable way
to tune the ETL algorithm and get the desired compro-
mise between compression ratio and accuracy. In our
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
254

experiments, we observed a γ value of 0.01 as ideal.
Figure 4 shows the training time per epoch for dif-
ferent values of γ, which reduces with an increase in
γ as fewer filters get chosen. We observe a per-epoch
reduction of 32% for γ = 0.01 for head pose. This
speeds up the finetuning step, resulting in accelerated
transfer learning. Figure 5 presents the inference time
on CPU per image at different γ values. A dramatic
decrease in inference time of 90% enables the ETL
models to perform inference in real-time, which is im-
portant for deploying on low-powered edge devices.
5 CONCLUSION
In this work, we have presented ETL: an efficient pro-
cedure for transfer learning of face tasks. ETL pro-
duces lightweight and accurate models for face tasks
without large datasets by efficient pruning and trans-
fer learning foundation face models. It has only one
tunable hyperparameter, which adjusts the trade-off
between compression ratio and accuracy, making it
predictable and easy to use. The high compression
ratio makes real-time inference on the CPU possible,
which is essential for deploying deep models on low-
resource edge devices.
REFERENCES
A. Dhall, R. Goecke, S. L. and Gedeon, T. (2012). Collect-
ing large, richly annotated facial-expression databases
from movies. IEEE MultiMedia.
Antipov, G., Baccouche, M., Berrani, S.-A., and Dugelay,
J.-L. (2017). Effective training of convolutional neu-
ral networks for face-based gender and age prediction.
Pattern Recognit.
Aytar, Y. and Zisserman, A. (2011). Tabula rasa: Model
transfer for object category detection. In Computer
Vision (ICCV), 2011 IEEE International Conference
on.
Bengio, Y. (2012). Deep learning of representations for
unsupervised and transfer learning. In Proceedings
of ICML Workshop on Unsupervised and Transfer
Learning.
Bengio, Y., Bergeron, A., Boulanger-Lewandowski, N.,
Breuel, T., Chherawala, Y., Cisse, M., Erhan, D., Eu-
stache, J., Glorot, X., Muller, X., et al. (2011). Deep
learners benefit more from out-of-distribution exam-
ples. In Proceedings of the Fourteenth International
Conference on Artificial Intelligence and Statistics.
Cao, Q., Shen, L., Xie, W., Parkhi, O. M., and Zisserman,
A. (2018). Vggface2: A dataset for recognising faces
across pose and age. In 2018 13th IEEE international
conference on automatic face & gesture recognition
(FG 2018), pages 67–74. IEEE.
Caruana, R. (1995). Learning many related tasks at the
same time with backpropagation. In Advances in neu-
ral information processing systems.
Chollet, F. (2017). Xception: Deep learning with depth-
wise separable convolutions. 2017 IEEE Conference
on Computer Vision and Pattern Recognition (CVPR).
Donahue, J., Jia, Y., Vinyals, O., Hoffman, J., Zhang, N.,
Tzeng, E., and Darrell, T. (2014). Decaf: A deep con-
volutional activation feature for generic visual recog-
nition. In International conference on machine learn-
ing.
Dua, I., John, T. A., Gupta, R., and Jawahar, C. (2020a).
Dgaze: Driver gaze mapping on road. In 2020
IEEE/RSJ International Conference on Intelligent
Robots and Systems (IROS).
Dua, I., Nambi, A. U., Jawahar, C. P., and Padmanabhan,
V. N. (2019). Autorate: How attentive is the driver?
2019 14th IEEE International Conference on Auto-
matic Face and Gesture Recognition (FG 2019), pages
1–8.
Dua, I., Nambi, A. U., Jawahar, C. V., and Padmanabhan,
V. N. (2020b). Evaluation and visualization of driver
inattention rating from facial features. IEEE Transac-
tions on Biometrics, Behavior, and Identity Science.
Duong, C. N., Luu, K., Quach, K. G., and Le, N. T. H.
(2019a). Shrinkteanet: Million-scale lightweight face
recognition via shrinking teacher-student networks.
ArXiv.
Duong, C. N., Quach, K. G., Le, N. T. H., Nguyen, N., and
Luu, K. (2019b). Mobiface: A lightweight deep learn-
ing face recognition on mobile devices. 2019 IEEE
10th International Conference on Biometrics Theory,
Applications and Systems (BTAS).
Frankle, J. and Carbin, M. (2019). The lottery ticket hy-
pothesis: Finding sparse, trainable neural networks.
arXiv: Learning.
Gong, Y., Liu, L., Yang, M., and Bourdev, L. D. (2014).
Compressing deep convolutional networks using vec-
tor quantization. ArXiv.
Gourier, N., Hall, D., and Crowley, J. L. (2004). Estimating
face orientation from robust detection of salient facial
features. In ICPR International Workshop on Visual
Observation of Deictic Gestures.
Guo, D., Rush, A. M., and Kim, Y. (2021). Parameter-
efficient transfer learning with diff pruning. In
ACL/IJCNLP.
Guo, Y., Zhang, L., Hu, Y., He, X., and Gao, J. (2016). Ms-
celeb-1m: A dataset and benchmark for large-scale
face recognition. In European conference on com-
puter vision, pages 87–102. Springer.
He, Y., Liu, P., Wang, Z., Hu, Z., and Yang, Y. (2018). Filter
pruning via geometric median for deep convolutional
neural networks acceleration. 2019 IEEE/CVF Con-
ference on Computer Vision and Pattern Recognition
(CVPR), pages 4335–4344.
He, Y., Zhang, X., and Sun, J. (2017). Channel pruning for
accelerating very deep neural networks. 2017 IEEE
International Conference on Computer Vision (ICCV),
pages 1398–1406.
ETL: Efficient Transfer Learning for Face Tasks
255

Hitawala, S. (2018). Evaluating resnext model architecture
for image classification. ArXiv.
Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B.,
de Laroussilhe, Q., Gesmundo, A., Attariyan, M., and
Gelly, S. (2019). Parameter-efficient transfer learning
for nlp. In ICML.
Howard, A. G., Zhu, M., Chen, B., Kalenichenko, D.,
Wang, W., Weyand, T., Andreetto, M., and Adam,
H. (2017). Mobilenets: Efficient convolutional neu-
ral networks for mobile vision applications. ArXiv.
Hubara, I., Courbariaux, M., Soudry, D., El-Yaniv, R., and
Bengio, Y. (2017). Quantized neural networks: Train-
ing neural networks with low precision weights and
activations. ArXiv.
Iandola, F. N., Moskewicz, M. W., Ashraf, K., Han, S.,
Dally, W. J., and Keutzer, K. (2016). Squeezenet:
Alexnet-level accuracy with 50x fewer parameters and
¡1mb model size. ArXiv.
Jin, H., Zhang, S., Zhu, X., Tang, Y., Lei, Z., and Li,
S. (2019). Learning lightweight face detector with
knowledge distillation. 2019 International Confer-
ence on Biometrics (ICB).
John, T. A., Balasubramanian, V. N., and Jawahar, C. V.
(2021). Canonical saliency maps: Decoding deep face
models. ArXiv, abs/2105.01386.
Khorrami, P., Paine, T. L., and Huang, T. S. (2015). Do deep
neural networks learn facial action units when doing
expression recognition? In Proceedings of the 2015
IEEE International Conference on Computer Vision
Workshop (ICCVW).
Kim, M. and Smaragdis, P. (2016). Bitwise neural net-
works. ArXiv.
Kossaifi, J., Tzimiropoulos, G., Todorovic, S., and Pantic,
M. (2017). Afew-va database for valence and arousal
estimation in-the-wild. Image and Vision Computing.
Lee, N., Ajanthan, T., and Torr, P. H. S. (2019). Snip:
Single-shot network pruning based on connection sen-
sitivity. ArXiv, abs/1810.02340.
Li, H., Kadav, A., Durdanovic, I., Samet, H., and Graf, H.
(2017). Pruning filters for efficient convnets. In Pro-
ceedings of the International Conference on Learning
Representations (ICLR).
Li, H., Kadav, A., Durdanovic, I., Samet, H., and Graf, H. P.
(2016). Pruning filters for efficient convnets. ArXiv,
abs/1608.08710.
Lim, J. J., Salakhutdinov, R. R., and Torralba, A. (2011).
Transfer learning by borrowing examples for multi-
class object detection. In Advances in neural informa-
tion processing systems.
Liu, Z., Luo, P., Wang, X., and Tang, X. (2015). Deep learn-
ing face attributes in the wild. In Proceedings of In-
ternational Conference on Computer Vision (ICCV).
Long, J. L., Zhang, N., and Darrell, T. (2014). Do convnets
learn correspondence? In Advances in Neural Infor-
mation Processing Systems.
Luo, J.-H., Zhang, H., yu Zhou, H., Xie, C.-W., Wu, J.,
and Lin, W. (2018). Thinet: Pruning cnn filters for
a thinner net. IEEE Transactions on Pattern Analysis
and Machine Intelligence, 41:2525–2538.
Martin Koestinger, Paul Wohlhart, P. M. R. and Bischof,
H. (2011). Annotated Facial Landmarks in the Wild:
A Large-scale, Real-world Database for Facial Land-
mark Localization. In Proc. First IEEE International
Workshop on Benchmarking Facial Image Analysis
Technologies.
Miyashita, D., Lee, E. H., and Murmann, B. (2016). Convo-
lutional neural networks using logarithmic data repre-
sentation. ArXiv.
Molchanov, P., Tyree, S., Karras, T., Aila, T., and
Kautz, J. (2016). Pruning convolutional neural net-
works for resource efficient transfer learning. ArXiv,
abs/1611.06440.
Oquab, M., Bottou, L., Laptev, I., and Sivic, J. (2014).
Learning and transferring mid-level image represen-
tations using convolutional neural networks. In Pro-
ceedings of the 2014 IEEE Conference on Computer
Vision and Pattern Recognition.
Parkhi, O. M., Vedaldi, A., and Zisserman, A. (2015). Deep
face recognition. In British Machine Vision Confer-
ence.
Rastegari, M., Ordonez, V., Redmon, J., and Farhadi, A.
(2016). Xnor-net: Imagenet classification using bi-
nary convolutional neural networks. In ECCV.
Razavian, A. S., Azizpour, H., Sullivan, J., and Carlsson,
S. (2014). Cnn features off-the-shelf: An astound-
ing baseline for recognition. In Proceedings of the
2014 IEEE Conference on Computer Vision and Pat-
tern Recognition Workshops.
Sharma, A. and Foroosh, H. (2020). Slim-cnn: A light-
weight cnn for face attribute prediction. 2020 15th
IEEE International Conference on Automatic Face
and Gesture Recognition (FG 2020).
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S. E.,
Anguelov, D., Erhan, D., Vanhoucke, V., and Rabi-
novich, A. (2015). Going deeper with convolutions.
2015 IEEE Conference on Computer Vision and Pat-
tern Recognition (CVPR).
Tibshirani, R. (1996). Regression shrinkage and selection
via the lasso. Journal of the Royal Statistical Society.
Series B (Methodological).
Tommasi, T., Orabona, F., and Caputo, B. (2010). Safety
in numbers: Learning categories from few examples
with multi model knowledge transfer. In Proceed-
ings of IEEE Computer Vision and Pattern Recogni-
tion Conference.
Wang, C. and Lan, X. (2017). Model distillation with
knowledge transfer in face classification, alignment
and verification. ArXiv.
Wu, X., He, R., Sun, Z., and Tan, T. (2018). A light cnn
for deep face representation with noisy labels. IEEE
Transactions on Information Forensics and Security.
Yosinski, J., Clune, J., Bengio, Y., and Lipson, H. (2014).
How transferable are features in deep neural net-
works? In Proceedings of the 27th International Con-
ference on Neural Information Processing Systems -
Volume 2.
Zamir, A. R., Sax, A., Shen, W., Guibas, L., Malik, J., and
Savarese, S. (2018). Taskonomy: Disentangling task
VISAPP 2022 - 17th International Conference on Computer Vision Theory and Applications
256

transfer learning. In Proceedings of the IEEE Confer-
ence on Computer Vision and Pattern Recognition.
Zhang, H., Zhao, H., Liu, C., and Yu, D. (2020). Task-to-
task transfer learning with parameter-efficient adapter.
In NLPCC.
Zhang, M. S. and Stadie, B. C. (2020). One-shot pruning of
recurrent neural networks by jacobian spectrum eval-
uation. ArXiv, abs/1912.00120.
Zhang, X., Zhou, X., Lin, M., and Sun, J. (2018). Shuf-
flenet: An extremely efficient convolutional neural
network for mobile devices. 2018 IEEE/CVF Con-
ference on Computer Vision and Pattern Recognition.
Zhou, B., Khosla, A., Lapedriza,
`
A., Oliva, A., and Tor-
ralba, A. (2014). Object detectors emerge in deep
scene cnns. CoRR.
ETL: Efficient Transfer Learning for Face Tasks
257
