
Experimental Verification of Collocation Detection Methods
Galiya S. Ybytayeva
1 a
, Nina F. Khairova
2 b
, Orken Zh. Mamyrbayev
3 c
,
Kuralay Zh. Mukhsina
3 d
and Bagashar Zh. Zhumazhanov
3 e
1
Satbayev University, 22 Satpayev Street, Almaty, 050000, Kazakhstan
2
National Technical University “Kharkiv Polytechnic Institute”, 2 Kirpichov Str., Kharkiv, 61000, Ukraine
3
Institute of Information and Computational Technologies, 28 Shevchenko Str., Almaty, 050010, Kazakhstan
Keywords:
Collocation, Corpus, Corpus Linguistics, Corpora, Association Measures.
Abstract:
The article describes the results of a study to determine the correct phrases in the Kazakh language. The
experiment consisted in the search and analysis of bigrams with frequent verbs, adjectives and nouns of the
Kazakh language. Applying a statistical method to corpus material allows researchers to quantify the data
obtained. The article provides an overview of MI, t-score indicators for calculating the strength of links within
phrases, including their main characteristics. The purpose is to study the combinability characteristics of these
lexical units, to correlate the results obtained on the basis of various association measures on different corpus,
to compare the most popular association measures.
1 INTRODUCTION
In the process of penetration of modern information
and communication technologies into all areas of sci-
ence, in particular, into philological science, the pop-
ularity of using linguistic corpora of texts in the study
of various aspects of the language is growing. In
recent years, a whole range of methodological stud-
ies has appeared in the methodological literature on
teaching schoolchildren and students the lexical and
grammatical side of a foreign language using vari-
ous linguistic corpora (Sysoyev, 2010; Chernyakova,
2012; Ryazanova, 2012). An analysis of this and
other studies shows that the authors have reached a
certain agreement on the conceptual content of the
term “corpus linguistics”. It refers to an organized
collection of texts selected and tagged according to a
specific methodology and presented electronically.
The main attention in our research is paid to the
corpus of parallel texts. In our study, we understand
the corpus of parallel texts as a type of corpus linguis-
tics consisting of a source text in one language and its
translation into another language or languages.
a
https://orcid.org/0000-0002-4243-0928
b
https://orcid.org/0000-0002-9826-0286
c
https://orcid.org/0000-0001-7569-1721
d
https://orcid.org/0000-0002-8627-1949
e
https://orcid.org/0000-0002-5035-9076
This is a linguistic corpus of texts that allows you
to study lexical connectivity or the phenomenon of
word combinations in context.
Recently, in connection with the increasing need
for automated systems, much attention is paid to the
problem of automatic segmentation of word combina-
tions in texts. There are various statistical indicators
to evaluate the compatibility of words. Some dimen-
sions are called associative measures or association
measures. They allow you to calculate the strength of
the connection between the elements of word combi-
nations and are based on the frequency of these word
combinations and the individual words included in
them. Thus, it is possible to calculate some charac-
teristics of the stability of lexical units, which allows
them to be arranged on a conditional scale: from free
combinations to phraseological units. In total, there
are more than 80 measures to assess the strength of the
connectedness of word combinations (Pecina, 2009).
The article is organized as follows. Section 2 is
devoted to the literature review. Section 3 provides an
overview of the statistical method, Section 4 presents
the research methodology, and the final section dis-
cusses the research findings and suggests future plans.
Ybytayeva, G., Khairova, N., Mamyrbayev, O., Mukhsina, K. and Zhumazhanov, B.
Experimental Verification of Collocation Detection Methods.
DOI: 10.5220/0012008900003561
In Proceedings of the 5th Workshop for Young Scientists in Computer Science and Software Engineering (CSSE@SW 2022), pages 13-18
ISBN: 978-989-758-653-8; ISSN: 2975-9471
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
13

2 RELATED WORKS
Although the term “collocation” has recently come
into regular use, it occupies one of the most impor-
tant places in modern linguistics. In a broad sense, it
is a combination of two or more words that tend to
co-occur. Currently, collocations play a leading role
in lexicographic practice (Atkins and Rundell, 2008;
Kilgarriff, 2006). Recently, special collocation dic-
tionaries are being created abroad and in Kazakhstan
(Krishnamurthy, 2006; Smagulova, 2010; Zhanuzak
et al., 2011).
However, existing dictionaries of regular expres-
sions, firstly, do not contain their complete list, and
secondly, they often do it in an insufficiently consis-
tent manner. This is especially true for the Kazakh
language. Therefore, the relevance of works on auto-
matic detection of collocations from texts is undeni-
able.
Currently, we see several important application
tasks that require automated methods for extracting
collocations from large corpora of texts. In particu-
lar, these tasks include the creation of dictionaries and
other lexicographic tools, the creation of ontologies,
language learning, repair of linguistic processors, and
information retrieval.
Let us briefly discuss the concept of the word
combination. There are different definitions of this
concept. In general, many definitions of collocation
are based on the phenomenon of semantic and gram-
matical interdependence of phrase elements (Iordan-
skaya and Mel’chuk, 2007).
The term ”collocation” in the Russian scientific
literature was first used by Akhmanova (Akhmanova,
1996) in the Dictionary of Linguistic Terms. The first
work in Russian linguistics devoted to the study of the
concept of collocation in the material of the Russian
language was the monograph of Borisova (Borisova,
1995).
Kozhakhmetova et al. (Kozhakhmetova et al.,
1988) were worked on the problem of translation of
correct word combinations from the Kazakh language
to a foreign language without loss of meaning and
national-cultural aspect. The scholars published a dic-
tionary of some 2,300 regular expressions. It is effec-
tive to use in verbal translation, but we believe that it
would be more effective if the regular word combina-
tions were divided into meaning categories.
3 STATISTICAL METHOD
Nowadays the term “collocation” is widely used in
corpus linguistics, in which the concept of colloca-
tion is reinterpreted or simplified compared to tradi-
tional linguistics. This approach can be called statisti-
cal. Priority is given to the frequency of coincidences,
so word combinations in corpus linguistics can be de-
fined as statistically persistent phrases. In addition,
a statistically persistent combination can be phraseo-
logical and arbitrary. In recent years, a lot of research
and development on collocations has appeared, ad-
dressing both the theoretical aspects of a statistical ap-
proach to this notion and practical methods of phrase
detection.
This is the emergence of a large representative cor-
pus of texts, allowing to obtain reliable information
on the frequency of a particular combination in the
language as a whole. A high value of the frequency
of matches seems to indicate the stability of the com-
bination. However, this description is not sufficient
to talk about the preferred combinability of certain
words. Therefore, a number of statistical measures
(called “association measures”) have been created to
calculate the strength of the relationship between ele-
ments in a word combination. In general, these mea-
sures take into account both the frequency of match-
ing and other parameters, primarily the frequency in
a given corpus of each individual element.
However, statistics are not enough. The question
needs to be answered as to what other requirements
such statistically stable combinations should meet.
Most corpus managers are able to calculate the
frequency of occurrence of words or word forms and
the frequency of matches. Based on this data, there
are many measures of association.
The total number of these dimensions is counted
in dozens. The values of associative measures can be
seen as indicators of the strength of the syntagmatic
relationship between phrasal elements. See (Evert,
2004) for a description of the most common mea-
sures. MI, t-score is used more frequently than others.
Some case managers allow the calculation of these
measures.
The MI (mutual information) measure introduced
in (Church and Hanks, 1990) compares context-
dependent frequencies, such as randomly occurring
words in a text, with independent frequencies:
MI(n, c) = log
2
f (n, c) · N
f (n) · f (c)
, (1)
here: n – keyword (node); c – collocation; f (n, c) –
frequency of occurrence of keyword n paired with
collocation c; f (n), f (c) – absolute (independent) fre-
quency of keyword n and word c in the corpus (text);
N – total number of word uses in the corpus (text).
If the value of MI(n, c) is greater than a certain
value, then the expression can be considered statisti-
CSSE@SW 2022 - 5th Workshop for Young Scientists in Computer Science Software Engineering
14

cally significant. If MI(n, c) is less than zero, then n
and c are called complementary.
The t-score also takes into account the frequency
of occurrence of a keyword and its combination, an-
swering the question of how non-random the strength
of the association between the word combinations is:
t − score =
f (n, c) −
f (n)· f (c)
N
p
f (n, c)
(2)
4 IDENTIFICATION OF WORD
COMBINATIONS BASED ON
THE STATISTICAL METHOD
The aim of the work is a comparative analysis of dif-
ferent associative measures based on the corpus of the
Kazakh language. In addition, the dependence of the
results (the list of word combinations derived from
the same measure) on the text material (text type) is
investigated.
Our dataset includes a parallel Russian-Kazakh
corpus, which has been developed over three years
(Khairova et al., 2019), and an XML dictionary
of synonyms with criminally related vocabulary
(Khairova et al., 2021). The parallel Kazakh-Russian
corpus includes texts from four news sites of the
Kazakh information Internet space zakon.kz, cara-
van.kz, lenta.kz, nur.kz for the period from April 2018
to June 2021.
At the moment the volume of the parallel Kazakh-
Russian corpus is 3000 texts in Russian and 3000
in Kazakh, including two thousand texts containing
agreed Kazakh-Russian sentences.
We extracted the vocabulary for our XML dic-
tionary of synonyms manually from the English,
Ukrainian, Kazakh and Russian texts on criminal mat-
ters. Seven main thematic categories were identified
for the terms, Movement, Traffic Accident, Injure,
Offense, Arrest, Trial, PD. The choice of categories
was due to the fact that the information resources
from which the texts were taken contained the largest
amount of data on the three criminal areas of “Po-
lice”, “Transfer”, “Crime” and their aforementioned
subspecies. This made it possible to make our dictio-
nary narrowly focused. All terms were also divided
by parts of speech, i.e. only nouns, verbs, adjectives
and word combinations were included in the dictio-
nary. Figure 1 shows a fragment of the dictionary,
which now includes about 650 basic words (over 320
nouns, over 100 adjectives, about 170 verbs and 40
word combinations) and over 2500 synonyms. It is
currently still under active development.
Our study was based on the corpus of news texts
“nur.kz”, “zakon.kz”, “patrul.kz”, “caravan.kz”, “in-
form.kz”, which includes 857 texts.
Table 1 contains data for 15 word combinations
with word “police” sorted by value of MI parame-
ter. The columns of the table, in addition to the word
combination itself, show the following characteris-
tics: Freq Word 1 & Word 2 – frequency of matching,
Freq Word 1 – frequency of word combination, Freq
Word 2 – key word, MI – MI value, T-score – t-score
value.
The analysis of the data in table 1 (15 word com-
binations in total) shows that the ranks of the word
combinations obtained using different indicators do
not coincide.
It should also be noted that different dimensions
affect the frequency of the words composing a word
combination and the frequency of their combinabil-
ity. Thus, MI is considered to be sensitive to low-
frequency words, while t-score is useful for finding
high-frequency word combinations.
We compared the automatically generated word
combinations on different association indices with
data from different dictionaries. The mate-
rial served as collections of 2 nouns without
homonyms (sozdik.kz) and 1 adjective (Kazakh-
Russian, Russian-Kazakh Terminological Dictionary.
Jurisprudence).
We call the above word combinations “correct”.
Below are graphs showing MI values, t-score mea-
surements on the ordinate axis and bigram ranks on
the abscissa axis. Black colour indicates “correct”
word combinations from the dictionary “sozdik.kz”
(4, 10 ranks) and “Kazakh-Russian, Russian-Kazakh
terminological dictionary. Jurisprudence” (rank 7) in-
dicates an additional phrase found in the dictionary.
The same tendency is observed for all obtained
word combinations: the smaller the value of the
measure, the greater the probability that these word
combinations will not be registered as regular word
combinations in dictionaries of the Kazakh language.
Thus, we can say that the compatibility data given in
dictionaries corresponds to the data obtained on the
basis of associative measures.
As a result of the experiment, it seems important
to identify phrases that are not registered in any of the
dictionaries. The analysis of such word combinations
shows that the bigrams located at the top of the list by
degree of probability (sorted in descending order of
one of the dimensions) turn out to be stable, so they
can be included in the list.
As mentioned above, other statistical criterion
methods based on linguistic models should also work.
This idea has been adopted and implemented in the fa-
Experimental Verification of Collocation Detection Methods
15
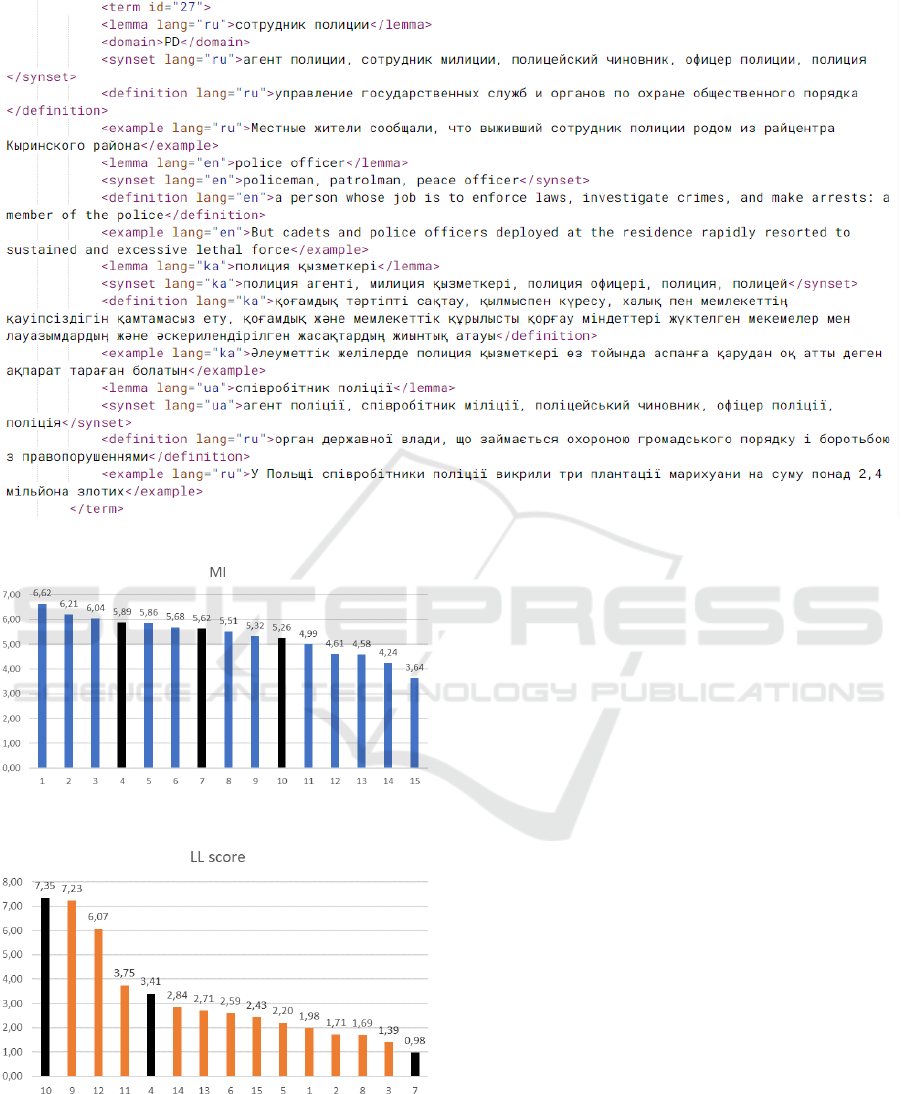
Figure 1: The fragment of the multilingual synonyms dictionary.
Figure 2: Values of the MI measure for collocations with
the word “Police”.
Figure 3: Values of the t-score measure for collocations
with the word “Police”.
mous Sketch Engine (Kilgarriff et al., 2004). It yields
typical word combinations for a given keyword, on
the one hand, due to a syntax restricting the compat-
ibility of words in a given language, and on the other
hand, due to possible laws related to semantics and
linguistic origin.
It turns out that there are few “correct” colloca-
tions, but this is because the vocabulary we have been
relying on is too small, so it needs to be expanded.
We can say that a new vocabulary is needed, which
should contain various regular expressions.
The results of searching and identifying word
combinations of this type are useful for lexicogra-
phers who know how to select different examples for
dictionaries, and for linguists who study vocabulary
and syntax in a certain aspect.
5 CONCLUSION
When comparing the phrases obtained using statisti-
cal methods with dictionaries, the same tendency is
observed: the lower the value of the measure, the
more these phrases are not recorded in dictionaries
of the Kazakh language, and vice versa. Most of the
phrases recorded in dictionaries are at the top of the
list based on one of the measures of association. Thus,
it can be said that the data on stable compatibility
given in dictionaries coincide with the data obtained
on the basis of measures of association, or, in other
words, statistical measures of association better de-
termine the real semantic-syntagmatic relations.
A comparative analysis of different association
CSSE@SW 2022 - 5th Workshop for Young Scientists in Computer Science Software Engineering
16
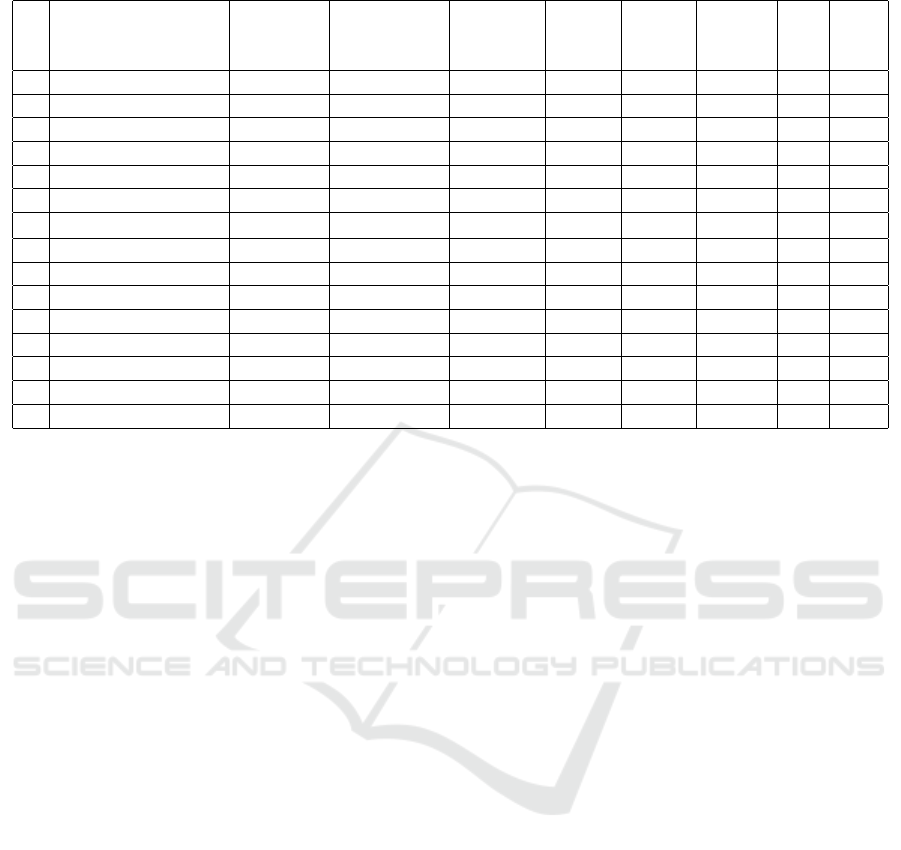
Table 1: Values of associative measures for the word “Polisia”.
№ Collocation Word 1 Word 2
Freq
Word 1
& Word 2
Freq
Word 1
Freq
Word 2
Word in
Corpus
MI
T-
score
1 Patr
´
uldik polısıa patr
´
uldik polısıa 4 8 906 178645 6,62 1,98
2 Qarjy polısıasy qarjy polısıasy 3 8 906 178645 6,21 1,71
3 Polısıa jasa
´
gy polısıa jasa
´
gy 2 906 6 178645 6,04 1,39
4 Polısıa b
´
olimi polısıa b
´
olimi 12 906 40 178645 5,89 3,41
5 Polısıa
´
ga j
´
ugin
´
y polısıa
´
ga j
´
ugin
´
y 5 906 17 178645 5,86 2,20
6 Polısıa shaqyr
´
y polısıa shaqyr
´
y 7 906 27 178645 5,68 2,59
7
´
Askerı polısıa
´
askerı polısıa 1 4 906 178645 5,62 0,98
8 Tur
´
gylyqty polısıa tur
´
gylyqty polısıa 3 13 906 178645 5,51 1,69
9 Polısıa qyzmetkeri polısıa qyzmetkeri 55 906 272 178645 5,32 7,23
10 Polısıa basqarmasy polısıa basqarmasy 57 906 294 178645 5,26 7,35
11 Polısıa qyzmeti polısıa qyzmeti 15 906 93 178645 4,99 3,75
12 Polısıa departamenti polısıa departamenti 40 906 323 178645 4,61 6,07
13 Polısıa
´
ga habarlas
´
y polısıa
´
ga habarlas
´
y 8 906 66 178645 4,58 2,71
14 Polısıa basshysy polısıa basshysy 9 906 94 178645 4,24 2,84
15 Polısıa k
´
oligi polısıa k
´
oligi 7 906 111 178645 3,64 2,43
measures carried out on a set of all data obtained for
different word classes shows the following.
The MI measure can give the best average result.
It makes it possible to distinguish between correct
phraseological collocations as well as collocations in
which proper names act as collocations, as well as
low-frequency special terms. The disadvantages of
using the t-score are primarily related to the fact that
it determines the frequency with collocations, in par-
ticular with auxiliary words. Therefore, in order to
“remove” the most frequent words for t-score, it is
necessary to set up a list of stop words whose com-
binations are always at the top of the table: auxiliary
words, pronouns or conjunctions. However, this also
applies to other dimensions.
Whether statistical measures should be taken into
account when searching for a lemma or a phrase
remains an open question. The structural syntac-
tic formulas and semantic constraints underlying the
phrases also need to be taken into account.
In the future it is planned to test the effectiveness
of the method on a large corpus.
ACKNOWLEDGEMENTS
This work was carried out with the financial support
of the Committee of Science of the Ministry of Ed-
ucation and Science of the Republic of Kazakhstan
(No. AR09259309).
REFERENCES
Akhmanova, O. S. (1996). Slovar’ lingvisticheskikh termi-
nov. Editorial URSS, Moscow.
Atkins, B. T. S. and Rundell, M. (2008). The Oxford Guide
to Practical Lexicography. Oxford University Press.
Borisova, Y. G. (1995). Kollokatsii. Chto eto takoye i kak
ikh izuchat’. Filologija, Moscow, 2 edition.
Chernyakova, T. A. (2012). Metodika formirovaniya lek-
sicheskikh navykov studentov na osnove lingvistich-
eskogo korpusa. The thesis for the degree of candidate
of pedagogical sciences.
Church, K. W. and Hanks, P. (1990). Word Associ-
ation Norms, Mutual Information, and Lexicogra-
phy. Computational Linguistics, 16(1):22–29. https:
//aclanthology.org/J90-1003.
Evert, S. (2004). The Statistics of Word Co-occurences:
Word Pairs and Collocations. PhD thesis, Institut
f
¨
ur Maschinelle Sprachverarbeitung (IMS), Univer-
sit
¨
at Stuttgart, Stuttgart.
Iordanskaya, L. N. and Mel’chuk, I. A. (2007). Smysl i so-
chetayemost’ v slovare. Yazyki slavyanskikh kul’tur,
Moscow.
Khairova, N., Kolesnyk, A., Mamyrbayev, O., and
Mukhsina, K. (2019). The Aligned Kazakh-Russian
Parallel Corpus Focused on the Criminal Theme.
In Lytvyn, V., Sharonova, N., Hamon, T., Chered-
nichenko, O., Grabar, N., Kowalska-Styczen, A., and
Vysotska, V., editors, Proceedings of the 3rd In-
ternational Conference on Computational Linguis-
tics and Intelligent Systems (COLINS-2019). Volume
I: Main Conference, Kharkiv, Ukraine, April 18-19,
2019, volume 2362 of CEUR Workshop Proceedings,
pages 116–125. CEUR-WS.org. http://ceur-ws.org/
Vol-2362/paper11.pdf.
Experimental Verification of Collocation Detection Methods
17

Khairova, N., Kolesnyk, A., Mamyrbayev, O., Ybytayeva,
G., and Lytvynenko, Y. (2021). Automatic multilin-
gual ontology generation based on texts focused on
criminal topic. In Sharonova, N., Lytvyn, V., Chered-
nichenko, O., Kupriianov, Y., Kanishcheva, O., Ha-
mon, T., Grabar, N., Vysotska, V., Kowalska-Styczen,
A., and Jonek-Kowalska, I., editors, Proceedings of
the 5th International Conference on Computational
Linguistics and Intelligent Systems (COLINS 2021).
Volume I: Main Conference, Lviv, Ukraine, April 22-
23, 2021, volume 2870 of CEUR Workshop Proceed-
ings, pages 108–117. CEUR-WS.org. http://ceur-ws.
org/Vol-2870/paper11.pdf.
Kilgarriff, A. (2006). Collocationality (and how to mea-
sure it). In Corino, E., Marello, C., and Onesti,
C., editors, Proceedings of the 12th EURALEX In-
ternational Congress, pages 997–1004, Torino, Italy.
Edizioni dell’Orso. https://euralex.org/publications/
collocationality-and-how-to-measure-it/.
Kilgarriff, A., Rychl
´
y, P., Smrz, P., and Tugwell, D. (2004).
The Sketch Engine. In Williams, G. and Vessier,
S., editors, Proceedings of the 11th EURALEX Inter-
national Congress, pages 105–115, Lorient, France.
Universit
´
e de Bretagne-Sud, Facult
´
e des lettres et des
sciences humaines. https://euralex.org/publications/
the-sketch-engine/.
Kozhakhmetova, K. K., Zhaysakova, R. E., and
Kozhakhmetova, S. O. (1988). Kazakh-Russian
phraseological dictionary. Mektep, Almaty.
Krishnamurthy, R. (2006). Collocations, pages 596–600.
Elsevier, Netherlands, 2nd edition. https://doi.org/10.
1016/B0-08-044854-2/00414-4.
Pecina, P. (2009). Lexical Association Measures: Colloca-
tion Extraction. Studies in Computational and The-
oretical Linguistics. Institute of Formal and Applied
Linguistics, Prague. https://ufal.mff.cuni.cz/books/
preview/pecina
preview.pdf.
Ryazanova, Y. A. (2012). Metodika formirovaniya gram-
maticheskikh navykov rechi studentov na osnove
lingvisticheskogo korpusa. The thesis for the degree
of candidate of pedagogical sciences.
Smagulova, G. S. (2010). Magynalas frazeologizmder
sozdigi. Yeltanym baspasy, Almaty.
Sysoyev, P. V. (2010). Lingvisticheskiy korpus v metodike
obucheniya inostrannym yazykam. Yazyk i kul’tura,
1(9):99–111.
Zhanuzak, T., Omarbekov, S., and Zhunisbek, A. (2011).
Kazak adebietinin sozdigi. On bes tomdyk. Almaty.
CSSE@SW 2022 - 5th Workshop for Young Scientists in Computer Science Software Engineering
18
