
Research on Improved Conv-TasNet of Speech Enhancement for
Non-Stationary and Low SNR Noise During Aircraft Operating
Deyin Zhang
a
, Wenxuan Hong
b
, Juntong Li
c
, Yuyao Zhang
d
and Li Wang
e
Institute of Electronic and Electrical Engineering, Civil Aviation Flight University of China, Guanghan, China
Keywords: Civil Aviation, Noise, Non-Stationary, Speech Enhancement, Neural Network.
Abstract: A speech enhancement method based on improved Conv-TasNet (Convolution Time-Domain Audio Separa-
tion Network) is proposed in this paper so as to solve the problems of the high noise environment of the airport
seriously affects the communication between airport ground staff. The traditional speech enhancement algo-
rithm used by civil aviation is not effective in suppressing low SNR (signal-to-noise) ratio and non-stationary
noise. The improved Conv-TasNet is based on the baseline Conv-TasNet, and fused the multi-head-attention
module and the Efficient Channel Attention Network channel attention module. The ablation experiment is
carried out by using four neural networks to deal with the noisy speech of five kinds SNR: 10dB, 5dB, 0dB,
-5dB respectively. The performance of the neural network is analyzed by four subjective and objective speech
evaluation indicators including MOS (Mean Opinion Score), segSNR (Segment Signal-to-Noise Ratio),
PESQ (Perceptual Evaluation of Speech Quality) and STOI (Short-Time Objective Intelligibility). The exper-
iment results show that, the improved Conv-TasNet has an average increase of 1.4984 in MOS, 11.9261 in
segSNR, 0.5868 in PESQ, and 0.0455 in STOI compared with the baseline Conv-TasNet. The improved neu-
ral network has better speech quality and intelligibility, which can solve the problem of used in base-
line Conv-TasNet has poor effect on speech enhancement with low SNR and non-stationary environmental
noise during aircraft operating.
1 INTRODUCTION
The working environment of civil aviation staff has
many sources of noise, mainly including wind noise
from aircraft take-off and landing, engine running
noise (DING Cong et al.,2021), etc. Its characteristics
are high sound level, wide influence range, three-di-
mensional spatial diffusion, and non-stationary, etc.
When the aircraft is taking off and landing, the noise
can reach 100~180 decibels (DING Cong et al.,
2021), which seriously affects the speech communi-
cation between civil aviation staff (HE Liqing, 2020)
and will lead to errors in communication between the
two parties. Therefore, in a high-noise environment,
how to reduce the harm of high noise to civil aviation
staff and ensure the high quality and high efficiency
of speech information exchange between relevant
civil aviation staff is an urgent problem to be solved.
Speech enhancement refers to extracting the original
a
https://orcid.org/0000-0003-0763-4690
b
https://orcid.org/0000-0003-4126-1189
c
https://orcid.org/0000-0002-4985-5929
d
https://orcid.org/0000-0002-3820-1436
e
https://orcid.org/0000-0003-1017-8171
speech signal from a noisy speech signal as un-
distorted as possible through signal processing
(
Khattak Muhammad Irfan et al., 2022
). The methods of
speech enhancement are mainly divided into unsuper-
vised and supervised methods (
Ribas Dayana et al.,
2022
). Among them, unsupervised methods are
mainly divided into time-domain methods and fre-
quency-domain methods, such as spectral subtrac-
tion, wiener filtering, etc (
G Thimmaraja Yadava et al.,
2022; Jaiswal Rahul Kumar et al., 2022
). Supervised
method is mainly divided into artificial neural net-
work (
Wang Youming et al., 2021
), Hidden Markov
Model (
E. Golrasan et al., 2016
) and non-negative ma-
trix (
Tank Vanita Raj et al., 2022
). Most of the speech
enhancement technologies used in the civil aviation
field are based on traditional field are unsupervised
methods. An adaptive Kalman filtering algorithm
based on wavelet analysis was used to the research of
VHF speech enhancement technology (LU Yong,
776
Zhang, D., Hong, W., Li, J., Zhang, Y. and Wang, L.
Research on Improved Conv-TasNet of Speech Enhancement for Non-Stationary and Low SNR Noise During Aircraft Operating.
DOI: 10.5220/0012047300003612
In Proceedings of the 3rd International Symposium on Automation, Information and Computing (ISAIC 2022), pages 776-781
ISBN: 978-989-758-622-4; ISSN: 2975-9463
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)

2021). A VHF speech enhancement algorithm based
on improved power spectrum subtraction was pro-
posed (YI Xue, 2020). The MMSE-LSA method for
speech enhancement was adopted in the noise envi-
ronment of the aircraft cockpit (HE Liqing, 2020).
The traditional unsupervised speech enhancement
technology is suitable for stationary noise with low
sound level, and has a better suppression effect for
stationary environmental noise. However, due to the
limitations of the traditional algorithm, it is very in-
sufficient for the non-stationary high noise such as
airport environment, and the neural network can
make up for this problem. Therefore, in order to solve
the problem that the noise in the working environ-
ment of the civil aviation staff seriously affects the
speech communication between personnel and dam-
ages the hearing of the personnel. An improved Conv-
TasNet is proposed in this paper. It is based on the
baseline Conv-TasNet (LUO Y, 2019), and fused the
multi-head-attention module and the ECA-Net chan-
nel attention network. It solves the problem that the
baseline Conv-TasNet has poor performance of
speech enhancement in dealing with low SNR speech
and non-stationary noise.
2 NEURAL NETWORK SPEECH
ENHANCEMENT MODEL
2.1 Baseline Conv-TasNet
The Conv-TasNet is a time-domain based end-to-end
speech separation model, which adopts an encoder-
decoder structure, including an encoder, a separator,
and a decoder, as shown in Figure 1.
Figure 1: The structure of baseline Conv-TasNet.
Among them, the encoder consists of a single one-bit
convolutional network and an activation function
PReLU(Parametric Rectified Linear Unit), in which a
one-dimensional convolution with a fixed convolu-
tion kernel size is used for feature extraction. The in-
put noisy speech signal is first cut into multiple audio
segments with partial overlap and fixed length.
The separator generates a weight mask, shielding the
noise speech to extract the pure speech signal, and re-
alizes the function of speech enhancement. The en-
coded noisy speech signal first goes through a nor-
malization layer to keep its input distribution con-
sistent during the training process, solving the prob-
lem of internal covariate shift caused by updating pa-
rameters, enhancing the generalization ability of the
model, and avoid gradient disappearance and gradient
explosion. Then use a 11 convolutional layer to
keep the minimum number of input feature channels.
The processed sequence enters the TCN layer (
Y. A.
Farha and J. Gall, 2019
), and after the output from the
TCN module, the Parametric Rectified Linear Unit is
used as the activation function. Then use 11 convo-
lution to restore the number of feature channels. Fi-
nally, through the Sigmoid activation function, the
time domain mask of the signal source is obtained.
The decoder is similar in structure to the encoder but
with opposite function. Its function is to reconstruct
the separated audio signal to obtain the time domain
waveform of the original signal.
2.2 Multi-Head-Attention Module
The multi-head-attention is a variant of the attention
mechanism (
YANG Lei et al., 2022
), which is essen-
tially an integration of several self-attention mecha-
nisms. The structure is shown in Figure 2. Use multi-
ple queries to splice different groups of information
from input information in parallel. The advantage is
that relevant information can be obtained from differ-
ent subspaces.
Scaled Dot-Product Attention
Linear Linear Linear
Concat
Linear
Figure 2: The structure of multi-head-attention.
2.3 Channel Attention Network
Efficient Channel Attention Network (ECA-Net) is
based on the shortcomings of the SENet network (HU
J et al., 2020), such as poor versatility and an addi-
tional large amount of data, by using a fast 1D convo-
lution of size K instead of the dimension reduction
operation, avoiding the side effects of the dimension
reduction operation to obtain the information of
Research on Improved Conv-TasNet of Speech Enhancement for Non-Stationary and Low SNR Noise During Aircraft Operating
777

cross-channel interaction, and the effect is to obtain a
greater performance improvement on the basis of
adding very few parameters. The structure of ECA-
Net is shown in Figure 3.
Figure 3: The structure of ECA-Net.
2.4 Improved Conv-TasNet
Compared with the general environmental noise, the
airport environmental noise has more non-stationary
characteristics and lower SNR. Although the TCN
(Temporal Convolutional Network) used in the sepa-
rator by the baseline Conv-TasNet also improves the
spatial level of the CNN, it does not consider the cor-
relation between speech channels, especially for the
low SNR noisy speech. Therefore, an improved
Conv-TasNet is proposed in this paper. It is based on
the baseline Conv-TasNet, and fuses the multi-head-
attention module and the ECA-Net channel attention
module. The multi-head-attention module is placed
after the LN in the bottleneck layer, and the ECA-Net
is placed after the depth-wise convolution in the TCN.
The network structure is shown in Figure 4.
Figure 4: The structure of improved Conv-TasNet.
Multi-head-attention module can use efficient matrix
operation, which improves the efficiency of parallel
computing efficiency of the network. At the same
time, the multi-head-attention module can calculate
the similarity between the input speech signal feature
of each frame and the adjacent frame. For the speech
signal containing non-stationary environmental noise,
it can more obviously distinguish the pure speech part
and the noise part of the input feature. And the opera-
tion is based on independent frames at the same time,
without flattening the input features, and avoid the
problem of destroying the voice signal structure.
ECA-Net channel attention module can make the net-
work to fully consider the correlation between the
channels. For low noise ratio of noise speech, its cor-
relation between channels is complex, and the intro-
duction of ECA-Net can further strengthen the im-
portance of input information, improving the effective
use of each information, strengthening the subsequent
convolution layer of channel relationship mapping,
and achieve the purpose of improving network speech
enhancement performance.
3 EXPERIMENT AND RESULT
ANALYSIS
3.1 Dataset Establishment
The noise sample set is partly derived from the do-
mestic classic airport recording and the network pub-
lic airport environment noise audio; the pure voice
sample set is derived from the network public TIMIT
voice library; and the noisy voice is derived from the
open space real-time dialogue recording and additive
synthesis. Among them, the additive synthesis of
noisy speech refers to the additive superposition of
the noise sample set and the pure speech sample set
according to a certain SNR. Finally, 9530 noise-con-
taining speech items with a sampling rate of 16kHz
and a bit depth of 32bit are synthesized.
3.2 Comparison Method
Ablation experiments were designed to test the effec-
tiveness of the baseline Conv-TasNet fused the mod-
ules. In this paper, the baseline Conv-TasNet is
named BCTN, and baseline Conv-TasNet fused
multi-head-attention modules is named MCTN, and
baseline Conv-TasNet fused ECA-Net is named
ECTN, and baseline Conv-TasNet fused both two
modules is named MECTN. All models are trained in
the same environment and the same sample set.
3.3 Performance Analysis
3.3.1 Baseline Conv-TasNet Performance
Figure 5 shows the denoising effect of five airport
noise speech with different ambient noise ratio,
namely the Mel spectrogram of pure speech, noisy
speech and speech processed by four networks under
each SNR.
ISAIC 2022 - International Symposium on Automation, Information and Computing
778
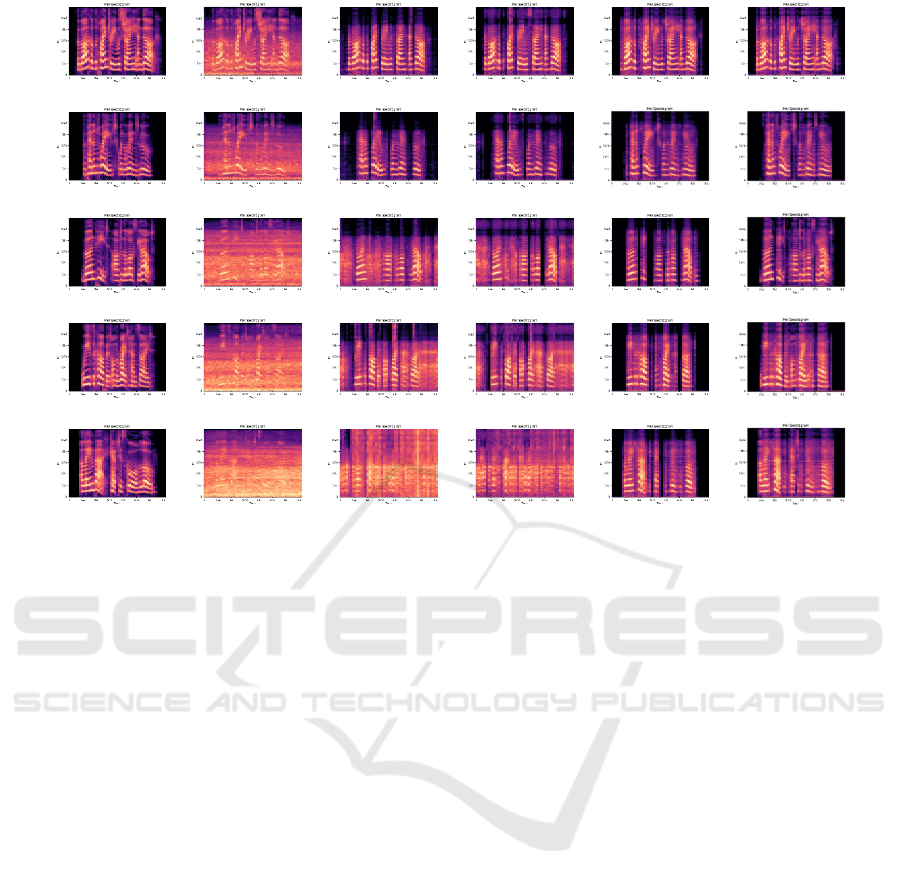
(1)s
p
eech A (2)10dB noisy (3)BCTN (4)MCTN (5)ECTN (6)MECTN
(7)speech B (8)5dB noisy (9)BCTN (10)MCTN (11)ECTN (12)MECTN
(13)s
p
eech C (14)0dB noisy (15)BCTN (16)MCTN (17)ECTN (18)MECTN
(19)speech D (20)-5dB noisy (21)BCTN (22)MCTN (23)ECTN (24)MECTN
(25)speech E (26)-10dB noisy (27)BCTN (28)MCTN (29)ECTN (30)MECTN
Figure 5: Speech enhancement effects of noisy speech processed by different models under different SNR.
As can be seen from Figure 5(3)(9)(15)(21)(27), after
the baseline Conv-TasNet processing, it can basically
restore the timing and energy intensity of pure speech.
However, for the silent segment of the front and the
last part of the pure voice signal, part of the environ-
mental noise is still there. Moreover, with the de-
crease of SNR, the high-frequency harmonic loss is
gradually serious, and the energy intensity is obvi-
ously low with the serious loss of speech signal. From
figure 5(4)(10)(16)(22)(28), after the fusion of multi-
ple attention module, the high frequency harmonic
loss is significantly reduced, and the energy intensity
of each frequency is closer to the pure voice, visible
for the prediction of non-stationary noise is more ac-
curate, but for the pure voice signal and the last ex-
pansion of silent segment, still retain part of environ-
mental noise, and for the middle part of the voice sig-
nal has many obvious eliminations. As can be seen
from figure 5(5)(11)(17)(23)(29), after integrating the
ECA-Net module, the environmental noise at the ex-
panded silent segment of the first and last parts of the
pure speech signal is significantly eliminated, and the
middle part of the voice signal is not significantly
eliminated. Therefore, after the introduction of ECA-
Net, the network can better restore the timing of pure
speech, especially for the low energy intensity and
low SNR. From figure 5(6)(12)(18)(24)(30), after the
fusion of the multiple attention module and the ECA-
Net channel attention module, the network combines
the advantages of the two modules,not only the har-
monic loss of the high-frequency part is significantly
reduced, the energy intensity of each frequency is
closer to the pure speech, but also the ambient noise
at the first and last part of the extended silent segment
of the pure speech signal and the noise in the noisy
speech with low SNR are significantly eliminated. It
can be seen that the network is more accurate for non-
stationary noise prediction, and the ability of pure
speech at low SNR is significantly improved.
3.3.2 Subjective and Objective Evaluation
In order to evaluate the network performance more
comprehensively, this paper uses both subjective and
objective evaluation. The subjective evaluation
adopts MOS (
Randhir Singh et al., 2017
), the objective
evaluation used segSNR (
Rashmirekha Ram et al.,
2019
), PESQ (
RIX ANTONY W et al., 2002
) and STOI
(
TAAL C H et al., 2011
). Four network models were
used for 200 pieces of five different SNR speech with
noise for speech enhancement, and average of the
evaluation scores of each SNR was calculated, as
shown in Table 1.
Research on Improved Conv-TasNet of Speech Enhancement for Non-Stationary and Low SNR Noise During Aircraft Operating
779
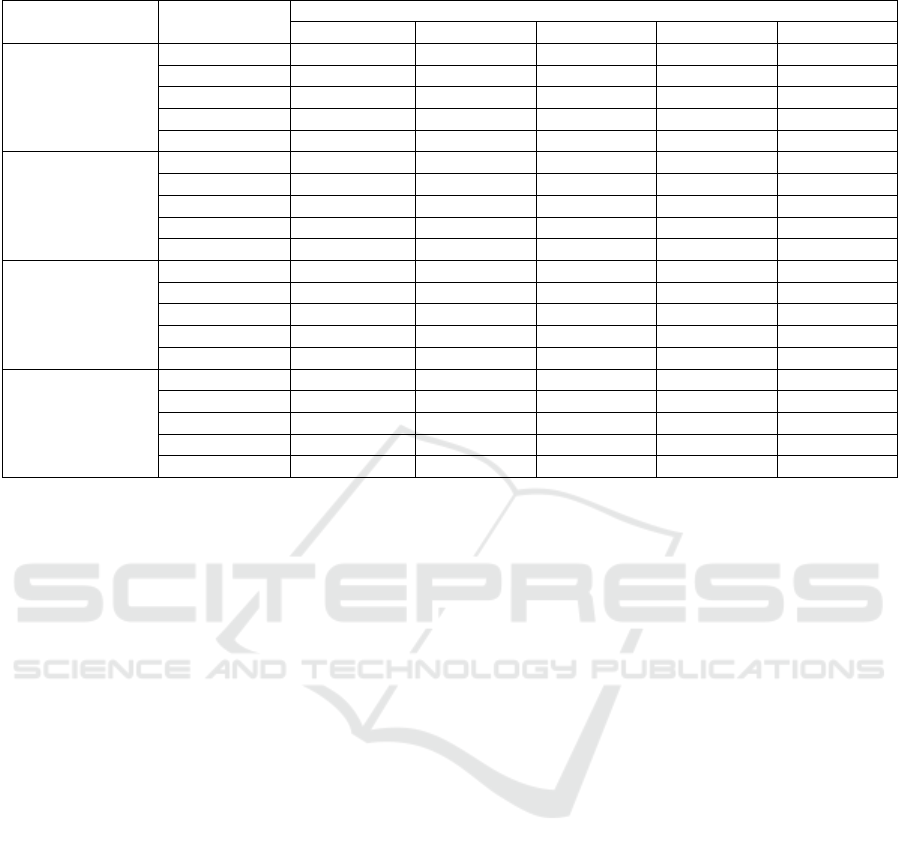
Table 1: Evaluation index of network model for speech enhancement with different SNR.
Evaluation Model
SNR
10dB 5
d
B0
d
B -5dB -10dB
MOS
Nois
y
2.713 1.916 1.641 1.873 1.477
BCTN 2.880 2.891 2.984 3.067 2.989
MCTN 3.083 3.051 3.207 3.287 3.112
ECTN 3.170 3.170 3.255 3.310 3.205
MECTN 3.317 3.495 3.362 3.479 3.459
segSNR
Nois
y
3.7957 -1.8659 -5.0278 -7.1134 -8.5055
BCTN 8.7555 4.6158 3.2732 2.0801 0.3003
MCTN 9.8841 6.3587 5.1664 4.8988 2.3299
ECTN 10.3367 6.6742 5.7543 4.2594 2.0641
MECTN 13.8277 8.4318 7.1765 6.8463 4.6311
PESQ
Nois
y
1.4424 1.1470 1.0525 1.0367 1.0250
BCTN 1.7582 1.5849 1.3874 1.2565 1.1545
MCTN 1.8488 1.6761 1.4847 1.3999 1.2555
ECTN 1.9628 1.7876 1.5669 1.4702 1.3510
MECTN 2.1786 1.8548 1.7617 1.5846 1.4579
STOI
Nois
y
0.9425 0.8696 0.7380 0.7429 0.5104
BCTN 0.9595 0.8722 0.7561 0.7566 0.5256
MCTN 0.9707 0.8910 0.7762 0.7783 0.5486
ECTN 0.9796 0.9037 0.7797 0.7817 0.5465
MECTN 0.9923 0.9177 0.750 0.7974 0.5735
It can be seen from the above table, after the baseline
Conv-TasNet and the improved Conv-TasNet en-
hance the noise-containing speech, the speech is sig-
nificantly improved in all the four evaluation indica-
tors. At the five SNRs, increased the MOS by 1.0382,
segSNR by 7.5484, PESQ by 0.2876, and STOI by
0.0133. Conv-TasNet only fused multi-head-attention
module and only fused ECA-Net are both better than
baseline Conv-TasNet for high SNR or low SNR
speech, increased MOS by 17.90% and 25.02% re-
spectively, segSNR by 1.923 and 2.013 respectively,
PESQ by 17.63% and 25.50% respectively, STOI by
0.019dB and 0.024dB respectively. However, Im-
proved Conv-TasNet, which simultaneously fused the
multi-head-attention and ECA-Net, increased the
MOS by 1.4984, segSNR by 11.9261,0. PESQ by
0.5868, and STOI by 0.0455. In conclusion, the im-
proved Conv-TasNet speech enhancement algorithm
proposed here is able to handle the low SNR ratio and
non-stationary noise-containing speech more effec-
tively than the baseline Conv-TasNet.
4 CONCLUSIONS
A speech enhancement method based on improved
Conv-TasNet is proposed in this paper, it fused multi-
head-attention module and ECA-Net network based
on the baseline Conv-TasNet. The experimental re-
sults show that after the baseline network integrates
the two modules, the prediction of non-stationary
noise and the speech signal at low SNR have a higher
completeness. Compared with the baseline Conv-
TasNet, the proposed improved Conv-TasNet in-
creases MOS by 1.4984, segSNR by 11.9261, PESQ
by 0.5868 and STOI by 0.0455. Therefore, the im-
proved Conv-TasNet has better speech quality and
understanding, which can solve the problem of the
traditional unsupervised speech enhancement algo-
rithm on such low signal to noise ratio and non-sta-
tionary environment noise speech enhancement in
airports.
ACKNOWLEDGEMENTS
The authors would like to acknowledge the financial
support of Research Fund of Civil Aviation Flight
University of China (Grant No. J2019-88 and Grant
No. ZJ2022-007).
REFERENCES
DING Cong, ZENG Wei-li, WEI Wen-bin, YANG Ai-wen.
Review of Civil Airport Noise Assessment [J]. Aero-
nautical Computing Technique,2021,51(05):130-134.
E. Golrasan, H. Sameti. Speech enhancement based on hid
den Markov model using sparse code shrinkage[J]. Jou
rnal of Artificial Intelligence and Data Mining,2016,4(
2).
ISAIC 2022 - International Symposium on Automation, Information and Computing
780

G Thimmaraja Yadava,G Nagaraja B,S Jayanna H. A spati
al procedure to spectral subtraction for speech enhance
ment[J]. Multimedia Tools and Applications,2022,81(1
7).
HE Liqing. Study of Artificial Intelligence Flight Co-Pilot
Speech Recognition Technology[D]. Civil Aviation Fli
ght University of China, 2020.DOI: 10.27722/d.cnki.g
zgmh.2020.000026.
HU J, SHEN L, ALBANIE S, et al. Squeeze-and-excitatio
n networks[J]. IEEE Transactions on Pattern Analysis
and Machine Intelligence,2020, 42(8): 2011-2023.
Jaiswal Rahul Kumar, Yeduri Sreenivasa Reddy, Cenkera
maddi Linga Reddy. Single-channel speech enhancem
ent using implicit Wiener filter for high-quality speech
communication[J]. International Journal of Speech Te
chnology,2022,25(3).
Khattak Muhammad Irfan, Saleem Nasir, Gao Jiechao, Ve
rdu Elena, Fuente Javier Parra. Regularized sparse feat
ures for noisy speech enhancement using deep neural n
etworks[J]. Computers and Electrical Engineering,202
2,100.
LU Yong. Research on speech enhancement algorithm bas
ed on VHF[J]. Electronic Measurement Technology,20
21,44(02):65-70.
LUO Y, MESGARANI N. Conv-TasNet: surpassing ideal
time- frequency magnitude masking for speech separat
ion[J]. IEEE/ACM Transactions on Audio, Speech, and
Language Processing, 2019, 27(8):1256-1266.
Randhir Singh, Ajay Kumar, Parveen Kumar Lehana. Effe
ct of bandwidth modifications on the quality of speech
imitated by Alexandrine and Indian Ringneck parrots[J
]. International Journal of Speech Technology,2017,20
(3):659-672.
Rashmirekha Ram, Mihir Narayan Mohanty. Use of radial
basis function network with discrete wavelet transform
for speech enhancement[J]. Int. J. of Computational V
ision and Robotics,2019,9(2):207-223.
Ribas Dayana, Miguel Antonio, Ortega Alfonso, Lleida Ed
uardo. Wiener Filter and Deep Neural Networks: A W
ell-Balanced Pair for Speech Enhancement[J]. Applied
Sciences,2022,12(18).
RIX ANTONY W, BEERENDS JOHN G , HOLLIER MI
CHAEL P,et al. Perceptual evaluation of speech qualit
y (PESQ) - a new method for speech quality assessmen
t of telephone networks and codecs[C]//Proceedings of
the 2001 IEEE International Conference on Acoustics
, Speech, and Signal Processing. Piscataway: IEEE Pr
ess,2002: 749-752.
TAAL C H, HENDRIKS R C, HEUSDENS R, et al. An al
gorithm for intelligibility prediction of time–frequency
weighted noisy speech[J].IEEE Transactions on Audio
Speech & Language Processing, 2011,19(7): 2125-21
36.
Tank Vanita Raj, Mahajan Shrinivas Padmakar. Adaptive r
ecurrent nonnegative matrix factorization with phase c
ompensation for Single-Channel speech enhancement[
J]. Multimedia Tools and Applications,2022,81(20).
Wang Youming, Han Jiali, Zhang Tianqi, Qing Didi. Spee
ch enhancement from fused features based on deep neu
ral network and gated recurrent unit network[J]. EURA
SIP Journal on Advances in Signal Processing,2021,2
021(1).
Y. A. Farha and J. Gall, "MS-TCN: Multi-Stage Temporal
Convolutional Network for Action Segmentation," 201
9 IEEE/CVF Conference on Computer Vision and Patt
ern Recognition (CVPR)
, 2019, pp. 3570-3579, doi: 10
.1109/CVPR.2019.00369.
YANG Lei, ZHAO Hongdong, YU Kuaiguai. End-to-end s
peech emotion recognition based on multi-head attenti
on[J]. Journal of Computer Applications,2022,42(06):
1869-1875.
YI Xue. VHF Speech Enhancement Based on Short-time S
pectrum Estimation[D]. Civil Aviation University of C
hina, 2020.000078.DOI: 10.27627/d.cnki.gzmhy.2020.
000078.
Research on Improved Conv-TasNet of Speech Enhancement for Non-Stationary and Low SNR Noise During Aircraft Operating
781
