
Hand Segmentation with Mask-RCNN Using Mainly Synthetic Images as
Training Sets and Repetitive Training Strategy
Amin Dadgar and Guido Brunnett
Computer Science, Chemnitz University of Technology, Straße der Nationen 62, 09111, Chemnitz, Germany
Keywords:
Machine Learning, Neural Networks, Deep Learning, Segmentation, Synthetic Training Set, Transfer
Learning, Learning Saturation, Premature Learning Saturation, and Repetitive Training.
Abstract:
We propose an approach to segment hands in real scenes. To that, we employ 1) a relatively large amount
of sorely simplistic synthetic images, 2) a small number of real images, and propose 3) a training scheme of
repetitive training to resolve the phenomenon we call premature learning saturation (for using relatively large
training set). The results suggest the feasibility of hand segmentation subject to attending to the parameters and
specifications of each category with meticulous care. We conduct a short study to quantitatively demonstrate
the benefits of our repetitive training on a more general ground with the Mask-RCNN framework.
1 INTRODUCTION
For the training of deep neural networks, the creation
and annotation of large amounts of data are major is-
sues. The feasibility of employing synthetic training
data appears to be attractive for the immense costs re-
duction foreseeable in those phases.
A recent advancement on this direction is an ap-
proach referred to as SaneNet (Dadgar and Brunnett,
2020). Albeit the employment of simplistic synthetic
data as the training-set, their approach demonstrated
promising results on detecting hands in various sce-
narios. Inspired from the invariancy concept existed
in conventional deep nets, the SaneNet exploited this
notion further to accomplish the goal. Building on
these experiences, we extend this approach towards
the more challenging task of hand segmentation.
There exist discrepancies (e.g., in texture, scene,
background, and object details) between synthetic
and real images. A workaround for attenuating the
impacts of those discrepancies is to employ a larger
amount of synthetic data with higher diversity. Sup-
posedly, increasing the amount of training data should
not pose an obstacle, for the data can be generated
and annotated automatically. However, in training
our networks on relatively larger amounts of synthetic
data, we discovered a problem we refer to as prema-
ture learning saturation (Fig.1).
Learning saturation is a state of training in which
the training loss does not decrease meaningfully as
the hidden units output values close to the asymptotic
Figure 1: Learning saturation is a well-known state of train-
ing phases in which the training loss does not decrease
meaningfully and can have many reasons. This state occurs
in all training phases of our experiments. However, when
we have to employ relatively larger datasets, this learning
saturation would be premature. That means the network
enters that state in the early stages/steps. That leads the net-
works to merely learn the main features from the initial por-
tion of the training set and almost ignore the rest of the data.
The Figure shows one epoch, with 1000 steps, of a training
process using 45K synthetic images. After approximately
step 300
th
, the loss seemingly worsens, and the training en-
ters the saturation phase. Thus the network has seemingly
processed merely 15000 images effectively (e.g., one-third
of the entire training session). In other words, about 30K of
them could not contribute meaningfully to the learning. We
call the phenomenon premature learning saturation.
ends of the activation function (Rakitianskaia and En-
gelbrecht, 2015). This state is usually displayed in the
loss, after an initial drop and a somewhat consistent
decrease, by undirected fluctuations. Such behavior
can have many reasons, such as, high initial weights,
a small-sized net (e.g., underfitting), and an improper
learning rate. However, if one selects these param-
eters carefully, networks would encounter this state
during the final stages of training.
220
Dadgar, A. and Brunnett, G.
Hand Segmentation with Mask-RCNN Using Mainly Synthetic Images as Training Sets and Repetitive Training Strategy.
DOI: 10.5220/0011658900003417
In Proceedings of the 18th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2023) - Volume 4: VISAPP, pages
220-228
ISBN: 978-989-758-634-7; ISSN: 2184-4321
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
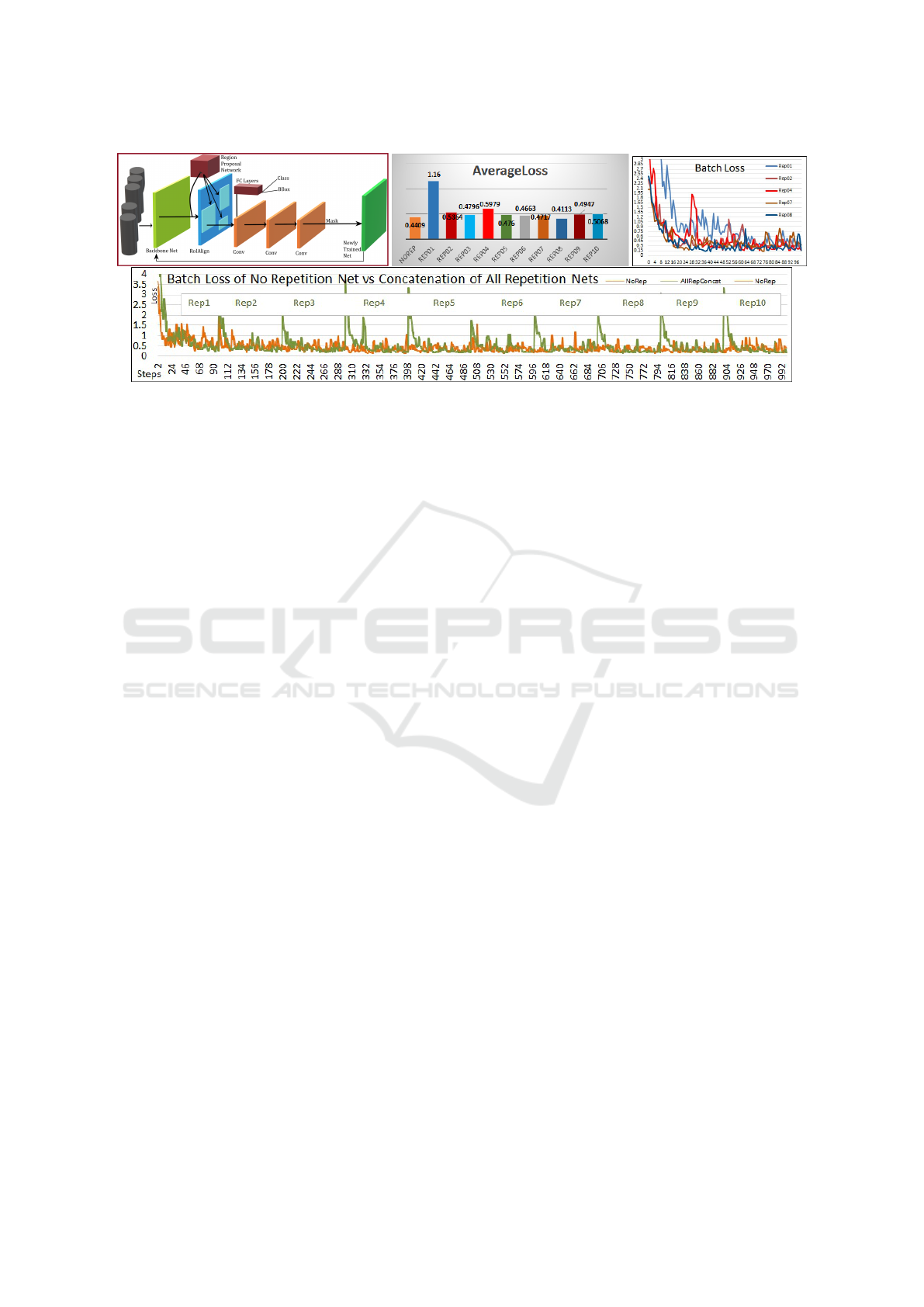
Figure 2: Repetitive training (upper left) is a specific scheme to approach training. There, we divide our database into smaller
subsets. Then, we train our several networks over each of these subsets. While training, we employ the resulting network
from the previous subset as the backbone of the following subset’s training. With this approach, we aim to address the issue
of premature learning saturation. In upper middle figure, besides clear improvements in the average loss after each repetition
(except for repetition 4), the overall loss (0.4113) after 8
th
repetition is better than the loss of the training with no repetition
(0.4409) on the far left orange bar. In this short comparison, repetitions 9 and 10 did not introduce any improvements in the
average loss. Therefore, we would consider repetition eight’s network as the final net. In upper right figure, each training
session has one epoch, with 100 steps (and 4.5K images). By arguing the occurrence of saturation on approximately > 80
th
step, the saturation takes place in relatively late stages and thus is not premature, demonstrating a potential explanation for
the advantage of our repetitive training. The bottom figure shows the comparison between the batch losses of the repetitions
(in a concatenated format) and of the conventional training without repetition. The green curve demonstrates the advantage
of repetitive training (specially at the end of the epoch).
The problem arises when networks enter that state
ere long the final (compared to the total number of)
training stages/steps. In cases where synthetic data
constitutes a much larger shred of the training-set, and
thus the size of the training sets ought to be higher
than usual, the learning saturation seems to occur
sooner (thus premature). Therefore, facing a trade-off
becomes inevitable. That is, on one side, we resort to
increasing the size of the synthetic set to compensate
for the existing discrepancies between synthetic and
real data. On the other side, networks seldom learn (if
at all) useful features, after some early stages, due to
that premature learning saturation consequence.
In our experiments, we frequently encountered the
phenomenon directly after the networks merely em-
ployed a small portion of the training data. Conse-
quently, we suspected this early (premature) satura-
tion leads the networks to learn simply from the initial
training data and seemingly, ignores almost the rest.
To mitigate that problem, we propose a particu-
lar type of learning scheme called repetitive training
(Fig.2-left). In our approach, we first randomly divide
our relatively large set of training data into smaller
subsets. Then, starting from the first subset, we train
the default backbone CNN (e.g., Resnet101). Next,
we employ the resultant network from the previous
training phase as the backbone net, and with the sec-
ond subset, we train a new network. We continue this
procedure until all subsets are used. Therefore, we
repetitively transfer the knowledge learned from the
net (and subset) of the last iteration to the next.
The main focus of this paper is to report on our
results for hand segmentation using networks mainly
trained with synthetic data (plus a few real images
≈ 250) and with repetitive training. We consume no
effort to introduce a new model’s architecture. There-
fore, we employ a well-known neural network archi-
tecture which is called the Mask-RCNN (He et al.,
2020). To segment a new object, a dataset with ≈ 4K
images has an adequate size for training a network
of such characteristics. However, the size of our syn-
thetic data amounts to ≈ 45K images, thus higher than
the typical size by ×10. Therefore, one can examine
the effect of repetitive training on this network.
There is a set of parameters that plays a crucial
role in determining the performance of the networks
(Section 4). Among them, the background’s similari-
ties (besides the repetitive training) seems to play the
most significant role. Therefore, here our focus is
to segment hands on the inputs when the background
has similarities with the training set, using repetitive
training on Mask-RCNN. We leave the more general
investigations of our repetitive training’s benefits on
different scenarios and networks for the future works.
Thus, our work goes beyond the existing literature
in two ways. First, we extend the Mask-RCNN with
mainly synthetic data to segment hands. Secondly,
with our repetitive training, we exploit the transfer
Hand Segmentation with Mask-RCNN Using Mainly Synthetic Images as Training Sets and Repetitive Training Strategy
221

learning in a novel way suitable for this challeng-
ing task (on specific examples), and Mask-RCNN,
despite employing mainly sorely simplistic synthetic
images (alongside a few real ones which have back-
ground similarities with the test set) as the training
set.
Since our results point toward hand segmentation
on a limited number of test sets, we end the introduc-
tion by elaborating more on the general advantages
of repetitive training in resolving premature satura-
tion, based on a short comparative study (Fig.2). To
conduct a systematic comparison, we perform both
of these training schemes with the same training set
(e.g., synthetic data without any real data), the same
number of epochs (e.g., one), and equal values for the
learning rates (e.g., 0.001). The number of overall
steps also is equal (e.g. 1000). In the case of con-
ventional training (e.g., the orange bar at the far left
side of the Fig.2-upper middle), we carry out these
1000 steps in one session. However, in the case of
repetitive training, each repetition has 100 steps (e.g.,
10 × 100 = 1000). The major difference the two,
here, is the number of layers under training. For
conventional training, we let all layers, whereas, for
the repetitive training, we consider alternative layers
of all,all,all,3+,3+,all,all,4+,5+,all learn from our
training set. Finding the optimal frozen layers for
each repetition can be an iterative process.
As seen in Fig.2-upper right, the repetitive train-
ing improves the average loss continuously (expect on
the 4
th
) with the best loss of 0.4113 on the 8
th
repe-
tition (which is better than the conventional loss of
0.4409). Repetitions 9 and 10 did not improve the
average loss. Therefore, we would consider the 8
th
net as the final network. Besides, the Fig.2-bottom
shows the comparison between the batch losses of
all repetitions (with concatenation) and that of the
conventional training. The green curve demonstrates
our repetitive training’s advantages at the end of each
epoch. We illustrate the loss of a selected repetitions
in Fig.2-upper right. One can argue that saturation
begins after step 80. Compared to 100 total steps, the
saturation is not premature anymore, illustrating each
net learns from much of the data, and providing a po-
tential explanation for the advantages of our repetitive
training.
Though the prime inspiration of the method is to
repeatedly train the resulting networks on the next
subset. In Section 4 we demonstrate utilizing an iden-
tical subset for retraining the next net, in some cases,
would also lead to satisfactory results. Testing the
broader applicability of the repetitive training, as a
more general training strategy, requires an extensive
study of different CNN models on various application
domains and objects. Therefore, here, we provide ev-
idence for the feasibility of the approach for a specific
problem, particular object, and a certain network.
2 LITERATURE REVIEW
Currently, there exist many successful object segmen-
tation frameworks, and they fall into two main cate-
gories: semantic, and instance segmentation. The ear-
lier one is a class-level segmentation (e.g., DeepLab
(Chen et al., 2018)), whereas, the latter one, on the
other hand, identifies each object on instance-level for
all trained classes.
Belonging to the family of region-based convo-
lutional neural networks or RCNN (Girshick et al.,
2012), the Mask-RCNN demonstrated one of the most
successful performances on instance segmentation.
The current default framework segments 99 objects
spanning a wide range of categories (e.g., from liv-
ing creatures to electronic devices). It supplies a sim-
ple framework that is straightforward to extend to
segment a new set of objects. Besides, it possesses
other significant properties that make it an appropri-
ate choice of network for this study.
First, it provides us with a wide range of possibil-
ities in setting parameters, from as simple as epoch
numbers to as sophisticated as freezing some layers
during the training. That permits a more thorough
investigation of proposed approaches. Second, be-
sides employing standard convolutional neural net-
works (e.g., V GG, Resnet50, or Resnet101 (He et al.,
2016)), MRCNN allows us to employ a self-trained
net as the backbone to transfer learning. That is es-
sential to study the properties of repetitive training.
Transfer learning (Pan and Yang, 2009), enables
machine learning frameworks to transfer knowledge
by storing the information (e.g., weights in the realm
of convolutional neural networks, CNN), gained from
one field of a problem (e.g., person segmentation)
and applying it to a related but different domain (e.g.,
hand segmentation). Our strategy of repetitive learn-
ing also follows the approach of transfer learning, but
in a different fashion. More specifically, the knowl-
edge is not transferred to a different domain, but to
the same domain (with different training-set and dif-
ferent parameters) over and over again. Beside inves-
tigating this training strategy, an informative study in
which how a segmentation framework, in general, and
the Mask-RCNN, in specific, would perform when
trained on synthetic data, is missing in the literature.
VISAPP 2023 - 18th International Conference on Computer Vision Theory and Applications
222

Figure 3: Forearm rotation with the bind-pose fingers (Top).
Forearm rotation with changing fingers’ states (Bottom).
3 METHODOLOGY
Synthetic Data. To attend to the goal of SaneNet
extension to segmentation, we employ a synthetic
database with similar constraints as in (Dadgar
and Brunnett, 2018). That database is created by
considering in-plane-axis rotation axes as following:
If
−→
V = {v
i
|i = 1,2,...,28} is the total pose vector of
one (right) hand then,
{v
1
,v
2
,v
3
} is the global translation (3 DoF, L
1
),
{v
4
,v
5
,v
6
} is the global rotation (3 DoF, L
2
),
{v
7
,v
8
,} is the wrist rotation (2 DoF, L
3
),
{v
9
,v
10
,v
11
} is the little finger rotation, L
5
1
,
{v
13
,v
14
,v
15
} is the ring finger rotation, L
5
2
{v
17
,v
18
,v
19
} is the middle finger rotation, L
5
3
,
{v
21
,v
22
,v
23
} is the index finger rotation, L
5
4
, and
{v
25
,v
26
,v
27
,v
28
} is the thumb finger rotation, L
5
5
.
By selecting the Forearm rotation with bind-pose
(L
2
) and with fingers motion (L
11
) in in-plane-axis ro-
tation (Fig.3), the data structures are:
−→
V
L
2
InPlane
= {v
4
,v
5
}
−→
V
L
11
InPlane
= {v
4
,v
5
,v
9
,v
10
,v
11
,v
12
,v
13
,v
14
,
v
15
,v
17
,v
18
,v
19
,v
21
,v
22
,v
23
,v
25
,v
26
,v
27
,v
28
}
(1)
Considering 2
◦
-step resolution over two in-plane axes
for both L
2
and L
11
data structures (1), there will be
[(360/2 × 360/2) = 32400 × 2] ≈ 65K poses. By
eliminating the non-plausible poses, the final number
of synthetic poses will be 45K+. We then construct
the images with white background and simple shad-
ing and extract the mask of the hands and perform the
automatic annotation.
Repetitive Training. For extending transfer learn-
ing to repetitive training, we divide the 45K+ syn-
thetic images into S smaller subsets by randomly se-
lecting the images. We, in this paper, use S = 4 or
= 10 with an equal number of synthetic images in
each subset (≈ 10K or ≈ 4.5K). Then, we train a
set of networks using each of those subsets within a
queue of sessions. That is, beginning with the first
subset, we train the first network. Then, we employ
the resultant network as the backbone net for the next
training session, and by employing the second subset,
we train a second network. We continue the procedure
until all subsets are used. To initialize (e.g., train-
ing the first network), we employ an off-the-shelf net
(e.g., Resnet101) as the backbone. For each repetition
session, the Mask-RCNN parameters’ values, such as
step, epoch, ROI numbers, and the frozen layers, can
be different marking one advantage of this training
scheme. For it assists us to concentrate on improving
a particular aspect of the network during each session.
Real Data. In our approach, we consider a few real
images from three different datasets for training pur-
poses. We will analyze these three sets and their
characteristics later in detail (Section 4). However,
here we mark that there are 128 images from Ego-
hands (Fig.5) (Bambach et al., 2015), 130 images
from Kawulok (Fig.7) (Kawulok et al., 2014), and
two more sets from alternative labs as 125 images
from Altlab1 (Fig.6-left), and 125 images from Al-
tlab2 (Fig.6-right). For some networks, we employ
merely one set, and for some others, we might use
two real-sets, in turn or combined. That would lead
the total number of real images either to be ≈ 130
or ≈ 250. In either cases, the percentage of the real
to the synthetic data, µ, remains insignificant (e.g.,
130
45K
= 0.29%, or
250
45K
= 0.56%). However, their spec-
ifications (e.g., background, scale, size) should play a
crucial role in the successful segmentation.
4 EXPERIMENT
We spotted relatively a large set of parameters (in
three categories) require to be properly adjusted: a)
Employing repetitive-training and its settings or not
using it, b) Real training data specifications, and c)
Entire training data specifications. We consider four
parameters from the first two categories (a) and b))
to define the experiments’ types (Table 1): 1) AHA:
All Real Hands in the training-set are Annotated, 2)
BGS and 3) SCS which stand for Background and
Scale Similarity between the real part of training-set
and the test-set respectively, and 4) RPT: Repetitive
Training. By setting them true or false, we will have
2
4
= 16 variant net types which rises to 18 types (de-
noted as A-R) with two extra cases of training with
no real date. However, we employ a selection of them
Hand Segmentation with Mask-RCNN Using Mainly Synthetic Images as Training Sets and Repetitive Training Strategy
223

Vid
1
Vid
2
Vid
3
Img
1
Figure 4: Four test sets: Vid
1
, which has a similar back-
ground and context with one of the training sets. Second,
Vid
2
, which is a cropped and scaled-up version of the Vid
1
with the identical size. Third, Vid
3
, which its background,
scale, and context are different from the real training sets.
Fourth, Img
1
, which consists of randomly selected 1500 im-
ages from 11K-Hand dataset (Afifi, 2017) 100 of which are
annotated for IoU and F1
score
computation.
in our evaluations (Sections 4.1) to keep the paper
within reasonable limits. Additionally, some of these
types (e.g., Ty
(F)
) do not require training the network
anew but rather can be addressed by employing a dif-
ferent test sets. We train the networks with stochas-
tic gradient descent (SGD) optimizer, momentum 0.9,
learning rate of 0.001, and the initial backbone net as
Resnet101 unless mentioned otherwise. During the
training, we set the image size to 1024 × 800px.
The category c) refers to a set of parameters such
as i) the subsets’ number and the amount of images
in each, and ii) the replications’ number for real im-
ages. The replication parameter is necessary for, the
amount of synthetic images (compared to the real
ones) is excessive (e.g., ≥ 45K). Thus the probability
of real images’ engagement within the training pro-
cess decreases for each step and the chance of net-
works to learn more from them before entering the
saturation phase decreases. Therefore, we replicate
(e.g., simple copy-paste) them (n = 5 or 10) times
to alleviate the issue. Additionally, from category
a), there is another parameter by which we determine
the choice of frozen layers. If we systematically de-
fined the experiments with these parameters (too), we
would have exceeded the limits of this paper.
We consider four test sets for the evaluations
(Fig.4): First, Vid
1
which has a similar background
and context with one of the training sets Fig.6 and
contains one subject. There, the hand undertakes
various challenging postures and the frames’ size is
1920×1100px. Second, Vid
2
is a cropped and scaled-
up version of Vid
1
with the same frame size. Vid
2
en-
ables us to examine and investigate the influence of
scales on performance. Third, Vid
3
which has differ-
ent background, scale, and context with Altlab train-
ing sets Fig.6. The video contains one subject but two
hands (which sometimes occlude each other), and the
frames’ size is 1920 × 1080px. Fourth, Img
1
which
consists of randomly chosen 1500 images from the
11K-hand dataset (Afifi, 2017). This test-set con-
tains limited hand postures but is diverse over the
subjects, skin colors, and genders with the size of
Figure 5: EgoHands Dataset (Bambach et al., 2015). They
have the size of 1280 × 720. The scenarios here are two-
subject-games (e.g., chess), and therefore, there exist vari-
ant amounts of hands with complex backgrounds.
1600 × 1200px. For IoU and F1
score
calculations of
Img
1
, we randomly select 100 images from it.
To gain an insight into our four training image
sets, we demonstrate their characteristics and their
comparisons with the test sets briefly: First is the syn-
thetic images (Fig.3) with the size of 1280 × 720px
and plain white backgrounds (comparable to the Img
1
test-set). The images contain no shadows and possess
merely shading. The hand model has a fixed size, and
the hand’s region relatively covers a small portion of
the entire image.
Second is the Egohands images (Fig.5) which
have the size of 1280 × 720px. The scenarios are
two-person-games (e.g., chess), and we select them
in a fashion that they contain no heads. Here, there
exist variant amounts of (maximum four) hands and
complex backgrounds. Thus, there are seldom sem-
blances of scale and context between this and the test
sets. Additionally, for this set, we consider two anno-
tation strategies: a) right-hands only, b) all-hands.
Third, the Altlab
1
images (Fig.6-left) have the
size of 1920×1100px. Its scenario is free movements
of hands with occasional digit gestures. The set con-
tains heads, and the background color and the scene
are identical to that of the Vid
1
test-set. That leads the
Altlab1’s set to be the most similar training-set to one
of the test sets (Vid
1
). However, there are valuable
discrepancies on the subject, hands’ side, and many
gestures between them. Fourth, the Altlab
2
images
(Fig.6-right) have the size of 1920×1100px. The sce-
nario here is also free movements of hands with occa-
sional digit gestures. Besides containing similar dis-
crepancies of Altlab
1
, this time, the background and
the scene are different from that of the Vid
1
test-set.
Finally, the Kawulok images (Fig.7) have their
sizes range from 151 × 208 to 640 × 480. The sce-
nario in Kawulok set is digit-gestures. The images
here contain merely one hand with no heads and have
a simplistic (but non-white) backgrounds, and the
hands cover most of the image patch. Thus, this set is
the closest one, in characteristics, to the Img
1
.
By considering the content of these real sets, we
define two experiments as follows: When the training
set contains synthetic images with 1) No real data, 2)
Various combinations of real data. To evaluate the
performance of the segmentation networks quantita-
tively, we consider four metrics: I) Mean IoU , II) Ac-
VISAPP 2023 - 18th International Conference on Computer Vision Theory and Applications
224

Figure 6: The Altlab
1
training-set (left) and Altlab
2
training-set (right). Both sets have images with the size
of 1920 × 1100 pixels and contains head with scenario of
free movement of hands with occasional digit gestures. The
Altlab
1
has the background color and the scene identical to
that of the Vid
1
test-set. However, the background color and
the scene of the The Altlab
1
are different from Vid
1
.
Figure 7: Kawulok1Hand Dataset (Kawulok et al., 2014).
The selected images have their sizes range from 151 × 208
to 640 × 480. The scenario here is specific digit-gestures.
The entire images of this set contain merely one hand, and
they do not include heads. They have a simplistic (but non-
white) background, and the hands cover most of the image.
curacy (Acc), and III) F1
Score
. Besides these three, we
define a fourth metric denoted as T PH. It reveals the
number of true positives oriented toward the number
of segmented hands having the highest score. There
are frames in which the true positive has the highest
score compared to the false positive scores. Thus we
can filter out the false positives as if there is none.
Therefore, the T PH can reveal valuable information
about the performance of the networks.
4.1 Evaluation
We trained and tested an ample amount of networks
(300+) with variant parameter settings to achieve our
best results, pacing through a trial-and-error path. For
the evaluation purposes, we select a limited number
of (= 11) cases (Table 3, 4) within two experiments
considering 6 types (Table 2).
E
E
Exp
1
: This experiment employs two net types
(Ty
(A)
and Ty
(B)
) seeking to investigate the poten-
tials of the synthetic dataset and repetitive training,
when no real data is employed. Since the background
of our training set, here, is simplistic, the main fo-
cus here is to investigate the influence of the repeti-
tion for segmenting hands on Img
1
which has simple
backgrounds (C
#
1
and C
#
2
in Table 3). However, we
present two more cases that can reveal interesting in-
formation about our simplistic training set. The cases
C
#
1
, C
#
3
, and C
#
4
have the same network that we test
on three different test sets Vid
1
, Vid
2
, Img
1
, respec-
tively (epochs = 5, steps = 1000, ROI = 300, and
trained layers = 4+). The case C
#
2
employs repetitive
training (ten repetitions) with the same learning rate
as other cases, various epoch numbers for each repe-
tition (maximum 5), and the following trained layers:
all,all,3+,3+,4+,4+,5+,5+,heads,heads. As
seen in the table, C
#
2
though have a slightly worse
Acc and F1
score
, due to merely one more false posi-
tive on C
#
2
. However, both of them have T PH = 100,
so the false positives can be canceled out, emphasiz-
ing more weight on the IoU for their comparison. As
for the IoU , we face an improvement (to almost 90%)
on C
#
2
, pointing toward the benefits of our repetitive
training scheme. In C
#
3
and C
#
4
(with more complex
backgrounds), there are many false positives (Fig.8-
a). However, the true positives are also high result-
ing in noticeable scores. In C
#
4
, the hands’ scale be-
comes similar (to the synthetic images), and the back-
ground becomes simpler. Therefore, the performance
is much better than in C
#
3
. One major issue with C
#
3
and C
#
4
is that the true positives do not exhibit the
highest scores for us to filter false cases (low T PH),
suggesting we should include real data and repetitive
training if higher IoU and F1
score
are sought. To end,
we also carried out repetitive training with no real data
for Vid
1
and Vid
2
. The repetition reduced false posi-
tives, only in some cases. However, the true positives
also decreased, so we do not report those cases.
E
E
Exp
2
: This experiment seeks to investigate the po-
tentials of the synthetic dataset and repetitive training,
combined with real data. For Egohands dataset, we
employ the annotation of all-hands and in some cases
annotation of right hands-only. Furthermore, we di-
vide the training set into 10 and 4 subsets. This exper-
iment (considering all scales and backgrounds simi-
larities) fall into types Ty
(D)
, Ty
(L)
, Ty
(P)
, and Ty
(R)
with illustrating the eight best cases. When using
Egohands (thoroughly distinctive background) in our
training set, the performance does not suggest any
advantages. However, there is a case that reveals a
unique behavior (C
#
5
). That is, false positives show
considerable reduction using our repetitive training
(and 10 subsets with 4.5K images in each set). As
shown in Fig.8-b, though there are no true positives,
the mere reduction of false positives to zero is an op-
timistic outcome because we employ it as the back-
bone net of our future repetitions. Zero false posi-
tives are achievable in earlier repetitions of our train-
ing scheme. However, we continue the repetition un-
til robust error-free results are witnessed (e.g., C
#
5
)
on Vid
1
(and also on Vid
2
). We train this network
with epoch=4, spets=150, RoI=150, with ×5 repli-
cations of Egohands, and only right hands are anno-
tated. Then we employ the Altlab
1
dataset (that has
similarities of backgrounds with Vid
1
and Vid
2
) as a
part of our training set, with dividing the synthetic
dataset into 4 subsets (each containing ≈ 10K images)
Hand Segmentation with Mask-RCNN Using Mainly Synthetic Images as Training Sets and Repetitive Training Strategy
225

Table 1: By setting RPT, AHA, BGS, and SCS true/false and adding two case (of no real date) we have 18 types (A-R).
Type A B C D E F G H I J K L M N O P Q R
RPT × × × × × × × × ×
AHA
No RlDB
No RlDB
× × × × × × × ×
BGS × × × × × × × ×
SCS × × × × × × × ×
Table 2: Network’s types we selected in our experiments.
Network’s types of Evaluation Section
Exp Exp
1
Exp
2
Type A B D L P R
Network’s types of Ablation Study Section
Type K L M N O P Q R
Table 3: E
E
Exp
1
: No real data is included in the training sets.
Input TtlHnd IoU Acc F1
C
#
1
I mg
1
100 0.837 0.862 0.926
C
#
2
I mg
1
100 0.89 0.855 0.922
C
#
3
Vid
1
1425 0.483 0.259 0.412
C
#
4
Vid
2
1425 0.580 0.515 0.680
and ×10 replications. In repetitive training, instead
of using Resnet101, we employ C
#
5
as the backbone.
Subsequently, that leads to indirectly combining the
Al tlab
1
and Egohands (and their advantages) during
the training sessions. With such a combination, we
decrease the false positives while increasing the true
positives. In C
#
6
, we train from layer fourth onward
and thus freeze the previous ones. Though the number
of FP is high, most metrics experienced significant
improvements compared to C
#
3
. We restart the train-
ing from layer three onward, and with this modifica-
tion, signs of profound improvement begin to appear,
(C
#
9
in Table 4 and Fig.8-c and -d). Testing the iden-
tical network of C
#
9
on the Vid
2
(in C
#
10
), decreases
F1
Score
. However, there is an increment in the num-
ber of those true positives (e.g., hands) that exhibit
the highest value. That suggests the network’s suc-
Table 4: E
E
Exp
2
: Real data is included in the train sets.
Repetition on Resnet101: with Egohands, 10 Subsets
Input TtlHnd IoU Acc F1
C
#
5
Vid
1
1425 NAN NAN NAN
Repetition on C
#
5
: with Altlab
1
4 Subsets, Starting From Lyr 4
C
#
6
Vid
1
1425 0.592 0.361 0.530
Repetition on C
#
5
: with Altlab
1
4 Subsets, Starting From Lyr 3
C
#
7
Vid
1
1425 0.826 0.030 0.059
C
#
8
Vid
1
1425 0.747 0.543 0.704
C
#
9
Vid
1
1425 0.700 0.811 0.900
C
#
10
Vid
2
1425 0.703 0.607 0.755
C
#
11
Vid
3
1500 0.452 0.560 0.718
a) b) c) d)
Figure 8: Result visualization: a) C
#
3
resulted in many false
positives, b) C
#
5
created optimism because of zero false pos-
itives. The best results achieved using c) C
#
9
, and d) C
#
10
.
a) b) c) d)
Figure 9: Result visualization: a) False Positives when
Resnet50 is the Backbone Network, b) True Positives, c)
Comparison of a network similar to C
#
9
with a network
trained on Kawulok Dataset Fig.7, d) Comparison of net-
works (trained with no real data) using conventional train-
ing C
#
1
and using repetitive training C
#
2
on Img
1
.
cess on distinct hand scales. In the repetition for C
#
9
,
merely changing the freezing layer (and not the sub-
set) was adequate to significantly improve the results
compared to C
#
8
. For training these networks, we set
epoch = 4, steps = 500, and ROI = 300.
4.2 Ablation Study
In exploring our way for a successful segmentation
we considered training various types (See Table 2)
and initially focused on using Vid
1
. One of the trou-
blesome false positives to mitigate during this period
was the ‘person’ (or ‘subject’). Because, during many
testing phases, its region remained among the FPs
irrespective of the selected parameter settings. Ini-
tially, we suspected this false positive comes with the
off-the-shelve backbone default classes. However, by
altering the backbone from Resnet101 to Resnet50
and employing repetitive training (Fig.9-a), the seg-
mented area of the false positives is partial and re-
sembles a scaled-up hand. That led us to this re-
alization, the hand’s scales and backgrounds in the
real data play significant roles. Additionally, the ini-
tial training’s repetitions resulted in no true positives.
However, as we continued the repetition process, the
T Ps increased to a skimp but an informative amount
(five segmentations) as in Fig.9-b. To further exam-
ine the significance of scale similarities, we trained
one more set of networks with our selected Kawulok
dataset (Fig.7), with repetition, and tested them on the
VISAPP 2023 - 18th International Conference on Computer Vision Theory and Applications
226

Img
1
. As qualitatively visible in Fig.9-c, the network
trained on the Kawulak dataset as a part of the train-
ing set achieves higher IoU (0.78 compared to 0.06
when trained on Altlabs). We anticipated that is for
the higher similarities in scales the Kawulak dataset
has with Img
1
.
We then employed the Altlab datasets (See Fig.6)
as the real part of training-set (Ty
(M)
, Ty
(N)
, Ty
(O)
,
Ty
(P)
, Ty
(Q)
, and Ty
(R)
). By employing Altlab
1
, the
false positive number enhanced. However, since the
overall true positive faced a slight decay, the F1
score
slightly decreased. By employing Altlab
2
(C
#
6
), we
achieved slightly better enhancement for the false
positives. We speculated it is because of the variant
backgrounds the Altlab
2
training set contains. How-
ever, true positives showed more decrease resulting in
the same F1
score
. When the images’ number in each
subset was 10K, the performance did not always illus-
trate improvements. That points to the networks’ sen-
sitivity of the training on the number of images each
subset ought to contain, and consequently the number
of repetitions we should carry out during the training.
Above, we witnessed enhancement in true posi-
tives using Altlab
1
. In C
#
5
, we faced enhancement of
false positives using Egohands. Therefore, we consid-
ered training with the combination Egohands dataset
with Altlab (especially Altlab
1
) to intertwine the ad-
vantages of both training sets: 1) reducing the false
positives with the Egohands dataset and 2) increas-
ing the true positives with Altlab
1
. We considered six
types of Ty
(K)
, Ty
(L)
, Ty
(M)
, Ty
(N)
, Ty
(Q)
, Ty
(R)
with
various settings, such as the number of real data repli-
cation (e.g., ×10 ) and the number of subsets and
repetitions. However, we did not achieve satisfactory
performance. That is, despite witnessing some im-
provements in IoU, by employing repetitive training,
a pivotal improvement (on both IoU and F1
Scores
) was
not measurable. All these guided us: First, to employ
Egohands data, carry out the repetition (C
#
5
). Sec-
ond, to use the Altlab
1
and perform another repetition
(C
#
9
). That is, we combined the two datasets in two
separate repetitive sessions toward E
E
Exp
2
.
5 DISCUSSION & CONCLUSION
We extended the Mask-RCNN framework to hand
segmentation using mainly simplistic synthetic im-
ages and a few real images (SaneNet approach) as
the training-set. To benefit from our sorely simplistic
data, we introduced a specific training scheme with
repetition. We had to accurately set a range of param-
eters (from the real to synthetic data, and the repeti-
tion to frozen layers) to achieve optimal results.
For training and testing ample number of net-
works, we considered five training and four test sets,
with diverse characteristics (backgrounds, scales, and
scenarios). The performance was significant even
when our training set was mainly simplistic synthetic
data. We also conducted a short study (Section 1),
quantitatively demonstrating the benefits of our repet-
itive training on a more general ground (with Mask-
RCCN). There, we showed that repetitive training can
help improving the average and batch loss when we
employ similar parameters for both schemes. Initially,
we aimed for the right-hands only segmentation. But
this goal is not feasible, even if we train the Deeplab,
(Chen et al., 2018) with purely 4K real images.
As future works, we can pace into several fasci-
nating paths. First, we can consider repetitive train-
ing using purely (but with slightly more sophisticated)
synthetic data. That enables us to analyze the effec-
tiveness of the method in eliminating the necessity of
incorporating real images. As a piece of evidence in
that direction, we trained networks solely on synthetic
data once without repetitive training (C
#
1
) and once
with repetition (C
#
2
) and achieved a higher IoU on a
simple test-set (See Fig.9-d). Second, we can evaluate
the efficacy of our training scheme on a wider range of
tasks such as classification, detection, segmentation,
and pose estimation networks using purely real data.
Alongside diverse tasks and networks, the consider-
ation of various objects (besides hands) can examine
the validity of this training as a more general scheme
in the realm of machine learning.
ACKNOWLEDGEMENTS
This project was funded by the Deutsche Forschungs-
gemeinschaft (DFG) CRC 1410 / project ID
416228727. I also thank Mr. Stefan Helmert, with
whom I conducted fruitful scientific discussions.
REFERENCES
Afifi, M. (2017). 11K Hands: Gender recognition and bio-
metric identification using a large dataset of hand im-
ages. Springer.
Bambach, S., Crandall, D. J., and Yu, C. (2015). Lending
A Hand: Detecting Hands and Recognizing Activities
in Complex Egocentric Interactions. In IEEE.
Chen, L.-C., Papandreou, G., Kokkinos, I., Murphy, K.,
and Yuille, A. L. (2018). DeepLab: Semantic Image
Segmentation with Deep Convolutional Nets, Atrous
Convolution, and Fully Connected CRFs. IEEE Trans
PAMI, 40(4):834–848.
Hand Segmentation with Mask-RCNN Using Mainly Synthetic Images as Training Sets and Repetitive Training Strategy
227

Dadgar, A. and Brunnett, G. (2018). Multi-Forest Classifi-
cation and Layered Exhaustive Search Using a Fully
Hierarchical Hand Posture / Gesture Database. In VIS-
APP, Funchal.
Dadgar, A. and Brunnett, G. (2020). SaneNet: Training a
Fully Convolutional Neural Network Using Synthetic
Data for Hand Detection. IEEE SAMI, pages 251–256.
Girshick, R., Donahue, J., Darrell, T., Malik, J., and Berke-
ley, U. C. (2012). Rich feature hierarchies for accurate
object detection and semantic segmentation.
He, K., Gkioxari, G., Doll
´
ar, P., and Girshick, R. (2020).
Mask R-CNN. IEEE Trans on PAMI, 42(2):386–397.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep resid-
ual learning for image recognition. IEEE Proc CVPR,
Dec:770–778.
Kawulok, M., Kawulok, J., Nalepa, J., and Smolka, B.
(2014). Self-adaptive algorithm for segmenting skin
regions. Eurasip Journl on Adv in SigProc, (1):1–22.
Pan, S. J. and Yang, Q. (2009). A Survey on Transfer Learn-
ing. IEEE Knowledge & Data Eng, 194:781–789.
Rakitianskaia, A. and Engelbrecht, A. (2015). Measuring
saturation in neural networks. IEEE Symp Series on
Computational Intelligence, pages 1423–1430.
VISAPP 2023 - 18th International Conference on Computer Vision Theory and Applications
228
