
Federated Health Recommender System
Sarah Pinon
1 a
, Simon Jacquet
1
, Colin Vanden Bulcke
2 b
, Edouard Chatzopoulos
3 c
,
Xavier Lessage
4 d
and Rapha
¨
el Michel
4 e
1
NaDI, Namur Digital Institute, University of Namur, Belgium
2
IONS, Institute of NeuroScience, UCLouvain, Belgium
3
ICTEAM, Institute of Information and Communication Technologies, Electronics and Applied Mathematics, UCLouvain,
Belgium
4
CETIC, DSIDE, Charleroi, Belgium
Keywords:
Health, Precision Medicine, Patient-Oriented Decision Support System, Recommender System, Federated
Learning.
Abstract:
Precision Medicine is a new and growing approach to health care. This initiative includes different patient-
oriented Decision Support Systems (DSS), such as Health Recommender Systems (HRS). These patient-
oriented DSS aim to increase the accuracy and personalization of health care. However, the development
of these systems faces a major obstacle related to the confidential and private nature of medical data. These
systems require, indeed, a large volume of data to run effectively. But medical data are dispersed among sev-
eral institutions and cannot be centralized for strict confidentiality reasons. To address this issue, this position
paper proposes a system’s architecture in which Federated Learning is exploited to build a HRS. Federated
Learning allows exploiting the data maintained by different institutions to build the system without requiring
their sharing. To demonstrate the feasibility of our proposition, we build a Federated Drug Recommender Sys-
tem. The goal of the system is to assist doctors in their administration of drugs by using historical disease-drug
interactions and drug data. As a position paper, the objective of this use case is limited to a proof of concept
realized on non-sensitive open-source data. Our ambition is then to use the architecture proposed in this paper
to develop a Federated HRS on real medical data.
1 INTRODUCTION
Precision Medicine is currently increasing in popu-
larity with its ambitious promises of achieving an
incomparable quality of healthcare (Koenig et al.,
2017; Kosorok and Laber, 2019). To achieve its
promises, this healthcare approach aims to offer per-
sonalized treatment strategies to patients by consid-
ering a large amount of data. This data includes, for
example, the patient’s clinical condition, lifestyle, ge-
netics, biomarker information. By including all this
information, this medicine is able to offer more pre-
cise therapeutic strategies (Koenig et al., 2017).
The aspiration of Precision Medicine is perfectly
a
https://orcid.org/0000-0001-5392-1020
b
https://orcid.org/0000-0002-2210-1625
c
https://orcid.org/0000-0001-5848-7999
d
https://orcid.org/0000-0003-0861-0068
e
https://orcid.org/0000-0001-5505-9171
aligned with the mission of Health Recommendation
Systems (HRS). HRS are, indeed, intended to help
healthcare professionals to deal with medical infor-
mation overload (e.g. medical results, drug informa-
tion, pathology information) in their patient decision-
making (Tran et al., 2021). These patient-oriented de-
cision support systems consider these large volumes
of data to recommend, for example, the most appro-
priate medication, treatment or lifestyle (De Croon
et al., 2021).
The performance of HRS, like any RS, depends
crucially and positively on the volume of data ex-
ploited (Tan et al., 2020). In the era of Big Data,
the volume of medical data available is increasingly
important, coming from clinical institutions, individ-
ual patients, pharmaceutical industries,...(Xu et al.,
2021). This emergence represents a great opportunity
for HRS.
However, the accessibility of this data is challeng-
Pinon, S., Jacquet, S., Bulcke, C., Chatzopoulos, E., Lessage, X. and Michel, R.
Federated Health Recommender System.
DOI: 10.5220/0011722700003414
In Proceedings of the 16th International Joint Conference on Biomedical Engineering Systems and Technologies (BIOSTEC 2023) - Volume 5: HEALTHINF, pages 439-444
ISBN: 978-989-758-631-6; ISSN: 2184-4305
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
439

ing. Indeed, medical data is, in the hospital context
for example, fragmented across several hospitals. For
confidentiality and privacy reasons, these data cannot
be easily accessed and centralized on a server outside
the institutions to build an effective RS. This limits the
creation of a robust, generalizable and high-quality
system. Conversely, by developing small, local sys-
tems within each hospital, several biases will impact
the quality of the results, such as considering only a
subset of conditions or treatments (Xu et al., 2021;
Rieke et al., 2020).
To exploit medical data from several hospitals to
build a generalizable model, we propose to use Feder-
ated learning (FL). The privacy and security concerns
very important in the medical sector are, by this way,
addressed. Indeed, the FL allows institutions to train
the RS on their own infrastructure without exchang-
ing raw (e.i. sensitive) data. The only information
shared between the different parties for the construc-
tion of the global model corresponds to the model pa-
rameters (Kaissis et al., 2020; Li et al., 2020; Rieke
et al., 2020; Xu et al., 2021).
In this paper, we propose the architecture of a
HRS exploiting the FL, named Federated Health Rec-
ommender System (F-HRS). The particularity of the
proposed architecture lies in the integration of FL to
build the recommendation model. In this way, our
system overcomes the medical data confidentiality is-
sues stated above. This position paper demonstrates
then the feasibility of our proposition by using non-
sensitive and open-source data to develop a Feder-
ated Drug Recommender System. In future work, we
will exploit real data from hospitals to demonstrate
the usefulness and effectiveness of our system in real
situations.
This paper is organized as follows: Section 2 re-
views the state of the literature about HRS and FRS.
Section 3 develops the architecture of the proposed
system, the selected model used in our system and
the federated learning method exploited. Section 4
presents our proof of feasibility. Section 4 discusses
our future works. Section 5 concludes the paper.
2 LITERATURE REVIEW
Recommendation systems in the health field are in-
tended for two types of users: (1) patients or healthy
users and (2) health professionals. In the case of pa-
tients, these RS allow to involve patients in the co-
creation of their own health. HRS for healthcare
professionals aim at assisting these professionals to
provide precise patient-oriented decision (De Croon
et al., 2021; Tran et al., 2021). In this project, we
focus on HRS for healthcare professionals. The ma-
jority of these HRS concern, in the literature, the rec-
ommendation of drugs for different pathologies (e.g.
diabetes, migraine, infectious diseases).
A major challenge faced by existing HRS is the
accessibility of medical data that is sensitive and con-
fidential(Tran et al., 2021). To deal with this prob-
lem, the commonly used approach is data encryption.
This method allows to keep the confidentiality of the
data while exploiting them in the system of recom-
mendations (Tran et al., 2021). Indeed, data encryp-
tion, such as homomorphic encryption, involves en-
cryption of the data by the users before sending it to
another party. It is then the encrypted data, and not the
raw and complete data, which is used to compute the
interest function (Hoens et al., 2013). However, this
approach of data encryption raises problems due to its
high computational and communication costs, which
considerably reduces the performance of the recom-
mendation system(Tran et al., 2021).
A technique increasingly used by RS to exploit
larger and more widely distributed data while pre-
serving its confidentiality and security is Federated
Learning (Alamgir et al., 2022). This type of learning
has the particularity, as opposed to data encryption, to
train the algorithm where the data are located (e.g. in
each hospital). After this local training, the model pa-
rameters are, after an encryption, returned to the cen-
tral model. By this way, the data confidentiality and
privacy are protected which is especially important in
the medical field (Kaissis et al., 2020).
To the best of our knowledge, despite the interest
of Federated Learning for Recommendation Systems
and medical data accessibility issues, no HRS has yet
integrated the Federated Approach to exploit all med-
ical data while preserving their privacy.
3 F-HRS ARCHITECTURE
F-HRS architecture proposed has three main compo-
nents, namely: the Input Data, the Recommender Al-
gorithm and the Federated Method. This section de-
velops each of these components. Figure 1 illustrates
the combination of these components in an architec-
tural way. This illustration is further explained in the
following subsections.
3.1 Input Data
F-HRS exploits different types of databases, as shown
in Figure 1. On the one hand, our system uses hospital
data related to patients such as their medical history,
their profile, the results of their medical examinations.
HEALTHINF 2023 - 16th International Conference on Health Informatics
440
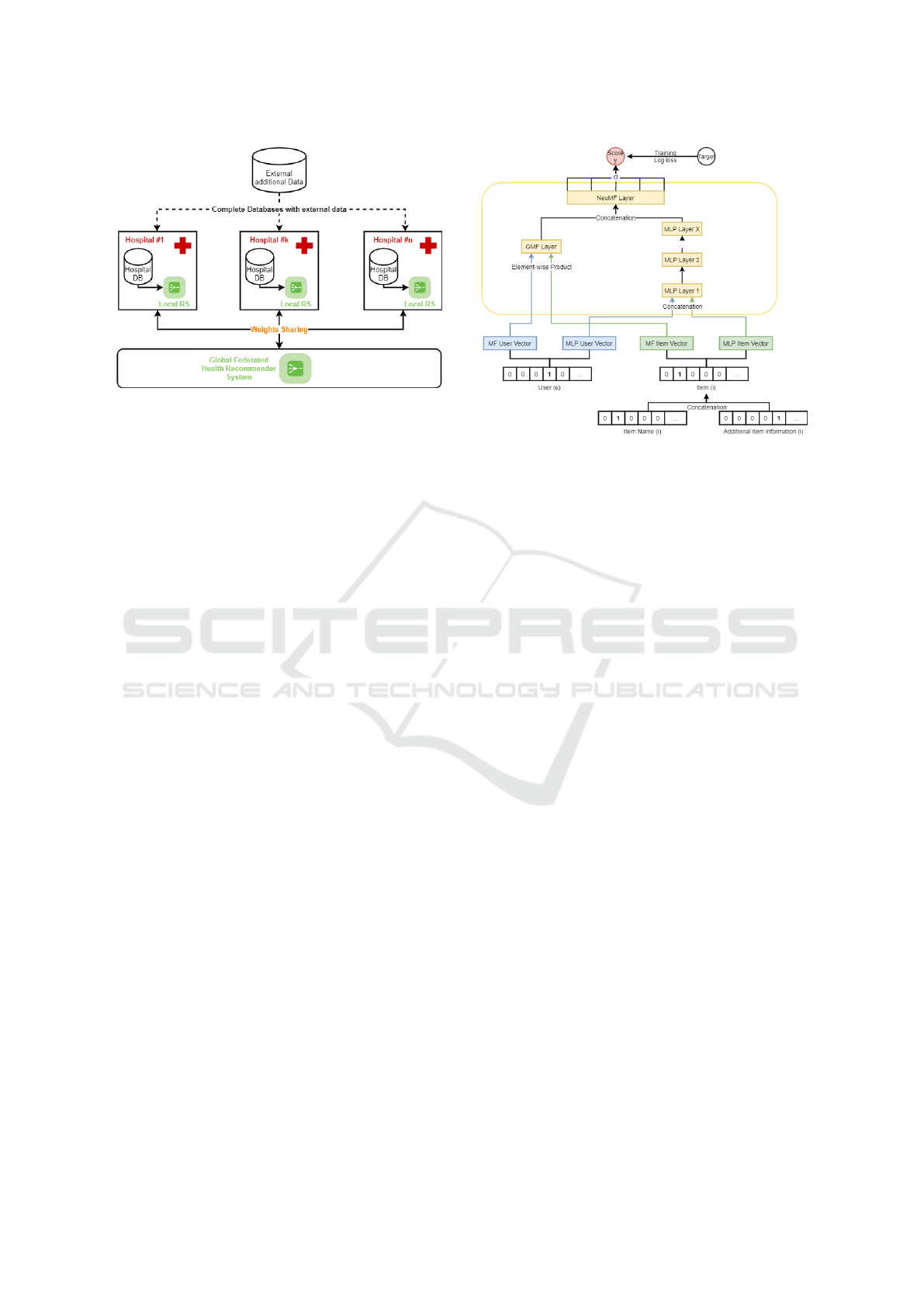
Figure 1: F-HRS Architecture.
These data are in the database of the individual hos-
pitals and cannot be shared due to their private status.
On the other hand, our system can be fed by an ex-
ternal database containing information on the recom-
mendation items. This database, unlike the others, is
open-source and can therefore be used by the different
hospitals.
3.2 Recommender Algorithm
The Recommender Algorithm used by our F-HRS is
the Neural Collaborative Filtering (NCF) Algorithm
(He et al., 2017a). This algorithm works on the princi-
ple of collaborative filtering. This filtering is famous
in RS and consists in finding users similar to the user
of interest and recommending to this user items liked
or used by these similar users (Schafer et al., 2007).
We have chosen this algorithm because the integration
of a neural network within the Collaborative Filter-
ing Algorithm allows to learn the interaction function
between users and items automatically from the data
rather than manually as is the case in the basic algo-
rithm. Moreover, the NCF Algorithm allows to easily
integrate content features representing users and/or
items and therefore offer more accurate and relevant
recommendations(He et al., 2017b).
Concretely, the NCF algorithm used is illustrated
in Figure 2. To process, the algorithm requires, as in-
puts, positive and negative examples of interactions
between users and items. In our case, we applied the
general approach which consists of randomly gener-
ate four negative examples for each user or patient by
using items for which the user has not yet interacted.
Positive and negative interactions between users and
items are stored into binary matrix. The users or items
matrix can, eventually, be enriched with additional
data, by concatenating the binary vectors, as shown
in Figure 2 for the items case. Each complete user’s
vector and item’s vector from the matrix are then em-
Figure 2: Neural Collaborative Filtering Architecture.
bedded in d dimensions, eight by default. These vec-
tors are concatenated and introduced in the neural net-
work. Inputs are passed to the hidden layers of the
multilayer neural network to learn these non-linear re-
lationships between users and items. Most NCF im-
plementations use 4-5 dense layers with less than 100
neurons per layer. The last layer of the network is a
sigmoid function which maps its inputs to a score be-
tween zero and one to represent the probability that
the user interacts with the item. The algorithm is
trained on five epochs, which a standard. For each
epoch, a new set of negative examples is composed
for each user.
3.3 Federated Learning
To integrate the Federated approach to the HRS, we
follow the five general steps, namely (Nishio and Yo-
netani, 2019):
1. Initialization: A global model is initialized ran-
domly or by pre-training with public data. For our
experiments, we randomly initialized the weights,
which is a common practice in federated learning.
2. Client Selection: The different parties (e.i. hospi-
tals) which will contribute to the federated train-
ing are selected. By default, our framework se-
lects clients (e.i. hospital servers) in their start or-
der without taking into account a possible client
to be discarded. If the need arises, it is quite pos-
sible to add additional functionality to this frame-
work to select clients based on various criteria (e.
i. such as performance or dataset quality).
3. Distribution: The weights from the global model
are shared with the parties. This step is criti-
cal and must incorporate the best approach to se-
Federated Health Recommender System
441

cure weight distribution (P. Treleaven and Pitha-
dia, 2022) based on, for example, homomorphic
encryption (HE) classical encryption (TLS), dif-
ferential privacy (DP) or Secure Multi-party Com-
putation (SMPC).
4. Update and Upload: Each party (e.i. hospital)
trains the model (e.i. Collaborative Filtering Al-
gorithm) on their local data, and subsequently up-
loads the updates model weights to the server.
5. Aggregation: The weights collected are aggre-
gated and the global model is replaced with the
model resulting from the aggregation. The aggre-
gation can be carried out by means of a weighted
sum for example, but there are many methods de-
pending on the type of data to be trained. In our
system, we use the Federated Averaging method.
This aggregation method is the most prevalent
one, because of both its simplicity and its perfor-
mance. Federated averaging consists in comput-
ing the weight of the global model as the average
of the weights of the clients models.
All steps except the Initialization are iterated until
the global model achieves a desired level of perfor-
mance.
Various frameworks are available for the deploy-
ment of this Federated approach. In the context of
this project, we opted for Flower (Beutel et al., 2021).
Flower is an open source framework dedicated to
facilitate the deployment of machine learning algo-
rithms in federated environments. The following fig-
ure 3 shows its architecture based on an aggregation
server and several clients running with different envi-
ronments. The main particularity of Flower compared
to other Federated Learning frameworks is its support
for a wide variety of machine learning back-end li-
braries such as Pytorch, Tensorflow or Jax thanks to
its ML framework-agnostic implementation. Flower
is also flexible, as it allows both single host simulation
and multi-host deployment of the federated procedure
(Liu et al., 2022).
Figure 3: Flower core framework architecture.
4 PROOF OF FEASIBILITY
To demonstrate the feasibility of the proposed archi-
tecture, we develop a simple Federated Drug Recom-
mender System based on non-sensitive open-source
data. To goal of this Recommender System is to as-
sist the doctors in the drugs administration.
To achieve this, our system exploits two types of
databases. The first concerns interactions between
drugs and diseases (Dat, 2018). The second is re-
lated to drugs’ features (e.g. pharmaceutical class,
contraindications) (Dru, 2022).
To build our system, we divide the data set with
the drugs pathology’s interactions in a training and
test sets. The test set contains for each pathology the
last drug related in the database. First, we used the
training set to build our system following the archi-
tecture developed in the previous sections. In a sec-
ond step, we evaluated the performance of our system
by checking if the last drug associated to the pathol-
ogy for which we search for a drug is in the ten drugs
recommendations made by our system.
The performance of our Federated Drug Recom-
mender System is not presented in this paper. These
figures are, indeed, at the moment irrelevant since our
system is still being improved and requires better and
real data to illustrate the relevance of the approach.
Nevertheless, thanks to our use case, the technical fea-
sibility of the architecture could be validated.
5 POTENTIAL ISSUES AND
CONCERNS
During the development of our system architecture,
we considered potential problems related to our ap-
plication domain (i.e. the medical sector) and to the
applied approach.
First, the medical field is facing a lack of stan-
dardization of data formats and protocols which can
negatively affect the integration of data from multiple
sources. To face this problem, we have two solutions.
In a first step, it is possible to focus on data collected
by widely used software and therefore store it accord-
ing to a certain standardized structure. Secondly, this
problem of standardization is known within the liter-
ature and the medical section. It generates, indeed,
the development of standardized data formats such as
OMOP (Klann et al., 2019; Makadia and Ryan, 2014).
These new data formats would solve this heterogene-
ity problem.
Second, implementing the federated approach is
more resource intensive than a traditional centralized
system. Nevertheless, the potential benefits of a fed-
HEALTHINF 2023 - 16th International Conference on Health Informatics
442

erated approach in the medical field can far outweigh
the challenges of implementing it.
Third, the risk of data bias and incorrect recom-
mendations to the incomplete data in any machine
learning system is a reality. With the federated learn-
ing, we try to reduce that risk by training a module
with more data coming from multiple sources. By this
way, more comprehensive data can be available but
also more diverse datasets. Non-IID data across data
providers can, indeed, be a major issue in FL. How-
ever, a lot of research (Li et al., 2019; Zhao et al.,
2018) is carried out and techniques are being devel-
oped to improve the quality of federated systems in
such settings.
6 FUTURE WORK
Having developed the architecture of our F-HRS and
demonstrated its technical feasibility, our next goal
is to operationalize this system on real data. To
achieve this, we are in discussion with different hos-
pitals to get our local models developed on their real
database. This step will obviously require some para-
metric adaptations of the system.
Moreover, after several discussions with health
care professionals, it is clear that hospital data is
rarely in a structured format. Generally, medical re-
ports are available as PDF documents written in nat-
ural language. To be able to integrate this impor-
tant information into our recommender system, an im-
portant step related to the data preparation must be
considered. To do so, different techniques of Natu-
ral Language Processing will have to be mobilized in
order to transform these unstructured data into struc-
tured data.
7 CONCLUSIONS
In this position paper, we propose to integrate the Fed-
erated Learning to build a health recommender model.
By this way, we want to overcome the lack of data
that medical institutions face in developing patient-
oriented decision support systems. Indeed, federated
approach allows to train a general and robust recom-
mender model on data from several institutions with-
out the need to share the raw data. The technical feasi-
bility of our solution has been demonstrated via open-
source data in the context of a drug-recommender sys-
tem.
ACKNOWLEDGEMENTS
We would like to thank the Walloon region for the
funding of the ARIAC project, of which our F-
HRS project was born and is part. Thanks also to
the TRAIL organization which organized the TRAIL
Summer Workshop in September 2022 during which
our F-HRS project was developed.
REFERENCES
(2018). Recommendation medicines by using a re-
view. https://www.kaggle.com/code/chocozzz/
recommendation-medicines-by-using-a-review/data.
Accessed on 2022-09-08.
(2022). Drugcentral. https://drugcentral.org/. Accessed on
2022-09-08.
Alamgir, Z., Khan, F. K., and Karim, S. (2022). Federated
recommenders: methods, challenges and future. Clus-
ter Computing, pages 1–22.
Beutel, Qiu, T. M., Parcollet, de Gusmao, and Lane (2021).
Flower: A friendly federated learning framework. On-
device Intelligence Workshop at the Fourth Confer-
ence on Machine Learning and Systems (MLSys).
De Croon, R., Van Houdt, L., Htun, N. N.,
ˇ
Stiglic, G.,
Abeele, V. V., Verbert, K., et al. (2021). Health recom-
mender systems: systematic review. Journal of Medi-
cal Internet Research, 23(6):e18035.
He, X., Liao, L., Zhang, H., Nie, L., Hu, X., and
Chua, T.-S. (2017a). Neural collaborative filtering.
https://arxiv.org/.
He, X., Liao, L., Zhang, H., Nie, L., Hu, X., and Chua, T.-S.
(2017b). Neural collaborative filtering. In Proceed-
ings of the 26th international conference on world
wide web, pages 173–182.
Hoens, T. R., Blanton, M., Steele, A., and Chawla, N. V.
(2013). Reliable medical recommendation systems
with patient privacy. ACM Transactions on Intelligent
Systems and Technology (TIST), 4(4):1–31.
Kaissis, G. A., Makowski, M. R., R
¨
uckert, D., and Braren,
R. F. (2020). Secure, privacy-preserving and feder-
ated machine learning in medical imaging. Nature
Machine Intelligence, 2(6):305–311.
Klann, J. G., Joss, M. A., Embree, K., and Murphy,
S. N. (2019). Data model harmonization for the
all of us research program: Transforming i2b2 data
into the omop common data model. PloS one,
14(2):e0212463.
Koenig, I. R., Fuchs, O., Hansen, G., von Mutius, E., and
Kopp, M. V. (2017). What is precision medicine? Eu-
ropean respiratory journal, 50(4).
Kosorok, M. R. and Laber, E. B. (2019). Precision
medicine. Annual review of statistics and its appli-
cation, 6:263.
Li, T., Sahu, A. K., Talwalkar, A., and Smith, V. (2020).
Federated learning: Challenges, methods, and fu-
ture directions. IEEE Signal Processing Magazine,
37(3):50–60.
Federated Health Recommender System
443

Li, X., Huang, K., Yang, W., Wang, S., and Zhang, Z.
(2019). On the convergence of fedavg on non-iid data.
arXiv preprint arXiv:1907.02189.
Liu, X., Shi, T., Xie, C., Li, Q., Hu, K., Kim, H., Xu,
X., Li, B., and Song, D. X. (2022). Unifed: A
benchmark for federated learning frameworks. ArXiv,
abs/2207.10308.
Makadia, R. and Ryan, P. B. (2014). Transforming the pre-
mier perspective
R
hospital database into the observa-
tional medical outcomes partnership (omop) common
data model. Egems, 2(1).
Nishio, T. and Yonetani, R. (2019). Client selection for fed-
erated learning with heterogeneous resources in mo-
bile edge. IEEE International Conference on Com-
munications, 2019-May.
P. Treleaven, M. S. and Pithadia, H. (2022). Unifed: Fed-
erated learning: The pioneering distributed machine
learning and privacy-preserving data technology. ieee.
Rieke, N., Hancox, J., Li, W., Milletari, F., Roth, H. R.,
Albarqouni, S., Bakas, S., Galtier, M. N., Landman,
B. A., Maier-Hein, K., et al. (2020). The future of
digital health with federated learning. NPJ digital
medicine, 3(1):1–7.
Schafer, J. B., Frankowski, D., Herlocker, J., and Sen, S.
(2007). Collaborative filtering recommender systems.
In The adaptive web, pages 291–324. Springer.
Tan, B., Liu, B., Zheng, V., and Yang, Q. (2020). A fed-
erated recommender system for online services. In
Fourteenth ACM Conference on Recommender Sys-
tems, pages 579–581.
Tran, T. N. T., Felfernig, A., Trattner, C., and Holzinger,
A. (2021). Recommender systems in the healthcare
domain: state-of-the-art and research issues. Journal
of Intelligent Information Systems, 57(1):171–201.
Xu, J., Glicksberg, B. S., Su, C., Walker, P., Bian, J., and
Wang, F. (2021). Federated learning for healthcare
informatics. Journal of Healthcare Informatics Re-
search, 5(1):1–19.
Zhao, Y., Li, M., Lai, L., Suda, N., Civin, D., and Chandra,
V. (2018). Federated learning with non-iid data. arXiv
preprint arXiv:1806.00582.
HEALTHINF 2023 - 16th International Conference on Health Informatics
444
