
An Ontology-Based Augmented Observation for Decision-Making in
Partially Observable Environments
Saeedeh Ghanadbashi
1 a
, Akram Zarchini
2 b
and Fatemeh Golpayegani
1 c
1
School of Computer Science, University College Dublin, Ireland
2
Department of Computer Engineering, Sharif University of Technology, Islamic Republic of Iran
Keywords:
Multi-Agent Systems (MAS), Partially Observable Environment, Autonomy, Reinforcement Learning (RL),
Ontology, Job Shop Scheduling Environment.
Abstract:
Decision-making is challenging for agents operating in partially observable environments. In such environ-
ments, agents’ observation is often based on incomplete, ambiguous, and noisy sensed data, which may lead
to perceptual aliasing. This means there might be distinctive states of the environment that appear the same to
the agents, and agents fail to take suitable actions. Currently, machine learning, collaboration, and practical
reasoning techniques are used to improve agents’ observation and their performance in such environments.
However, their long exploration and negotiation periods make them incapable of reacting in real time and
making decisions on the fly. The Ontology-based Observation Augmentation Method (OOAM) proposed
here, improves agents’ action selection in partially observable environments using domain ontology. OOAM
generates an ontology-based schema (i.e., mapping low-level sensor data to high-level concepts), and infers
implicit observation data from explicit ones. OOAM is evaluated in a job shop scheduling environment, where
the required sensed data to process the orders can be delayed or corrupted. The results show that the average
utilization rate and the total processed orders have increased by 17% and 25% respectively compared to Trust
Region Policy Optimization (TRPO) as a state-of-the-art method.
1 INTRODUCTION
Multi-agent Systems (MAS) are comprised of agents
interacting in an environment, coordinating their be-
havior, and making decisions autonomously to solve
complex problems (Stankovic et al., 2009). The
complexity of an agent’s decision-making process
is affected by the properties of its environment
(Wooldridge, 2009). In many real-world problems,
noisy and inaccurate sensed data or missing data
cause partial observability leading to incomplete and
noisy state observation. In such environments, an
agent’s observed state differs from the environment’s
state, and the agent must construct its state repre-
sentation. Reinforcement Learning (RL) is a com-
mon technique used in such environments and is a
trial-and-error learning technique that enables agents
to find suitable actions to maximize the total cumu-
lative reward. Learning is difficult in partially ob-
a
https://orcid.org/0000-0003-0983-301X
b
https://orcid.org/0000-0003-4738-7604
c
https://orcid.org/0000-0002-3712-6550
servable environments, where the same observation
may be obtained from two different states, and the
agent most often requires two different actions in each
state. To tackle this challenge, various modified RL
algorithms are proposed (Le et al., 2018; Parisotto
and Salakhutdinov, 2018; Igl et al., 2018), however,
they are not suitable when on the fly decision-making
is desirable. Practical reasoning is also used to en-
able agents to infer knowledge from their environ-
ment and interaction with other agents (Golpayegani
et al., 2019). However, the uncertainty caused by par-
tially observable environments makes reasoning more
complex and leads to inconsistencies in many tradi-
tional reasoning systems.
In 1977, Feigenbaum pointed out that artificial in-
telligence systems’ power lies in their ability to en-
code and exploit domain-specific knowledge, leading
to the paradigm that “in the knowledge lies the power”
(Feigenbaum, 1977). Domain-specific knowledge is
often encoded in ontologies. Ontology describes con-
cepts, properties, relationships, and rules (Zouaq and
Nkambou, 2010). Ontology rules are in the form of an
implication between an antecedent and a consequent.
Ghanadbashi, S., Zarchini, A. and Golpayegani, F.
An Ontology-Based Augmented Observation for Decision-Making in Partially Observable Environments.
DOI: 10.5220/0011793200003393
In Proceedings of the 15th International Conference on Agents and Artificial Intelligence (ICAART 2023) - Volume 2, pages 343-354
ISBN: 978-989-758-623-1; ISSN: 2184-433X
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
343

An inference engine can generate new relationships
based on existing rules. There is some evidence in
the literature that ontological knowledge can improve
the accuracy of Machine Learning (ML) algorithms
(Caruana et al., 2013; Motta et al., 2016), however,
the concerns related to partial observability are not
addressed.
In this paper, we focus on partially observ-
able environments in which agents cannot ac-
cess full observation, which may affect their
decision-making. We present an Ontology-based
Observation Augmentation Method (OOAM) that im-
proves agents’ action selection in a partially observ-
able environment. To do so, agents map their ob-
servations to an ontology-based schema by specify-
ing concepts, relationships, and properties. Then they
use an inference engine to extract implicit observation
data to be used alongside their learning algorithm. A
Job Shop Scheduling (JSS) environment with a high
level of partial observability is chosen as a case study
for this paper. Our method performance is compared
to Trust Region Policy Optimization (TRPO) learning
algorithm. The results show that OOAM can improve
the agent’s observation and outperforms the baseline
method.
The paper is organized as follows. A running ex-
ample is described in Section 2. A review of relevant
literature is presented in Section 3. Section 4 briefly
presents the required background knowledge. Section
5 describes our method and how it works. Section 6
defines the case study and analyses the results. Fi-
nally, our conclusion and future works are discussed
in Section 7.
2 RUNNING EXAMPLE: JOB
SHOP SCHEDULING
JSS is a problem where multiple jobs/orders are pro-
cessed on several machines and several operational
steps must be included in each job, each of which
must be completed in a specific order. For instance,
the job may involve manufacturing consumer prod-
ucts like automobiles. Figure 1 illustrates this envi-
ronment. The job shop scheduler agent is responsible
for scheduling jobs so that all of them can be com-
pleted in the shortest amount of time.
As orders are generated by sources, they are
placed in the queue. A job shop scheduler agent then
selects which order to send from the queue to which
machine for the next operation step. The processed
orders will then be sent to the sinks for consumption.
JSS is a suitable case study for this paper as it requires
the learning agents to operate in partially observable
environments.
3 RELATED WORK
RL techniques used in partially observable environ-
ments estimate unobservable state variables. In (Le
et al., 2018), the authors proposed a hierarchical deep
RL approach for learning, where the learning agents
need an internal state to memorize important events
in partially observable environments. In (Oh et al.,
2016; Parisotto and Salakhutdinov, 2018), the authors
built a memory system to learn to store arbitrary in-
formation about the environment over numerous steps
to generalize such information for the new environ-
ments. Recurrent Neural Networks (RNNs) can com-
pensate for missing information by developing their
internal dynamics and memory (Duell et al., 2012;
Hausknecht and Stone, 2015; Mnih et al., 2016).
Therefore, in many of the current works, the RL
agents require some form of memory to learn optimal
behaviors over numerous steps. Furthermore, model-
based techniques are used where the agent requires
learning a suitable model of the environment first.
In all of these current learning techniques, tack-
ling partial observability is the main challenge when
on the fly decision-making is required (Dulac-Arnold
et al., 2021). To improve RL’s performance, agents
require mechanisms to augment their observation on
the fly. In a JSS environment, for example, we may
not have observations for all machines/orders because
they are delayed, corrupted, or even missing (Wasch-
neck et al., 2016). Partial observability is the essen-
tial characteristic of the JSS environment which can
hugely impact the scheduling decision-making pro-
cess (Buchmeister et al., 2017; Pfitzer et al., 2018).
In the JSS environment, these partial observabilities
may appear as dynamic/stochastic events such as ma-
chine failure, longer-than-expected processing times,
and urgent orders.
The term ontology refers to the semantics of data
that are machine-understandable and contributed by
users (Fong et al., 2019). In ML, domain-specific
knowledge encoded with ontology can be used to con-
strain search and find optimal or near-optimal solu-
tions faster or find a solution that is generalized better
(Kulmanov et al., 2021). As part of ML tasks, on-
tologies are used in several ways, including enrich-
ment of features derived from the ontology, calculat-
ing similarities or distances between instances based
on the ontology’s structure and knowledge, and deter-
mining probabilistic dependencies between instances
and features based on the entities’ dependencies in
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
344

Figure 1: Job shop scheduling environment. Dot lines indicate possible operations.
the ontology (Bloehdorn and Hotho, 2009). (Motta
et al., 2016) proposed a summarization method that
reinforces learning functions by using semantic re-
lationships between ontology concepts. The authors
of (Youn and McLeod, 2007) created an ontology
base on classification results and queried this ontol-
ogy instead of querying the decision tree. To im-
prove the accuracy of an SVM algorithm, (Caruana
et al., 2013) used ontology augmentation as a feed-
back loop. As described in (Ghanadbashi and Gol-
payegani, 2022), an automatic goal-generation model
is described to address the emergent requirements in
unknown situations, and ontology, inference rules,
and backward reasoning are used to define a new goal.
In (Ghanadbashi and Golpayegani, 2021), using an
environment ontology, an Ontology-based Intelligent
Traffic Signal Control (OITSC) model is proposed,
which enhances the RL traffic controllers’ observa-
tion and improves their action selection when traffic
flow is stochastic and dynamic. Even though the use
of ontology in these works has shown promising re-
sults, they use in very controlled environments and
simplifying assumptions. This paper aims to evaluate
the proposed augmentation method in a more com-
plex scenario (i.e., multiple noisy parameters must be
considered by the agent) in a JSS environment.
4 BACKGROUND
The required background for the proposed method is
discussed as follows.
4.1 Partially Observable Markov
Decision Process (POMDP)
Partially observable problems are typically formu-
lated as a Partially Observable Markov Decision Pro-
cess (POMDP). A POMDP provides a discrete-time
stochastic control process that describes an environ-
ment mathematically. In the standard formulation of
POMDP (Ω,S,A,r, p, W , γ), at time step t ≥ 0, an
agent is in state s
t
∈ S , takes an action a
t
∈ A, receives
an instant reward r
t
= r (s
t
,a
t
) ∈ R and transitions to
a next state s
t+1
∼ p (· | s
t
,a
t
) ∈ S . π : S 7→ P(A) de-
notes a policy in which P(A) represents distributions
over the action space A. The discounted cumulative
reward under policy π is R(π) = E
π
[
∑
∞
t=0
γ
t
r
t
], where
γ ∈ [0,1) is a discount factor. Ω is the possibly infi-
nite set of observations, and W : S → Ω is the func-
tion that generates observations o based on the unob-
servable state s of the process through a set of con-
ditional observation probabilities. At each time, the
agent receives an observation o ∈ Ω which depends
on the new state of the environment, s
′
, and on the
just taken action, a, with probability W (o,a, s
′
) (Sut-
ton and Barto, 2018). The objective of RL is to search
for a policy π that achieves the maximum cumulative
reward π
∗
= argmax
π
R(π). For convenience, under
policy π we define action value function Q
π
(s,a) =
E
π
[R(π) | s
0
= s, a
0
= a] and value function V
π
(s) =
E
π
[R(π) | s
0
= s, a
0
∼ π (· | s
0
)]. We also define
the advantage function A
π
(s,a) = Q
π
(s,a) − V
π
(s)
(Schulman et al., 2015).
4.2 Trust Region Policy Optimization
Approximating π
∗
can be accomplished using a
direct policy search within a given policy class
An Ontology-Based Augmented Observation for Decision-Making in Partially Observable Environments
345

π
θ
,θ ∈ Θ, where Θ represents the policy’s param-
eter space. We can update the parameter θ with
policy gradient ascent, by computing ∇
θ
R(π
θ
) =
E
π
θ
[
∑
∞
t=0
A
π
θ
(s
t
,a
t
)∇
θ
logπ
θ
(a
t
| s
t
)], then updating
θ
new
← θ+α∇
θ
R(π
θ
) with some learning rate α > 0.
Alternatively, we could consider first a trust region
optimization problem (Schulman et al., 2015):
max
θ
new
E
π
θ
π
θ
new
(a
t
| s
t
)
π
θ
(a
t
| s
t
)
A
π
θ
s
t
,a
t
∥
θ
new
− θ
∥
2
≤ ε
(1)
for some ε > 0. If we do a linear ap-
proximation of the objective in Equation 1,
E
π
θ
h
π
θ
new
(a
t
|s
t
)
π
θ
(a
t
|s
t
)
A
π
θ
(s
t
,a
t
)
i
≈ ∇
θ
R(π
θ
)
T
(θ
new
− θ),
we recover the policy gradient update by properly
choosing ε given α.
Trust Region Policy Optimization (TRPO) uses
information theoretic constraints rather than Eu-
clidean constraints (as in Equation 1) between θ
new
and θ to better capture the geometry on the parameter
space induced by the underlying distributions (Schul-
man et al., 2015). In particular, consider the following
trust region formulation:
max
θ
new
E
π
θ
π
θ
new
(a
t
| s
t
)
π
θ
(a
t
| s
t
)
A
π
θ
s
t
,a
t
E
s
[KL [π
θ
(· | s)||π
θ
new
(· | s)]] ≤ ε,
(2)
where E
s
[·] is the state visitation distribution in-
duced by π
θ
. By enforcing the trust region with the
KL divergence, the update according to Equation 2
optimizes a lower bound of R (π
θ
) during training to
avoid taking large steps that irreversibly degrade pol-
icy performance as with vanilla policy gradients (see
Equation 1).
4.3 Ontology
Ontology is used when a semantic description is
needed (for example, when interpreting an unfore-
seen event is required) (Zouaq and Nkambou, 2010).
An ontology describes concepts C, properties F, re-
lationships E, and logical rules J. Relationships ex-
press which concepts are associated with which con-
cepts/values by which properties (E ⊆ C × F × C).
The domain and range of a relationship determine
what kind of instances it can be used for (i.e., do-
main) and what kind of values it can have (i.e.,
range) (Horrocks et al., 2004). To develop an on-
tology, the ontology development 101 strategy (Noy
et al., 2001) and the ontology editing environment
Prot
´
eg
´
e (Musen, 2015) can be used. In addition, the
SABiO guidelines for ontology Verification and Vali-
dation (V&V) are used for the evaluation of ontolo-
gies (i.e., for identifying missing or irrelevant con-
cepts) (de Almeida Falbo, 2014).
The inference engine is the part of an intelligent
system that infers new information based on known
facts, using logical rules. Ontology engineers manu-
ally assert the logical rules using Semantic Web Rule
Language (SWRL) for the inference engine to com-
pare them with facts in the knowledge base. When
the IF (condition) part of the rule matches a fact, the
rule is fired and its THEN (action) part is executed.
The Modus Ponens rule is one of the most impor-
tant rules of inference, and it states that if “A” and “A
→ B” is true, then we can infer that “B” will be true.
If “A” implies “B”, then “A” is called the antecedent,
and “B” is called the consequent. An inference engine
can search for an answer using two basic approaches.
These are:
Forward Chaining: Infer from logical rules in
the knowledge base in the forward direction by ap-
plying Modus Ponens rule to extract more data until a
goal is reached.
Example:
“A” Machine capacity is full.
“A → B” If the machine capacity is full, then it is
in a working status.
=⇒
“B” Machine is in a working status.
Backward Chaining: Starts with a list of goals
and works backward from the consequent to the an-
tecedent to see if any known facts support any of these
consequences.
Example:
“A → B” If the machine is broken, then it is in a
failure status.
“C → A” If the machine has metal fatigue, then it
is broken.
“C” Machine has metal fatigue.
=⇒
“B” Machine is in a failure status.
Figure 2 shows the ontology we created for mod-
eling the concepts in a JSS environment. The JSS on-
tology describes semantics such as “an order has a
processing time, which can be actual or current” as
machine-understandable concepts. In ontology, there
are six high-level concepts (i.e., superclass), includ-
ing Source, Order, WorkArea, Group, Machine, and
Sink, each related to a separate entity defined in the
environment. A superclass can have subclasses rep-
resenting more specific concepts than the superclass.
An important type of relation is the partOf relation.
This defines which subclasses are part of which su-
perclass. For example, Generate, Consume, and Pro-
cess are partOf OperationStep, which in turn is partOf
Order.
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
346

Figure 2: Ontology for job shop scheduling environment.
5 ONTOLOGY-BASED
OBSERVATION
AUGMENTATION METHOD
In an environment where data is partially observ-
able, the RL agents’ observations will be imperfect
and noisy, and this causes uncertainty in their action
selection (i.e., decision-making) process. We pro-
pose an Ontology-based Observation Augmentation
Method (OOAM) to complement agents’ learning by
improving the agent’s decision-making process on the
fly when a partially observable state s
t
g
i
is observed.
OOAM comprises two stages: in the first stage, the
agent g
i
uses the domain ontology to generate an
ontology-based schema of its observation data, and
in the second stage, the agent uses inference engine to
augment its partial observation with explicit data.
The following subsections describe how we have
modeled the JSS agent and the two stages of OOAM.
5.1 JSS Agent
The job shop scheduler is modeled as an RL agent
that receives reward and state observation from the
environment and takes action accordingly. This RL
agent uses TRPO as a learning algorithm and its state,
action, and reward are modeled as follows:
State: We model information of each state s
t
for
the job shop scheduler at time step t as Equation 3.
The details of the parameters are listed in Table 1.
An Ontology-Based Augmented Observation for Decision-Making in Partially Observable Environments
347
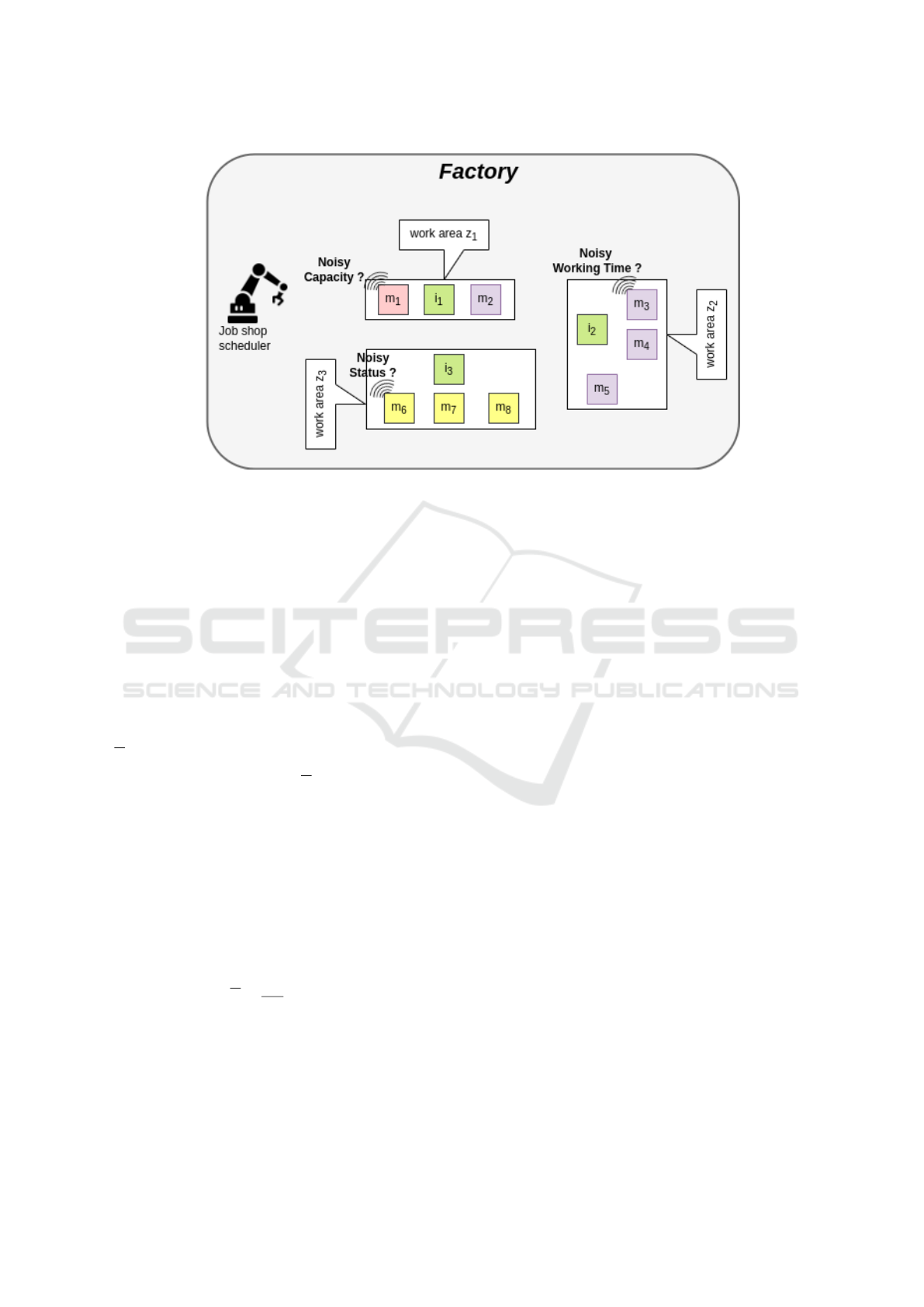
Figure 3: Job shop scheduling environment. The machines of the group n
1
are marked with purple color, group n
2
with pink
color, and group n
3
with yellow color. There is noise in the machines’ capacity, status, and working time data.
s
t
= {M
t
,D
t
,w
t
d
i
, f
t
d
i
,c
t
d
i
,u
t
m
i
,l
t
m
i
,y
t
m
i
,h
t
m
i
,k
t
m
i
,B
t
m
i
,
bi
t
m
i
,bo
t
m
i
,bp
t
m
i
}
(3)
In the JSS environment, some machines’ capacity,
status, and working time observations are noisy, so
the agent’s observations are partial (see Figure 3).
Action: The action is defined as choosing one of
the machines for processing an order.
A = {1, .. ., |M|} (4)
Reward: The reward function is defined as maxi-
mizing the average utilization rate of all the machines
E as shown in Equation 5:
R = max(E) (5)
Since a failed machine cannot be assigned an or-
der until it is repaired, the percentage utilization of
an individual machine E
m
i
is calculated based on its
working time as follows (t
′
shows the time of the last
utilization rate calculation):
E
m
i
= u
t
m
i
/(t − t
′
− l
t
m
i
) (6)
Then the average utilization rate is computed as
follows:
E =
1
|M|
|M|
∑
i=1
E
m
i
(7)
5.2 Observation Modeling
In this paper, ontology is used to enable agents to
represent and interpret their observations. To rep-
resent an observation, they map low-level sensor data
streams to high-level concepts. Sensors often produce
raw data and unstructured streams and they measure
phenomena values such as waiting time of an order.
Semantic Sensor Network (SSN) ontology is used to
describe sensor resources and the data they collect
as observations. It has been created as a standard
model for sensor networks to describe sensor systems
(Haller et al., 2019). We use the data model proposed
in (Duy et al., 2017) to use SSN ontology with cross-
domain knowledge for annotation and present sen-
sors and sensor data (see Figure 4). We can see the
ssn:observation class that describes sensor data ob-
served by an agent. The ssn:property indicates the
property (e.g., waiting time) of the feature of interest
(e.g., order) that is described by a JSS ontology.
In this paper, the RL agent uses the same approach
to annotate raw environment data streams by seman-
tic description and defined by combined ontology.
The environment data stream is indicated by concepts
(e.g., machine, order) and their properties (e.g., wait-
ing time, working time). We call this an ontology-
based schema. For example, in the ontology-based
schema for the JSS environment, “Machine” (i.e., do-
main) “hasStatus” (i.e., relationship) and can be a
“Failure” one (i.e., range). These relationships en-
able concept inheritance and automated reasoning.
We define L
t
g
i
= {C
t
g
i
,F
t
g
i
,E
t
g
i
,J} as the schema de-
scribing the data observed by agent g
i
at time step t.
C
t
g
i
indicates the concepts, F
t
g
i
indicates the proper-
ties, and E
t
g
i
shows the relationships between them.
J shows logical rules defined by ontology engineers
in the domain-specific ontology. When a semantic
description is needed, the agent uses an ontology-
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
348

Figure 4: Concept of the data model (Duy et al., 2017).
based schema, which consists of surrounding con-
cepts and the relationships among concepts as ob-
served by agents. From the data with rich seman-
tic description, the agent can interpret and reason
for implicit observation data by inference engine ap-
proaches.
5.3 Observation Augmentation
In this stage, agents infer implicit information from
sensed data (i.e., known facts) using forward chain-
ing over ontology’s logical rules (see Section 4.3).
By applying forward chaining, to the logical rules
J
1
: c
x
→c
y
and J
2
: c
y
→Y and by assuming that con-
cepts c
x
and c
y
are explicitly observed by the agent
then it can deduce new logical rule J : c
x
→Y that state
implicit observation data for concept c
x
will be Y (see
Algorithm 1)
1
.
In the JSS environment, we have defined several
logical rules which will be used by the JSS agent. Ta-
bles 2, 3, and 4 are three examples of the observation
augmentation stage that can be applied in the JSS en-
1
The code of the OOAM-TRPO algorithm is publicly
available: https://github.com/akram0618/ontology-based-
observation-augmentation-RL
Algorithm 1: Observation Augmentation (s
t
g
i
,L
t
g
i
).
1: for c
x
in C
t
g
i
do
2: if c
x
has noisy value then
3: for c
y
in C
t
g
i
do
4: Extract rules J
1
,J
2
,. .. ,J
n
related to c
x
and c
y
5: if New rule J : c
x
→Y is inferable then
6: Assign value Y to c
x
7: end if
8: end for
9: end if
10: end for
vironment to deduce partial observable data.
Table 2 describes the inference rules that can infer
the implicit observation related to the capacity of ma-
chine a. Suppose that the sum of orders in the input
buffer x, the output buffer y, and the processing buffer
z of the machine is less than the machine’s capacity c.
In that case, the machine’s remaining capacity is free.
Table 3 describes the inference rules that can infer
the implicit observation related to the status of ma-
chine a. The machine is currently failing if the last
time it failed m was greater than the last time it started
a process n.
An Ontology-Based Augmented Observation for Decision-Making in Partially Observable Environments
349

Table 1: Details of state representation.
Parameter Information
M
t
List of machines at time step t.
D
t
List of orders at time step t.
w
t
d
i
The waiting time of order d
i
shows the length of time the order has waited to be completely
processed by a machine at time step t.
f
t
d
i
The actual processing time of order d
i
shows the predetermined processing time of the order in
the machine.
c
t
d
i
The current processing time of order d
i
shows the length of time since the order arrived in the
machine’s processing buffer until now.
u
t
m
i
The working time of machine m
i
shows the total processing time of the machine at time step t.
l
t
m
i
The failure time of machine m
i
is calculated by taking the total time the machine failed at time
step t.
y
t
m
i
The last broken start time of machine m
i
indicates the last time the machine is failed.
h
t
m
i
The last process start time of machine m
i
indicates the last time a process is started in the
machine.
k
t
m
i
The status of machine m
i
shows the machine’s status, including failure, working, or idle at time
step t.
bi
t
m
i
The buffer in of machine m
i
indicates the number of orders in the input buffer of the machine.
bo
t
m
i
The buffer out of machine m
i
indicates the number of orders in the output buffer of the machine.
bp
t
m
i
The processing buffer of machine m
i
specifies whether any orders are being processed in the
machine.
B
t
m
i
The capacity of machine m
i
specifies the total number of orders in the machine.
Table 2: JSS inference rules related to the capacity of the
machine a.
Inference rules
JobShopScheduler(?i)
2
, Machine(?a),
hasInputBuffer(?a, ?x), hasOutputBuffer(?a,
?y), hasProcessingBuffer(?a, ?z),
hasNumber(?x, ?n
1
), hasNumber(?y, ?n
2
),
hasNumber(?z, ?n
3
), hasInitialCapacity(?a, ?c),
hasSum(?n
1
, ?n
2
, ?n
3
, ?N), isLess(?N, ?c) − >
hasRemainingCapacity(?a, Free)
Table 3: JSS inference rules related to the status of the ma-
chine a.
Inference rules
JobShopScheduler(?i), Machine(?a),
hasLastBrokenStart(?a, ?m),
hasLastProcessStart(?a, ?n), isGreater(?m, ?n)
− > hasStatus(?a, Failure)
Table 4 describes the inference rules that can infer the
implicit observation related to the working time of the
2
In Semantic Web Rule Language (SWRL), variables
are indicated using the standard convention of prefixing
them with a question mark.
machine a. Based on the actual processing time of
orders in the machine’s input p
2
and output buffers
p
3
, as well as the order processing time at the moment
p
1
, we can estimate the machine’s working time.
Table 4: JSS inference rules related to working time of the
machine a.
Inference rules
JobShopScheduler(?i), Machine(?a),
hasInputBuffer(?a, ?x), hasOutputBuffer(?a,
?y), Order(?d
1
, ?d
2
, ?d
3
), inProcess(?d
1
, ?a),
inInputBuffer(?d
2
, ?x), inOutputBuffer(?d
3
, ?y),
hasCurrentProcessingTime(?d
1
, ?p
1
),
hasActualProcessingTime(?d
2
, ?p
2
),
hasActualProcessingTime(?d
3
, ?p
3
),
hasSum(?p
1
, ?p
2
, ?p
3
, ?P) − >
hasWorkingTime(?a, ?P)
6 EVALUATION
We evaluate OOAM in a JSS environment. We
have simulated a JSS environment consisting of three
sources, i
1
, i
2
, and i
3
to generate orders and eight ma-
chines, {m
1
,m
2
,. .. ,m
8
} processing orders based on
the specified sequence of operations. Each machine
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
350

Table 5: Job shop scheduling environment setting.
Description
Order load
Light Three orders are generated at each time step.
Heavy Six orders are generated at each time step.
Noise level
Low Noisy capacity data: In 0.5% of cases where a machine’s capacity is full, it is ob-
served as free.
Noisy working time data: In two of eight randomly selected machines, the working
time is randomly noised with a number between zero and four.
High Noisy capacity data: In 1% of cases where a machine’s capacity is full, it is observed
as free.
Noisy status data: The status of four of eight randomly selected machines has noise,
i.e., if the machine is a failure, it will be observed as no failure.
Table 6: The percentage change in performance metrics - The TRPO algorithm and the OOAM-TRPO algorithm - Noisy
status data.
Scenario
Performance Criteria
Utilization Rate Processed Orders
High-Light 10% 17%
High-Heavy 6% 12%
AVG 8% 15%
Table 7: The percentage change in performance metrics - The TRPO algorithm and the OOAM-TRPO algorithm - Noisy
capacity data.
Scenario
Performance Criteria
Utilization Rate Processed Orders
Low-Light 8% 11%
Low-Heavy 19% 21%
High-Light 12% 17%
High-Heavy 36% 40%
AVG 19% 22%
has one processing capacity, so only one order can be
processed at a time. The capacity of sources (i.e., the
number of orders generated at each time step) is set
according to the scenarios defined in the following.
Machines are categorized into three groups, n
1
, n
2
,
and n
3
, placed at three work areas, z
1
, z
2
, and z
3
.
Scenarios: To evaluate the OOAM model, four
scenarios (See Table 5) are defined to cover different
order loads (i.e., number of orders per time step) and
noise levels.
Baseline: TRPO algorithm (Kuhnle, 2020;
Kuhnle et al., 2019) is selected as the baseline al-
gorithm. Simulated episodes are set to 1000, and
each episode has 100 simulation steps. The baseline
algorithm performance is compared to our proposed
model OOAM.
Performance Metrics: The following metrics are
used to evaluate the performance of the proposed
model:
• Average utilization rate of machines E (see Equa-
tion 7).
• Total processed orders |D
p
|: The number of or-
ders successfully processed.
6.1 Results and Discussion
The average utilization rate and total processed orders
in 10 runs in each scenario are reported in Figure 5
for the TRPO algorithm and the OOAM-TRPO algo-
rithm. The results show that the OOAM-TRPO algo-
rithm increases the average utilization rate and total
processed orders compared to the TRPO algorithm.
We observe that the average utilization rate increased
by 19%, 8%, and 24%, and the total processed or-
ders increased by 22%, 15%, and 38% in augment-
ing partial observable data of machines’ capacity, sta-
tus, and working time, respectively (see Tables 7, 6,
and 8). Thus, when the job shop scheduler agent aug-
ments noisy machines’ working time and capacity, the
percentage change is more significant than augment-
ing noisy machines’ status. This is because, for the
agent, capacity and working time are more important
parameters when choosing an appropriate machine to
process orders. Also, the average utilization rate and
An Ontology-Based Augmented Observation for Decision-Making in Partially Observable Environments
351
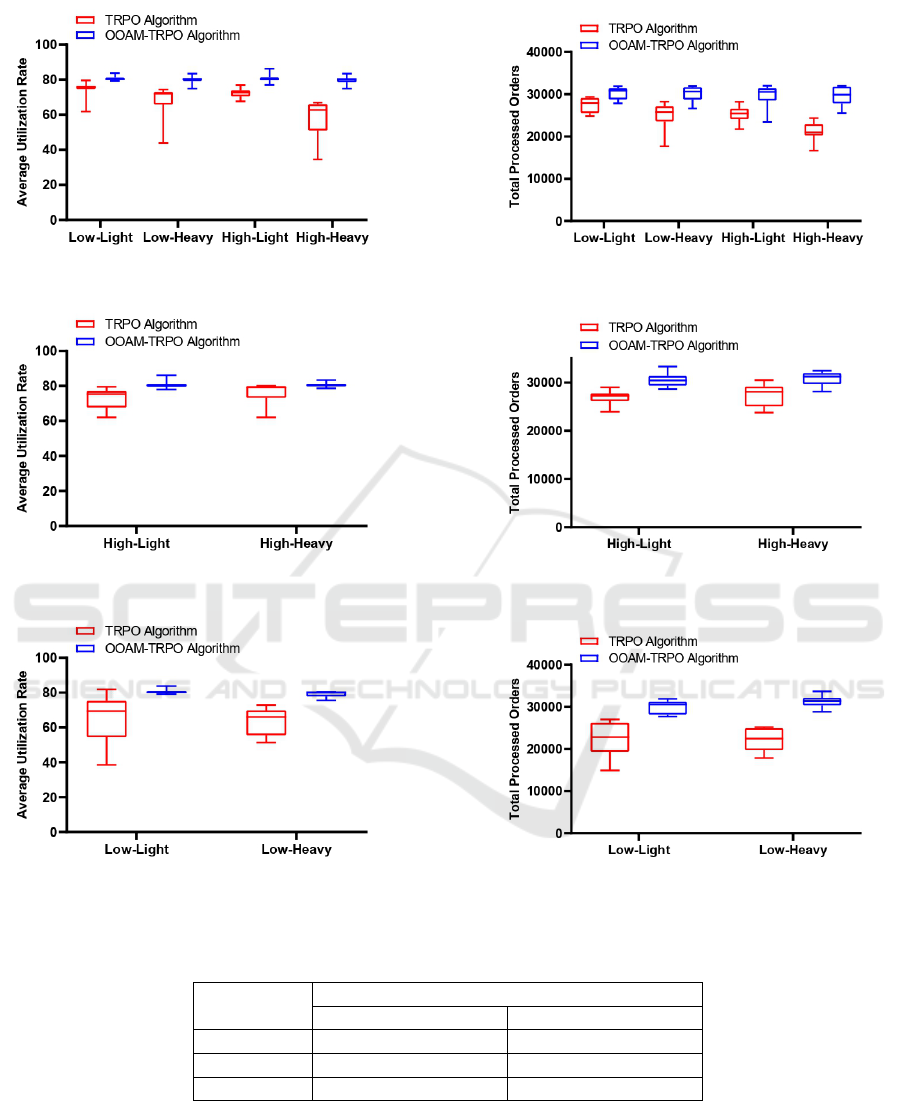
(a) Average utilization rate - Noisy capacity data. (b) Total processed orders - Noisy capacity data.
(c) Average utilization rate - Noisy status data. (d) Total processed orders - Noisy status data.
(e) Average utilization rate - Noisy working time data. (f) Total processed orders - Noisy working time data.
Figure 5: The TRPO algorithm and the OOAM-TRPO algorithm.
Table 8: The percentage change in performance metrics - The TRPO algorithm and the OOAM-TRPO algorithm - Noisy
working time data.
Scenario
Performance Criteria
Utilization Rate Processed Orders
Low-Light 23% 35%
Low-Heavy 24% 41%
AVG 24% 38%
total processed orders improve better in Heavy sce-
narios than in Light scenarios. The reason for this is
that the number of orders generated has increased, re-
sulting in increased times the agent has to choose ma-
chines to process orders and an increase in the impact
of improving the machines’ noisy data on the agent’s
performance. With noisy capacity data, where there
is both low and high noise, we see that the improve-
ment for High scenarios is more significant than for
Low scenarios. Since the amount of noise is more re-
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
352

markable, an improvement in noise will significantly
impact the agent’s decision-making.
7 CONCLUSION AND FUTURE
WORK
Many real-world problems are set in partially ob-
servable environments. Learning decision-making
policies in such environments is challenging because
the observation is incomplete, ambiguous, and noisy
from the perspective of learning agents and hence
negatively impacts agents’ action selection. In this pa-
per, the proposed Ontology-based Observation Aug-
mentation Method (OOAM) enables agents to aug-
ment their observation through ontologies, improving
their action selection in partially observable environ-
ments.
This paper can be extended in several directions.
An ontology’s accuracy and completeness play a sig-
nificant role in OOAM’s performance. Ontologies
need to evolve and frequently update in dynamic en-
vironments. This problem can be addressed using
ontology evolution techniques (Zablith et al., 2015).
In this paper, we have only looked at partially ob-
servable environments and tested the proposed so-
lution in job shop scheduling scenarios. The gen-
eralization of OOAM is not tested so far. How-
ever, this method can be generalized to other appli-
cation domains through modeling and using the rel-
evant ontologies and applying the inference mecha-
nism accordingly. In our future work, OOAM will be
tested in other scenarios and environments (e.g., non-
deterministic environments). Also, this work can be
validated further in a real-world job shop scheduling
environment through experimental work. In multi-
agent environments, agents can exchange their in-
ferred knowledge of environments by an ontology-
based schema. To achieve consistency in distributed
systems, agents must be able to coordinate their dif-
ferent/conflicting understandings of the environment,
which might be based on different distributed on-
tologies. Sensor ontology matching/alignment tech-
niques (Xue et al., 2021) can be used for determining
the correspondences between heterogeneous concepts
that exist in two different ontologies. Also, literature
on combining relationship information from multiple
data sources to infer previously unobserved relation-
ships could be investigated to deal with partial observ-
ability in multi-agent systems (Akdemir et al., 2020).
REFERENCES
Akdemir, D., Knox, R., and Isidro y S
´
anchez, J. (2020).
Combining partially overlapping multi-omics data in
databases using relationship matrices. Frontiers in
Plant Science, 11:947.
Bloehdorn, S. and Hotho, A. (2009). Ontologies for ma-
chine learning. In Handbook on Ontologies, pages
637–661. Springer.
Buchmeister, B., Ojstersek, R., and Palcic, I. (2017). Ad-
vanced methods for job shop scheduling. Advances in
Production and Industrial Engineering, page 31.
Caruana, G., Li, M., and Liu, Y. (2013). An ontology en-
hanced parallel SVM for scalable spam filter training.
Neurocomputing, 108:45–57.
de Almeida Falbo, R. (2014). SABiO: Systematic Ap-
proach for Building Ontologies. In Workshop on On-
tologies in Conceptual Modeling and Information Sys-
tems Engineering co-located with International Con-
ference on Formal Ontology in Information Systems
(ONTO.COM/ODISE@FOIS).
Duell, S., Udluft, S., and Sterzing, V. (2012). Solving
partially observable reinforcement learning problems
with recurrent neural networks. In Neural Networks:
Tricks of the Trade, pages 709–733. Springer.
Dulac-Arnold, G., Levine, N., Mankowitz, D. J., Li, J.,
Paduraru, C., Gowal, S., and Hester, T. (2021). Chal-
lenges of real-world reinforcement learning: Defini-
tions, benchmarks and analysis. Machine Learning,
110(9):2419–2468.
Duy, T. K., Quirchmayr, G., Tjoa, A., and Hanh, H. H.
(2017). A semantic data model for the interpretion
of environmental streaming data. In International
Conference on Information Science and Technology
(ICIST), pages 376–380. IEEE.
Feigenbaum, E. A. (1977). The art of artificial intelligence:
Themes and case studies of knowledge engineering.
In International Joint Conference on Artificial Intelli-
gence (IJCAI), volume 2. Boston.
Fong, A. C. M., Hong, G., and Fong, B. (2019). Augmented
intelligence with ontology of semantic objects. In In-
ternational Conference on Contemporary Computing
and Informatics (IC3I), pages 1–4. IEEE.
Ghanadbashi, S. and Golpayegani, F. (2021). An ontology-
based intelligent traffic signal control model. In In-
ternational Intelligent Transportation Systems Con-
ference (ITSC), pages 2554–2561. IEEE.
Ghanadbashi, S. and Golpayegani, F. (2022). Using ontol-
ogy to guide reinforcement learning agents in unseen
situations. Applied Intelligence (APIN), 52(2):1808–
1824.
Golpayegani, F., Dusparic, I., and Clarke, S. (2019). Using
social dependence to enable neighbourly behaviour in
open multi-agent systems. ACM Transactions on In-
telligent Systems and Technology (TIST), 10(3):1–31.
Haller, A., Janowicz, K., Cox, S. J., Lefranc¸ois, M., Tay-
lor, K., Le Phuoc, D., Lieberman, J., Garc
´
ıa-Castro,
R., Atkinson, R., and Stadler, C. (2019). The modular
SSN ontology: A joint W3C and OGC standard spec-
An Ontology-Based Augmented Observation for Decision-Making in Partially Observable Environments
353

ifying the semantics of sensors, observations, sam-
pling, and actuation. Semantic Web, 10(1):9–32.
Hausknecht, M. and Stone, P. (2015). Deep recurrent q-
learning for partially observable MDPs. In AAAi Fall
Symposium Series.
Horrocks, I., Patel-Schneider, P. F., Boley, H., Tabet, S.,
Grosof, B., Dean, M., et al. (2004). SWRL: A seman-
tic web rule language combining OWL and RuleML.
W3C Member Submission, 21(79):1–31.
Igl, M., Zintgraf, L., Le, T. A., Wood, F., and White-
son, S. (2018). Deep variational reinforcement learn-
ing for POMDPs. In Proceedings of the 35th Inter-
national Conference on Machine Learning (ICML),
pages 2117–2126, Vienna. PMLR.
Kuhnle, A. (2020). Simulation and reinforcement learn-
ing framework for production planning and control of
complex job shop manufacturing systems. Accessed:
2021-06-01.
Kuhnle, A., R
¨
ohrig, N., and Lanza, G. (2019). Autonomous
order dispatching in the semiconductor industry using
reinforcement learning. Procedia CIRP, 79:391–396.
Kulmanov, M., Smaili, F. Z., Gao, X., and Hoehndorf,
R. (2021). Semantic similarity and machine learn-
ing with ontologies. Briefings in Bioinformatics,
22(4):bbaa199.
Le, T. P., Vien, N. A., and Chung, T. (2018). A deep hier-
archical reinforcement learning algorithm in partially
observable markov decision processes. IEEE Access,
6:49089–49102.
Mnih, V., Badia, A. P., Mirza, M., Graves, A., Lillicrap, T.,
Harley, T., Silver, D., and Kavukcuoglu, K. (2016).
Asynchronous methods for deep reinforcement learn-
ing. In International Conference on Machine Learn-
ing, pages 1928–1937. PMLR.
Motta, J. A., Capus, L., and Tourigny, N. (2016). Vence: A
new machine learning method enhanced by ontologi-
cal knowledge to extract summaries. In Proceedings
of the Science and Information Conferences (SAI),
Computing Conference, pages 61–70. IEEE.
Musen, M. A. (2015). The prot
´
eg
´
e project: A look back and
a look forward. AI Matters, 1(4):4–12.
Noy, N. F., McGuinness, D. L., et al. (2001). Ontology
development 101: A guide to creating your first ontol-
ogy. Technical report, Stanford Knowledge Systems
Laboratory.
Oh, J., Chockalingam, V., Lee, H., et al. (2016). Control of
memory, active perception, and action in minecraft.
In International Conference on Machine Learning,
pages 2790–2799. PMLR.
Parisotto, E. and Salakhutdinov, R. (2018). Neural map:
Structured memory for deep reinforcement learning.
In Proceedings of the 6th International Conference on
Learning Representations (ICLR), Vancouver. Open-
Review.net.
Pfitzer, F., Provost, J., Mieth, C., and Liertz, W. (2018).
Event-driven production rescheduling in job shop en-
vironments. In International Conference on Automa-
tion Science and Engineering (CASE), pages 939–
944. IEEE.
Schulman, J., Levine, S., Abbeel, P., Jordan, M., and
Moritz, P. (2015). Trust region policy optimization.
In International Conference on Machine Learning
(ICML), pages 1889–1897. PMLR.
Stankovic, M., Krcadinac, U., Kovanovic, V., and Jo-
vanovic, J. (2009). Intelligent software agents and
multi-agent systems. In Encyclopedia of Information
Science and Technology, Second Edition, pages 2126–
2131. IGI Global.
Sutton, R. S. and Barto, A. G. (2018). Reinforcement learn-
ing: An introduction. MIT Press.
Waschneck, B., Altenm
¨
uller, T., Bauernhansl, T., and Kyek,
A. (2016). Production scheduling in complex job
shops from an industry 4.0 perspective: A review and
challenges in the semiconductor industry. SAMI@
iKNOW, pages 1–12.
Wooldridge, M. (2009). An introduction to multiagent sys-
tems, pages 23–26. John Wiley & Sons.
Xue, X., Wu, X., Jiang, C., Mao, G., and Zhu, H. (2021).
Integrating sensor ontologies with global and local
alignment extractions. Wireless Communications and
Mobile Computing, 2021.
Youn, S. and McLeod, D. (2007). Efficient spam email fil-
tering using adaptive ontology. In Proceedings of the
4th International Conference on Information Technol-
ogy (ITNG), pages 249–254, Las Vegas. IEEE.
Zablith, F., Antoniou, G., d’Aquin, M., Flouris, G., Kondy-
lakis, H., Motta, E., Plexousakis, D., and Sabou,
M. (2015). Ontology evolution: A process-centric
survey. The Knowledge Engineering Review (KER),
30(1):45–75.
Zouaq, A. and Nkambou, R. (2010). A survey of do-
main ontology engineering: Methods and tools. In
Advances in Intelligent Tutoring Systems, pages 103–
119. Springer.
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
354
