
Using Sparse Representation of EEG Signal from a Shallow Sparse
Autoencoder for Epileptic Seizure Prediction
Gul Hameed Khan, Nadeem Ahmad Khan, Wala Saadeh and Muhammad Awais Bin Altaf
Lahore University of Management Sciences (LUMS), Lahore, Pakistan
Keywords:
Autoencoder, Electroencephalogram (EEG), Feature Selection, Seizure Prediction, Signal Sparsity.
Abstract:
Patients with epilepsy are affected with unexpected seizure events, which significantly diminish their quality
of life. It is crucial to evaluate whether an epileptic patient’s brain state is indicative of a possible seizure
occurrence so that necessary therapy or alarm can be generated on time. If seizures could be predicted before
the onset, interventions may be applied to avoid further damage during seizure attack, and patients could
take medications or other treatments to prevent seizures from occurring. This research describes a patient-
specific technique for predicting epileptic seizures based on a hybrid model. Single layer sparse autoencoder
is trained to obtain a aparse representation of the scalp electroencephalogram (EEG) signals. SVM classifier
is used to categorize the sparse signal as inter-ictal or pre-ictal. Individual EEG channel analysis for seizure
prediction are presented. In addition, various hidden sizes of the autoencoder for optimal sparse representation
are anlyzed.The proposed model evaluates 13 patients from the CHB-MIT dataset and obtains a sensitivity of
98% and an area under the curve (AUC) of 98%. We have evaluated the performance of our hybrid strategy
to both deep learning models and conventional procedures. The proposed method outperforms current seizure
prediction techniques, proving its efficacy.
1 INTRODUCTION
Epilepsy is a prevalent neurological disorder classi-
fied as the second most likely neural disease of the
brain, and the number of epileptic patients has in-
creased dramatically in recent years. A spontaneous
epileptic seizure is characterized by the transient and
instantaneous abnormal disruption of brain neurons
(Yang et al., 2021b). Seizures caused by epilepsy
can produce serious disruptions in a patient’s emo-
tions, behavior, movements, and awareness, and can
result in severe damage or even death. The prema-
ture death rate of these patients is two to three times
that of disease-free persons, placing a significant bur-
den on the patients, their families, and the community
(Rasheed et al., 2021).
The hypothesis underlying seizure prediction is
that there exists a transition state (preictal) between
the interictal (normal state) and the ictal (seizure
state) (Truong et al., 2018). This notion is supported
by an abundance of clinical evidence. Consequently,
researchers have devoted a substantial amount of ef-
fort over the past few decades to attempting to antici-
pate epileptic seizures based on intracranial EEG and
scalp EEG signals, with the latter being more practi-
cal for clinical application (Zhang and Li, 2022).
Early prediction of epileptic seizures provides suf-
ficient time before the seizure really occurs; this is
extremely important because the treatment can pre-
vent the attack. The problem of seizure prediction (or
forecasting) is detecting seizure symptoms and deter-
mining if the patient is on the verge of an attack (Ryu
and Joe, 2021). Detecting seizure symptoms is analo-
gous to identifying the inter-ictal and pre-ictal phases,
according to the phase distinction.
Therefore, similar to conventional signal classifi-
cation, numerous methods for seizure prediction have
been proposed in the literature based on feature ex-
traction and classification. For forecasting epileptic
seizures from EEG readings, machine learning ap-
proaches and computational algorithms are applied
with different feature extraction techniques. For ex-
ample, (Usman et al., 2017) used empirical mode de-
composition (EMD) for preprocessing and retrieved
time and frequency domain information for training
a prediction model. A patient-specific technique for
predicting epileptic seizures based on the common
spatial pattern (CSP) feature extraction of scalp EEG
signals is presented in (Alotaiby et al., 2017). Seizure
prediction framework using bag-of-wave (BoWav)
Khan, G., Khan, N., Saadeh, W. and Altaf, M.
Using Sparse Representation of EEG Signal from a Shallow Sparse Autoencoder for Epileptic Seizure Prediction.
DOI: 10.5220/0011813400003414
In Proceedings of the 16th International Joint Conference on Biomedical Engineering Systems and Technologies (BIOSTEC 2023) - Volume 4: BIOSIGNALS, pages 125-132
ISBN: 978-989-758-631-6; ISSN: 2184-4305
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
125

feature extraction and synchronization patterns is pro-
posed by (Cui et al., 2018). However, conventional
features are generally chosen empirically after a brief
period of time, therefore the key characteristics may
be ignored (Cui et al., 2018).
In a relatively new trend, deep learning algo-
rithms are being used in medical image and signal
processing. Interest has been drawn to deep learn-
ing techniques due to their robust feature extraction
capacity. This is possible because of advances in
computing power and the availability of big data.
These algorithms have a lot of potential and can have
a big impact because, in most cases, their perfor-
mance is better than what was possible with tradi-
tional machine learning techniques. Researchers have
mostly been interested in convolutional neural net-
works (CNNs) for seizure prediction (Truong et al.,
2018). This is likely because CNNs have been ex-
tensively used in image processing and are therefore
better known and more established in the research
community. Moreover, Long Short-Term Memory
(LSTM), stacked autoencoders (SAE) and convolu-
tional autoencoders (CAE) are developed for classify-
ing EEG data resulting in high accuracy systems (Ryu
and Joe, 2021), (Tautan et al., 2019). These meth-
ods, however, have a significant energy consumption
as well as a huge number of parameters and hardware
resources (Zhao et al., 2020). Therefore, these tech-
niques cannot be used with small, low-power wear-
able or implantable medical equipment. To continu-
ously update the epileptic patients, the devices should
run in real-time.
There have been significant advancements in the
field of epileptic seizure prediction, with promising
outcomes reported by various methodologies. How-
ever, these existing systems typically utilize mul-
tichannel EEG signals for pre-ictal and inter-ictal
recognition. These methods extract features from
multiple EEG channels or analyse all available chan-
nels collectively in order to categorize multi-channel
epochs of short time intervals as pre-ictal or inter-
ictal for seizure prediction. Existing approaches do
not analyze individual EEG channels for the identifi-
cation of abnormalities or signal variations that lead
to these state shifts. This also holds true for epilep-
tic seizure detection techniques. EEG analysis at the
level of a single channel is important for various rea-
sons: Initially, a neurologist would like to construct
his analysis of multi-channel EEG input bottom up
(from individual signal to group level). The indi-
vidual signal-level evidence builds the multichannel
epoch-level determination. Second, analysis at the
level of individual signals can reveal the potential of
each EEG channel for seizure prediction depending
on the type of seizure. Exploring multi-channel EEG
analysis by combining single channel evaluations is
an effective approach. This technique also presents
the possibility of exploring the use of minimal EEG
channels for seizure prediction (or detection) rather
than using data from the entire scalp. In addition,
the advancement of such a system is advantageous for
the creation and usage of wearable devices and sensor
networks, resulting in greater wearing comfort and a
more compact form factor due to a reduction in pro-
cessing demand.
This paper presents an approach for epileptic
seizure prediction using a hybrid model comprising of
a shallow sparse autoencoder (AE) and support vec-
tor machine (SVM) classifier. We therefore elaborate
these methods as follows:
1.1 Shallow Sparse Autoencoder
The basic components of an AE are: an encoder and a
decoder. To rebuild the original dataset x from the en-
coder’s representation y, the decoder is configured to
minimize the difference between x and ˆx, as shown in
Fig. 1. The encoder’s output y represents the reduced
representation of x, which consists of n samples. To
be more precise, an encoder is a function f (.) that
converts a given input x into some unknown represen-
tation y. The procedure is stated as follows:
A shallow AE with a single hidden layer compris-
ing of n neurons in the input/output layer and m hid-
den neurons is developed with m < n as shown in Fig.
1. Encoder layer is evaluated with sharing weights
W
E
∈ R
n×m
and biases vector b
x
∈ R
m
. The decoder
layer reconstructs the signal with weights W
D
∈ R
m×n
and biases vector b
y
∈ R
n
. These weights and biases
of the model are calculated over signal reconstruction
error instead of classification results. The scaled con-
jugate gradient (SCG) was designated to update these
weights and bias values. Encoding process for input
EEG signal x ∈ R
n
is modeled as:
y = f (W
E
x + b
x
) (1)
Where f (
.
) represents the activation function in
the encoder neurons. Two inputs, a bias vector b and
a matrix W , are used to configure the decoder. In most
cases, the activation function is selected based on
the characteristics of the available data (Meng et al.,
2017). However, in contrast to non-linear functions,
linear activation helps in building a system with low
computational cost. For this reason, both the encod-
ing and decoding procedures will use linear activa-
tions. For the encoder’s activation function, the satu-
BIOSIGNALS 2023 - 16th International Conference on Bio-inspired Systems and Signal Processing
126

rating linear transfer function (Satlin) is described as:
satlin(x) =
−1 x < −1
0 −1 ⩽ x ⩽ 1
1 x > 1
(2)
Finding the values of the training parameters θ =
(W, b
x
, b
y
) that minimize the reconstruction loss for a
given dataset is the goal of AE training.
Θ = min
θ
L(x, ˆx) = min
θ
L(x, f (W
T
x + b)) (3)
The reconstruction loss L in AE’s training phase
is typically derived from the square of the error:
L(θ) =
1
n
n
∑
k=1
(x − ˆx)
2
(4)
Here, both the n and m represents the number of
samples in the signal. The decoder layer reconstructs
the sparse vector y ∈ R
m
to its original form as:
ˆx = W
D
y + b
y
(5)
AE’s objective function reconstructs the input to
its original form. High weights of hidden layers make
the generated features more dependent on the net-
work structure rather than the input data. Therefore,
to avoid this complexity, sparse AE imposes weight-
decay regularization so as to keep neuron weights
small.
Θ = αmin
θ
L(x, ˆx)+ λ||W||
2
(6)
Here, α is the scale parameter to control the
weights of the data reconstruction loss. We used L
2
regularization ||W ||
2
to ensure weight matrix W hav-
ing small elements. Hyper parameter λ is incorpo-
rated to control the regularization strength. Transfer
function to compute decoder layer’s output is linear
function (Purelin) f (x) = x. These functions are ap-
plied to each signal sample using the Mean Square
Error (MSE) loss function, presented in equation 4.
MSE is used in the AE’s training phase to compare the
original and reconstructed signals. Encoding yields
a sparse representation of the signal, while decoding
generates a reconstruction of the signal to its original
form. The decoding is only added in training phase to
ensure the best sparse representation of the data pos-
sible.
Sparsity level of the AE for input signal of length
n and hidden size m is given as:
SparsityLevel =
n
m
(7)
1.2 Gaussian SVM
The Gaussian kernel SVM is frequently employed
due to its excellent performance, and is frequently re-
garded as one of the most effective techniques when
it comes to supervised learning (Yang et al., 2021a).
To ensure that models perform well, it is necessary
to precisely determine hyper-parameters such ker-
nel width and penalty factor. The performance of
the Gaussian kernel SVM is thoroughly examined in
(Yang et al., 2021a) when the hyper-parameters are
set to their most extreme values (0 or ∞). The Leave-
One-Out (LOO) approach’s local density and preci-
sion serve as the cornerstone of the parameter op-
timization strategy, which is suggested to increase
computing efficiency. The kernel width of each sam-
ple is dependent on the local density necessary to en-
sure a higher separability in feature space, and the
LOO approach refines the grid search to identify the
ideal penalty value. The proposed method is evalu-
ated for validity by comparison to the grid method
(Yang et al., 2021a).
The impact of various kernel functions on SVM
characteristics is highly variable (Yang et al., 2021a).
Here, we used the Gaussian kernel presented in equa-
tion 8. An optimized hyperplane in kernel space is
generated by a Gaussian function of kernel scale 4
and kernel offset 0.1. Training instances are separable
for these parameters and yield optimal results. The
feature space that training data is mapped to is deter-
mined by the kernel width. As a result, the success of
an SVM’s training procedure is profoundly affected
by its accuracy.
k(x
i
, x
j
) = exp(−
||x
i
− x
j
||
2
2σ
2
) (8)
Some of the key contributions of the proposed
method are:
• We have used sparse representation generated by
the AE for seizure prediction
• Our framework provides individual EEG channel
analysis for seizure prediction
• Using autoencoder with only one hidden layer
will reduce the computational complexity of the
algorithm
• Multiple Hidden sizes of autoencoder are ana-
lyzed to obtain optimum sparse representation ca-
pable of effectively classifying the data as inter-
ictal or pre-ictal
• Our method outperforms state of the art seizure
prediction techniques
Using Sparse Representation of EEG Signal from a Shallow Sparse Autoencoder for Epileptic Seizure Prediction
127

2 PROPOSED METHODOLOGY
AE based feature extraction method achieved great
success in generating implicit features of high dimen-
sional data (Meng et al., 2017). AE use artificial neu-
ral networks to reduce dimensionality by minimizing
the reconstruction loss. Due to this, AE and its exten-
sions demonstrate a promising ability to extract mean-
ingful features, particularly in signal processing do-
main (Meng et al., 2017).
The fundamental processing architecture em-
ployed in this paper to predict epileptic seizures is
depicted in Figure 1. Firstly, a sparse AE with only
one hidden layer is trained to obtain a sparse signal
directly from the raw EEG data. SVM classifier pro-
cesses these sparse signal samples to categorize the
data as inter-ictal or pre-ictal. Ability of various hid-
den sizes of the AE are analyzed for seizure predic-
tion.
Using the raw EEG data directly without any
transformation or feature extraction and AE with
only one hidden layer will reduce the computational
complexity of the algorithm. Avoiding the compli-
cated process for extracting features, a lot of memory
for storing high-precision parameters, and complex
arithmetic computations will reduce the hardware re-
sources requirement. It is desirable in wearable de-
vices that demand low-power consumption and real-
time operation. Therefore, the proposed methodol-
ogy is computationally efficient, and its classification
performance is comparable to that of existing seizure
prediction techniques.
EEG data is divided into 1-second segments for
each channel. These 1-second segments are fed into
the AE. Different seizure prediction methods in the
literature commonly use EEG data segments ranging
from 1 to 30 seconds in length (Zhang and Li, 2022),
(Khan et al., 2021). The proposed algorithm pro-
cesses one-second EEG segments using a single EEG
channel. The EEG dataset used in this work has pre-
viously been preprocessed for noise and artifact re-
moval. As a result, to minimize the computational
overhead of preprocessing, we use raw EEG data di-
rectly.
AE with single hidden layer processes each 1-sec
EEG trial to produce its sparse representation. In
the training phase, an encoder is used to determine
a sparse representation of the signal, and a decoder is
designated to restore the signal to its original form.
The sparse signal samples are used as input to classi-
fier model to categorize the data as inter-ictal or pre-
ictal. However, the decoder part of the AE is dis-
carded in the testing phase and only the encoder is uti-
lized for seizure prediction. Numerous hidden sizes
of AE are analyzed to obtain an optimum sparse sig-
nal samples capable of classifying the data precisely.
Figure 1: Work flow architecture of the proposed seizure
prediction method.
2.1 Evaluation Data
In order to evaluate the effectiveness of the proposed
seizure prediction system, we experimented with the
Children’s Hospital Boston-collected PhysioNet scalp
EEG database CHB-MIT. There are 163 seizure oc-
currences recorded from 23 pediatric patients with
916 hours of continuous scalp EEG (sEEG) monitor-
ing. Recordings from 22 participants are organized
into 23 cases and sampled at 256 Hz.
We evaluate the common 18 channels for each pa-
tient to ensure model consistency and patient wise
uniformity as in (Ryu and Joe, 2021), (Sun et al.,
2021), (Gao et al., 2022). Because there are numerous
patients in the experiment using different channels,
we used the same 18 channels that all patients had.
Therefore, we utilize 18 channels (“FP1-F7”, “F7-
T7”, “T7-P7”, “P7-O1”, “FP1-F3”, “F3-C3”, “C3-
P3”, “P3-O1”, “FP2-F4”, “F4-C4”, “C4-P4”, “P4-
O2”, “FP2-F8”, “F8-T8”, “T8-P8”, “P8-O2”, “FZ-
CZ”, “CZ-PZ”).
2.2 System Parameters
We experimented the proposed seizure prediction al-
gorithm with various hidden sizes of the AE. For a an
input size of 256, the encoder layer length varies from
64 to 8, corresponding to the sparsity levels 4 to 32 as
demonstrated in equation 7. Reducing the AE’s hid-
den size will decrease the computational cost of the
algorithm. In addition, analyzing the EEG signals to-
wards seizure prediction with different hidden sizes
of the AE will help to select an optimum hidden size
as we do not have a specific formula to build an AE
with the most appropriate hidden size.
BIOSIGNALS 2023 - 16th International Conference on Bio-inspired Systems and Signal Processing
128

Table 1: Subjects information used in this study from the
CHB-MIT database.
Patient
ID
No. of seizure
events
Inter-ictal Duration
(hrs)
1 7 14
2 3 23
3 6 22
5 5 14
9 4 46
10 6 26
13 5 14
14 5 5
18 6 24
19 3 25
20 5 20
21 4 22
23 5 13
Total 64 268.6
The time interval between at least 4 hours (hrs) be-
fore the start of a seizure and 4 hrs after it has ended
is known as the inter-ictal phase. CHB-MIT dataset
demonstrates that many seizures can take place near
together. In the seizure prediction task, we are inter-
ested in forecasting a seizure episode that will occur
within roughly 30 minutes of the previous one. As a
result, we treat seizures that happen within 30 min-
utes of one another as a single seizure, with the first
seizure’s onset serving as the start of the combined
seizure. Additionally, we only take into account pa-
tients with less than 10 seizures per day for the predic-
tion task because it is not necessary to predict seizures
occurrence for patients experiencing seizures on av-
erage every 2 hours. These parameters indicate that
13 participants have sufficient data (at least three pri-
mary seizures and three hrs of interictal recording).
The subject ID, total number of seizure occurrences,
and length of the inter-ictal period for each subject are
included in the Table 1 thorough description of each
subjects’ information.
The Seizure Prediction Horizon (SPH) is the time
between the alert triggered in anticipation of the
seizure occurrence and the actual ictal state onset.
For an accurate forecast, a seizure must occur after
the SPH and before the Seizure Occurrence Period
(SOP), which is the estimated time span for seizure
occurrence. A false alarm will be generated if the pre-
diction algorithm produces a positive signal (a seizure
is imminent) but there is no seizure during the SOP.
After the alert has been triggered, the ideal therapeutic
application of SPH is giving the patient sufficient time
to take preventative measures. A patient’s SPH must
be lengthy enough to allow for adequate safety mea-
sures once the alarm is activated. To comfort the pa-
Figure 2: Variations in Seizure prediction performance of
the proposed method using different hidden sizes (Sparsity
Levels) of the AE for channel ‘FzCz’ (best case).
tient, however, the SOP should not be overly lengthy.
In this research, we employ the SPH period of 10 min-
utes and the SOP period of 30 minutes.
Inter-ictal EEG recordings are more prevalent than
pre-ictal EEG recordings because the ictal state is un-
common across lengthy hours of EEG recordings. In
machine learning methods, it is commonly assumed
that data from different classes should be distributed
uniformly (Rasheed et al., 2021). A classifier trained
on a greater number of examples for one class in
comparison to other classes will be biased and pre-
fer an uneven decision. To overcome the class imbal-
ance problem, numerous strategies are discussed in
the literature, including overlapping window (Truong
et al., 2018),(Dissanayake et al., 2021), generative ad-
versarial network (GAN) (Rasheed et al., 2021), and
synthetic minority over-sampling technique (SMOTe)
(Usman et al., 2021). We utilize SMOTe to produce
additional pre-ictal data during the training phase,
hence addressing the issue of data imbalance as de-
scribed in (Usman et al., 2021). By supplement-
ing pre-ictal state data with an overlapping window,
SMOTe can alleviate the class imbalance issue.
3 SYSTEM EVALUATION
3.1 Experimental Setup
Using the CHB-MIT database, the AE model for
sparse representation of the input signal is trained us-
ing 10 minutes of pre-ictal EEG data (1-second du-
ration segments) for each seizure. For example, as
indicated in Table 1, Patient 1 has experienced seven
seizures. Therefore, we extract 70 (7 × 10) minutes
of pre-ictal data and the same amount of data for
the inter-ictal phase for this patient. Various model
assessment strategies have been presented in the lit-
Using Sparse Representation of EEG Signal from a Shallow Sparse Autoencoder for Epileptic Seizure Prediction
129
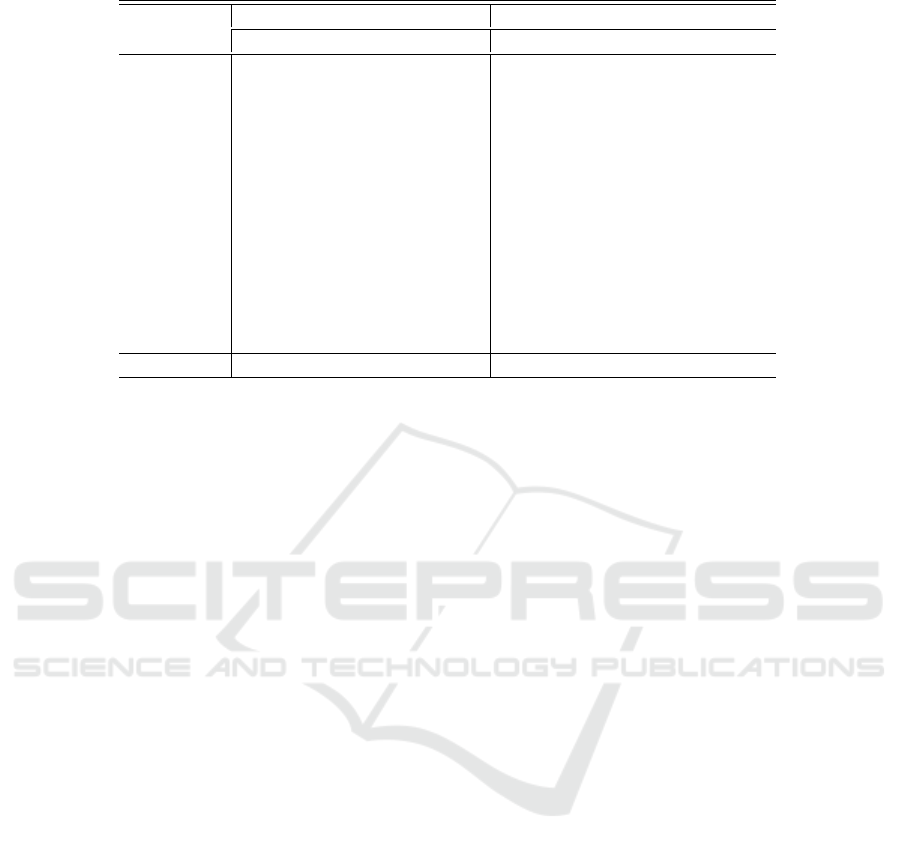
Table 2: Patient wise classification results of the proposed seizure prediction method with AE’s hidden size 64.
Patient ID
Channel ‘FzCz’ (Best Case) Channel ‘FP1F7’ (Worst Case)
Ac Sen Spe AUC Ac Sen Spe AUC
1 99.0 100 97.8 100 92.6 89.2 96.1 97.0
2 93.8 98.7 91.8 98.0 89.7 85.8 93.4 94.0
3 96.3 98.1 93.0 99.0 88.0 97.4 78.4 89.0
5 96.1 98.1 95.0 99.0 83.4 74.7 92.2 92.0
9 97.5 98.3 94.6 99.0 89.2 82.4 95.9 90.0
10 95.0 99.3 91.0 100 91.9 86.0 97.8 94.0
13 95.7 99.4 91.8 98.0 88.0 87.2 88.9 94.0
14 94.1 91.2 98.0 99.0 87.2 78.3 96.9 95.0
18 95.4 99.1 91.3 100 86.8 86.5 87.1 88.0
19 94.1 97.0 91.5 98.0 94.0 97.8 90.3 95.0
20 97.0 99.0 96.1 100 97.1 96.0 98.2 95.0
21 95.8 99.3 92.5 99.0 87.1 85.3 88.8 91.0
23 92.0 91.0 92.0 95.0 86.1 84.6 87.7 90.0
Average 96.0 98.0 93.5 98.8 89.3 87.1 92.0 92.6
erature, including patient-wise data partitioning into
train and test sets (Zhang et al., 2021a), k-fold CV
(Rasheed et al., 2021), (Ryu and Joe, 2021), and LOO
CV (Gao et al., 2022). As a result, for a fair compari-
son and to avoid over-fitting, we evaluated the perfor-
mance of the proposed seizure prediction model using
the same 10-fold CV as the majority of existing ap-
proaches. Raw trials/segments of duration 1 second
were utilized without any preprocessing. The com-
pressed form of these segments was utilized to train
the 10-fold CV-based classifier.
3.2 System Performance
The sampling rate of the dataset is 256, while the hid-
den size of AE is 64 (at sparsity level 4). This im-
plies that the sparse signal length is 64, which the
SVM classifier uses to identify the data as pre-ictal
or inter-ictal. Among the 18 available EEG channels
of the dataset, we present the results of best and worst
performing channels. Channel ‘FzCz’ corresponds to
the the best case providing the highest average clas-
sification results for all the patients, whereas, chan-
nel ‘FP1F7’ is the worst case. Table 2 provides a
summary of the patient-specific seizure prediction re-
sults achieved with these two channels. Performance
metrics include prediction accuracy (Ac), sensitiv-
ity (Sen), specificity (Spe), and area under the curve
(AUC). Even when using a single EEG channel, the
proposed approach can produce results comparable to
those of previous studies on the prediction of seizures.
The prerequisite is the Neurologist’s selection of the
channel.
The proposed classification approach is also eval-
uated using an AE with variable hidden sizes that gen-
erates sparse signals of varying lengths. Figure 2 il-
lustrates the average Ac, Sen, Spe, and AUC of the
proposed method for seizure prediction at each spar-
sity level. Statistical analysis of performance eval-
uation demonstrates that the proposed classification
model can be utilized in a variety of system-required
scenarios. The highest sparsity level reported is 32,
which corresponds to compressing an input signal of
length 256 to merely 8 samples.
3.3 Performance Comparison
Table 3 illustrates the performance comparison be-
tween the proposed algorithm and other existing
epileptic seizure prediction approaches for the CHB-
MIT dataset. However, even if the same datasets were
used, the model performance would be affected by the
selection of samples by different methods, the wide
variety of channel configurations, the division of data,
the duration of the pre-ictal period, and training ap-
proaches (such as processing for unbalanced data) and
evaluation techniques (LOO, k-fold CV etc). We used
a framework that is quite relevant to the existing high
performance approaches in order to achieve a com-
parative analysis that is pretty fair.
Methods for classifying EEG at the segment level
(1-30 sec intervals) and providing classification re-
sults in terms of accuracy, sensitivity, specificity, and
AUC are compared. In this table, we present the best
single-channel results. The AE utilized sparsity level
4. Classification performance statistics demonstrate
that our method yields comparable results to the state-
of-the-art, particularly in terms of prediction sensitiv-
ity, which is the most crucial factor to ensure that no
seizure event prediction is missed.
BIOSIGNALS 2023 - 16th International Conference on Bio-inspired Systems and Signal Processing
130

Table 3: Average classification results comparison with some recent seizure prediction methods for CHB-MIT database.
Ref. - Year No.
of Pa-
tients
Channels Segment
Length
SPH
(min)
Evaluation Data
balanc-
ing
Ac
(%)
Sen
(%)
Spe
(%)
AUC
(%)
(Yang et al.,
2021b)
13 22 5 sec 30 10-fold CV Overlap
window
92.0 87.8 92.8 91.3
(Rasheed
et al., 2021)-
2021
13 22 60 sec 10 10-fold CV GAN 92.0 90.9 89 -
(Truong
et al., 2018)
13 22 30 sec 30 LOO-CV
Seizure wise
Overlap
window
81.2 - -
(Ryu and
Joe, 2021)
23 18 10 sec 10 k-fold CV - 92.6 91.2 94.1 -
(Zhang et al.,
2021b)
19 23 8 sec 15 Train/Test
split
Overlap
window
89.9 92.9 87.0 -
(Usman
et al., 2021)
22 23 29 sec 32 k-Fold CV SMOTe - 93 92.5 -
(Liang et al.,
2022)
13 All 30 sec 30 LOO-CV Pa-
tient Wise
Overlap
window
- 88.3 - -
(Dissanayake
et al., 2021)
24 23 10 sec 60 10-fold CV Overlap
window
91.5 92.4 89.9 96.9
(Zhang et al.,
2021a)
13 23 5 sec 5 Test 1 patient;
Train Rest
- 80.0 - 74.1 -
(Sun et al.,
2021)
17 18 1.5 sec 30 4-fold CV Overlap
window
- 97.1 95.6 91.7
(Li et al.,
2021)
19 All 5 sec 15 LOO-CV
Seizure Wise
- - 95.5
-
- 93.8
-
(Gao et al.,
2022)
16 18 4 sec 30 LOO-CV Overlap
window
- 93.3 - -
(Halawa
et al., 2022)
16 18 10 sec 8 70% Train
30% Test
Overlap
window
93.4 - - 86.5
This work
(Channel
‘FP1F7’,
Worst Case)
13 1 1 sec 10 10-fold CV SMOTe 89.3 87.1 92.0 92.6
This work
(Channel
‘FzCz’ ,
Best case)
13 1 1 sec 10 10-fold CV SMOTe 96.0 98.0 93.5 98.8
4 CONCLUSIONS
Using a single-layer autoencoder and SVM classi-
fier, we introduced a hybrid method for developing
a baseline model for the early prediction of epileptic
episodes in this study. Two phases of EEG data pro-
cessing are proposed for the prediction of seizures.
First, a sparse signal is generated using a dimension-
ality reduction methodology based on a deep learning
method for unsupervised learning. The SVM classi-
fier is then trained to classify the data as either inter-
ictal or pre-ictal. Analysis of a single EEG chan-
nel are provided to predict the beginning of epileptic
episodes. Evaluation at the level of individual sig-
nals reveals the seizure-predicting capability of each
EEG channel. This method provides the possibility of
combining analysis of fewer EEG channels to get re-
liable seizure prediction on their basis. The proposed
method outperformed state-of-the-art methodologies,
with an average prediction sensitivity of 98% percent
and an area under the curve (AUC) of 98%. Develop-
ing such a high-performance system is beneficial for
the construction and usage of wearable devices and
sensor networks, making them more comfortable to
Using Sparse Representation of EEG Signal from a Shallow Sparse Autoencoder for Epileptic Seizure Prediction
131

use and smaller in size as a result of the decreased
processing requirements. In the future, the current
effort will be broadened to produce more exhaustive
findings.
REFERENCES
Alotaiby, T. N., Alshebeili, S. A., Alotaibi, F. M., and Alr-
shoud, S. R. (2017). Epileptic seizure prediction using
csp and lda for scalp eeg signals. Computational in-
telligence and neuroscience, 2017.
Cui, S., Duan, L., Qiao, Y., and Xiao, Y. (2018). Learning
eeg synchronization patterns for epileptic seizure pre-
diction using bag-of-wave features. Journal of Am-
bient Intelligence and Humanized Computing, pages
1–16.
Dissanayake, T., Fernando, T., Denman, S., Sridharan, S.,
and Fookes, C. (2021). Deep learning for patient-
independent epileptic seizure prediction using scalp
eeg signals. IEEE Sensors Journal, 21(7):9377–9388.
Gao, Y., Chen, X., Liu, A., Liang, D., Wu, L., Qian, R., Xie,
H., and Zhang, Y. (2022). Pediatric seizure prediction
in scalp eeg using a multi-scale neural network with
dilated convolutions. IEEE Journal of Translational
Engineering in Health and Medicine, 10:1–9.
Halawa, R. I., Youssef, S. M., and Elagamy, M. N. (2022).
An efficient hybrid model for patient-independent
seizure prediction using deep learning. Applied Sci-
ences, 12(11):5516.
Khan, G. H., Khan, N. A., Altaf, M. A. B., and Abid, M.
U. R. (2021). Classifying single channel epileptic eeg
data based on sparse representation using shallow au-
toencoder. In 2021 43rd Annual International Confer-
ence of the IEEE Engineering in Medicine and Biol-
ogy Society (EMBC), pages 643–646. IEEE.
Li, Y., Liu, Y., Guo, Y.-Z., Liao, X.-F., Hu, B., and
Yu, T. (2021). Spatio-temporal-spectral hierarchical
graph convolutional network with semisupervised ac-
tive learning for patient-specific seizure prediction.
IEEE transactions on cybernetics.
Liang, D., Liu, A., Li, C., Liu, J., and Chen, X.
(2022). A novel consistency-based training strategy
for seizure prediction. Journal of Neuroscience Meth-
ods, 372:109557.
Meng, Q., Catchpoole, D., Skillicom, D., and Kennedy, P. J.
(2017). Relational autoencoder for feature extraction.
In 2017 International Joint Conference on Neural Net-
works (IJCNN), pages 364–371. IEEE.
Rasheed, K., Qadir, J., O’Brien, T. J., Kuhlmann, L., and
Razi, A. (2021). A generative model to synthesize eeg
data for epileptic seizure prediction. IEEE Transac-
tions on Neural Systems and Rehabilitation Engineer-
ing, 29:2322–2332.
Ryu, S. and Joe, I. (2021). A hybrid densenet-lstm model
for epileptic seizure prediction. Applied Sciences,
11(16):7661.
Sun, B., Lv, J.-J., Rui, L.-G., Yang, Y.-X., Chen, Y.-G., Ma,
C., and Gao, Z.-K. (2021). Seizure prediction in scalp
eeg based channel attention dual-input convolutional
neural network. Physica A: Statistical Mechanics and
its Applications, 584:126376.
Tautan, A.-M., Dogariu, M., and Ionescu, B. (2019). Detec-
tion of epileptic seizures using unsupervised learning
techniques for feature extraction. In 2019 41st Annual
International Conference of the IEEE Engineering in
Medicine and Biology Society (EMBC), pages 2377–
2381. IEEE.
Truong, N. D., Nguyen, A. D., Kuhlmann, L., Bonyadi,
M. R., Yang, J., Ippolito, S., and Kavehei, O. (2018).
Convolutional neural networks for seizure prediction
using intracranial and scalp electroencephalogram.
Neural Networks, 105:104–111.
Usman, S. M., Khalid, S., and Bashir, Z. (2021). Epileptic
seizure prediction using scalp electroencephalogram
signals. Biocybernetics and Biomedical Engineering,
41(1):211–220.
Usman, S. M., Usman, M., and Fong, S. (2017). Epilep-
tic seizures prediction using machine learning meth-
ods. Computational and mathematical methods in
medicine, 2017.
Yang, J., Wu, Z., Peng, K., Okolo, P. N., Zhang, W., Zhao,
H., and Sun, J. (2021a). Parameter selection of gaus-
sian kernel svm based on local density of training
set. Inverse Problems in Science and Engineering,
29(4):536–548.
Yang, X., Zhao, J., Sun, Q., Lu, J., and Ma, X. (2021b).
An effective dual self-attention residual network for
seizure prediction. IEEE Transactions on Neural Sys-
tems and Rehabilitation Engineering, 29:1604–1613.
Zhang, Q., Ding, J., Kong, W., Liu, Y., Wang, Q.,
and Jiang, T. (2021a). Epilepsy prediction through
optimized multidimensional sample entropy and bi-
lstm. Biomedical Signal Processing and Control,
64:102293.
Zhang, S., Chen, D., Ranjan, R., Ke, H., Tang, Y., and
Zomaya, A. Y. (2021b). A lightweight solution to
epileptic seizure prediction based on eeg synchroniza-
tion measurement. The Journal of Supercomputing,
77(4):3914–3932.
Zhang, X. and Li, H. (2022). Patient-specific seizure pre-
diction from scalp eeg using vision transformer. In
2022 IEEE 6th Information Technology and Mecha-
tronics Engineering Conference (ITOEC), volume 6,
pages 1663–1667. IEEE.
Zhao, S., Yang, J., Xu, Y., and Sawan, M. (2020). Binary
single-dimensional convolutional neural network for
seizure prediction. In 2020 IEEE International Sym-
posium on Circuits and Systems (ISCAS), pages 1–5.
BIOSIGNALS 2023 - 16th International Conference on Bio-inspired Systems and Signal Processing
132
