
Sentence Transformers and DistilBERT for Arabic Word Sense Induction
Rakia Saidi
1 a
and Fethi Jarray
1,2 b
1
LIMTIC Laboratory, UTM University, Tunis, Tunisia
2
Higher institute of Computer Science of Medenine, Gabes University, Medenine, Tunisia
Keywords:
Clustering, Word Embedding, Word Sense Induction, NLP, BERT, Arabic Language.
Abstract:
Word sense induction (WSI) is a fundamental task in natural language processing (NLP) that consists in dis-
covering the sense associated to each instance of a given target ambiguous word. In this paper, we propose
a two-stage approach for solving Arabic WSI. In the first stage, we encode the input sentence into context
representations using Transformer-based encoder such as BERT or DistilBERT. In the second stage, we apply
clustering to the embedded corpus obtained in the first stage by using K-Means and Agglomerative Hierar-
chical Clustering (HAC). We evaluate our proposed method on the Arabic WSI summarization task. Exper-
imental results show that our model achieves new state-of-the-art on both the Open Source Arabic Corpus
(OSAC)(Saad and Ashour, 2010) and the SemEval arabic (2017).
1 INTRODUCTION
In natural language processng (NLP), Word Sense
Disambiguation (WSD) and Word Senses Induction
(WSI) are two close tasks that aim to determine the
sense of an ambiguous word. Given a sense inventory
for each word such as Wordnet, WSD is a supervised
task that aims to assign a sense to every ambiguous
word. Given a target word (e.g., “Bank”) and a set
of sentences containing the target (e.g., “he cashed a
check at the bank”, “he sat on the bank of the river”),
WSI is an unsupervised task that aims to cluster the
sentences according to their senses. Unlike the su-
pervised WSD, do not need to know the label (sense)
of each sentence, but the sentences inside a cluster
should be close to each other in terms of lexical sim-
ilarity and far apart from sentences in other clusters.
An example is shown in the figure 1.
In this paper we are concerned by WSI task and
we seek to partition sentences into groups based on
their semantic similarity.
In this study, the transformers model more es-
pecially BERT embedding was explored for Arabic
WSI. A two-stage approach were designed where first
we encoded sentences by transformer-based encoder
and second we applied clustering algorithms to par-
tition sentences. To the best of our knowledge, this
is the first Deep neural network based approach for
Arabic WSI.
a
https://orcid.org/0000-0003-0798-4834
b
https://orcid.org/0000-0003-2007-2645
The rest of the paper is organized as follows: Sec-
tion 2 presents the state of the art. Our approach is
explained in Section 3. The experimental setup is pre-
sented in Section 4. Results and discussion are pre-
sented in Section 5. We conclude this paper with a
summary of our contributions and discuss future ex-
tensions.
2 STATE OF THE ART
The problem of arabic WSI or unsupervised word
sense have been studied using a few methods.
(Rogati et al., 2003) defined a stemming model
based on statistical machine translation, Its only train-
ing resources were an English stemmer and a short
(10K phrases) parallel corpus. After the training
phase, parallel text is not required. By letting the
stemmer adapt to a chosen domain or genre, mono-
lingual, unannotated material can be used to further
enhance the stemmer. Rogati et al. presented results
for Arabic and mentioned that the method can be used
for any language that needs affix removal.
To address this specific issue, (Pinto et al., 2007)
describe a method that relies on clustering of a self-
expanded version of the original dataset. Using point-
wise mutual information, the self-expansion tech-
nique replaces each term in the original corpus with
a set of co-related terms. Pinto et al. mentioned that
this concept, which was evaluated for the English lan-
guage, performs well for the Arabic language as well,
1020
Saidi, R. and Jarray, F.
Sentence Transformers and DistilBERT for Arabic Word Sense Induction.
DOI: 10.5220/0011891700003393
In Proceedings of the 15th International Conference on Agents and Artificial Intelligence (ICAART 2023) - Volume 3, pages 1020-1027
ISBN: 978-989-758-623-1; ISSN: 2184-433X
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)

Figure 1: Five senses of the word bank in WordNet.
demonstrating its linguistic flexibility.
For the word embedding approaches, (Djaidri
et al., 2018) used the word2vec models. They inves-
tigated CBOW and Skipgram. Then, using the An-
noy indexer, which is quicker than the Gensim simi-
larity function, the model enables the construction of
an indexer based on the cosine similarity. The graph
is clustered to produce the various word meanings.
They collaborated with OSAC and Aracorpus, two
distinct news corporations. For a sample of Arabic
ambiguous words, they mentioned that they had good
results for word sense induction and good word sense
discrimination performance.
Our method fits into the approaches of word em-
bedding the only difference is that we exploited the
models to transform more precisely BERT due to the
limits of word2vec which are:
• Training: The networks’ training differs signif-
icantly. A straightforward single-layered neu-
ral network called Word2Vec is trained using the
ngrams of each distinct word as training data. A
sentence from the corpus is used to train BERT
to predict a masked word and the following sen-
tence.
• Vectors: Word2vec stores a single vector repre-
sentation of a word, whereas BERT creates a vec-
tor for a word based on its placement in a phrase
or a sentence.
Besides, these word embedding methods were applied
in several WSD works such us (El-Razzaz et al., 2021;
Saidi and Jarray, 2022; Al-Hajj and Jarrar, 2021; Saidi
et al., 2022b; Saidi et al., 2022a), so we want to know
its results on the WSI since these two problems are
very close.
3 PROPOSED APPROACH
We propose a two stage clustering approach for WSI.
First, we generate the sentence embedding by fine
tuning BERT and DistilBERT framework. Second,
run clustering algorithms such as K-means and HAC
sentence embedding vectors.
Our model using k-means algorithm is presented
in figure 2.
Identify number of cluster k
Get center of k-means
K-means algorithm
Get Clustering Data
If centroid change
Calculate cluster center again
Yes
No
DistilBERT DistilBERT
Word embedding
DistilBERT
Input data
n words /sentences
Start
End
Figure 2: Arabic WSI model based on K-Means algorithm
and DistilBERT word embedding.
Sentence Transformers and DistilBERT for Arabic Word Sense Induction
1021
3.1 Sentence Embedding
Word embedding refers to feature learning techniques
in NLP where words are mapped to distributed dense
vectors. Different word embedding techniques have
been proposed in the literature such as wor2vec,
GLOVE, Elmo and BERT. Similarly, sentence em-
bedding refers to a vector representation of an entire
sentence. It can be obtained by the aggregation of its
words embeddings or directly by creating a dummy
token that represents the sentence.
After reloading the data, we used DistilBERT
from SentenceTransformers:
1. BERT. Bidirectional Encoder Representations
from Transformers (BERT) is an unsupervised
language representation. It has been successfully
used in different NLP tasks, such as sentiment
analysis (Chouikhi et al., 2021) and documents
summarization (Tanfouri and Jarray, 2022). Prac-
tically, we input a sentence into BERT and we get
the vector representation of the sentence as the
hidden representation of the special classification
token ([CLS])
2. DistilBERT. DistilBERT (Sanh et al., 2019) is
a general-purpose pre-trained version of BERT,
40% smaller, 60% faster, that retains 97% of the
language understanding capabilities.
3. Sentence-BERT (SBERT). Sentence-BERT
(SBERT) is an extension of the BERT model
based on siamese network and triplet loss to
generate semantically meaningful sentence em-
beddings A Siamese Network is a deep learning
network that contains two identical subnetworks
used to generate feature vectors for each input
and compute the similarity between the two
inputs.
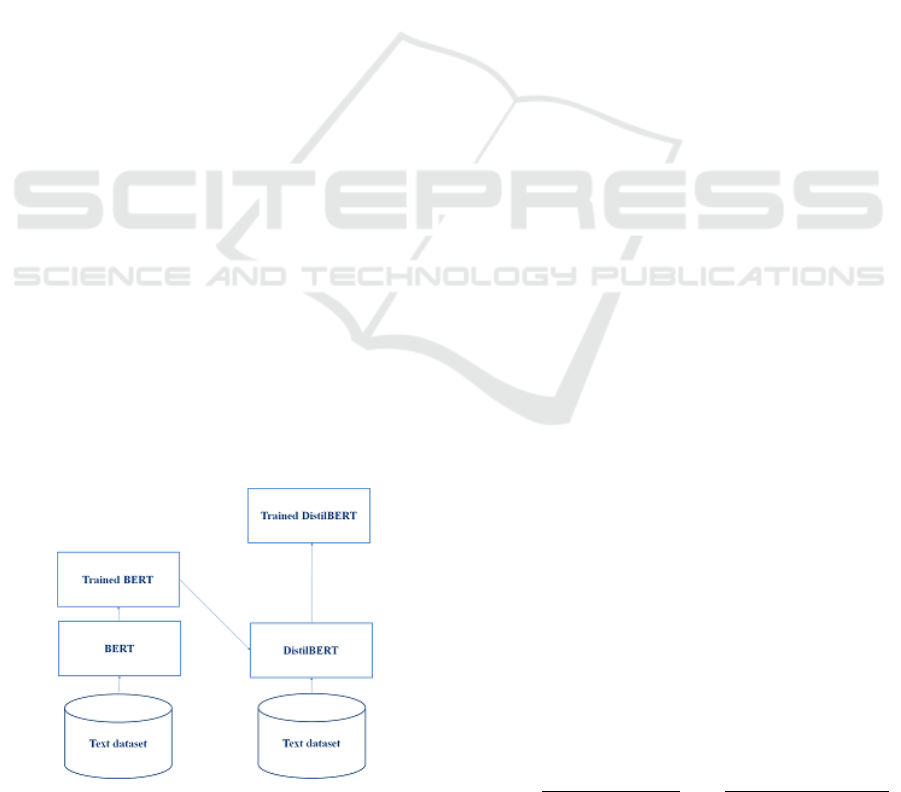
Figure 3 shows the difference between BERT
model and DistilBERT model.
Figure 3: DistilBERT vs BERT.
3.2 Sentence Clustering
Sentence clustering consists in dividing a textual cor-
pus into groups of semantically similar sentences. In
WSI, ideally, each sense will be assigned to a differ-
ent cluster. We cluster sentence embedding through
K-Means and hierarchical agglomerative clustering
HAC.
K-Means is an unsupervised Machine Learning
algorithm that aims to partition data points into K
clusters of equal variance. It alternates between the
assignment of the data points to the nearest clusters
while keeping the centroid of the clusters fixed, and
updating the centroid centers while holding the as-
signments fixed. HAC consists in iteratively merging
the two nearest pairs of clusters by the first step. The
second step of our approach consists on applying K-
Means and HAC to cluster the sentences embedding
obtained by the first step. The main advantage of hier-
archical clustering over K-Means clustering is that it
is not necessary to prespecify the number of clusters
and it can be applied to both categorical and numer-
ical features. However, HAC may be slow for very
large datasets due to the updates of the distance ma-
trix at each iteration and it may be less efficient when
clusters have a hyper spherical shape.
3.3 WSI Evaluation
This is the first Arabic work for WSI that uses a metric
for evaluation. Clustering validation has been recog-
nized as one of the important factors essential to the
success of clustering algorithms. How to effectively
and efficiently assess the clustering results of cluster-
ing algorithms is the key to the problem.
We used the internal cluster validation index
Calinski-Harabasz (CH) Index. CH-index can be used
to evaluate the model when ground truth labels are
not known, where the validation of how well the clus-
tering has been done is made using quantities and
features inherent to the dataset. The CH-index also
known as Variance Ratio Criterion (VRC) is a mea-
sure of how similar an object is to its own cluster (co-
hesion) compared to other clusters (separation). Here
cohesion is estimated based on the distances from the
data points in a cluster to its cluster centroid and sepa-
ration is based on the distance of the cluster centroids
from the global centroid.
The CH-index for K clusters on a dataset D =
[d
1
,d
2
,d
3
,. . . d
N
] is defined as,
CH =
"
∑
K
k=1
n
k
∥
c
k
− c
∥
2
K − 1
#
/
"
∑
K
k=1
∑
n
k
i=1
∥
d
i
− c
k
∥
2
N − K
#
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
1022

Table 1: CH-index for Arabic WSI model.
Dataset #Cluster CH on K-
Means
CH on
HAC-
Ward
CH on
HAC-
Single
CH on
HAC-
Complete
CH on
AHC-
AVG
5 238.83 192.35 7.29 11.563 11.61
OSAC 10 207.43 174.75 6.51 50.55 6.74
50 85.03 78.32 2.78 58.14 52.08
15 183.42 82.56 6.45 82.56 16.76
SemEval 34 105.49 61.39 7.68 61.39 12.67
50 81.72 75.81 7.45 51.65 13.12
where, n
k
and c
k
are the number of points and centroid
of the kth cluster respectively, c is the global centroid
of the dataset, N is the total number of data points.
4 EXPERIMENTAL RESULTS
AND EVALUATION
4.1 Dataset
We valid our approach on two Arabic datasets
:The Open Source Arabic Corpus (OSAC)(Saad and
Ashour, 2010) and the SemEval arabic task
1
.
• OSAC.
It is a corpus constructed from many websites. It
is split into three primary categories: Following
the elimination of stop words, the BBC-Arabic
Corpus has 1,860,786 (1.8M) words and 106,733
unique words, whereas the CNN-Arabic Corpus
contains 2,241,348 (2.2M) words and 144,460
unique words. After stopping words were re-
moved, OSAC, which was gathered from sev-
eral sources(Saad and Ashour, 2010) , contained
roughly 18,183,511 (18M) words and 449,600
unique words. It is divided into 10 categories.
This corpus is used in (Djaidri et al., 2018) as a
baseline.
• SemEval.
We used a new version of SemEval (2017), it is
split into three subtask: Message Polarity Classi-
fication (Subtask A), Topic-Based Message Polar-
ity Classification (Subtasks B-C) and Tweet quan-
tification (Subtasks D-E), it contains 2,278 for
training, 585 for validation and 1,518 for test. We
investigated just the training data. This data set
contains 34 classes. This corpus is used in (Pinto
et al., 2007) as a baseline.
1
https://www.dropbox.com/s/i9tkaajuq1qbgjq/
2017 Arabic train final.zip?
4.2 Experimental Results
We run the following experiments to study the differ-
ent aspects of the proposed approach. We automati-
cally clean and cluster the datasets as the following:
• Experiment 1 : the number of cluster equal to
the number of class existing in the dataset (10 for
OSAC and 34 for Arabic SemEval).
• Experiment 2: the number of clusters is greater
than the number of classes existing in the dataset.
• Experiment 3 : the number of clusters is less than
the number of classes existing in the dataset.
For the HAC clustering algorithm, we adopt four
similarity measures: ward link, single link, complete
link and average link. For all experiments, we choose
to do the same number of samples (5000), it helps
us after to do a credible comparison between the ob-
tained results.
Our main experimental results using CH-index
metric are shown in Table 1. The CH-index on K-
Means outperforms the CH-index on HAC and the
ward linkage outperforms the other linkage types,
For SemEval data and when the number of cluster
is 34, all the sentences containing the same word or
the same context as this word are put into the same
cluster, for example the sentences related to the word
" YK
ðPY
K
@ " are all put in the cluster 4.
Because the ward linkage performs better than
others, we choose to plot some clusters points.
We tested also AHC algorithm with un-predefined
number of cluster. Figure 5 plots the embedding data
with Agglomerative Clustering with 3 clusters and
with no predefined clusters.
The dendogram (with complete(1) ,ward(2) sin-
gle(3) and average(4) linkage) are presented in fig-
ure 6 for SemEval embedding data and in figure 7 for
OSAC.
Table 1 shown that the CH-index on K-Means
for OSAC performs better than on SemEval, so we
can note that our system gives better results in word
sense clustering (OSAC dataset) than in sentences
Sentence Transformers and DistilBERT for Arabic Word Sense Induction
1023
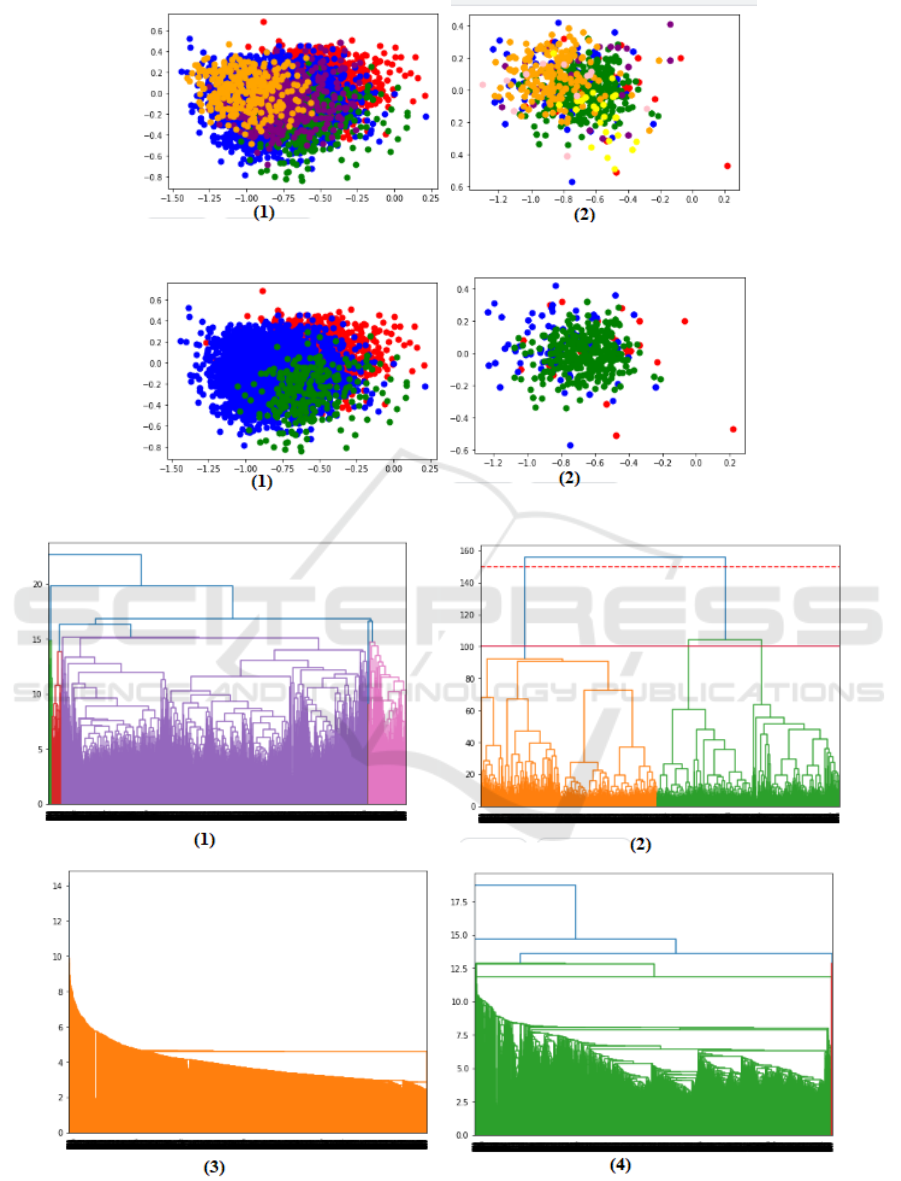
Figure 4: AHC for each embedding data, 10 for OSAC(1) and 34 for arabic SEMEVAL(2), this figure shows 5 clusters.
Figure 5: Result without predefined number of cluster, OSAC(1) and SEMEVAL(2).
Figure 6: Dendogram for SemEval data embedding.
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
1024

Figure 7: Dendogram for OSAC data embedding.
Table 2: CH of an example by updating the number of sam-
ples.
#Example #Cluster CH
3 284.94
10 131.84
2000 50 57.49
100 41.17
150 34.97
3 346.62
10 177.79
3000 50 75.78
100 54.35
150 45.76
3 387.62
10 198.72
4000 50 93.54
100 66.12
150 55.07
(Semeval). Based on this result, we chose to test a
set of words by modifying each time the number of
examples as well as the number of clusters. These
tests are shown in table 2.
If we have a higher number of examples the CH-
index increases, if we have less number of cluster we
have a good CH-index.
Number of Examples: 4000
For example, the word "
HA J
.
K@
" and the word
"H
.
Aj
.
J
@
" belong in the same cluster when the num-
ber of cluster equals to 10, but each word belongs in
a cluster when the number of clusters increases (150
here).
With 10 clusters:
in Cluster 3:
,"I
.
j
J
K@
" ,"H
.
Aj
@
" ,"
HAJ
.
K@
" ,"I
.
º
@
,"H
.
A
J
K@
" ,"I
.
j
J
K@
" ,"I
.
j
J
K@
" ,"H
.
Y
J
K@
" ," éJ
.
J
K@
"
," èAJ
.
J
K@
" ," èAJ
.
J
K@
" ," èAJ
.
J
K@
" ," èAJ
.
J
K@
" ," èAJ
.
J
K@
"
¡J
.
K
P@
" ,"H
.
A
K
P@
" ,"H
.
@
Q
¯@
" ,"H
.
A
j
J
K@
" ,"H
.
@Y
J
K@
"
,"AJ
.
K
P@
" ,"AJ
.
K
P@
" ,"AJ
.
K
P@
" ,"I
.
º
K
P@
" ,"K
.
"H
.
Aj
.
J
@
" ,"K
.
Q
K
A
J
@
" ,"ù
£
AJ
.
K
P@
"
Sentence Transformers and DistilBERT for Arabic Word Sense Induction
1025
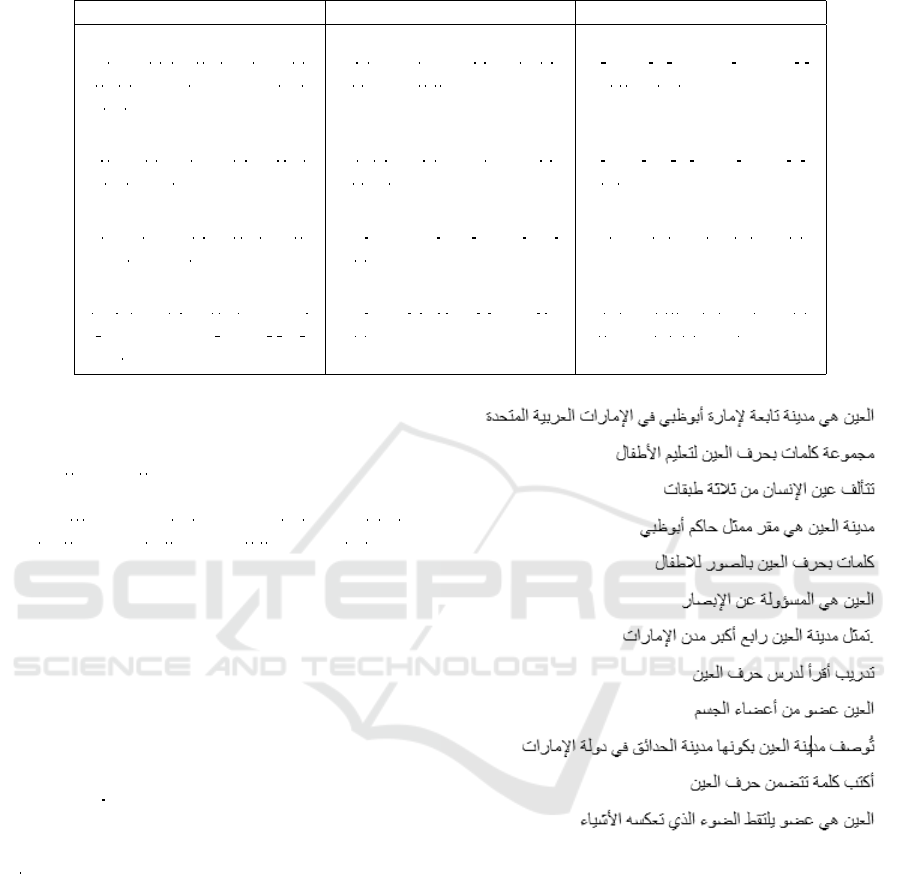
Table 3: Eye Clustering.
Cluster 1 Cluster 2 Cluster 3
èPAÓB
éªK
.
A
K
é
JK
YÓ ù
ë
á
ªË@
éJ
K
.
QªË@
H@PAÓB
@ ú
¯ ú
æ
.
£ñK
.
@
èYj
JÖ
Ï
@
á
ªË@
¬Qm
'
.
HAÒÊ¿
é«ñÒm
.
×
ÈA
®£
B@ Õæ
ʪ
JË
áÓ
àA
B
@
á
«
Ë
A
J
K
HA
®J
.
£
é
KC
K
É
JÜ
Ø
Q
®Ó ù
ë
á
ªË@
é
JK
YÓ
ú
æ
.
£ñK
.
@ Õ»Ag
PñËAK
.
á
ªË@
¬Qm
'
.
HAÒÊ¿
ÈA
®£CË
á«
éËð
ñÖ
Ï
@ ù
ë
á
ªË@
PA
.
B
@
Q
.
»
@ ©K
.
@P
á
ªË@
é
JK
YÓ É
JÖ
ß
.
H@PAÓB
@
àYÓ
¬Qk PYË
@Q
¯
@ I
.
K
PY
K
á
ªË@
Õæm
.
Ì
'@ ZA
«
@
áÓ ñ
«
á
ªË@
Aî
EñºK
.
á
ªË@
é
JK
YÓ
ñ
K
é ËðX ú
¯
K@Y m
Ì
'@
é
J K
Y Ó
H@PAÓB
@
¬Qk
áÒ
J
K
éÒÊ¿ I
.
J»
@
á
ªË@
Zñ
Ë@ ¡
®
JÊK
ñ
« ù
ë
á
ªË@
ZAJ
B@ 麪
K ø
YË@
With 150 clusters:
In Cluster 1:
"
HAJ
.
K@
" ,"
IJ
.
K
@"
In the cluster 45:
,"ÈY
J
.
J
@
" ,"H
.
@ñ
j
.
J
@
" ,"H
.
C
j
.
J
@
" ,"
éK
.
Aj
.
J
@
"
,"I
.
k
.
ñ
J
@
" ,"I
.
«
ñ
J
@
" ,"I
.
Ê
®
J
@
" ,"H
.
Aj
.
J
@
"
We can observe and note that when the number
of clusters is higher, the senses of words are closer
and belong to the same cluster and for the sentences
when the number of clusters is higher and the same
word is used in different contexts, our system is able
to eliminate the ambiguity of meaning and put each
group of sentences with the same meaning together in
a cluster and other sentences in another cluster despite
all the sentences containing the same word. We take
the word
á
« (eye en english) as an example. This
word in Arabic has 100 meanings and each one can
be distinguished according to the context containing
á
«. We used three senses in different sentences. Fig-
ure 8 present the set of sentences example and table 3
present its clustering.
We observed that the set of sentences was clus-
tered into three clusters: cluster 1 eye is a city in Emi-
rat, cluster 2 eye is an alphabet letter in the Arabic
language and cluster 3 eye is the organ.
5 CONCLUSION
In this paper, we have proposed a novel two-step ap-
proach for Arabic word sense induction. First, we
encode every sentence by transformer-based encoder.
Second, we cluster the embedded sentences by clus-
Figure 8: Eye sentences example.
tering algorithms such as k-means and HAC. We eval-
uate the model on both OSAC and Semval datasets.
The experimental results achieve state-of-the-art per-
formance through Calinski-Harabasz (CH) Index with
238.83 on K-Means algorithm and 192.35 on HAC-
Ward linkage method for the OSAC dataset.
REFERENCES
Al-Hajj, M. and Jarrar, M. (2021). Arabglossbert: Fine-
tuning bert on context-gloss pairs for wsd.
Chouikhi, H., Chniter, H., and Jarray, F. (2021). Arabic
sentiment analysis using bert model. In International
ICAART 2023 - 15th International Conference on Agents and Artificial Intelligence
1026

Conference on Computational Collective Intelligence,
pages 621–632. Springer, Cham.
Djaidri, A., Aliane, H., and Azzoune, H. (2018). A new
arabic word embeddings model for word sense induc-
tion. In 19th International Conference on Computa-
tional Linguistics and intelligent Text Processing, CI-
Cling.
El-Razzaz, M., Fakhr, M. W., and Maghraby, F. A. (2021).
Arabic gloss wsd using bert. Applied Sciences,
11(6):2567.
Pinto, D., Rosso, P., Benajiba, Y., Ahachad, A., and
Jim
´
enez-Salazar, H. (2007). Word sense induction
in the arabic language: A self-term expansion based
approach. In Proc. 7th Conference on Language
Engineering of the Egyptian Society of Language
Engineering-ESOLE, pages 235–245.
Rogati, M., McCarley, J. S., and Yang, Y. (2003). Unsu-
pervised learning of arabic stemming using a parallel
corpus. In Proceedings of the 41st annual meeting of
the Association for Computational Linguistics, pages
391–398.
Saad, M. K. and Ashour, W. M. (2010). Osac: Open
source arabic corpora. In 6th ArchEng Int. Sympo-
siums, EEECS, volume 10.
Saidi, R. and Jarray, F. (2022). Combining bert repre-
sentation and pos tagger for arabic word sense dis-
ambiguation. In International Conference on Intel-
ligent Systems Design and Applications, pages 676–
685. Springer.
Saidi, R., Jarray, F., and Alsuhaibani, M. (2022a). Com-
parative analysis of recurrent neural network architec-
tures for arabic word sense disambiguation. In WE-
BIST, pages 272–277.
Saidi, R., Jarray, F., Kang, J., and Schwab, D. (2022b).
Gpt-2 contextual data augmentation for word sense
disambiguation. In PACIFIC ASIA CONFERENCE
ON LANGUAGE, INFORMATION AND COMPUTA-
TION.
Sanh, V., Debut, L., Chaumond, J., and Wolf, T. (2019).
Distilbert, a distilled version of bert: smaller, faster,
cheaper and lighter. arXiv preprint arXiv:1910.01108.
Tanfouri, I. and Jarray, F. (2022). Genetic algorithm and
latent semantic analysis based documents summariza-
tion technique. In KDIR, pages 223–227.
Sentence Transformers and DistilBERT for Arabic Word Sense Induction
1027
