
A Topic-Based Data Distribution Management for HLA
Alberto Falcone
a
and Alfredo Garro
b
Department of Informatics, Modeling, Electronics and Systems Engineering, University of Calabria,
Via P. Bucci 41/C, Rende, Italy
Keywords:
Distributed Simulation, High Level Architecture (HLA), Data Distribution Management (DDM), Data
Reduction, Topic-Based Publish-Subscribe.
Abstract:
Modeling and Simulation (M&S) represents a fundamental technology for designing and studying complex
systems in various industrial and scientific domains, when real-world testing is too costly to perform in terms
of safety, time, and other resources. To promote the reusability and interoperability of simulation models al-
lowing them to interoperate without geographic constraints, distributed simulation has been introduced. One
of the most widely adopted standards for distributed simulation is IEEE 1516-2010 - High Level Architecture
(HLA). Among the services provided by HLA, a key one is the Data Distribution Management (DDM) that
allows to reduce the transmission and reception of unnecessary data in order to improve communication effec-
tiveness among simulation models. Although many matching algorithms have been proposed in the literature,
the upcoming HLA 4.0 standard defines a DDM that still relies on performing matching verification by calcu-
lating the overlap between regions using their dimensions. In this paper, a novel topic-based publish-subscribe
messaging system is proposed to improve the performance, reliability, and scalability of DDM services. Ex-
periments show that the proposed topic-based approach achieves better performance than the standard one.
1 INTRODUCTION
In the last years, the complexity of Cyber-Physical
Systems (CPSs) has increased exponentially, mainly
due to the heterogeneity of the involved components
and related interactions that connect the cyber world,
through a network of interconnected computational
resources (e.g., sensors, actuators, and processing
units), to the physical one (Lee, 2008; Falcone et al.,
2020; Falcone et al., 2022). CPSs are characterized
by being highly automated, intelligent, and collabora-
tive. The design and implementation of CPSs repre-
sent a challenging task due to the vast network and
computing resources connected to the physical en-
vironment involving multiple domains such as con-
trols, network protocols, and software engineering.
To capture the structure and behavior of such sys-
tems, researchers rely on Modeling and Simulation
(M&S) techniques (Bouskela et al., 2021; Derler
et al., 2012; Falcone et al., 2014). M&S represents
a pillar technology for designing and studying com-
plex systems in various industrial and scientific do-
mains, when real-world testing is too costly to per-
a
https://orcid.org/0000-0002-2660-1432
b
https://orcid.org/0000-0003-0351-0869
form in terms of safety, time, and other resources. To
promote the reusability and interoperability of simu-
lation models allowing them to interoperate without
geographic constraints, Distributed Simulation (DS)
has been introduced (Fujimoto, 2000). One of the
most widely adopted standards for distributed simu-
lation is IEEE 1516-2010 - High Level Architecture
(IEEE Std. 1516-2010, 2010).
The HLA standard defines a generic architecture
to support reusability and interoperability across sim-
ulation models. The standard was developed in 1996
under the guidance of the United States Department
of Defense (DoD) Modeling and Simulation Coordi-
nation Office (M&S CO). After its definition, HLA
caught the interest in the industrial and scientific do-
mains, so it was later moved into an IEEE interna-
tional standard with the official name “IEEE 1516”.
In the HLA terminology, a distributed simulation is
called Federation, which is composed of many HLA
simulation applications called Federates. Federates
interact with each other, in the same Federation, using
the services provided by the Run-Time Infrastructure
(RTI) that represents the communication middleware
that implements the HLA interface specifications and
rules. The structure and semantics of the data ex-
changed are delineated following the Object Model
186
Falcone, A. and Garro, A.
A Topic-Based Data Distribution Management for HLA.
DOI: 10.5220/0012051500003546
In Proceedings of the 13th International Conference on Simulation and Modeling Methodologies, Technologies and Applications (SIMULTECH 2023), pages 186-193
ISBN: 978-989-758-668-2; ISSN: 2184-2841
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)

Template (OMT) specifications. The RTI provides six
service groups to handle the distributed simulation ex-
ecution: Federation Management, Declaration Man-
agement, Object Management, Ownership Manage-
ment, Time Management, and Data Distribution Man-
agement (DDM).
DDM provides a set of services to minimize the
transmission and reception of unnecessary data and
then maximize communication effectiveness among
Federates, letting them specify the data of interest.
Specifically, the interest in specific information is ex-
pressed as bounded portions of a n-dimensional space
of user-defined dimensions. Both consumer and pro-
ducer federates specify the upper and lower bounds
for a specific portion, thus creating a so-called re-
gion. Federates that produce data define update re-
gions; whereas, federates that consume data specify
subscription regions.
At the core level, DDM services use an algorithm
that scans all n-dimensional regions to find the pairs
of regions (update,subscription) that generate over-
lap. The RTI routes data from producer federates to
consumer ones if and only if there is an overlap, i.e., a
match between their update and subscription regions.
According to the HLA standard, a match must be re-
ported to the RTI exactly once by the DDM services.
This problem is well-known in theoretical computer
science and can be solved using suitable algorithms
with ad-hoc spatial data structures. However, many
DDM implementations tend to rely on less efficient
algorithms that adopt complex spatial data structures
whose manipulation may have a significant impact
on computational resource utilization (Marzolla and
D’angelo, 2020).
In this paper, the novel Topic-Based Matching Al-
gorithm (TBMA) is proposed to improve the perfor-
mance, reliability, and scalability of DDM services.
TBMA defines the concept of topic to handle a high
number of regions, where the match operation is per-
formed by using topics instead of calculating overlaps
between regions’ coordinates.
The paper is structured as follows. Section 2
provides the problem statement along with key def-
initions. Section 3 discusses related work on the
HLA DDM services and existing matching algo-
rithms. Section 4 describes the proposed topic-based
DDM approach. Section 5 presents experiments car-
ried out to evaluate the performance of the proposed
topic-based matching algorithm, where the simulation
results have been compared with the standard one. Fi-
nally, conclusions are discussed in Section 6.
2 PROBLEM STATEMENT
The DDM services are based on the following defini-
tions (IEEE Std. 1516-2010, 2010):
Definition 1: Dimension. It is a non-negative interval
with an associated label. The interval is defined by an
ordered pair of values [d
lb
,d
ub
] := {x ∈ R | d
lb
≤ x ≤
d
ub
}, with d
lb
≤ d
ub
. The interval lower bound d
lb
is
0 for every dimension, while the upper bound d
ub
can
vary for each dimension.
Definition 2: Range. It is a continuous semi-open
interval defined on a dimension d. It is defined by an
ordered pair of values [r
lb
,r
ub
) := {x ∈ R | r
lb
≤ x <
r
ub
}, with r
ub
− r
lb
≥ 1. The component of the range
r
lb
and r
ub
are known as range lower bound and range
upper bound, respectively.
Definition 3: Region Specification. It is defined as a
set of ranges, named RS. RS must contain at most one
range r for any given dimension d ∈ D, where the di-
mension set D is derived starting from the ranges that
constitute RS. Each range r ∈ RS is defined in terms
of bounds [0, d
ub
), where d
ub
is the corresponding di-
mension’s upper bound.
Definition 4: Region Template. It is defined as an
incomplete region specification in which one or more
dimensions have not been assigned ranges.
Definition 5: Region Realization. It is defined as a
region specification that is associated with an instance
attribute for update, a sent interaction, or a class at-
tribute or interaction class for subscription. The term
region may be used in cases where a region specifica-
tion, a region realization, or both apply.
The DDM process goes through four phases: (i)
declaration, (ii) match, (iii) connect, and (iv) for-
ward, which repeatedly occur throughout the feder-
ation execution (IEEE Std. 1516-2010, 2010; Zhu
and Wang, 2022). In the declaration step, feder-
ates create regions with a specific set of dimensions,
and declare the HLAObjectClass and/or HLAInterac-
tionClass data that they intend to publish and/or sub-
scribe, in terms of update and subscription regions,
respectively. In the match phase, the overlap between
each pair of update and subscription regions is cal-
culated, and obtained pairs are reported to the RTI.
After that, in the connect phase, the RTI establishes
connections between the sending federate and receiv-
ing ones. Finally, In the forward phase, data are for-
warded through the created connections.
The region matching problem can be defined as
follow. Given an update region set U = {u
1
,u
2
,...,u
n
}
and a subscription region set S = {s
1
,s
2
,...,s
m
}, such
that U
T
S ̸= {
/
0}, and R = U
S
S. An update u
i
and a
subscription s
j
region overlap if and only if all ranges
of dimensions that are contained in both regions over-
A Topic-Based Data Distribution Management for HLA
187

lap pairwise. If the regions do not have any dimen-
sions in common, they do not overlap. Algorithm 1
delineates the steps to check for overlap between two
ranges a = [a
lb
,a
ub
) and b = [b
lb
,b
ub
) for a given a
dimension d.
Algorithm 1: Calculation of an overlap between ranges for
a given a dimension d.
Require: d ▷ dimension
Require: a, b ▷ ranges defined both on d
1: overlap ← {(a
lb
= b
lb
)∨(a
lb
< b
ub
∧ b
lb
< a
ub
)}
2: return overlap
Figure 1 depicts an example of a two-dimensional
region matching problem composed of two subscrip-
tion regions S = {s
1
,s
2
} and one update region U =
{u
1
} both specified on the dimensions X and Y ,
where, for example, X and Y can represent latitude
and longitude, respectively (M
¨
oller et al., 2016). It is
easy to identify that the pair {(s
2
,u
1
)} is the solution
to the region matching problem, since their ranges
overlap on both dimensions. The pair {(s
1
,u
1
)} is
not part of the solution; therefore, s
2
will receive data
from u
1
while s
1
will not.
Dimension X
Dimension Y
S1
S2
U1
Figure 1: An example of the region matching problem in a
two-dimensional space.
The correct definition of the region matching al-
gorithm is crucial for the network and processing cost
(Raczy et al., 2005). This problem can be reduced
to the rectangles intersection problem. To find the
intersections between two-dimensional rectangles, in
(Bentley and Wood, 1980), the authors developed
an algorithm with computational complexity equal to
O(N · log(N) + K), where N is the number of two-
dimensional rectangles and K is the number of inter-
secting pairs discovered. However, the proposed al-
gorithm can only be applied to two-dimensional rect-
angles and does not offer a generic solution for n-
dimensional rectangles.
The following section reviews the existing liter-
ature contributions dealing with both the DDM ser-
vices and region matching algorithms.
3 RELATED WORK
Four relevant DDM matching algorithms have been
developed, i.e., Region-Based Matching (RBM),
Grid-Based Matching (GBM), Hybrid-Based Match-
ing (HBM), and Sort-Based Matching (SBM).
3.1 Region-Based Matching
The Region-Based Matching algorithm is also known
as Brute-Force Matching algorithm. Given a dimen-
sion d, it finds overlaps by comparing each update re-
gion with all the subscription ones. The RBM match-
ing algorithm is simple to implement and allows to
derive exact overlapping information. The compu-
tational complexity is O(n · m), where n and m are
the number of update and subscription regions, re-
spectively. However, this computational complexity
is affected by the number of dimensions; therefore,
in the generic d-dimensional case, i.e., running the
RBM algorithm for each dimension d and calculat-
ing intersections between regions, the computational
complexity is O(d · (n · m)).
The main advantage of this algorithm is its sim-
plicity, but it has scalability issues as regions and di-
mensions grow. RBM was adopted in the first ver-
sion of the Defense Modeling and Simulation Office
(DMSO) RTI implementation of the HLA 1.3 spec-
ifications, and in the M
¨
AK High-Performance RTI
(Wood, 2002; Pan et al., 2011).
3.2 Grid-Based Matching
The Grid-Based Matching algorithm works by par-
titioning the Multi-Dimensional Coordinate Space
(MDCS) into a grid of cells. Each region r is then
mapped, through a function f (r), to the correspond-
ing cells of the grid. In GBM, an overlap between an
update and a subscription region happens if and only
if they have at least one cell of the grid in common
(Boukerche et al., 2005).
While the GBM algorithm has a lower computa-
tional overhead than the RBM one, the overlapping
information is not exactly determined. Therefore, ir-
relevant data may be received by a subscribing feder-
ate f
s
even if it has no region overlaps with the up-
dating federate f
u
, but only because f
s
and f
u
have
at least one cell in the grid in common. Obviously,
SIMULTECH 2023 - 13th International Conference on Simulation and Modeling Methodologies, Technologies and Applications
188

this leads to unnecessary consumption of network re-
sources, and f
s
has to discard irrelevant data it re-
ceives. To overcome this issue, many RTI implemen-
tations with GBM-based DDM services adopt an ad-
ditional data filter on the receiving side.
The computational complexity is O(c + n · m/c),
where c is the number of cells, n and m are the num-
ber of update and subscription regions, respectively.
In the generic d-dimensional case, i.e., running the
GBM algorithm for each dimension d, the computa-
tional complexity is O(d ·(c +n ·m/c)) (Marzolla and
D’angelo, 2020).
Like RBM, this algorithm is simple to implement
but is more scalable than the first one. The perfor-
mance of the GBM algorithm depends not only on the
grid size but also on the size of the individual cells
that compose it. Indeed, the larger the cell size, the
greater the amount of irrelevant data transferred, but
the shorter the time the GBM algorithm takes to de-
tect overlaps between regions. On the other hand, the
smaller the cell size, the less irrelevant data will be
transferred, but the GBM algorithm needs much more
computational resources to determine overlaps. For
this reason, the choice of the cell size represents a cru-
cial aspect as it impacts the performance of the DDM
services based on GBM (Ayani et al., 2000; Tan et al.,
2000a).
3.3 Hybrid-Based Matching
The Hybrid-Based Matching algorithm combines the
GBM and RBM algorithms. Specifically, GBM is
used to partition the MDCS into a grid of cells, then
map regions to grid cells; while RBM is used to per-
form exact matching between update and subscription
regions that overlap the same cells in the grid (Tan
et al., 2000b).
This approach has two advantages. On the one
hand, it has a lower computational cost than the RBM
algorithm in determining the overlap information. On
the other hand, it overcomes the issue of the GBM al-
gorithm since it allows obtaining exact overlapping
information. Nevertheless, the main issue of the
HBM algorithm is that it has the same drawbacks as
GBM, i.e., the performance depends on the size of
both the grid and cells.
3.4 Sort-Based Matching
The Sort-Based Matching algorithm improves match-
ing performance by sorting the boundaries of re-
gions before evaluating their overlap (Pan et al., 2007;
Raczy et al., 2005).
The algorithm uses a bit-matrix M ∈ R
nxm
, where
n and m are the number of update and subscription
regions, respectively. Semantically, a row n
i
, with i =
0,...,|n| indicates the update region, while a column
m
j
, with j = 0,...,|m| the subscription region. Each
element M
i, j
is defined as follow:
(
1, if the regions i, j overlap,
0, otherwise.
(1)
Two sets of subscription regions (SubSetBe f ore and
SubSetA f ter) are defined as n-bit vectors to track re-
gions. The algorithm operates as follows. Given a
dimension d, it begins by assuming that each update
region overlaps each subscriber region; as a conse-
quence, each matrix element is initialized to 1. Then,
it inserts the ranges’ bounds of all regions into an or-
dered list ord list, initializes SubSetBe f ore = {
/
0},
and adds all subscription regions into SubSetA f ter.
Upon the initialization is completed, ord list is
scanned from bottom to top and operates, for each
element l
i
, with i = |ord list|,...,0, as follows. If l
i
is:
• a lower bound of a subscription region R, then
SubSetA f ter \ {R};
• an upper bound of a subscription region R, then
SubSetBe f ore ∪ {R};
• a lower bound of an update region R, then all re-
gions in SubSetBe f ore do not overlap with R, then
M is updated;
• an upper bound of an update region R, all regions
in SubSetA f ter do not overlap with R, then M is
updated.
The computational complexity is O(n · m), where n
and m are the number of update and subscription
regions, respectively. In the generic d-dimensional
case, i.e., running the SBM algorithm for each di-
mension d, the computational complexity becomes
O(d · (n · m)) (Raczy et al., 2005).
4 A TOPIC-BASED
PUBLISH-SUBSCRIBE
APPROACH FOR DDM
Despite research progress, most of the existing
region-matching algorithms need to scan every region
to find overlaps with others, resulting in a waste of
computing resources. To face these needs and short-
comings, the Topic-based publish-subscribe messag-
ing system (TBMS), of which the Topic-Based Match-
ing algorithm (TBM) is part, has been defined. The
idea behind this new messaging system is to have an
A Topic-Based Data Distribution Management for HLA
189
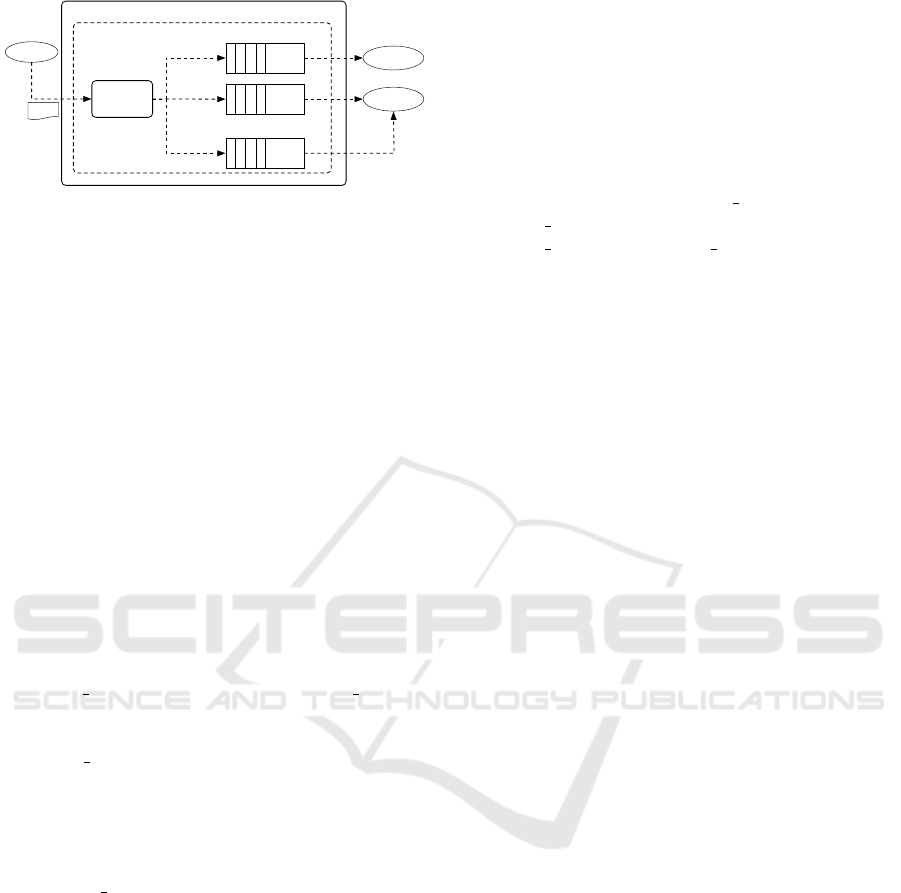
Run-time Infrastructure (RTI)
Data Distribution Management (DDM)
Producer
Topic
Queue (1)
Topic
Queue (2)
Topic
Queue (N)
Exchanger
…
Binding
Binding
Binding
Consumer
(A)
Consumer
(B)
Update
Data
Figure 2: Architecture of the Topic-based publish-subscribe
messaging system.
“exchanger” with a queuing system that mediates the
communication between federates, minimizing mu-
tual awareness, i.e., what federates should have of
each other to be able to exchange messages, effec-
tively implementing decoupling. A producer feder-
ate sends a message to the exchanger, which in turn
forwards it, by using the TBM algorithm, to the cor-
responding queue that consumer federates use to get
the message. A key advantage of TBMS is that the ex-
changer forwards messages to queues without need-
ing to know consumer federates.
TBMS changes the way with which DDM ser-
vices manage regions and find overlaps by intro-
ducing the concept of “topic”. A topic is a well-
structured string defined using a dot-delimited format,
and it is used to filter and deliver HLAObjectClass
and HLAInteractionClass messages. The structure of
a topic is composed of three parts:
region id.{ob ject|interaction}.instance id (2)
where:
• region id represents the identifier of the region;
• {ob ject|interaction} specifies the supported
datatype: object, for managing HLAObjectClass
and interaction for handling HLAInteractionClass
(IEEE Std. 1516-2010, 2010);
• instance id represents the identifier of the in-
stance.
Figure 2 depicts the architecture of TBMS along
with the key parts: Producer Federates, Exchanger,
Bindings, Queues, and Consumer Federates.
Producer Federates (see, Federate (A) in Figure 2)
are responsible for creation regions by using the cre-
ateRegion() method, with a specific set of dimensions.
For every dimension, the lower and upper bounds
of the range of that region are defined through the
setRangeLowerBound() and setRangeUpperBound()
methods, respectively (IEEE Std. 1516-2010, 2010).
A Producer Federate sends HLAObjectClass and
HLAInteractionClass messages to the Exchanger
component. When the Exchanger receives the mes-
sage, it is responsible for routing it to different Queues
by using the message’s topic information and Bind-
ings, which connect the exchange and queues.
The wildcard “*” has been defined to identify all
elements in a specific position of the topic structure.
This wildcard may be used to define a binding over a
topic following the same topic’s structure and Rule 1:
Rule 1. If the second part of the binding uses the
wildcard, then the last part must have the wildcard.
For example, < region id > . ∗ .∗, and
< region id > .ob ject.∗ are valid bindings; whereas,
< region id > . ∗ . < instance id > is invalid.
The Exchanger component forwards messages to
queues depending on wildcard matches between the
message’s topic and the queue binding’s routing pat-
tern. It is important to note that once the Producer
Federates sends a message to the Exchanger, it does
not wait for a response, i.e., it is not blocked.
Consumer Federates (see, Federates (B) and (C)
in Figure 2) defines one or more bindings and sub-
scribe to the related queues in order to receive mes-
sages from Producer Federates, and then process
them.
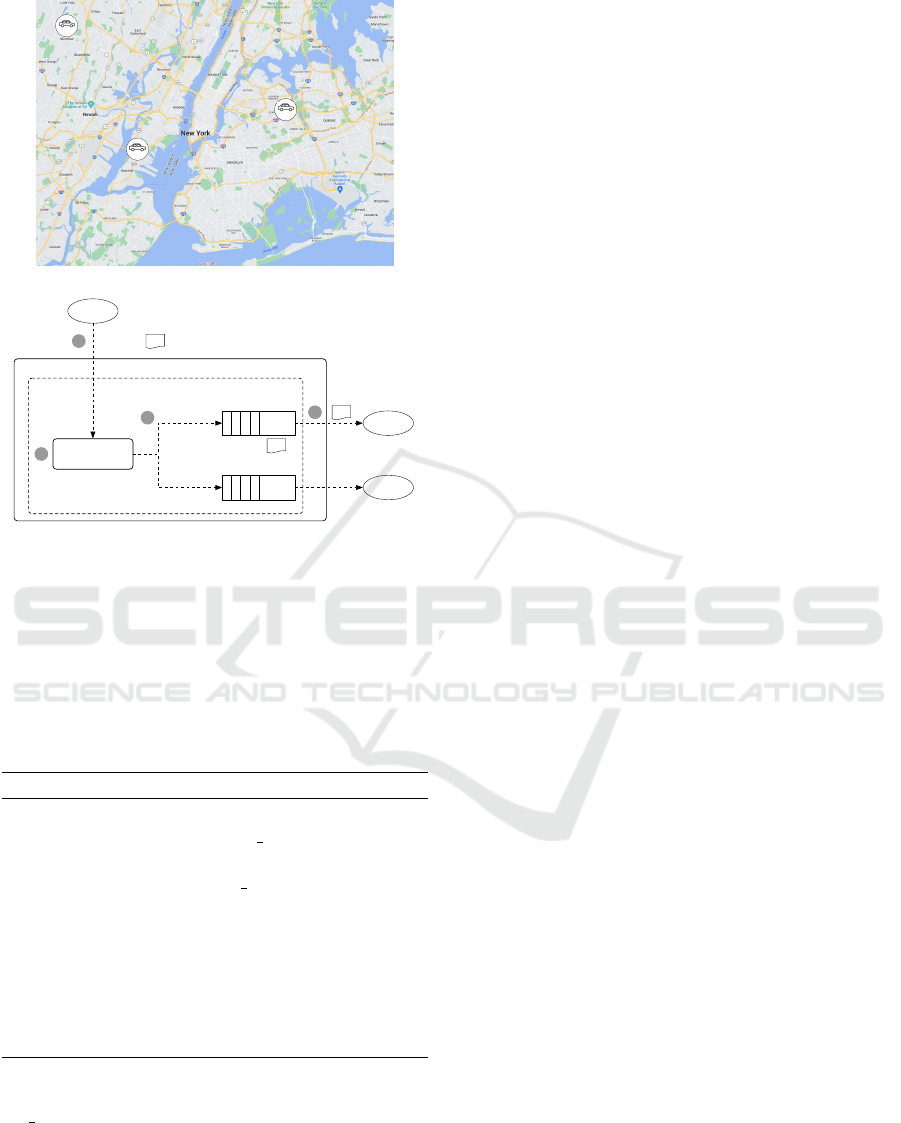
In order to explain the Topic-based publish-
subscribe messaging system more easily, a scenario
related to a drone patrol system is examined, as re-
ported in Figure 3. In this scenario, Federate (A) sim-
ulates three cars in the New York area, and related
data are published/updated on the RTI using the DDM
services extended with the proposed solution. Feder-
ates (B) and (C) simulate two drones used to patrol
the New York area, with the difference that Federates
(B) is interested in tracking and monitoring all cars,
whereas Federates (C) wants to track only “car1”.
When the simulation starts, Federate (A) creates
the region r
1
and simulates the movement of the three
cars (car
1
, car
2
, and car
3
) in the New York area. Fed-
erates (B) and (C) define the bindings r
1
.ob ject.∗ and
r
1
.ob ject.car
1
, respectively, and subscribe to the re-
lated queues. Every time Federate (A) updates data
related to a car and publishes it on the RTI, the fed-
erate sends a message consisting of two parts: (i) the
reference topic; and (ii) the car’s data (see Figure 3b
- step 1). Upon the Exchanger receives the message
(see Figure 3b - step 2), it uses the TBM algorithm
to forward the message to the corresponding queues
(see Figure 3b - step 3), and then to the subscriber
Federate(s) (see Figure 3b - step 4).
4.1 Topic-Based Matching Algorithm
The Topic-Based Matching algorithm allows the Ex-
changer component to deliver messages to queues
based on wildcard matches between the topic and the
binding patterns, which is specified by queues. All
SIMULTECH 2023 - 13th International Conference on Simulation and Modeling Methodologies, Technologies and Applications
190
Car1
Car2
Car3
(a)
Run-time Infrastructure (RTI)
Data Distribution Management (DDM)
Federate
(A)
Topic
Queue (1)
Topic
Queue (2)
Exchanger
Federate
(B)
Federate
(C)
r1.object.car1
r1.object.*
msg
(r1.object.car2, )
msg
msg
1
2
3
4
(b)
Figure 3: A scenario related to a drone patrol system: (a)
depicts the positions of car1, car2, and car3 on the map;
whereas, (b) reports the configuration of TBMS.
messages with a topic that matches a binding’s pat-
tern are routed to the queue, and then forwarded to
the consumer federates. Algorithm 2 presents the
steps performed by TBM to find overlaps between the
topic and binding patterns. It uses a key − value data
Algorithm 2: The Topic-Based Matching algorithm.
Require: t, m ▷ t - topic, m - message
1: bindings = Map < binding pattern,queue >
2: for entry in bindings do
3: bind ← entry.binding pattern
4: if wildcardMatch(bind,t) then
5: q ← entry.queue
6: q.enqueue(m)
7: else
8: discard m
9: end if
10: end for
structure to manage the associations between bind-
ing patterns and queues. For each entry in bindings
(see line 2), the algorithm checks whether the wild-
card bind matches with the topic t or not (Golan et al.,
2019). If yes, the queue q is retrieved, and then the
message m is enqueued into q in order to be forwarded
to all subscribed federates (see lines 5- 6). Otherwise,
the algorithm continues with the next entry.
The “wildcardMatch” method has a computa-
tional complexity of O(m), where m is the length of
the topic (Hajiaghayi et al., 2021). Since it is called
for each entry in bindings, the computational com-
plexity of TBM algorithm is O(n · m).
The following section presents the experiments
carried out to evaluate the performance of the Topic-
Based Matching algorithm. The gathered results have
been compared with the matching algorithm adopted
in HLA 4.0 (see, Algorithm 1).
5 EXPERIMENTAL EVALUATION
This section presents the experiments carried out
to evaluate the performance of the TBM algorithm.
The experiments have been written in the Java lan-
guage and performed on a MacBook Pro, equipped
with MacOS Catalina 10.15, 16GB of RAM, and
1TB of HD. To promote comparability of the simu-
lation results with those available in the literature, the
two − dimensional case has been considered.
To perform the experiments a RabbitMQ infras-
tructure has been set up (Rostanski et al., 2014;
Ayanoglu et al., 2016). RabbitMQ is a message-
oriented middleware, also known as message-broker,
that implements the Advanced Message Queuing Pro-
tocol (AMQP). It offers a common platform for send-
ing/receiving messages, ensuring the security of com-
munications. RabbitMQ acts as an intermediary be-
tween message consumers and producers, this pecu-
liarity makes it easy to decouple the involved parts.
RabbitMQ guarantees the delivery of messages, pro-
vides non-blocking features, and can be configured to
push notifications to producers. Moreover, it provides
support to the publish/subscribe mechanism, asyn-
chronous processing, and message queues.
To conduct the experiments, three factors have
been considered: Total number of regions, Overlap
rate, and Update rate. The first one is the most ob-
vious factor. If there are more regions, the match-
ing algorithm will take longer to determine overlaps.
The total number of regions, used in the experiments,
varies from 1000 to 10000. Each region has a size
of 20x20. All regions are evenly distributed in a
5000x5000 routing space.
The Overlap rate represents, as defined by Equa-
tion 3, the number of subscribed regions over the total
number of regions. The higher this rate, the longer it
takes for the algorithm to check whether or not two
regions intersect. In the experiments, three different
overlap rates were used: 0.25 (low), 0.50 (medium),
and 0.75 (high). Finally, the Update rate represents
A Topic-Based Data Distribution Management for HLA
191
the generation rate of update events on regions de-
fined by using a probabilistic model. It is used by the
producer federate to rate the generation of messages
to subscriber federates. In the experiments, the Pois-
son distribution has been chosen with mean number
of events per time interval λ = 0.8 in order to avoid
an excessive generation of events.
Overlap rate =
|subscribed regions|
|total regions|
(3)
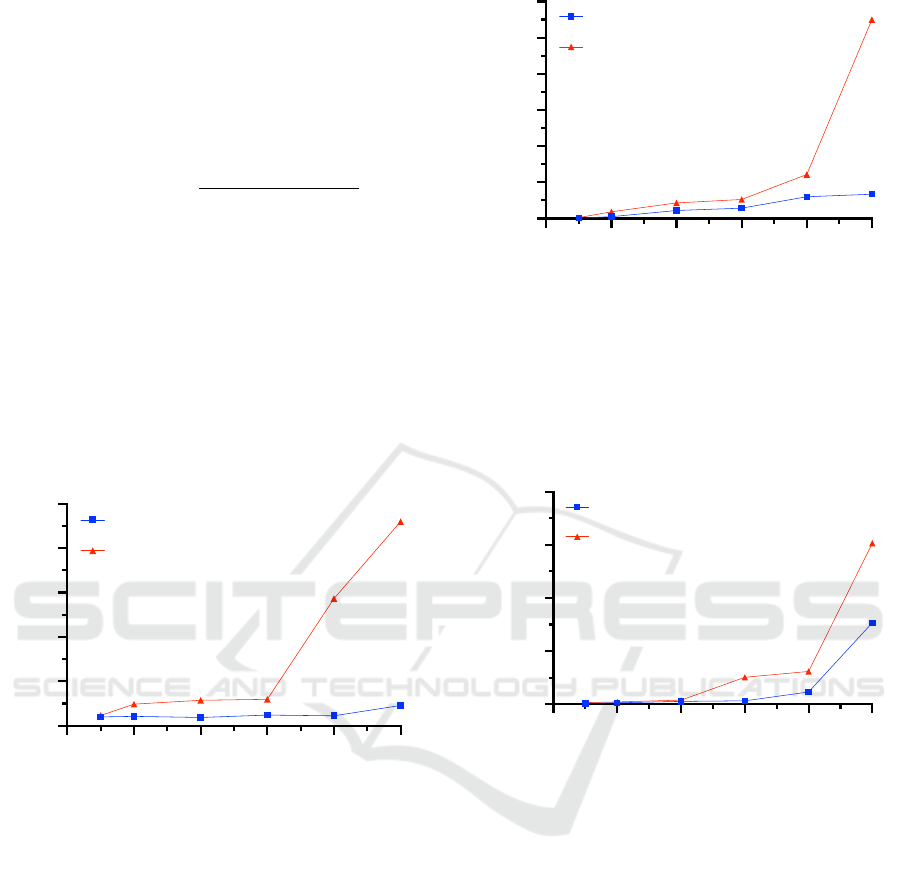
Figure 4 shows the time performance comparison be-
tween T BM and RBM matching algorithms with a low
overlap rate, i.e., 0.25. In this situation, since there
is a low number of intersections between subscription
and update regions, the computational cost for finding
overlaps does not vary much between the two consid-
ered algorithms as long as the total number of regions
remains relatively low, i.e., less than 6000 regions.
While, with a large number of regions, more signif-
icant than 6000, the T BM algorithm achieves much
better performance than RBM.
0 2000 4000 6000 8000 10000
0
5
10
15
20
25
Number of regions
Time (ms)
TBM
RBM
Figure 4: Performance comparison between the TBM and
RBM matching algorithms, with low overlap rate 0.25.
Figure 5 depicts the time performance compari-
son between the TBM and RBM matching algorithms
with an overlap rate of 0.50. In this situation, the com-
putational cost of both matching algorithms clearly
increases with respect to the previous case, since there
are more regions to evaluate. However, similar to
the previous scenario, the performance trend remains,
and the performance of the RBM algorithm is very
poor, while the proposed T BM algorithm has a better
processing time, especially when the total number of
regions is greater than 6000.
Concerning the scenario with a high overlap rate,
i.e., 0.75, there is a high degree of intersections be-
tween regions. The computational cost of both match-
ing algorithms still increases compared to the previ-
ous cases, as both directly depend on the total num-
ber of regions. Similarly to the previous scenarios,
0 2000 4000 6000 8000 10000
0
25
50
75
100
125
150
Number of regions
Time (ms)
TBM
RBM
Figure 5: Performance comparison between the TBM and
RBM matching algorithms, with medium overlap rate 0.50.
the computational cost shows the same trend, and the
RBM algorithm keeps achieving a lower performance
than the proposed T BM one. Figure 6 shows the time
performance comparison between the T BM and RBM
matching algorithms with a high overlap rate.
0 2000 4000 6000 8000 10000
0
500
1000
1500
2000
Number of regions
Time (ms)
TBM
RBM
Figure 6: Performance comparison between the TBM and
RBM matching algorithms, with high overlap rate 0.75.
6 CONCLUSIONS
In this paper, the novel Topic-based publish-subscribe
messaging system (TBMS), of which the Topic-Based
Matching algorithm (TBM) is part, has been defined
to improve the performance, reliability, and scalabil-
ity of DDM services in HLA. To evaluate the perfor-
mance of T BM, a set of experiments has been carried
out by considering different overlap rates. The exper-
iment results were compared with the ones obtained
with the standard Region-Based Matching (RBM) al-
gorithm. Results highlight the fact that the proposed
T BM algorithm achieves better performance than the
RBM one in the all considered overlap rates. Further
investigation will focus on the reliability and scalabil-
ity of the proposal.
SIMULTECH 2023 - 13th International Conference on Simulation and Modeling Methodologies, Technologies and Applications
192

REFERENCES
Ayani, R., Moradi, F., and Tan, G. (2000). Optimizing
cell-size in grid-based ddm. In Proceedings Four-
teenth Workshop on Parallel and Distributed Simula-
tion, pages 93–100. IEEE.
Ayanoglu, E., Aytas, Y., and Nahum, D. (2016). Mastering
rabbitmq. Packt Publishing Ltd.
Bentley, J. L. and Wood, D. (1980). An optimal worst
case algorithm for reporting intersections of rectan-
gles. IEEE Transactions on Computers, 29(07):571–
577.
Boukerche, A., McGraw, N. J., Dzermajko, C., and Lu, K.
(2005). Grid-filtered region-based data distribution
management in large-scale distributed simulation sys-
tems. In 38th Annual Simulation Symposium, pages
259–266. IEEE.
Bouskela, D., Falcone, A., Garro, A., Jardin, A., Otter,
M., Thuy, N., and Tundis, A. (2021). Formal Re-
quirements Modeling for Cyber-Physical Systems En-
gineering: an integrated solution based on FORM-L
and Modelica. Requirements Engineering, 27(1):1–
30.
Derler, P., Lee, E. A., and Sangiovanni Vincentelli, A.
(2012). Modeling cyber–physical systems. Proceed-
ings of the IEEE, 100(1):13–28.
Falcone, A., Garro, A., Mukhametzhanov, M. S., and
Sergeyev, Y. D. (2020). Representation of Grossone-
based Arithmetic in Simulink for Scientific Comput-
ing. Soft Computing, 24(23):17525–17539.
Falcone, A., Garro, A., Mukhametzhanov, M. S., and
Sergeyev, Y. D. (2022). Simulation of Hybrid Systems
Under Zeno Behavior Using Numerical Infinitesimals.
Communications in Nonlinear Science and Numerical
Simulation, 111:106443.
Falcone, A., Garro, A., and Tundis, A. (2014). Mod-
eling and simulation for the performance evaluation
of the on-board communication system of a metro
train. In the 13th International Conference on Mod-
eling and Applied Simulation, MAS 2014, Held at the
International Multidisciplinary Modeling and Simula-
tion Multiconference, I3M 2014, Bordeaux, France,
September 10-12, 2014, pages 20–29. Dime Univer-
sity of Genoa.
Fujimoto, R. M. (2000). Parallel and distributed simulation
systems, volume 300. Citeseer.
Golan, S., Kopelowitz, T., and Porat, E. (2019). Stream-
ing pattern matching with d wildcards. Algorithmica,
81(5):1988–2015.
Hajiaghayi, M., Saleh, H., Seddighin, S., and Sun, X.
(2021). String matching with wildcards in the mas-
sively parallel computation model. In Proceedings
of the 33rd ACM Symposium on Parallelism in Algo-
rithms and Architectures, pages 275–284.
IEEE Std. 1516-2010 (2010). IEEE Standard for Model-
ing and Simulation (M&S) High Level Architecture
(HLA): 1516-2010 (Framework and Rules); 1516.1-
2010 (Federate Interface Specification); 1516.2-2010
(Object Model Template (OMT) Specification).
Lee, E. A. (2008). Cyber physical systems: Design chal-
lenges. In 2008 11th IEEE International Symposium
on Object and Component-Oriented Real-Time Dis-
tributed Computing (ISORC), pages 363–369.
Marzolla, M. and D’angelo, G. (2020). Parallel data distri-
bution management on shared-memory multiproces-
sors. ACM Transactions on Modeling and Computer
Simulation (TOMACS), 30(1):1–25.
M
¨
oller, B., Antelius, F., Johansson, M., and Karlsson, M.
(2016). Building scalable distributed simulations: De-
sign patterns for hla ddm. In Proc. of Fall Simulation
Interoperability Workshop, 2016-SIW, volume 3.
Pan, K., Turner, S. J., Cai, W., and Li, Z. (2007). An ef-
ficient sort-based ddm matching algorithm for hla ap-
plications with a large spatial environment. In 21st
International Workshop on Principles of Advanced
and Distributed Simulation (PADS’07), pages 70–82.
IEEE.
Pan, K., Turner, S. J., Cai, W., and Li, Z. (2011). A dynamic
sort-based ddm matching algorithm for hla applica-
tions. ACM Transactions on Modeling and Computer
Simulation (TOMACS), 21(3):1–17.
Raczy, C., Tan, G., and Yu, J. (2005). A sort-based
ddm matching algorithm for hla. ACM Transactions
on Modeling and Computer Simulation (TOMACS),
15(1):14–38.
Rostanski, M., Grochla, K., and Seman, A. (2014). Evalua-
tion of highly available and fault-tolerant middleware
clustered architectures using rabbitmq. In 2014 feder-
ated conference on computer science and information
systems, pages 879–884. IEEE.
Tan, G., Ayani, R., Zhang, Y., and Moradi, F. (2000a). Grid-
based data management in distributed simulation. In
Proceedings 33rd Annual Simulation Symposium (SS
2000), pages 7–13. IEEE.
Tan, G., Zhang, Y., and Ayani, R. (2000b). A hybrid
approach to data distribution management. In Pro-
ceedings Fourth IEEE International Workshop on Dis-
tributed Simulation and Real-Time Applications (DS-
RT 2000), pages 55–61. IEEE.
Wood, D. D. (2002). Implementation of ddm in the mak
high performance rti. In Proceedings of the simulation
interoperability workshop. Citeseer.
Zhu, G. and Wang, H. (2022). Empirical study of
large-scale hla simulation of parallel region-matching
knowledge recognition algorithm based on region
matching. Computational Intelligence and Neuro-
science, 2022.
A Topic-Based Data Distribution Management for HLA
193
