
Multi-Lang Question Answering Framework for Decision Support in
Educational Institutes
Walaa A. Elnozahy
a
and Ghada A. El Khayat
b
Information Systems and Computers Department, Faculty of Business, Alexandria University, Alexandria, Egypt
Keywords: Question Answering System, Education, Information System, Ontology, Question Answering, Knowledge
Extraction, Information Retrieval, Education Data, Linked Data, Decision Support, Arabic NLP,
Multi-Lingual, Student Recruitment.
Abstract: Language Diversity has always been an important factor in different educational institutes; Also, a challenge
for those interested in Data Analysis, Question answering, and Natural Language Processing (NLP).
Researchers who are interested in linguistics are involved in enhancing language processing techniques, and
how to apply them. They usually work through Question answering systems or Chatbots. Question Answering
Systems and chatbots are now highly recognized, especially after the huge commercial announcement for
services such as ChatGPT and Google’s new AI tool. Considering that these tools are very useful as open-
domain tools. However, if we think from an institutional perspective, it will require further validation due to
the domain type and the data type. it’s also easier for the Decision maker to comprehend and use. During the
past few years, many attempts have been made to include Question Answering Systems in the Education
sector. However, most of these attempts were single language Software mostly using English. Also, targeted
students as a decision-maker to support the education process between teachers and students instead of the
educational actors on a strategic level. The scarcity of the tools available in this domain, make it a challenging
topic that needs more research attention. In this research, we are Proposing a Multi-lang Question Answering
Framework that aims to support the Educational Sector from a strategic point of view. It aims to provide a
Generic framework that will help Universities Identify the Students who will be best fit for a specific
university program. The framework aims to cope with and adjust to the data type and enhance its conditions
from historical data. Regardless of the resource language and origin. It is based on an ontological model for
the education domain and uses NLP to process the data and get relevant answers for the users. Future work
for this research will focus on enhancing the retrieval for the system, especially using the Arabic language,
and support more languages in the tool.
1 INTRODUCTION
Question Answering Systems (QA) are getting more
exposure currently with the rise of new tools that
support a general purpose. One of the main tools here
is the trending ChatGPT, which was launched on 30
November 2022. The tool doesn’t focus on a specific
domain, instead, it is an open domain chatbot
(OpenAI, 2022). The launch of the tool increased the
estimated value of the company to 29 billion US
dollars (Hao, 2022; Jin & Kruppa, 2023). Even
though the ChatGPT is an Open-Domain, it impacted
many domains including the Education domain. As
a
https://orcid.org/0009-0007-8245-0185
b
https://orcid.org/0000-0002-6201-629X
per (Rudolph et al., 2023), ChatGPT has a huge
impact on education and the learning process from
both student and teacher perspectives. However, it is
not concerned with the strategic or administrative
perspective. Overall, the Question answering system
is a powerful tool that is simple and provides replies
to the decision-makers’ questions using Natural
language. It provides simple and precise answers to
user questions. (Pudaruth et al., 2016).
Previously, many attempts were made in
education to support decisions such as an attempt
(Elnozahy et al., 2019) to apply the question-
answering framework that was used to support
student Orientation, Recruitment, and Retention,
Elnozahy, W. and El Khayat, G.
Multi-Lang Question Answering Framework for Decision Support in Educational Institutes.
DOI: 10.5220/0012059700003470
In Proceedings of the 15th International Conference on Computer Supported Education (CSEDU 2023) - Volume 1, pages 427-435
ISBN: 978-989-758-641-5; ISSN: 2184-5026
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
427

another one (Hien, 2018) which targeted staff support
and help to answer student questions. Another
attempt by (Colace et al., 2018; Okonkwo et al.,
2020). These are just a small variety of research for
using question answering in education support. But
also, but also in other domains even in Chemistry
Engineering as per (Zhou et al., 2021) the research
showed a proof of concept of a system that grants
access to accessing chemical data from knowledge
graphs.
The tool mainly depends on Natural language
processing to comprehend and analyze the data to
extract correct answers. According to a review made
in 2021 about Question answering in Education, it
showed that most of the research considered just one
language, mainly English. They consider 2 Latin
languages, rarely considering Arabic (Elnozahy & El
Khayat, 2021).
Based on a survey conducted in 2021 by
(Alwaneen &Azmi & Aboalsamh, 2021) offered a
summary of all the challenges of Arabic question-
answering. This was concluded in the language nature
and challenges including the lack of suitable tools and
techniques based on the language structure compared
to Latin and Romance languages. Especially the
resource scarcity in this language compared to other
languages such as English, German, French, Italian,
Spanish, Portuguese, and Chinese.
In another survey conducted in 2022, a survey on
Question answering tackled how the tools are
working and the type of data sources. And the
majority was open domain similar to ChatGPT.
(Antoniou & Bassiliades, 2022). One of the proposed
attempts in 2022, was a cross-lingual Question
answering system which considered Arabic-English
resources and processing. (Elnozahy & El Khayat,
2022).
In this Research, we are proposing a Muli-lang
Question answering framework that supports
strategic decision-makers in universities. It provides
insights & recommendations on which students will
be the best fit for a specific university program
through the review of students’ competencies. The
System is a further enhancement of a Question
answering framework provided in 2019 (Elnozahy &
El Khayat 2019) and static language handling
(Elnozahy & El Khayat, 2022). In this research, we
are trying to overcome the language barrier by not just
considering the Arabic language but proposing a
generic free language System.
This paper is organized as follows: Section 2
contains a review of the related work and literature,
section 3 presents the Multi-lang Question Answering
Farmwork and the proposed implementation, and the
discussion and future work are in section 4.
2 LITERATURE REVIEW
In this section, I provided a review of the related work
and literature to the problem under study. Starting
with a review of Natural language processing in
Arabic & Latin Languages, recent work on Question
answering and its handling, and Question Answering
systems in the education Domain.
2.1 Natural Language Processing in
Arabic & Latin Languages
Natural language processing (NLP) is the process of
analyzing languages that are responsible for
developing techniques and tools that can support
language analysis whether in written or spoken forms
(Marie-Saint et al., 2018). The natural language
processing techniques are used in various
applications such as sentiment analysis (Verma &
Jain, 2022), text categorization (Chang et al., 2008),
web page spam detection (EL-Mohdy et al., 2018),
translation (Harrat et al., 2019) and many more
applications.
Language processing has different challenges
based on the language. For instance, if we consider
Arabic Natural Language Processing, the complexity
is higher than most of the other languages concerning
the following:
● The shape of the language is different from
normal Latin letters.
● The form of the letters has one vs multiple
forms.
● Grammar rules, and the fact that changing one
letter in a word may change its tense
completely.
● Sentence compositions considering that one
word can have multiple meanings based on the
context and is represented as a sentence in
English (Marie-Saint et al., 2018)
Same consideration is to be noted when working
with other languages such as Chinese, where one
letter can represent a full sentence. However, the
Chinese have multiple resources and materials, unlike
the Arabic. (Conneau et al., 2019). A wide range of
attempts is constantly being made to provide
language tools that would make processing easier
Using various approaches such as Machine learning
EKM 2023 - 6th Special Session on Educational Knowledge Management
428
approaches, semantic approaches, deep learning, and
other approaches. It is mainly done through a set of
techniques such as Sentiment Analysis, Named Entity
Recognition (NER), Keyword Extraction,
Lemmatization, and stemming techniques (Elbarougy
et al., 2020; Bourahouat et al., 2023).
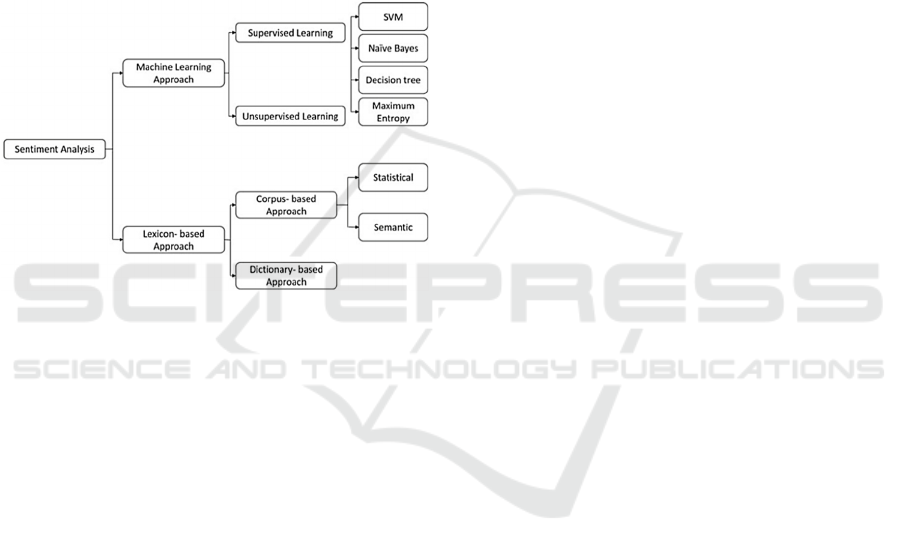
Sentiment Analysis is a way to evaluate the
feelings of the word, either negative or positive, or
natural feeling. It uses various techniques such as
figure 1, a machine learning approach using
supervised and unsupervised learning techniques, or
lexicon-based approval that either uses a dictionary,
statistical methods, or semantic methods (Abualigah
et al., 2020a).
Figure 1: Techniques for Sentiment Analysis.
Also, the Named Entity Recognition technique, is
a process where the system tags the sentences based
on the related entity such as [Organisation, person,
location, time, and measurement (Shaalan, 2014).
Then we have the Text Summarization
techniques, which can be explained as the process of
eliminating the extra text to keep the core goal and
important elements of the text of the document. (Al-
Abdallah & Al-Taani, 2019). The techniques can be
summarised based on multiple models for example
using semantic analysis, fuzzy method, Neural
network-based method, and machine learning
methods. (Abualigah et al., 2020b).
To be able to perform the previously mentioned
application a set of actions or steps are mostly in
action to do text pre-processing and handling which
can be specified in the following details or crucial
steps. Tokenization, the system splits the paragraphs
into tokens ``words”. This is harder to do in Arabic as
sometimes the same word is a sentence, or two words
would form one word. (Alotaiby et al., 2009).
Normalization, where we unify the look and feel of
the text by Removing diacritics, punctuation, and any
whitespace duplication, also remove the definition
letter in English “the, a, an”, in Arabic “لا” in French
“le, la, les, las” to unify the letters despite its different
looks (Gharib et al., 2009). Stemming and
lemmatization, which is replacing the word with its
stem. stemming is done using tools such as a rooted
stemmer or light stemmer (Alhaj et al., 2020). Also,
using N-gram techniques (Yousef et al., 2014). Once
the stem is done, the lemmatization process starts to
get the root word through morphological analysis.
Morphological Analysis, an advanced process after
stem (lemmatization). It aims to get the root of the
world based on its morphology. It’s simple for
English. Also, contributions are made to Arabic and
other languages. For example, Buckwalter Arabic
Morphological Analyzer (BAMA) a main
contribution since 2004 (Buckwalter, 2004), then by
2017 another contribution of Alkhalil Morpho
(Boudchiche et al., 2017). Part of Speech Tagging
[POS] at this point a syntactic role is assigned to each
word. The three main POS’s: Noun, Verbs, adverbs,
conjunctions, interrogative particles, and
interjections. There are many tools available in
different languages including Arabic that can be used
here. (Abumalloh et al., 2016; Chiche & Yitagesu,
2022; Li et al., 2022).
As per (Elnozahy & El Khayat 2022) many tools
are created by other researchers to support different
languages such as word2vec, Bi-directional Encoder
Representations from Transformers (BERT). Which
has an alternative in other languages for example in
Arabic it works on Aravec and Arabert. We can sum
this up by saying that each language has a set of tools
created using known Machine learning techniques to
overcome most of its obstacles.
2.2 Question Answering Systems
Question answering is a generic framework that
provides a very sophisticated yet simple and
insightful result. The framework consists of multiple
sections/ modules, the data source, and whether it’s
internal or external. The processing ability and
techniques or what’s called the approach. Then the
extraction and representation.
2.2.1 Question Answering Techniques &
Approaches
As per the literature, question-answering systems
have five approaches which are the Linguistic
approach, statistical approach, pattern matching, and
surface and template-based approach. Each approach
has its unique methodology and handling. Also, some
intersection between the approach techniques would
happen (Elnozahy & El Khayat, 2021).
Multi-Lang Question Answering Framework for Decision Support in Educational Institutes
429
● The linguistic approach uses Natural
Language Processing (NLP) Techniques to
understand and evaluate the question. Also,
through Tokenization, part of speech (POS),
tagging and parsing, etc. it can extract and
identify the answer (Sasikumar & Sindhu,
2014).
● The statistical approach gives better results
than other approaches as it is independent of
structured query languages, also it can
formulate queries in natural language form. It
mostly uses statistical techniques such as
Support vector machine classifiers, Bayesian
Classifiers, and maximum entropy models.
● The Pattern matching approach is used to
interpret input sounds or utterances through
the merging of the words meaning. Here we
have fixed patterns that are being matched
with words’ patterns. This approach replaces
the sophisticated processing in other
computing approaches through the expressive
power of text patterns (AbuShawar & Atwell,
2016; Dwivedi & Singh, 2013).
● Surface Pattern-based approach is learning
based on patterns that are automatically
learned from data. It surfaces the text to get the
similarly crafted data that is related to the
Question (information needed). It is
considered a method for Pattern matching.
● The last approach is the template-based
approach. Which works on a template of
keywords and data “questions preformatted
patterns”. The main goal here is the
demonstration in replacement for the
explanation of question and answer.
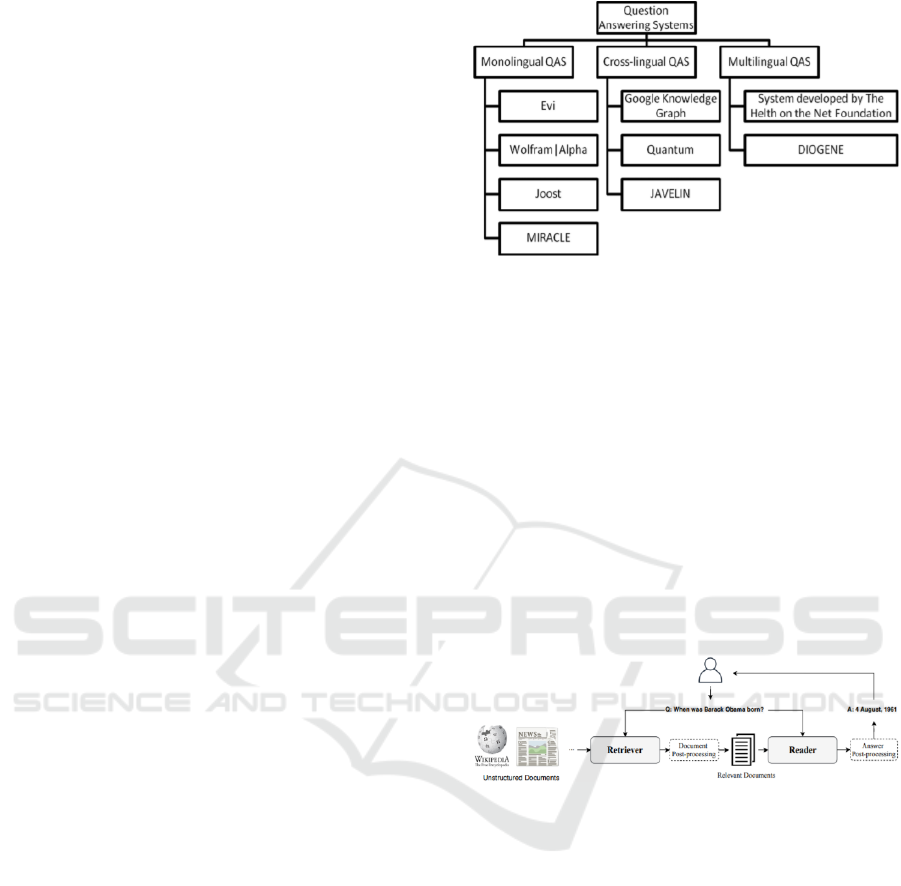
In a review paper about Question answering
(Ojokoh & Adebisi, 2018) a categorization of the
question-answering systems in terms of the following
criteria.
● Domain Classification whether it’s the open
domain or closed domain.
● Question types such as factoid or WH-
Questions, list, causal questions, etc.
● Data Source classification
● Language classification where it’s classified
based on the number of supported language
figure 2, (Lebedeva and Zaitseva 2015)
Figure 2: Language paradigm-based classification.
● Approaches classification where the QA
systems are grouped based on the approach
they are using by NLP, statistical, or pattern.
2.2.2 Question Answering Systems
Architecture
The simple architecture for question answering can be
represented in the following 3 main steps: (Zhu, et al.,
2021)
● Question analysis
● Search for the data source
● Extract answer.
Figure 3: QA “Retriever-Reader” Architecture.
In figure 3, an overview of the question-answering
process is represented starting with the user asking a
question then it is sent to the reader to parse then
searched to retrieve the data, then the data is
evaluated based on the score to get the correct results.
The data source provided could be a Document as
shown in the example explained in the figure, or a
different source based on the database, or ontology.
A Question Answering called “YodaQA” stands
for “Yet anOther Deep Answering pipeline” was built
to work on unstructured sources. DBpedia ontology
& the Freebase RDF dump are the main sources for
this system. DBpedia is an online ontology created in
2007 (Auer et al., 2007). Systems use full-text search,
structured search, and document search. as search
techniques (Figure 4) (Baudiš & Šedivý, 2015).
EKM 2023 - 6th Special Session on Educational Knowledge Management
430
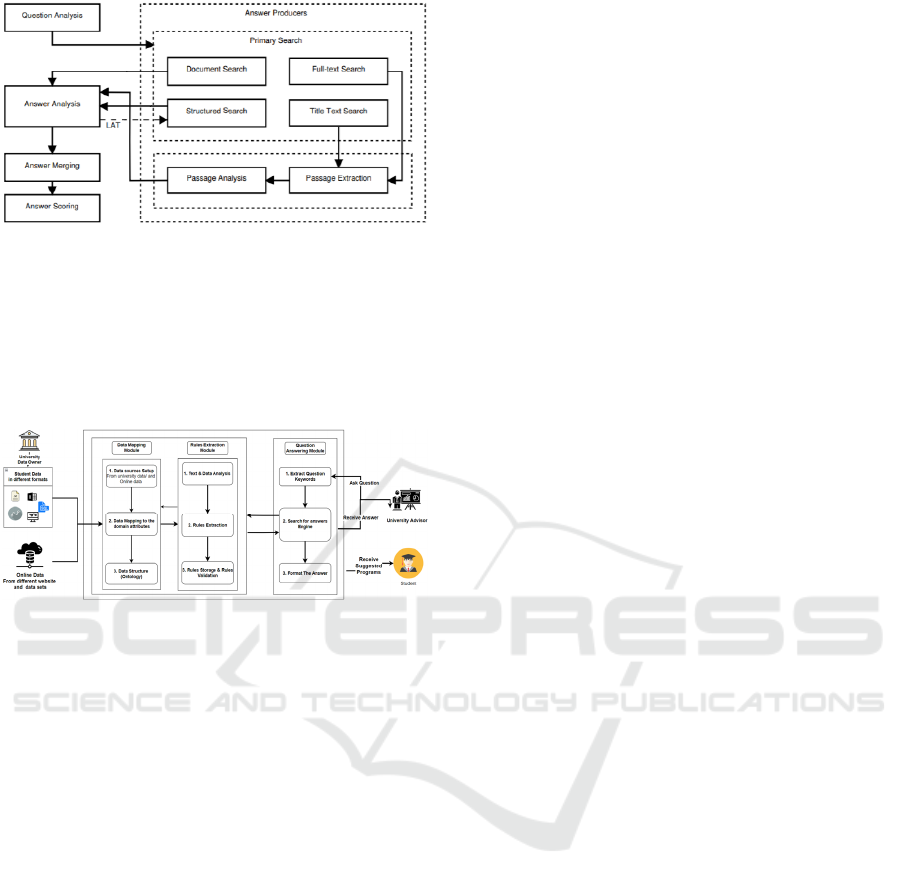
Figure 4: QA process Pipeline.
A Question Answering model by (Elnozahy & El
Khayat, 2019) gathers data from multiple data
sources in the university. The framework is divided
into 3 main sources: the new student data, university
programs data, and their related requirements, and
historical data See figure 5.
Figure 5: Question-answering framework.
Many contributions are made inside and outside
the education sector, however, in this paper we will
focus on the handling inside the educational Domain.
Based on a review made in 2021 regarding the
Educational Question answering systems showed the
different aspects and goals of educational systems
which can be summarised in 3 categories.
First, The Students’ Support effect can be
summarised in the following:
● Provide the material of the course to its
students and help them get the material and
study.
● Provide accurate information about the
subjects and the course content.
● Create an interactive environment and
engaging experience that will make the
learning process better.
● Provide answers to Students to help them
through the administrative steps needed.
● Get individual help, especially for specific
cases.
● Also create a personalized experience for the
student to make the learning process fun.
● Provide advisory roles for students and help
them make academic decisions for their
programs or activities.
Second, the Professors' Support can be stated in
the following:
● Allow professors to understand the students
more.
● Forecast the student's behavior by Modelling
his learning style.
● Provide student profiles for the professors
based on the personalized learning process.
● Help the Professor assess the student's
progress.
● Enables teachers to analyze and assess a
student’s learning ability (Durall & Kapros,
2020; Ndukwe et al., 2019; Sreelakshmi et al.,
2019)
Lastly, Management Support which contains the
least number of contributions which can be
summarised in
● Help in determining whether to accept or
reject the student’s admission (Elnozahy et al.,
2019).
● Reduce the frequent static work
[administrative tasks] that require lots of time
(Hien et al., 2018; Ho et al., 2019; Ranoliya et
al., 2017).
When investigating the different languages of the
Question answering system, we found that most of the
resources available and datasets are mostly in
English. There has been a lot of work on translating
English QA datasets to Arabic (Mozannar et al.,
2019). This research was an open-domain QA based
on the Wikipedia article. It considered translating
using the Stanford Question Answering Dataset
(Arabic-SQuAD). It’s common based on the
literature to use the translation when having multiple
data sources with a different language than the user
language. This approach is useful considering the
great development of NLP techniques and their
accuracy (Bensalah et al., 2022) also (Tahsin
Mayeesha et al., 2021) the contribution was using
(SQuAD) data but is translated into the Bengali
language. the contribution made by (Artetxe et al.,
2020) showed that the translation of datasets and
artifacts would produce new knowledge. Many
Bilingual and Cross-lingual QAs were created based
on this Idea which helped overcome many issues.
Multi-Lang Question Answering Framework for Decision Support in Educational Institutes
431
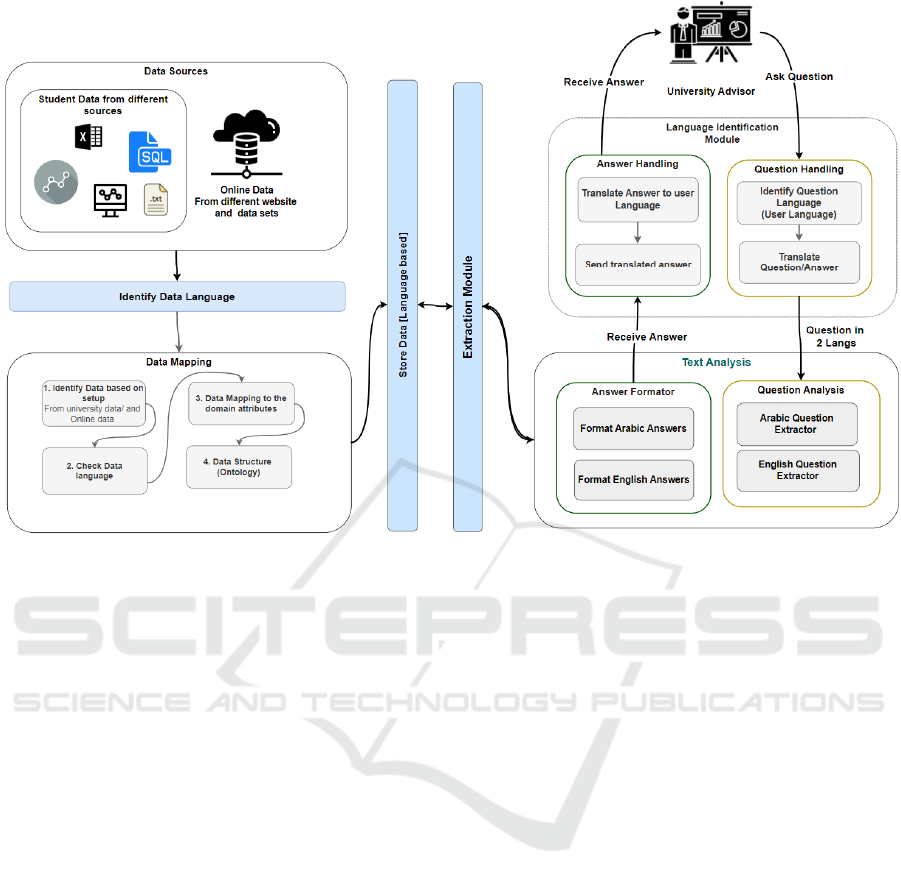
Figure 6: Multi-Lang Question Answering System.
3 PROPOSED
MULTI-LANGUAGE
QUESTION ANSWERING
FRAMEWORK
Initially, the proposal here is an enhancement of the
previous work done in (Elnozahy & El Khayat, 2019)
and (Elnozahy &El Khayat, 2022). These papers
proposed a university framework that supports
decision-makers in determining the suitable students
for a specific university program. It gives a
recommendation based on program requirements and
student competencies.
The Framework as stated before is for universities
to help identify the most appropriate students’
profiles for different programs. the identification is
done through textual data analysis from university
data, open source data, and student activities data.
These data can be the students’ expressions about
what they would like to do in their future careers for
example. It will be gathered when the student applies
to the university program through the system used. In
the following sections, we are going to start with
defining the proposed solution components and
Overall structure, then provide the system analysis
and technical structure diagrams that will help us with
the implementation later.
The proposed solution was limited to one
language, then proposed an extension to two
languages. The proposal had limitations in terms of
language. Especially with the different types and
dialects of the data. Which contains Arabic, English,
and French. Which makes supporting just one
language or a cross-lingual enough. The proposed
solution is based on language detection and
translation ability integrated with the extract module.
The framework shown in figure 6 behaves as the
following:
First, in terms of data Saving and Identifying
● Data sources are configurable and can contain
multiple sources with different types and
extensions.
● Once configured a language detector runs. To
identify the data source language, and whether
it’s just one or multiple languages.
● Once detected, the system relates the data to
domain attributes and maps it to the ontology.
● Once all is done, data is saved based on the
language in the data store.
EKM 2023 - 6th Special Session on Educational Knowledge Management
432

Second, the Question processing module
● Starts with users asking questions.
● System identifies question language.
● System analyses the question based on the
language.
● Once done we move to the extraction module.
Third, the Extraction module, this part starts with:
● Identify the available language in the system
ex. [Arabic, English, and French]
● System translates the question to these
languages and starts searching the data store to
get these data.
● Once data is found, the system returns the data
to the next module [forming answers].
Forth, in the Answer formatting module, after
extracting the answer, the system behaves based on
user question language. Get all the data and transform
everything to the user's language then formulate the
final answer.
The proposal is aiming to achieve justice while
selecting and recommending students to the different
programs. The students in our university case are
learning in Arabic, English, and French. we have a
department per each. while the proposed programs
are available to all students if they can achieve
specific levels for the prerequisites. Using the system,
the university administrators will be able to find the
students who are the best fit for this program. as the
system was restricted to English, it caused a lack of
information as it initially ignored all the Arabic and
French data. so instead of doing a custom-made
solution per language. the proposed framework which
mainly depended on back-and-forth translation for
questions & answers. which will make the result free
of the language barrier.
The framework is proposing a university system,
where some administration and setup are required to
define all sources for the data. Then setup and allow
language identification and determine allowed/ needed
languages in the system. Accordingly, the results will
be extracted. System itself is dynamic and domain data
is updated as per the provided data. The ontology
entities can be developed from the analysed data itself
through the Named Entity Recognition NER.
The framework develops a highly generic way to
extract and answer decision-maker questions without
considering the language barrier. In the end, it
provides high-quality results and accurate
information about the data from all of the students’
historical data, current data, and other related
program data.
4 DISCUSSION AND FUTURE
WORK
In this paper we proposed a new attempt to create a
Multi-language Question Answering Framework.
The framework aims to provide a tool to help support
education decision-making in universities and
educational institutions. The proposed solution goal
is to increase the amount of information gathered
from university data by using different languages.
This is a generic framework, so it will adjust if new
data is fed with a new language.
This framework has many challenges that would
be validated and contribute to the results of the
framework such as the language detector works with
multiple languages including Arabic with all its
complexity. The paper considered the complexity of
the translation module and the different nature of the
data inside the system. All are to be applied to the
student’s assignment process for academic programs.
Another challenge is the development of the
language analysis for the data and the question. which
is also called pragma-linguistics analysis. going
deeper with such an analysis will allow the system to
identify deeper meaning for the data and identify the
intentions not just the text itself. which will develop
the system understanding and expressing
methodologies.
A further enhancement would be applied to the
question-answering system to enhance and confirm
the techniques used in translation. Also, the mapping
considers different languages. Validation and testing
are highly considered in this framework as multiple
rounds will be needed before confirming a valid result
which can be confirmed by comparing real-life
examples with the system result which shall be
considered as a further enhancement in the future.
REFERENCES
Abualigah, L., Alfar, H. E., Shehab, M., & Hussein, A. M.
A. (2020a). Sentiment analysis in healthcare: a brief
review. In Recent Advances in NLP: The Case of Arabic
Language, 129-141.
Abualigah, L., Bashabsheh, M. Q., Alabool, H., & Shehab,
M. (2020b). Text summarization: a brief review. In
Recent Advances in NLP: The Case of Arabic
Language, 1-15.
Abumalloh, R. A., Al-Sarhan, H. M., Ibrahim, O., & Abu-
Ulbeh, W. (2016). Arabic part-of-speech tagging. In
Journal of Soft Computing and Decision Support
Systems, 3(2), 45-52.
AbuShawar, B., & Atwell, E. (2016). Usefulness,
localizability, humanness, and language-benefit:
Multi-Lang Question Answering Framework for Decision Support in Educational Institutes
433

additional evaluation criteria for natural language
dialogue systems. In International Journal of Speech
Technology, 19, 373-383.
Al-Abdallah, R. Z., & Al-Taani, A. T. (2019, February).
Arabic text summarization using firefly algorithm. In
2019 amity international conference on artificial
intelligence (AICAI) (pp. 61-65). IEEE.
Alhaj, Y. A., Al-qaness, M. A., Dahou, A., Abd Elaziz, M.,
Zhao, D., & Xiang, J. (2020). Effects of Light
Stemming on Feature Extraction and Selection for
Arabic Documents Classification. In Recent Advances
in NLP: The Case of Arabic Language (pp. 59-79).
Springer, Cham
Alotaiby, F., Alkharashi, I., & Foda, S. (2009). Processing
large Arabic text corpora: Preliminary analysis and
results. In Proceedings of the second international
conference on Arabic language resources and tools
(pp. 78-82).
Alwaneen, T. H., Azmi, A. M., Aboalsamh, H. A., Cambria,
E., & Hussain, A. (2021). Arabic question answering
system: a survey. In Artificial Intelligence Review, 1-
47.
Antoniou, C., & Bassiliades, N. (2022). A survey on
semantic question answering systems. In The
Knowledge Engineering Review, 37.
Artetxe, M., Labaka, G., & Agirre, E. (2020). Translation
artifacts in cross-lingual transfer learning. arXiv
preprint arXiv:2004.04721.
Auer, S., Bizer, C., Kobilarov, G., Lehmann, J., Cyganiak,
R., & Ives, Z. (2007). Dbpedia: A nucleus for a web of
open data. In The semantic web (pp. 722-735).
Springer, Berlin, Heidelberg.
Baudiš, P., & Šedivý, J. (2015, September). Modeling of
the question answering task in the yodaqa system. In
International Conference of the cross-language
evaluation Forum for European languages (pp. 222-
228). Springer, Cham.
Bensalah, N., Ayad, H., Adib, A., & Ibn El Farouk, A.
(2022). CRAN: an hybrid CNN-RNN attention-based
model for Arabic machine translation. In Networking,
Intelligent Systems and Security (pp. 87-102). Springer,
Singapore.
Boudchiche, M., Mazroui, A., Bebah, M. O. A. O.,
Lakhouaja, A., & Boudlal, A. (2017). AlKhalil Morpho
Sys 2: A robust Arabic morpho-syntactic analyzer. In
Journal of King Saud University-Computer and
Information Sciences, 29(2), 141-146.
Bourahouat, G., Abourezq, M., & Daoudi, N. (2023).
Systematic Review of The Arabic Natural Language
Processing: Challenges, Techniques and New Trends.
In Journal of Theoretical and Applied Information
Technology, 101(3).
Buckwalter, T. (2004). Issues in Arabic orthography and
morphology analysis. In proceedings of the workshop
on computational approaches to Arabic script-based
languages (pp. 31-34).
Chang, P. C., Galley, M., & Manning, C. D. (2008, June).
Optimizing Chinese word segmentation for machine
translation performance. In Proceedings of the third
workshop on statistical machine translation (pp. 224-
232).
Chiche, A., & Yitagesu, B. (2022). Part of speech tagging:
a systematic review of deep learning and machine
learning approaches. In Journal of Big Data
, 9(1), 1-25.
Colace, F., De Santo, M., Lombardi, M., Pascale, F.,
Pietrosanto, A., & Lemma, S. (2018). Chatbot for E-
Learning: A Case of Study. In International Journal of
Mechanical Engineering and Robotics Research, 7(5).
Conneau, A., Khandelwal, K., Goyal, N., Chaudhary, V.,
Wenzek, G., Guzmán, F., & Stoyanov, V. (2019).
Unsupervised cross-lingual representation learning at
scale. In arXiv preprint arXiv:1911.02116.
Durall, E., & Kapros, E. (2020, July). Co-design for a
competency self-assessment chatbot and survey in
science education. In International Conference on
Human-Computer Interaction (pp. 13-24). Springer,
Cham.
Dwivedi, S. K., & Singh, V. (2013). Research and reviews
in question answering system. In Procedia Technology,
10, 417-424.
EL-Mohdy, E. M., El-Gamal, A. F., & Abdelkader, H. E.
(2018). Web Mining Techniques to Block Spam Web
Sites. In International Journal of Computer
Applications, 975, 8887.
Elbarougy, R., Behery, G., & El Khatib, A. (2020). A
proposed natural language processing preprocessing
procedures for enhancing arabic text summarization. In
Recent Advances in NLP: The Case of Arabic Language
(pp. 39-57). Springer, Cham.
Elnozahy, W., El Khayat, G. (2022). Arabic/English
Question Answering system to support decision-
making in Education. In proceeding of Alexandria
Pedagogical Innovation and Technology Enhanced
Learning.
Elnozahy, W. A., El Khayat, G. A., Cheniti-Belcadhi, L., &
Said, B. (2019). Question Answering System to
Support University Students’ Orientation, Recruitment
and Retention. In Procedia Computer Science, 164, 56-
63.
Elnozahy, W. A., El Khayat, G. A., (2021). Review on
Question Answering Systems that Support Decision
Making in Education. In Proceedings of ICT in Our
Lives, Digital Inclusion.
Gharib, T. F., Habib, M. B., & Fayed, Z. T. (2009). Arabic
Text Classification Using Support Vector Machines. In
Int. J. Comput. Their Appl., 16(4), 192-199.
Hao, K. (2022, December 29). Everything to know about
Elon Musk’s OpenAI, the maker of ChatGPT.
Augustman,https://www.augustman.com/sg/gear/tech/o
penai-what-to-know-about-the-company-behind-chatgpt
Harrat, S., Meftouh, K., & Smaili, K. (2019). Machine
translation for Arabic dialects (survey). In Information
Processing & Management, 56(2), 262-273.
Hien, H. T., Cuong, P. N., Nam, L. N. H., Nhung, H. L. T.
K., & Thang, L. D. (2018, December). Intelligent
assistants in higher-education environments: the FIT-
EBot, a chatbot for administrative and learning support.
In Proceedings of the ninth international symposium on
EKM 2023 - 6th Special Session on Educational Knowledge Management
434

information and communication technology (pp. 69-
76).
Ho, C. C., Lee, H. L., Lo, W. K., & Lui, K. F. A. (2018,
July). Developing a chatbot for college student
programme advisement. In 2018 International
Symposium on Educational Technology (ISET) (pp. 52-
56). IEEE.
Jin, B., & Kruppa, M. (2023, January 5). Cheating with
ChatGPT: Can an AI chatbot pass AP Lit?. In The Wall
Street Journal, https://www.wsj.com/articles/chatgpt-
creator-openai-is-in-talks-for-tender-offer-that-would-
value-it-at-29-billion-11672949279
Lebedeva, O., & Zaitseva, L. (2014). Question Answering
Systems in Education and their Classifications. In Joint
International Conference on Engineering Education &
International Conference on Information Technology
(pp. 359-366).
Li, H., Mao, H., & Wang, J. (2022). Part-of-Speech
Tagging with Rule-Based Data Preprocessing and
Transformer. In Electronics, 11(1), 56.
Marie-Sainte, S. L., Alalyani, N., Alotaibi, S., Ghouzali, S.,
& Abunadi, I. (2018). Arabic natural language
processing and machine learning-based systems. In
IEEE Access, 7, 7011-7020.
Mozannar, H., Hajal, K. E., Maamary, E., & Hajj, H.
(2019). Neural arabic question answering. In arXiv
preprint arXiv:1906.05394.
Ndukwe, I. G., Daniel, B. K., & Amadi, C. E. (2019, June).
A machine learning grading system using chatbots. In
International Conference on Artificial Intelligence in
Education (pp. 365-368). Springer, Cham
Ojokoh, B., & Adebisi, E. (2018). A review of question
answering systems. In Journal of Web Engineering,
17(8), 717-758.
Okonkwo, C. W., & Ade-Ibijola, A. (2020). Python-Bot: A
Chatbot for Teaching Python Programming. In
Engineering Letters, 29(1).
OpenAI (2022, November 30). ChatGTP: Optimizing
language models for dialogue https://openai.com/
blog/chatgpt/
Pudaruth, S., Boodhoo, K., & Goolbudun, L. (2016,
March). An intelligent question answering system for
ict. In 2016 International Conference on Electrical,
Electronics, and Optimization Techniques (ICEEOT)
(pp. 2895-2899). IEEE.
Ranoliya, B. R., Raghuwanshi, N., & Singh, S. (2017,
September). Chatbot for university related FAQs. In
2017 International Conference on Advances in
Computing, Communications and Informatics
(ICACCI) (pp. 1525-1530). IEEE.
Rudolph, J., Tan, S., & Tan, S. (2023). ChatGPT: Bullshit
spewer or the end of traditional assessments in higher
education?. In Journal of Applied Learning and
Teaching.
Sasikumar, U., & Sindhu, L. (2014). A survey of natural
language question answering system. In International
Journal of Computer Applications, 108(15), 42-46.
Shaalan, K. (2014). A survey of arabic named entity
recognition and classification. In Computational
Linguistics, 40(2), 469-510.
Sreelakshmi, A. S., Abhinaya, S. B., Nair, A., & Nirmala,
S. J. (2019, November). A question answering and quiz
generation chatbot for education. In 2019 Grace
Hopper Celebration India (GHCI) (pp. 1-6). IEEE.
Tahsin Mayeesha, T., Md Sarwar, A., & Rahman, R. M.
(2021). Deep learning based question answering system
in Bengali. In Journal of Information and
Telecommunication, 5(2), 145-178.
Verma, S., & Jain, A. K. (2022). A Survey on Sentiment
Analysis Techniques for Twitter. In Data Mining
Approaches for Big Data and Sentiment Analysis in
Social Media (pp. 57-90). IGI Global.
Yousef, N., Abu-Errub, A., Odeh, A., & Khafajeh, H.
(2014). An improved Arabic word's roots extraction
method using n-gram technique. In Journal of
Computer Science, 10(4), 716.
Zhou, X., Nurkowski, D., Mosbach, S., Akroyd, J., & Kraft,
M. (2021). Question Answering System for Chemistry.
In Journal of Chemical Information and Modeling,
61(8), 3868-3880
Zhu, F., Lei, W., Wang, C., Zheng, J., Poria, S., & Chua, T.
S. (2021). Retrieving and reading: A comprehensive
survey on open-domain question answering. arXiv
preprint arXiv:2101.00774.
Multi-Lang Question Answering Framework for Decision Support in Educational Institutes
435
