
Towards Serendipitous Learning Resource Recommendation
Sahar Sayahi
1
, Leila Ghorbel
1
, Corinne Amel Zayani
1
and Ronan Champagnat
2
1
MIRACL Laboratory, Sfax University, Tunis Road Km 10 BP.242, Sfax, 3021, Tunisia
2
L3i Laboratory, La Rochelle University, Avenue Michel Cr
´
epeau, La Rochelle, 17042, France
Keywords:
Online Learning, Recommender System, Filter Bubble, Educational Dataset, Data Mining, Serendipity
Dimensions.
Abstract:
Since the outbreak of the pandemic, online learning has become widely applied. Indeed, learners follow
Learning Resources (LR) available on different platforms. Therefore, it’s very difficult for learners to choose
LR that matches their needs. They may face disorientation and cognitive overload problems. In fact, multiple
studies have been conducted on Recommender Systems (RS) in order to provide learners with the best LR
that correspond to their needs and complete their training. Unfortunately, these basic RS can lead to an
overly restricted set of suggestions and inadvertently place learners in a so-called “filter bubble”. The latter is
resolved through serendipitous RS, which suggest to learners surprising LR based on serendipity dimensions
such as unexpectedness, novelty and usefulness. In this research paper, we first present our serendipity-
oriented recommendation architecture. Then, we enrich our collected educational dataset with the dimensions
of serendipity. Finally, we evaluate the real learner’s satisfaction on serendipitous LR’s recommendation.
1 INTRODUCTION
Over the past few years, the need for online learning
has increased, especially after the Coronavirus pan-
demic. During the lockdown period, online learn-
ing became a necessity in numerous countries to
continue maintaining the educational process (Her-
mawan, 2021). This learning mode reinforces the im-
portance of enhancing and developing online learn-
ing platforms in several forms: LMS (Learning Man-
agement System), LCMS (Learning Content Man-
agement System) or MOOC (Massive Open Online
Courses) (Vora et al., 2020). These platforms provide
an important number of available LR which can gen-
erate for learners certain problems of disorientation
and cognitive overload (Dien et al., 2022).
RS have emerged as a solution to overcome these
problems. They aim to satisfy the learner through
suggesting the best LR to complete his/her training.
In literature, there are three basic recommendation ap-
proaches (Kundu et al., 2021), namely content-based,
collaborative filtering, and hybrid. These approaches
suffer from the problems of cold start, sparsity and
scalability. In order to overcome the above mentioned
problems, advanced RS have emerged in a wide range
of fields. These systems take into consideration real
users’ social relationships (Troudi et al., 2021) and
use matrix factorisation and deep learning (Guo et al.,
2019; Dien et al., 2022; Zhang et al., 2022). De-
parting from this review, we notified that the major-
ity of basic and advanced RS focus on recommenda-
tions that are very close to the learner’s profile. They
always provide him/her with the same type and con-
tent of resources on the same subject and idea. This
problem is called the filter bubble (Nguyen et al.,
2014), which is resolved by serendipity-oriented RS.
The latter suggest to learners surprising LR based on
serendipity dimensions.
The most important problem of serendipitous RS
is the lack of public available datasets for evaluation.
In order to overcome this problem, we mainly tackle
the basic principle and specify the steps of the con-
struction of our dataset. The latter must contain di-
mensions explaining the serendipity of LR from the
learner’s perspective.
The rest of this paper is organized as follows. In
section 2, some existing studies about recommender
systems, serendipity, and educational datasets are pre-
sented and discussed. Then, in section 3.2, we give an
overview of our approach. In section 4, we demon-
strate the data processing. In section 5, we identify
the applied algorithms to determine the serendipity
dimensions. In section 6, we describe the evaluation
results. Finally, section 7 concludes the paper and of-
454
Sayahi, S., Ghorbel, L., Zayani, C. and Champagnat, R.
Towards Serendipitous Learning Resource Recommendation.
DOI: 10.5220/0012059800003470
In Proceedings of the 15th International Conference on Computer Supported Education (CSEDU 2023) - Volume 1, pages 454-462
ISBN: 978-989-758-641-5; ISSN: 2184-5026
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)

fers certain prospects for future works.
2 STATE OF THE ART
In this section, an overview about RS, serendipity and
the faced challenges is displayed followed by a de-
tailed synthesis.
2.1 Recommender Systems, Serendipity
and Challenges
RS have emerged in online learning to enhance
the quality of learning process and make it easier.
They both help and motivate learners to more ac-
curately learn and improve their academic perfor-
mance through suggesting items (Learning resources:
courses activities, videos, ...) that correspond to their
needs (Fraihat and Shambour, 2015).
Based on an in-depth study, we inferred that RS (Dien
et al., 2022; Guo et al., 2019; Troudi et al., 2021),
in different fields including online learning, focus on
items (courses, movies, jobs, etc.) that are very close
to the user’s (learner’s) profile. In (Zhang et al., 2022;
Guo et al., 2022), authors developed a session-based
recommendation approach which takes into account
the dependency between items and user’s behaviour.
These works aim to capture the sequential dependen-
cies between items within the current session.
The above mentioned approaches always provide
users with the same type and content of items having
the same subject and idea. This problem is called the
filter bubble (Nguyen et al., 2014; Pardos and Jiang,
2020) which is resolved by a serendipity-oriented RS.
The latter helps the user find a surprisingly interest-
ing item that he/she might not have otherwise dis-
covered (or it would have been really hard to dis-
cover) (Kaminskas and Bridge, 2016; Pardos and
Jiang, 2020).
Serendipity is a complicated and interesting con-
cept for research. The major source of complexity and
ambiguity of this concept resides in the fact that it is
in association with emotion (Ziarani and Ravanmehr,
2021b). As a result, defining serendipity in RS is a
challenging problem.
In order to properly interpret user’s emotion to-
wards items, there are several serendipity dimen-
sions that are determined in different research studies
(Kotkov et al., 2020; Ziarani and Ravanmehr, 2021b;
Zhang et al., 2021). These dimensions can be mea-
sured in terms of item usefulness, novelty and un-
expectedness. Items with these dimensions are very
rare, making it hard to present serendipitous rec-
ommendations (Ziarani and Ravanmehr, 2021a; Li
et al., 2019). For this reason, the majority of the re-
search works that tackle the serendipity in recommen-
dation have faced numerous challenges. Authors in
(Ziarani and Ravanmehr, 2021b) stated different chal-
lenges, among which we can mention ambiguity in
serendipity definition, methods for serendipity evalu-
ation, emotional aspect and the lack of public datasets
for serendipity.
In this paper, we address the two last challenges.
The first concerns emotional aspects of serendipitous
recommendations, which is always very subjective
and imprecise, contributing to the difficulty of find-
ing them. The second challenge relates to lack of
public datasets for serendipity, and specially educa-
tional public datasets. In fact, the majority of avail-
able datasets that contain especially serendidpty label
are related to movie recommendation
1
. Additionally,
the avalability of general RS datasets such as Movie-
Lens
2
, OpenStreetMap
3
and Jester
4
help researchers
perform works that deal with serendipitous recom-
mendations .
In the current work, we are basically interested
in online learning domain where research works
are based on RS for Technology Enhanced Learn-
ing (TEL). From this perspective, before presenting
the serendipity recommendation approaches, we have
studied the most prominent datasets used in this do-
main for different purposes (Educational Data Min-
ing, Process Mining, etc.).
2.2 Educational Datasets
In literature, there are three types of data sources that
represent the public available datasets in educational
domain (Mihaescu and Popescu, 2021). The first
type consists of general-purpose repositories where
educational datasets are uploaded such as UCI ML
5
,
Mendeley
6
and Harvard Dataverse
7
data repositories.
The second type of Datasets used in competitions
stands for a category that became very popular in the
last years. These datasets are invested to speed up
the comparative analysis of proposed solutions com-
pared to the solution of other competitors. The third
type corresponds to standalone datasets. The dataset
maintenance, the proposed solution and the results are
1
https://grouplens.org/datasets/serendipity-2018/
2
https://grouplens.org/datasets/movielens/
3
https://www.openstreetmap.org/map=6/33.971/9.562
4
https://eigentaste.berkeley.edu/dataset/
5
UCI Machine Learning Repository,
https://archive.ics.uci.edu/ml/index.php
6
Mendeley Data Repository,
https://data.mendeley.com/
7
Harvard Dataverse, https://dataverse.harvard.edu/
Towards Serendipitous Learning Resource Recommendation
455

at the disposal of the author.
Data represented in these datasets are collected af-
ter the analysis of resources and learners’ data in order
to improve their learning experience and skills.
After checking the content of these datasets, we
realized that they differ a lot in their structure, their
recorded features which are useful uniquely for a spe-
cific purpose and their usefulness in terms of citations,
practical uses and approaches. Furthermore, we no-
tice that most of data are encrypted.
Although these datasets have been used for a long
time and are among the most referenced ones, we find
it difficult to find some of them as they are cited but
not publicly available. Consequently, we are unmoti-
vated to use them in our work and even in our future
academic research.
For this reason, we opted for elaborating our
dataset.
Table 1 exhibits some educational datasets and
their main features.
2.3 Synthesis
Owing to the importance of RS, various works have
been developed in this context. However, in view of
the complexity and variety of challenges, RS for on-
line learning have not been yet well elaborated, where
most researchers use basic RS. As far as our research
is concerned, we seek to make serendipitous recom-
mendations. Therefore, we discuss approaches that
invest serendipity for RS. These approaches display
various basic shortcomings.
The first shortcoming is related to the dimensions
of serendipity in the recommendation (unexpected-
ness, novelty, usefulness, etc.) to achieve serendip-
ity. We notice that some works are confused in terms
of using one or two features (Ziarani and Ravanmehr,
2021a; Zhang et al., 2021; Li et al., 2019; Kaminskas
and Bridge, 2016; Pardos and Jiang, 2020).
The second shortcoming resides in the fact that the
majority of works that are concerned with serendipity
do not take into account user’s behavior and the emo-
tional aspect (Ziarani and Ravanmehr, 2021a; Zhang
et al., 2021; Kaminskas and Bridge, 2016).
Finally, it is noteworthy that almost all RS re-
search studies are about movies or music (Ziarani and
Ravanmehr, 2021a; Zhang et al., 2021; Li et al., 2019;
Kaminskas and Bridge, 2016).
From this perspective, in order to overcome these
limitations, we set forward our approach for LR rec-
ommendation based on serendipity dimensions. The
basic merit of this approach lies in extracting a spe-
cific educational dataset and determining the dimen-
sions of serendipity.
Figure 1: Motivated scenario.
3 OVERVIEW OF THE
PROPOSED APPROACH
In order to introduce our proposed approach, we
demonstrate the basic objectives to achieve serendipi-
tous LR recommendation by a scenario in section 3.1.
Then, we identify the proposed architecture in section
3.2.
3.1 Motivating Scenario
In this part, we exhibit a motivating scenario to clar-
ify the basic purpose of the proposed approach that
relates to the importance of serendipity-oriented rec-
ommender systems for online learning. In figure 1,
We consider a student “Ali” who wants to accumu-
late knowledge and skills associated with his interests.
Therefore, at the first step, he subscribes to the Moo-
dle Learning Management System (LMS) provided
by his school. Then, he follows the existing courses
in Moodle delivered by his teachers (1). In order to
enhance the education level, researchers include a ba-
sic recommender system based to the learner pref-
erence (2). Unfortunately, using this type of rec-
ommender systems makes the provided courses very
similar to Ali’s profile. In fact, Ali’s profile con-
tains the school’s courses, which will make him feel
so bored and less motivated to learn more. For this
reason, there is a real need to add “Serendipitous
Courses” in the Moodle platform to make Ali more
motivated and enable him to accumulate further new
information. Therefore, the idea is to enhance the rec-
ommender system in Moodle by adding the serendip-
ity aspect. In this case, Ali will receive serendipitous
courses (3), which will offer him the possibility to im-
prove his skills and capacities with useful, unexpected
and novel courses. Thus, based on our solution, Ali
would feel very satisfied.
EKM 2023 - 6th Special Session on Educational Knowledge Management
456
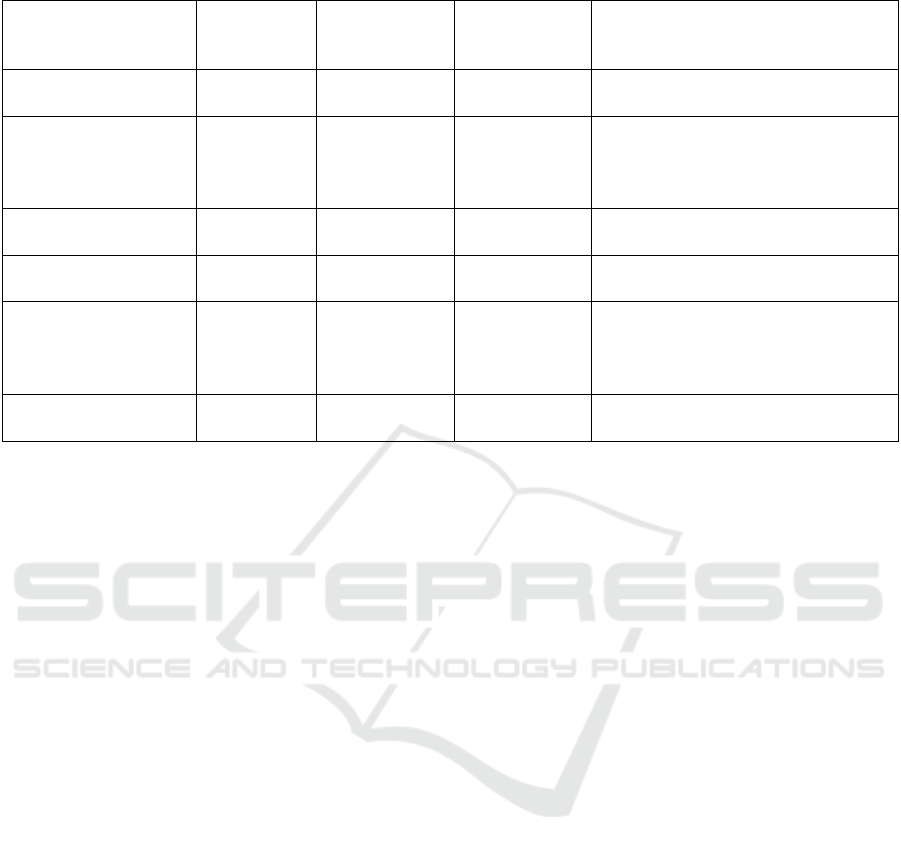
Table 1: Educational Datasets.
Datasets Repository Nb of cita-
tions
(nb of in-
stances, nb of
features)
Purposes
Student Performance
Dataset
1
2014
UCI ML 394 (649,30) Prediction of students’ grade
Educational Process
Mining Dataset
(EPM)
2
2015
UCI ML 42 (230318,13) Predicting learning difficulties, ana-
lyzing structured learning behavior
or discovering student behavior pat-
terns
Video Game Learn-
ing Analytics
3
2020
Harvard
Dataverse
(331,25) Early Reading and Writing Assess-
ment in Preschool
RecSysTEL Datatel
Challenge
4
2010
Competition not mentioned not mentioned Technology Enhanced Learning
EdNet: A Large-
Scale Hierarchical
Dataset in Educatio
5
2020
Competition not mentioned 780 K users Collect real students’ question-
solving logs
Learn Moodle
August
6
2016
Standalone not mentioned 6119 students Inspire better teaching practices ev-
erywhere
1
Student Performance Data Set, http://archive.ics.uci.edu/ml/datasets/Student+Performance
2
Educational Process Mining (EPM): A Learning Analytics Data Set, https://tinyurl.com/y27yduo3
3
Early Reading and Writing Assessment in Preschool, https://doi.org/10.7910/DVN/V7E9XD
4
RecSysTEL Datatel Challenge 2010, http://adenu.ia.uned.es/workshops/recsystel2010/datatel.htm
5
EdNet competition site, http://ednet-leaderboard.s3-website-ap-northeast-1.amazonaws.com/
6
Learn Moodle August 2016, https://research.moodle.org/158/
3.2 Proposed Architecture to Attend
Serendipitous Recommendations
In order to elaborate a serendipity-oriented RS, we
build up an architecture that can be summarized in
four main layers: Social media, Data extraction,
Serendipity dimension extraction and Recommenda-
tion. Figure 2 illustrates the proposed architecture.
The second and the third layers aim to erect educa-
tional serendipity-oriented data. The Data extraction
layer will be detailed in section 4, and the Serendipity
dimension extraction layer will be detailed in section
5.
The recommendation layer of our architecture will
be addressed in the subsequent work. It aims to build
a RS oriented serendipity using the extracted data.
The algorithm of recommendation takes place at two
stages. The first stage predicts a sequence of k courses
(as LR). The second stage applies the re-ranking of k
predicted courses according to the dimensions of the
serendipity and recommends the course that best ver-
ifies the usefulness, unexpectedness and novelty ac-
cording to the learner’s interests and behavior.
4 DATA EXTRACTION
As mentioned earlier in section 2.2, the available ed-
ucational dataset has several limitations and cannot
cover our requirements to achieve serendipity. For
this reason, we collected our own dataset correspond-
ing to our needs. Our chief target is to gather data in
a legal way via API (Application Program Interface)
provided by diverse social media platforms such as
YouTube and Linked-In. This choice of source di-
versity is enacted basically to have data variety with
different types of LR such as courses represented by
texts, videos, etc.
In our experiment we are confined to extract the data
from YouTube using its available API by “beautiful-
soupe”.
We developed a dataset consisting of three data
tables. The first collected data are named “Course-
Data”, where every course is identified with an ID and
other features as depicted in table 2. CourseData in-
volves information about 2362 courses represented by
9 features: identifier, title, description, type, course
link, number of likes , views and comments as well as
the duration.
The second dataset “LearnerDtata” involves in-
Towards Serendipitous Learning Resource Recommendation
457
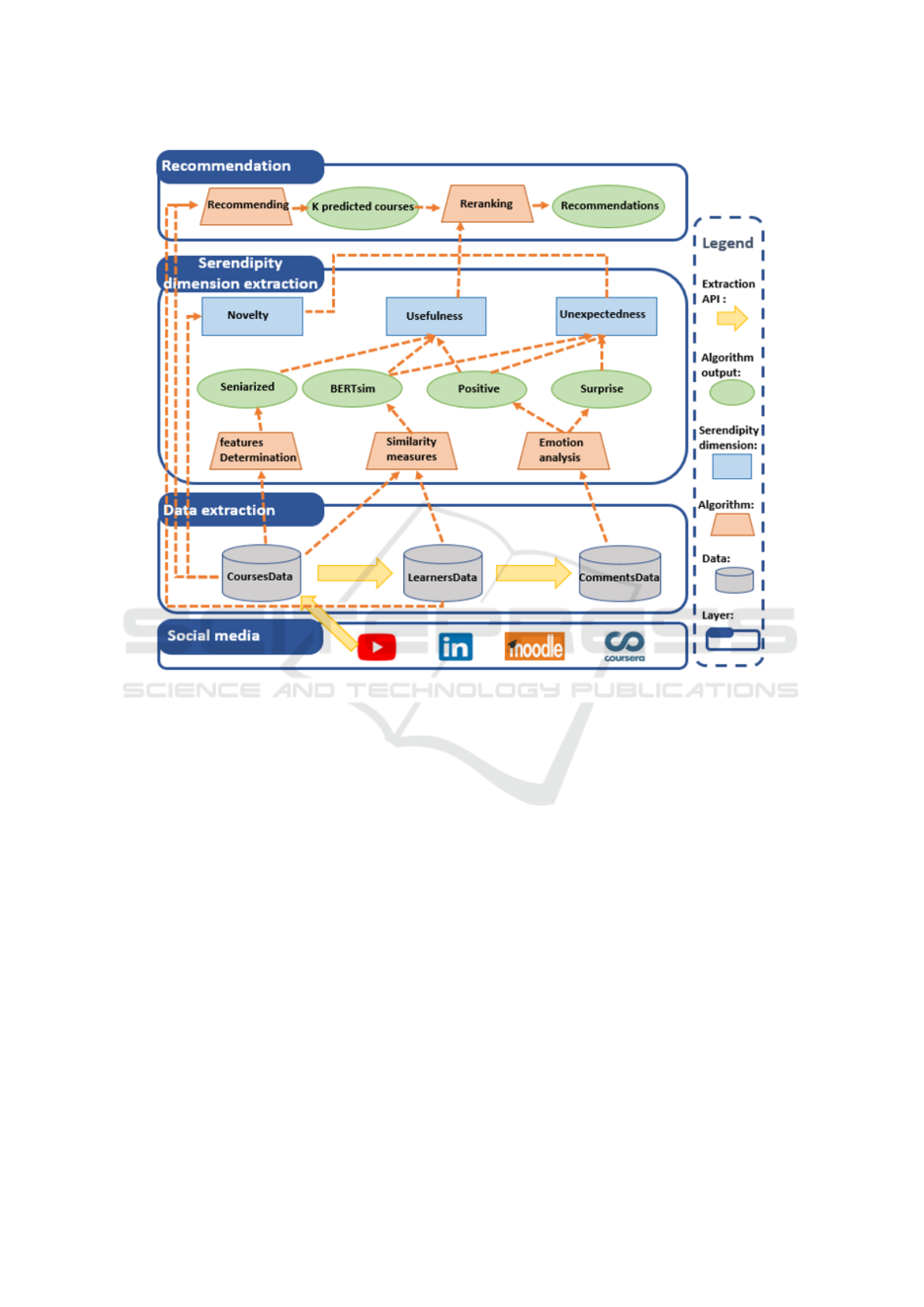
Figure 2: Serendipity-oriented recommendation architecture.
formation about 99394 learners represented by 7 at-
tributes, as plotted in table 3. The learner is identi-
fied with his/her name and linked with the informa-
tion about his/her interactions, some of which charac-
terize his/her behavior.
The extracted data on the learner will be added to
his/her profile.
Once the courses data and learner’s data are
extracted from the Data extraction layer, we
switch to the serendipity dimension extraction layer
(section3.2).
5 SERENDIPITY DIMENSION
EXTRACTION
Notably, the serendipity dimensions that are mostly
used in previous works are novelty, unexpectedness
and usefulness. However, these dimensions are iden-
tified specifically in domains other than online learn-
ing. From this perspective, we determined them
through emotions analysis algorithms and other al-
gorithms to identify attributes to enrich the extracted
data. These dimensions are used in order to provide
serendipitous recommendations.
5.1 Usefulness Dimension
Authors in (Kotkov et al., 2016) defined a useful item
that a user likes, consumes or is interested in. How-
ever, in the educational domain, the usefulness affects
equally the quality of the course. As far as our work
is concerned, we consider that a useful course should
be represented in a pedagogical way and has a pos-
itive impact. Additionally, it should be close to the
learner’s interest. Consequently, we assert that the
usefulness of course can be achieved using the equa-
tion below.
Usefulness = (CoursePedagogy = True)
& (CourseMark = Positive)
& (BERT sim > threshold)
(1)
EKM 2023 - 6th Special Session on Educational Knowledge Management
458

Table 2: CourseData.
Features Description
CourseId Represents the unique ID of
the course
CourseTitle Represents to the title of the
course
CourseDescription Represents the description
of the educational course
content
CourseUrl link of the course.
PublishedDate Represents the date on
which the course is pub-
lished in the form of
time-day-month-year.
ViewsNB Represents the number of
views on the course
LikesNB Represents the number of
learners who likes a course
CommentNB Represents the number of
comments related to the
course
CourseDuration Represents the duration of
the course in terms of hours,
minutes and seconds.
Table 3: LearnerData.
Features Description
LearnerName Name of the learner.
CourseId Id of course followed by a given
learner.
CommentId Id of the comment done by the
user.
CommentURL Comment link, if does not exist,
it will take the value “nan”.
CommentDate Date time-day-month-years,
when the comment is added.
CommentLikes Number of the likes on the com-
ment.
RepliesCount Number of replies on the com-
ment.
where the pedagogy of course is verified by this equa-
tion:
CoursePedagogy = (CourseSeniarization = True)
&(CourseMark = Positive
∥CourseMark = Neutral)
(2)
The learner’s comment describes his/her emotion fac-
ing the given course. For this reason, in our analysis
we used comments on courses as input. We invested
Lexicon-based emotion analysis to classify courses
according to their notices if positive, neutral or nega-
tive. In fact, we used three lexicon-based approaches
(Aljedaani et al., 2022): the TextBlob, VADER and
AFINN. Notably, these approaches provide output
polarity scores to determine learner’s emotion on a
course. Since each model has its own advantages, we
chose to use all the three together so as to increase
the performance of the labeling. Therefore, we ob-
tained three course’s marks outputs, then we applied a
majority algorithm to determine the final course mark
(CourseMark), in order to use it as a feature in the
data set.
Poor LR structure is one of the main factors for
learner dropout. For this reason, we recommend
courses organized in a pedagogical way. Thus, we
set forward a method to determine whether a course
is pedagogical or not. We assumed that a course, in
addition to its mark (positive or negative), needs to be
well organized and divided into sections by time dis-
tribution to be scenarized (CourseSeniarization). In
fact, we used the description of course as the input
of the algorithm that verifies the scenarization. We
have considered that the learner’s interest can be de-
fined by the topic of the taken course. Indeed, the
title of the course generally describes its subject mat-
ter. In order to verify if the given courses are close to
the learner’s interests or not, we implemented a model
that verifies the similarity between the course title and
the sequence of followed courses in the learner’s pro-
file. We used the high performance semantic simi-
larity BERT (Peinelt et al., 2020), and we supposed
that two courses are similar if the result of the model
BERTsim>threshold.
5.2 Unexpectedness Dimension
Unexpectedness is the core of the serendipity in the
recommendation. As defined in (Kotkov et al., 2016),
an unexpected item differs from the profile of the user
regardless of whether it is novel or useful. In our case,
we define that an unexpected course should have a
good mark and make the learner positively surprised.
Further more, it should be different from the learner’s
profile. Therefore, we applied the equation below:
Unexpectedness = (CourseMark = Positive)
& (CourseSur prise = true)
& course ∄ in the Learner
′
s pro f ile
(3)
In order to verify if a course can surprise a learner,
we analyzed the learner’s emotion by implementing a
lexical approach based on an algorithm using a dic-
tionary containing surprising terms. For this analysis,
we took the learner’s comments on this course as an
input to our algorithms.
Towards Serendipitous Learning Resource Recommendation
459

5.3 Novelty Dimension
Novelty refers to the ability of recommending new
and unprecedented recommendations (Ziarani and
Ravanmehr, 2021b). Hence, in order to improve on-
line learning, we need to recommend courses that are
novel for the learner. The novelty of the course can be
expressed according to this equation:
Novelty = (PublishedDate < threshold)
& (LikesNB > avrgLikes)
(4)
A course is considered novel if it is recently published
and has a good feedback from a large number of learn-
ers. The feedback can be likes, comments or shares.
5.4 Data Enrichment with Dimensions
of Serendipity
After applying the previous algorithms based on
serendipity, we added new features that are necessary
for achieving serendipity dimensions. As a result, we
integrated 6 new features to the CourseData, as dis-
played in table 4:
Table 4: Data enrichment.
Features Description
CourseLeghth Refers to the fact whether
the length of the course is
short, medium or long.
CourseSeniarization Stands for the fact whether
the course is scenarized or
not.
CourseType Refers to the type of
course content: text,
video, image or audio.
CourseMark Represents the mark of
the learner on the course
which can be positive,
CoursePedagogy Refers to the educational
pathway of the course
construction, if it is peda-
gogical or not.
6 EVALUATION
Evaluating a recommender system makes it possible
to assess its performance against its objectives. To
evaluate a recommender system, two approaches are
possible, namely an online (user studies) and an of-
fline evaluation.
Figure 3: Learner Satisfaction with recommendations.
6.1 Online Evaluation
In the online evaluation, the recommender system is
tested by real users investing in a real application. It
allows the system not only to generate very reliable
results but also to measure the performance of the ap-
plication in a real-use context. Since the serendipi-
tous recommendations are based on emotional anal-
ysis, it is important to conduct a test on real learners
to measure user satisfaction through explicit ratings.
Users receive the generated recommendations, then
rate them.
In our work, we are proposed that we can achieve
the relevance of recommendation only when it is char-
acterized by the three dimensions of serendipity (cf.
section 5). In order to evaluate our RS (more pre-
cisely the dimensions of serendipity), we conducted
a real test with 100 learners. Then, we test their sat-
isfaction on serendipity. For this reason, we asked
them if they are satisfied with the serendipity of rec-
ommendations or not. The result in figure 3 reveals
that 91,2% of courses are serendipitous. Therefore,
we conclude that the recommendations are relevant.
Afterward, we give a questionnaire from which
we test the satisfaction of learners for each dimen-
sion. We asked the main questions according to the
serendipity dimensions inspired from (Taramigkou
et al., 2013). These questions are outlined in table
5.
Table 5: Real learners based evaluation.
Question Yes No
Do you think this recommendation
is useful for you?
Have you seen these courses be-
fore?
Are you expecting a suggestion
similar to this one?
As reported in figure 4, most of recommended LR
are considered “useful” by (85%), “novel” (70%) and
“unexpected” (67%), which implies that the learners
tried and appreciated the serendipity of the recom-
mendations.
EKM 2023 - 6th Special Session on Educational Knowledge Management
460
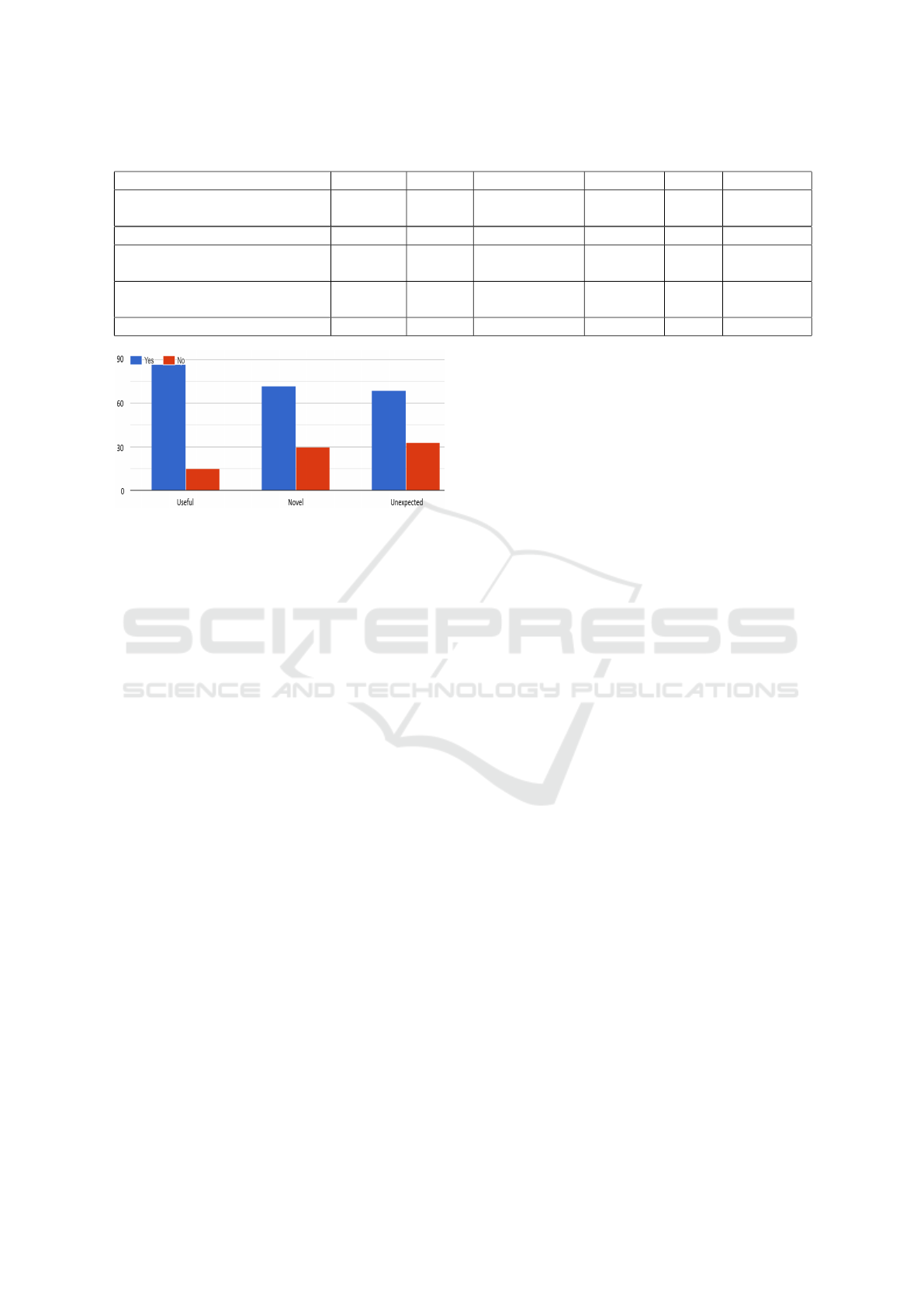
Table 6: Comparison of obtained results based on serendipity dimensions.
Approach/Serendipity measures Usefulness Novelty Unexpectedness Precision Recall F-measure
(Ziarani and Ravanmehr,
2021a)(Zhang et al., 2021)
X 0.67 0.73 0.69
(Li et al., 2019) X 0.85 0.93 0.88
(Kaminskas and Bridge,
2016)
X 0.7 0.76 0.72
(Pardos and Jiang,
2020)(Menk et al., 2017)
X X 0.68 0.75 0.71
Our Approach X X X 0.91 1 0.95
Figure 4: Serendipity dimension satisfaction.
6.2 Offline Evaluation
In order to make the evaluation of the recommender
system more accurate, the offline evaluation is based
on a well-defined mathematical calculation, in which
the values of the precision, recall, and F-measure are
used.
The precision (Pre) determines the probability that
a recommended item is relevant, by dividing the
Number of Relevant Recommendations (NRR) by the
Total Number of Recommendations(TNR)
Pre = NRR/T NR
(5)
The recall (Rec) highlights the Number of Relevant
Recommendations that were returned to the user out
of the Total Number of Relevant Recommendations.
Rec = NRR/T NRR
(6)
The F-measure (F-me) considers both the last two
measures simultaneously and indicates the overall rel-
evance of the list of recommendations.
F-me = (2 ∗ Pre ∗ Rec)/(Pre + Rec)
(7)
In order to study the performance and reliability
of the proposed approach, we have taken into account
the different dimensions of serendipity. We com-
pared our approach with the following state-of-art ap-
proaches in table 6.
From the results of the table, we can observe that
relying only on one or two dimensions of serendip-
ity is somewhat less satisfying with F-measure values
between 0.69 and 0.88. We conclude that using all
three dimensions together gives better results with an
F-measure value of 0.95.
7 CONCLUSION
In this paper, we are basically interested in achieving
serendipitous recommendations of LR. For this rea-
son, we investigated RS as well as serendipity dimen-
sions and challenges. We notice that the most crucial
challenges in this context are the availability of edu-
cational datasets and the determination of serendip-
ity dimensions. First, in order to explain our goal
and method, we presented a motivational scenario and
the architecture of the proposed approach. The latter
consists of four layers: social media, Data extraction,
Serendipity dimension extraction, and Recommenda-
tion. In the data extraction layer, we defined a dataset
describing the learner and the characteristics of the
taken courses from social media. Then, we applied
some algorithms to determine the three serendipity
dimensions: Usefulness, Novelty, and Unexpected-
ness. Indeed, these dimensions allow us to provide
”serendipitous” recommendations.
We undertook an online and offline evaluation for
learners who proved the relevance of serendipitous
recommendations.
In future research work, we will detail the fourth
layer. We aspire to adapt and test the recommenda-
tion layer of the proposed approach in such Learning
Management Systems as Moodle.
ACKNOWLEDGEMENTS
This work was financially supported by the PHC
Utique program of the French Ministry of Foreign
Affairs and Ministry of higher education and re-
search and the Tunisian Ministry of higher education
and scientific research in the CMCU project number
22G1403.
Towards Serendipitous Learning Resource Recommendation
461

REFERENCES
Aljedaani, W., Rustam, F., Mkaouer, M. W., Ghallab, A.,
Rupapara, V., Washington, P. B., Lee, E., and Ashraf,
I. (2022). Sentiment analysis on twitter data inte-
grating textblob and deep learning models: the case
of us airline industry. Knowledge-Based Systems,
255:109780.
Dien, T. T., Thanh-Hai, N., and Thai-Nghe, N. (2022). An
approach for learning resource recommendation using
deep matrix factorization. Journal of Information and
Telecommunication, 6(4):1–18.
Fraihat, S. and Shambour, Q. (2015). A framework of se-
mantic recommender system for e-learning. Journal
of Software, 10(3):317–330.
Guo, J., Ji, W., Yuan, J., and Wang, X. (2022). Multi-
channel orthogonal decomposition attention network
for sequential recommendation. In Pacific-Asia Con-
ference on Knowledge Discovery and Data Mining,
pages 288–300. Springer.
Guo, T., Wen, Y., Wang, F., and Hou, J. (2019). Learning re-
source recommendation based on generalized matrix
factorization and long short-term memory model. In
2019 IEEE International Conference on Cloud Com-
puting Technology and Science (CloudCom), pages
217–222. IEEE.
Hermawan, D. (2021). The rise of e-learning in covid-19
pandemic in private university: challenges and oppor-
tunities. IJORER: International Journal of Recent Ed-
ucational Research, 2(1):86–95.
Kaminskas, M. and Bridge, D. (2016). Diversity, serendip-
ity, novelty, and coverage: a survey and empiri-
cal analysis of beyond-accuracy objectives in recom-
mender systems. ACM Transactions on Interactive In-
telligent Systems (TiiS), 7(1):1–42.
Kotkov, D., Veijalainen, J., and Wang, S. (2020). How does
serendipity affect diversity in recommender systems?
a serendipity-oriented greedy algorithm. Computing,
102(2):393–411.
Kotkov, D., Wang, S., and Veijalainen, J. (2016). A survey
of serendipity in recommender systems. Knowledge-
Based Systems, 111:180–192.
Kundu, S. S., Sarkar, D., Jana, P., and Kole, D. K. (2021).
Personalization in education using recommendation
system: An overview. Computational Intelligence in
Digital Pedagogy, pages 85–111.
Li, X., Jiang, W., Chen, W., Wu, J., and Wang, G. (2019).
Haes: A new hybrid approach for movie recommen-
dation with elastic serendipity. In Proceedings of the
28th ACM International Conference on Information
and Knowledge Management, pages 1503–1512.
Menk, A., Sebastia, L., and Ferreira, R. (2017). Cu-
rumim: A serendipitous recommender system for
tourism based on human curiosity. In 2017 IEEE 29th
International Conference on Tools with Artificial In-
telligence (ICTAI), pages 788–795. IEEE.
Mihaescu, M. C. and Popescu, P. S. (2021). Review on
publicly available datasets for educational data min-
ing. Wiley Interdisciplinary Reviews: Data Mining
and Knowledge Discovery, 11(3):e1403.
Nguyen, T. T., Hui, P.-M., Harper, F. M., Terveen, L., and
Konstan, J. A. (2014). Exploring the filter bubble: the
effect of using recommender systems on content di-
versity. In Proceedings of the 23rd international con-
ference on World wide web, pages 677–686.
Pardos, Z. A. and Jiang, W. (2020). Designing for serendip-
ity in a university course recommendation system. In
Proceedings of the tenth international conference on
learning analytics & knowledge, pages 350–359.
Peinelt, N., Nguyen, D., and Liakata, M. (2020). tbert:
Topic models and bert joining forces for semantic sim-
ilarity detection. In Proceedings of the 58th annual
meeting of the association for computational linguis-
tics, pages 7047–7055.
Taramigkou, M., Bothos, E., Christidis, K., Apostolou, D.,
and Mentzas, G. (2013). Escape the bubble: Guided
exploration of music preferences for serendipity and
novelty. In Proceedings of the 7th ACM conference on
Recommender systems, pages 335–338.
Troudi, A., Ghorbel, L., Amel Zayani, C., Jamoussi, S., and
Amous, I. (2021). Mder: Multi-dimensional event rec-
ommendation in social media context. The Computer
Journal, 64(3):369–382.
Vora, M., Barvaliya, H., Balar, P., and Jagtap, N. (2020).
E-learning systems and moocs-a review. Int. J. Res.
Appl. Sci. Eng. Technol, 8(9):636–641.
Zhang, M., Yang, Y., Abbas, R., Deng, K., Li, J., and Zhang,
B. (2021). Snpr: A serendipity-oriented next poi rec-
ommendation model. In Proceedings of the 30th ACM
International Conference on Information & Knowl-
edge Management, pages 2568–2577.
Zhang, Q., Wang, S., Lu, W., Feng, C., Peng, X., and
Wang, Q. (2022). Rethinking adjacent dependency in
session-based recommendations. In Pacific-Asia Con-
ference on Knowledge Discovery and Data Mining,
pages 301–313. Springer.
Ziarani, R. J. and Ravanmehr, R. (2021a). Deep neural
network approach for a serendipity-oriented recom-
mendation system. Expert Systems with Applications,
185:115660.
Ziarani, R. J. and Ravanmehr, R. (2021b). Serendipity
in recommender systems: a systematic literature re-
view. Journal of Computer Science and Technology,
36(2):375–396.
EKM 2023 - 6th Special Session on Educational Knowledge Management
462
