
QTrail-DB: A Query Processing Engine for Imperfect Databases with
Evolving Qualities
Maha Asiri and Mohamed Y. Eltabakh
Computer Science Department, Worcester Polytechnic Institute (WPI), MA, U.S.A.
Keywords:
Imperfect Database, Data’s Quality, Quality Propagation, Query Optimization.
Abstract:
Imperfect databases are very common in many applications due to various reasons ranging from data-entry
errors, transmission errors, and wrong instruments’ readings, to faulty experimental setups leading to incorrect
results. The management and query processing of imperfect databases is a very challenging problem requires
incorporating the data’s qualities within the database engine. Even more challenging, the qualities are not
static and may evolve over time. Unfortunately, most of the state-of-art techniques deal with the data quality
problem as an offline task. In this paper, we propose the “QTrail-DB” system that introduces a new quality
model based on the new concept of “Quality Trails”, which captures the evolution of the data’s qualities
over time. QTrail-DB extends the relational data model to incorporate the quality trails within the database
system. We propose a new query algebra, called “QTrail Algebra”, that enables transparent propagation and
derivations of the data’s qualities within a query pipeline. QTrail-DB is developed within PostgreSQL and
experimentally evaluated using real-world datasets to demonstrate its efficiency and practicality.
1 INTRODUCTION
In most modern applications it is almost a fact that
the working databases may not be perfect and may
contain low-quality data records (Batini and Scanna-
pieco, 2006; Rahm and Do, 2016). The presence of
such low-quality data is due to many reasons includ-
ing missing or wrong values, redundant information,
human errors, or network transmission errors. A sci-
ence survey has revealed that 80.3% of the partici-
pant research and scientific groups have admitted that
their working databases contain records of low qual-
ity, which puts their analysis and explorations at risk
(Twombly, 2011). Moreover, a recent IBM report
found that the cost of Poor Data Quality for the US
Economy around $3 trillion per year. This includes
direct costs as well as indirect costs (IBM, 2021).
Even more challenging, the qualities of the data
tuples are typically not static, they may change over
time (evolve) depending on various events taking
place in the database. The emerging scientific ap-
plications are excellent examples in which tracking
and maintaining the data’s qualities is of utmost im-
portance. For example, Figure 1 illustrates a possible
sequence of operations that may take place in biolog-
ical databases. First, a data tuple r (e.g., a gene tuple)
can be imported from an external source to the local
ID Name Seq
JW0335 lacZ … ATGAGG…
…
JW4778 cyaA … TTGTAC…
(b) Annotation-driven quality trails capturing the quality history of each record.
Time
E2: New comment
record indicating a
wrong value
E3: Failed comparison
with external Repository
E4: Update event
correcting the
wrong value
E5: New article is
added supporting the
tuple’s content
E1: Insertion
event
Quality Level
t
1
t
2
t
3
t
4
t
5
Auxiliary information attached to each transition, e.g.,
triggering event and other statistics.
…"
…"
…"
…"
…"
To tuple r
in DB
1- Importing tuple r from Source S.
2- A scientist inserting a comment in DB
indicating a possible wrong value in r.
3- Performing a comparison with other
repositories to validate the data. Tuple r
did not match the repository.
4- A scientists updates tuple r and fixes
the error.
5- A scientific articles related to and
supporting r’s content is added to DB.
…"
r’s initial quality depends
on S’s credentials
r’s quality is decreased
r’s quality is decreased
further
r’s quality increases
r’s quality increases
Time Dimension
Figure 1: Database tuples with Evolving Qualities over
Time.
database. At that time, r would be assigned an ini-
tial quality score depending on the source’s credibil-
ity. Then, a scientist may insert a comment highlight-
ing a possible error in the tuple (e.g., the gene’s start
position does not seem correct), based on which r’s
Asiri, M. and Eltabakh, M.
QTrail-DB: A Quer y Processing Engine for Imperfect Databases with Evolving Qualities.
DOI: 10.5220/0012081200003541
In Proceedings of the 12th International Conference on Data Science, Technology and Applications (DATA 2023), pages 295-302
ISBN: 978-989-758-664-4; ISSN: 2184-285X
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
295

quality should be decreased. After a while, a verifica-
tion step that compares the local data with an external
repository may confirm that r contains an incorrect
value, which will further decrease r’s quality. Subse-
quent actions in the database may either increase or
decrease r’s quality over time, e.g., Steps 4 and 5 in
Figure 1, which are an update operation on r (e.g.,
correcting the gene’s start position), and the addition
of a scientific article matching r’s new content, re-
spectively, should both enhance r’s quality. In gen-
eral, each tuple in the database may have its quality
changing over time based on different operations tak-
ing place in the database.
In such imperfect databases with dynamic and
evolving qualities over time, the standard query pro-
cessing that treats all tuples the same while ignoring
their qualities is indeed a very limited approach. For
example, several interesting and challenging ques-
tions may arise beyond the standard data querying,
which include:
1. What was the quality of tuple r before the last re-
vision?
2. Why r’s quality has drastically dropped at time t,
and what did we do to fix that?
3. Given my complex query, e.g., involving selec-
tion, joins, grouping and aggregation, and set op-
erators, what is quality of each output tuple? Can I
trust the results and build further analysis on them
or not?
Certainly, supporting these types of questions is of
critical importance to end-users and high-level appli-
cations. It warrants the need for fundamental changes
in the underlying DBMS. In this paper, we propose
the “QTrail-DB” system, an advanced query pro-
cessing engine for imperfect databases with evolv-
ing qualities. We identify two major tasks to be ad-
dressed, which are:
Task 1−Systematic Modeling of Evolving Quali-
ties: With the large scale of modern databases, even a
very small percentage of low-quality data may trans-
late to a very large number of low-quality records.
This makes it very challenging and time-consuming
process. Therefore, the underlying database engine
must be able to capture and model the data qualities
in a systematic way, and also keep track of their evo-
lution over time (Refer to Questions 1 & 2).
Task 2−Quality Propagation and Assessment of
Query Results: It is a continuous process of col-
lecting and generating data of various degrees of
qualities—with possible interleaving of offline efforts
to verify and fix the imperfect tuples. Therefore, it is
unavoidable to query the data while having tuples of
different qualities. Each tuple r in the output results
should have an inferred and derived quality based on
input tuples contributed to r’s computation (Refer to
Question 3).
QTrail-DB proposes a full integration of the data’s
qualities into all layers of a DBMS. This integra-
tion includes introducing a new quality model that
captures the evolving qualities of each data tuple
over time, called a “Quality Trail” and proposing
a new relational algebra, called “QTrail Algebra”,
that enables seamless and transparent propagation
and derivations of the data’s qualities within a query
pipeline.
The key contributions of this paper are summa-
rized as follows:
• Proposing the “QTrail-DB” system that treats
data’s qualities as an integral component within
relational databases. In contrast to existing re-
lated work, QTrail-DB is the first to quantify
and model the data’s qualities, and fully integrate
them within the data processing cycle. (Section 2)
• Introducing a new quality model based on the new
concept of “quality trails” that captures the evolv-
ing quality history of each data tuple over time
and a new query algebra, called “QTrail Algebra”
that extends the semantics of the standard query
operators to manipulate and propagate the quality
trails.(Section 3 and 4 )
• Developing the QTrail-DB prototype system
within the PostgreSQL engine, and evaluating its
performance using real-world biological datasets.
(Sections 5 and 6)
2 RELATED WORK
Due to its critical importance, data quality has been
extensively studied in literature. The most related to
our work are the following.
Cleaning and Repairing Technique: A main thread
of research is on data cleaning, repairing, and cleans-
ing, where potential low-quality data records are iden-
tified, and then fixed. The underlying techniques in
these system vary significantly from fully-automated
heuristics-based techniques, comparison-based with
external sources and repositories, and rule-driven
techniques, to human-in-the-loop mechanisms. With
the variety of algorithms and techniques for data
cleaning, several extensible and generic frameworks
have been proposed to integrate these algorithms,
e.g., (Dallachiesa et al., 2013). The common theme
in all of these systems is that they all work in total
isolation from query processing.
DATA 2023 - 12th International Conference on Data Science, Technology and Applications
296
Quality Assessment Techniques: On the other hand,
very little attention is given to quality assessment
at query time. It has been addressed in the con-
text of mining operations, sensor data, and relational
databases. The core of these techniques is based
on statistical assumptions about the underlying data.
And then, each technique studies its domain-specific
operations and how they affect the statistical mea-
sures.
A major limitation in these systems is the assumed
statistics may not be available in many applications.
For example, the work in (Ballou et al., 2006)—which
is the most related to QTrail-DB—assume that the
probability of error in each column in the database
is known in advance, which is not the case in many
applications. And even if this knowledge is available,
it a coarse-grained knowledge over an entire column
and not tied to specific tuples.
Uncertain and Probabilistic Databases: Another
big area of research is focusing on uncertain and
probabilistic databases (Galindo et al., 2006; Widom,
2005a). In these systems, a given data value can be
uncertain, and hence it is represented by a possible
set of values, a probability distribution function over
a given range, or a probability of actual presence. In
uncertain databases, the query engine is extended to
operate on these uncertain values and tuples, and en-
force correct semantics (called “possible worlds”).
Although uncertainty is related to data qualities in
some sense, these systems are fundamentally differ-
ent from QTrail-DB since the notion of “quality” is
not part of these systems.
3 QTrail-DB DATA & QUALITY
MODELS
QTrail-DB has an extended data model, where each
data tuple carries a “quality trail” encoding the evolv-
ing quality of this tuple. More formally, for a given
relation R having n data attributes, each data tuple
r ∈R has the schema of: r = ⟨v
1
,v
2
,...,v
n
,Q
r
⟩, where
v
1
,v
2
,...,v
n
are the data values of r, and Q
r
is r’s
quality trail. Q
r
is a vector in the form of Q
r
=
⟨q
1
,q
2
,...,q
z
⟩, where each point q
i
is a quality tran-
sition defined as follows.
Definition 3.1 (Quality Transition). A quality tran-
sition represents a change in a tuple’s quality and
it consists of a 4-ary vector ⟨score, timestamp, trig-
geringEvent, statistics⟩, where “score” is a quality
score ranging between 1 (the lowest quality) and
MaxQuality (the highest quality), “timestamp” is the
time at which the score becomes applicable, “trig-
geringEvent” is a text field describing the event that
ID Name Seq
JW0335 lacZ … ATGAGG…
…
JW4778 cyaA … TTGTAC…
(b) Annotation-driven quality trails capturing the quality history of each record.
Time
E2: New comment
record indicating a
wrong value
E3: Failed comparison
with external Repository
E4: Update event
correcting the
wrong value
E5: New article is
added supporting the
tuple’s content
E1: Insertion
event
Quality Level
t
1
t
2
t
3
t
4
t
5
Auxiliary information attached to each transition, e.g.,
triggering event and other statistics.
…"
…"
…"
…"
…"
To tuple r
in DB
1- Importing tuple r from Source S.
2- A scientist inserting a comment in DB
indicating a possible wrong value in r.
3- Performing a comparison with other
repositories to validate the data. Tuple r
did not match the repository.
4- A scientists updates tuple r and fixes
the error.
5- A scientific articles related to and
supporting r’s content is added to DB.
…"
r’s initial quality depends
on S’s credentials
r’s quality is decreased
r’s quality is decreased
further
r’s quality increases
r’s quality increases
Time Dimension
Figure 2: Example of r’s Quality Trail Corresponding To
Operations in Figure 1.
triggered this quality transition, and “statistics” field
contains various statistics that will be maintained
and updated during query processing.Only “score”,
and “timestamp” are mandatory fields, while “trig-
geringEvent”, and “statistics” are optional fields.
Since r’s quality is evolving over time, the length
of Q
r
’s vector is also increasing over time by the addi-
tion of new transitions (Refer to Figure 2). The qual-
ity trail is formally defined as follows.
Definition 3.2 (Quality Trail). A quality trail of a
given tuple r ∈ R is denoted as Q
r
and is repre-
sented as a vector of quality transitions. The tran-
sitions in Q
r
are chronologically ordered, i.e., for all
i, Q
r
[i].timestamp < Q
r
[i + 1].timestamp. Moreover,
the quality transitins have a stepwise changing pat-
tern, i.e., Q
r
[i] is the valid transition over the time pe-
riod [Q
r
[i].timestamp,Q
r
[i+ 1].timestamp).
Referring to the data tuple r from Figure 1, its cor-
responding quality trail is depicted in Figure 2. With
each of the actions highlighted in Figure 1, r’s quality
trail will change (evolve) from the L.H.S (the inser-
tion time) to the R.H.S (the current time). Each point
in the quality trail is a quality transition. For example,
at time t
4
, a new quality transition is added to the trail
consisting of: ⟨4,t
4
,“updating a wrong value”, {...}⟩.
This transition remains valid (the most recent one) un-
til time t
5
when a new transition is added. The statis-
tics field and its usage will be discussed in more detail
in Section 4.
4 QUALITY PROPAGATION AND
ASSESSMENT OF QUERY
RESULTS
In this section, we present the extended query pro-
cessing engine of QTrail-DB for propagating the qual-
ity trails within a query plan. We propose a new SQL
QTrail-DB: A Query Processing Engine for Imperfect Databases with Evolving Qualities
297

Merge Operator Ω(Q
1
,Q
2
,…,Q
n
)
Output:
- Quality trail Q
o
! Initially has no transitions
1. Position a sweep line L to the left-most transition in Q
1
,Q
2
,…,Q
n
2. While (more transitions are available) Do
3. Move L right to the next transition at time t
4. S={s
1
, s
2
, …, s
n
} ! Set of active transitions at t from Q
1
,Q
2
,…,Q
n
5. s
out
! A new output transition
6. s
out
.score = Min( S.s
i
.score ), 1 ≤ i ≤ n
7. s
out
.timestamp = t
8. s
out
.statistics = StatsCombine(S.s
i
.statistics), 1 ≤ i ≤ n
9. s
out
.triggeringEvent = Null
10. Q
o
.addTransition(s
out
)
11. End While
12. Return Q
o
Order Operator χ(Q
1
,Q
2
,…,Q
n
)
Output:
sortedList: Sorted list of quality trails (Initially empty)
- Call function SortFn(Q
1
,Q
2
,…,Q
n
)
- Return sortedList; // highest quality inserted first.
Function SortFn( S: Set of quality trails )
1. Sort S descending based on the most-recent transition’s score values
2. Divide S into groups having the same score value (still descending).
3. For (each group g in S (in the sorted order)) Loop
4. If (size of g = 1) Then
5. - Output the quality trail in g to sortedList
6. Else
7. For (each quality trail Q
i
in g having no more transitions) Loop
8. - Output Q
i
to sortedList & remove from g
9. End For
10. If (more quality trails exist in g) Then
11. - Trim the current active transition from each quality trail
12. - Recursively call SortFn(g’s quality trails)
13. End If
14. End For
Figure 3: Pseudocode of the Merge Ω Operator.
algebra, called “QTrail Algebra”, in which the stan-
dard query operators have been extended to seam-
lessly manipulate the quality trails associated with
each tuple. In this section, we assume the quality
trails have been created and maintained (The focus of
Section 5), and thus we will focus now on the query-
time propagation.
Fortunately, in the provenance literature, the prop-
agation semantics of the tuples’ lineage is a well stud-
ied problem under the different operators. In spe-
cific, we use the same semantics as in the Trio sys-
tem (Widom, 2005b). Therefore, after each algebraic
transformation, we can track the input tuples con-
tributing to a specific output tuple without the need for
re-inventing the wheel. Yet, the unsolved challenge is
how to translate this knowledge to derivations over
the quality trails?. In the following, we study the se-
mantics of deriving the quality trails of each output
record from its contributing input records.
Selection Operator (σ
p
(R)): The operator applies
data-based selection predicates p over relation R, and
reports the qualifying tuples. Predicates p reference
only the data values v
1
,v
2
,...,v
n
within the tuples.
The extension to the selection operator is straightfor-
ward since the content of the qualifying tuples do not
change, and thus the output quality trails remain un-
changed. The algebraic expression is: σ
p
(R) = {r =
⟨v
1
,v
2
,...,v
n
,Q
r
⟩ ∈ R | p(r) = True}
Projection Operator π
a
1
,a
2
,...,a
n
(R): In QTrail-DB,
the quality trails are at the tuple level, and not tied
to specific attribute(s) within the tuple. Therefore,
the projection operator will not change the quality
of its input tuples. That is: π
a
1
,a
2
,...,a
n
(R) = {r
′
=
⟨a
1
,a
2
,...,a
n
,Q
r
⟩} ∀ r ∈ R.
Merge Operator (Ω(Q
1
,Q
2
,...)): Several of the re-
lational operators, e.g., join, grouping, aggregation,
among others, involve merging multiple input tuples
together to form one output tuple. Therefore, the
corresponding input quality trails may also need to
be merged and combined together. To perform this
merge operation over quality trails, we introduce the
new Merge operator Ω(Q
1
,Q
2
,...). This operator is
not a physical operator, instead it is a logical opera-
tor that executes within other physical operators, e.g.,
join, grouping, and duplicate elimination.
The Merge operator’s logic is presented in Fig-
ure 3, and its functionality is illustrated using the ex-
ample in Figure 4. Assume combining three tuples
r
1
, r
2
, and r
3
having quality trails Q
r1
,Q
r2
, and Q
r3
,
respectively. All quality trails are typically aligned
from the R.H.S (which is the query time Q
t
), i.e., each
quality trial must have a valid transition at time Q
t
.
However, the trails are not necessarily aligned from
the L.H.S since the data tuples may be inserted into
the database at different times (See Figure 4). The
quality trail of the output tuple Q
o
is derived using
a sweep line algorithm over the input quality trails
starting from left to right and jumping over the tran-
sition points as illustrated in Figure 4 (Lines 1-3 in
Figure 3). The basic idea behind the algorithm is that
the quality of the output tuple at any given point in
time t should be the lowest among the qualities of the
contributing tuples at time t.
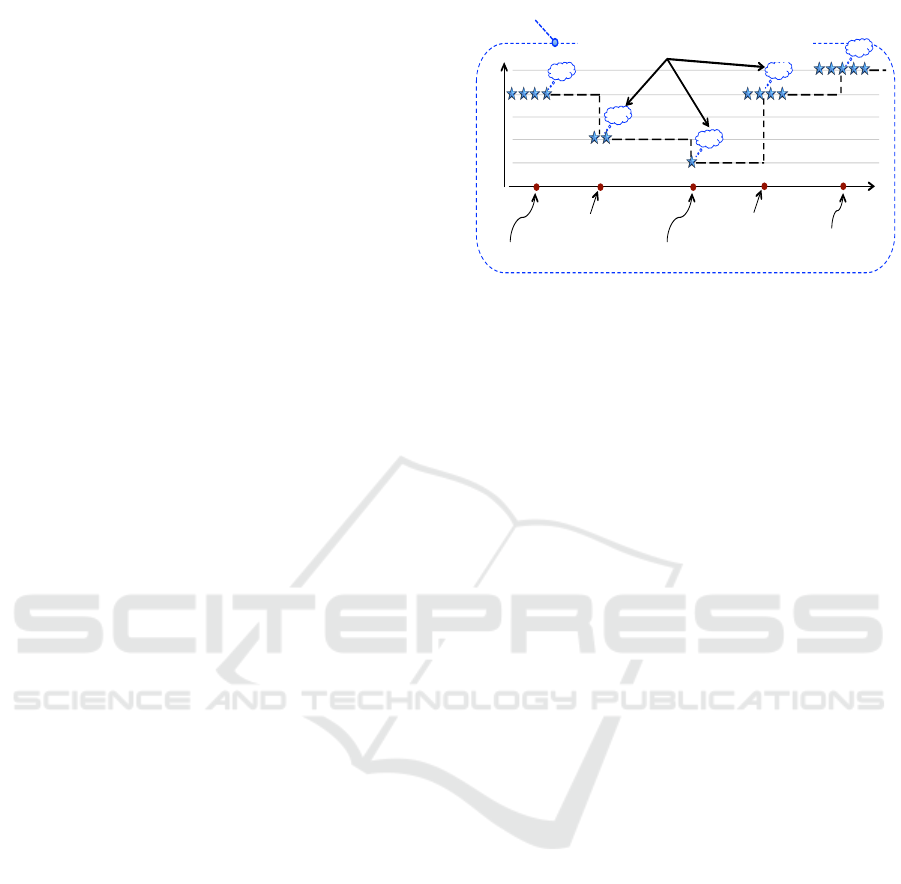
Referring to the example in Figure 4, the sweep
line starts at Position 1, where only Q
r1
exists and
has a quality level 4-star, which will be produced in
the output. The line then jumps to Position 2, where
Q
r3
starts participating with a quality level 3-star, and
hence a 3-star transition will be added to Q
o
. The
sweep line keeps moving to the subsequent positions,
and at each position, it calculates the lowest qual-
ity score among the input participants to be the out-
put’s quality score at this position (Lines 5-7 in Fig-
ure 3). For example, referring to the example in Fig-
ure 4(a), at time t
4
, the contributing input qualities
from Q
r1
,Q
r2
, and Q
r3
, are 2-star, 3-star, and 5-star,
and thus the corresponding quality transition on Q
o
will have a 2-star score.
Although Q
o
’s quality scores reflect only the low-
est score among the input values, the statistics field
associated with each quality transition is intended to
provide deeper insights on the other values contribut-
ing to the score. Initially, the statistics associated with
each quality transition, e.g., Min, Max, Avg, are set to
the transition’s score value as illustrated in Figure 3.
And then, as the transitions get merged, new statis-
tics are computed and get attached to the new quality
transition. For example, the sweep line at Position 6
encounters scores 4-star, 2-star, and 1-star transitions
along with their initial statistics. Notice that Q
r2
’s ac-
tive transition at Position 6 is still the 2-star transition
DATA 2023 - 12th International Conference on Data Science, Technology and Applications
298

Time
Q
t
1
2
4
5
4
3
2
2
1
Query Time
Direction of the sweep line
in the Merge operator
1 2 3 4 5 6 7 8
2
4
2 2
1 1 1
3
ToDo: statistics...distributive and algebraic. Also Q-trails are at the tuple-level, but the include sell-
level annotations...
2.1 Research Task I: Quality Propagation and Assessment of Query Results
In this research task, we address the challenges of assessing the quality of query results under complex
processing and transformations. For example, referring to Figure ??, assume that we have relations R,
S, and T stored in the Quality-Annotated Data repository, which means that each tuple in these relations
already has its quality trail attached to it. It is very common that a single query or workflow on these
relations may involve several of the standard query operators, e.g., selection, projection, join, grouping and
aggregations, and duplicate eliminations, to produce the desired output relation O. The key question that we
address in this task is: What is the quality of each output tuple in O? Notice that our objective is not to just
infer the qualities at the last stage of processing, but to incrementally derive them after each transformation.
Otherwise, other quality-based processing would not be feasible, e.g., applying predicates and functions
on the qualities at any processing stage (Research Task II), and enabling constraints-based processing for
quality maximization (Research Task III). We propose extending the semantics and algebra of the query
operators to seamlessly manipulate the quality trails. All operators—as well as the manipulation functions
over quality trails introduced in Section ??— will consume and produce quality trails conforming to the
data model presented in Section ??. And thus, they can be seamlessly pipelined during processing. In the
following, we highlight the proposed extensions.
•Selection Operator (
p
(R)): The extension to the selection operator is straightforward since this operator
does not modify the quality trails of its input tuples. Therefore, if tuple r =<a
1
,a
2
,....,a
n
, Q > satisfies
the defined predicates p, then r will be produced in the output along with its quality trail Q.
• Merge Operator ((Q
1
, Q
2
)): Several of the relational operators, e.g., join, grouping, and aggregation
involve merging multiple tuples together to form one output tuple, and thus the input quality trails will also
need to be merged/combined together. We introduce the logical merge operator over the quality trails
that works as follows. Assume that tuples r
1
and r
2
in Figure ?? will be merged together, e.g., in a join
or aggregation, then we use a sweep line algorithm over Q
1
and Q
2
from left to right that jumps over their
transition points.
Q
r1
, Q
r2
, Q
r3
2.2 Research Task II:
2.3 Research Task III:
2.4 Research Task IV:
2.5 Research Task V:
2.6 Research Task VI:
6
ToDo: statistics...distributive and algebraic. Also Q-trails are at the tuple-level, but the include sell-
level annotations...
2.1 Research Task I: Quality Propagation and Assessment of Query Results
In this research task, we address the challenges of assessing the quality of query results under complex
processing and transformations. For example, referring to Figure ??, assume that we have relations R,
S, and T stored in the Quality-Annotated Data repository, which means that each tuple in these relations
already has its quality trail attached to it. It is very common that a single query or workflow on these
relations may involve several of the standard query operators, e.g., selection, projection, join, grouping and
aggregations, and duplicate eliminations, to produce the desired output relation O. The key question that we
address in this task is: What is the quality of each output tuple in O? Notice that our objective is not to just
infer the qualities at the last stage of processing, but to incrementally derive them after each transformation.
Otherwise, other quality-based processing would not be feasible, e.g., applying predicates and functions
on the qualities at any processing stage (Research Task II), and enabling constraints-based processing for
quality maximization (Research Task III). We propose extending the semantics and algebra of the query
operators to seamlessly manipulate the quality trails. All operators—as well as the manipulation functions
over quality trails introduced in Section ??— will consume and produce quality trails conforming to the
data model presented in Section ??. And thus, they can be seamlessly pipelined during processing. In the
following, we highlight the proposed extensions.
•Selection Operator (
p
(R)): The extension to the selection operator is straightforward since this operator
does not modify the quality trails of its input tuples. Therefore, if tuple r =<a
1
,a
2
,....,a
n
, Q > satisfies
the defined predicates p, then r will be produced in the output along with its quality trail Q.
• Merge Operator ((Q
1
, Q
2
)): Several of the relational operators, e.g., join, grouping, and aggregation
involve merging multiple tuples together to form one output tuple, and thus the input quality trails will also
need to be merged/combined together. We introduce the logical merge operator over the quality trails
that works as follows. Assume that tuples r
1
and r
2
in Figure ?? will be merged together, e.g., in a join
or aggregation, then we use a sweep line algorithm over Q
1
and Q
2
from left to right that jumps over their
transition points.
Q
r1
, Q
r2
, Q
r3
2.2 Research Task II:
2.3 Research Task III:
2.4 Research Task IV:
2.5 Research Task V:
2.6 Research Task VI:
6
ToDo: statistics...distributive and algebraic. Also Q-trails are at the tuple-level, but the include sell-
level annotations...
2.1 Research Task I: Quality Propagation and Assessment of Query Results
In this research task, we address the challenges of assessing the quality of query results under complex
processing and transformations. For example, referring to Figure ??, assume that we have relations R,
S, and T stored in the Quality-Annotated Data repository, which means that each tuple in these relations
already has its quality trail attached to it. It is very common that a single query or workflow on these
relations may involve several of the standard query operators, e.g., selection, projection, join, grouping and
aggregations, and duplicate eliminations, to produce the desired output relation O. The key question that we
address in this task is: What is the quality of each output tuple in O? Notice that our objective is not to just
infer the qualities at the last stage of processing, but to incrementally derive them after each transformation.
Otherwise, other quality-based processing would not be feasible, e.g., applying predicates and functions
on the qualities at any processing stage (Research Task II), and enabling constraints-based processing for
quality maximization (Research Task III). We propose extending the semantics and algebra of the query
operators to seamlessly manipulate the quality trails. All operators—as well as the manipulation functions
over quality trails introduced in Section ??— will consume and produce quality trails conforming to the
data model presented in Section ??. And thus, they can be seamlessly pipelined during processing. In the
following, we highlight the proposed extensions.
•Selection Operator (
p
(R)): The extension to the selection operator is straightforward since this operator
does not modify the quality trails of its input tuples. Therefore, if tuple r =<a
1
,a
2
,....,a
n
, Q > satisfies
the defined predicates p, then r will be produced in the output along with its quality trail Q.
• Merge Operator ((Q
1
, Q
2
)): Several of the relational operators, e.g., join, grouping, and aggregation
involve merging multiple tuples together to form one output tuple, and thus the input quality trails will also
need to be merged/combined together. We introduce the logical merge operator over the quality trails
that works as follows. Assume that tuples r
1
and r
2
in Figure ?? will be merged together, e.g., in a join
or aggregation, then we use a sweep line algorithm over Q
1
and Q
2
from left to right that jumps over their
transition points.
Q
r1
, Q
r2
, Q
r3
2.2 Research Task II:
2.3 Research Task III:
2.4 Research Task IV:
2.5 Research Task V:
2.6 Research Task VI:
6
ToDo: statistics...distributive and algebraic. Also Q-trails are at the tuple-level, but the include sell-
level annotations...
2.1 Research Task I: Quality Propagation and Assessment of Query Results
In this research task, we address the challenges of assessing the quality of query results under complex
processing and transformations. For example, referring to Figure ??, assume that we have relations R,
S, and T stored in the Quality-Annotated Data repository, which means that each tuple in these relations
already has its quality trail attached to it. It is very common that a single query or workflow on these
relations may involve several of the standard query operators, e.g., selection, projection, join, grouping and
aggregations, and duplicate eliminations, to produce the desired output relation O. The key question that we
address in this task is: What is the quality of each output tuple in O? Notice that our objective is not to just
infer the qualities at the last stage of processing, but to incrementally derive them after each transformation.
Otherwise, other quality-based processing would not be feasible, e.g., applying predicates and functions
on the qualities at any processing stage (Research Task II), and enabling constraints-based processing for
quality maximization (Research Task III). We propose extending the semantics and algebra of the query
operators to seamlessly manipulate the quality trails. All operators—as well as the manipulation functions
over quality trails introduced in Section ??— will consume and produce quality trails conforming to the
data model presented in Section ??. And thus, they can be seamlessly pipelined during processing. In the
following, we highlight the proposed extensions.
•Selection Operator (
p
(R)): The extension to the selection operator is straightforward since this operator
does not modify the quality trails of its input tuples. Therefore, if tuple r =<a
1
,a
2
,....,a
n
, Q > satisfies
the defined predicates p, then r will be produced in the output along with its quality trail Q.
• Merge Operator ((Q
1
, Q
2
)): Several of the relational operators, e.g., join, grouping, and aggregation
involve merging multiple tuples together to form one output tuple, and thus the input quality trails will also
need to be merged/combined together. We introduce the logical merge operator over the quality trails
that works as follows. Assume that tuples r
1
and r
2
in Figure ?? will be merged together, e.g., in a join
or aggregation, then we use a sweep line algorithm over Q
1
and Q
2
from left to right that jumps over their
transition points.
Q
r1
, Q
r2
, Q
o
2.2 Research Task II:
2.3 Research Task III:
2.4 Research Task IV:
2.5 Research Task V:
2.6 Research Task VI:
6
3 3
5
2
Min: 1
Max: 1
Avg: 1
Min: 4
Max: 4
Avg: 4
Min: 2
Max: 2
Avg: 2
Min: 1
Max: 4
Avg: 2.3
t
1
t
2
t
3
t
4
t
5
t
6
t
7
t
8
Tuple r1
Tuple r2
Tuple r3
- Q
o
is the result from applying the
Merge operator over the three quality
trails Q
r1
, Q
r2
, Q
r3
. It is built using a
sweep line algorithm moving left-to-
right.
- Each quality transition generated
from the Merge operator has a score
equals the smallest among the
corresponding input transitions.
Moreover, it has statistics computed
by combining the input transitions’
statistics.
Figure 4: Example of the Merge Operator in QTrail-DB.
Function Name Description
QTransition[] getQualityTrail() Returns r’s quality trail as an array of quality
transitions.
Int getSize()
Returns the number of transitions in r’s quality trail
QTransition[] addTransition(QTransition q)
Augments q to the right-most side of r’s quality trail.
The function returns the new extended quality trail.
QTransition[] replaceTransition(Int pos,
QTransition q)
Replaces the quality transition at position pos with the
new transition q. The function returns the new
modified trail.
QTransition[] trim(Char direction, Int num) Trims r’s quality trail and retains only the first num
transitions starting from the L.H.S or R.H.S
(depending on direction). The function returns the
new trimmed trail.
… …
Figure 5: Manipulation Functions on r.QTrail Attribute.
occurred at Position 5 (at time t
5
). These statistics
will be combined by the Merge operator to compute
the new statistics of the Q
o
’s new transition (Line 8 in
Figure 3).
Finally, the newly created transition is added to
the output quality trail (Line 10 in Figure 3).
More operators are presented in details in the full
version of this paper (Author A, 2023).
5 CREATION & MAINTENANCE
OF QUALITY TRAILS
In this section, we present the creation and mainte-
nance mechanisms of the quality trails. Since QTrail-
DB is a generic engine, the goal is to design a set
of APIs that will act as the interface between QTrail-
DB and the external world. More specifically, QTrail-
DB allows the database developers to manipulate the
quality trails as any other attribute in the database.
The quality trails are designed as special attributes
added to the database relations, i.e., each relation
R has an automatically-added special attribute called
“QTrail”. QTrail attribute is of a newly added user-
defined type representing an array of quality transi-
tions (Refer to Definitions 3.1, and 3.2). On top of this
new type, a set of manipulation functions has been de-
veloped as presented in Figure 5. These built-in func-
tions are by no means comprehensive, but they are ba-
sic functions on top of which the database developers
may create more semantic-rich functions.
In Figure 5, we present few of the developed func-
tions including the descriptions of each (more details
available in the paper full version (Author A, 2023)).
In addition to these functions, we have also developed
a set of functions to manipulate a given quality transi-
tion, e.g., building a quality transition, and setting or
retrieving specific fields within a transition
1
.
6 EXPERIMENTS
Setup: QTrail-DB is implemented within the Post-
greSQL DBMS (Stonebraker et al., 1990). A Qual-
ity Trail is modeled as a new data type, i.e., a dy-
namic array of quality transitions. The default stor-
1
Other storage schemes are possible without affecting
the core functionalities of QTrail-DB. Only the implemen-
tation of the APIs may change.
QTrail-DB: A Query Processing Engine for Imperfect Databases with Evolving Qualities
299

age scheme is called “QTrail-Scheme”, in which each
of the users’ relations is automatically augmented
with a new “QTrail” column as presented in Sec-
tion 5. QTrail-DB is experimentally evaluated us-
ing an AMD Opteron Quadputer compute server with
two 16-core AMD CPUs, 128GB memory, and 2 TBs
SATA hard drive. QTrail-DB is compared with the
plain PostgreSQL DBMS to study the overheads as-
sociated with the new functionalities (w.r.t both time
and storage).
Application Datasets: We use a subset of the curated
UniProt real-world biological database (The Univer-
sal Protein Resource Databases, 2023). UniProt offers
a comprehensive repository for protein and functional
information for various species. We extracted four
main tables including Protein, Gene, Publication,
and Comment.
Our dataset consists of approximately 750,000
protein records (≈ 4.7GBs), 1.3 x 10
6
gene records
(≈ 8GBs), 12 x 10
6
publication records (≈ 4.5GBs),
and 8 x 10
6
comment records (≈ 6.5GBs). Thus, the
total size of the dataset is approximately 24GBs.
Workload: We focus on tracking the qualities of the
tuples in the Gene and Protein tables under the ad-
dition of new publications and comments. The qual-
ity score varies between 1 (the lowest quality), and
10 (the highest quality). To build the quality trails,
we implemented an “After Insert” database trigger on
each of the Publication and Comment tables such
that with the insertion of a new publication or com-
ment, the quality of the corresponding gene or pro-
tein will be updated. We assume that the insertion
of a new publication increases the quality (unless the
quality score is already the maximum, in which case
the new quality transition will have the same score as
the previous one). For the comment values, each com-
ment in UniProt has a code indicating the type of this
comment. One of these types is “CAUTION”, which
indicates a possible error or confusion in the data. All
comments having the “CAUTION” type are assumed
to decrease the quality (unless the quality score is al-
ready the minimum, in which case the new quality
transition will have the same score as the previous
one). For the other comment values, we randomly
labeled each one as “+”, “-”, or “∼”, which indicates
increasing, decreasing, or retaining the previous qual-
ity score, respectively
2
.
Unless otherwise is specified, we assume the fol-
lowing: (1) Each increase or decrease in the qual-
ity score is performed one step at a time, i.e., ±1,
and (2) If a quality transition is storing statistics—
2
We used random labeling since developing a free-text
semantic extraction tool (or leveraging an existing tool) is
not the focus of this paper.
Referred to as “Full Transitions”— then three types
of statistics are maintained, which are the {Min, Max,
Avg = (Sum, Count)}. The insertions of the publi-
cation and comment records are randomly interleaved
because the database does not maintain a global
timestamp ordering the records’ creation. When eval-
uating the query performance of QTrail-DB, we com-
pare against the standard query processing in which
the quality trails are not even stored in the database.
Finally, the query optimizer of PostgreSQL has not
been touched or modified, and hence the queries used
in the evaluation are optimized in the standard way.
Storage and Maintenance Evaluation: In Figure 6,
we study the storage overhead introduced by the qual-
ity trails. To put the comparison into perspective,
we compare “QTrail-Scheme” with another alterna-
tive where the quality trails of a given table R are
stored in a separate table R-QTrail (OID, QTrail) that
has one-to-one relationship with R. This scheme is
referred to as “Off-Table Scheme”. We study the stor-
age overheads under the two cases of: (1) Full Tran-
sitions, where each quality transition has content in
all its fields; the mandatory ones (score, and times-
tamp), and optional ones (triggeringEvent, and statis-
tics) (Figure 6(a)). In this case, the triggeringEvent
field is a string of length varying between 50 and 100
bytes. And (2) Minimal Transitions, where each qual-
ity transition has content in only the mandatory fields
(Figure 6(b)).
In each of the two figures, we measure the over-
head under different constraints on the maximum size
of a quality trail (the x-axis). The values Limit-5,
Limit-10, and Unlimited indicate keeping only up to
the last 5, 10, or ∞ transitions. The y-axis shows the
absolute storage overhead, while the percentages in-
side the rectangle boxes show the overhead—more
specifically that of the QTrail-Scheme—as a per-
centage of the sum of Gene and Protein sizes (≈
12.7GBs). As Figures 6(a) and 6(b) show, there is
no big difference between both storage schemes in
all cases. The Off-Table scheme is slightly higher
because of the storage of the unique tuple Id values
(OID column). In general, the quality trails do not in-
troduce much storage overhead even under the worst
case where the entire quality history is stored, e.g.,
the overhead is around 18% (for Full Transitions), and
3.7% (for Minimal Transitions). It is worth highlight-
ing that under the Unlimited case, the longest quality
trail consisted on 37 transitions.
In Figure 7, we study the maintenance overhead
of the quality trails. We consider the Unlimited case
of quality trails. To have fair comparison, we mea-
sure the time of updating a quality trail, e.g., adding
new transitions, w.r.t the time of updating other tra-
DATA 2023 - 12th International Conference on Data Science, Technology and Applications
300

0
100
200
300
400
500
600
0
500
1000
1500
2000
2500
0
0.2
0.4
0.6
0.8
1
1.2
1st Last 1st Last
All Some
4.5%
7.6%
18%
1%
1.8%
Limit-5 Limit-10 Unlimited
Limit-5 Limit-10 Unlimited
Storage Overhead (MBs)
Storage Overhead (MBs)
Max Length of Quality Trail Max Length of Quality Trail
(a) Storage Overhead Under Full Transitions (b) Storage Overhead Under Minimal Transitions
Minimal Transitions
3.7%
Relative Update Overhead
Off-Table Scheme QTrail-Scheme Off-Table Scheme QTrail-Scheme
Reference performance
(updating Gene.Seq)
Relative performance of updating Gene.StartPos
Batch Order & Transition Size
Off-Table Scheme QTrail-Scheme
Full Transitions
Figure 6: Quality Trail Storage Overhead.
0
100
200
300
400
500
600
0
500
1000
1500
2000
2500
0
0.2
0.4
0.6
0.8
1
1.2
1st Last 1st Last
All Some
4.5%
7.6%
18%
1%
1.8%
Limit-5 Limit-10 Unlimited
Limit-5 Limit-10 Unlimited
Storage Overhead (MBs)
Storage Overhead (MBs)
Max Length of Quality Trail Max Length of Quality Trail
(a) Storage Overhead Under Full Transitions (b) Storage Overhead Under Minimal Transitions
Minimal Transitions
3.7%
Relative Update Overhead
Off-Table Scheme QTrail-Scheme Off-Table Scheme QTrail-Scheme
Reference performance
(updating Gene.Seq)
Relative performance of updating Gene.StartPos
Batch Order & Transition Size
Off-Table Scheme QTrail-Scheme
Full Transitions
Figure 7: Quality Trail Update Performance.
0
5
10
15
20
25
30
35
40
0.01% 0.05% 0.10% 0.50% 0.01% 0.05% 0.10% 0.50%
QTrail-Scheme
Off-Table Scheme
0
2
4
6
8
10
12
14
16
18
0.01% 0.05% 0.10% 0.50% 0.01% 0.05% 0.10% 0.50%
QTrail-Scheme
Off-Table Scheme
Exec. Time Overhead %
Exec. Time Overhead %
Query Selectivity & Storage Scheme Query Selectivity & Storage Scheme
(a) SP Query Performance (No Index) (b) SP Query Performance (With Index)
x"
Unlimited
Limit-10
Limit-5
x"
Unlimited
Limit-10
Limit-5
Select Id, Name, Seq
From Gene
Where Id > val1
And Id < val2;
Select Id, Name, Seq
From Protein
Where Id > val1
And Id < val2;
(c) SP Query Templates
Figure 8: Performance of Select-Project (SP) Queries.
ditional fields, e.g., updating a text or integer fields.
In all cases, the update operation takes place from
within an After Insert trigger over the Comment table
as described in the experimental workload above. In-
side the trigger, the corresponding gene is retrieved
to update its data or its quality trail (See Example 2
in Section 5). The retrieval from the DB uses a B-
Tree index on the Gene.ID column. Each operation
is repeated 20 times, and their average is what we re-
port. As illustrated in Figure 7, we use the operation
of updating a string field, more specifically replacing
a segment of Gene.Seq field with another segment, as
our reference operation. That is, its execution time is
normalized to value 1, and the other operations will
be measured relative to this operation. The relative
performance of updating an integer field, more specif-
ically Gene.StartPos, it also depicted in the figure.
On average, the overhead of updating the integer field
is around 94% of updating the string field.
For updating the quality trails, we consider both
the QTrail-Scheme, and the Off-Table Scheme, and
the two cases of Full Transition, and Minimal Transi-
tion. For each case, we run a batch that consists of 20
transactions inserting records into the Comment table,
which yield to updating the genes’ quality trails. On
the x-axis, we report the average performance over the
entire batch under two scenarios: (1) The batch is the
1
st
, i.e., all quality trails are empty, and (2) The batch
is the Last, where all other records have been inserted
and the quality trails are almost complete. The re-
sults in Figure 7 show that operating on and updating
a quality trail structure is very comparable to updat-
ing other database fields. Under the QTrail-Scheme,
where the table to be queried and update is the Gene
table, the relative overhead ranged from 0.98% (The
1
st
batch with minimal transitions) to 1.11% (The last
batch with full transitions). The performance of the
Off-Table Scheme, where the table to be queried and
updated is called Gene-QTrail, is almost the same
except for the 1
st
batch case, where the Gene-QTrail
table is empty.
SP Query Performance: In the next experiments, we
evaluate the propagation and derivation of the qual-
ity trails at query time under various types of queries.
In Figure 8, we present the performance of Select-
Project (SP) queries. The query templates are pre-
sented in Figure 8(c). On the x-axis of Figures 8(a)
and 8(b), we vary the query selectivity from 0.01%
(corresponds to 75 protein tuples, or 130 gene tu-
ples) to 0.5% (corresponds to 3,750 protein tuples,
or 6,500 gene tuples), and consider the two storage
schemes QTrail-Scheme and Off-Table Scheme. The
y-axis measures the propagation overhead of the qual-
ity trails w.r.t the standard query performance, i.e.,
no quality trail storage or propagation. We consider
the propagation of the quality trails under the max
QTrail-DB: A Query Processing Engine for Imperfect Databases with Evolving Qualities
301

size constraints of Limit-5, Limit-10, and Unlimited.
Under each configuration, we execute 5 queries on
each of the Gene and Protein tables, and then report
the average of the observed overheads across the 10
queries. Figures 8(a) and 8(b) show the results under
the cases where the queries are executed without and
with an index, respectively.
The results show a big difference between the
QTrail-Scheme and the Off-Table Scheme. This is
mainly because the two operators that directly read
from disk have different implementation under the
two storage schemes. In the QTrail-Scheme, they
are implemented such that they read the quality trails
from the data tuples without any additional overhead.
Whereas in the Off-Table Scheme, they are imple-
mented to join the data tuples with the other table
that contains the quality trails. All the other operators
are independent of the physical storage of the quality
trails as they read them from the operators’ buffers in
the query pipeline. Since join is an expensive oper-
ation, the Off-Table Scheme encounters higher over-
head. In Figure 8(a), the query selectivity does not
play a big factor because a complete table scan is per-
formed regardless of the selectivity, which dominates
most of the cost. In contrast, in Figure 8(b), an index
is used to select the data tuples satisfying the query’s
predicates, and thus the performance is more sensitive
to the query selectivity. For the Off-Table Scheme,
the overhead increases as the selectivity increases—
and consequently the join cost increases. As the fig-
ure shows the Off-Table Scheme encounters between
2.5x and 6x higher overhead compared to the QTrail-
Scheme. It is important to highlight that the select and
project operators do not apply any manipulation over
the quality trails, and thus the encountered overheads
are mostly due to the additional storage introduced by
the quality trails.
Additional experiments and results are available in
the extended version of this paper (Author A, 2023).
7 CONCLUSION
We proposed QTrail-DB as an advanced query pro-
cessing engine for imperfect databases with evolving
qualities. At the conceptual level, QTrail-DB enables
high-level applications to model their data’s quali-
ties inside the database system, keep track of how
the qualities evolve over time, and build more in-
formed decisions based on the automatically quality-
annotated query results. At the technical level,
QTrail-DB involves several novel contributions in-
cluding: (1) Introducing a new quality model based
on the new concept of “quality trails” in contrast
to the commonly-used single-score quality model,
(2) Extending the relational data model to include the
quality trails, and (3) Proposing a new query algebra,
called “QTrail Algebra”, which extends the standard
query operators as well as introduces new quality-
related operators for the propagation and derivation
of quality trails at query time. The experimental eval-
uation has shown the practicality of QTrail-DB, and
the efficiency of its design choices.
REFERENCES
Author A, A. B. (2023). Anonymized title of the paper.
Ballou, D. P., Chengalur-Smith, I. N., and Wang, R. Y.
(2006). Sample-Based Quality Estimation of Query
Results in Relational Database Environments. IEEE
Knowledge and Data Engineering, 18(5).
Batini, C. and Scannapieco, M. (2006). Data Quality:
Concepts, Methodologies and Techniques. Addison-
Wesley.
Dallachiesa, M., Ebaid, A., Eldawy, A., Elmagarmid,
A. K., Ilyas, I. F., Ouzzani, M., and Tang, N. (2013).
NADEEF: a commodity data cleaning system. In SIG-
MOD Conference, pages 541–552.
Galindo, J., Urrutia, A., and Piattini, M. (2006). Fuzzy
databases: Modeling, design, and implementation.
Idea Group Publishing.
IBM (2021). The high cost of poor data quality for the us
economy. https://www.ibm.com/thought-leadership/
institute-business-value/report/poor-data-quality. Ac-
cessed on May 5, 2023.
Rahm, E. and Do, H. H. (2016). Data cleaning: Prob-
lems and current approaches. IEEE Data Eng. Bull.,
39(2):3–13.
Stonebraker, M., Rowe, L. A., and Hirohama, M.
(1990). The implementation of POSTGRES. TKDE,
2(1):125–142.
The Universal Protein Resource Databases (2023). http://
www.ebi.ac.uk/uniprot/.
Twombly, M. (2011). Science online survey: Support for
data curation. Science Journal, 331.
Widom, J. (2005a). Trio: A system for integrated man-
agement of data, accuracy, and lineage. CIDR, pages
262–276.
Widom, J. (2005b). Trio: A system for integrated man-
agement of data, accuracy, and lineage. CIDR, pages
262–276.
DATA 2023 - 12th International Conference on Data Science, Technology and Applications
302
